
Data Science interview questions list
List, compiled from medium article and peer-provided contributions.
Github (questions and answers): https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md
#interview #questions #meta
List, compiled from medium article and peer-provided contributions.
Github (questions and answers): https://github.com/alexeygrigorev/data-science-interviews/blob/master/theory.md
#interview #questions #meta
GitHub
data-science-interviews/theory.md at master · alexeygrigorev/data-science-interviews
Data science interview questions and answers. Contribute to alexeygrigorev/data-science-interviews development by creating an account on GitHub.
Forwarded from Spark in me (Alexander)
Russian Text Normalization for Speech Recognition
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
- De-Normalization (
We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
пять);- De-Normalization (
пять => 5);We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
TensorFlow Quantum
A Software Framework for Quantum Machine Learning
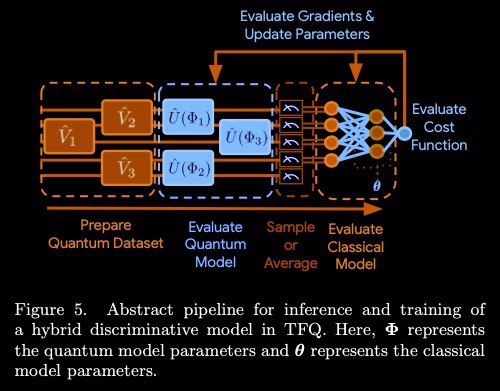
Introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data.
TFQ provides the tools necessary for bringing the quantum computing and ML research communities together to control and model natural or artificial quantum systems; e.g. Noisy Intermediate Scale Quantum (NISQ) processors with ~50-100 qubits.
A quantum model has the ability to represent and generalize data with a quantum mechanical origin. However, to understand quantum models, two concepts must be introduced – quantum data and hybrid quantum-classical models.
Quantum data exhibits superposition and entanglement, leading to joint probability distributions that could require an exponential amount of classical computational resources to represent or store. Quantum data, which can be generated/simulated on quantum processors/sensors/networks include the simulation of chemicals and quantum matter, quantum control, quantum communication networks, quantum metrology, and much more.
Quantum models cannot use quantum processors alone – NISQ processors will need to work in concert with classical processors to become effective. As TensorFlow already supports heterogeneous computing across CPUs, GPUs, and TPUs, it is a natural platform for experimenting with hybrid quantum-classical algorithms.
To build and train such a model, the researcher can do the following:
– prepare a quantum dataset
– evaluate a quantum NN model
- sample or Average
– evaluate a classical NN model
– evaluate сost function
– evaluate gradients & update parameters
blog post: https://ai.googleblog.com/2020/03/announcing-tensorflow-quantum-open.html
paper: https://arxiv.org/abs/2003.02989
#tfq #tensorflow #quantum #physics #ml
A Software Framework for Quantum Machine Learning
Introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data.
TFQ provides the tools necessary for bringing the quantum computing and ML research communities together to control and model natural or artificial quantum systems; e.g. Noisy Intermediate Scale Quantum (NISQ) processors with ~50-100 qubits.
A quantum model has the ability to represent and generalize data with a quantum mechanical origin. However, to understand quantum models, two concepts must be introduced – quantum data and hybrid quantum-classical models.
Quantum data exhibits superposition and entanglement, leading to joint probability distributions that could require an exponential amount of classical computational resources to represent or store. Quantum data, which can be generated/simulated on quantum processors/sensors/networks include the simulation of chemicals and quantum matter, quantum control, quantum communication networks, quantum metrology, and much more.
Quantum models cannot use quantum processors alone – NISQ processors will need to work in concert with classical processors to become effective. As TensorFlow already supports heterogeneous computing across CPUs, GPUs, and TPUs, it is a natural platform for experimenting with hybrid quantum-classical algorithms.
To build and train such a model, the researcher can do the following:
– prepare a quantum dataset
– evaluate a quantum NN model
- sample or Average
– evaluate a classical NN model
– evaluate сost function
– evaluate gradients & update parameters
blog post: https://ai.googleblog.com/2020/03/announcing-tensorflow-quantum-open.html
paper: https://arxiv.org/abs/2003.02989
#tfq #tensorflow #quantum #physics #ml
{kind=link}
Survey of machine-learning experimental methods at NeurIPS2019 and ICLR2020
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Twitter
Delip Rao
Survey of #MachineLearning experimental methods (aka "how do ML folks do their experiments") at #NeurIPS2019 and #ICLR2020, a thread of results:
{kind=link}
Can evolution be the Master Algorithm?
Fun AutoML-Zero experiments: Evolutionary search discovers fundamental ML algorithms from scratch, e.g., small neural nets with backprop.
Genetic programming learned operations reminiscent of dropout, normalized gradients, and weight averaging when trying to evolve better learning algorithms.
Paper: https://arxiv.org/abs/2003.03384
Code: https://git.io/JvKrZ
#automl #genetic
Fun AutoML-Zero experiments: Evolutionary search discovers fundamental ML algorithms from scratch, e.g., small neural nets with backprop.
Genetic programming learned operations reminiscent of dropout, normalized gradients, and weight averaging when trying to evolve better learning algorithms.
Paper: https://arxiv.org/abs/2003.03384
Code: https://git.io/JvKrZ
#automl #genetic
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 6 to 12 coronafearless people.
Forwarded from Karim Iskakov - канал (Vladimir Ivashkin)
New paper by Yandex.MILAB 🎉
Tired of waiting for backprop to project your face into StyleGAN latent space to use some funny vector on it? Just distilate this tranformation by pix2pixHD!
📝 arxiv.org/abs/2003.03581
👤 @iviazovetskyi, @vlivashkin, @digitman
📉 @loss_function_porn
Tired of waiting for backprop to project your face into StyleGAN latent space to use some funny vector on it? Just distilate this tranformation by pix2pixHD!
📝 arxiv.org/abs/2003.03581
👤 @iviazovetskyi, @vlivashkin, @digitman
📉 @loss_function_porn
We ignored lots of news on 👑🦠
What do you think?
What do you think?
Anonymous Poll
19%
IT’S NEVER ENOUGH
48%
We need only good stuff
34%
Please ignore it completely
Transferring Dense Pose to Proximal Animal Classes
Article on how to train DensePose for animals withiout labels
DensePose approach predicts the pose of humans densely and accurately given a large dataset of poses annotated in detail. It's super expensive to collect DensePose annotations for all different classes of animals. So authors show that, at least for proximal animal classes such as chimpanzees, it is possible to transfer the knowledge existing in DensePose for humans. They propose to utilize the existing annotations of humans and do self-training on unlabeled images of animals.
Link: https://asanakoy.github.io/densepose-evolution/
YouTube: https://youtu.be/OU3Ayg_l4QM
Paper: https://arxiv.org/pdf/2003.00080.pdf
#Facebook #FAIR #CVPR #CVPR2020 #posetransfer #dl
Article on how to train DensePose for animals withiout labels
DensePose approach predicts the pose of humans densely and accurately given a large dataset of poses annotated in detail. It's super expensive to collect DensePose annotations for all different classes of animals. So authors show that, at least for proximal animal classes such as chimpanzees, it is possible to transfer the knowledge existing in DensePose for humans. They propose to utilize the existing annotations of humans and do self-training on unlabeled images of animals.
Link: https://asanakoy.github.io/densepose-evolution/
YouTube: https://youtu.be/OU3Ayg_l4QM
Paper: https://arxiv.org/pdf/2003.00080.pdf
#Facebook #FAIR #CVPR #CVPR2020 #posetransfer #dl
YouTube
DensePose applied on chimps: comparison of our method before self-training (left) and after (right)
Frame-by-frame predictions produced by our model before (teacher) and after self-training (student).
After self training the 24-class body part segmentation is more accurate and stable.
Project page: https://asanakoy.github.io/densepose-evolution/
After self training the 24-class body part segmentation is more accurate and stable.
Project page: https://asanakoy.github.io/densepose-evolution/
👑🦠 We are building ultimate post on coronavirus, with the purpose on gathering all reliable and informative (not entertaining or just making you worry more) content there is to-date.
We just want to make a sane post on coronavirus, which will (to the best extent of our efforts) be bias and fake/unreliable news free, and comply with following rules:
1 Provided information should be correct, better if it is verifiable.
2 Source should be provided, if applicable. Only trustworthy sources are allowed (WHO, UN, academic institutions).
3 Biases and distributions should be taken into account: raw information is not that representative and can misguide opinions.
4 If appliable, information should be actionable — readers should get a clear picture of what they can do after reading it, not just get upset or worried.
You can submit information for considertion before the release of the post with our @opendatasciencebot, if you believe that it will be helpful to our dear audience and will serve your fellows well.
The post will be shared in a form of github repo, so contributions are welcome in advance 👹
We just want to make a sane post on coronavirus, which will (to the best extent of our efforts) be bias and fake/unreliable news free, and comply with following rules:
1 Provided information should be correct, better if it is verifiable.
2 Source should be provided, if applicable. Only trustworthy sources are allowed (WHO, UN, academic institutions).
3 Biases and distributions should be taken into account: raw information is not that representative and can misguide opinions.
4 If appliable, information should be actionable — readers should get a clear picture of what they can do after reading it, not just get upset or worried.
You can submit information for considertion before the release of the post with our @opendatasciencebot, if you believe that it will be helpful to our dear audience and will serve your fellows well.
The post will be shared in a form of github repo, so contributions are welcome in advance 👹
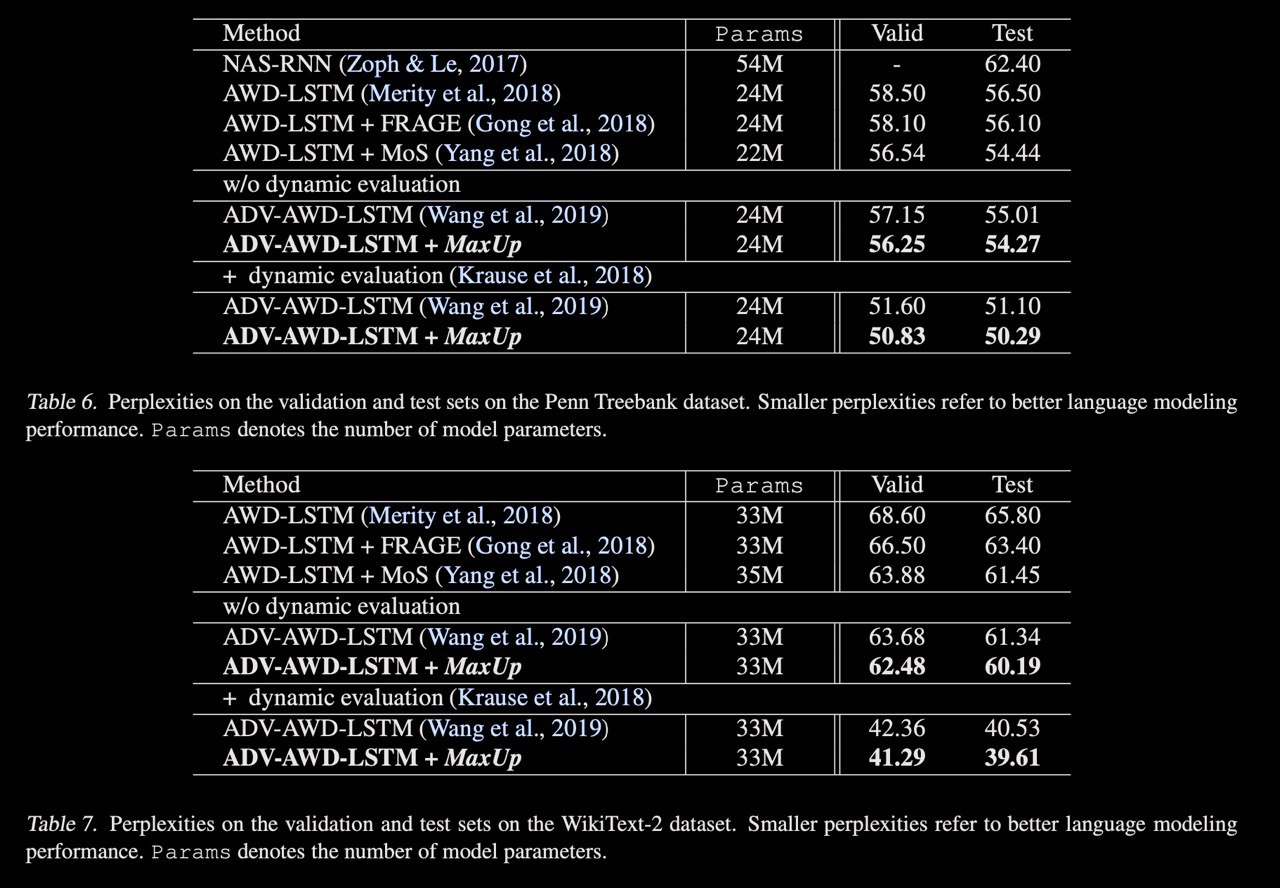
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
m times and then found aug with maximum loss and does backprop only through that. i.e. minimizing max loss.There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
augs without the overhead. Only m times to forward pass on the sample but one time to backprop. paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
{kind=link}
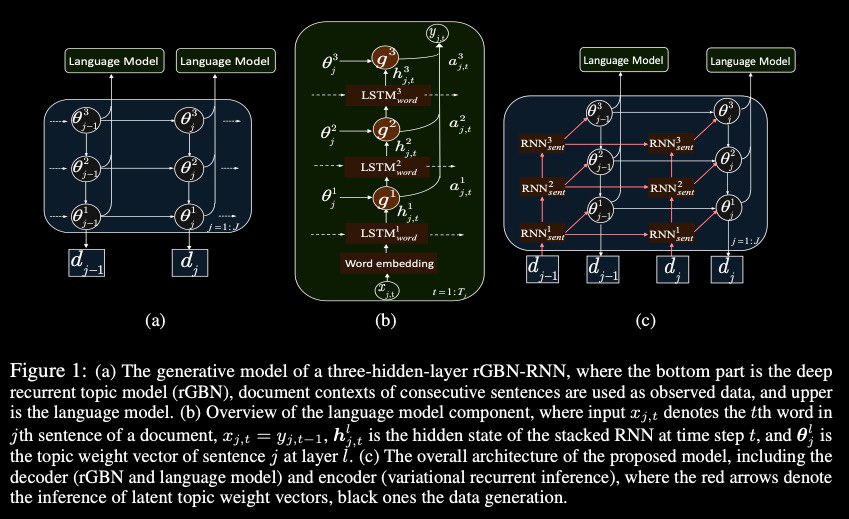
Recurrent Hierarchical Topic-Guided Neural Language Models
The authors propose a recurrent gamma belief network (rGBN) guided neural language modeling framework, a novel method to learn a language model and a deep recurrent topic model simultaneously.
For scalable inference, they develop hybrid SG-MCMC and recurrent autoencoding variational inference, allowing efficient end-to-end training.
Experiments results conducted on real-world corpora demonstrate that the proposed models outperform a variety of shallow-topic-model-guided neural language models, and effectively generate the sentences from the designated multi-level topics or noise while inferring the interpretable hierarchical latent topic structure of the document and hierarchical multiscale structures of sequences.
paper: https://openreview.net/forum?id=Byl1W1rtvH
#ICLR2020 #nlm #nlg
The authors propose a recurrent gamma belief network (rGBN) guided neural language modeling framework, a novel method to learn a language model and a deep recurrent topic model simultaneously.
For scalable inference, they develop hybrid SG-MCMC and recurrent autoencoding variational inference, allowing efficient end-to-end training.
Experiments results conducted on real-world corpora demonstrate that the proposed models outperform a variety of shallow-topic-model-guided neural language models, and effectively generate the sentences from the designated multi-level topics or noise while inferring the interpretable hierarchical latent topic structure of the document and hierarchical multiscale structures of sequences.
paper: https://openreview.net/forum?id=Byl1W1rtvH
#ICLR2020 #nlm #nlg
{kind=link}
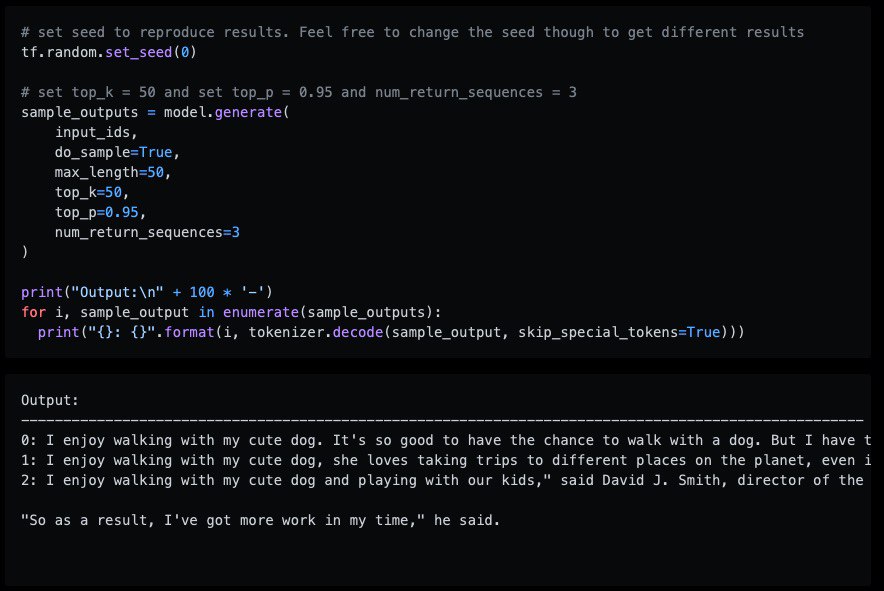
How to generate text: using different decoding methods for language generation with Transformers
by huggingface
in this blog, the author talk about how to generate text and compared some approaches like:
– greedy search
– beam search
– top-K sampling
– top-p (nucleus) sampling
blog post: https://huggingface.co/blog/how-to-generate
#nlp #nlg #transformers
by huggingface
in this blog, the author talk about how to generate text and compared some approaches like:
– greedy search
– beam search
– top-K sampling
– top-p (nucleus) sampling
blog post: https://huggingface.co/blog/how-to-generate
#nlp #nlg #transformers
{kind=link}
Forwarded from Karim Iskakov - канал (Karim Iskakov)
This media is not supported in your browser
VIEW IN TELEGRAM
Representing Scenes as Neural Radiance Fields for View Synthesis. You first feed a set of images to the model and then it can generate photorealistic novel views of the scene conditioning on your viewing direction. Amazing results!
🔎 matthewtancik.com/nerf
📝 arxiv.org/abs/2003.08934
📉 @loss_function_porn
🔎 matthewtancik.com/nerf
📝 arxiv.org/abs/2003.08934
📉 @loss_function_porn
👑🦠
As we promised, we compiled all intersting and relevant infomation in one post, not to lose focus on DS in our channel. And we made special emphasis on what you can do as engineers and active community members:
1 Follow WHO's advice (in the article below, also — in any self-respecting source of information you read) to lower your chances of getting infecting.
2 Stay inside, switch to remote work if possible.
3 Spread the word about the pandemia, share trustworthy information.
4 Take part in projects: review information, build models, research.
Needless to say, we are open to PRs and corrections. You are most welcome.
Link: https://github.com/open-data-science/ultimate_posts/blob/master/COVID_2019/README.md
P.S. We saw this on TikTok and Twitter: let’s try to keep emojis balanced.
#coronafeerless #covid2019 #ultimatepost
As we promised, we compiled all intersting and relevant infomation in one post, not to lose focus on DS in our channel. And we made special emphasis on what you can do as engineers and active community members:
1 Follow WHO's advice (in the article below, also — in any self-respecting source of information you read) to lower your chances of getting infecting.
2 Stay inside, switch to remote work if possible.
3 Spread the word about the pandemia, share trustworthy information.
4 Take part in projects: review information, build models, research.
Needless to say, we are open to PRs and corrections. You are most welcome.
Link: https://github.com/open-data-science/ultimate_posts/blob/master/COVID_2019/README.md
P.S. We saw this on TikTok and Twitter: let’s try to keep emojis balanced.
#coronafeerless #covid2019 #ultimatepost
GitHub
ultimate_posts/COVID_2019/README.md at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
NLP Newsletter #8 by Elvis Saravia
– Research and Publications
* Surveys on Contextual Embeddings and Language Models
* Visualizing Neural Networks with the Grand Tour
* Meta-Learning Initializations for Low-Resource Drug Discovery
* NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* Introducing Dreamer: Scalable Reinforcement Learning Using World Models
– Creativity, Ethics, and Society
* COVID-19 Open Research Dataset (CORD-19)
* SECNLP: A survey of embeddings in clinical natural language processing
* AI for 3D Generative Design
– Tools and Datasets
* Stanza (formerly StanfordNLP) – A Python NLP Library for Many Human Languages
* GridWorld Playground
* X-Stance: A Multilingual Multi-Target Dataset for Stance Detection
* Create interactive textual heatmaps for Jupyter notebooks
– Articles and Blog posts
* How to generate text: using different decoding methods for language generation with Transformers
* Training RoBERTa from Scratch – The Missing Guide
– Education
* Getting started with JAX (MLPs, CNNs & RNNs)
* NLP for Developers: Word Embeddings
* Thomas Wolf: An Introduction to Transfer Learning and HuggingFace
…
blog post: https://dair.ai/NLP_Newsletter_8/
#nlp #newsletter
– Research and Publications
* Surveys on Contextual Embeddings and Language Models
* Visualizing Neural Networks with the Grand Tour
* Meta-Learning Initializations for Low-Resource Drug Discovery
* NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* Introducing Dreamer: Scalable Reinforcement Learning Using World Models
– Creativity, Ethics, and Society
* COVID-19 Open Research Dataset (CORD-19)
* SECNLP: A survey of embeddings in clinical natural language processing
* AI for 3D Generative Design
– Tools and Datasets
* Stanza (formerly StanfordNLP) – A Python NLP Library for Many Human Languages
* GridWorld Playground
* X-Stance: A Multilingual Multi-Target Dataset for Stance Detection
* Create interactive textual heatmaps for Jupyter notebooks
– Articles and Blog posts
* How to generate text: using different decoding methods for language generation with Transformers
* Training RoBERTa from Scratch – The Missing Guide
– Education
* Getting started with JAX (MLPs, CNNs & RNNs)
* NLP for Developers: Word Embeddings
* Thomas Wolf: An Introduction to Transfer Learning and HuggingFace
…
blog post: https://dair.ai/NLP_Newsletter_8/
#nlp #newsletter
{kind=link}
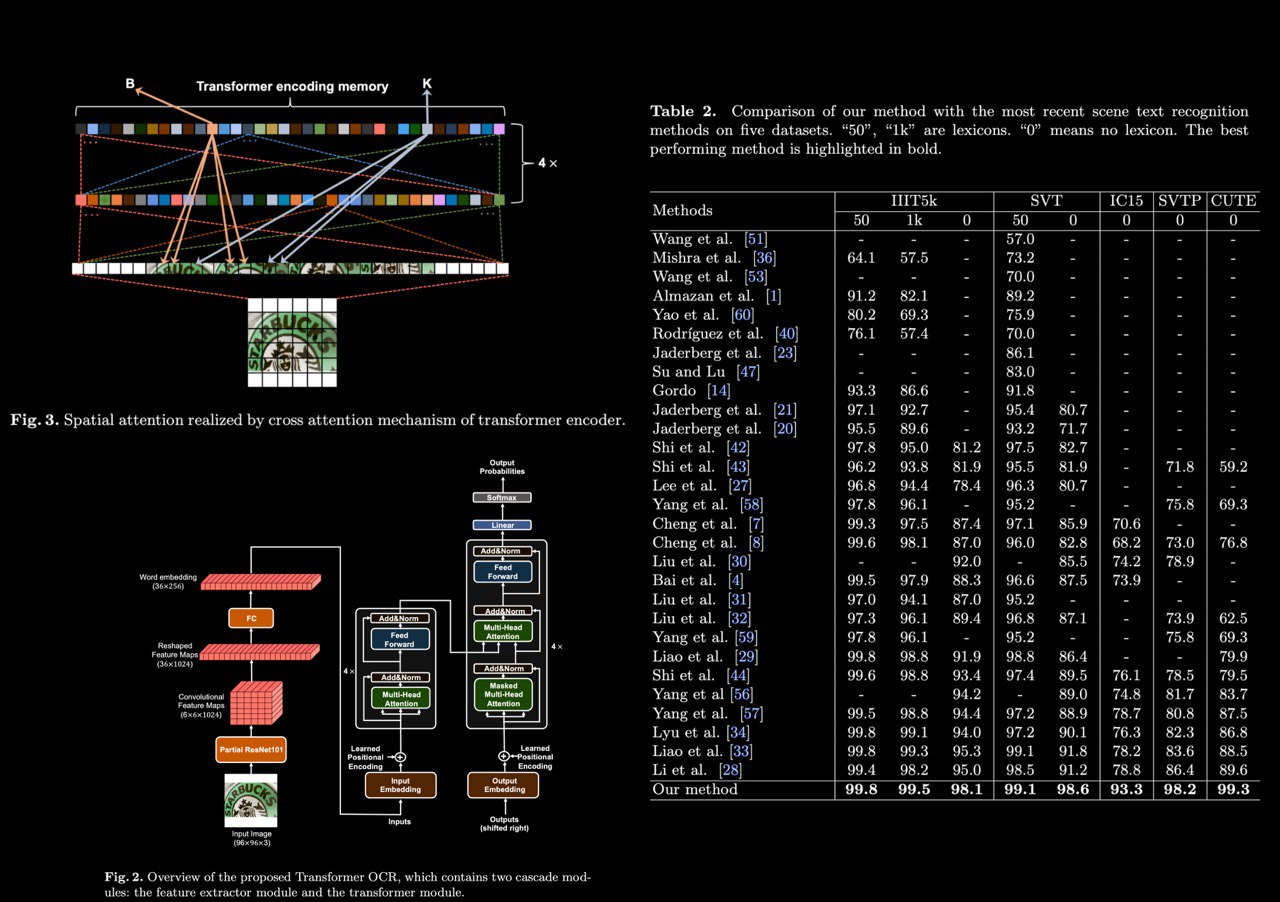
Scene Text Recognition via Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
{kind=link}
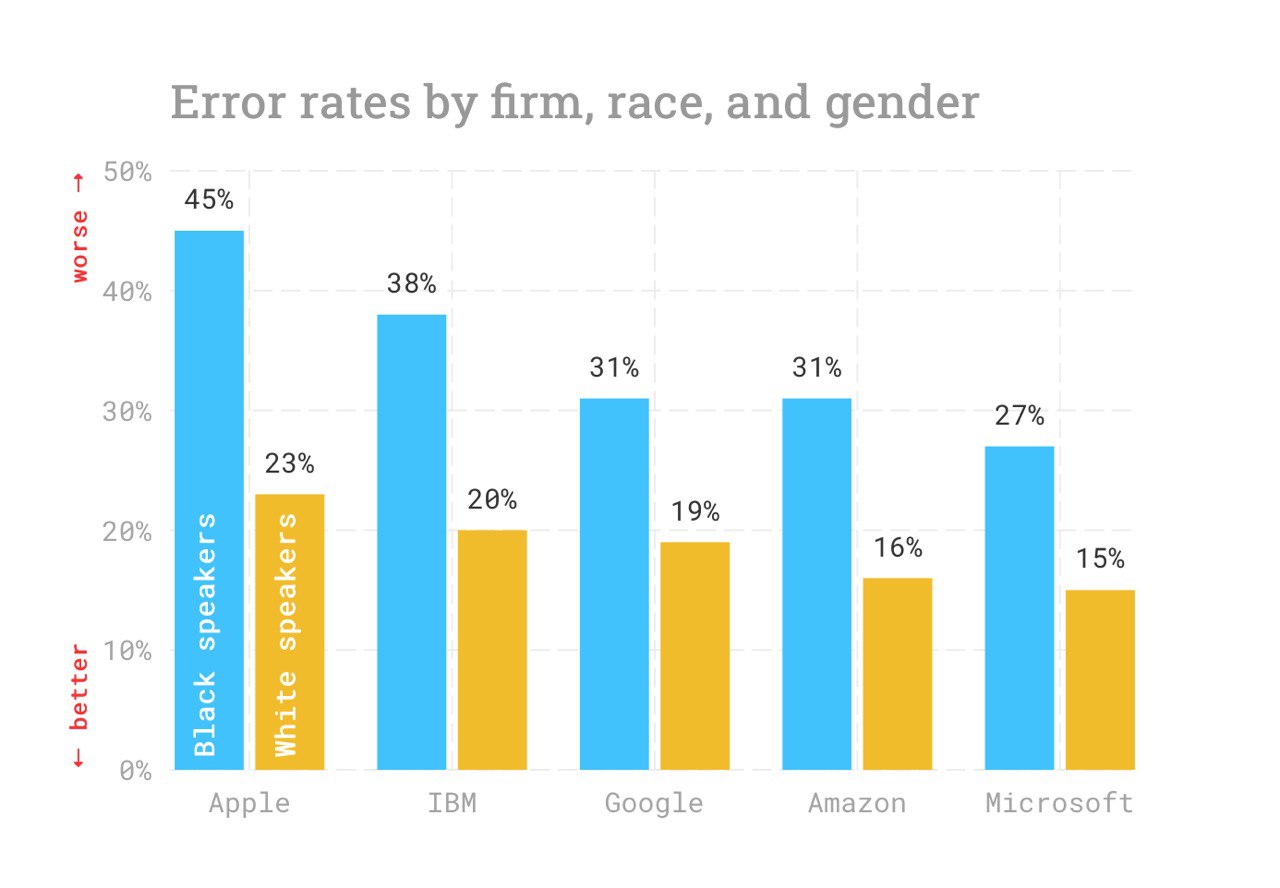
Racial Disparities in Automated Speech Recognition
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
{kind=link}
High-Resolution Daytime Translation Without Domain Labels
The authors propose a novel image-to-image translation model which is capable of learning on fully unsupervised data (without any domain labels, which is a major improvement over current state-of-the-art methods, namely FUNIT by NVIDIA) and an upscaling technique for generating high-resolution images while keeping scene semantics
For the generator, authors utilize resnet-like generator with skip connections and adaptive instance normalization. The key to success was the usage of two ideas:
1. Combined usage of styles, extracted from the real images, with the ones sampled from the prior distribution
2. Usage of a conditional discriminator, that takes both generated image and the style vector as an input
The enhancement network is inspired by ESRGAN and takes multiple transfer results, obtained via applying the generator to shifted and downsampled Hi-Res image.
Authors showcase their model on modeling various daytime appearances for a single given image as the main task. The model has been trained on a custom dataset of still landscape images with a varying time of day (which was unknown during training). Authors also show the versatility of the approach for artistic style transfer task, training the model on the WikiArt dataset and applying it to real photographs
Project link: https://saic-mdal.github.io/HiDT/
#gan #image2image #highresolution #cv
The authors propose a novel image-to-image translation model which is capable of learning on fully unsupervised data (without any domain labels, which is a major improvement over current state-of-the-art methods, namely FUNIT by NVIDIA) and an upscaling technique for generating high-resolution images while keeping scene semantics
For the generator, authors utilize resnet-like generator with skip connections and adaptive instance normalization. The key to success was the usage of two ideas:
1. Combined usage of styles, extracted from the real images, with the ones sampled from the prior distribution
2. Usage of a conditional discriminator, that takes both generated image and the style vector as an input
The enhancement network is inspired by ESRGAN and takes multiple transfer results, obtained via applying the generator to shifted and downsampled Hi-Res image.
Authors showcase their model on modeling various daytime appearances for a single given image as the main task. The model has been trained on a custom dataset of still landscape images with a varying time of day (which was unknown during training). Authors also show the versatility of the approach for artistic style transfer task, training the model on the WikiArt dataset and applying it to real photographs
Project link: https://saic-mdal.github.io/HiDT/
#gan #image2image #highresolution #cv
{kind=link}