
STMVis - Visual Analysis for Recurrent Neural Networks
LSTMVis a visual analysis tool for recurrent neural networks with a focus on understanding these hidden state dynamics. The tool allows a user to select a hypothesis input range to focus on local state changes, to match these states changes to similar patterns in a large data set, and to align these results with structural annotations from their domain. We provide data for the tool to analyze specific hidden state properties on dataset containing nesting, phrase structure, and chord progressions, and demonstrate how the tool can be used to isolate patterns for further statistical analysis.
http://lstm.seas.harvard.edu/
#harvard #video #dl #rnn
LSTMVis a visual analysis tool for recurrent neural networks with a focus on understanding these hidden state dynamics. The tool allows a user to select a hypothesis input range to focus on local state changes, to match these states changes to similar patterns in a large data set, and to align these results with structural annotations from their domain. We provide data for the tool to analyze specific hidden state properties on dataset containing nesting, phrase structure, and chord progressions, and demonstrate how the tool can be used to isolate patterns for further statistical analysis.
http://lstm.seas.harvard.edu/
#harvard #video #dl #rnn
lstm.seas.harvard.edu
LSTMVis
A visual analysis tool for recurrent neural networks
Another #CVPR2018 paper award: Global Pose Estimation with Attention-based RNNs.
Arxiv: https://arxiv.org/abs/1802.06857
#pose #rnn #dl
Arxiv: https://arxiv.org/abs/1802.06857
#pose #rnn #dl
A cool paper from Facebook AI (not from FAIR!) about detecting and reading text in images, at scale.
This is very useful for detecting inappropriate content on Facebook.
The system uses R-CNN/Detectron for detecting lines of text.
The OCR uses a ConvNet applied at the level of a whole line trained with CTC.
This concept of applying a ConvNet on a whole line of text, without prior segmentation, has roots in the early days of ConvNets, for example with this NIPS 1992 paper:
"Multi-Digit Recognition Using a Space Displacement Neural Network"
by Ofer Matan, Chris Burges, Yann LeCun and John Denker.
Link: https://papers.nips.cc/paper/557-multi-digit-recognition-using-a-space-displacement-neural-network
Youtuve video with short explanation: https://youtu.be/yl3P2tYewVg
#ocr #cv #dl #rnn #facebook #yannlecun #video
This is very useful for detecting inappropriate content on Facebook.
The system uses R-CNN/Detectron for detecting lines of text.
The OCR uses a ConvNet applied at the level of a whole line trained with CTC.
This concept of applying a ConvNet on a whole line of text, without prior segmentation, has roots in the early days of ConvNets, for example with this NIPS 1992 paper:
"Multi-Digit Recognition Using a Space Displacement Neural Network"
by Ofer Matan, Chris Burges, Yann LeCun and John Denker.
Link: https://papers.nips.cc/paper/557-multi-digit-recognition-using-a-space-displacement-neural-network
Youtuve video with short explanation: https://youtu.be/yl3P2tYewVg
#ocr #cv #dl #rnn #facebook #yannlecun #video
papers.nips.cc
Multi-Digit Recognition Using a Space Displacement Neural Network
Electronic Proceedings of Neural Information Processing Systems
Zero-Shot Style Transfer in Text Using Recurrent Neural Networks
This is an article on text style transfer. There is an example code to check the results.
Paper: https://arxiv.org/pdf/1711.04731.pdf
Code: https://github.com/keithecarlson/Zero-Shot-Style-Transfer
#NLP #seq2seq #dl #rnn
This is an article on text style transfer. There is an example code to check the results.
Paper: https://arxiv.org/pdf/1711.04731.pdf
Code: https://github.com/keithecarlson/Zero-Shot-Style-Transfer
#NLP #seq2seq #dl #rnn
GitHub
GitHub - keithecarlson/Zero-Shot-Style-Transfer
Contribute to keithecarlson/Zero-Shot-Style-Transfer development by creating an account on GitHub.
Reversible RNNs
Paper about how to reduce memory costs of GRU and LSTM networks by 10-15x without loss in performance. Also 5-10x for attention-based architectures. New paper with Matt MacKay, Paul Vicol, and Jimmy Ba, to appear at NIPS.
Link: https://arxiv.org/abs/1810.10999
#dl #RNN #NIPS2018
Paper about how to reduce memory costs of GRU and LSTM networks by 10-15x without loss in performance. Also 5-10x for attention-based architectures. New paper with Matt MacKay, Paul Vicol, and Jimmy Ba, to appear at NIPS.
Link: https://arxiv.org/abs/1810.10999
#dl #RNN #NIPS2018
And the same for #ResNet, #RNN and feed-forward #nn without residual connections.
Gradient Descent Finds Global Minima of Deep Neural Networks
ArXiV: https://arxiv.org/pdf/1811.03804.pdf
On the Convergence Rate of Training Recurrent Neural Networks
ArXiV: https://arxiv.org/pdf/1810.12065.pdf
A Convergence Theory for Deep Learning via Over-Parameterization
ArXiV: https://arxiv.org/pdf/1811.03962.pdf
#dl
Gradient Descent Finds Global Minima of Deep Neural Networks
ArXiV: https://arxiv.org/pdf/1811.03804.pdf
On the Convergence Rate of Training Recurrent Neural Networks
ArXiV: https://arxiv.org/pdf/1810.12065.pdf
A Convergence Theory for Deep Learning via Over-Parameterization
ArXiV: https://arxiv.org/pdf/1811.03962.pdf
#dl
Deep learning cheatsheets, covering content of Stanford’s CS 230 class.
CNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
RNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
TipsAndTricks: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-deep-learning-tips-and-tricks
#cheatsheet #Stanford #dl #cnn #rnn #tipsntricks
CNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
RNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
TipsAndTricks: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-deep-learning-tips-and-tricks
#cheatsheet #Stanford #dl #cnn #rnn #tipsntricks
stanford.edu
CS 230 - Convolutional Neural Networks Cheatsheet
Teaching page of Shervine Amidi, Graduate Student at Stanford University.
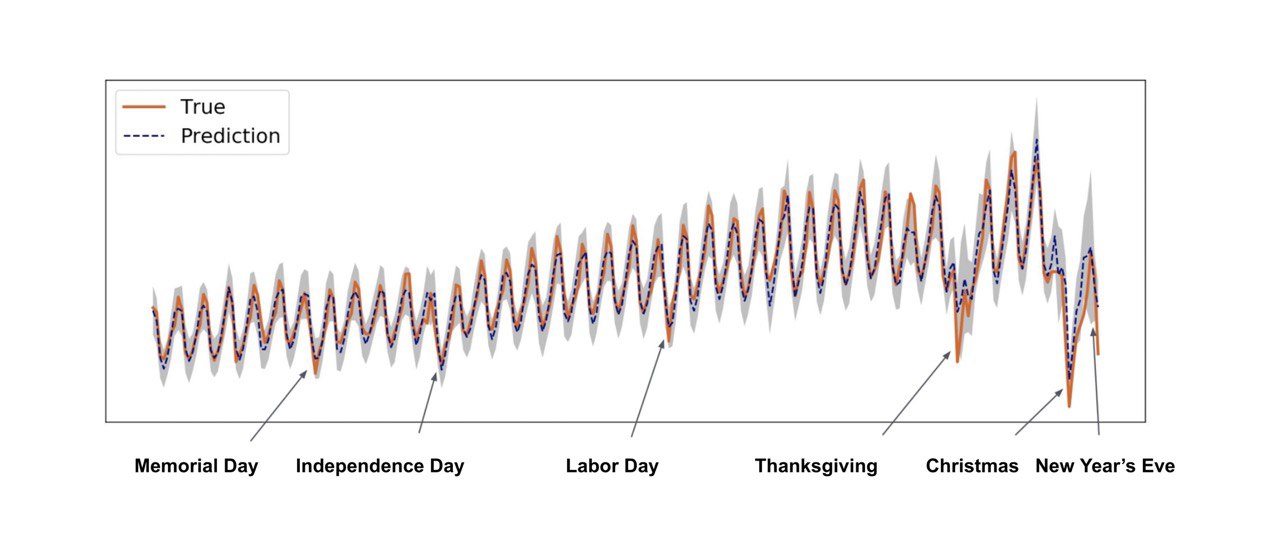
How Uber predicts prices
Engineering Uncertainty Estimation in Neural Networks for Time Series Prediction at Uber
Link: https://eng.uber.com/neural-networks-uncertainty-estimation/
#RNN #LSTM #Uber
Engineering Uncertainty Estimation in Neural Networks for Time Series Prediction at Uber
Link: https://eng.uber.com/neural-networks-uncertainty-estimation/
#RNN #LSTM #Uber
{kind=link}
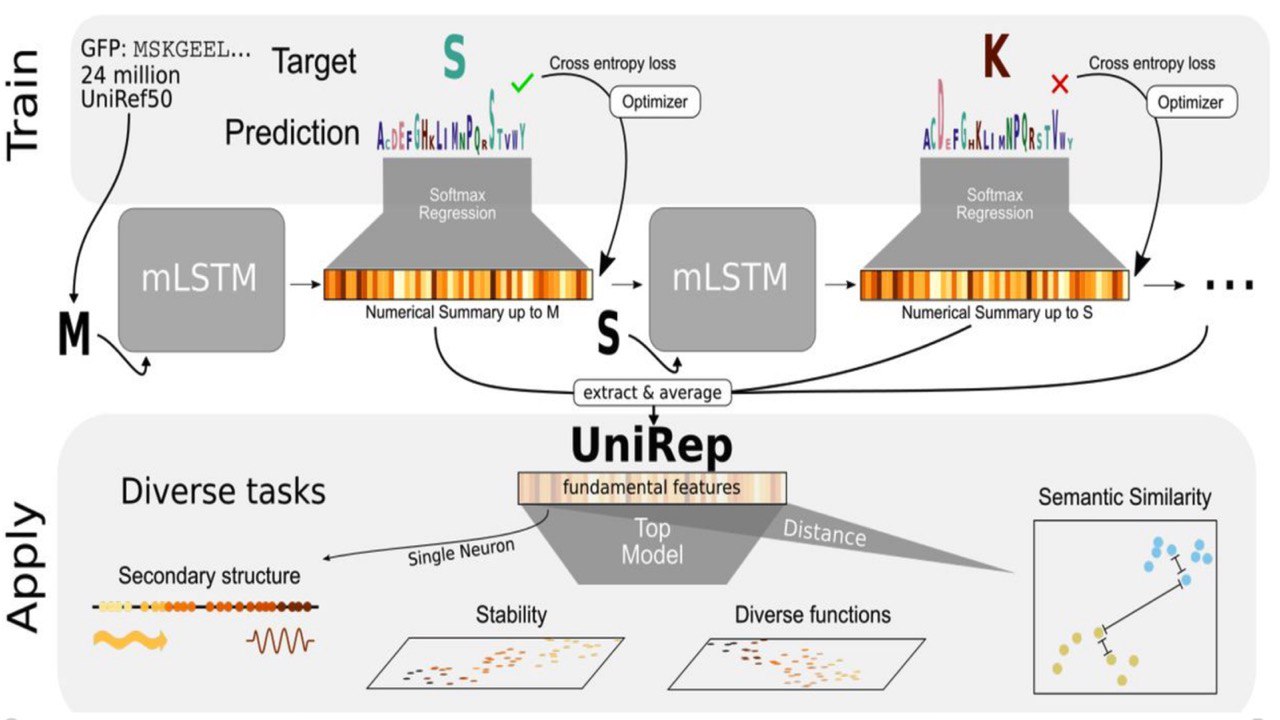
Unified rational protein engineering with sequence-only deep representation learning
UniRep predicts amino-acid sequences that form stable bonds. In industry, that’s vital for determining the production yields, reaction rates, and shelf life of protein-based products.
Link: https://www.biorxiv.org/content/10.1101/589333v1.full
#biolearning #rnn #Harvard #sequence #protein
UniRep predicts amino-acid sequences that form stable bonds. In industry, that’s vital for determining the production yields, reaction rates, and shelf life of protein-based products.
Link: https://www.biorxiv.org/content/10.1101/589333v1.full
#biolearning #rnn #Harvard #sequence #protein
{kind=link}