
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Work on conditional image generation
ArXiV: https://arxiv.org/abs/2012.02821
#GAN #DL #food2vec
Work on conditional image generation
ArXiV: https://arxiv.org/abs/2012.02821
#GAN #DL #food2vec
{kind=link}
{kind=link}
🔥New breakthrough on text2image generation by #OpenAI
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
{kind=link}
JigsawGAN: Self-supervised Learning for Solving Jigsaw Puzzles with Generative Adversarial Networks
The authors suggest a GAN-based approach for solving jigsaw puzzles. JigsawGAN is a self-supervised method with a multi-task pipeline: classification branch classifies jigsaw permutations, GAN branch recovers features to images with the correct order.
The proposed method can solve jigsaw puzzles efficiently by utilizing both semantic information and edge information simultaneously.
Paper: https://arxiv.org/abs/2101.07555
#deeplearning #jigsaw #selfsupervised #gan
The authors suggest a GAN-based approach for solving jigsaw puzzles. JigsawGAN is a self-supervised method with a multi-task pipeline: classification branch classifies jigsaw permutations, GAN branch recovers features to images with the correct order.
The proposed method can solve jigsaw puzzles efficiently by utilizing both semantic information and edge information simultaneously.
Paper: https://arxiv.org/abs/2101.07555
#deeplearning #jigsaw #selfsupervised #gan
{kind=link}
Real-World Super-Resolution of Face-Images from Surveillance Cameras
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
Most SR methods are trained on LR (low resolution) data, which is downsampled from HR (high resolution) data using bicubic interpolation, but real-life LR images are usually different, so models work worse on them. In this paper, the authors suggest using blur kernels, noise, and JPEG compression artifacts to generate LR images similar to the original ones.
Another suggested improvement is using ESRGAN and replacing VGG-loss with LPIPS-loss, as well as adding PatchGAN.
In addition, the authors show that NIMA metric better correlates with human perception (mean opinion rank) than traditional Image Quality Assessment methods.
Paper: https://arxiv.org/abs/2102.03113
#deeplearning #superresolution #gan #facesuperresolution
{kind=link}
Forwarded from Gradient Dude
LatentCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
A framework that learns meaningful directions in GANs' latent space using unsupervised contrastive learning. Instead of discovering fixed directions such as in previous work, this method can discover non-linear directions in pretrained StyleGAN2 and BigGAN models. The discovered directions may be used for image manipulation.
Authors use the differences caused by an edit operation on the feature activations to optimize the identifiability of each direction. The edit operations are modeled by several separate neural nets
∆_i(z) and learning. Given a latent code z and its generated image x = G(z), we seek to find edit operations ∆_i(z) such that the image x' = G(∆_i(z)) has semantically meaningful changes over x while still preserving the identity of x.📝 Paper
🛠 Code (next week)
#paper_tldr #cv #gan
Generating Furry Cars: Disentangling Object Shape and Appearance across Multiple Domains
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
This is an interesting paper about learning and combining representations of object shape and appearance from the different domains (for example, dogs and cars). This allows to create a model, which borrows different properties from each domain and generates images, which don't exist in a single domain.
The main idea is the following:
- use FineGAN as a base model;
- represent object appearance with a differentiable histogram of visual features;
- optimize the generator so that images with different shapes but similar appearances produce similar histograms;
Paper: https://openreview.net/forum?id=M88oFvqp_9
Project link: https://utkarshojha.github.io/inter-domain-gan/
Code will be available here: https://github.com/utkarshojha/inter-domain-gan
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-furrycars
#cv #gan #deeplearning #contrastivelearning
OpenReview
Generating Furry Cars: Disentangling Object Shape and Appearance...
We consider the novel task of learning disentangled representations of object shape and appearance across multiple domains (e.g., dogs and cars). The goal is to learn a generative model that...
Unsupervised 3D Neural Rendering of Minecraft Worlds
Work on unsupervised neural rendering framework for generating photorealistic images of Minecraft (or any large 3D block worlds).
Why this is cool: this is a step towards better graphics for games.
Project Page: https://nvlabs.github.io/GANcraft/
YouTube: https://www.youtube.com/watch?v=1Hky092CGFQ&t=2s
#GAN #Nvidia #Minecraft
Work on unsupervised neural rendering framework for generating photorealistic images of Minecraft (or any large 3D block worlds).
Why this is cool: this is a step towards better graphics for games.
Project Page: https://nvlabs.github.io/GANcraft/
YouTube: https://www.youtube.com/watch?v=1Hky092CGFQ&t=2s
#GAN #Nvidia #Minecraft
YouTube
NVIDIA GANcraft
Convert user-created 3D block worlds to realistic worlds!
More details at https://nvlabs.github.io/GANcraft/.
More details at https://nvlabs.github.io/GANcraft/.
GAN Prior Embedded Network for Blind Face Restoration in the Wild
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
Experimenting with CLIP+VQGAN to Create AI Generated Art
Tips and tricks on prompts to #vqclip. TLDR:
* Adding
* Using the pipe to split a prompt into separate prompts that are steered towards independently may be counterproductive.
Article: https://blog.roboflow.com/ai-generated-art/
Colab Notebook: https://colab.research.google.com/drive/1go6YwMFe5MX6XM9tv-cnQiSTU50N9EeT
#visualization #gan #generation #generatinveart #vqgan #clip
Tips and tricks on prompts to #vqclip. TLDR:
* Adding
rendered in unreal engine, trending on artstation, top of /r/art improves image quality significally.* Using the pipe to split a prompt into separate prompts that are steered towards independently may be counterproductive.
Article: https://blog.roboflow.com/ai-generated-art/
Colab Notebook: https://colab.research.google.com/drive/1go6YwMFe5MX6XM9tv-cnQiSTU50N9EeT
#visualization #gan #generation #generatinveart #vqgan #clip
🔥Alias-Free Generative Adversarial Networks (StyleGAN3) release
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
EditGAN: High-Precision Semantic Image Editing
Nvidia researches built an approach for editing segments of a picture with supposedly realtime picture augmentation according to the segment alterations. No demo is available yet though.
All the photoshop power users should relax, because appereance of such a tools means less work for them, not that the demand for the manual retouch will cease.
Website: https://nv-tlabs.github.io/editGAN/
ArXiV: https://arxiv.org/abs/2111.03186
#GAN #Nvidia
Nvidia researches built an approach for editing segments of a picture with supposedly realtime picture augmentation according to the segment alterations. No demo is available yet though.
All the photoshop power users should relax, because appereance of such a tools means less work for them, not that the demand for the manual retouch will cease.
Website: https://nv-tlabs.github.io/editGAN/
ArXiV: https://arxiv.org/abs/2111.03186
#GAN #Nvidia
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
Data Science by ODS.ai 🦜
There had been less posts than usual as you might have noticed, only because editor-in-chief's (mine) attention been directed to DeFi space in general and NFT in particular. However once involved with the beauty of AI and art, one can't just exit it, so…
GLIDE for image augmentation aka ToadVerse technical details
Technical details on how we used GLIDE for image augmentation.
Article Link: https://mirror.xyz/kefirski.eth/XN1cV27uHcAjN_tPSc_ckgSz4B3Nfh5l5HH9lRs9xEE
#GAN #StyleGAN2 #GLIDE #art #art_generation
Technical details on how we used GLIDE for image augmentation.
Article Link: https://mirror.xyz/kefirski.eth/XN1cV27uHcAjN_tPSc_ckgSz4B3Nfh5l5HH9lRs9xEE
#GAN #StyleGAN2 #GLIDE #art #art_generation
mirror.xyz
GLIDE for image augmentation aka ToadVerse technical details
We had an idea of shipping derivative of the Cryptoadz NFT collection because we like art, vibe, and community. We decided to exercise the idea of the existence of parallel blockchains and to integrate that into the lore of our collection. So, Toadverse as…
Imagen — new neural network for picture generation from Google
TLDR: Competitor of DALLE was released.
Imagen — text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. #Google key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Website: https://imagen.research.google
#GAN #CV #DL #Dalle
TLDR: Competitor of DALLE was released.
Imagen — text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. #Google key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Website: https://imagen.research.google
#GAN #CV #DL #Dalle
Data Science by ODS.ai 🦜
Big step after first DALL·E — DALL·E 2 In January 2021, OpenAI introduced DALL·E. One year later, their newest system, DALL·E 2, generates more realistic and accurate images with 4x greater resolution. The first DALL·E is a transformer model. It receives…
DALL·E Now Available in Beta
#Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around.
Images are also available for commercial use.
By default user can generate 460 images, further generations (or variations on generated images) will be available on paid plan.
Link: https://openai.com/blog/dall-e-now-available-in-beta/
#image #CV #GAN #generation #generatinveart
#Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around.
Images are also available for commercial use.
By default user can generate 460 images, further generations (or variations on generated images) will be available on paid plan.
Link: https://openai.com/blog/dall-e-now-available-in-beta/
#image #CV #GAN #generation #generatinveart
Openai
DALL·E now available in beta
We’ll invite 1 million people from our waitlist over the coming weeks. Users can create with DALL·E using free credits that refill every month, and buy additional credits in 115-generation increments for $15.
Data Science by ODS.ai 🦜
Experimenting with CLIP+VQGAN to Create AI Generated Art Tips and tricks on prompts to #vqclip. TLDR: * Adding rendered in unreal engine, trending on artstation, top of /r/art improves image quality significally. * Using the pipe to split a prompt into…
Some stats to get the perspective of the development of #dalle
«Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect, may mint someday. Curation is *1* step of AI art. I used to finish physicals in less time.»
Source: https://twitter.com/clairesilver12/status/1550709299797577729
#visualization #gan #generation #generatinveart #aiart #artgentips
«Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect, may mint someday. Curation is *1* step of AI art. I used to finish physicals in less time.»
Source: https://twitter.com/clairesilver12/status/1550709299797577729
#visualization #gan #generation #generatinveart #aiart #artgentips
Data Science by ODS.ai 🦜
Some stats to get the perspective of the development of #dalle «Used 1000 prompts in Dalle over the last 2 days, about 9 hours each day. Of those, saved ~300. 50 I like enough to share w/ socials. 12 enough to rework for future projects. 3 were perfect,…
Tips & Tricks on Image Generation
Generating images with AI tools is a skill, which can be improved and enhanced. So here is couple of articles, covering tips & tricks on how to generate better images with #midjourney. Most interesting one is #huggingface prompt generator, which uses #NLP model to generate sample prompts.
As an example, we tried to reproduce and improve our group avatar, following ideas in the articles. Prompt for an illustration to this post was generated with query
Midjourney Prompt Generator: https://huggingface.co/spaces/doevent/prompt-generator
List of Midjourney prompts: https://www.followchain.org/midjourney-prompts/
An advanced guide to writing prompts for Midjourney ( text-to-image): https://medium.com/mlearning-ai/an-advanced-guide-to-writing-prompts-for-midjourney-text-to-image-aa12a1e33b6
#visualization #gan #generation #generatinveart #aiart #artgentips
Generating images with AI tools is a skill, which can be improved and enhanced. So here is couple of articles, covering tips & tricks on how to generate better images with #midjourney. Most interesting one is #huggingface prompt generator, which uses #NLP model to generate sample prompts.
As an example, we tried to reproduce and improve our group avatar, following ideas in the articles. Prompt for an illustration to this post was generated with query
ferrofluids in form of a brain, beautiful connections chaos, swirling black network --ar 3:4 --iw 9 --q 2 --s 1250Midjourney Prompt Generator: https://huggingface.co/spaces/doevent/prompt-generator
List of Midjourney prompts: https://www.followchain.org/midjourney-prompts/
An advanced guide to writing prompts for Midjourney ( text-to-image): https://medium.com/mlearning-ai/an-advanced-guide-to-writing-prompts-for-midjourney-text-to-image-aa12a1e33b6
#visualization #gan #generation #generatinveart #aiart #artgentips
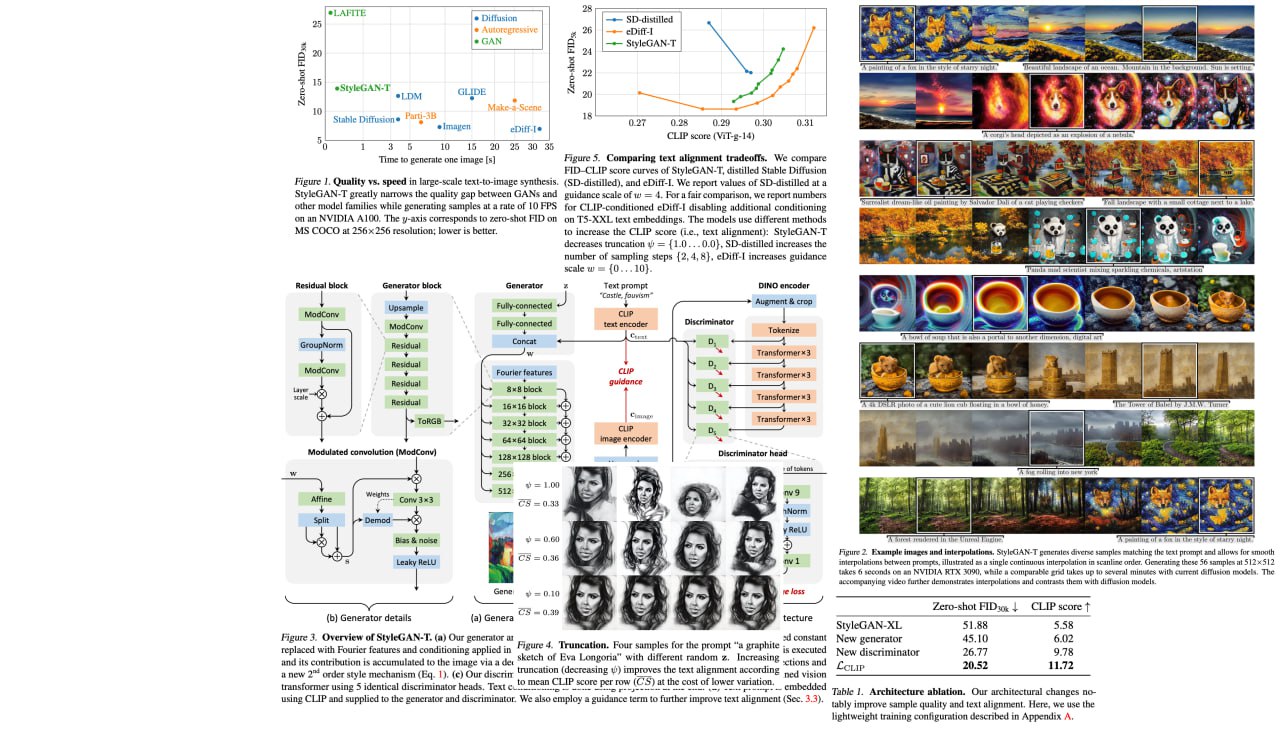
StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis
In this paper, the authors propose StyleGAN-T, a model designed for large-scale text-to-image synthesis. With its large capacity, stable training on diverse datasets, strong text alignment, and controllable variation-text alignment tradeoff, StyleGAN-T outperforms previous GANs and even surpasses distilled diffusion models, the previous frontrunners in fast text-to-image synthesis in terms of sample quality and speed.
StyleGAN-T achieves a better zero-shot MS COCO FID than current state of-the-art diffusion models at a resolution of 64×64. At 256×256, StyleGAN-T halves the zero-shot FID previously achieved by a GAN but continues to trail SOTA diffusion models.
Paper: https://arxiv.org/abs/2301.09515
Project link: https://sites.google.com/view/stylegan-t?pli=1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stylegan-t
#deeplearning #cv #gan #styletransfer
In this paper, the authors propose StyleGAN-T, a model designed for large-scale text-to-image synthesis. With its large capacity, stable training on diverse datasets, strong text alignment, and controllable variation-text alignment tradeoff, StyleGAN-T outperforms previous GANs and even surpasses distilled diffusion models, the previous frontrunners in fast text-to-image synthesis in terms of sample quality and speed.
StyleGAN-T achieves a better zero-shot MS COCO FID than current state of-the-art diffusion models at a resolution of 64×64. At 256×256, StyleGAN-T halves the zero-shot FID previously achieved by a GAN but continues to trail SOTA diffusion models.
Paper: https://arxiv.org/abs/2301.09515
Project link: https://sites.google.com/view/stylegan-t?pli=1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stylegan-t
#deeplearning #cv #gan #styletransfer
{kind=link}
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
Meet DragGAN, a groundbreaking approach that is set to revolutionize the way we control generative adversarial networks (GANs) and synthesize visual content! This innovative tool offers users unprecedented flexibility and precision when manipulating images, sidestepping the limitations of prior 3D models and annotated training data. With DragGAN, you can now "drag" any point of an image to a precise target position, introducing a nvel user-interactive element.
Two ingenious components underpin DragGAN's functionality: the first is a feature-based motion supervision that effortlessly guides the handle point towards the desired position, and the second is a novel point tracking approach that utilizes the discriminating features of the generator to maintain the handle points' positions. The real game-changer is that anyone can now deform an image with absolute control over pixel movements, enabling the manipulation of pose, shape, expression, and layout across diverse categories like animals, cars, humans, landscapes, and more. DragGAN outperforms its predecessors in both image manipulation and point tracking tasks, promising an exciting leap forward in AI-generated visual content!
Paper link: https://arxiv.org/abs/2305.10973
Code link: https://github.com/XingangPan/DragGAN
Project link: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-draggan
#deeplearning #cv #gan #imagemanipulation
Meet DragGAN, a groundbreaking approach that is set to revolutionize the way we control generative adversarial networks (GANs) and synthesize visual content! This innovative tool offers users unprecedented flexibility and precision when manipulating images, sidestepping the limitations of prior 3D models and annotated training data. With DragGAN, you can now "drag" any point of an image to a precise target position, introducing a nvel user-interactive element.
Two ingenious components underpin DragGAN's functionality: the first is a feature-based motion supervision that effortlessly guides the handle point towards the desired position, and the second is a novel point tracking approach that utilizes the discriminating features of the generator to maintain the handle points' positions. The real game-changer is that anyone can now deform an image with absolute control over pixel movements, enabling the manipulation of pose, shape, expression, and layout across diverse categories like animals, cars, humans, landscapes, and more. DragGAN outperforms its predecessors in both image manipulation and point tracking tasks, promising an exciting leap forward in AI-generated visual content!
Paper link: https://arxiv.org/abs/2305.10973
Code link: https://github.com/XingangPan/DragGAN
Project link: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-draggan
#deeplearning #cv #gan #imagemanipulation
{kind=link}