
Scene Text Recognition via Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
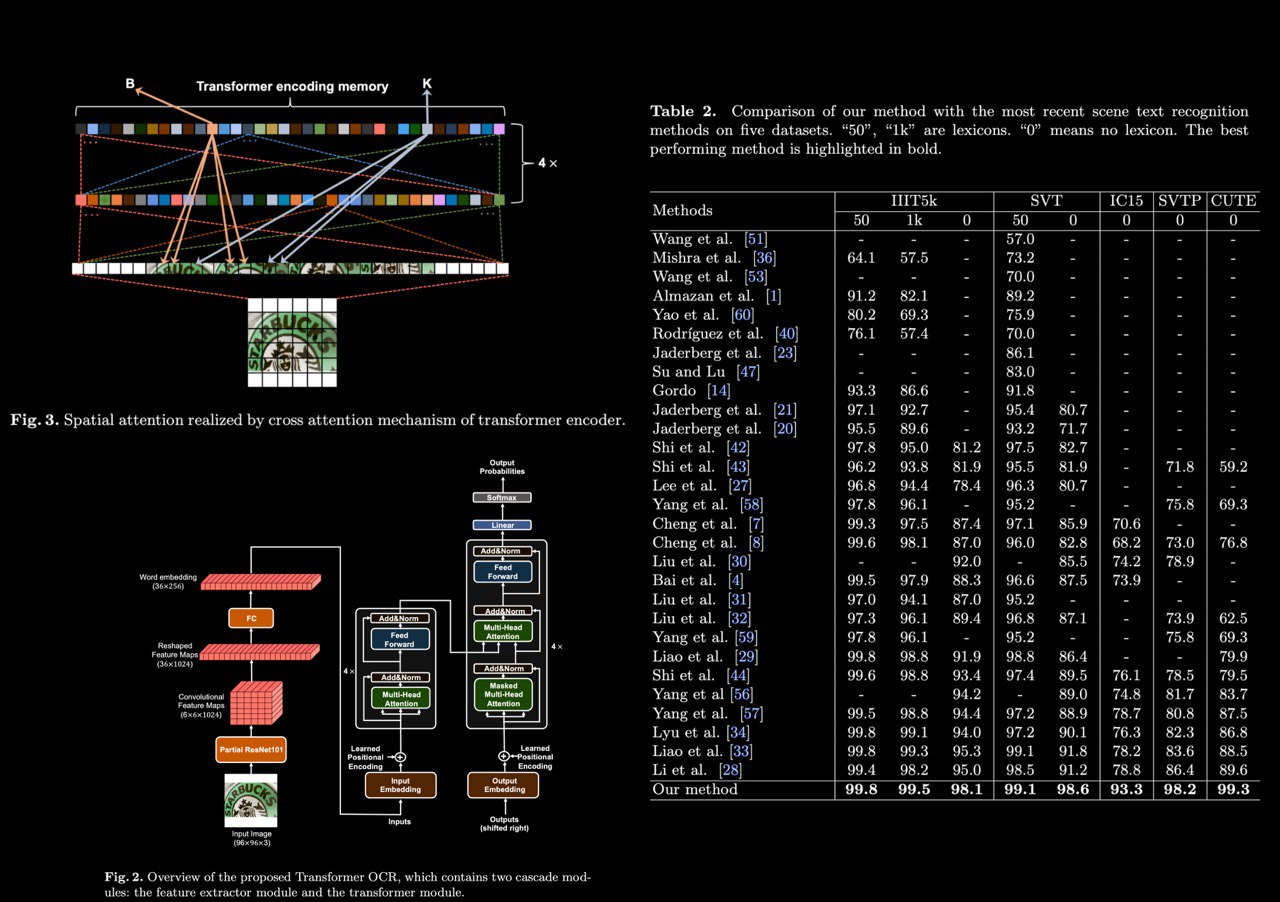
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
{kind=link}
Forwarded from Silero News (Alexander)
Silero TTS Released
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
Surprise! A quick pre-release of Silero Text-to-Speech models!
Speakers
10 voices (each available in 16 kHz and 8 kHz):
- 6 Russian voices;
- 1 English voice;
- 1 German voice, 1 Spanish voice, 1 French voice;
Why is this Different?
- One-line usage;
- A large library of voices;
- A fully end-to-end pipeline;
- Naturally sounding speech;
- No GPU or training required;
- Minimalism and lack of dependencies;
- Faster than real-time on one CPU thread (!!!);
- Support for
16kHz and 8kHz out of the box;Links
- Try our TTS models here;
- Quick summary;
- Performance benchmarks;
Stay tuned for much more detailed PR releases and
torch.hub release soon!GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Forwarded from Silero News (Alexander)
New TTS Models for Minority Languages of the CIS / Russia
In collaboration with the community, we created totally unique models for the languages of the peoples of Russia / the CIS:
- Bashkir (aigul_v2)
- Kalmyk (erdni_v2)
- Tatar (dilyara_v2)
- Uzbek (dilnavoz_v2)
We also tried to create the Ukrainian voice, but the data we had (sourced from audiobooks) was not very good (all other voices were created from recordings).
Some models sound almost perfect, some a bit worse. Typically this boils down to how speakers can provide steady consistent recordings.
We used anywhere from 1 hour to 6 hours of recordings to create each voice.
These models obviously do not include automated stress and have the same major caveats as other v2 models (i.e. best used with batch size 1 on 2-4 CPU threads).
Link
- https://github.com/snakers4/silero-models#text-to-speech
In collaboration with the community, we created totally unique models for the languages of the peoples of Russia / the CIS:
- Bashkir (aigul_v2)
- Kalmyk (erdni_v2)
- Tatar (dilyara_v2)
- Uzbek (dilnavoz_v2)
We also tried to create the Ukrainian voice, but the data we had (sourced from audiobooks) was not very good (all other voices were created from recordings).
Some models sound almost perfect, some a bit worse. Typically this boils down to how speakers can provide steady consistent recordings.
We used anywhere from 1 hour to 6 hours of recordings to create each voice.
These models obviously do not include automated stress and have the same major caveats as other v2 models (i.e. best used with batch size 1 on 2-4 CPU threads).
Link
- https://github.com/snakers4/silero-models#text-to-speech
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Forwarded from Silero News (Alexander)
We Have Published a Model For Text Repunctuation and Recapitalization
The model works with SINGLE sentences (albeit long ones) and:
- Inserts capital letters and basic punctuation marks (dot, comma, hyphen, question mark, exclamation mark, dash for Russian);
- Works for 4 languages (Russian, English, German, Spanish) and can be extended;
- By design is domain agnostic and is not based on any hard-coded rules;
- Has non-trivial metrics and succeeds in the task of improving text readability;
Links:
- Model repo - https://github.com/snakers4/silero-models#text-enhancement
- Colab notebook - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_te.ipynb
- Russian article - https://habr.com/ru/post/581946/
- English article - https://habr.com/ru/post/581960/
The model works with SINGLE sentences (albeit long ones) and:
- Inserts capital letters and basic punctuation marks (dot, comma, hyphen, question mark, exclamation mark, dash for Russian);
- Works for 4 languages (Russian, English, German, Spanish) and can be extended;
- By design is domain agnostic and is not based on any hard-coded rules;
- Has non-trivial metrics and succeeds in the task of improving text readability;
Links:
- Model repo - https://github.com/snakers4/silero-models#text-enhancement
- Colab notebook - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_te.ipynb
- Russian article - https://habr.com/ru/post/581946/
- English article - https://habr.com/ru/post/581960/
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models
Forwarded from Silero News (Alexander)
Silero TTS V3 Finally Released
We have just released a brand new Russian speech synthesis model.
We have made a number of promises we kept:
- Model size reduced 2x;
- New models are 10x faster (!);
- We added flags to control stress;
- Now the models can make proper pauses;
- High quality voice added (and unlimited "random" voices);
- All speakers squeezed into the same model;
- Input length limitations lifted, now models can work with paragraphs of text;
- Pauses, speed and pitch can be controlled via SSML;
- Sampling rates of 8, 24 or 48 kHz are supported;
- Models are much more stable — they do not omit words anymore;
Next steps:
- Release models for the CIS languages, English, some European languages and Hindic languages
- Even further 2-4x speed up
- Updated stress model
- Phonemes support and and built-in voice transfer
Links:
- GitHub - https://github.com/snakers4/silero-models#text-to-speech
- Colab - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_tts.ipynb
- Russian article - https://habr.com/ru/post/660565/
- English article - https://habr.com/ru/post/660571/
We have just released a brand new Russian speech synthesis model.
We have made a number of promises we kept:
- Model size reduced 2x;
- New models are 10x faster (!);
- We added flags to control stress;
- Now the models can make proper pauses;
- High quality voice added (and unlimited "random" voices);
- All speakers squeezed into the same model;
- Input length limitations lifted, now models can work with paragraphs of text;
- Pauses, speed and pitch can be controlled via SSML;
- Sampling rates of 8, 24 or 48 kHz are supported;
- Models are much more stable — they do not omit words anymore;
Next steps:
- Release models for the CIS languages, English, some European languages and Hindic languages
- Even further 2-4x speed up
- Updated stress model
- Phonemes support and and built-in voice transfer
Links:
- GitHub - https://github.com/snakers4/silero-models#text-to-speech
- Colab - https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_tts.ipynb
- Russian article - https://habr.com/ru/post/660565/
- English article - https://habr.com/ru/post/660571/
GitHub
GitHub - snakers4/silero-models: Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly…
Silero Models: pre-trained speech-to-text, text-to-speech and text-enhancement models made embarrassingly simple - snakers4/silero-models