
Baidu’s neural network based system learned to "clone" a voice with less than a minute of audio data from the speaker.
Explaining website: http://research.baidu.com/neural-voice-cloning-samples/
Paper: https://arxiv.org/pdf/1802.06006.pdf
#DeepLearning #Voice #Speech
Explaining website: http://research.baidu.com/neural-voice-cloning-samples/
Paper: https://arxiv.org/pdf/1802.06006.pdf
#DeepLearning #Voice #Speech
Google published new article about voice cloning: Expressive Speech Synthesis with Tacotron
link: https://research.googleblog.com/2018/03/expressive-speech-synthesis-with.html
samples: https://google.github.io/tacotron/publications/global_style_tokens/
#wavenet #audio #speech #deeplearning
link: https://research.googleblog.com/2018/03/expressive-speech-synthesis-with.html
samples: https://google.github.io/tacotron/publications/global_style_tokens/
#wavenet #audio #speech #deeplearning
Googleblog
Expressive Speech Synthesis with Tacotron
Make Trump Sing Again
Generated by a Trump TTS model trained based off the paper "Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis", where given a reference audio the model will try to replicate that style.
ArXiV: https://arxiv.org/pdf/1803.09017.pdf
Youtube: https://youtu.be/3rgAVT8b4fw
#tts #song #speech #DL
Generated by a Trump TTS model trained based off the paper "Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis", where given a reference audio the model will try to replicate that style.
ArXiV: https://arxiv.org/pdf/1803.09017.pdf
Youtube: https://youtu.be/3rgAVT8b4fw
#tts #song #speech #DL
Speech synthesis from neural decoding of spoken sentences
Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by #Nature. During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer.
Nature: https://www.nature.com/articles/s41586-019-1119-1
Paper: https://www.biorxiv.org/content/biorxiv/early/2018/11/29/481267.full.pdf
YouTube: https://www.youtube.com/watch?v=kbX9FLJ6WKw
#DeepDiveWeekly #DL #speech #audiolearning
Researchers tapped the brains of five epilepsy patients who had been implanted with electrodes to map the source of seizures, according to a paper published by #Nature. During a lull in the procedure, they had the patients read English-language texts aloud. They recorded the fluctuating voltage as the brain controlled the muscles involved in speaking. Later, they fed the voltage measurements into a synthesizer.
Nature: https://www.nature.com/articles/s41586-019-1119-1
Paper: https://www.biorxiv.org/content/biorxiv/early/2018/11/29/481267.full.pdf
YouTube: https://www.youtube.com/watch?v=kbX9FLJ6WKw
#DeepDiveWeekly #DL #speech #audiolearning
Nature
Speech synthesis from neural decoding of spoken sentences
Nature - A neural decoder uses kinematic and sound representations encoded in human cortical activity to synthesize audible sentences, which are readily identified and transcribed by listeners.
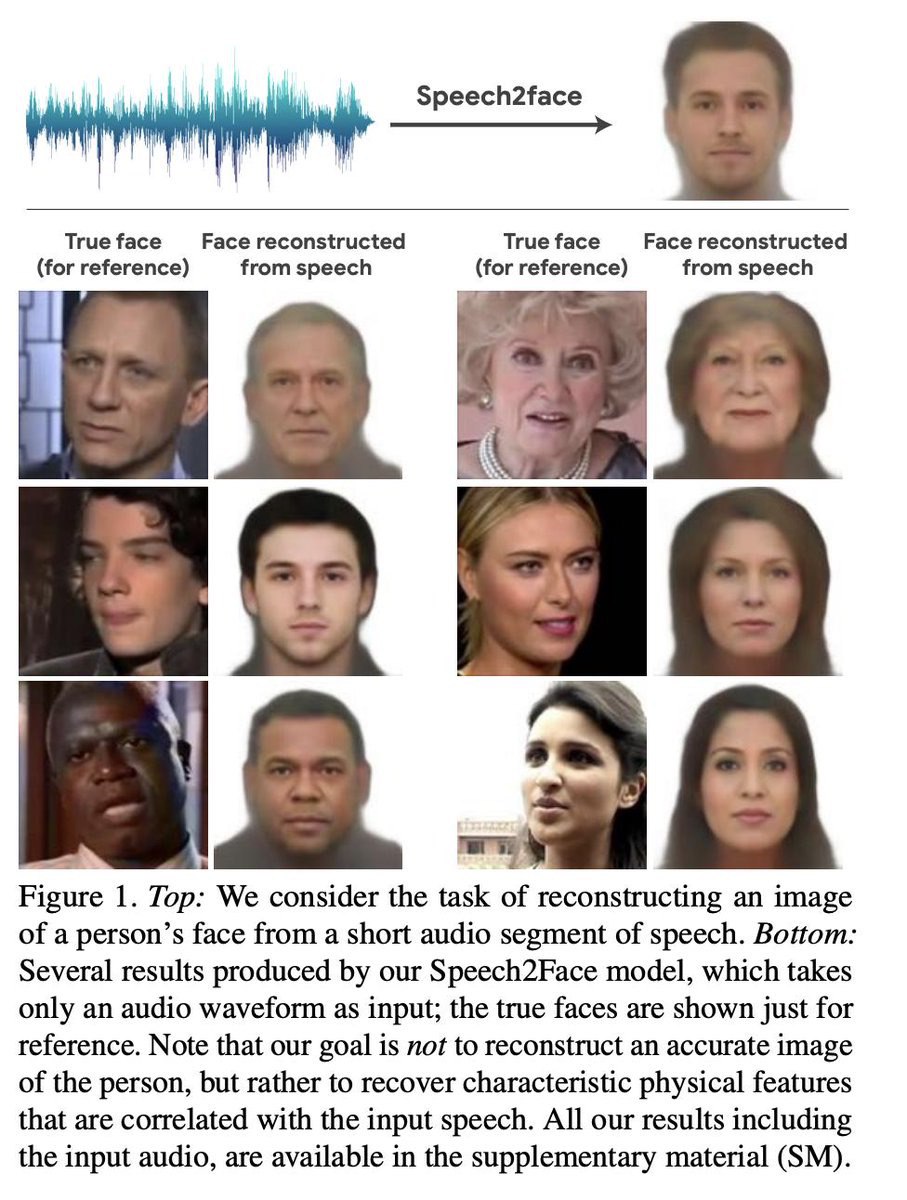
Recovering person appereance from person’s speech
As the result of the research, much resembling facial image of a person reconstructed from short audio recording of that person speaking.
ArXiV: https://arxiv.org/pdf/1905.09773v1.pdf
#speech #audiolearning #CV #DL #face
As the result of the research, much resembling facial image of a person reconstructed from short audio recording of that person speaking.
ArXiV: https://arxiv.org/pdf/1905.09773v1.pdf
#speech #audiolearning #CV #DL #face
{kind=link}
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
High-quality #speechrecognition systems require large amounts of data—yet many languages have little data available. Check out new research into an end-to-end system trained as a single model allowing for real-time multilingual speech recognition.
Link: https://ai.googleblog.com/2019/09/large-scale-multilingual-speech.html
#speech #audio #DL #Google
High-quality #speechrecognition systems require large amounts of data—yet many languages have little data available. Check out new research into an end-to-end system trained as a single model allowing for real-time multilingual speech recognition.
Link: https://ai.googleblog.com/2019/09/large-scale-multilingual-speech.html
#speech #audio #DL #Google
Googleblog
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
mellotron by #NVIDIA
It's a multispeaker #voice synthesis model based on #Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data.
By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate #speech in a variety of styles ranging from reading speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice.
Unlike other methods, Mellotron trains using only read speech data without alignments between text and audio.
Site: https://nv-adlr.github.io/Mellotron
Paper: https://arxiv.org/abs/1910.11997
Git: https://github.com/NVIDIA/mellotron
It's a multispeaker #voice synthesis model based on #Tacotron 2 GST that can make a voice emote and sing without emotive or singing training data.
By explicitly conditioning on rhythm and continuous pitch contours from an audio signal or music score, Mellotron is able to generate #speech in a variety of styles ranging from reading speech to expressive speech, from slow drawls to rap and from monotonous voice to singing voice.
Unlike other methods, Mellotron trains using only read speech data without alignments between text and audio.
Site: https://nv-adlr.github.io/Mellotron
Paper: https://arxiv.org/abs/1910.11997
Git: https://github.com/NVIDIA/mellotron
{kind=link}
Forwarded from Spark in me (Alexander)
Towards an ImageNet Moment for Speech-to-Text
First CV, and then (arguably) NLP, have had their ImageNet moment — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Following the release of our production models / metrics, this is our piece on this topic on thegradient.pub! So far this is the largest work ever we have done, and I hope that it will not go under the radar.
It is in our hands now to make sure that speech recognition brings value to people worldwide, and not only some fat cats.
So, without further ado:
- The piece itself https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/
- Some more links here https://spark-in.me/post/towards-an-imagenet-moment-for-speech-to-text
- If you are on Twitter, please repost this message - https://twitter.com/gradientpub/status/1243967773635571712
A lot of thanks to Thegradient team, especially Andrey and Jacob, for the sheer amount of work they put in to make this piece readable and understandable!
Please like, share, repost!
Also, there will be a second piece with criticism, so stay tuned!
#speech
#deep_learning
First CV, and then (arguably) NLP, have had their ImageNet moment — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Following the release of our production models / metrics, this is our piece on this topic on thegradient.pub! So far this is the largest work ever we have done, and I hope that it will not go under the radar.
It is in our hands now to make sure that speech recognition brings value to people worldwide, and not only some fat cats.
So, without further ado:
- The piece itself https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/
- Some more links here https://spark-in.me/post/towards-an-imagenet-moment-for-speech-to-text
- If you are on Twitter, please repost this message - https://twitter.com/gradientpub/status/1243967773635571712
A lot of thanks to Thegradient team, especially Andrey and Jacob, for the sheer amount of work they put in to make this piece readable and understandable!
Please like, share, repost!
Also, there will be a second piece with criticism, so stay tuned!
#speech
#deep_learning
The Gradient
Towards an ImageNet Moment for Speech-to-Text
First CV, and then NLP, have had their 'ImageNet moment' — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
This media is not supported in your browser
VIEW IN TELEGRAM
Nvidia AI Noise Reduction
#Nvidia launches #KrispAI competitor Noise Reduction by AI on RTX Videocards.
Seems it works significantly better then other that kind of tools. But it needs to have Nvidia RTX officially.
But it possible to run it on older cards. The instruction is below. Or you can just download already hacked executable (also, below)
Setup Guide: https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
The instruction: https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
Executable (use it on your own risk): https://mega.nz/file/CJ0xDYTB#LPorY_aPVqVKfHqWVV7zxK8fNfRmxt6iw6KdkHodz1M
#noisereduction #soundlearning #dl #noise #sound #speech #nvidia
#Nvidia launches #KrispAI competitor Noise Reduction by AI on RTX Videocards.
Seems it works significantly better then other that kind of tools. But it needs to have Nvidia RTX officially.
But it possible to run it on older cards. The instruction is below. Or you can just download already hacked executable (also, below)
Setup Guide: https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
The instruction: https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
Executable (use it on your own risk): https://mega.nz/file/CJ0xDYTB#LPorY_aPVqVKfHqWVV7zxK8fNfRmxt6iw6KdkHodz1M
#noisereduction #soundlearning #dl #noise #sound #speech #nvidia