
Make Trump Sing Again
Generated by a Trump TTS model trained based off the paper "Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis", where given a reference audio the model will try to replicate that style.
ArXiV: https://arxiv.org/pdf/1803.09017.pdf
Youtube: https://youtu.be/3rgAVT8b4fw
#tts #song #speech #DL
Generated by a Trump TTS model trained based off the paper "Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis", where given a reference audio the model will try to replicate that style.
ArXiV: https://arxiv.org/pdf/1803.09017.pdf
Youtube: https://youtu.be/3rgAVT8b4fw
#tts #song #speech #DL
Parallel Neural Text-to-Speech
#Baidu Research team has reached a new milestone in text-to-speech (#TTS) with the release of the first fully parallel neural TTS system. It generates speech from text with a single feed-forward pass, which brings ~17.5X speed-up over previous autoregressive models.
Link: https://arxiv.org/pdf/1905.08459.pdf
#Baidu Research team has reached a new milestone in text-to-speech (#TTS) with the release of the first fully parallel neural TTS system. It generates speech from text with a single feed-forward pass, which brings ~17.5X speed-up over previous autoregressive models.
Link: https://arxiv.org/pdf/1905.08459.pdf
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
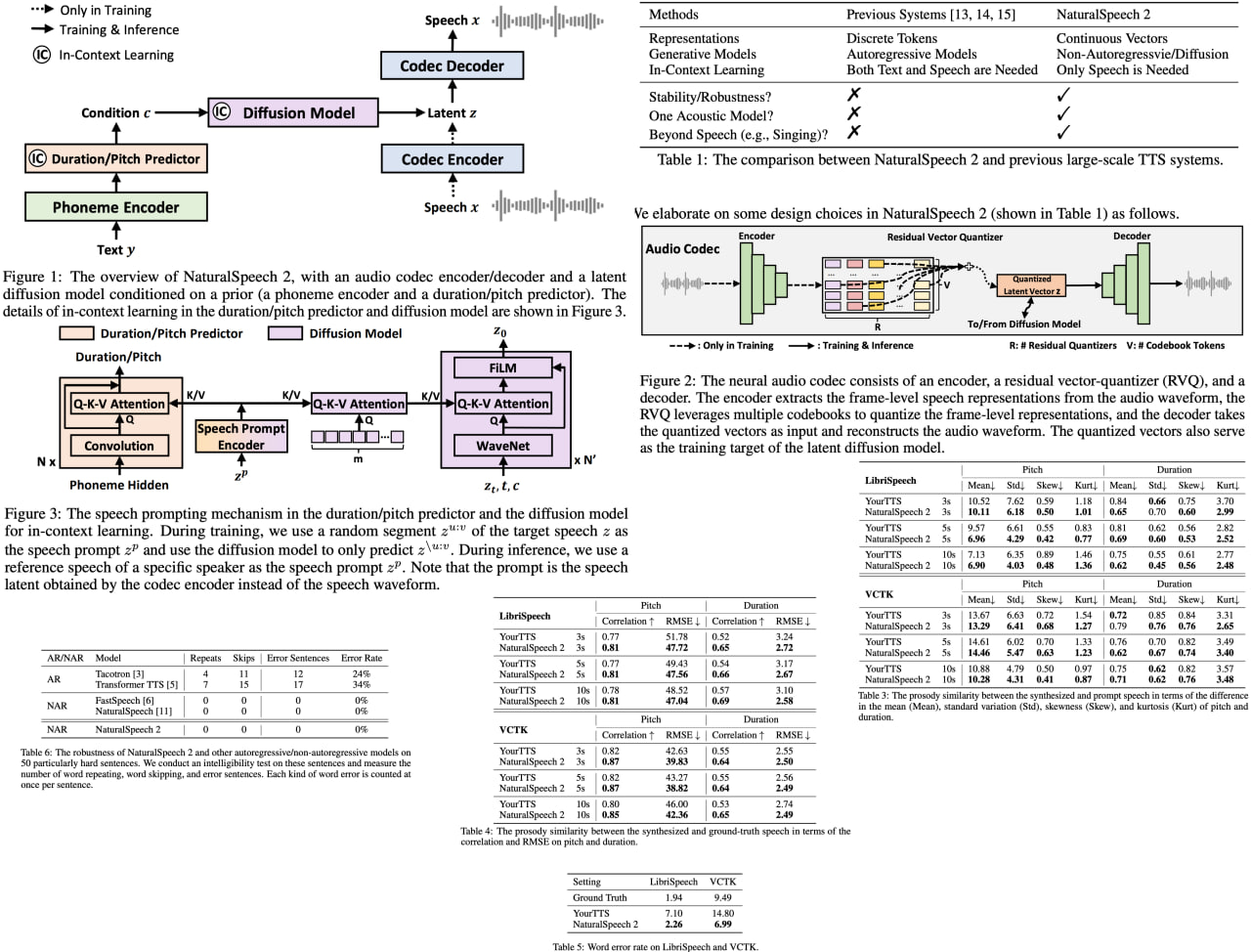
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
{kind=link}
🔥13👍5🆒2
MMS: Scaling Speech Technology to 1000+ languages
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
{kind=link}
🔥7❤5👍4🆒3