std::lower_bound
Продолжение басни с алгоритмами в STL. Предыдущие части можете найти тут жмак и жмак
Сегодня речь пойдет про бинарный поиск. Точнее немного более прикладную его вариацию - std::lower_bound.
На самом деле не удивительно, почему в списке 3-х самых используемых алгоритмов есть этот, учитывая, что на первом месте стояла сортировка. Если что-то и искать, то искать надо в упорядоченных структурах данных. Ведь преимущества очевидны: О(n) против O(logn) (можно и за О(1), но это другая уже другая история). Поэтому следует избегать использования линейного поиска (типа std::find), а использовать подходящий контейнер и эффективный алгоритм поиска над ним.
Функция выполняет поиск в отсортированном диапазоне и возвращает итератор на первый элемент, не меньший, чем заданное значение. За счет того, что поиск происходит в упорядоченном контейнере, алгоритмическая сложность такой операции - О(logn). То есть это очень эффективный способ найти нужный элемент в контейнере. В основе алгоритма лежит бинарный поиск, где на каждой итерации цикла диапазон поиска уменьшается вдвое.
Алгоритм может использоваться, как для поиска конкретного элемента, так и для поиска диапазона значений самостоятельно (открытый диапазон) или в сочетании с upper_bound (закрытый диапазон).
Немного более вариабельным lower_bound становится в применении к деревьям. Тогда возвращаемый итератор можно использовать для эффективной вставки ноды в дерево (например методом map::emplace_hint).
И не зря довольно часто на собесах встречаются задачи на бинарный поиск. Потому что это реально маст-хэв. Поэтому его в принципе полезно знать и уметь запрогать руками.
Stay cool.
#STL #algorithms #datastructures
Продолжение басни с алгоритмами в STL. Предыдущие части можете найти тут жмак и жмак
Сегодня речь пойдет про бинарный поиск. Точнее немного более прикладную его вариацию - std::lower_bound.
На самом деле не удивительно, почему в списке 3-х самых используемых алгоритмов есть этот, учитывая, что на первом месте стояла сортировка. Если что-то и искать, то искать надо в упорядоченных структурах данных. Ведь преимущества очевидны: О(n) против O(logn) (можно и за О(1), но это другая уже другая история). Поэтому следует избегать использования линейного поиска (типа std::find), а использовать подходящий контейнер и эффективный алгоритм поиска над ним.
Функция выполняет поиск в отсортированном диапазоне и возвращает итератор на первый элемент, не меньший, чем заданное значение. За счет того, что поиск происходит в упорядоченном контейнере, алгоритмическая сложность такой операции - О(logn). То есть это очень эффективный способ найти нужный элемент в контейнере. В основе алгоритма лежит бинарный поиск, где на каждой итерации цикла диапазон поиска уменьшается вдвое.
Алгоритм может использоваться, как для поиска конкретного элемента, так и для поиска диапазона значений самостоятельно (открытый диапазон) или в сочетании с upper_bound (закрытый диапазон).
Немного более вариабельным lower_bound становится в применении к деревьям. Тогда возвращаемый итератор можно использовать для эффективной вставки ноды в дерево (например методом map::emplace_hint).
И не зря довольно часто на собесах встречаются задачи на бинарный поиск. Потому что это реально маст-хэв. Поэтому его в принципе полезно знать и уметь запрогать руками.
Stay cool.
#STL #algorithms #datastructures
👍15🔥4❤2
Как найти минимум в несортированном массиве за константу
Ответ на первый взгляд простой и понятной - хрена с два у тебя такое прокатит. Но что, если вам говорят на собесе : "Вот есть класс стека с методами push_back и pop_back и есть метод min. Нужно, чтобы метод min работал за константное время". Как ни отникивайся, придется решать. Чем мы с вами и займемся. А перед этим делом сами подумайте: как бы вы это сделали? Бывалым ценителям алгоритмических задачек этот вопрос даже каплю пота не вызовет, а вот средних работяг может заставить попотеть.
Первое, что надо понимать - если у вас просто есть готовый массив и ничего больше, то вы не найдете минимум за константное время. Нужно что-то думать. Второе, что надо понимать - очень часто можно довольно просто понизить сложность операции за счет применения правильного хранилища. Например, если превратить массив в неупорядоченное мультимножество, то сложность поиска понижается с О(n) до О(~1). И с этой мысли нужно начинать, когда от вас требуют понизить сложность. Задумайтесь. Не зря нам дали удобную обертку для массива. Мы можем контролировать, как именно будут добавляться и удаляться данные из него, а также можем хранить в этом классе какие-то дополнительные структуры.
В данном случае, решением будет добавить в класс поле current_min_stack - стек, в который будет хранить текущие минимумы для каждого элемента исходного массива. Как только вызывается push_back(value), в current_min_stack добавляется минимум из value и текущей верхушки current_min_stack. На каждый вызов pop_back мы убираем из current_min_stack его последний элемент. А на вызов min мы возвращаем последний элемент из стека текущего минимума.
Не самый эффективный способ, знаем и получше. Вот и напишите в комментах, как улучшить алгоритм.
Stay cool.
#algorithms
Ответ на первый взгляд простой и понятной - хрена с два у тебя такое прокатит. Но что, если вам говорят на собесе : "Вот есть класс стека с методами push_back и pop_back и есть метод min. Нужно, чтобы метод min работал за константное время". Как ни отникивайся, придется решать. Чем мы с вами и займемся. А перед этим делом сами подумайте: как бы вы это сделали? Бывалым ценителям алгоритмических задачек этот вопрос даже каплю пота не вызовет, а вот средних работяг может заставить попотеть.
Первое, что надо понимать - если у вас просто есть готовый массив и ничего больше, то вы не найдете минимум за константное время. Нужно что-то думать. Второе, что надо понимать - очень часто можно довольно просто понизить сложность операции за счет применения правильного хранилища. Например, если превратить массив в неупорядоченное мультимножество, то сложность поиска понижается с О(n) до О(~1). И с этой мысли нужно начинать, когда от вас требуют понизить сложность. Задумайтесь. Не зря нам дали удобную обертку для массива. Мы можем контролировать, как именно будут добавляться и удаляться данные из него, а также можем хранить в этом классе какие-то дополнительные структуры.
В данном случае, решением будет добавить в класс поле current_min_stack - стек, в который будет хранить текущие минимумы для каждого элемента исходного массива. Как только вызывается push_back(value), в current_min_stack добавляется минимум из value и текущей верхушки current_min_stack. На каждый вызов pop_back мы убираем из current_min_stack его последний элемент. А на вызов min мы возвращаем последний элемент из стека текущего минимума.
Не самый эффективный способ, знаем и получше. Вот и напишите в комментах, как улучшить алгоритм.
Stay cool.
#algorithms
{kind=link}
👍24🔥6👎2❤1
Идиома RAII
Наши подписчики присылают нам новые идеи и даже конспекты лекций! Поблагодарим Сергея Нефедова за это 🙂
В сообществе C++ разработчиков достаточно часто можно услышать об идиоме RAII (resource acquisition is initialization). Про нее уже было написано много и не раз, но и я попробую рассказать про нее по-своему.
Начну издалека, но так, чтобы вам было понятнее. Каждая вычислительная система обладает ресурсами - объектами вычислительной системы, которые ограничены в количестве и времени использования. Такой объект необходимо вернуть этой системе. Примером таких ресурсов могут стать оперативная память, доступ к файлу, сетевое соединение.
Каждый объект данного типа зачастую обладает обобщенным жизненным циклом:
1. Захват ресурса
Пример: выделение памяти, получение доступа, установка соединения.
2. Владение ресурсом
Пример: чтение/запись в память/файл, передача данных по соединению
3. Возврат ресурса
Пример: освобождение памяти, закрытие файла / соединения
Суть идиомы RAII заключается в том, чтобы данный жизненный цикл всегда был исполнен, т.е. ресурс всегда будет возвращен системе, когда он программе больше не нужен. Идиома предлагает вам создавать сущности в ваших программах таким образом, чтобы избежать утечки этих ограниченных ресурсов. Это может быть неочевидно в рамках учебных программ. Но в больших коммерческих проектах, которые могут эксплуатироваться годами без перерыва, отсутствие менеджмента ресурсов может привести к исчерпанию этих ресурсов и потере целевой функциональности. Срок годности вашего продукта будет ограничен временем исполнения или запасом этих ресурсов. Это уже не IT технологии...
Как же этого достичь? Обратите внимание на классы в C++, ведь они тоже соответствуют этому жизненному циклу. Давайте проведем аналогии:
1. Конструктор класса — захват ресурса
Начало жизни объекта: можно выделить память, открыть файл, установить соединение.
2. Ваши методы класса — владение ресурсом
Множество операций над ресурсом. Например, запись в память, файл или передача данных по соединению. Так же тут могут быть определены операции передачи владения ресурсом другому объекту. Данная тема будет подробнее раскрыта в следующих постах про move семантику.
3. Деструктор класса — возврат ресурса
Завершение жизни объекта: возвращаем системе захваченные ресурсы - освобождаем память, закрываем файлы и соединение.
Классы, созданные с подачи идиомы RAII, берут на себя ответственность менеджмента ресурсов и предоставления механизмов взаимодействия с ними.
Примечательно, что возврат ресурсов будет происходить во время уничтожения данного объекта - автоматически, при выходе из области видимости объекта этого класса. Это является очень удобным механизмом контроля за ресурсами для разработчика.
Примерами таких классов из стандартной библиотеки C++ являются std::string, а так же умные указатели:
1) std::unique_ptr<typename> - удаляет выделенный на куче объект типа typename при выходе из области видимости.
2) std::shared_ptr<typename> - удаляет выделенный на куче объект типа typename при выходе из области видимости всех копий данного умного указателя.
Если вам интересно узнать мнение авторов по конкретной теме, поделиться своими знаниями или задать интересный вопрос - пишите в комментах. Попробуем разобраться вместе.
#cppcore #goodpractice
Наши подписчики присылают нам новые идеи и даже конспекты лекций! Поблагодарим Сергея Нефедова за это 🙂
В сообществе C++ разработчиков достаточно часто можно услышать об идиоме RAII (resource acquisition is initialization). Про нее уже было написано много и не раз, но и я попробую рассказать про нее по-своему.
Начну издалека, но так, чтобы вам было понятнее. Каждая вычислительная система обладает ресурсами - объектами вычислительной системы, которые ограничены в количестве и времени использования. Такой объект необходимо вернуть этой системе. Примером таких ресурсов могут стать оперативная память, доступ к файлу, сетевое соединение.
Каждый объект данного типа зачастую обладает обобщенным жизненным циклом:
1. Захват ресурса
Пример: выделение памяти, получение доступа, установка соединения.
2. Владение ресурсом
Пример: чтение/запись в память/файл, передача данных по соединению
3. Возврат ресурса
Пример: освобождение памяти, закрытие файла / соединения
Суть идиомы RAII заключается в том, чтобы данный жизненный цикл всегда был исполнен, т.е. ресурс всегда будет возвращен системе, когда он программе больше не нужен. Идиома предлагает вам создавать сущности в ваших программах таким образом, чтобы избежать утечки этих ограниченных ресурсов. Это может быть неочевидно в рамках учебных программ. Но в больших коммерческих проектах, которые могут эксплуатироваться годами без перерыва, отсутствие менеджмента ресурсов может привести к исчерпанию этих ресурсов и потере целевой функциональности. Срок годности вашего продукта будет ограничен временем исполнения или запасом этих ресурсов. Это уже не IT технологии...
Как же этого достичь? Обратите внимание на классы в C++, ведь они тоже соответствуют этому жизненному циклу. Давайте проведем аналогии:
1. Конструктор класса — захват ресурса
Начало жизни объекта: можно выделить память, открыть файл, установить соединение.
2. Ваши методы класса — владение ресурсом
Множество операций над ресурсом. Например, запись в память, файл или передача данных по соединению. Так же тут могут быть определены операции передачи владения ресурсом другому объекту. Данная тема будет подробнее раскрыта в следующих постах про move семантику.
3. Деструктор класса — возврат ресурса
Завершение жизни объекта: возвращаем системе захваченные ресурсы - освобождаем память, закрываем файлы и соединение.
Классы, созданные с подачи идиомы RAII, берут на себя ответственность менеджмента ресурсов и предоставления механизмов взаимодействия с ними.
Примечательно, что возврат ресурсов будет происходить во время уничтожения данного объекта - автоматически, при выходе из области видимости объекта этого класса. Это является очень удобным механизмом контроля за ресурсами для разработчика.
Примерами таких классов из стандартной библиотеки C++ являются std::string, а так же умные указатели:
1) std::unique_ptr<typename> - удаляет выделенный на куче объект типа typename при выходе из области видимости.
2) std::shared_ptr<typename> - удаляет выделенный на куче объект типа typename при выходе из области видимости всех копий данного умного указателя.
Если вам интересно узнать мнение авторов по конкретной теме, поделиться своими знаниями или задать интересный вопрос - пишите в комментах. Попробуем разобраться вместе.
#cppcore #goodpractice
{kind=link}
👍16❤9🔥3
Почему РКН не сможет полностью заблокировать VPN в России Ч2
Первая часть тут. Причин на самом деле немного больше, чем я описывал ранее, и они гораздо более абстрактные.
Начнём, как всегда, с базы, а точнее с экономики. Большинство адекватных IT-компаний в России использую впн для доступа к корпоративным ресурсам (надо ещё учитывать, что сейчас даже самая облезлая собака считает себя ИТ-компанией). С учётом увеличивающегося хакерского давления на отрасль, использование корпоративного VPN - критическая необходимость для сохранения конфиденциальности информации и защиты сети от несанкционированного доступа. Также специалистам нужны многие сервисы, к которым в России доступ запрещён: линкедин для эйчаров, quora для прогеров и прочих работяг, перечислять можно много. Исходя из всего этого, чисто экономической точки зрения, представьте потери отрасли от блокировки впн трафика. Это десятки и сотни миллиардов рублей. И непозволительная роскошь для страны, которая сильно нуждается в отечественных ИТ-продуктах.
Помимо этого есть и главный идейный фактор. Люди на атаку любой сложности рано или поздно изобретают защиту для этой атаки. Естественная гонка вооружений. На любой интернетный запрет от нашего правительства найдётся лазейка. VPN был такой лазейкой в 18 году, когда РКН блокировал телеграмм. Дальше на помощь придут так называемые технологии обфускации трафика.
Цель обфускации - маскировка VPN трафика, делая его похожим на обычный трафик, чтобы обойти DPI. Например, данные можно скрыть под видом изображений или звуковых файлов. Обфусцирующие протоколы, типа Shadowsocks, прекрасно проявляют себя в Китае, как средство обхода их великого файервола.
Так что заявления РКН нужны просто, чтобы пыль в глаза бросить. Пока есть хоть один провод, соединяющий РФ с остальным интернетом, наши кулибины найдут способы для связи с внешним миром.
Stay calm. Stay cool.
#net #howitworks #fun
Первая часть тут. Причин на самом деле немного больше, чем я описывал ранее, и они гораздо более абстрактные.
Начнём, как всегда, с базы, а точнее с экономики. Большинство адекватных IT-компаний в России использую впн для доступа к корпоративным ресурсам (надо ещё учитывать, что сейчас даже самая облезлая собака считает себя ИТ-компанией). С учётом увеличивающегося хакерского давления на отрасль, использование корпоративного VPN - критическая необходимость для сохранения конфиденциальности информации и защиты сети от несанкционированного доступа. Также специалистам нужны многие сервисы, к которым в России доступ запрещён: линкедин для эйчаров, quora для прогеров и прочих работяг, перечислять можно много. Исходя из всего этого, чисто экономической точки зрения, представьте потери отрасли от блокировки впн трафика. Это десятки и сотни миллиардов рублей. И непозволительная роскошь для страны, которая сильно нуждается в отечественных ИТ-продуктах.
Помимо этого есть и главный идейный фактор. Люди на атаку любой сложности рано или поздно изобретают защиту для этой атаки. Естественная гонка вооружений. На любой интернетный запрет от нашего правительства найдётся лазейка. VPN был такой лазейкой в 18 году, когда РКН блокировал телеграмм. Дальше на помощь придут так называемые технологии обфускации трафика.
Цель обфускации - маскировка VPN трафика, делая его похожим на обычный трафик, чтобы обойти DPI. Например, данные можно скрыть под видом изображений или звуковых файлов. Обфусцирующие протоколы, типа Shadowsocks, прекрасно проявляют себя в Китае, как средство обхода их великого файервола.
Так что заявления РКН нужны просто, чтобы пыль в глаза бросить. Пока есть хоть один провод, соединяющий РФ с остальным интернетом, наши кулибины найдут способы для связи с внешним миром.
Stay calm. Stay cool.
#net #howitworks #fun
{kind=link}
👍15❤3🔥1
Предупреждения компилятора Ч1
Наверно многие попадали в такую ситуацию, когда ваша программа работала корректно, но компилятор заваливал вас предупреждениями о тех или иных потенциальных проблемах. Нередко в приоритет ставится в первую очередь возможность компиляции и запуска, а уже потом исправление предупреждений. Это зачастую приводит к привычке игнорировать их совсем...
Но давайте подумаем, зачем же они вообще выводятся? В конце концов, кто-то посчитал важным добавить в компиляторе эти сообщения. Неужели это сделано, чтобы подпортить вам и без того сложную жизнь C++ разработчика?
Конечно, нет. Скажу больше, предупреждения должны вам помогать. Тревожным сигналом является то, если они вам мешают! Забегая вперед, скажу сразу, что в достаточно крупных компаниях возникновение предупреждений считается недопустимым. Сборка проектов устроена так, что возникновение любого предупреждения приводит к ошибке компиляции. Всё строго.
Предупреждения указывают на потенциально опасное место, где может возникнуть ошибка. Возможно, что она возникает только в определенных сценариях, с определенным набором данных. Но можете ли вы гарантировать, что такие сценарии никогда не произойдут? А если можете, то зачем вам засорять вывод лишними предупреждениями?
Некоторые ошибки допускаются случайно, по невнимательности, даже несмотря на высокие компетенции разработчика. Если предупреждений будет много, как быстро он заметит свою ошибку? Отсутствие каких-либо предупреждений по умолчанию позволит однозначно обратить на это внимание, когда оно возникнет.
Исправляйте все предупреждения. Строгость и дисциплинированность будут играть вам на руку на поздних этапах разработки, до которых с другими подходами можно и вовсе не дотянуть.
#compiler #goodpractice
Наверно многие попадали в такую ситуацию, когда ваша программа работала корректно, но компилятор заваливал вас предупреждениями о тех или иных потенциальных проблемах. Нередко в приоритет ставится в первую очередь возможность компиляции и запуска, а уже потом исправление предупреждений. Это зачастую приводит к привычке игнорировать их совсем...
Но давайте подумаем, зачем же они вообще выводятся? В конце концов, кто-то посчитал важным добавить в компиляторе эти сообщения. Неужели это сделано, чтобы подпортить вам и без того сложную жизнь C++ разработчика?
Конечно, нет. Скажу больше, предупреждения должны вам помогать. Тревожным сигналом является то, если они вам мешают! Забегая вперед, скажу сразу, что в достаточно крупных компаниях возникновение предупреждений считается недопустимым. Сборка проектов устроена так, что возникновение любого предупреждения приводит к ошибке компиляции. Всё строго.
Предупреждения указывают на потенциально опасное место, где может возникнуть ошибка. Возможно, что она возникает только в определенных сценариях, с определенным набором данных. Но можете ли вы гарантировать, что такие сценарии никогда не произойдут? А если можете, то зачем вам засорять вывод лишними предупреждениями?
Некоторые ошибки допускаются случайно, по невнимательности, даже несмотря на высокие компетенции разработчика. Если предупреждений будет много, как быстро он заметит свою ошибку? Отсутствие каких-либо предупреждений по умолчанию позволит однозначно обратить на это внимание, когда оно возникнет.
Исправляйте все предупреждения. Строгость и дисциплинированность будут играть вам на руку на поздних этапах разработки, до которых с другими подходами можно и вовсе не дотянуть.
#compiler #goodpractice
{kind=link}
❤14👍6❤🔥1
Предупреждения компилятора Ч2
Продолжаем тему предупреждений компилятора.
У каждого предупреждения существует некоторый паттерн, который компилятор пытается распознать и сообщить об этом разработчику.
Активировать данную функциональность можно двумя опциями компилятора:
Они включают в себя очень большое количество проверок. Рассмотрим некоторые типичные примеры:
1. Неиспользуемые переменные - пример
Переменная была объявлена, но не используется в коде. Разработчик забыл её использовать, либо появился так называемый мертвый код.
2. Неинициализированные переменные - пример
Значение переменной читается и используется до того, как ей было присвоено начальное значение. Достаточно серьезная ошибка, классифицируемая как UB - undefined behavior - неопределенное поведение.
3. Недостижимый код - пример
В вашей программе появился участок кода, который никогда не будет выполнен. Это может быть вызвано неправильной логикой или условиями, которые всегда являются ложными или всегда истинными.
4. Неправильное использование типов данных - пример
Преобразовании типов данных, которые могут привести к потере данных или неожиданному поведению программы.
5. Неоднозначные операции - пример
Компилятор может предупредить о неоднозначном использовании операций или перегруженных операторов, когда он не может определить, какой именно вариант операции вы хотите использовать.
6. Потенциальные проблемы безопасности - пример
Компилятор может выдавать предупреждения о возможных проблемах безопасности, таких как использование небезопасных функций или операций, которые могут привести к переполнению буфера.
К сожалению, не все проблемы кода могут быть распознаны компилятором на этапе компиляции, т.е. без ее запуска. Так что развивайте внутри недр своего мозга виртуальный компилятор - это необходимый инструмент каждого разработчика.
#compiler #goodpractice
Продолжаем тему предупреждений компилятора.
У каждого предупреждения существует некоторый паттерн, который компилятор пытается распознать и сообщить об этом разработчику.
Активировать данную функциональность можно двумя опциями компилятора:
g++ source.cpp -Wall -Wextra
Они включают в себя очень большое количество проверок. Рассмотрим некоторые типичные примеры:
1. Неиспользуемые переменные - пример
Переменная была объявлена, но не используется в коде. Разработчик забыл её использовать, либо появился так называемый мертвый код.
2. Неинициализированные переменные - пример
Значение переменной читается и используется до того, как ей было присвоено начальное значение. Достаточно серьезная ошибка, классифицируемая как UB - undefined behavior - неопределенное поведение.
3. Недостижимый код - пример
В вашей программе появился участок кода, который никогда не будет выполнен. Это может быть вызвано неправильной логикой или условиями, которые всегда являются ложными или всегда истинными.
4. Неправильное использование типов данных - пример
Преобразовании типов данных, которые могут привести к потере данных или неожиданному поведению программы.
5. Неоднозначные операции - пример
Компилятор может предупредить о неоднозначном использовании операций или перегруженных операторов, когда он не может определить, какой именно вариант операции вы хотите использовать.
6. Потенциальные проблемы безопасности - пример
Компилятор может выдавать предупреждения о возможных проблемах безопасности, таких как использование небезопасных функций или операций, которые могут привести к переполнению буфера.
К сожалению, не все проблемы кода могут быть распознаны компилятором на этапе компиляции, т.е. без ее запуска. Так что развивайте внутри недр своего мозга виртуальный компилятор - это необходимый инструмент каждого разработчика.
#compiler #goodpractice
{kind=link}
❤11👍5❤🔥1🔥1
Предупреждения компилятора Ч3
Завершаем серию постов о предупреждениях компилятора. На этот раз поговорим об исправлениях предупреждений.
Самым логичным способом устранения предупреждения является влияние на причины возникновения, однако в моей практике встречался и другой способ - сокрытие предупреждения. Антипример: https://compiler-explorer.com/z/K9v8j6Kbc. Такой способ позволяет замаскировать проблему, которая никуда не исчезнет!
Более того, при неумелом использовании сокрытие предупреждений распространится и на остальные части вашего проекта. Уязвимости созданные в начале разработки, перекочуют в разные части проекта, скопируются, а так же обрастут новыми потенциальными уязвимостями или костылями. Все это будет незаметно наращивать технический долг.
Возможно, что однажды это будет раскрыто. И вот тут уже перед вами будет стоять дилемма: проигнорировать их опять или героически начать всё исправлять? Исправлять баги в действующем продукте - это не только долго, но и опасно. Как гласит университетская шутка: "чётное количество ошибок может давать правильный результат".
Этот инструмент должен был вам помогать с самого первого дня разработки проекта, а теперь не может полноценно функционировать вовсе. Вероятно, что лучше было бы вовсе отказаться от предупреждений компилятора, чем пытаться их замаскировать? Другим эта функция теперь недоступна.
В качестве заключения, я хочу донести до вас одну простую мысль. Исправление предупреждений, однозначно, должно быть качественным, а не фиктивным.
#compiler #goodpractice
Завершаем серию постов о предупреждениях компилятора. На этот раз поговорим об исправлениях предупреждений.
Самым логичным способом устранения предупреждения является влияние на причины возникновения, однако в моей практике встречался и другой способ - сокрытие предупреждения. Антипример: https://compiler-explorer.com/z/K9v8j6Kbc. Такой способ позволяет замаскировать проблему, которая никуда не исчезнет!
Более того, при неумелом использовании сокрытие предупреждений распространится и на остальные части вашего проекта. Уязвимости созданные в начале разработки, перекочуют в разные части проекта, скопируются, а так же обрастут новыми потенциальными уязвимостями или костылями. Все это будет незаметно наращивать технический долг.
Возможно, что однажды это будет раскрыто. И вот тут уже перед вами будет стоять дилемма: проигнорировать их опять или героически начать всё исправлять? Исправлять баги в действующем продукте - это не только долго, но и опасно. Как гласит университетская шутка: "чётное количество ошибок может давать правильный результат".
Этот инструмент должен был вам помогать с самого первого дня разработки проекта, а теперь не может полноценно функционировать вовсе. Вероятно, что лучше было бы вовсе отказаться от предупреждений компилятора, чем пытаться их замаскировать? Другим эта функция теперь недоступна.
В качестве заключения, я хочу донести до вас одну простую мысль. Исправление предупреждений, однозначно, должно быть качественным, а не фиктивным.
#compiler #goodpractice
{kind=link}
❤12👍5🤯2
Код ревью Ч1
Во многих IT-компаниях процедура код-ревью является обязательной. Перед добавлением новых изменений в кодовую базу команда разработчиков проверяет друг друга с целью улучшить решение. Побочным эффектом является повышение компетенций автора. Я предлагаю рассматривать эту практику именно с этой стороны и сейчас поговорим, почему именно так.
Нередко на просторах интернета можно встретить достаточно токсичные треды с обсуждением какого-либо решения... Неудивительно, что многие начинающие разработчики побаиваются код-ревью. И все же это интернет, а не реальные коллеги. Тем не менее это вызов вашим компетенциям. Рассматривайте это, как способ проверить и повысить ваши навыки коммуникации и убеждения, расширить знания программирования. Часто нет однозначно правильного решения, все варианты обладают своими плюсами и минусами. В таком случае приходится убеждать других - это все влияет на ваш профессиональный авторитет в коллективе. Это важно и для собственной самооценки, и для карьерного роста.
Эмоциональная нагрузка со временем будет уменьшаться, и даже наоборот перерасти в азарт: а слабо ли мне пройти ревью без единого исправления? Это челлендж самому себе, но его проходить реально прикольно. Желаю вам испытать это чувство собственной неотразимости! 😊
К сожалению, в некоторых компаниях пренебрегают такой процедурой. На моей практике был печальный опыт получения проекта от другой компании, где не было такой процедуры. Отсутствие проверки расхолаживает разработчиков, а качество кода не улучшается со временем. Всегда есть возможность сэкономить и запилить костыль до лучших времен, которые, возможно, никогда не настанут. Я не преувеличиваю, бывает очень сложно доказать вышестоящему руководству, что необходимо выделить время на рефакторинг. С точки зрения потребителя и бизнеса ничего не меняется, это внутренние дела вашей кухни.
Я сделал однозначный для себя вывод, что код-ревью является необходимой процедурой коммерческой разработки. Качественный код нужно публиковать как можно раньше. Да, это требует времени и сил, но развивает коллектив и позволяет поддерживать проект очень долгое время, сокращает количество ошибок и багов, упрощает жизнь программистов в долгосрочной перспективе.
В следующей части давайте поговорим, как проводить код-ревью для своих коллег. На мой взгляд есть важные моменты, я хочу быть уверен, что вы их точно будете знать.
#commercial #goodpractice
Во многих IT-компаниях процедура код-ревью является обязательной. Перед добавлением новых изменений в кодовую базу команда разработчиков проверяет друг друга с целью улучшить решение. Побочным эффектом является повышение компетенций автора. Я предлагаю рассматривать эту практику именно с этой стороны и сейчас поговорим, почему именно так.
Нередко на просторах интернета можно встретить достаточно токсичные треды с обсуждением какого-либо решения... Неудивительно, что многие начинающие разработчики побаиваются код-ревью. И все же это интернет, а не реальные коллеги. Тем не менее это вызов вашим компетенциям. Рассматривайте это, как способ проверить и повысить ваши навыки коммуникации и убеждения, расширить знания программирования. Часто нет однозначно правильного решения, все варианты обладают своими плюсами и минусами. В таком случае приходится убеждать других - это все влияет на ваш профессиональный авторитет в коллективе. Это важно и для собственной самооценки, и для карьерного роста.
Эмоциональная нагрузка со временем будет уменьшаться, и даже наоборот перерасти в азарт: а слабо ли мне пройти ревью без единого исправления? Это челлендж самому себе, но его проходить реально прикольно. Желаю вам испытать это чувство собственной неотразимости! 😊
К сожалению, в некоторых компаниях пренебрегают такой процедурой. На моей практике был печальный опыт получения проекта от другой компании, где не было такой процедуры. Отсутствие проверки расхолаживает разработчиков, а качество кода не улучшается со временем. Всегда есть возможность сэкономить и запилить костыль до лучших времен, которые, возможно, никогда не настанут. Я не преувеличиваю, бывает очень сложно доказать вышестоящему руководству, что необходимо выделить время на рефакторинг. С точки зрения потребителя и бизнеса ничего не меняется, это внутренние дела вашей кухни.
Я сделал однозначный для себя вывод, что код-ревью является необходимой процедурой коммерческой разработки. Качественный код нужно публиковать как можно раньше. Да, это требует времени и сил, но развивает коллектив и позволяет поддерживать проект очень долгое время, сокращает количество ошибок и багов, упрощает жизнь программистов в долгосрочной перспективе.
В следующей части давайте поговорим, как проводить код-ревью для своих коллег. На мой взгляд есть важные моменты, я хочу быть уверен, что вы их точно будете знать.
#commercial #goodpractice
{kind=link}
👍13🔥3❤1
Код ревью Ч2
Продолжаем тему код-ревью. На этот раз поговорим об этом с точки зрения проверяющего.
Эмоциональный фон сильно влияет на скорость и качество исправлений замечаний, исполнения пожеланий других разработчиков. В одном из исследований было замечено, что люди получают большее удовольствие от работы, если в компании работает лучший друг. Зачем упускать возможность получать от работы удовольствие? Мы решаем проблему, а не самоутверждаемся за счет других!
На моем текущем месте работы однажды проводили тренинг по командообразованию. Мы обсуждали разные сложности в работе, в том числе эмоциональную нагрузку на код-ревью. Нам понадобилось два полных рабочих дня, чтобы проработать все сложности... И знаете какой итог был по окончанию этого мероприятия? Не поверите, но мы договорились делать друг другу комплименты там, где нам действительно что-то понравилось 😄 Конечно, лишь немногие стали придерживаться этой рекомендации, но прошел уже почти год и мне действительно стало приятнее работать с этими единицами!
Заводите друзей среди коллег, либо общайтесь, как с другом, пока вы ими действительно не станете. Это определяет всю манеру и способы взаимодействия друг с другом! Например:
1. Терпеливость и внимательность в общении
2. Допущение вкусовых предпочтений автора кода
Конечно, это не отменяет конструктивной критики, а лишь корректирует форму преподнесения ваших замечаний. Главной целью, как я уже говорил ранее, является улучшение предоставленного решения: исправление ошибок, работа над читаемостью кода, проверка логики и т.д.
«Абсолютная корректность системы - недостижима. Каждая последняя найденная ошибка является предпоследней»
Этот закон отражает сложность нетривиальных систем, с которыми разработчики сталкиваются каждый день. Следовательно, и решение необходимо искать ошибки на самых разных уровнях. Начиная с самых простых - синтаксических, заканчивая самыми сложными - соответствия целям бизнеса. В идеале, целеустремленный разработчик будет стремиться к пониманию потребностей своих клиентов и работать над их достижением.
Вовлеченность в каждый из этих вопросов определяет профессионализм разработчика.
#commercial #goodpractice
Продолжаем тему код-ревью. На этот раз поговорим об этом с точки зрения проверяющего.
Эмоциональный фон сильно влияет на скорость и качество исправлений замечаний, исполнения пожеланий других разработчиков. В одном из исследований было замечено, что люди получают большее удовольствие от работы, если в компании работает лучший друг. Зачем упускать возможность получать от работы удовольствие? Мы решаем проблему, а не самоутверждаемся за счет других!
На моем текущем месте работы однажды проводили тренинг по командообразованию. Мы обсуждали разные сложности в работе, в том числе эмоциональную нагрузку на код-ревью. Нам понадобилось два полных рабочих дня, чтобы проработать все сложности... И знаете какой итог был по окончанию этого мероприятия? Не поверите, но мы договорились делать друг другу комплименты там, где нам действительно что-то понравилось 😄 Конечно, лишь немногие стали придерживаться этой рекомендации, но прошел уже почти год и мне действительно стало приятнее работать с этими единицами!
Заводите друзей среди коллег, либо общайтесь, как с другом, пока вы ими действительно не станете. Это определяет всю манеру и способы взаимодействия друг с другом! Например:
1. Терпеливость и внимательность в общении
2. Допущение вкусовых предпочтений автора кода
Конечно, это не отменяет конструктивной критики, а лишь корректирует форму преподнесения ваших замечаний. Главной целью, как я уже говорил ранее, является улучшение предоставленного решения: исправление ошибок, работа над читаемостью кода, проверка логики и т.д.
«Абсолютная корректность системы - недостижима. Каждая последняя найденная ошибка является предпоследней»
Этот закон отражает сложность нетривиальных систем, с которыми разработчики сталкиваются каждый день. Следовательно, и решение необходимо искать ошибки на самых разных уровнях. Начиная с самых простых - синтаксических, заканчивая самыми сложными - соответствия целям бизнеса. В идеале, целеустремленный разработчик будет стремиться к пониманию потребностей своих клиентов и работать над их достижением.
Вовлеченность в каждый из этих вопросов определяет профессионализм разработчика.
#commercial #goodpractice
{kind=link}
❤10👍5🔥1
Код ревью Ч3
Продолжаем тему код-ревью. Давайте теперь попробуем назвать общее требование к автору и проверяющим. Я бы выделил коллективную ответственность за эволюцию кода проекта.
Специально использую термин эволюция, т.к. ваш проект изменяется каждый день. Заказчики присылают новые требования, конкуренты развивают свои продукты, разработчики добавляют новые фишки и исправляют баги... Каждая строчка кода проходит естественный и искусственный отбор.
Выбор потребителей - это этапы естественного отбора. Если ваш продукт уступает в чем-то, то его перестают выбирать. При такой динамике количество клиентов будет недостаточно, чтобы поддерживать ПО дальше, т.е. произойдет отбор не в вашу пользу.
Ваши замечания на ревью - это этап искусственного отбора. Проверка кода - это капля в море, но именно из них и состоит весь проект. Те баги, что вы пропускаете вперед, вы же и будете исправлять! Да, иногда стоит поискать слова и аргументы, чтобы объяснить сложную суть проблемы или преимущество вашего решения, которое вы видите сейчас или в будущем.
С моей точки зрения, автор несёт большую ответственность, т.к. именно он является наиболее погруженным в контекст участником, выполняет первичное тестирование. Если смотреть с этой позиции, автор выступает еще и в роли проверяющего, а исходное решение является нулевой итерацией проверки. Ну, и следовательно, их надо найти и устранить 😃
Предполагается, что опубликованное решение работает корректно, но мы всегда должны мыслить критически - проверять это предположение и превращать его в утверждение.
Пишите вопросы! Вам ответ - нам контент!
#commercial #goodpractice
Продолжаем тему код-ревью. Давайте теперь попробуем назвать общее требование к автору и проверяющим. Я бы выделил коллективную ответственность за эволюцию кода проекта.
Специально использую термин эволюция, т.к. ваш проект изменяется каждый день. Заказчики присылают новые требования, конкуренты развивают свои продукты, разработчики добавляют новые фишки и исправляют баги... Каждая строчка кода проходит естественный и искусственный отбор.
Выбор потребителей - это этапы естественного отбора. Если ваш продукт уступает в чем-то, то его перестают выбирать. При такой динамике количество клиентов будет недостаточно, чтобы поддерживать ПО дальше, т.е. произойдет отбор не в вашу пользу.
Ваши замечания на ревью - это этап искусственного отбора. Проверка кода - это капля в море, но именно из них и состоит весь проект. Те баги, что вы пропускаете вперед, вы же и будете исправлять! Да, иногда стоит поискать слова и аргументы, чтобы объяснить сложную суть проблемы или преимущество вашего решения, которое вы видите сейчас или в будущем.
С моей точки зрения, автор несёт большую ответственность, т.к. именно он является наиболее погруженным в контекст участником, выполняет первичное тестирование. Если смотреть с этой позиции, автор выступает еще и в роли проверяющего, а исходное решение является нулевой итерацией проверки. Ну, и следовательно, их надо найти и устранить 😃
Предполагается, что опубликованное решение работает корректно, но мы всегда должны мыслить критически - проверять это предположение и превращать его в утверждение.
Пишите вопросы! Вам ответ - нам контент!
#commercial #goodpractice
{kind=link}
❤9👍3🔥1
Код ревью Ч4
Продолжаем тему код-ревью.
Конечно, найти все ошибки самостоятельно нельзя. Это следует из закона, который я упомянул в одном из предыдущих постов. Но можно поспособствовать себе в этом! В основном, большая часть ошибок допускается по невнимательности или неосознанности принятых решений. Мне помогают следующие рекомендации:
1. Отдыхать после работы.
Без комментариев.
2. Не публиковать код вечером.
Не думаю, что вашим коллегам будет принципиально важно увидеть код как можно скорее - вечером или утром следующего дня. А вот вам этот перерыв поможет перевести дух и взглянуть на решение свежим взглядом. Я так неоднократно находил у себя разные мелочи.
3. Спрашивайте себя почему и зачем?
Почаще спрашивайте себя, зачем вы приняли такой решение тут? Почему это работает так там? И не забывайте отвечать на эти вопросы :) Это просто влияет на вашу осознанность и погруженность в код.
3. Представить себя на месте коллег
Бывало ли у вас такое, что вы идете по очень знакомой улице, но вспоминаете свои ощущения и впечатления, как это было впервые? Попробуйте погрузиться в это ментальное состояние и попробовать посмотреть на свой код чужими глазами, абстрагировавшись от контекста. Это то, что увидят ваши коллеги. Поймут ли они то, что задумали вы?
4. Как бы сказал ваш авторитет?
Да, можно представить себя на месте вашего авторитета и подумать, что бы он сказал по поводу того или иного решения?
Надеюсь, что и для вас эти рекомендации будут полезны! 😉
#commercial #goodpractice
Продолжаем тему код-ревью.
Конечно, найти все ошибки самостоятельно нельзя. Это следует из закона, который я упомянул в одном из предыдущих постов. Но можно поспособствовать себе в этом! В основном, большая часть ошибок допускается по невнимательности или неосознанности принятых решений. Мне помогают следующие рекомендации:
1. Отдыхать после работы.
Без комментариев.
2. Не публиковать код вечером.
Не думаю, что вашим коллегам будет принципиально важно увидеть код как можно скорее - вечером или утром следующего дня. А вот вам этот перерыв поможет перевести дух и взглянуть на решение свежим взглядом. Я так неоднократно находил у себя разные мелочи.
3. Спрашивайте себя почему и зачем?
Почаще спрашивайте себя, зачем вы приняли такой решение тут? Почему это работает так там? И не забывайте отвечать на эти вопросы :) Это просто влияет на вашу осознанность и погруженность в код.
3. Представить себя на месте коллег
Бывало ли у вас такое, что вы идете по очень знакомой улице, но вспоминаете свои ощущения и впечатления, как это было впервые? Попробуйте погрузиться в это ментальное состояние и попробовать посмотреть на свой код чужими глазами, абстрагировавшись от контекста. Это то, что увидят ваши коллеги. Поймут ли они то, что задумали вы?
4. Как бы сказал ваш авторитет?
Да, можно представить себя на месте вашего авторитета и подумать, что бы он сказал по поводу того или иного решения?
Надеюсь, что и для вас эти рекомендации будут полезны! 😉
#commercial #goodpractice
{kind=link}
❤11👍4❤🔥1
std::optional
Сталкивались ли с необходимостью определить особенное состояние переменной, которая может принимать разные значения?
Приведу пример из практики. Недавно мне нужно было придумать интерфейс для передачи необязательных целочисленных параметров в функцию. В данном контексте особенным состоянием является отсутствие одного или нескольких значений.
Как вообще можно теоретические решить подобную проблему? Мне пришли в голову следующие варианты:
1. Определить несколько реализаций функций
Крайне неудобный способ, необходимо проверять всевозможные комбинации переменных и под них писать реализации функций.
2. Использовать специальную константу
Специально заданное значение может быть одним из возможных значений, которые передал пользователь, хоть и крайне редким. А вам, как коллегам автора решения, было бы удобно искать специально подобранные константы для ваших новых реализаций?
3. Передавать std::map с параметрами
Неудобное обращение и проверка существования ключа мапы. Накладные расходы на хранение и обслуживание структуры.
4. Передавать указатели на значения
Такой способ может показаться удобным, т.к. nullptr однозначно определяет отсутствие значения. Неудобно, что можно случайно забыть сделать проверку и словить segfault 🥲
5. Использовать специальный класс
Именно этот способ я и выбрал для себя. Давайте расскажу подробнее ниже.
В стандарте языка существует шаблонный класс std::optional<T>, который предоставляет разработчику возможность зарезервировать память под объект класса T и отложить момент инициализации, вплоть до бесконечности. Пользователь имеет возможность узнать состояние объекта и получить к нему доступ. В случае попытки получить доступ к объекту в невалидном состоянии будет брошено исключение std::bad_optional_access (лучше, чем не отлавливаемый segfault 😉).
По сути этот класс представляет из себя обертку над внутри лежащим классом, который добавляет специальное логическое поле для сохранения состояния объекта - инициализировано или нет. Объект std::optional резервирует память под объект класса T там, где его аллоцировали - на стеке или куче, как std::array. Это совсем немного увеличивает расход памяти (+1 байт) и выравнивает полученную структуру.
Это, действительно, удобный, явный и понятный способ показать, что значение переменной может отсутствовать. Помимо этого, класс так же снабжен специальными методами, которые позволяют обработать или изменять состояние внутрилежащего объекта. А при необходимости - обработать ошибочное поведение вашей программы.
Пример: https://compiler-explorer.com/z/65KrTnjbe
Так же это подталкивает меня к мысли, что можно создавать аналогичные обертки, которые будут хранить в себе намного больше состояний внутрилежащего объекта. Данные будут хорошо связаны и легки в использовании другими разработчиками
#cpp17 #STL
Сталкивались ли с необходимостью определить особенное состояние переменной, которая может принимать разные значения?
Приведу пример из практики. Недавно мне нужно было придумать интерфейс для передачи необязательных целочисленных параметров в функцию. В данном контексте особенным состоянием является отсутствие одного или нескольких значений.
Как вообще можно теоретические решить подобную проблему? Мне пришли в голову следующие варианты:
1. Определить несколько реализаций функций
Крайне неудобный способ, необходимо проверять всевозможные комбинации переменных и под них писать реализации функций.
2. Использовать специальную константу
Специально заданное значение может быть одним из возможных значений, которые передал пользователь, хоть и крайне редким. А вам, как коллегам автора решения, было бы удобно искать специально подобранные константы для ваших новых реализаций?
3. Передавать std::map с параметрами
Неудобное обращение и проверка существования ключа мапы. Накладные расходы на хранение и обслуживание структуры.
4. Передавать указатели на значения
Такой способ может показаться удобным, т.к. nullptr однозначно определяет отсутствие значения. Неудобно, что можно случайно забыть сделать проверку и словить segfault 🥲
5. Использовать специальный класс
Именно этот способ я и выбрал для себя. Давайте расскажу подробнее ниже.
В стандарте языка существует шаблонный класс std::optional<T>, который предоставляет разработчику возможность зарезервировать память под объект класса T и отложить момент инициализации, вплоть до бесконечности. Пользователь имеет возможность узнать состояние объекта и получить к нему доступ. В случае попытки получить доступ к объекту в невалидном состоянии будет брошено исключение std::bad_optional_access (лучше, чем не отлавливаемый segfault 😉).
По сути этот класс представляет из себя обертку над внутри лежащим классом, который добавляет специальное логическое поле для сохранения состояния объекта - инициализировано или нет. Объект std::optional резервирует память под объект класса T там, где его аллоцировали - на стеке или куче, как std::array. Это совсем немного увеличивает расход памяти (+1 байт) и выравнивает полученную структуру.
Это, действительно, удобный, явный и понятный способ показать, что значение переменной может отсутствовать. Помимо этого, класс так же снабжен специальными методами, которые позволяют обработать или изменять состояние внутрилежащего объекта. А при необходимости - обработать ошибочное поведение вашей программы.
Пример: https://compiler-explorer.com/z/65KrTnjbe
Так же это подталкивает меня к мысли, что можно создавать аналогичные обертки, которые будут хранить в себе намного больше состояний внутрилежащего объекта. Данные будут хорошо связаны и легки в использовании другими разработчиками
#cpp17 #STL
{kind=link}
❤17🔥5👍3👏1
Как правильно запретить объекту копироваться
Бывают такие ситуации, когда объект владеет каким-то ресурсом единолично, то есть имеет над ним так называемый ownership. В этом случае время жизни и использования ресурса совпадает с временем жизни объекта, а использование этого же самого ресурса другим объектом будет приносить странные side effect’ы. Например у нас есть класс, который содержит файл в качестве поля и который открывает этот файл в конструкторе и закрывает в деструкторе. Что должно происходить при копировании объекта этого класса? Должен ли файл ещё раз открываться или в начале в копируемом объекте закрываться, а потом открываться в скопированном? Все варианты выглядят выстрелом в хлебало, поэтому логично запретить таким объектам копироваться.
Как это сделать? Самое широкоиспользуемое решение - объявить конструктор копирования и оператор присваивания приватными и жить счастливо. Никто снаружи класса не сможет получить доступ к этим специальным методам, а при попытке будет ошибка компиляции. Но это только снаружи класса. Внутри класса-то можно использовать приватные поля и методы. И тут уже огромный простор для ошибок, в зависимости от того, как вы определили специальные методы.
Такой код
class NonCopyable {
private:
NonCopyable( const NonCopyable& ) {}
void NonCopyable::operator=( const NonCopyable& ) {}
};
void NonCopyable::SomeOtherMehod() {
callSomething( *this );
}
Приведёт к вызову копирующего конструктора и копированию всех полей, что ведёт к неопределенному поведению.
Но С++11 подарил нам прекрасную фича - можно пометить любую функцию как = delete и компилятор просто не будет генерировать код для неё. Поэтому такие функции физически не могут быть вызваны. Пометив наши методы удаленными, мы уберём возможность любой сущности их вызывать и сильно обезопасим код.
К тому же, использование этой фичи повышает читаемость кода. А так как пометить удаленной можно любую функцию, то можно удалить ненужную перегрузку или запретить вызывать функцию с ошибочным приведением параметров.
Modern C++ - сила.
Stay cool.
#cppcore #cpp11 #goodpractice
Бывают такие ситуации, когда объект владеет каким-то ресурсом единолично, то есть имеет над ним так называемый ownership. В этом случае время жизни и использования ресурса совпадает с временем жизни объекта, а использование этого же самого ресурса другим объектом будет приносить странные side effect’ы. Например у нас есть класс, который содержит файл в качестве поля и который открывает этот файл в конструкторе и закрывает в деструкторе. Что должно происходить при копировании объекта этого класса? Должен ли файл ещё раз открываться или в начале в копируемом объекте закрываться, а потом открываться в скопированном? Все варианты выглядят выстрелом в хлебало, поэтому логично запретить таким объектам копироваться.
Как это сделать? Самое широкоиспользуемое решение - объявить конструктор копирования и оператор присваивания приватными и жить счастливо. Никто снаружи класса не сможет получить доступ к этим специальным методам, а при попытке будет ошибка компиляции. Но это только снаружи класса. Внутри класса-то можно использовать приватные поля и методы. И тут уже огромный простор для ошибок, в зависимости от того, как вы определили специальные методы.
Такой код
class NonCopyable {
private:
NonCopyable( const NonCopyable& ) {}
void NonCopyable::operator=( const NonCopyable& ) {}
};
void NonCopyable::SomeOtherMehod() {
callSomething( *this );
}
Приведёт к вызову копирующего конструктора и копированию всех полей, что ведёт к неопределенному поведению.
Но С++11 подарил нам прекрасную фича - можно пометить любую функцию как = delete и компилятор просто не будет генерировать код для неё. Поэтому такие функции физически не могут быть вызваны. Пометив наши методы удаленными, мы уберём возможность любой сущности их вызывать и сильно обезопасим код.
К тому же, использование этой фичи повышает читаемость кода. А так как пометить удаленной можно любую функцию, то можно удалить ненужную перегрузку или запретить вызывать функцию с ошибочным приведением параметров.
Modern C++ - сила.
Stay cool.
#cppcore #cpp11 #goodpractice
{kind=link}
❤14👍6🔥2
Предсказуемость
Этот пост я бы хотел посвятить теме предсказуемости в разработке программ. Это очень интересное свойство, корни которого заложены глубоко в человеке.
На одной из экскурсий по архитектуре моего города экскурсовод обратил внимание на восприятие человеком красоты архитектуры. Оно складывается не только из чисто субъективного ощущения прекрасного, но и визуального ощущения надежности строения. Иначе говоря, будете ли вы считать здание красивым, если ваше внутреннее чувство говорит о его хрупкости? Человек желает видеть перед собой прочное, монументальное здание. То есть поведение этого здания предсказуемо - оно не обрушится, там безопасно. Это является одним из факторов, определяющим дизайн здания и выбор отделочных материалов. Предсказуемость затрагивает многие сферы жизни. Строительство, отношения людей и т.д., в том числе программирование.
Предсказуемость поведения тех или иных участков кода позволяет нам с уверенностью взять их в работу и без сомнений доверить новые вычисления. Иначе это будет порождать в нас тревогу, а ни не рухнет ли там ничего? А правильно ли мы используем тот или иной инструмент для решения конкретных задач? Да, конечно, лопатой можно забивать гвозди, но эффективно ли это? Лопата быстро сломается, а вот молотком работать и удобнее, и быстрее.
Давайте вспомним предыдущие посты: магические числа, идиома RAII, комментарии в коде, Ссылки vs Указатели, optional, как правильно запретить копирование - не об этой ли предсказуемости шла речь в данных постах? Мы там всегда пытаемся что-то гарантировать, что-то показать, что-то сделать явным и однозначным.
Написание предсказуемого кода — это козырь, который позволит вам уверенней принимать решения, быстрее решать проблемы и легче ориентироваться в коде коллег. Все это связано с ограниченностью человеческих способностей, которую надо уметь принимать и работать с ней.
Конечно, может показаться скучным делать что-то предсказуемое. Но, уверяю, весь азарт и веселье как раз и заключается в том, чтобы обеспечить эту предсказуемость 😉
#howitworks #fun
Этот пост я бы хотел посвятить теме предсказуемости в разработке программ. Это очень интересное свойство, корни которого заложены глубоко в человеке.
На одной из экскурсий по архитектуре моего города экскурсовод обратил внимание на восприятие человеком красоты архитектуры. Оно складывается не только из чисто субъективного ощущения прекрасного, но и визуального ощущения надежности строения. Иначе говоря, будете ли вы считать здание красивым, если ваше внутреннее чувство говорит о его хрупкости? Человек желает видеть перед собой прочное, монументальное здание. То есть поведение этого здания предсказуемо - оно не обрушится, там безопасно. Это является одним из факторов, определяющим дизайн здания и выбор отделочных материалов. Предсказуемость затрагивает многие сферы жизни. Строительство, отношения людей и т.д., в том числе программирование.
Предсказуемость поведения тех или иных участков кода позволяет нам с уверенностью взять их в работу и без сомнений доверить новые вычисления. Иначе это будет порождать в нас тревогу, а ни не рухнет ли там ничего? А правильно ли мы используем тот или иной инструмент для решения конкретных задач? Да, конечно, лопатой можно забивать гвозди, но эффективно ли это? Лопата быстро сломается, а вот молотком работать и удобнее, и быстрее.
Давайте вспомним предыдущие посты: магические числа, идиома RAII, комментарии в коде, Ссылки vs Указатели, optional, как правильно запретить копирование - не об этой ли предсказуемости шла речь в данных постах? Мы там всегда пытаемся что-то гарантировать, что-то показать, что-то сделать явным и однозначным.
Написание предсказуемого кода — это козырь, который позволит вам уверенней принимать решения, быстрее решать проблемы и легче ориентироваться в коде коллег. Все это связано с ограниченностью человеческих способностей, которую надо уметь принимать и работать с ней.
Конечно, может показаться скучным делать что-то предсказуемое. Но, уверяю, весь азарт и веселье как раз и заключается в том, чтобы обеспечить эту предсказуемость 😉
#howitworks #fun
{kind=link}
👍11🔥5❤3
CREATE TABLE IF NOT EXIST
Вроде бы SQL запрос с подобным началом выглядит довольно разумно: зачем создавать таблицу, когда она уже есть в базе. Однако же он таит в себе проблему. В многопоточном приложении этот запрос может приводить к состоянию гонки.
Короткая справка по race condition'у: это такое состояние программы, когда корректность выполнения куска кода зависит от таймингов или порядка выполнения операций в нем.
Давайте посмотрим, что происходит внутри базы данных, что может вызвать такие проблемы. Запрос «CREATE TABLE IF NOT EXISTS» проверяет, существует ли таблица в базе данных. Если это не так, таблица создается; в противном случае он пропускает этап создания. Однако при одновременном выполнении нескольких запросов может возникнуть состояние гонки из-за следующих шагов:
1️⃣ Проверка существования таблицы. Первый шаг — проверить, существует ли таблица в базе данных. Это включает в себя доступ к метаданным базы данных и поиск имени таблицы.
2️⃣ Создание таблицы: если таблица не существует, запрос переходит к ее созданию. Это включает в себя выделение ресурсов, определение схемы таблицы и обновление метаданных.
2️⃣ Атомарность. Основная проблема возникает, когда несколько запросов одновременно проверяют существование таблицы. Они могут увидеть, что таблицы не существует, и создать ее самостоятельно. Результатом является попытка создание нескольких одинаковых таблиц, что нарушает смысл условия «ЕСЛИ НЕ СУЩЕСТВУЕТ».
Последствия этой проблемы: ошибки там, где вы их не ожидаете. Нельзя в большинстве реляционных баз данных взять и просто создать 2 одинаковые таблицы. Вы получите ошибку. А самое приятное, что эта ошибка зависит от Бога Рандома, поэтому отловить ее, воспроизвести или пофиксить будет непросто.
В будущем расскажу, как предотвратить эти проблемы.
Stay cool.
#database #multitasking
Вроде бы SQL запрос с подобным началом выглядит довольно разумно: зачем создавать таблицу, когда она уже есть в базе. Однако же он таит в себе проблему. В многопоточном приложении этот запрос может приводить к состоянию гонки.
Короткая справка по race condition'у: это такое состояние программы, когда корректность выполнения куска кода зависит от таймингов или порядка выполнения операций в нем.
Давайте посмотрим, что происходит внутри базы данных, что может вызвать такие проблемы. Запрос «CREATE TABLE IF NOT EXISTS» проверяет, существует ли таблица в базе данных. Если это не так, таблица создается; в противном случае он пропускает этап создания. Однако при одновременном выполнении нескольких запросов может возникнуть состояние гонки из-за следующих шагов:
1️⃣ Проверка существования таблицы. Первый шаг — проверить, существует ли таблица в базе данных. Это включает в себя доступ к метаданным базы данных и поиск имени таблицы.
2️⃣ Создание таблицы: если таблица не существует, запрос переходит к ее созданию. Это включает в себя выделение ресурсов, определение схемы таблицы и обновление метаданных.
2️⃣ Атомарность. Основная проблема возникает, когда несколько запросов одновременно проверяют существование таблицы. Они могут увидеть, что таблицы не существует, и создать ее самостоятельно. Результатом является попытка создание нескольких одинаковых таблиц, что нарушает смысл условия «ЕСЛИ НЕ СУЩЕСТВУЕТ».
Последствия этой проблемы: ошибки там, где вы их не ожидаете. Нельзя в большинстве реляционных баз данных взять и просто создать 2 одинаковые таблицы. Вы получите ошибку. А самое приятное, что эта ошибка зависит от Бога Рандома, поэтому отловить ее, воспроизвести или пофиксить будет непросто.
В будущем расскажу, как предотвратить эти проблемы.
Stay cool.
#database #multitasking
{kind=link}
👍13❤2❤🔥1
Проверяем число на степень двойки
У меня всегда была страсть к решению разного рода задачек и меня всегда восхищало то, как более компетентные люди используют неочевидные способы решения таких задач. Это всегда подстегивает энтузиазм и желание изучать новое. Сегодняшняя тема однажды привела меня в шоковое состояние, когда я проверял своё решение.
Казалось бы. Очень простая задача. Узнать, является ли число степенью двойки. Решаем через цикл, пока число не равно единице, делим на два и если ни при одном делении нет остатка - число является степенью двойки. Если хоть один остаток от деления был, тогда не является.
Или сдвигаем число вправо побитово на один бит на каждой итерации и если он нулевой всегда, то возвращаем true.
Написали, запускаем тесты. Тесты проходят. Победа. Небольшая конечно, задача-то плевая. А потом ты заходишь в решения и видишь, что кто-то решил эту задачу за константную сложность. What. The. Fuck. ???
Чтобы самостоятельно решить задачу за константу, нужно глубоко шарить за системы счисления. Чтобы понять, как решать, глубоко шарить не нужно, там все просто. Попробуйте подумать пару минут, я подожду……….
Решили? Надеюсь у нас здесь сборник гениев и все решили. А для таких, как я, рассказываю.
Когда число является степенью основания системы счисления, оно представляется как единица с несколькими нулями, например, 1000 в двоичной - это 8, 10000 - это 16. Ну вы поняли. С десятичной же тоже самое. Причём количество нулей равно показателю степени числа.
Ещё вводные. Если мы вычтем единицу из нашего числа, то получим новое число, количество разрядов которого ровно на один меньше, и каждая цифра которого сменится с нуля на единицу. Например, 100 - 1 = 11, 1000 - 1 = 111, 10000 - 1 = 1111.
Теперь магия. Когда мы применим операцию логического И к исходному числу Х и к числу Х - 1, то мы получим ноль. Х & (Х - 1) = 0.
Вот так вот. Всего 3 простейшие операции помогут вам определить, является ли число степенью двойки.
Строгое доказательство данного утверждения опущу за ненадобностью, смельчаки в комментах могут попробовать его оформить.
А вы знаете какие-нибудь удивительные решения простых задачек? Оставьте ответ в комментах.
Stay optimized. Stay cool.
#algorithms #fun
У меня всегда была страсть к решению разного рода задачек и меня всегда восхищало то, как более компетентные люди используют неочевидные способы решения таких задач. Это всегда подстегивает энтузиазм и желание изучать новое. Сегодняшняя тема однажды привела меня в шоковое состояние, когда я проверял своё решение.
Казалось бы. Очень простая задача. Узнать, является ли число степенью двойки. Решаем через цикл, пока число не равно единице, делим на два и если ни при одном делении нет остатка - число является степенью двойки. Если хоть один остаток от деления был, тогда не является.
Или сдвигаем число вправо побитово на один бит на каждой итерации и если он нулевой всегда, то возвращаем true.
Написали, запускаем тесты. Тесты проходят. Победа. Небольшая конечно, задача-то плевая. А потом ты заходишь в решения и видишь, что кто-то решил эту задачу за константную сложность. What. The. Fuck. ???
Чтобы самостоятельно решить задачу за константу, нужно глубоко шарить за системы счисления. Чтобы понять, как решать, глубоко шарить не нужно, там все просто. Попробуйте подумать пару минут, я подожду……….
Решили? Надеюсь у нас здесь сборник гениев и все решили. А для таких, как я, рассказываю.
Когда число является степенью основания системы счисления, оно представляется как единица с несколькими нулями, например, 1000 в двоичной - это 8, 10000 - это 16. Ну вы поняли. С десятичной же тоже самое. Причём количество нулей равно показателю степени числа.
Ещё вводные. Если мы вычтем единицу из нашего числа, то получим новое число, количество разрядов которого ровно на один меньше, и каждая цифра которого сменится с нуля на единицу. Например, 100 - 1 = 11, 1000 - 1 = 111, 10000 - 1 = 1111.
Теперь магия. Когда мы применим операцию логического И к исходному числу Х и к числу Х - 1, то мы получим ноль. Х & (Х - 1) = 0.
Вот так вот. Всего 3 простейшие операции помогут вам определить, является ли число степенью двойки.
Строгое доказательство данного утверждения опущу за ненадобностью, смельчаки в комментах могут попробовать его оформить.
А вы знаете какие-нибудь удивительные решения простых задачек? Оставьте ответ в комментах.
Stay optimized. Stay cool.
#algorithms #fun
{kind=link}
👍21❤4🔥4
Реактивность
Этот пост я бы хотел посвятить понятию реактивности в программировании. Как и многие другие понятия, оно основано на устоявшихся процессах в природе и других областях человеческой жизни, например, в медицине.
«Реактивность – (от латинского reactia – противодействие) – свойство организма реагировать изменениями жизнедеятельности на воздействие различных факторов окружающей среды» - учебно-методическое пособие по медицине.
Реактивное программирование - парадигма, ориентированная на потоки данных и автоматическое распространение изменений от нижестоящих моделей к вышестоящим.
Рассмотрим пример:
1.
2.
3.
4.
В императивном программировании ожидается, что
В реактивном программировании ожидается, что значения выражений будут равны:
Лучше понять этот пример можно, если представить что в качестве значения каждой переменной используются не просто числа, а лямбда-функции: https://compiler-explorer.com/z/Ge589afdW
Давайте подумаем, какие преимущества дает данное свойство реактивности:
1. Удобное распространение изменений
Разработчику не нужно проверять изменения каждой переменной, т.к. в механизм изменений заложено предсказуемое поведение.
2. Высокая отзывчивость
Изменения распространяются сразу, как только было сделано изменение, а результат вычислений будет вычислен тогда, когда он понадобится (в отличие от каких-то механизмов пересчета изменений).
3. Масштабируемость
Достаточно изменить лишь какую-то часть алгоритма, чтобы добавить новую функциональность.
4. Удобное создание сложных алгоритмов обработки
Алгоритм обработки не требует полного пересоздания с нуля, а может усложняться там, где это удобнее всего сделать.
Конечно, использование функций, это не самый эффективный способ, но он наглядно демонстрирует идею реактивности. Это понимание мне понадобится, чтобы обосновать некоторые другие идеи, о которых я хочу рассказать в следующих постах.
#howitworks #fun
Этот пост я бы хотел посвятить понятию реактивности в программировании. Как и многие другие понятия, оно основано на устоявшихся процессах в природе и других областях человеческой жизни, например, в медицине.
«Реактивность – (от латинского reactia – противодействие) – свойство организма реагировать изменениями жизнедеятельности на воздействие различных факторов окружающей среды» - учебно-методическое пособие по медицине.
Реактивное программирование - парадигма, ориентированная на потоки данных и автоматическое распространение изменений от нижестоящих моделей к вышестоящим.
Рассмотрим пример:
1.
b = 3; c = 5;2.
a = b + c;3.
b = c;4.
c = 2;В императивном программировании ожидается, что
a = 8; b = 5; c = 2;, т.к. при вычислении результата каждой операции используется значение переменной на текущий момент исполнения.В реактивном программировании ожидается, что значения выражений будут равны:
a = 4; b = 2; c = 2;, т.е. изменения, примененные к нижестоящим моделям (в данном контексте, переменные b и c), автоматически распространят свои изменения на вышестоящие модели (переменные a и b). Получаются такие цепочки зависимостей c -> a и c -> b -> a. Лучше понять этот пример можно, если представить что в качестве значения каждой переменной используются не просто числа, а лямбда-функции: https://compiler-explorer.com/z/Ge589afdW
Давайте подумаем, какие преимущества дает данное свойство реактивности:
1. Удобное распространение изменений
Разработчику не нужно проверять изменения каждой переменной, т.к. в механизм изменений заложено предсказуемое поведение.
2. Высокая отзывчивость
Изменения распространяются сразу, как только было сделано изменение, а результат вычислений будет вычислен тогда, когда он понадобится (в отличие от каких-то механизмов пересчета изменений).
3. Масштабируемость
Достаточно изменить лишь какую-то часть алгоритма, чтобы добавить новую функциональность.
4. Удобное создание сложных алгоритмов обработки
Алгоритм обработки не требует полного пересоздания с нуля, а может усложняться там, где это удобнее всего сделать.
Конечно, использование функций, это не самый эффективный способ, но он наглядно демонстрирует идею реактивности. Это понимание мне понадобится, чтобы обосновать некоторые другие идеи, о которых я хочу рассказать в следующих постах.
#howitworks #fun
{kind=link}
🤔10❤4😨2
std::transform
Последний пост из серии про 3 самых нужных алгоритма STL. Предыдущая часть тут.
Часто при работе с текстом или с сырыми числовыми данными нам нужно каким-то образом предобработать все это дело. Ну например, привести все буквы к нижнему регистру. Или поменять все небуквенные символы в пробелы. Или занулить все отрицательные числа в массиве. Эти задачи больше приближены к обработке пользовательского ввода или файлов с данными. Поэтому, хоть и не очень часто, но тут и там встречаются в бэкэнд приложениях. И такую простую предобработку объектов может на себя взять алгоритм std::transform.
Не такой уж он из себя какой-то особенный алгоритм. Просто проходится по одному ренджу, применяет к элементам операцию и записывает в другую последовательность. По факту, просто проход по итераторам, ничего супералгоритмического. Я могу и сам запросто такое написать, не опасаясь долгой отладки. Однако у std::transform полно преимуществ, по сравнению с таким подходом.
1️⃣ Это стандартный именованный алгоритм. Все плюсовые программисты знают, что это такое и будут быстрее понимать ваш код.
2️⃣ Стандартные алгоритмы обычно написаны оптимально и работают быстрее, чем самописный код.
3️⃣ Универсальный обобщенный интерфейс. Я могу записывать обработанные данные в любой другой контейнер или в тот же самый. Главное, чтобы типы контейнеров и возвращаемого значения унарного оператора метчились.
Почему этот алгоритм достоин оказаться в тройке полезнейших? Я немного наврал во введении о сфере его применения. Дело в том, что бэкэнд-приложения построены вокруг data flow. То есть от пользователей получают какие-то данные и дальше эти данные проходят длинный цикл обработки, сохранения, кэширования и прочих безобразий. Данные на протяжении своего цикла жизни претерпевают различные преобразования. В одном случае данные представлены в атомарном семантическом виде: запрос, сообщение, геопозиция и так далее. И преобразовываются они атомарно. А в других случаях мы имеем семантическую группу данных для обработки: буквы в тексте, несколько текстов, пиксели для изображения и тд. И эти данные надо как-то трансформировать в другие данные по ходу того самого flow. Вот именно для такого широкого контекста задач хорошо применим std::transform. Просто для поддержки этого утверждения приведу несколько примеров конкретных задач. Нормализация численного массива, применение фильтров к изображениям, манипуляции со строками, манипуляции буквами в строках, шифрование набора текстов, хеширование набора объектов, преобразование даты и времени между разными часовыми поясами, преобразование географических координат, бесконечное множество математических преобразований. Вроде увесисто и убедительно получилось.
На этом завершаю этот цикл постов. Пользуйтесь стандартной библиотекой с умом и будет вам счастье)
Stay completed. Stay cool.
#STL #algorithms
Последний пост из серии про 3 самых нужных алгоритма STL. Предыдущая часть тут.
Часто при работе с текстом или с сырыми числовыми данными нам нужно каким-то образом предобработать все это дело. Ну например, привести все буквы к нижнему регистру. Или поменять все небуквенные символы в пробелы. Или занулить все отрицательные числа в массиве. Эти задачи больше приближены к обработке пользовательского ввода или файлов с данными. Поэтому, хоть и не очень часто, но тут и там встречаются в бэкэнд приложениях. И такую простую предобработку объектов может на себя взять алгоритм std::transform.
Не такой уж он из себя какой-то особенный алгоритм. Просто проходится по одному ренджу, применяет к элементам операцию и записывает в другую последовательность. По факту, просто проход по итераторам, ничего супералгоритмического. Я могу и сам запросто такое написать, не опасаясь долгой отладки. Однако у std::transform полно преимуществ, по сравнению с таким подходом.
1️⃣ Это стандартный именованный алгоритм. Все плюсовые программисты знают, что это такое и будут быстрее понимать ваш код.
2️⃣ Стандартные алгоритмы обычно написаны оптимально и работают быстрее, чем самописный код.
3️⃣ Универсальный обобщенный интерфейс. Я могу записывать обработанные данные в любой другой контейнер или в тот же самый. Главное, чтобы типы контейнеров и возвращаемого значения унарного оператора метчились.
Почему этот алгоритм достоин оказаться в тройке полезнейших? Я немного наврал во введении о сфере его применения. Дело в том, что бэкэнд-приложения построены вокруг data flow. То есть от пользователей получают какие-то данные и дальше эти данные проходят длинный цикл обработки, сохранения, кэширования и прочих безобразий. Данные на протяжении своего цикла жизни претерпевают различные преобразования. В одном случае данные представлены в атомарном семантическом виде: запрос, сообщение, геопозиция и так далее. И преобразовываются они атомарно. А в других случаях мы имеем семантическую группу данных для обработки: буквы в тексте, несколько текстов, пиксели для изображения и тд. И эти данные надо как-то трансформировать в другие данные по ходу того самого flow. Вот именно для такого широкого контекста задач хорошо применим std::transform. Просто для поддержки этого утверждения приведу несколько примеров конкретных задач. Нормализация численного массива, применение фильтров к изображениям, манипуляции со строками, манипуляции буквами в строках, шифрование набора текстов, хеширование набора объектов, преобразование даты и времени между разными часовыми поясами, преобразование географических координат, бесконечное множество математических преобразований. Вроде увесисто и убедительно получилось.
На этом завершаю этот цикл постов. Пользуйтесь стандартной библиотекой с умом и будет вам счастье)
Stay completed. Stay cool.
#STL #algorithms
{kind=link}
❤10🥰2👍1
Как узнать размер блока, выделенного malloc?
Маллок в современном С++ не играет такую важную роль в разработке, как это есть и было в разработке на чистом С. Однако мы до сих пор встречаемся с легаси кодом(и вряд ли когда-нибудь перестанем это делать) и поэтому нам нужно знать некоторые тонкости и особенности языка С.
Маллок и еще несколько функций всегда используются в паре с free() как комбинация выделения и освобождения памяти. Но задумывались ли вы, почему в маллок мы передаем размер массива, а во free - нет? Что делать, если я забыл, сколько я памяти выделил и мне нужно это узнать?
Дело в том, что это знание естественно хранится, просто ответственность за хранение не перекладывается на пользователя. Стандартный аллокатор выделяет на самом деле немного больше памяти, чем просите вы. Дополнительная память выделятся под внутренние структуры аллокатора и, ожидаемо, размер выделенной памяти. Напоминаю, что это все очень сильно привязано к реальной реализации стандартной библиотеки С, поэтому сказать нечто большее без привязки к реальной системе и коду нельзя.
Поэтому, зная указатель на выделенный блок, аллокатор сам знает, как ему найти реальное начало выделенного блока и реальное количество выделенных байт. Значит для освобождения памяти пользователю не нужно знать размер блока.
Что насчет того, может ли пользователь узнать размер выделенной памяти. И да, и нет. Скорее нет, чем да. Библиотека Linux систем предоставляет такую функцию, как malloc_usable_size, которая возвращает длину реально выделенного блока памяти. Это значит, что вы не получите то количество байт, которое вы запросили. Вам вернется несколько большее число. И это число определяется только имплементацией. Никто заранее в точности вам не скажет верное число.
Вряд ли вы когда-нибудь забывали размер выделенного блока, поэтому тоже вряд ли, что в продакшен коде вы будете это использовать(учитывая, что решение неточное и непереносимое). Но, надеюсь, вы немного больше узнали о стандартном аллокаторе.
Stay aware. Stay cool.
#cppcore #memory #howitworks #hardcore
Маллок в современном С++ не играет такую важную роль в разработке, как это есть и было в разработке на чистом С. Однако мы до сих пор встречаемся с легаси кодом(и вряд ли когда-нибудь перестанем это делать) и поэтому нам нужно знать некоторые тонкости и особенности языка С.
Маллок и еще несколько функций всегда используются в паре с free() как комбинация выделения и освобождения памяти. Но задумывались ли вы, почему в маллок мы передаем размер массива, а во free - нет? Что делать, если я забыл, сколько я памяти выделил и мне нужно это узнать?
Дело в том, что это знание естественно хранится, просто ответственность за хранение не перекладывается на пользователя. Стандартный аллокатор выделяет на самом деле немного больше памяти, чем просите вы. Дополнительная память выделятся под внутренние структуры аллокатора и, ожидаемо, размер выделенной памяти. Напоминаю, что это все очень сильно привязано к реальной реализации стандартной библиотеки С, поэтому сказать нечто большее без привязки к реальной системе и коду нельзя.
Поэтому, зная указатель на выделенный блок, аллокатор сам знает, как ему найти реальное начало выделенного блока и реальное количество выделенных байт. Значит для освобождения памяти пользователю не нужно знать размер блока.
Что насчет того, может ли пользователь узнать размер выделенной памяти. И да, и нет. Скорее нет, чем да. Библиотека Linux систем предоставляет такую функцию, как malloc_usable_size, которая возвращает длину реально выделенного блока памяти. Это значит, что вы не получите то количество байт, которое вы запросили. Вам вернется несколько большее число. И это число определяется только имплементацией. Никто заранее в точности вам не скажет верное число.
Вряд ли вы когда-нибудь забывали размер выделенного блока, поэтому тоже вряд ли, что в продакшен коде вы будете это использовать(учитывая, что решение неточное и непереносимое). Но, надеюсь, вы немного больше узнали о стандартном аллокаторе.
Stay aware. Stay cool.
#cppcore #memory #howitworks #hardcore
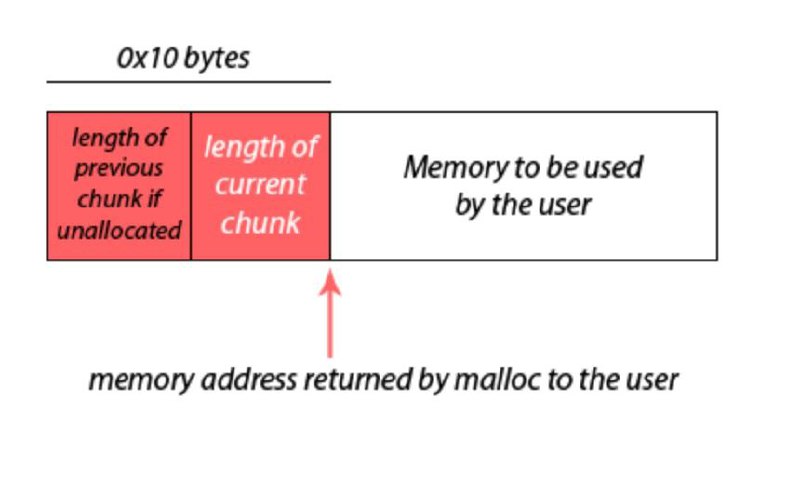{kind=link}
❤13🔥2❤🔥1