
An agent which learned to play Mario without rewards. Instead, it was incentivized to avoid "boredom" (that is, getting into states where it can predict what will happen next). Discovered warp levels, how to defeat bosses, etc.
Link: https://blog.openai.com/reinforcement-learning-with-prediction-based-rewards/
#RL #openai
Link: https://blog.openai.com/reinforcement-learning-with-prediction-based-rewards/
#RL #openai
OpenAI’s new model can generate surprisingly realistic fake news.
New model, called GPT-2 is an unsupervised language model that can generate coherent paragraphs and perform rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training.
Link: https://blog.openai.com/better-language-models/
Paper: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
#OpenAI #NLP #fakenews #qa #DL
New model, called GPT-2 is an unsupervised language model that can generate coherent paragraphs and perform rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training.
Link: https://blog.openai.com/better-language-models/
Paper: https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
#OpenAI #NLP #fakenews #qa #DL
Open AI releasing MMO.
Spoiler: it is not MMORPG. It is Massively Multiagent Mame environment for reinforcement learning agents. It will allow to develop something what for #trueAI will be like an amoeba to human. But it’s live now.
Link: https://blog.openai.com/neural-mmo/
Github: https://github.com/openai/neural-mmo
3DClient github: https://github.com/jsuarez5341/neural-mmo-client
#OpenAI
Spoiler: it is not MMORPG. It is Massively Multiagent Mame environment for reinforcement learning agents. It will allow to develop something what for #trueAI will be like an amoeba to human. But it’s live now.
Link: https://blog.openai.com/neural-mmo/
Github: https://github.com/openai/neural-mmo
3DClient github: https://github.com/jsuarez5341/neural-mmo-client
#OpenAI
Data Science by ODS.ai 🦜
Exploring Neural Networks with Activation Atlases Amazing interactive article on feature visualizations, letting us see through the eyes of the neural network. The hidden layers of neural networks are quite fun to inspect. Interactive website: https:…
Introducing Activation Atlases by #OpenAI
OpenAI in collaboration with #Google created activation atlases, a new technique for visualizing what interactions between neurons can represent.
Link: https://blog.openai.com/introducing-activation-atlases/
Direct demo link: https://distill.pub/2019/activation-atlas/app.html
Github: https://github.com/tensorflow/lucid/#activation-atlas-notebooks
OpenAI in collaboration with #Google created activation atlases, a new technique for visualizing what interactions between neurons can represent.
Link: https://blog.openai.com/introducing-activation-atlases/
Direct demo link: https://distill.pub/2019/activation-atlas/app.html
Github: https://github.com/tensorflow/lucid/#activation-atlas-notebooks
OpenAI
Introducing Activation Atlases
We’ve created activation atlases (in collaboration with researchers from Google Brain), a new technique for visualizing interactions between neurons.
OpenAI’s MuseNet architecture to generate music.
#MuseNet — neural network which discovered how to generate music from first 5 or so notes, using many different instruments and styles.
Post: https://openai.com/blog/musenet/
MuseNet will play an experimental concert today from 12–3pm PT on livestream: http://twitch.tv/openai
#audiolearning #musicgeneration #OpenAI #soundgeneration
#MuseNet — neural network which discovered how to generate music from first 5 or so notes, using many different instruments and styles.
Post: https://openai.com/blog/musenet/
MuseNet will play an experimental concert today from 12–3pm PT on livestream: http://twitch.tv/openai
#audiolearning #musicgeneration #OpenAI #soundgeneration
Openai
MuseNet
We’ve created MuseNet, a deep neural network that can generate 4-minute musical compositions with 10 different instruments, and can combine styles from country to Mozart to the Beatles. MuseNet was not explicitly programmed with our understanding of music…
GPT-2: 6-Month Follow-Up
#OpenAI released the 774 million parameter #GPT2 language model.
Link: https://openai.com/blog/gpt-2-6-month-follow-up/
#NLU #NLP
#OpenAI released the 774 million parameter #GPT2 language model.
Link: https://openai.com/blog/gpt-2-6-month-follow-up/
#NLU #NLP
Openai
GPT-2: 6-month follow-up
We’re releasing the 774 million parameter GPT-2 language model after the release of our small 124M model in February, staged release of our medium 355M model in May, and subsequent research with partners and the AI community into the model’s potential for…
Testing Robustness Against Unforeseen Adversaries
OpenAI developed a method to assess whether a neural network classifier can reliably defend against adversarial attacks not seen during training. The method yields a new metric, #UAR (Unforeseen Attack Robustness), which evaluates the robustness of a single model against an unanticipated attack, and highlights the need to measure performance across a more diverse range of unforeseen attacks.
Link: https://openai.com/blog/testing-robustness/
ArXiV: https://arxiv.org/abs/1908.08016
Code: https://github.com/ddkang/advex-uar
#GAN #Adversarial #OpenAI
OpenAI developed a method to assess whether a neural network classifier can reliably defend against adversarial attacks not seen during training. The method yields a new metric, #UAR (Unforeseen Attack Robustness), which evaluates the robustness of a single model against an unanticipated attack, and highlights the need to measure performance across a more diverse range of unforeseen attacks.
Link: https://openai.com/blog/testing-robustness/
ArXiV: https://arxiv.org/abs/1908.08016
Code: https://github.com/ddkang/advex-uar
#GAN #Adversarial #OpenAI
⭐️Fine-Tuning GPT-2 from Human Preferences
#OpenAI team fine-tuned 774M parameters model to achieve better scores in #summarization and stylistic text continuation in terms of human understanding.
Article definately worths reading (approx 15 min.) with Challenges and lessons learned section and examples.
Link: https://openai.com/blog/fine-tuning-gpt-2/
Paper: https://arxiv.org/abs/1909.08593
Code: https://github.com/openai/lm-human-preferences
#NLP #NLU #finetuning
#OpenAI team fine-tuned 774M parameters model to achieve better scores in #summarization and stylistic text continuation in terms of human understanding.
Article definately worths reading (approx 15 min.) with Challenges and lessons learned section and examples.
Link: https://openai.com/blog/fine-tuning-gpt-2/
Paper: https://arxiv.org/abs/1909.08593
Code: https://github.com/openai/lm-human-preferences
#NLP #NLU #finetuning
Openai
Fine-tuning GPT-2 from human preferences
We’ve fine-tuned the 774M parameter GPT-2 language model using human feedback for various tasks, successfully matching the preferences of the external human labelers, though those preferences did not always match our own. Specifically, for summarization tasks…
🎓 Reinforcement Learning Course from OpenAI
Reinforcement Learning becoming significant part of the data scientist toolbox.
OpenAI created and published one of the best courses in #RL. Algorithms implementation written in #Tensorflow.
But if you are more comfortable with #PyTorch, we have found #PyTorch implementation of this algs
OpenAI Course: https://spinningup.openai.com/en/latest/
Tensorflow Code: https://github.com/openai/spinningup
PyTorch Code: https://github.com/kashif/firedup
#MOOC #edu #course #OpenAI
Reinforcement Learning becoming significant part of the data scientist toolbox.
OpenAI created and published one of the best courses in #RL. Algorithms implementation written in #Tensorflow.
But if you are more comfortable with #PyTorch, we have found #PyTorch implementation of this algs
OpenAI Course: https://spinningup.openai.com/en/latest/
Tensorflow Code: https://github.com/openai/spinningup
PyTorch Code: https://github.com/kashif/firedup
#MOOC #edu #course #OpenAI
GitHub
GitHub - openai/spinningup: An educational resource to help anyone learn deep reinforcement learning.
An educational resource to help anyone learn deep reinforcement learning. - openai/spinningup
🔥OpenAI realesed the 1.5billion parameter GPT-2 model
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Post: https://openai.com/blog/gpt-2-1-5b-release/
GPT-2 output detection model: https://github.com/openai/gpt-2-output-dataset/tree/master/detector
Research from partners on potential malicious uses: https://d4mucfpksywv.cloudfront.net/papers/GPT_2_Report.pdf
#NLU #GPT2 #OpenAI #NLP
Openai
GPT-2: 1.5B release
As the final model release of GPT-2’s staged release, we’re releasing the largest version (1.5B parameters) of GPT-2 along with code and model weights to facilitate detection of outputs of GPT-2 models. While there have been larger language models released…
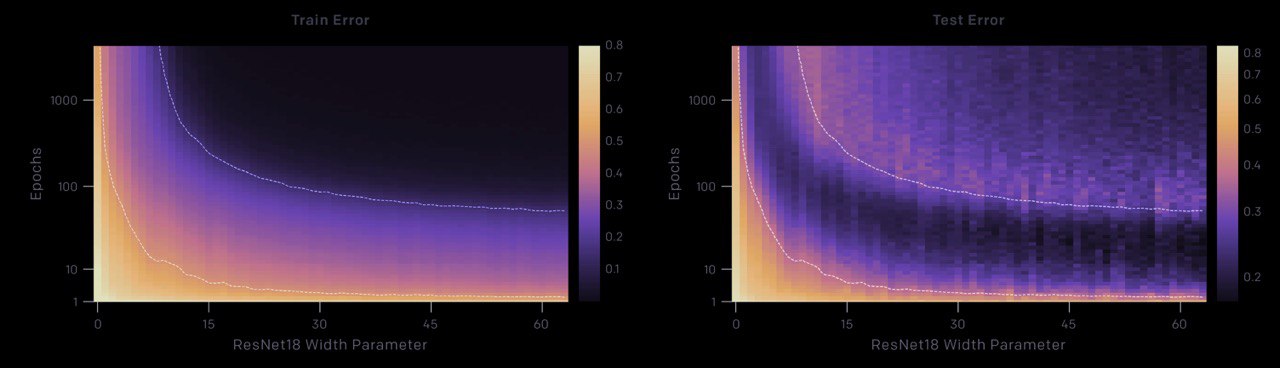
DEEP DOUBLE DESCENT
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
{kind=link}
🎙🎶Improved audio generative model from OpenAI
Wow! OpenAI just released Jukebox – neural net and service that generates music from genre, artist name, and some lyrics that you can supply. It is can generate even some singing like from corrupted magnet compact cassette.
Some of the sounds seem it is from hell. Agonizing Michel Jakson for example or Creepy Eminiem or Celien Dion
#OpenAI 's approach is to use 3 levels of quantized variational autoencoders VQVAE-2 to learn discrete representations of audio and compress audio by 8x, 32x, and 128x and use the spectral loss to reconstruct spectrograms. And after that, they use sparse transformers conditioned on lyrics to generate new patterns and upsample it to higher discrete samples and decode it to the song.
The net can even learn and generates some solo parts during the track.
explore some creepy songs: https://jukebox.openai.com/
code: https://github.com/openai/jukebox/
paper: https://cdn.openai.com/papers/jukebox.pdf
blog: https://openai.com/blog/jukebox/
#openAI #music #sound #cool #fan #creepy #vae #audiolearning #soundlearning
Wow! OpenAI just released Jukebox – neural net and service that generates music from genre, artist name, and some lyrics that you can supply. It is can generate even some singing like from corrupted magnet compact cassette.
Some of the sounds seem it is from hell. Agonizing Michel Jakson for example or Creepy Eminiem or Celien Dion
#OpenAI 's approach is to use 3 levels of quantized variational autoencoders VQVAE-2 to learn discrete representations of audio and compress audio by 8x, 32x, and 128x and use the spectral loss to reconstruct spectrograms. And after that, they use sparse transformers conditioned on lyrics to generate new patterns and upsample it to higher discrete samples and decode it to the song.
The net can even learn and generates some solo parts during the track.
explore some creepy songs: https://jukebox.openai.com/
code: https://github.com/openai/jukebox/
paper: https://cdn.openai.com/papers/jukebox.pdf
blog: https://openai.com/blog/jukebox/
#openAI #music #sound #cool #fan #creepy #vae #audiolearning #soundlearning
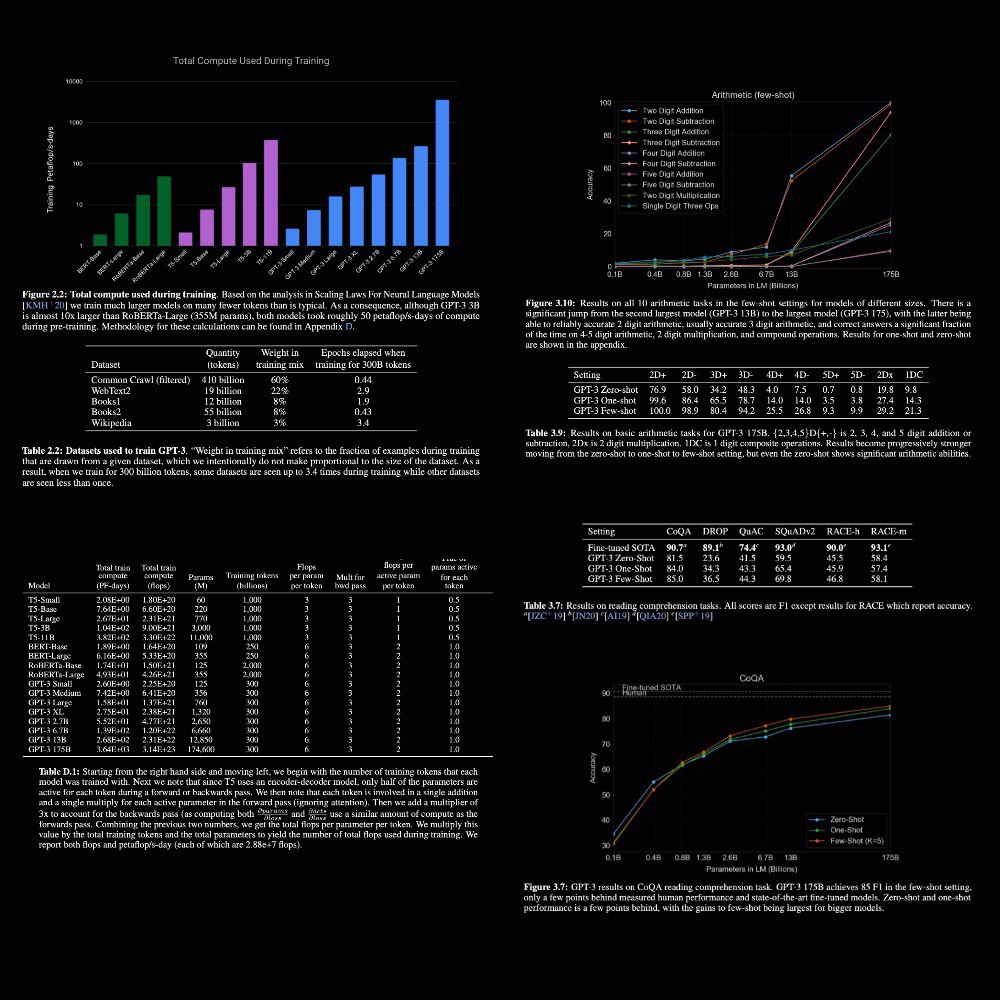
GPT-3: Language Models are Few-Shot Learners
#openAI train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting
Their model applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
Achieves strong performance on many NLP datasets, including translation, q&a, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Also, they find that GPT-3 can generate samples of news articles in which human evaluators have difficulty distinguishing from articles written by humans.
175 billion parameters! And on some tasks, it is not performed
It is all you need to know about
paper: https://arxiv.org/abs/2005.14165.pdf
#nlp #gpt #gpt3 #language #model
#openAI train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting
Their model applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
Achieves strong performance on many NLP datasets, including translation, q&a, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Also, they find that GPT-3 can generate samples of news articles in which human evaluators have difficulty distinguishing from articles written by humans.
175 billion parameters! And on some tasks, it is not performed
It is all you need to know about
paper: https://arxiv.org/abs/2005.14165.pdf
#nlp #gpt #gpt3 #language #model
{kind=link}
Image GPT
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
🔥New breakthrough on text2image generation by #OpenAI
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
{kind=link}