
Суперкомпьютерный Blacklist.
Сильный удар США по Китаю.
8го апреля правительство США включило в черный список организаций, деятельность которых противоречит интересам национальной безопасности или внешней политики США, семь суперкомпьютерных центров Китая (официальный пресс-релиз
Де-факто это значит, что:
• Эти центры теперь не смогут приобрести ничего (даже кофемолку) американского производства без специального разрешения правительства США.
• Ни одна компания мира, в здравом уме, не пойдет на нарушение этого запрета. Ибо она не только заплатит многомиллионный штраф, но и получит запрет на продажу всей её продукции в США.
То есть суперкомпьютерный Blacklist – это очень серьёзно.
Официальная причина запрета 8 апреля – «эти организации участвуют в создании суперкомпьютеров, используемых военными силами Китая, в его дестабилизирующих усилиях по модернизации вооруженных сил и / или в программах создания оружия массового уничтожения».
Конечно же, это стандартная отмазка. Правительство США использует их уже десятки лет: сначала, ограничивая поставки суперкомпьютеров в СССР, потом в Россию, сейчас в Китай, а скоро, полагаю, опять и в Россию.
Мне эта кухня с черными списками, экспортным контролем, лицензиями и штрафами известна до мельчайших деталей. С 1996 по 2002 я был одним из главных действующих лиц грандиозного скандала о, якобы, нарушении законов США при поставке суперкомпьютеров SGI в Россию. Обвинения правительства США были те же: суперкомпьютеры могут использоваться для «модернизации вооруженных сил и / или в программах создания оружия массового уничтожения» (см. 1, 2, 3, 4).
На деле же шла подковерная борьба за расширение НАТО на Восток, и США нужно было найти точки давления на Россию.
Так что же за причина заставляет США снова использовать ту же схему давления на Китай?
Полагаю, дело вот в чем.
2020е годы станут десятилетием триумфа машинного обучения. А главный ограничивающий фактор здесь - производительность компьютеров при обучении моделей.
Потенциал вычислительной мощности страны – наилучший показатель её перспектив в гонке за место среди технологических лидеров мира в самом широком спектре областей: от физики до медицины. Про ИИ я и не говорю. Здесь вообще все пока замыкается на машинное обучение.
Попадет ли страна в восьмерку или двадцатку лидеров, можно примерно оценить по суммарной вычислительной мощности её суперкомпьютеров.
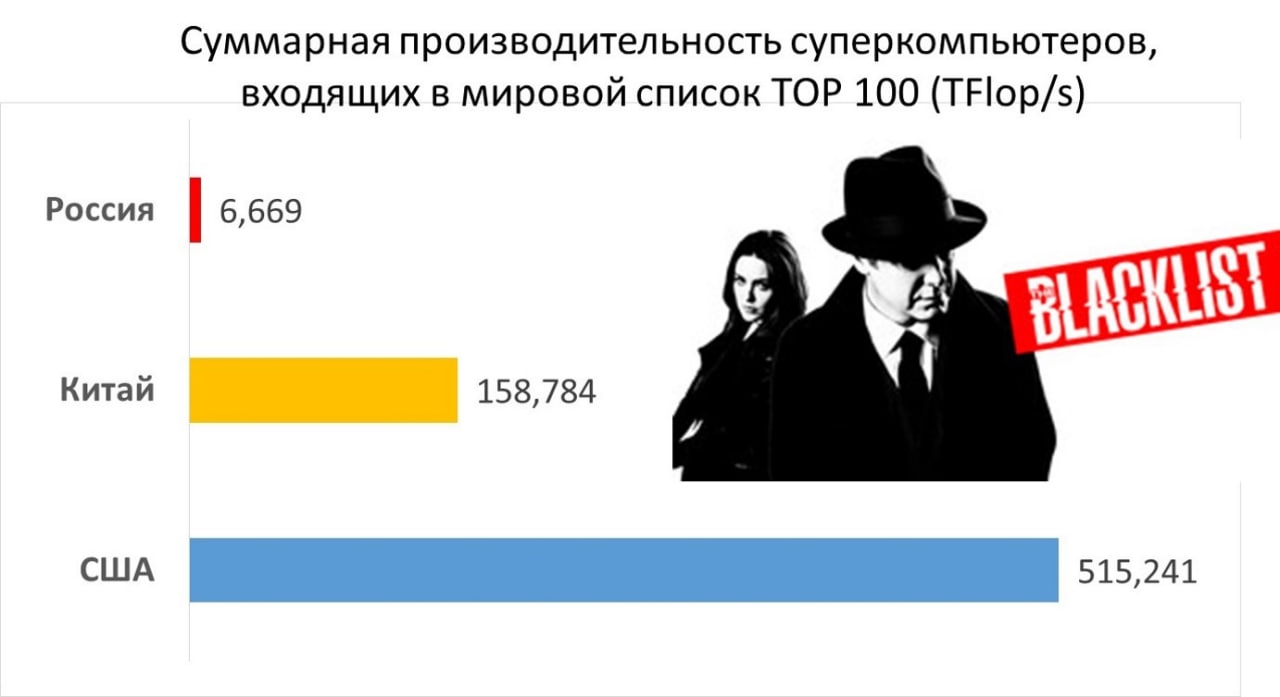
На приведенном графике сравнение России, Китая и США по суммарной вычислительной мощности суперкомпьютеров каждой из стран, входящих в сотню самых высокопроизводительных компьютеров мира (по состоянию на конец 2020).
Комментировать положение России не буду. Всё, увы, очевидно.
А вот про более чем троекратный отрыв США от Китая скажу.
США знают, что от сохранения их лидерства по этому показателю в значительной мере зависит итог цифровой битвы с Китаем за звание сверхдержавы №1. Поэтому они и начали снова свои «танцы с бубном» вокруг черных списков суперкомпьютеров и комплектующих к ним.
Но только остановить Китай будет трудно. Самый мощный из их суперкомпьютеров уже оснащен процессорами только китайского производства. И 3 из 7 центров, внесенных США в черный список, заняты разработкой новых процессоров для 100%ного избавления китайских суперкомпьютеров от поставок из США.
К слову, на прошлой же неделе в Китае запущен проект создания завода по производству процессоров для квантовых компьютеров.
Так что к 2025му суперкомпьютеры из США Китаю могут уже не понадобиться.
#Россия #Китай #США #HPC
Сильный удар США по Китаю.
8го апреля правительство США включило в черный список организаций, деятельность которых противоречит интересам национальной безопасности или внешней политики США, семь суперкомпьютерных центров Китая (официальный пресс-релиз
Де-факто это значит, что:
• Эти центры теперь не смогут приобрести ничего (даже кофемолку) американского производства без специального разрешения правительства США.
• Ни одна компания мира, в здравом уме, не пойдет на нарушение этого запрета. Ибо она не только заплатит многомиллионный штраф, но и получит запрет на продажу всей её продукции в США.
То есть суперкомпьютерный Blacklist – это очень серьёзно.
Официальная причина запрета 8 апреля – «эти организации участвуют в создании суперкомпьютеров, используемых военными силами Китая, в его дестабилизирующих усилиях по модернизации вооруженных сил и / или в программах создания оружия массового уничтожения».
Конечно же, это стандартная отмазка. Правительство США использует их уже десятки лет: сначала, ограничивая поставки суперкомпьютеров в СССР, потом в Россию, сейчас в Китай, а скоро, полагаю, опять и в Россию.
Мне эта кухня с черными списками, экспортным контролем, лицензиями и штрафами известна до мельчайших деталей. С 1996 по 2002 я был одним из главных действующих лиц грандиозного скандала о, якобы, нарушении законов США при поставке суперкомпьютеров SGI в Россию. Обвинения правительства США были те же: суперкомпьютеры могут использоваться для «модернизации вооруженных сил и / или в программах создания оружия массового уничтожения» (см. 1, 2, 3, 4).
На деле же шла подковерная борьба за расширение НАТО на Восток, и США нужно было найти точки давления на Россию.
Так что же за причина заставляет США снова использовать ту же схему давления на Китай?
Полагаю, дело вот в чем.
2020е годы станут десятилетием триумфа машинного обучения. А главный ограничивающий фактор здесь - производительность компьютеров при обучении моделей.
Потенциал вычислительной мощности страны – наилучший показатель её перспектив в гонке за место среди технологических лидеров мира в самом широком спектре областей: от физики до медицины. Про ИИ я и не говорю. Здесь вообще все пока замыкается на машинное обучение.
Попадет ли страна в восьмерку или двадцатку лидеров, можно примерно оценить по суммарной вычислительной мощности её суперкомпьютеров.
На приведенном графике сравнение России, Китая и США по суммарной вычислительной мощности суперкомпьютеров каждой из стран, входящих в сотню самых высокопроизводительных компьютеров мира (по состоянию на конец 2020).
Комментировать положение России не буду. Всё, увы, очевидно.
А вот про более чем троекратный отрыв США от Китая скажу.
США знают, что от сохранения их лидерства по этому показателю в значительной мере зависит итог цифровой битвы с Китаем за звание сверхдержавы №1. Поэтому они и начали снова свои «танцы с бубном» вокруг черных списков суперкомпьютеров и комплектующих к ним.
Но только остановить Китай будет трудно. Самый мощный из их суперкомпьютеров уже оснащен процессорами только китайского производства. И 3 из 7 центров, внесенных США в черный список, заняты разработкой новых процессоров для 100%ного избавления китайских суперкомпьютеров от поставок из США.
К слову, на прошлой же неделе в Китае запущен проект создания завода по производству процессоров для квантовых компьютеров.
Так что к 2025му суперкомпьютеры из США Китаю могут уже не понадобиться.
#Россия #Китай #США #HPC
{kind=link}
Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке.
В 2020-х расклад сил в технологическом соревновании стало предельно просто оценивать. Революция «Глубокого обучения Больших моделей на Больших данных» превратила вычислительную мощность в ключевой фактор прогресса практически всех интеллектуально емких индустрий: от разработки новых лекарств до новых видов вооружений. А там, где задействован ИИ (а он уже почти всюду) вычислительная мощность, вообще, решает все.
Формула превосходства стала предельно проста:
• собери как можно больше данных;
• создай как можно более сложную (по числу параметров) модель;
• обучи модель как можно быстрее.
Тот, у кого будет «больше-больше-быстрее» имеет максимально высокие шансы выиграть в технологической гонке. А здесь все упирается в вычислительную мощность «железа» (HW) и алгоритмов (SW).
И при всем уважении к алгоритмам, но в этой паре их роль №2. Ибо алгоритм изобрести, скопировать или даже украсть все же проще, чем HW. «Железо» либо есть, либо его нет.
Это мы проходили еще в СССР. Это же стало даже более критическим фактором в эпоху «Глубокого обучения Больших моделей на Больших данных».
Вот два самых свежих примера.
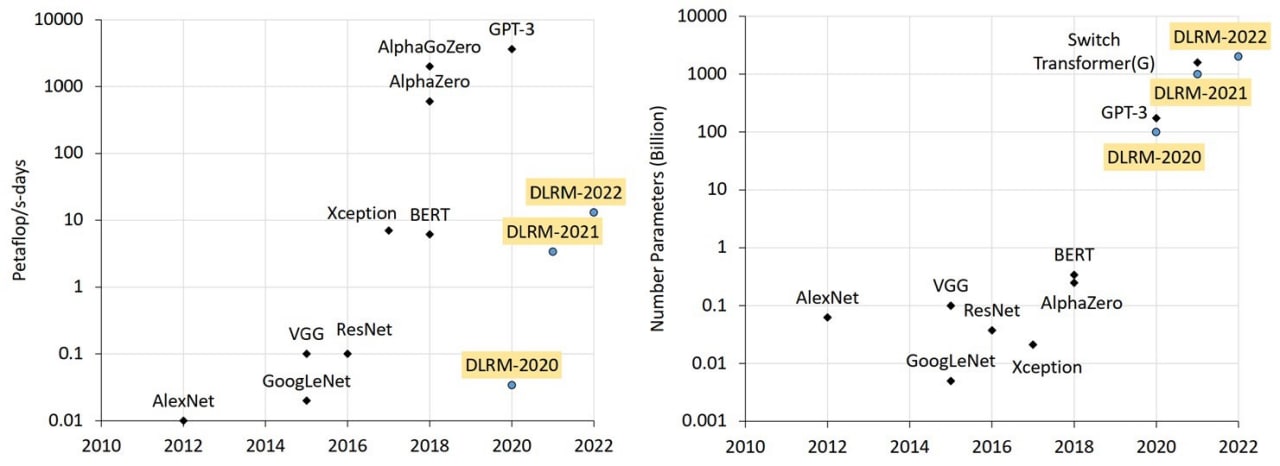
1) Facebook раскрыл свою систему рекомендаций. Она построена на модели рекомендаций глубокого обучения (DLRM). Содержит эта модель 12 триллионов параметров и требует суммарного объема вычислений более 10 Petaflop/s-days.
2) Microsoft скоро продемонстрирует модель для ИИ с 1 триллионом параметров. Она работает на системе вычислительной производительности 502 Petaflop/s на 3072 графических процессорах.
Для сравнения, языковая модель GPT-2, разработанная OpenAI 2 года назад, поразила мир тем, что у нее было 1,5 миллиарда параметров. А GPT-3, вышедшая в 2020 имела уже 175 млрд. параметров.
Как видите, модели с триллионами параметров – уже данность. И чтобы их учить не годами, а днями, нужно «железо» сумасшедшей вычислительной мощности.
Т.е. сами видите, - есть «железо» - участвуй в гонке, нет «железа» - кури в сторонке.
На приложенной картинке свежие данные о размерах моделей и требуемой для них вычислительной мощности.
#HPC #ИИгонка
В 2020-х расклад сил в технологическом соревновании стало предельно просто оценивать. Революция «Глубокого обучения Больших моделей на Больших данных» превратила вычислительную мощность в ключевой фактор прогресса практически всех интеллектуально емких индустрий: от разработки новых лекарств до новых видов вооружений. А там, где задействован ИИ (а он уже почти всюду) вычислительная мощность, вообще, решает все.
Формула превосходства стала предельно проста:
• собери как можно больше данных;
• создай как можно более сложную (по числу параметров) модель;
• обучи модель как можно быстрее.
Тот, у кого будет «больше-больше-быстрее» имеет максимально высокие шансы выиграть в технологической гонке. А здесь все упирается в вычислительную мощность «железа» (HW) и алгоритмов (SW).
И при всем уважении к алгоритмам, но в этой паре их роль №2. Ибо алгоритм изобрести, скопировать или даже украсть все же проще, чем HW. «Железо» либо есть, либо его нет.
Это мы проходили еще в СССР. Это же стало даже более критическим фактором в эпоху «Глубокого обучения Больших моделей на Больших данных».
Вот два самых свежих примера.
1) Facebook раскрыл свою систему рекомендаций. Она построена на модели рекомендаций глубокого обучения (DLRM). Содержит эта модель 12 триллионов параметров и требует суммарного объема вычислений более 10 Petaflop/s-days.
2) Microsoft скоро продемонстрирует модель для ИИ с 1 триллионом параметров. Она работает на системе вычислительной производительности 502 Petaflop/s на 3072 графических процессорах.
Для сравнения, языковая модель GPT-2, разработанная OpenAI 2 года назад, поразила мир тем, что у нее было 1,5 миллиарда параметров. А GPT-3, вышедшая в 2020 имела уже 175 млрд. параметров.
Как видите, модели с триллионами параметров – уже данность. И чтобы их учить не годами, а днями, нужно «железо» сумасшедшей вычислительной мощности.
Т.е. сами видите, - есть «железо» - участвуй в гонке, нет «железа» - кури в сторонке.
На приложенной картинке свежие данные о размерах моделей и требуемой для них вычислительной мощности.
#HPC #ИИгонка
{kind=link}
Россия на карте мира ИИ.
Место и перспектива трёх стран в мировой ИИ-гонке.
Еще пару лет назад был смысл в применении разнообразных рейтингов для оценки положения стран в мировой ИИ-гонке (см. (1)). Теперь это уже не так. Практические успехи глубокого обучения (основное направление развития современных ИИ-систем) привели к тому, что на это направлении развития ИИ теперь приходятся 95%+ всех денег и талантов. А это значит, что как минимум на ближайшую декаду, лидеры глубокого обучения будут лидерами мировой ИИ-гонки.
А в глубоком обучении, - как в беге. Выигрывает тот, у кого лучше физическая подготовка. Конечно, есть и другие факторы (спортивный дух, настрой, воля к победе, техника …). Но без исключительно хорошей физической подготовки в гонке не выиграть.
Эквивалентом физической подготовки в современном глубоком обучении является вычислительная мощность компьютера, на котором обучаются модели со все большим числом параметров. В крупнейшей на сегодня языковой модели transformer от Microsoft число параметров составляет 530 млрд. Насколько круто возросли требования к вычислительной мощности для таких моделей видно из этого графика (2).
В результате вычислительная мощность стала главным показателем потенциала роста величины и сложности новых все более совершенных моделей глубокого обучения. И это относится как к бизнесу компаний БигТеха, так и к академическим исследовательским центрам, а также к каждой стране в целом.
Для оценки вычислительной мощности для такого рода задач обучения сверхбольших моделей создан специальный тест HPL-AI (3). Но по этому тесту пока что оценена производительность лишь 19 высокопроизводительных вычислительных комплексов мира. Поэтому для более широкого и полного сравнения самых высокопроизводительных систем для ИИ пока продолжают использовать показатель скорости вычислений с плавающей точкой (Flop/s), как это принято в рейтинге ТОР500 (4).
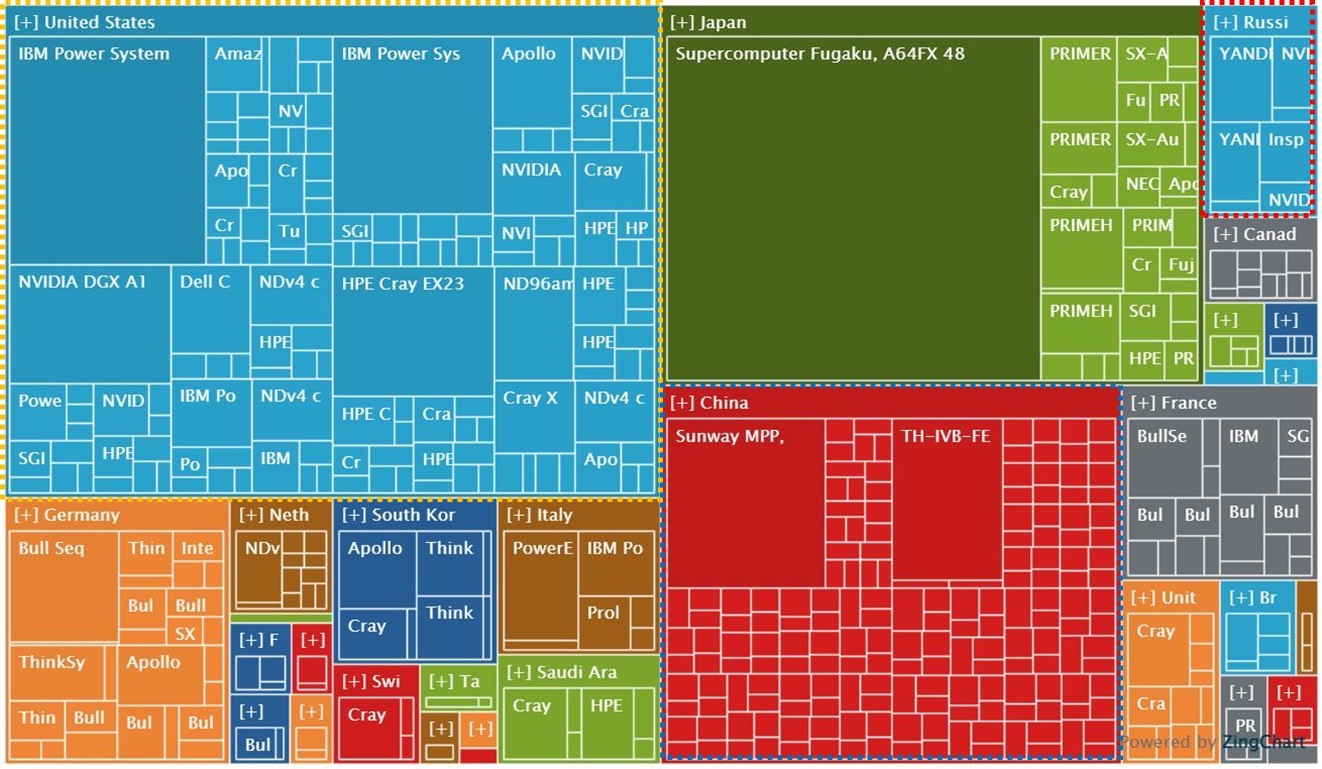
И по этой оценке карта мира ИИ выглядит так, как на приложенном к посту рисунке.
Совокупная вычислительная мощность каждой из стран соответствует площади прямоугольников, в свою очередь разделенных на более мелкие прямоугольники, соответствующие вычислительной мощности отдельных высокопроизводительных систем.
• Россия обведена красным пунктиром (7 систем, самая мощная из них у Яндекса – 21,5 петафлопс (10^15 Flop/s)
• Китай обведен синим пунктиром (173 системы, самая мощная – 93 петафлопс – на 26% превышает производительность всех российских систем в ТОР500).
• США обведены желтым пунктиром (149 систем, самая мощная – 149 петафлопс –в 2 раза превышает производительность всех российских систем в ТОР500).
Таково сегодняшнее место России на карте мира ИИ.
А теперь о перспективе.
На этом рисунке (5) вычислительная мощность трёх новых суперкомпьютерных систем соответствует площади трёх прямоугольников:
• Желтый – это Китай: 25 января с.г. SenseTime запустил Artificial Intelligence Data Centre (AIDC) нового поколения SenseCore; его вычислительная мощность 3740 петафлопс (в 51 раз превышает производительность всех российских систем в ТОР500)
• Синий – это США: к 2023 году Facebook (Meta) доведет вычислительную мощность своего AI supercomputer RSC до 4900 петафлопс (в 67 раз превышает производительность всех российских систем в ТОР500)
• Красный – это Россия: к 2026 планируется создать суперкомпьютер на разрабатываемых сейчас отечественных процессорах «Эльбрус-32С» производительностью в 100 петафлопс.
#ИИ #HPC #Россия #Китай #США
1 2 3 4 5
Место и перспектива трёх стран в мировой ИИ-гонке.
Еще пару лет назад был смысл в применении разнообразных рейтингов для оценки положения стран в мировой ИИ-гонке (см. (1)). Теперь это уже не так. Практические успехи глубокого обучения (основное направление развития современных ИИ-систем) привели к тому, что на это направлении развития ИИ теперь приходятся 95%+ всех денег и талантов. А это значит, что как минимум на ближайшую декаду, лидеры глубокого обучения будут лидерами мировой ИИ-гонки.
А в глубоком обучении, - как в беге. Выигрывает тот, у кого лучше физическая подготовка. Конечно, есть и другие факторы (спортивный дух, настрой, воля к победе, техника …). Но без исключительно хорошей физической подготовки в гонке не выиграть.
Эквивалентом физической подготовки в современном глубоком обучении является вычислительная мощность компьютера, на котором обучаются модели со все большим числом параметров. В крупнейшей на сегодня языковой модели transformer от Microsoft число параметров составляет 530 млрд. Насколько круто возросли требования к вычислительной мощности для таких моделей видно из этого графика (2).
В результате вычислительная мощность стала главным показателем потенциала роста величины и сложности новых все более совершенных моделей глубокого обучения. И это относится как к бизнесу компаний БигТеха, так и к академическим исследовательским центрам, а также к каждой стране в целом.
Для оценки вычислительной мощности для такого рода задач обучения сверхбольших моделей создан специальный тест HPL-AI (3). Но по этому тесту пока что оценена производительность лишь 19 высокопроизводительных вычислительных комплексов мира. Поэтому для более широкого и полного сравнения самых высокопроизводительных систем для ИИ пока продолжают использовать показатель скорости вычислений с плавающей точкой (Flop/s), как это принято в рейтинге ТОР500 (4).
И по этой оценке карта мира ИИ выглядит так, как на приложенном к посту рисунке.
Совокупная вычислительная мощность каждой из стран соответствует площади прямоугольников, в свою очередь разделенных на более мелкие прямоугольники, соответствующие вычислительной мощности отдельных высокопроизводительных систем.
• Россия обведена красным пунктиром (7 систем, самая мощная из них у Яндекса – 21,5 петафлопс (10^15 Flop/s)
• Китай обведен синим пунктиром (173 системы, самая мощная – 93 петафлопс – на 26% превышает производительность всех российских систем в ТОР500).
• США обведены желтым пунктиром (149 систем, самая мощная – 149 петафлопс –в 2 раза превышает производительность всех российских систем в ТОР500).
Таково сегодняшнее место России на карте мира ИИ.
А теперь о перспективе.
На этом рисунке (5) вычислительная мощность трёх новых суперкомпьютерных систем соответствует площади трёх прямоугольников:
• Желтый – это Китай: 25 января с.г. SenseTime запустил Artificial Intelligence Data Centre (AIDC) нового поколения SenseCore; его вычислительная мощность 3740 петафлопс (в 51 раз превышает производительность всех российских систем в ТОР500)
• Синий – это США: к 2023 году Facebook (Meta) доведет вычислительную мощность своего AI supercomputer RSC до 4900 петафлопс (в 67 раз превышает производительность всех российских систем в ТОР500)
• Красный – это Россия: к 2026 планируется создать суперкомпьютер на разрабатываемых сейчас отечественных процессорах «Эльбрус-32С» производительностью в 100 петафлопс.
#ИИ #HPC #Россия #Китай #США
1 2 3 4 5
{kind=link}
Отставание России от США в области ИИ уже колоссально.
А через несколько лет оно увеличится до трёх километров.
Так уж получилось, что прогресс в области ИИ во многом определяется наличием огромных вычислительных мощностей, требуемых для обучения гигантских нейросетей-трансформеров.
Грег Брокман (соучредитель и СТО OpenAI) формулирует это так:
«Мы думаем, что наибольшую выгоду получит тот, у кого самый большой компьютер».
Я уже демонстрировал, насколько критично наличие мощного компьютинга для обучения Больших моделей в посте «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке».
Место России на карте мира по вычислительной мощности суперкомпьютеров более чем скромное. В списке ТОР500 суперкомпьютеров на этот год у США 149 систем, а у России 7. При этом, только одна из систем США по своей производительности превышает производительность всех российских систем (см. мой пост). Председатель оргкомитета суперкомпьютерного форума России, д.ф.м.н, член-корр. РАН Сергей Абрамов оценивает отставание России от США в области суперкомпьютинга примерно в 10 лет.
Но в области обучения больших моделей для ИИ-приложений ситуация еще хуже. Здесь мало вычислительной мощности обычных серверов и требуются специальные ускорители вычислений. Спецы по машинному обучению из Яндекса это комментируют так.
«Например, если обучать модель с нуля на обычном сервере, на это потребуется 40 лет, а если на одном GPU-ускорителе V100 — 10 лет. Но хорошая новость в том, что задача обучения легко параллелится, и если задействовать хотя бы 256 тех же самых V100, соединить их быстрым интерконнектом, то задачу можно решить всего за две недели.»
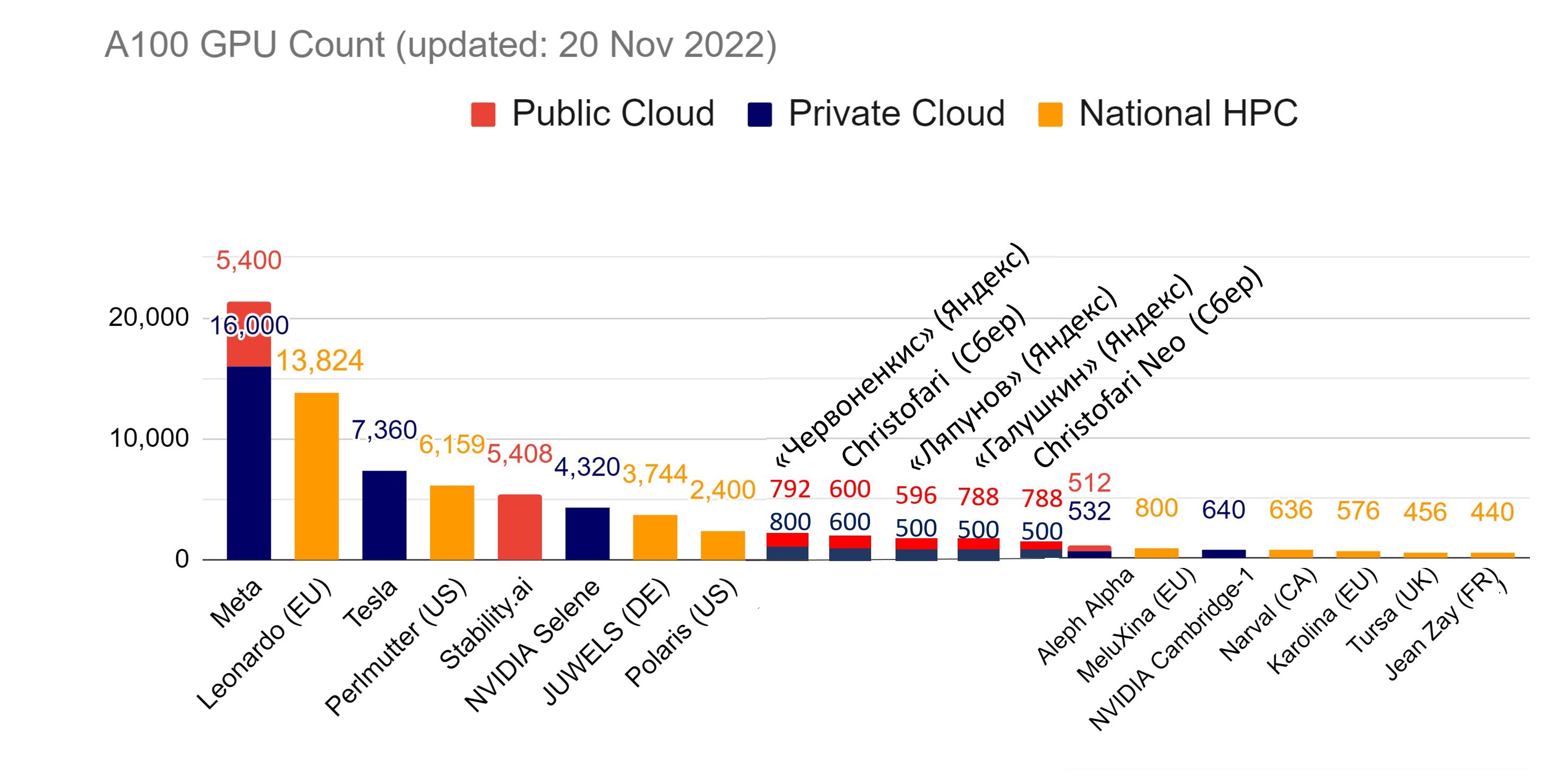
Поэтому, показатель числа GPU-ускорителей в вычислительных кластерах разных стран (общедоступных, частных и национальных) позволяет оценивать темпы развития систем ИИ в этих странах. Актуальная статистика данного показателя ведется в State of AI Report Compute Index. Состояние на 20 ноября приведено на приложенном рисунке, куда я добавил данные по пяти крупнейшим HPC-кластерам России (разбивка по public/private – моя оценка).
Из рисунка видно, что обучение больших моделей, занимающее на HPC-кластере всем известной американской компании дни и недели, будет требовать на HPC-кластере Яндекса месяцев, а то и лет.
Но это еще не вся беда. Введенные экспортные ограничения на поставку GPU-ускорителей в Россию и Китай за несколько лет многократно увеличат отрыв США в области обучения больших моделей для ИИ-приложений.
И этот отрыв будет измеряться уже не годами и даже не десятилетиями, а километрами, - как в старом советском анекдоте.
«Построили у нас самый мощный в мире компьютер и задали ему задачу, когда же наступит коммунизм. Компьютер думал, думал и выдал ответ: "Через 3 километра". На требование расшифровать столь странный ответ компьютер выдал:
— Каждая пятилетка — шаг к коммунизму.»
#ИИ #HPC #Россия #ЭкспортныйКонтроль
А через несколько лет оно увеличится до трёх километров.
Так уж получилось, что прогресс в области ИИ во многом определяется наличием огромных вычислительных мощностей, требуемых для обучения гигантских нейросетей-трансформеров.
Грег Брокман (соучредитель и СТО OpenAI) формулирует это так:
«Мы думаем, что наибольшую выгоду получит тот, у кого самый большой компьютер».
Я уже демонстрировал, насколько критично наличие мощного компьютинга для обучения Больших моделей в посте «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке».
Место России на карте мира по вычислительной мощности суперкомпьютеров более чем скромное. В списке ТОР500 суперкомпьютеров на этот год у США 149 систем, а у России 7. При этом, только одна из систем США по своей производительности превышает производительность всех российских систем (см. мой пост). Председатель оргкомитета суперкомпьютерного форума России, д.ф.м.н, член-корр. РАН Сергей Абрамов оценивает отставание России от США в области суперкомпьютинга примерно в 10 лет.
Но в области обучения больших моделей для ИИ-приложений ситуация еще хуже. Здесь мало вычислительной мощности обычных серверов и требуются специальные ускорители вычислений. Спецы по машинному обучению из Яндекса это комментируют так.
«Например, если обучать модель с нуля на обычном сервере, на это потребуется 40 лет, а если на одном GPU-ускорителе V100 — 10 лет. Но хорошая новость в том, что задача обучения легко параллелится, и если задействовать хотя бы 256 тех же самых V100, соединить их быстрым интерконнектом, то задачу можно решить всего за две недели.»
Поэтому, показатель числа GPU-ускорителей в вычислительных кластерах разных стран (общедоступных, частных и национальных) позволяет оценивать темпы развития систем ИИ в этих странах. Актуальная статистика данного показателя ведется в State of AI Report Compute Index. Состояние на 20 ноября приведено на приложенном рисунке, куда я добавил данные по пяти крупнейшим HPC-кластерам России (разбивка по public/private – моя оценка).
Из рисунка видно, что обучение больших моделей, занимающее на HPC-кластере всем известной американской компании дни и недели, будет требовать на HPC-кластере Яндекса месяцев, а то и лет.
Но это еще не вся беда. Введенные экспортные ограничения на поставку GPU-ускорителей в Россию и Китай за несколько лет многократно увеличат отрыв США в области обучения больших моделей для ИИ-приложений.
И этот отрыв будет измеряться уже не годами и даже не десятилетиями, а километрами, - как в старом советском анекдоте.
«Построили у нас самый мощный в мире компьютер и задали ему задачу, когда же наступит коммунизм. Компьютер думал, думал и выдал ответ: "Через 3 километра". На требование расшифровать столь странный ответ компьютер выдал:
— Каждая пятилетка — шаг к коммунизму.»
#ИИ #HPC #Россия #ЭкспортныйКонтроль
{kind=link}
У Китая и России появился шанс не дать США уйти в отрыв в области ИИ.
В этом году США пошли на крайние меры, чтобы не позволить Китаю догнать и перегнать США в важнейшей для нацбезопасности индустрии ИИ. Введенные США экспортные ограничения на высокопроизводительные процессоры сильно усложняют Китаю (не имеющему пока соизмеримых по производительности собственных процессоров) возможность конкуренции в области ИИ. Заодно под раздачу экспортных ограничений (по известным причинам) попала и Россия. И это лишает российские компании и без того тусклой перспективы, - пусть не догнать США, но хотя бы отставать на годы, а не на десятилетия.
Но тут случилось такое, что мало кто мог предвидеть.
Компания Together объявила, что смогла обучить свою модель с открытым кодом GPT-JT (6 млрд параметров):
• децентрализованно (на разнородной группе не самых крутых графических процессоров)
• соединенных медленными интернет-каналами (1 Гбит/с)
Авторы модели GPT-JT придумали кучу хитрых способов уменьшения вычислительной и коммуникационной нагрузки при децентрализованном обучении. В результате, эта модель на тестах классификации приближается к современным моделям, которые намного её крупнее (например, InstructGPT davinci v2).
Это достижение может иметь колоссальные последствия.
✔️ До сих пор магистральная линия развития ИИ определялась ограниченным набором компаний, имеющих доступ к большим централизованным компьютерам. На этих высокопроизводительных вычислительных комплексах обучались все т.н. большие модели, начиная от AlphaZero и заканчивая GPT3.
✔️ Компаниям, не имеющим в распоряжении суперкомпьютерных мощностей в этой гонке было нечего ловить (см мой пост «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке»).
GPT-JT сметает шашки с доски, предлагая совершенно иной сценарий будущего.
Вместо нескольких компаний – гигантов, оснащенных суперкомпьютерными системами для ИИ, распределенные коллективы разработчиков могут объединять свои скромные компьютерные мощности через не самые быстрые интернет-каналы, чтобы вместе обучать большие модели.
Но это возможно лишь при условии, что разработчики GPT-JT смогут её масштабировать со скромных 6 млрд параметров на сотни миллиардов. Ибо таково требование сегодняшних больших моделей. А в 2023 счет пойдет уже на триллионы параметров.
#ИИ #HPC #Россия #Китай #ЭкспортныйКонтроль
В этом году США пошли на крайние меры, чтобы не позволить Китаю догнать и перегнать США в важнейшей для нацбезопасности индустрии ИИ. Введенные США экспортные ограничения на высокопроизводительные процессоры сильно усложняют Китаю (не имеющему пока соизмеримых по производительности собственных процессоров) возможность конкуренции в области ИИ. Заодно под раздачу экспортных ограничений (по известным причинам) попала и Россия. И это лишает российские компании и без того тусклой перспективы, - пусть не догнать США, но хотя бы отставать на годы, а не на десятилетия.
Но тут случилось такое, что мало кто мог предвидеть.
Компания Together объявила, что смогла обучить свою модель с открытым кодом GPT-JT (6 млрд параметров):
• децентрализованно (на разнородной группе не самых крутых графических процессоров)
• соединенных медленными интернет-каналами (1 Гбит/с)
Авторы модели GPT-JT придумали кучу хитрых способов уменьшения вычислительной и коммуникационной нагрузки при децентрализованном обучении. В результате, эта модель на тестах классификации приближается к современным моделям, которые намного её крупнее (например, InstructGPT davinci v2).
Это достижение может иметь колоссальные последствия.
✔️ До сих пор магистральная линия развития ИИ определялась ограниченным набором компаний, имеющих доступ к большим централизованным компьютерам. На этих высокопроизводительных вычислительных комплексах обучались все т.н. большие модели, начиная от AlphaZero и заканчивая GPT3.
✔️ Компаниям, не имеющим в распоряжении суперкомпьютерных мощностей в этой гонке было нечего ловить (см мой пост «Есть «железо» - участвуй в гонке. Нет «железа» - кури в сторонке»).
GPT-JT сметает шашки с доски, предлагая совершенно иной сценарий будущего.
Вместо нескольких компаний – гигантов, оснащенных суперкомпьютерными системами для ИИ, распределенные коллективы разработчиков могут объединять свои скромные компьютерные мощности через не самые быстрые интернет-каналы, чтобы вместе обучать большие модели.
Но это возможно лишь при условии, что разработчики GPT-JT смогут её масштабировать со скромных 6 млрд параметров на сотни миллиардов. Ибо таково требование сегодняшних больших моделей. А в 2023 счет пойдет уже на триллионы параметров.
#ИИ #HPC #Россия #Китай #ЭкспортныйКонтроль
{kind=link}
Будущее человечества отдано в руки Бигтеха США?
Хаос революции или небывалое закручивание гаек - это зависит от того, в чьих руках будет ИИ через 5 лет.
В течение десятилетия на Земле будет создан ИИ, способный выполнять большую часть когнитивной работы, на которую способны люди.
Обеспечение безопасного для общества развития сверхмощного инструментария ИИ в течение ближайшего десятилетия должно быть высшим приоритетом ведущих государств мира и их общественных и политических институтов.
«История показывает, - когда силы вне правительства приобретают жесткую политическую власть, вы получаете: либо а) хаос революции, либо б) дикую гиперреакцию государства, направленную на возвращение себе власти.
Я не понимаю, чем должен руководствоваться Западный мир, пойдя на такой риск. Но он на этот риск идет!».
Так пишет исследователь ИИ и бывший спецсоветник по науке и технологиям премьер-министра Великобритании Джеймс Филлипс в воззвании к правительству своей страны, обеспокоенный тем, что европейские правительства уступают контроль за созданием AGI ряду субъектов частного бизнеса США.
«Такое развитие окажет беспрецедентное влияние на наше общество; «агентные» формы AGI могут также представлять собой экзистенциальную угроза нашей безопасности. Нынешний путь развития AGI по самой своей сути небезопасен» - пишет в своем воззвании Джеймс Филлипс.
Далее он предлагает 3 шага для сохранения демократического контроля за тем, каким будет будущее мира.
1. Закупить национальную инфраструктуру суперкомпьютеров ИИ, сравнимую с ведущими частными лабораториями США.
2. Создать консультативную группу исследователей, работающих на фронтире практики развития ИИ (а не академических ученых), чтобы определить основные исследовательские проекты ИИ для запуска в этой инфраструктуре.
3. Создайть элитную государственную исследовательскую лабораторию под руководством лидера с техническими навыками и предпринимательским опытом, чтобы разработать исследовательскую программу национального фронтира практики развития ИИ.
В заключение Джеймс Филлипс вбивает последние гвозди аргументации.
• Начавшаяся интеллектуальная революция делает это десятилетие самым важным в истории человечества.
• Текущий путь развития ИИ нерегулируемый, необъяснимый и небезопасный.
• Великобритания может направить развитие ИИ в выгодном направлении.
• Нынешнее научное руководство и институты растратили эту способность впустую в течение десятилетия.
• Наше преимущество испаряется в нынешней конкурентной среде.
И еще раз самое главное - для дальнейшего развития ИИ нужны мощнейшие суперкомпьютеры.
«К сожалению, в госсекторе Великобритании в настоящее время имеется менее 1000 первоклассных графических процессоров для ИИ. Это означает, что одна частная лаборатория в Калифорнии сейчас использует только для обучения одной модели, как минимум, в 25 раз больше общей доступной вычислительной мощности, через вся Великобритания».
Мне остается лишь напомнить о том, что я недавно писал - «отставание России от США в области ИИ уже колоссально, а через несколько лет оно увеличится до трёх километров».
Также см. мой пост о том, что будущее в руках тех, кто сможет платить по $100 млн за обучение одной модели.
#ИИ #HPC #AGI
Хаос революции или небывалое закручивание гаек - это зависит от того, в чьих руках будет ИИ через 5 лет.
В течение десятилетия на Земле будет создан ИИ, способный выполнять большую часть когнитивной работы, на которую способны люди.
Обеспечение безопасного для общества развития сверхмощного инструментария ИИ в течение ближайшего десятилетия должно быть высшим приоритетом ведущих государств мира и их общественных и политических институтов.
«История показывает, - когда силы вне правительства приобретают жесткую политическую власть, вы получаете: либо а) хаос революции, либо б) дикую гиперреакцию государства, направленную на возвращение себе власти.
Я не понимаю, чем должен руководствоваться Западный мир, пойдя на такой риск. Но он на этот риск идет!».
Так пишет исследователь ИИ и бывший спецсоветник по науке и технологиям премьер-министра Великобритании Джеймс Филлипс в воззвании к правительству своей страны, обеспокоенный тем, что европейские правительства уступают контроль за созданием AGI ряду субъектов частного бизнеса США.
«Такое развитие окажет беспрецедентное влияние на наше общество; «агентные» формы AGI могут также представлять собой экзистенциальную угроза нашей безопасности. Нынешний путь развития AGI по самой своей сути небезопасен» - пишет в своем воззвании Джеймс Филлипс.
Далее он предлагает 3 шага для сохранения демократического контроля за тем, каким будет будущее мира.
1. Закупить национальную инфраструктуру суперкомпьютеров ИИ, сравнимую с ведущими частными лабораториями США.
2. Создать консультативную группу исследователей, работающих на фронтире практики развития ИИ (а не академических ученых), чтобы определить основные исследовательские проекты ИИ для запуска в этой инфраструктуре.
3. Создайть элитную государственную исследовательскую лабораторию под руководством лидера с техническими навыками и предпринимательским опытом, чтобы разработать исследовательскую программу национального фронтира практики развития ИИ.
В заключение Джеймс Филлипс вбивает последние гвозди аргументации.
• Начавшаяся интеллектуальная революция делает это десятилетие самым важным в истории человечества.
• Текущий путь развития ИИ нерегулируемый, необъяснимый и небезопасный.
• Великобритания может направить развитие ИИ в выгодном направлении.
• Нынешнее научное руководство и институты растратили эту способность впустую в течение десятилетия.
• Наше преимущество испаряется в нынешней конкурентной среде.
И еще раз самое главное - для дальнейшего развития ИИ нужны мощнейшие суперкомпьютеры.
«К сожалению, в госсекторе Великобритании в настоящее время имеется менее 1000 первоклассных графических процессоров для ИИ. Это означает, что одна частная лаборатория в Калифорнии сейчас использует только для обучения одной модели, как минимум, в 25 раз больше общей доступной вычислительной мощности, через вся Великобритания».
Мне остается лишь напомнить о том, что я недавно писал - «отставание России от США в области ИИ уже колоссально, а через несколько лет оно увеличится до трёх километров».
Также см. мой пост о том, что будущее в руках тех, кто сможет платить по $100 млн за обучение одной модели.
#ИИ #HPC #AGI
James W. Phillips' Newsletter
Securing Liberal Democratic Control of AGI through UK Leadership
This was originally a piece co-written to influence policy makers, and had input from a range of people including senior frontier industry figures, former senior government advisers, and others who share the concerns raised in this piece. This is being published…
США наступили на дыхательный шланг китайского ИИ.
Хитрый, но изящный способ не дать Китаю догнать.
"Дальше сами!" - сказал полякам Сусанин по известной шуточной прибаутке.
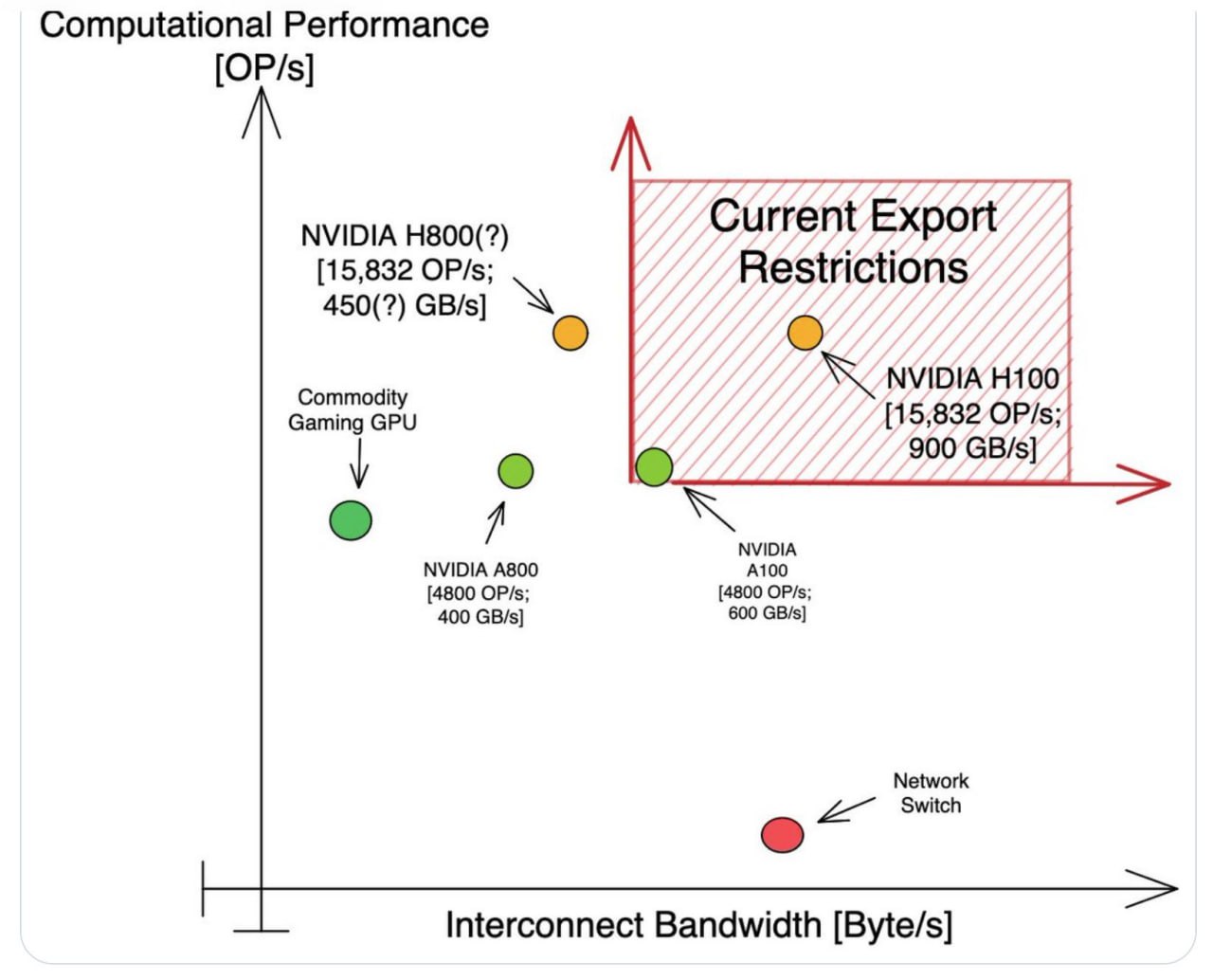
Примерно тот же смысл позавчерашнего объявления компании Nvidia о новой версии своего чипа H100 для экспорта в Китай. Теперь на чипе H800 будут работать крупнейшие проекты Китая в области ИИ, ведущиеся компаниями Alibaba, Baidu и Tencent.
Следуя экспортным ограничениям, установленным правительством США, Nvidia должна была урезать производительность поставляемых в Китай базовых чипов для ИИ-систем. Урезать нужно было на столько, чтобы
а) выбить Китай из конкурентной борьбы в области ИИ,
б) но при этом оставить крупнейших разработчиков ИИ в Китае привязанными к оборудованию, произведенному в США (до сих пор это было оборудование компании Nvidia).
Т.е. если бы вообще запретили поставки любых ИИ-чипов в Китай, то:
1) Nvidia понесла бы большие финансовые потери,
2) и, что самое главное, Китай просто бы сорвался с крючка, вынуждая своих ИИ-разработчиков от безысходности пытаться делать свои системы на китайских ИИ-чипах (сильно пока уступающих чипам Nvidia).
Поэтому Nvidia придумала хитрый, но изящный способ и в лужу сесть и зад не замочить:
• оставив производительность чипа (операции в сек) H800 такой же, как у H100,
• у H800 тупо вдвое урезали пропускную способность передачи данных (GB в сек)
– см. поясняющий рисунок от Леннарта Хайма.
Дальше сами крутитесь, - как бы говорит Nvidia словами Госдепа США.
А крутиться Китаю придется еще лет 5-7 (только тогда, по их планам, у Китая появится возможность производства у себя ИИ-чипов, конкурентных чипам Nvidia).
Есть, правда, еще вариант - забирать под себя производителя этих чипов Taiwan Semiconductor Manufacturing Co. (можно вместе с островом, но можно и без).
#ИИ #HPC #США #Китай #ЭкспортныйКонтроль
Хитрый, но изящный способ не дать Китаю догнать.
"Дальше сами!" - сказал полякам Сусанин по известной шуточной прибаутке.
Примерно тот же смысл позавчерашнего объявления компании Nvidia о новой версии своего чипа H100 для экспорта в Китай. Теперь на чипе H800 будут работать крупнейшие проекты Китая в области ИИ, ведущиеся компаниями Alibaba, Baidu и Tencent.
Следуя экспортным ограничениям, установленным правительством США, Nvidia должна была урезать производительность поставляемых в Китай базовых чипов для ИИ-систем. Урезать нужно было на столько, чтобы
а) выбить Китай из конкурентной борьбы в области ИИ,
б) но при этом оставить крупнейших разработчиков ИИ в Китае привязанными к оборудованию, произведенному в США (до сих пор это было оборудование компании Nvidia).
Т.е. если бы вообще запретили поставки любых ИИ-чипов в Китай, то:
1) Nvidia понесла бы большие финансовые потери,
2) и, что самое главное, Китай просто бы сорвался с крючка, вынуждая своих ИИ-разработчиков от безысходности пытаться делать свои системы на китайских ИИ-чипах (сильно пока уступающих чипам Nvidia).
Поэтому Nvidia придумала хитрый, но изящный способ и в лужу сесть и зад не замочить:
• оставив производительность чипа (операции в сек) H800 такой же, как у H100,
• у H800 тупо вдвое урезали пропускную способность передачи данных (GB в сек)
– см. поясняющий рисунок от Леннарта Хайма.
Дальше сами крутитесь, - как бы говорит Nvidia словами Госдепа США.
А крутиться Китаю придется еще лет 5-7 (только тогда, по их планам, у Китая появится возможность производства у себя ИИ-чипов, конкурентных чипам Nvidia).
Есть, правда, еще вариант - забирать под себя производителя этих чипов Taiwan Semiconductor Manufacturing Co. (можно вместе с островом, но можно и без).
#ИИ #HPC #США #Китай #ЭкспортныйКонтроль
{kind=link}