
☠ 9 способов защититься от утечки данныхныхНачнем с определения. Нарушение данных — это нарушение безопасности, при котором конфиденциальные, защищенные или конфиденциальные данные копируются, передаются, просматриваются, крадутся или используются лицом, не уполномоченным на это. Здесь все довольно понятно, а вот кто и как давайте разберем.
Существует много разных факторов утечки персональных данных. Основные из них:
от безалаберности сотрудников/разработчиков: открытые БД, открытые порты и т.п.;
слив данных самими сотрудниками;
дыры безопасности сайтов.
Давайте чуть более подробно расскажем про каждый пункт.
К нам приходил запрос от крупной сети АЗС, у которых злоумышленники воровали бонусные баллы клиентов. Для того чтобы понять в чем дело компания предоставила нам исходный код для анализа. Решение разрабатывала одна из топовых Российских IT команд, код был качественным, но без самой базовой проработки безопасности.
Читать дальше
@data_analysis_ml
👍9👎1
Visual Genome: датасет размеченных изображений
https://neurohive.io/ru/datasety/visual-genome-dataset-razmechennyh-izobrazhenij/
@data_analysis_ml
https://neurohive.io/ru/datasety/visual-genome-dataset-razmechennyh-izobrazhenij/
@data_analysis_ml
👍4🤮3
🔎 Обзор методологий, принципов и концепций разных типов хранилищ данных
Data Warehouse Design
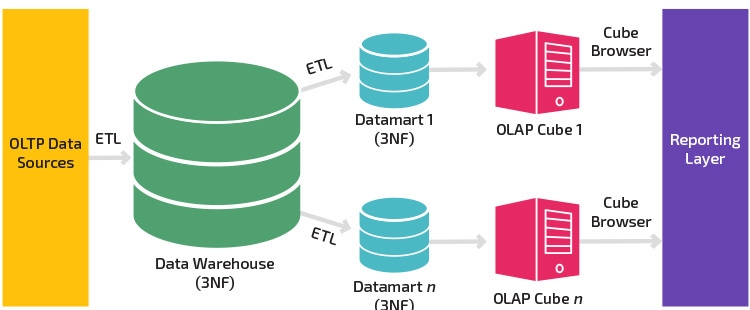
Подход Kimball
Модель данных Kimball — это восходящий подход к проектированию архитектуры хранилища данных (DWH или DW), в котором витрины данных сначала формируются на основе бизнес-требований.
Данные из источников данных с помощью ETL извлекаются и загружаются в промежуточную область сервера реляционной базы данных.
После того, как данные загружены в промежуточную область хранилища данных, следующий этап включает загрузку данных в многомерную модель хранилища данных, денормализованную по своей природе (схема звезда).
Эта модель разделяется на таблицу фактов, которая представляет собой числовые данные транзакций, и таблицы измерений, которые являются справочной информацией, которая является контекстом для данных в таблице фактов.
Читать дальше
@data_analysis_ml
Data Warehouse Design
Подход Kimball
Модель данных Kimball — это восходящий подход к проектированию архитектуры хранилища данных (DWH или DW), в котором витрины данных сначала формируются на основе бизнес-требований.
Данные из источников данных с помощью ETL извлекаются и загружаются в промежуточную область сервера реляционной базы данных.
После того, как данные загружены в промежуточную область хранилища данных, следующий этап включает загрузку данных в многомерную модель хранилища данных, денормализованную по своей природе (схема звезда).
Эта модель разделяется на таблицу фактов, которая представляет собой числовые данные транзакций, и таблицы измерений, которые являются справочной информацией, которая является контекстом для данных в таблице фактов.
Читать дальше
@data_analysis_ml
{kind=link}
👍13🔥4
This media is not supported in your browser
VIEW IN TELEGRAM
🌍 Создание приложения Flask на Python для визуализации мест путешествий
В данной статье мы покажем, как создавать пользовательскую карту, на которую можно прикрепить фотографии достопримечательностей, посещенных во время отпуска. Помимо этого, у вас будет возможность добавлять текст для более полного описания впечатлений о поездках.
В конце вы узнаете, как развернуть приложение на Heroku, чтобы друзья тоже смогли увидеть ваше творение.
Читать дальше
@data_analysis_ml
В данной статье мы покажем, как создавать пользовательскую карту, на которую можно прикрепить фотографии достопримечательностей, посещенных во время отпуска. Помимо этого, у вас будет возможность добавлять текст для более полного описания впечатлений о поездках.
В конце вы узнаете, как развернуть приложение на Heroku, чтобы друзья тоже смогли увидеть ваше творение.
Читать дальше
@data_analysis_ml
👍17
FAST-VQA: эффективная сквозная оценка качества видео с выборкой фрагментов
Github: https://github.com/timothyhtimothy/fast-vqa
Paper: https://arxiv.org/abs/2207.02595v1
Dataset: https://paperswithcode.com/dataset/kinetics
@data_analysis_ml
Github: https://github.com/timothyhtimothy/fast-vqa
Paper: https://arxiv.org/abs/2207.02595v1
Dataset: https://paperswithcode.com/dataset/kinetics
@data_analysis_ml
👍7👎3
🌠 Что такое Apache Superset? Установка Docker. Примеры дашбордов
Apache Superset — Open-Source инструмент для визуализации данных, входящий в портфолио продуктов Apache Foundation. Зародился Apache Superset в компании Airbnb, там же где появился Airflow. Эта система является очень популярной и хорошо развивается за счет привлечения новых контрибьютеров.
Количество комитов авторов на Github неуклонно растет.
В настоящее время Superset широко используется во многих компаниях по всему миру (полный перечень компаний, использующих Apache Superset). Например, Superset запускается в производственной среде Airbnb внутри Kubernetes и ежедневно обслуживает более 600 активных пользователей, просматривающих более 100 000 диаграмм в день.
Также Apache Superset приобретает популярность в России, в том числе после ухода западных вендоров.
Ознакомиться с полным функционалом и настройками Superset можно в официальной документации https://superset.apache.org/docs/intro.
Читать дальше
@data_analysis_ml
Apache Superset — Open-Source инструмент для визуализации данных, входящий в портфолио продуктов Apache Foundation. Зародился Apache Superset в компании Airbnb, там же где появился Airflow. Эта система является очень популярной и хорошо развивается за счет привлечения новых контрибьютеров.
Количество комитов авторов на Github неуклонно растет.
В настоящее время Superset широко используется во многих компаниях по всему миру (полный перечень компаний, использующих Apache Superset). Например, Superset запускается в производственной среде Airbnb внутри Kubernetes и ежедневно обслуживает более 600 активных пользователей, просматривающих более 100 000 диаграмм в день.
Также Apache Superset приобретает популярность в России, в том числе после ухода западных вендоров.
Ознакомиться с полным функционалом и настройками Superset можно в официальной документации https://superset.apache.org/docs/intro.
Читать дальше
@data_analysis_ml
👍20❤2🔥2👎1
Делимся отличной новостью: Минцифры внесло Газпромбанк в реестр аккредитованных IT-компаний!
Банк не первый год активно развивает цифровые продукты, над которыми сегодня работают тысячи крутых диджитал-специалистов. И теперь айтишники смогут получить дополнительные государственные льготы.
Вы тоже можете стать частью команды Газпромбанка! Вакансии в IT и других направлениях — по ссылке > https://vk.cc/cf61ir
Банк не первый год активно развивает цифровые продукты, над которыми сегодня работают тысячи крутых диджитал-специалистов. И теперь айтишники смогут получить дополнительные государственные льготы.
Вы тоже можете стать частью команды Газпромбанка! Вакансии в IT и других направлениях — по ссылке > https://vk.cc/cf61ir
👍5🔥2👎1
⚡️ Synthetic Minority Over-sampling Technique, SMOTE) — алгоритм предварительной обработки данных
Метод увеличения числа примеров миноритарного класса (Synthetic Minority Over-sampling Technique, SMOTE) — это алгоритм предварительной обработки данных, используемый для устранения дисбаланса классов в наборе данных.
В реальном мире нередко приходится обучать модель на наборе данных с очень малым количеством примеров определенного класса. Чаще всего эта проблема возникает при создании классификатора для диагностирования редких заболеваний, выявления производственных дефектов, раскрытия мошеннических транзакций.
Во всех перечисленных сферах применения МО характер данных (очень редкие случаи) не позволяет собрать больше примеров. Однако модель, обученная таким образом, может оказаться малоэффективной.
Одним из способов решения этой проблемы является сокращение числа примеров мажоритарного класса. Иными словами, из набора данных исключаются строки мажоритарного класса, чтобы выровнять количество строк мажоритарного и миноритарного классов.
Читать дальше
@data_analysis_ml
Метод увеличения числа примеров миноритарного класса (Synthetic Minority Over-sampling Technique, SMOTE) — это алгоритм предварительной обработки данных, используемый для устранения дисбаланса классов в наборе данных.
В реальном мире нередко приходится обучать модель на наборе данных с очень малым количеством примеров определенного класса. Чаще всего эта проблема возникает при создании классификатора для диагностирования редких заболеваний, выявления производственных дефектов, раскрытия мошеннических транзакций.
Во всех перечисленных сферах применения МО характер данных (очень редкие случаи) не позволяет собрать больше примеров. Однако модель, обученная таким образом, может оказаться малоэффективной.
Одним из способов решения этой проблемы является сокращение числа примеров мажоритарного класса. Иными словами, из набора данных исключаются строки мажоритарного класса, чтобы выровнять количество строк мажоритарного и миноритарного классов.
Читать дальше
@data_analysis_ml
{kind=link}
👍12🔥2
Шаблоны проектирования систем машинного обучения
https://uproger.com/shablony-proektirovaniya-sistem-mashinnogo-obucheniya/
https://uproger.com/shablony-proektirovaniya-sistem-mashinnogo-obucheniya/
UPROGER | Программирование
Шаблоны проектирования систем машинного обучения
Конструкция систем машинного обучения претерпела несколько изменений за последнее десятилетие с улучшением производительности памяти и процессора, систем хранения и увеличения масштабов наборов данных. Мы описываем, как изменились эти шаблоны проектирования…
👍14
Обзор библиотеки Datatable в Python для обработки больших объёмов данных.
Если вы пользовались языком R, то, скорее всего, вы уже работали с пакетом data.table. В R это расширение пакета data.frame. Для пользователей R он полезен в обработке больших объёмов данных (например, около 100 ГБ в RAM).
data.table в R — многофункциональный пакет с высокой производительностью. Он лёгок в использовании, удобен и быстр. Конечно, он очень известен: у него более 400 тысяч скачиваний каждый месяц и его используют почти 650 пакетов CRAN и Bioconductor.
А что делать тем, кто использует Python? Хорошие новости: для этого языка существует библиотека datatable, которая поддерживает большие данные, датасеты как внутри динамической памяти, так и вне, мультипотоковые алгоритмы и обеспечивает высокую производительность.
Читать дальше
@data_analysis_ml
Если вы пользовались языком R, то, скорее всего, вы уже работали с пакетом data.table. В R это расширение пакета data.frame. Для пользователей R он полезен в обработке больших объёмов данных (например, около 100 ГБ в RAM).
data.table в R — многофункциональный пакет с высокой производительностью. Он лёгок в использовании, удобен и быстр. Конечно, он очень известен: у него более 400 тысяч скачиваний каждый месяц и его используют почти 650 пакетов CRAN и Bioconductor.
А что делать тем, кто использует Python? Хорошие новости: для этого языка существует библиотека datatable, которая поддерживает большие данные, датасеты как внутри динамической памяти, так и вне, мультипотоковые алгоритмы и обеспечивает высокую производительность.
Читать дальше
@data_analysis_ml
{kind=link}
👍20🔥3
✒️ Обучение алгоритма генерации текста на основе высказываний философов и писателей
Наверняка вы мечтали поговорить с великим философом: задать ему вопрос о своей жизни, узнать его мнение или просто поболтать. В наше время это возможно за счет чат-ботов, которые поддерживают диалог, имитируя манеру общения живого человека. Подобные чат-боты создаются благодаря технологиям обработки естественного языка и генерации текста. Уже сейчас существуют обученные модели, которые неплохо справляются с данной задачей.
В этой статье я расскажу о своем опыте обучения алгоритма генерации текста, основанного на высказываниях великих личностей. В датасете для обучения модели используются цитаты десяти известных философов, писателей и ученых.
Конечный текст будет генерироваться на основе высказываний всех десяти мыслителей.Но если вы захотите “пообщаться” с кем-то конкретным, например, с Сократом или Ницше, то Google Colab, в котором велась работа, прилагается в конце статьи. С его помощью можно будет поэкспериментировать только с генерацией выбранного вами философа.
Читать дальше
@data_analysis_ml
Наверняка вы мечтали поговорить с великим философом: задать ему вопрос о своей жизни, узнать его мнение или просто поболтать. В наше время это возможно за счет чат-ботов, которые поддерживают диалог, имитируя манеру общения живого человека. Подобные чат-боты создаются благодаря технологиям обработки естественного языка и генерации текста. Уже сейчас существуют обученные модели, которые неплохо справляются с данной задачей.
В этой статье я расскажу о своем опыте обучения алгоритма генерации текста, основанного на высказываниях великих личностей. В датасете для обучения модели используются цитаты десяти известных философов, писателей и ученых.
Конечный текст будет генерироваться на основе высказываний всех десяти мыслителей.Но если вы захотите “пообщаться” с кем-то конкретным, например, с Сократом или Ницше, то Google Colab, в котором велась работа, прилагается в конце статьи. С его помощью можно будет поэкспериментировать только с генерацией выбранного вами философа.
Читать дальше
@data_analysis_ml
{kind=link}
👍9❤1🔥1
📊 Улучшение визуализации данных с помощью диаграмм с двумя осями в Python
Визуализация данных облегчает понимание тенденций и позволяет принимать обоснованные решения. Для оптимального представления данных важно правильно выбрать вид диаграммы. Более того, некоторые диаграммы, такие как столбиковые и многолинейные, можно дополнительно настроить для лучшего разъяснения данных.
Помимо косметических преобразований графических изображений (с помощью цвета и шрифта), можно воспользоваться дополнительными функциями, такими как общее направление линий, прогнозы и двухосевая реализация. В этой статье мы расскажем, как использовать двухосевую линейную диаграмму, чтобы более наглядно продемонстрировать аудитории корреляции и тенденции между точками данных. Мы также кратко рассмотрим, как может выглядеть обычная диаграмма без двойной оси, чтобы вы могли решить, какое из двух графических представлений максимально соответствует вашим потребностям в визуализации.
Читать дальше
@data_analysis_ml
Визуализация данных облегчает понимание тенденций и позволяет принимать обоснованные решения. Для оптимального представления данных важно правильно выбрать вид диаграммы. Более того, некоторые диаграммы, такие как столбиковые и многолинейные, можно дополнительно настроить для лучшего разъяснения данных.
Помимо косметических преобразований графических изображений (с помощью цвета и шрифта), можно воспользоваться дополнительными функциями, такими как общее направление линий, прогнозы и двухосевая реализация. В этой статье мы расскажем, как использовать двухосевую линейную диаграмму, чтобы более наглядно продемонстрировать аудитории корреляции и тенденции между точками данных. Мы также кратко рассмотрим, как может выглядеть обычная диаграмма без двойной оси, чтобы вы могли решить, какое из двух графических представлений максимально соответствует вашим потребностям в визуализации.
Читать дальше
@data_analysis_ml
👍17
This media is not supported in your browser
VIEW IN TELEGRAM
Используем библиотеку matplotlib для создания интересной анимации данных.
Изображение имитации дождя выполнено с помощью библиотеки Matplotlib, известной как прародитель пакетов для визуализации данных на python. Matplotlib имитирует капли дождя на поверхности путем анимирования масштаба и непрозрачности 50 точек графика разброса. В этой статье мы рассмотрим анимации в Matplotlib и несколько способов их создания.
Читать дальше
@data_analysis_ml
Изображение имитации дождя выполнено с помощью библиотеки Matplotlib, известной как прародитель пакетов для визуализации данных на python. Matplotlib имитирует капли дождя на поверхности путем анимирования масштаба и непрозрачности 50 точек графика разброса. В этой статье мы рассмотрим анимации в Matplotlib и несколько способов их создания.
Читать дальше
@data_analysis_ml
👍20🔥3👎1
5️⃣ грязных трюков в соревновательном Data Science, о которых тебе не расскажут в приличном обществе. 🔥
Привет, чемпион! Возможно, ты сейчас участвуешь в соревновании по анализу данных или просто решил погрузиться в мира Data Science. Тогда эта статья будет тебе очень полезна!
Сражу скажу, что трюки, о которых мы сегодня поговорим, я не просто так назвал "грязными". Речь пойдет о вещах, которые в каком-то смысле нечестные или просто вводят в заблуждение других участников соревнований. Долго думал, стоит ли про эти техники вообще рассказывать, ведь в борьбе за призовые всегда велик соблазн начать хитрить. Решил, что все-таки расскажу про некоторые приемы, дабы вооружить честных людей, которые играют по правилам.
Будем разбирать приемы по ходу увеличения уровня их "грязи" - поехали!
Читать дальше
@data_analysis_ml
Привет, чемпион! Возможно, ты сейчас участвуешь в соревновании по анализу данных или просто решил погрузиться в мира Data Science. Тогда эта статья будет тебе очень полезна!
Сражу скажу, что трюки, о которых мы сегодня поговорим, я не просто так назвал "грязными". Речь пойдет о вещах, которые в каком-то смысле нечестные или просто вводят в заблуждение других участников соревнований. Долго думал, стоит ли про эти техники вообще рассказывать, ведь в борьбе за призовые всегда велик соблазн начать хитрить. Решил, что все-таки расскажу про некоторые приемы, дабы вооружить честных людей, которые играют по правилам.
Будем разбирать приемы по ходу увеличения уровня их "грязи" - поехали!
Читать дальше
@data_analysis_ml
{kind=link}
👍21❤3👎3
📊 Путеводитель по Big Data для начинающих: методы и техники анализа больших данных
Методы и техники анализа Big Data: Machine Learning, Data mining, краудсорсинг, нейросети, предиктивный и статистический анализ, визуализация, смешение и интеграция данных, имитационные модели. Как разобраться во множестве названий и аббревиатур? Читайте наш путеводитель.
читать дальше
@data_analysis_ml
Методы и техники анализа Big Data: Machine Learning, Data mining, краудсорсинг, нейросети, предиктивный и статистический анализ, визуализация, смешение и интеграция данных, имитационные модели. Как разобраться во множестве названий и аббревиатур? Читайте наш путеводитель.
читать дальше
@data_analysis_ml
👍7👎2
3️⃣6️⃣ лучших инструментов для визуализации данных ↩️
Если вы ищете способ просто и понятно рассказать о сложных данных, географии, объяснить неочевидные взаимосвязи, сложные или простые идеи, то вам нужна визуализация. Она хороша тем, что сразу привлекает внимание к ключевому посланию, демонстрирует закономерности, которые трудно уловить в тексте или в таблице с цифрами.
Существует много специальных инструментов для визуализации: некоторые из них совсем простые: нужно только загрузить данные и выбрать, как они будут отображаться. Другие программы более сложные и комплексные — требуют настройки и, например, знаний JavaScript.
Мы подобрали самые разные варианты: и для тех, кому нужен быстрый понятный результат, и для продвинутых пользователей. Есть из чего выбрать.
Читать дальше
@data_analysis_ml
Если вы ищете способ просто и понятно рассказать о сложных данных, географии, объяснить неочевидные взаимосвязи, сложные или простые идеи, то вам нужна визуализация. Она хороша тем, что сразу привлекает внимание к ключевому посланию, демонстрирует закономерности, которые трудно уловить в тексте или в таблице с цифрами.
Существует много специальных инструментов для визуализации: некоторые из них совсем простые: нужно только загрузить данные и выбрать, как они будут отображаться. Другие программы более сложные и комплексные — требуют настройки и, например, знаний JavaScript.
Мы подобрали самые разные варианты: и для тех, кому нужен быстрый понятный результат, и для продвинутых пользователей. Есть из чего выбрать.
Читать дальше
@data_analysis_ml
👍19👎3
Основная математика для науки о данных
https://www.kdnuggets.com/2022/06/essential-math-data-science-eigenvectors-application-pca.html
@data_analysis_ml
https://www.kdnuggets.com/2022/06/essential-math-data-science-eigenvectors-application-pca.html
@data_analysis_ml
KDnuggets
Essential Math for Data Science: Eigenvectors and Application to PCA - KDnuggets
In this article, you’ll learn about the eigendecomposition of a matrix.
👍13👎2
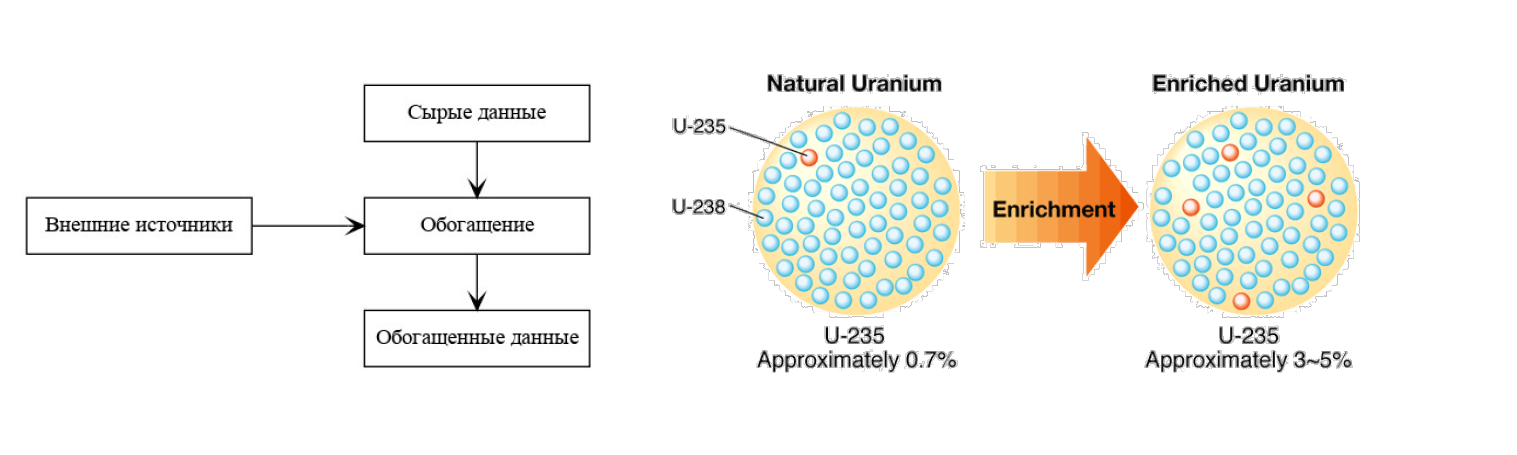
🎯 Обогащение данных — что это и почему без него никак
Задача обогащения данных напрямую связана с темой их обработки и анализа. Обогащение нужно для того, чтобы конечные потребители данных получали качественную и полную информацию.
Сам термин "обогащение данных" — это перевод англоязычного Data enrichment, который проводит аналогию между данными и... ураном. Точно так же, как промышленники насыщают урановую руду, увеличивая долю изотопа 235U, чтобы её можно было использовать (хочется надеяться, в мирных целях), в процессе обогащения данных мы насыщаем их информацией.
Читать дальше
@data_analysis_ml
Задача обогащения данных напрямую связана с темой их обработки и анализа. Обогащение нужно для того, чтобы конечные потребители данных получали качественную и полную информацию.
Сам термин "обогащение данных" — это перевод англоязычного Data enrichment, который проводит аналогию между данными и... ураном. Точно так же, как промышленники насыщают урановую руду, увеличивая долю изотопа 235U, чтобы её можно было использовать (хочется надеяться, в мирных целях), в процессе обогащения данных мы насыщаем их информацией.
Читать дальше
@data_analysis_ml
{kind=link}
👍14