
Immudb – самая быстрая в мире неизменная база данных, построенная на модели нулевого доверия
Immudb - это база данных со встроенной криптографической проверкой. Она отслеживает изменения в конфиденциальных данных, и целостность истории будет защищена клиентами без необходимости доверять самой базе. Она может работать как хранилище ключей и значений, так и/или как реляционная база данных (SQL).
#GitHub | #SQL #Data
@data_analysis_ml
Immudb - это база данных со встроенной криптографической проверкой. Она отслеживает изменения в конфиденциальных данных, и целостность истории будет защищена клиентами без необходимости доверять самой базе. Она может работать как хранилище ключей и значений, так и/или как реляционная база данных (SQL).
#GitHub | #SQL #Data
@data_analysis_ml
👍19
5️⃣ преимуществ low-code подхода к аналитике данных.
Возможность мало кодировать, а больше использовать готовые компоненты и визуальное проектирование позволяет решать задачи анализа с меньшими затратами сил разработчиков. В статье расскажем об основных преимуществах подобного подхода.
Потребность в инструментах, минимизирующих программирование, существовала давно. Цель любой организации — быстро и с минимальными затратами решить задачу, при этом учесть особенности бизнеса компании. Проблема в том, что сложно удовлетворить этим критериям одновременно. Можно либо воспользоваться готовыми решениями, позволяющими получить результат быстро, но без учета нюансов бизнеса и с потерей гибкости. Либо разработать уникальное решение под себя, что требует много времени и дорогостоящих специалистов.
Low-code — это метод разработки, позволяющий проектировать логику быстро, с небольшими затратами на внедрение и поддержку. Low-code сводит к минимуму использование программного кода, заменяя его визуальными средствами конструирования.
Мы выделили 5 основных преимуществ low-code подхода при работе над аналитическими проектами.
Читать дальше
@data_analysis_ml
Возможность мало кодировать, а больше использовать готовые компоненты и визуальное проектирование позволяет решать задачи анализа с меньшими затратами сил разработчиков. В статье расскажем об основных преимуществах подобного подхода.
Потребность в инструментах, минимизирующих программирование, существовала давно. Цель любой организации — быстро и с минимальными затратами решить задачу, при этом учесть особенности бизнеса компании. Проблема в том, что сложно удовлетворить этим критериям одновременно. Можно либо воспользоваться готовыми решениями, позволяющими получить результат быстро, но без учета нюансов бизнеса и с потерей гибкости. Либо разработать уникальное решение под себя, что требует много времени и дорогостоящих специалистов.
Low-code — это метод разработки, позволяющий проектировать логику быстро, с небольшими затратами на внедрение и поддержку. Low-code сводит к минимуму использование программного кода, заменяя его визуальными средствами конструирования.
Мы выделили 5 основных преимуществ low-code подхода при работе над аналитическими проектами.
Читать дальше
@data_analysis_ml
{kind=link}
👍13
This media is not supported in your browser
VIEW IN TELEGRAM
Pulse – инструмент, который превращает пиксилезированные фотографии лица в картинки с высоким качеством
Получив входное изображение с низким разрешением, PULSE ищет в выходных данных генеративной модели (StyleGAN) изображения с высоким разрешением, которые перцептивно схожи с входной картинкой | #Python #AI #Interesting
@data_analysis_ml
Получив входное изображение с низким разрешением, PULSE ищет в выходных данных генеративной модели (StyleGAN) изображения с высоким разрешением, которые перцептивно схожи с входной картинкой | #Python #AI #Interesting
@data_analysis_ml
👍15😁6
💡10 фич для ускорения анализа данных в Python
Советы и рекомендации, особенно в программировании, могут быть очень полезны. Маленький шоткат, аддон или хак может сэкономить кучу времени и серьёзно увеличить производительность. Я собрала свои самые любимые и сделала из них эту статью. Какие-то из советов ниже уже известны многим, а какие-то появились совсем недавно. Так или иначе, я уверена, они точно не будут лишними, когда вы в очередной раз приступите к проекту по анализу данных.
Читать дальше
@data_analysis_ml
Советы и рекомендации, особенно в программировании, могут быть очень полезны. Маленький шоткат, аддон или хак может сэкономить кучу времени и серьёзно увеличить производительность. Я собрала свои самые любимые и сделала из них эту статью. Какие-то из советов ниже уже известны многим, а какие-то появились совсем недавно. Так или иначе, я уверена, они точно не будут лишними, когда вы в очередной раз приступите к проекту по анализу данных.
Читать дальше
@data_analysis_ml
👍49🔥5
➕ SQL-запросы, о которых должен знать каждый дата-инженер. Гайд по по работе с SQL в Data Science.
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
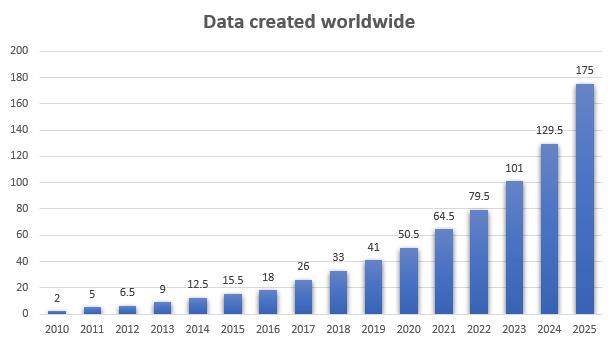
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтов
Есть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Читать дальше
@data_analysis_ml
{kind=link}
👍28😢1
Python FastAPI: OpenAPI, CRUD, PostgreSQL в Docker и внедрение зависимостей
https://nuancesprog.ru/p/14818/
https://nuancesprog.ru/p/14818/
👍9👎1
📲 Собеседование на позицию Data Scientist: 46 типичных вопросов.
Проверка знаний на собеседованиях — обычная практика. И мы сейчас не о глупых «Где вы видите себя через 5 лет?», а о нормальных вопросах по специальности. Вопросы будут смешаны по темам, но все они относятся к машинному обучению и Data Science. Попробуйте сначала ответить на каждый вопрос самостоятельно!
Часть 1
Часть 2
@data_analysis_ml
Проверка знаний на собеседованиях — обычная практика. И мы сейчас не о глупых «Где вы видите себя через 5 лет?», а о нормальных вопросах по специальности. Вопросы будут смешаны по темам, но все они относятся к машинному обучению и Data Science. Попробуйте сначала ответить на каждый вопрос самостоятельно!
Часть 1
Часть 2
@data_analysis_ml
👍39
🎓 Опенсорсные массивы данных для Computer Vision
Computer Vision (CV) — одна из самых увлекательных тем в сфере искусственного интеллекта (Artificial Intelligence, AI) и машинного обучения (Machine Learning, ML). Это важная часть многих современных конвейеров AI/ML, преобразующая практически все отрасли и позволяющая компаниям осуществлять революцию в работе машин и бизнес-систем.
В науке CV многие десятилетия была уважаемой областью computer science, и за многие годы в этой сфере было проведено множество исследований по её совершенствованию. Однако революцию в ней совершило недавно начавшееся применение глубоких нейросетей, ставшее стимулом ускорения её развития.
Читать дальше
@data_analysis_ml
Computer Vision (CV) — одна из самых увлекательных тем в сфере искусственного интеллекта (Artificial Intelligence, AI) и машинного обучения (Machine Learning, ML). Это важная часть многих современных конвейеров AI/ML, преобразующая практически все отрасли и позволяющая компаниям осуществлять революцию в работе машин и бизнес-систем.
В науке CV многие десятилетия была уважаемой областью computer science, и за многие годы в этой сфере было проведено множество исследований по её совершенствованию. Однако революцию в ней совершило недавно начавшееся применение глубоких нейросетей, ставшее стимулом ускорения её развития.
Читать дальше
@data_analysis_ml
👍7
♻️ Мета выпустила переводчик на 200 языков.
В открытом доступе теперь лежит модель No language left behind (Ни один язык не останется за бортом), которая переводит с 200+ различных языков.
Модель уже применняется для улучшения переводов на Facebook, Instagram и Wikipedia.
Код
Статья
Demo
Blog
#AI #ML #NLP
@data_analysis_ml
В открытом доступе теперь лежит модель No language left behind (Ни один язык не останется за бортом), которая переводит с 200+ различных языков.
Модель уже применняется для улучшения переводов на Facebook, Instagram и Wikipedia.
Код
Статья
Demo
Blog
#AI #ML #NLP
@data_analysis_ml
👍15🔥7
🔍 Как обнаружить выбросы в проекте по исследованию данных
Выброс — это данные, которые имеют слишком высокое или слишком низкое значение по отношению к другим исследуемым данным. Конечно, в наборе данных может быть несколько выбросов, поэтому приходится неоднократно исключать их из набора данных. В противном случае выбросы способны вызывать статистические проблемы в анализе данных.
Но каковы критерии исключения выбросов? Чтобы ответить на этот вопрос, рассмотрим три метода обнаружения выбросов.
Читать дальше
@data_analysis_ml
Выброс — это данные, которые имеют слишком высокое или слишком низкое значение по отношению к другим исследуемым данным. Конечно, в наборе данных может быть несколько выбросов, поэтому приходится неоднократно исключать их из набора данных. В противном случае выбросы способны вызывать статистические проблемы в анализе данных.
Но каковы критерии исключения выбросов? Чтобы ответить на этот вопрос, рассмотрим три метода обнаружения выбросов.
Читать дальше
@data_analysis_ml
{kind=link}
❤16👍10🔥1
Копируем голос за 5 секунд, для генерации речи в реальном времени
⚙️ GitHub/Инструкция
📹 Видео
@data_analysis_ml
⚙️ GitHub/Инструкция
📹 Видео
@data_analysis_ml
👍8
📎 Крутые наборы данных для машинного обучения
Более 50 открытых наборов для ваших исследований
Хорошее исследование в машинном обучении начинается с подходящего набора данных. Нет необходимости тратить целый вечер на создание собственного набора в MySQL или, что еще хуже, в Excel. В принципе, все что угодно — от статистики COVID-19 до заклинаний Гарри Поттера — можно найти в виде базы данных.
Читать дальше
@data_analysis_ml
Более 50 открытых наборов для ваших исследований
Хорошее исследование в машинном обучении начинается с подходящего набора данных. Нет необходимости тратить целый вечер на создание собственного набора в MySQL или, что еще хуже, в Excel. В принципе, все что угодно — от статистики COVID-19 до заклинаний Гарри Поттера — можно найти в виде базы данных.
Читать дальше
@data_analysis_ml
👍20🔥10🥰1🤔1
🎓 Stanford CS25 новый бесплатный курс по Трансформерам
https://web.stanford.edu/class/cs25/
https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM
@data_analysis_ml
https://web.stanford.edu/class/cs25/
https://www.youtube.com/playlist?list=PLoROMvodv4rNiJRchCzutFw5ItR_Z27CM
@data_analysis_ml
👍7
🦾 Как создать свой датасет с Киркоровым и Фейсом на Яндекс.Толоке
Где найти данные?
1. Смотрим публичные датасеты, такие как ImageNet, COCO, openimages.
2. Если нужных размеченных данных в популярных публичных датасетах нет, то гуглим, открываем на arxiv.org статьи по этим темам в надежде, что где-нибудь там будет ссылка на нужный нам датасет.
3. Если первые два пункта провалились, значит нужного датасета нет, и его надо создать!
Очевидно, что никто раньше не занимался задачей классификации Киркорова и Фейса. Поэтому придется самим создать такой датасет.
Читать дальше
@data_analysis_ml
Где найти данные?
1. Смотрим публичные датасеты, такие как ImageNet, COCO, openimages.
2. Если нужных размеченных данных в популярных публичных датасетах нет, то гуглим, открываем на arxiv.org статьи по этим темам в надежде, что где-нибудь там будет ссылка на нужный нам датасет.
3. Если первые два пункта провалились, значит нужного датасета нет, и его надо создать!
Очевидно, что никто раньше не занимался задачей классификации Киркорова и Фейса. Поэтому придется самим создать такой датасет.
Читать дальше
@data_analysis_ml
🔥10👍3💩3❤1😱1
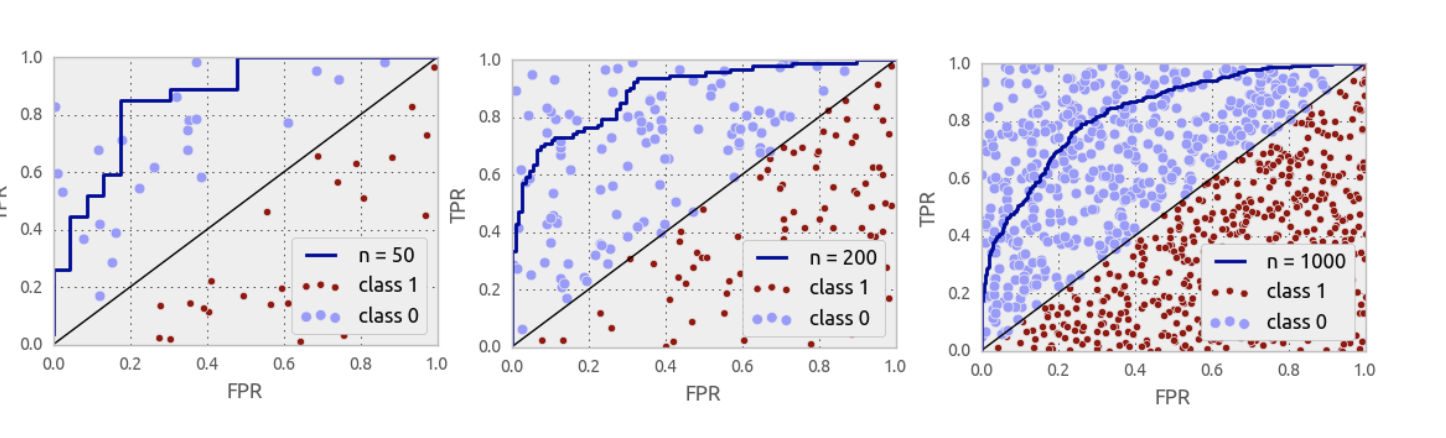
📉 ROC и AUC простыми словами.
Площадь под ROC-кривой – один из самых популярных функционалов качества в задачах бинарной классификации. На мой взгляд, простых и полных источников информации «что же это такое» нет. Как правило, объяснение начинают с введения разных терминов (FPR, TPR), которые нормальный человек тут же забывает. Также нет разборов каких-то конкретных задач по AUC ROC. В этом посте описано, как я объясняю эту тему студентам и своим сотрудникам…
Допустим, решается задача классификации с двумя классами {0, 1}. Алгоритм выдаёт некоторую оценку (может, но не обязательно, вероятность) принадлежности объекта к классу 1. Можно считать, что оценка принадлежит отрезку [0, 1].
Часто результат работы алгоритма на фиксированной тестовой выборке визуализируют с помощью ROC-кривой (ROC = receiver operating characteristic, иногда говорят «кривая ошибок»), а качество оценивают как площадь под этой кривой – AUC (AUC = area under the curve). Покажем на конкретном примере, как строится кривая.
Читать Дальше
@data_analysis_ml
Площадь под ROC-кривой – один из самых популярных функционалов качества в задачах бинарной классификации. На мой взгляд, простых и полных источников информации «что же это такое» нет. Как правило, объяснение начинают с введения разных терминов (FPR, TPR), которые нормальный человек тут же забывает. Также нет разборов каких-то конкретных задач по AUC ROC. В этом посте описано, как я объясняю эту тему студентам и своим сотрудникам…
Допустим, решается задача классификации с двумя классами {0, 1}. Алгоритм выдаёт некоторую оценку (может, но не обязательно, вероятность) принадлежности объекта к классу 1. Можно считать, что оценка принадлежит отрезку [0, 1].
Часто результат работы алгоритма на фиксированной тестовой выборке визуализируют с помощью ROC-кривой (ROC = receiver operating characteristic, иногда говорят «кривая ошибок»), а качество оценивают как площадь под этой кривой – AUC (AUC = area under the curve). Покажем на конкретном примере, как строится кривая.
Читать Дальше
@data_analysis_ml
{kind=link}
👍17🔥9👎2
Кручу, верчу логи при помощи SQL — облегчаем анализ данных
Бывает такая ситуация, что необходимо проанализировать большой объём данных системы логирования событий на предмет аномалий или инцидентов. Просматривать такой массив данных трудно и нецелесообразно. Для этих целей можно обратиться к специализированному программному обеспечению, но нужно знать к какому. Не всегда есть время на изучение. И хорошо, если под конкретные задачи на примете есть несколько вариантов. А если их нет, тогда как быть?
Выход есть всегда, было бы желание. Поговорим о том, как можно довольно быстро загрузить некий массив таких данных куда-то и заняться его анализом.
Читать дальше
@data_analysis_ml
Бывает такая ситуация, что необходимо проанализировать большой объём данных системы логирования событий на предмет аномалий или инцидентов. Просматривать такой массив данных трудно и нецелесообразно. Для этих целей можно обратиться к специализированному программному обеспечению, но нужно знать к какому. Не всегда есть время на изучение. И хорошо, если под конкретные задачи на примете есть несколько вариантов. А если их нет, тогда как быть?
Выход есть всегда, было бы желание. Поговорим о том, как можно довольно быстро загрузить некий массив таких данных куда-то и заняться его анализом.
Читать дальше
@data_analysis_ml
👍12❤1🔥1
Needl – генератор случайного интернет-трафика
Позволяет скрыть ваш истинный трафик, что, по сути, делает ваши данные «иглой в стоге сена» и, следовательно, их труднее найти.
Цель проекта состоит в том, чтобы вашему интернет-провайдеру, правительству и т. д. было сложнее отслеживать вашу историю просмотров и привычки.
#GitHub | #Python #Privacy
@data_analysis_ml
Позволяет скрыть ваш истинный трафик, что, по сути, делает ваши данные «иглой в стоге сена» и, следовательно, их труднее найти.
Цель проекта состоит в том, чтобы вашему интернет-провайдеру, правительству и т. д. было сложнее отслеживать вашу историю просмотров и привычки.
#GitHub | #Python #Privacy
@data_analysis_ml
🔥16💩7👍2
📊 В Data Science не нужна математика (Почти)
Ребята с «вышкой» всё время умничают, что в Data Science нужна «математика», но стоит копнуть глубже, оказывается, что это не математика, а вышмат.
В реальной повседневной работе Data Scientist'а я каждый день использую знания математики. Притом очень часто это далеко не «вышмат». Никакие интегралы не считаю, детерминанты матриц не ищу, а нужные хитрые формулы и алгоритмы мне оперативнее просто загуглить.
Решил накидать чек-лист из простых математических приёмов, без понимания которых — тебе точно будет сложно в DS. Если ты только начинаешь карьеру в DS, то тебе будет особенно полезно. Мощь вышмата не принижаю, но для старта всё сильно проще, чем кажется. Важно прочитать до конца!
Читать дальше
@data_analysis_ml
Ребята с «вышкой» всё время умничают, что в Data Science нужна «математика», но стоит копнуть глубже, оказывается, что это не математика, а вышмат.
В реальной повседневной работе Data Scientist'а я каждый день использую знания математики. Притом очень часто это далеко не «вышмат». Никакие интегралы не считаю, детерминанты матриц не ищу, а нужные хитрые формулы и алгоритмы мне оперативнее просто загуглить.
Решил накидать чек-лист из простых математических приёмов, без понимания которых — тебе точно будет сложно в DS. Если ты только начинаешь карьеру в DS, то тебе будет особенно полезно. Мощь вышмата не принижаю, но для старта всё сильно проще, чем кажется. Важно прочитать до конца!
Читать дальше
@data_analysis_ml
🔥29👍11😁4
♠️ Продвинутый покерный ИИ был обучен за 20 часов
Конечно когда появляется новая технология, кто-то хочет заработать на ней денег с минимальным вовлечением в процесс. Поэтому неудивительно, что появляются покер-боты с искусственным интеллектом. Покер с точки зрения ИИ является задачей с неполной информацией в отличие, например, от шахмат, поэтому исследователю подобное решать интереснее (но о своих доходах с этого бота они не отчитались, зато статья есть). Бот реализован на решающих деревьях.У ИИ есть большое преимущество перед людьми-игроками — лучший покер-фейс.
Смотреть
Сатья
@data_analysis_ml
Конечно когда появляется новая технология, кто-то хочет заработать на ней денег с минимальным вовлечением в процесс. Поэтому неудивительно, что появляются покер-боты с искусственным интеллектом. Покер с точки зрения ИИ является задачей с неполной информацией в отличие, например, от шахмат, поэтому исследователю подобное решать интереснее (но о своих доходах с этого бота они не отчитались, зато статья есть). Бот реализован на решающих деревьях.У ИИ есть большое преимущество перед людьми-игроками — лучший покер-фейс.
Смотреть
Сатья
@data_analysis_ml
YouTube
This Superhuman Poker AI Was Trained in 20 Hours!
❤️ Check out Weights & Biases here and sign up for a free demo:
https://www.wandb.com/papers
Weights & Biases blog post with the 1 line of code visualization: https://www.wandb.com/articles/visualize-keras-models-with-one-line-of-code
📝 The paper "Superhuman…
https://www.wandb.com/papers
Weights & Biases blog post with the 1 line of code visualization: https://www.wandb.com/articles/visualize-keras-models-with-one-line-of-code
📝 The paper "Superhuman…
👍7