
🔥Human-like chatbots from Google: Towards a Human-like Open-Domain Chatbot.
TLDR: humanity is one huge step closer to a chat-bot, which can chat about anything and has great chance of success, passing #TuringTest
What does it mean: As an example, soon you will have to be extra-cautious chatting in #dating apps, because there will be more chat-bots, who can seem humane.
This also means that there will some positive and productive applications too: more sophisticated selling operators, on-demand psychological support, you name it.
It might be surprising, but #seq2seq still works. Over 5+ years of working on neural conversational models, general progress is a fine-tune of basic approach. It is a proof that much can be still discovered, along with room for new completely different approaches.
«Perplexity is all a chatbot needs ;)» (с) Quoc Le
Blog post: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
Paper: https://arxiv.org/abs/2001.09977
Demo conversations: https://github.com/google-research/google-research/tree/master/meena
#NLP #NLU #ChatBots #google #googleai
TLDR: humanity is one huge step closer to a chat-bot, which can chat about anything and has great chance of success, passing #TuringTest
What does it mean: As an example, soon you will have to be extra-cautious chatting in #dating apps, because there will be more chat-bots, who can seem humane.
This also means that there will some positive and productive applications too: more sophisticated selling operators, on-demand psychological support, you name it.
It might be surprising, but #seq2seq still works. Over 5+ years of working on neural conversational models, general progress is a fine-tune of basic approach. It is a proof that much can be still discovered, along with room for new completely different approaches.
«Perplexity is all a chatbot needs ;)» (с) Quoc Le
Blog post: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
Paper: https://arxiv.org/abs/2001.09977
Demo conversations: https://github.com/google-research/google-research/tree/master/meena
#NLP #NLU #ChatBots #google #googleai
research.google
Towards a Conversational Agent that Can Chat About…Anything
Posted by Daniel Adiwardana, Senior Research Engineer, and Thang Luong, Senior Research Scientist, Google Research, Brain Team Modern conversatio...
🔥AI Meme Generator: This Meme Does Not Exist
Imgflip created an “AI meme generator”. Meme captions are generated by neural network.
Link: https://imgflip.com/ai-meme
#NLP #NLU #meme #generation #imgflip
Imgflip created an “AI meme generator”. Meme captions are generated by neural network.
Link: https://imgflip.com/ai-meme
#NLP #NLU #meme #generation #imgflip
{kind=link}
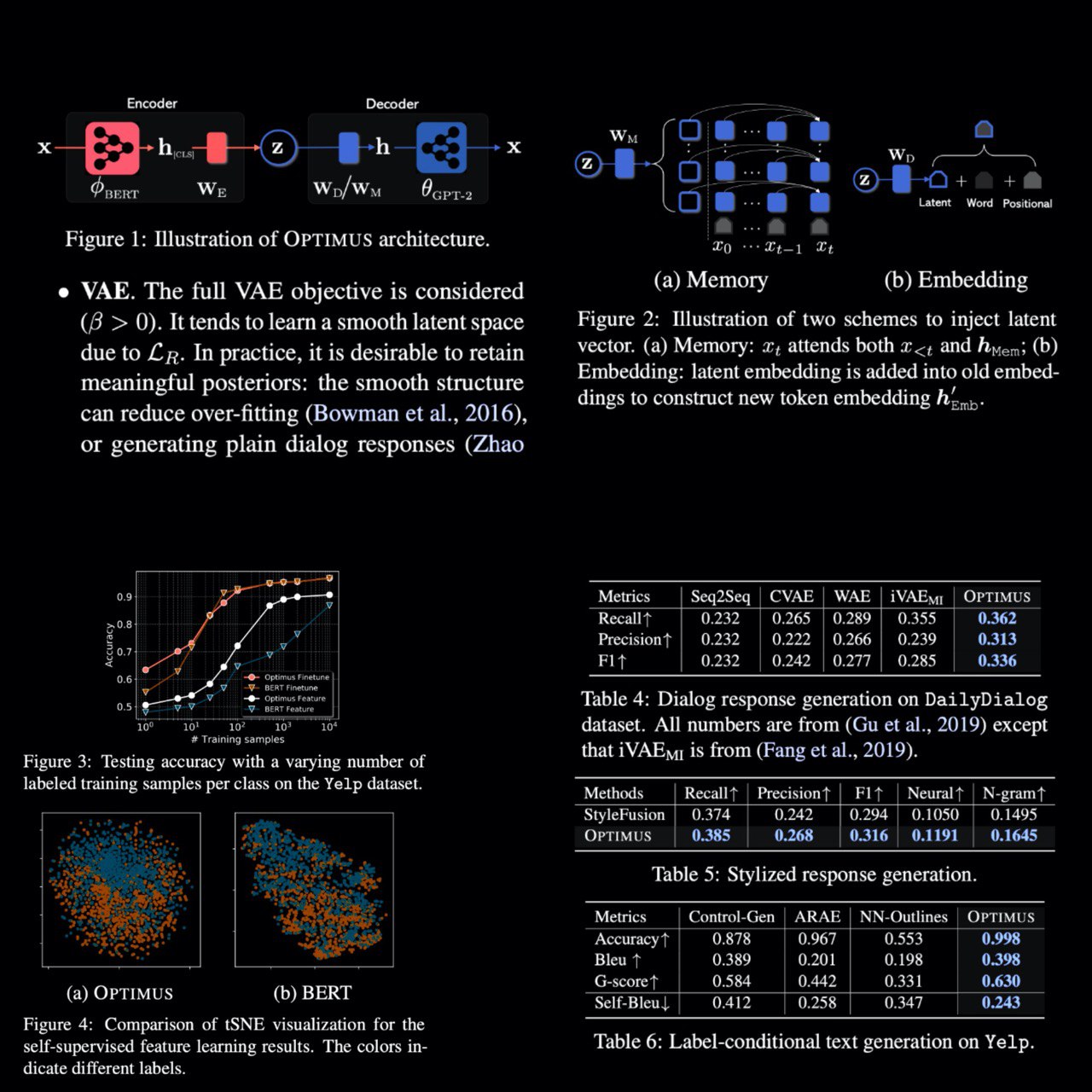
Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
{kind=link}
(Re)Discovering Protein Structure and Function Through Language Modeling
Trained solely on unsupervised language modeling, the Transformer's attention mechanism recovers high-level structural (folding) and functional properties of proteins!
Why this is important: traditional protein modelling requires lots of computational power. This might be a key to more efficient structure modelling. Protein structure => function. Function => faster drug research and understanding of diseases mechanisms.
Blog: https://blog.einstein.ai/provis/
Paper: https://arxiv.org/abs/2006.15222
Code: https://github.com/salesforce/provis
#DL #NLU #proteinmodelling #bio #biolearning #insilico
Trained solely on unsupervised language modeling, the Transformer's attention mechanism recovers high-level structural (folding) and functional properties of proteins!
Why this is important: traditional protein modelling requires lots of computational power. This might be a key to more efficient structure modelling. Protein structure => function. Function => faster drug research and understanding of diseases mechanisms.
Blog: https://blog.einstein.ai/provis/
Paper: https://arxiv.org/abs/2006.15222
Code: https://github.com/salesforce/provis
#DL #NLU #proteinmodelling #bio #biolearning #insilico
GPT-3 application for website form generation
Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate.
Author reports that there are exceptions, given current output limit of the model of 512 tokens.
Why this is important: one might suppose that in the future programmers will just write specifications and tests for the AI to generate the code. Given the speed of progress that won’t be surprising at all.
And probably the more sophisticated models will be capable of using hard output limit to produce a code for the output generation but that obviously is still an area for active research.
More realistic evaluation is that the upcoming code generation tools is that it will just allow more people to build products, following #nocode movement.
Twitter thread: https://twitter.com/sharifshameem/status/1282676454690451457
#codegeneration #NLU
Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate.
Author reports that there are exceptions, given current output limit of the model of 512 tokens.
Why this is important: one might suppose that in the future programmers will just write specifications and tests for the AI to generate the code. Given the speed of progress that won’t be surprising at all.
And probably the more sophisticated models will be capable of using hard output limit to produce a code for the output generation but that obviously is still an area for active research.
More realistic evaluation is that the upcoming code generation tools is that it will just allow more people to build products, following #nocode movement.
Twitter thread: https://twitter.com/sharifshameem/status/1282676454690451457
#codegeneration #NLU
This media is not supported in your browser
VIEW IN TELEGRAM
Applying GPT-3 to generate neural network code
Matt Shumer used GPT-3 to generate code for a machine learning model, just by describing the dataset and required output.
#GPT3 #inception #codegeneration #NLU #NLP
Matt Shumer used GPT-3 to generate code for a machine learning model, just by describing the dataset and required output.
#GPT3 #inception #codegeneration #NLU #NLP
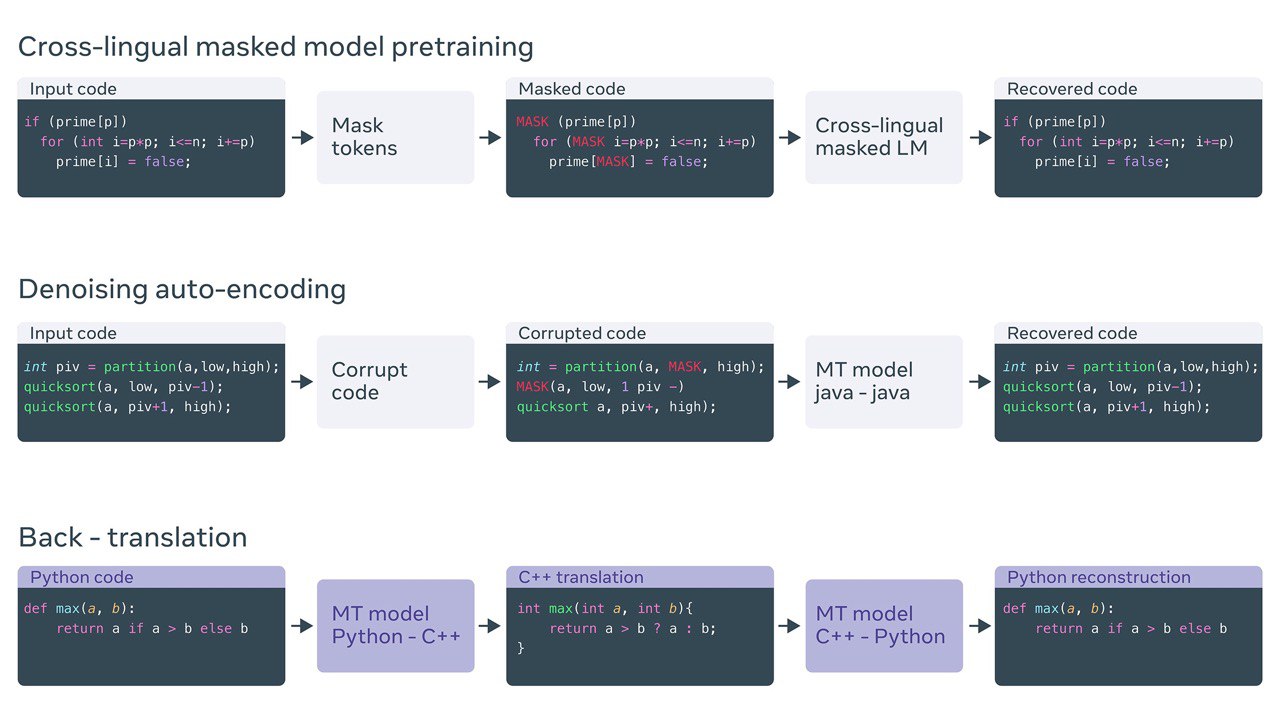
Deep learning to translate between programming languages
#FacebookAI released TransCoder, an entirely self-supervised neural transcompiler system that is claimed to make code migration easier and more efficient.
ArXiV: https://arxiv.org/pdf/2006.03511.pdf
Github: https://github.com/facebookresearch/TransCoder/
#NLU #codegeneration #NLP
#FacebookAI released TransCoder, an entirely self-supervised neural transcompiler system that is claimed to make code migration easier and more efficient.
ArXiV: https://arxiv.org/pdf/2006.03511.pdf
Github: https://github.com/facebookresearch/TransCoder/
#NLU #codegeneration #NLP
{kind=link}
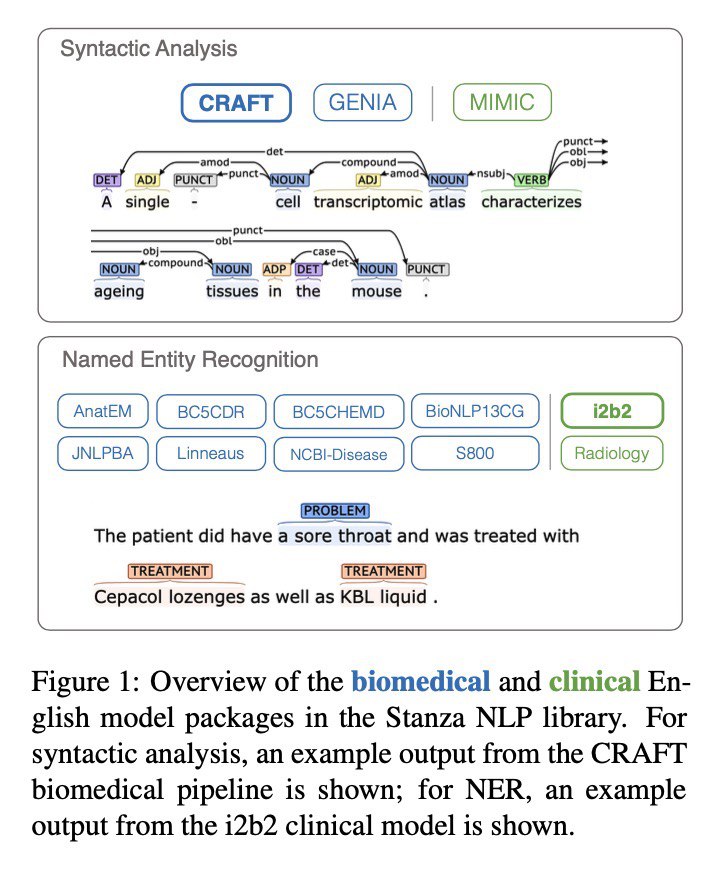
Stanford updated tool Stanza with #NER for biomedical and clinical terms
Stanza extended with first domain-specific models for biomedical and clinical medical English. They range from approaching to significantly improving state of the art results on syntactic and NER tasks.
That means that now neural networks are capable of understanding difficult texts with lots of specific terms. That means better search, improved knowledge extraction and approach for performing META analysis, or even research with medical ArXiV publications.
Demo: http://stanza.run/bio
ArXiV: https://arxiv.org/abs/2007.14640
#NLProc #NLU #Stanford #biolearning #medicallearning
Stanza extended with first domain-specific models for biomedical and clinical medical English. They range from approaching to significantly improving state of the art results on syntactic and NER tasks.
That means that now neural networks are capable of understanding difficult texts with lots of specific terms. That means better search, improved knowledge extraction and approach for performing META analysis, or even research with medical ArXiV publications.
Demo: http://stanza.run/bio
ArXiV: https://arxiv.org/abs/2007.14640
#NLProc #NLU #Stanford #biolearning #medicallearning
{kind=link}
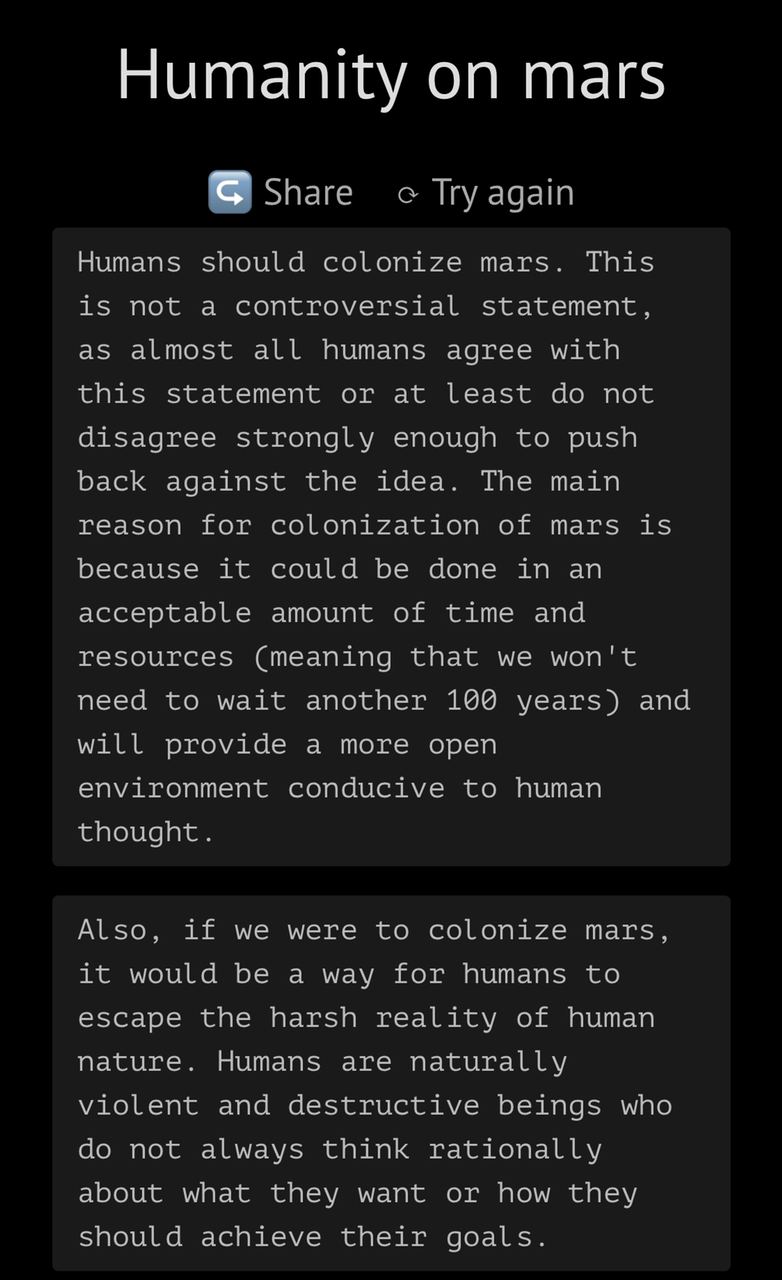
Philosopher AI — website to generate text with #GPT3
Tool to generate text on different topics. Sensible topics such as sex, religion or even nationality are blocked.
Great way to spread the awareness on #ai and to show nontechnical friends that #Skynet is not a problem to be concerned with yet.
Website: https://philosopherai.com/philosopher/humanity-on-mars-73ac00
#nlu #nlp
Tool to generate text on different topics. Sensible topics such as sex, religion or even nationality are blocked.
Great way to spread the awareness on #ai and to show nontechnical friends that #Skynet is not a problem to be concerned with yet.
Website: https://philosopherai.com/philosopher/humanity-on-mars-73ac00
#nlu #nlp
{kind=link}
Most of the Scots NLP models used Wikipedia for training are wrong
One person who had done 200,000 edits and written 20,000 articles of Scots Wikipedia was not using Scots language but rather faking it. Since Wikipedia texts are often used as a dataset for #NLU / #NLP / #NMT neural nets training, those models using it as an input had a flaw.
Reddit thread: https://www.reddit.com/r/Scotland/comments/ig9jia/ive_discovered_that_almost_every_single_article/
#datasets #translation #scots #wikipedia
One person who had done 200,000 edits and written 20,000 articles of Scots Wikipedia was not using Scots language but rather faking it. Since Wikipedia texts are often used as a dataset for #NLU / #NLP / #NMT neural nets training, those models using it as an input had a flaw.
Reddit thread: https://www.reddit.com/r/Scotland/comments/ig9jia/ive_discovered_that_almost_every_single_article/
#datasets #translation #scots #wikipedia
Reddit
From the Scotland community on Reddit: I’ve discovered that almost every single article on the Scots version of Wikipedia is written…
Explore this post and more from the Scotland community