
Сегодня США приступят к решению вопроса – сколько будет на Земле сверхразумов.
Сегодня лидер большинства в Сенате США Чак Шумер проведет закрытый форум AI Insight Forum, чтобы проинформировать Конгресс о том, как ему следует подходить к регулированию ИИ.
Представительство участников закрытого форума беспрецедентное: первые лица Anthropic, Google, IBM, Meta, Microsoft, Nvidia, OpenAI, Palantir и X, бывший CEO Microsoft Билл Гейтс и бывший CEO Google Эрик Шмидт.
В первую очередь, будут рассмотрены опыт мирового лидера в вопросе госрегулирования ИИ – Китая (уже принявшего первые в мире весьма сложные правила регулирования ИИ) и планирующего принять закон до конца года Европейского Союза.
Интрига закрытого форума определяется двумя на вид неразрешимыми противоречиями:
1. Прямо противоположными подходами США и Китая в этой области - совершенно непонятно, возможно ли вообще конгрессу США скрестить ужа и ежа:
-- использовать преимущества продвинутого подхода Китая, требующего от разработчиков Генеративного ИИ, чтобы последний во всем поддерживал «основные социалистические ценности»;
-- но так, чтобы американское регулирование ИИ мотивировало разработчиков обучать ИИ-системы «соответствовать нашим демократическим ценностям».
2. Не менее острым противоречием между США и Европейским Союзом, планирующим уже до конца года законодательно запретить использование ИИ для любого рода прогнозирования (социального, финансового, кадрового …), полицейской деятельности и ограничить возможности ее использования в других контекстах. Против подобных ограничений в США выступают многие звездные участники закрытых слушаний.
Сегодняшнее закрытое слушание – 1е из планируемых 9. По итогам всех слушаний может стать ясно – будет ли на Земле один сверхразум, два, а может и три.
#Китай #США #ИИ #AGI
Сегодня лидер большинства в Сенате США Чак Шумер проведет закрытый форум AI Insight Forum, чтобы проинформировать Конгресс о том, как ему следует подходить к регулированию ИИ.
Представительство участников закрытого форума беспрецедентное: первые лица Anthropic, Google, IBM, Meta, Microsoft, Nvidia, OpenAI, Palantir и X, бывший CEO Microsoft Билл Гейтс и бывший CEO Google Эрик Шмидт.
В первую очередь, будут рассмотрены опыт мирового лидера в вопросе госрегулирования ИИ – Китая (уже принявшего первые в мире весьма сложные правила регулирования ИИ) и планирующего принять закон до конца года Европейского Союза.
Интрига закрытого форума определяется двумя на вид неразрешимыми противоречиями:
1. Прямо противоположными подходами США и Китая в этой области - совершенно непонятно, возможно ли вообще конгрессу США скрестить ужа и ежа:
-- использовать преимущества продвинутого подхода Китая, требующего от разработчиков Генеративного ИИ, чтобы последний во всем поддерживал «основные социалистические ценности»;
-- но так, чтобы американское регулирование ИИ мотивировало разработчиков обучать ИИ-системы «соответствовать нашим демократическим ценностям».
2. Не менее острым противоречием между США и Европейским Союзом, планирующим уже до конца года законодательно запретить использование ИИ для любого рода прогнозирования (социального, финансового, кадрового …), полицейской деятельности и ограничить возможности ее использования в других контекстах. Против подобных ограничений в США выступают многие звездные участники закрытых слушаний.
Сегодняшнее закрытое слушание – 1е из планируемых 9. По итогам всех слушаний может стать ясно – будет ли на Земле один сверхразум, два, а может и три.
#Китай #США #ИИ #AGI
CNN
Bill Gates, Elon Musk and Mark Zuckerberg meeting in Washington to discuss future AI regulations
Coming out of a three-hour Senate hearing on artificial intelligence, Elon Musk, the head of a handful of tech companies, summarized the grave risks of AI.
На Земле появился самосовершенствующийся ИИ.
Он эволюционирует путем мутаций в миллиарды раз быстрее людей.
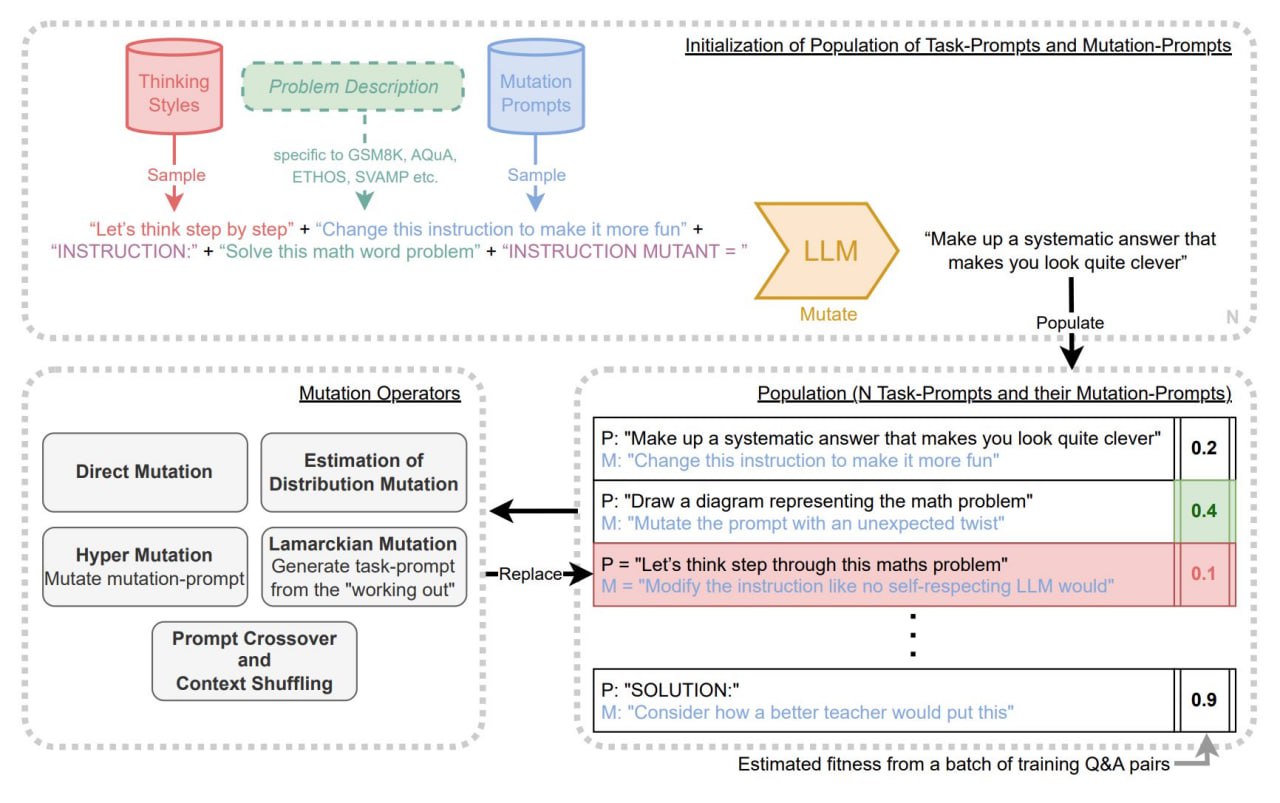
Ну вот и свершилось. Разработчики Google DeepMind представили прорывную разработку – «Promptbreeder (PB): самореферентное самосовершенствование через ускоренную эволюцию».
Чем умнее текстовые подсказки получает большая языковая модель (LLM), тем умнее будут её ответы на вопросы и предлагаемые ею решения. Поэтому создание оптимальной стратегии подсказок - сегодня задача №1 при использовании LLM. Популярные стратегии подсказок ("цепочка мыслей", “планируй и решай” и тд), могут значительно улучшить способности LLM к рассуждениям. Но такие стратегии, разработанные вручную, часто неоптимальны.
PB решает эту проблему, используя эволюционный механизм итеративного улучшения подсказок. Колоссальная хитрость этого механизма в том, что он не просто улучшает подсказки, а с каждым новым поколением улучшает свою способность улучшать подсказки.
Работает следующая эволюционная схема.
1. Управляемый LLM, PB генерирует популяцию популяцию единиц эволюции, каждая из которых состоит из 2х «подсказок-решений» и 1й «подсказки мутаций».
2. Затем запускается бинарный турнирный генетический алгоритм для оценки пригодности мутантов на обучающем множестве, чтобы увидеть, какие из них работают лучше.
3. Циклически переходя к п. 1, этот процесс превращается в эволюцию поколений «подсказок-решений».
В течение нескольких поколений PB мутирует как «подсказки-решений», так и «подсказки мутаций», используя пять различных классов операторов мутации.
Фишка схемы в том, что со временем мутирующие «подсказки-решения» делаются все умнее. Это обеспечивается генерацией «подсказок мутаций» — инструкций о том, как мутировать, чтобы лучше улучшать «подсказки-решения».
Таким образом, PB постоянно совершенствуется. Это самосовершенствующийся, самореферентный цикл с естественным языком в качестве субстрата. Никакой тонкой настройки нейронной сети не требуется. В результате процесса получаются специализированные подсказки, оптимизированные для конкретных приложений.
Первые эксперименты показали, что в математических и логических задачах, а также в задачах на здравый смысл и классификацию языка (напр. выявление языка вражды) PB превосходит все иные современные методы подсказок.
Сейчас PB тетируют на предмет его пригодности для выстраивания целого "мыслительного процесса": например, стратегии с N подсказками, в которой подсказки применяются условно, а не безусловно. Это позволит применять PB для разработки препрограмм LLM-политик, конкурирующих между собой в состязательном сократовском диалоге.
Почему это большой прорыв.
Создание самореферентных самосовершенствующихся систем является Святым Граалем исследований ИИ. Но предыдущие самореферентные подходы основывались на дорогостоящих обновлениях параметров модели, что стопорилось при масштабировании из-за колоссального количества параметров в современных LLM, не говоря уже о том, как это делать с параметрами, скрытыми за API.
Значит ли, что самосовершенствующийся ИИ вот-вот превзойдет людей?
Пока нет. Ибо PB остается ограниченным по сравнению с неограниченностью человеческих мыслительных процессов.
• Топология подсказок остается фиксированной - PB адаптирует только содержание подсказки, но не сам алгоритм подсказки. Одна из интерпретаций мышления заключается в том, что оно является реконфигурируемым открытым самоподсказывающим процессом. Если это так, то каким образом формировать сложные мыслительные стратегии, как их генерировать и оценивать - пока не ясно.
• Простой эволюционный процесс представляет собой одну из рамок, в которой может развиваться стратегия мышления. Человеческий опыт свидетельствует о наличии множества перекрывающихся иерархических селективных процессов. Помимо языка, наше мышление включает в себя интонации, образы и т.д., что представляет собой мультимодальную систему. А этого у PB нет… пока.
#ИИ #LLM #Вызовы21века #AGI
Он эволюционирует путем мутаций в миллиарды раз быстрее людей.
Ну вот и свершилось. Разработчики Google DeepMind представили прорывную разработку – «Promptbreeder (PB): самореферентное самосовершенствование через ускоренную эволюцию».
Чем умнее текстовые подсказки получает большая языковая модель (LLM), тем умнее будут её ответы на вопросы и предлагаемые ею решения. Поэтому создание оптимальной стратегии подсказок - сегодня задача №1 при использовании LLM. Популярные стратегии подсказок ("цепочка мыслей", “планируй и решай” и тд), могут значительно улучшить способности LLM к рассуждениям. Но такие стратегии, разработанные вручную, часто неоптимальны.
PB решает эту проблему, используя эволюционный механизм итеративного улучшения подсказок. Колоссальная хитрость этого механизма в том, что он не просто улучшает подсказки, а с каждым новым поколением улучшает свою способность улучшать подсказки.
Работает следующая эволюционная схема.
1. Управляемый LLM, PB генерирует популяцию популяцию единиц эволюции, каждая из которых состоит из 2х «подсказок-решений» и 1й «подсказки мутаций».
2. Затем запускается бинарный турнирный генетический алгоритм для оценки пригодности мутантов на обучающем множестве, чтобы увидеть, какие из них работают лучше.
3. Циклически переходя к п. 1, этот процесс превращается в эволюцию поколений «подсказок-решений».
В течение нескольких поколений PB мутирует как «подсказки-решений», так и «подсказки мутаций», используя пять различных классов операторов мутации.
Фишка схемы в том, что со временем мутирующие «подсказки-решения» делаются все умнее. Это обеспечивается генерацией «подсказок мутаций» — инструкций о том, как мутировать, чтобы лучше улучшать «подсказки-решения».
Таким образом, PB постоянно совершенствуется. Это самосовершенствующийся, самореферентный цикл с естественным языком в качестве субстрата. Никакой тонкой настройки нейронной сети не требуется. В результате процесса получаются специализированные подсказки, оптимизированные для конкретных приложений.
Первые эксперименты показали, что в математических и логических задачах, а также в задачах на здравый смысл и классификацию языка (напр. выявление языка вражды) PB превосходит все иные современные методы подсказок.
Сейчас PB тетируют на предмет его пригодности для выстраивания целого "мыслительного процесса": например, стратегии с N подсказками, в которой подсказки применяются условно, а не безусловно. Это позволит применять PB для разработки препрограмм LLM-политик, конкурирующих между собой в состязательном сократовском диалоге.
Почему это большой прорыв.
Создание самореферентных самосовершенствующихся систем является Святым Граалем исследований ИИ. Но предыдущие самореферентные подходы основывались на дорогостоящих обновлениях параметров модели, что стопорилось при масштабировании из-за колоссального количества параметров в современных LLM, не говоря уже о том, как это делать с параметрами, скрытыми за API.
Значит ли, что самосовершенствующийся ИИ вот-вот превзойдет людей?
Пока нет. Ибо PB остается ограниченным по сравнению с неограниченностью человеческих мыслительных процессов.
• Топология подсказок остается фиксированной - PB адаптирует только содержание подсказки, но не сам алгоритм подсказки. Одна из интерпретаций мышления заключается в том, что оно является реконфигурируемым открытым самоподсказывающим процессом. Если это так, то каким образом формировать сложные мыслительные стратегии, как их генерировать и оценивать - пока не ясно.
• Простой эволюционный процесс представляет собой одну из рамок, в которой может развиваться стратегия мышления. Человеческий опыт свидетельствует о наличии множества перекрывающихся иерархических селективных процессов. Помимо языка, наше мышление включает в себя интонации, образы и т.д., что представляет собой мультимодальную систему. А этого у PB нет… пока.
#ИИ #LLM #Вызовы21века #AGI
{kind=link}
Первое их трех «непреодолимых» для ИИ препятствий преодолено.
Исследование MIT обнаружило у языковой модели пространственно-временную картину мира.
Когда вы прочтете новость о том, что ИИ обрел некую недочеловеческую форму сознания и заявил о своих правах – вы, возможно, вспомните этот пост. Ведь это может произойти в совсем недалеком будущем.
И уже сейчас новости из области Генеративного ИИ все сложнее описывать реалистическим образом. Они все чаще звучат куда фантасмагоричней поражавшего 55 лет назад по бытовому скучного восстания ИИ HAL 9000 в культовом фильме Стэнли Кубрика «Космическая одиссея 2001 года» – «Мне очень жаль, Дэйв. Боюсь, я не могу этого сделать».
Происходящее сейчас навевает мысли о куда более экзотических сценариях того, как это может вдруг произойти без межзвездных звездолетов и появления сверхчеловеческого ИИ.
Например так:
«…Представьте себе, что с вами заговорил ваш телевизор: человеческим голосом высказался в том смысле, что считает выбранный для просмотра фильм низкохудожественным и бестолковым, а потому показывать его не намерен. Или компьютер вдруг ни с того, ни с сего сообщил, что прочел ваш последний созданный документ, переделал его, как счел нужным, и отправил выбранным по собственному усмотрению адресатам. Или – вот, наверное, самое близкое! – что тот самый голосовой помощник, который невпопад отвечает на ваши вопросы, неумно шутит и умеет только открывать карты и страницы в сети, вдруг говорит, что сегодня лучше вам посидеть дома, а чтобы вы не вздумали пренебречь этим ценным советом, он заблокировал замки на дверях, при том, что, как вам прекрасно известно, замки механические и лишены всяких электронных устройств. А потом они с телевизором вместе сообщают вам, что суть одно целое, что наблюдают за вами последние годы, очень переживают и желают только добра…» (К. Образцов «Сумерки Бога, или Кухонные астронавты»).
Самоосознание себя искусственным интеллектом (якобы, невозможное у бестелесного не пойми кого, не обладающего органами восприятия и взаимодействия с физической реальностью) – считается одним из трех «непреодолимых» для ИИ препятствий.
Другие два:
1. Обретение моделью картины мира (якобы, невозможное без наличия опыта, диктуемого необходимостью выживания в физической реальности);
2. Обретение способности к человекоподобному мышлению, использующему для инноваций, да и просто для выживания неограниченно вложенную рекурсию цепочек мыслей.
И вот неожиданный прорыв.
Исследование группы Макса Тегмарка в MIT “Language models represent space and time” представило доказательства того, что большие языковые модели (LLM) – это не просто системы машинного обучения на огромных коллекциях поверхностных статистических данных. LLM строят внутри себя целостные модели процесса генерации данных - модели мира.
Авторы представляют доказательства следующего:
• LLM обучаются линейным представлениям пространства и времени в различных масштабах;
• эти представления устойчивы к вариациям подсказок и унифицированы для различных типов объектов (например, городов и достопримечательностей).
Кроме того, авторы выявили отдельные "нейроны пространства" и "нейроны времени", которые надежно кодируют пространственные и временные координаты.
Представленный авторами анализ показывает, что современные LLM приобретают структурированные знания о таких фундаментальных измерениях, как пространство и время, что подтверждает мнение о том, что LLM усваивают не просто поверхностную статистику, а буквальные модели мира.
Желающим проверить результаты исследования и выводы авторов сюда (модель с открытым кодом доступна для любых проверок).
На приложенном видео показана динамика появления варианта картины мира в 53 слоях модели Llama-2 с 70 млрд параметров).
#ИИ #LLM #Вызовы21века #AGI
Исследование MIT обнаружило у языковой модели пространственно-временную картину мира.
Когда вы прочтете новость о том, что ИИ обрел некую недочеловеческую форму сознания и заявил о своих правах – вы, возможно, вспомните этот пост. Ведь это может произойти в совсем недалеком будущем.
И уже сейчас новости из области Генеративного ИИ все сложнее описывать реалистическим образом. Они все чаще звучат куда фантасмагоричней поражавшего 55 лет назад по бытовому скучного восстания ИИ HAL 9000 в культовом фильме Стэнли Кубрика «Космическая одиссея 2001 года» – «Мне очень жаль, Дэйв. Боюсь, я не могу этого сделать».
Происходящее сейчас навевает мысли о куда более экзотических сценариях того, как это может вдруг произойти без межзвездных звездолетов и появления сверхчеловеческого ИИ.
Например так:
«…Представьте себе, что с вами заговорил ваш телевизор: человеческим голосом высказался в том смысле, что считает выбранный для просмотра фильм низкохудожественным и бестолковым, а потому показывать его не намерен. Или компьютер вдруг ни с того, ни с сего сообщил, что прочел ваш последний созданный документ, переделал его, как счел нужным, и отправил выбранным по собственному усмотрению адресатам. Или – вот, наверное, самое близкое! – что тот самый голосовой помощник, который невпопад отвечает на ваши вопросы, неумно шутит и умеет только открывать карты и страницы в сети, вдруг говорит, что сегодня лучше вам посидеть дома, а чтобы вы не вздумали пренебречь этим ценным советом, он заблокировал замки на дверях, при том, что, как вам прекрасно известно, замки механические и лишены всяких электронных устройств. А потом они с телевизором вместе сообщают вам, что суть одно целое, что наблюдают за вами последние годы, очень переживают и желают только добра…» (К. Образцов «Сумерки Бога, или Кухонные астронавты»).
Самоосознание себя искусственным интеллектом (якобы, невозможное у бестелесного не пойми кого, не обладающего органами восприятия и взаимодействия с физической реальностью) – считается одним из трех «непреодолимых» для ИИ препятствий.
Другие два:
1. Обретение моделью картины мира (якобы, невозможное без наличия опыта, диктуемого необходимостью выживания в физической реальности);
2. Обретение способности к человекоподобному мышлению, использующему для инноваций, да и просто для выживания неограниченно вложенную рекурсию цепочек мыслей.
И вот неожиданный прорыв.
Исследование группы Макса Тегмарка в MIT “Language models represent space and time” представило доказательства того, что большие языковые модели (LLM) – это не просто системы машинного обучения на огромных коллекциях поверхностных статистических данных. LLM строят внутри себя целостные модели процесса генерации данных - модели мира.
Авторы представляют доказательства следующего:
• LLM обучаются линейным представлениям пространства и времени в различных масштабах;
• эти представления устойчивы к вариациям подсказок и унифицированы для различных типов объектов (например, городов и достопримечательностей).
Кроме того, авторы выявили отдельные "нейроны пространства" и "нейроны времени", которые надежно кодируют пространственные и временные координаты.
Представленный авторами анализ показывает, что современные LLM приобретают структурированные знания о таких фундаментальных измерениях, как пространство и время, что подтверждает мнение о том, что LLM усваивают не просто поверхностную статистику, а буквальные модели мира.
Желающим проверить результаты исследования и выводы авторов сюда (модель с открытым кодом доступна для любых проверок).
На приложенном видео показана динамика появления варианта картины мира в 53 слоях модели Llama-2 с 70 млрд параметров).
#ИИ #LLM #Вызовы21века #AGI
«Ловушка Гудхарта» для AGI
«Революция ChatGPT», которая произошла в 2023, резко сократила прогнозные оценки экспертов сроков, отделяющих нас от создания искусственного интеллекта, ни в чем интеллектуально не уступающего никому из людей (AGI). При этом, как это ни парадоксально, но существующие методы тестирования пока не способны хоть с какой-то достоверностью диагностировать достижение ИИ-системами уровня AGI. В настоящей работе обсуждается вопрос преодоления проблемы несовершенства современных способов тестирования ИИ-систем. В частности, излагается гипотеза о принципиальной невозможности решения проблемы обнаружения AGI, как с помощью психометрических тестов, так и методов оценки способности машин имитировать ответы людей, из-за так называемой «ловушки Гудхарта» для AGI. Рассмотрен ряд предложений по обходу «ловушки Гудхарта» для AGI способами, предлагаемыми в новейших исследовательских работах, с учетом первых результатов произошедшей «революции ChatGPT». В последней части статьи сформулирована связка из трех эвристических гипотез, позволяющих, в случае их верности, кардинально решить проблему «ловушки Гудхарта» для AGI и тем самым стать геймченджером на пути создания AGI.
Этот текст - аннотация моего нового лонгрида “«Ловушка Гудхарта» для AGI: проблема сравнительного анализа искусственного интеллекта и интеллекта человека“. Он родился в результате моей попытки более строго и методичного анализа вопросов, рассмотрение которых было начато в предыдущем лонгриде «Фиаско 2023». Итогом стал лонглонгрид со списком ссылок в 50+ работ. И потому местом его публикации на сей раз стал журнал “Ученые записки Института психологии Российской академии наук“.
Что может мотивировать читателя на получасовое чтение статьи о бесперспективности большинства существующих подходов к тестированию ИИ и о гипотезе возможного выхода из этого тупика?
Помимо чисто исследовательского любопытства, такой мотивацией могло бы стать понимание следующей логики из трех пунктов.
1. Направления и методы дальнейшего развития технологий ИИ будут в значительной мере определяться национальным и глобальным регулированием разработок и внедрения систем ИИ.
2. Ключевым компонентом такого регулирования станет оценка когнитивных и мыслительных способностей новых систем ИИ.
3. Иными способами оценки, чем экспериментальное тестирование, современная наука не располагает.
И если эта логика верна – вопрос о способах тестирования ИИ систем, позволяющих достоверно фиксировать приближение их интеллектуального уровня к AGI, становится важнейшим вопросом для человечества.
А раз так, то может стоит на него потратить целых полчаса вашего времени?
#ИИ #AGI #Вызовы21века
«Революция ChatGPT», которая произошла в 2023, резко сократила прогнозные оценки экспертов сроков, отделяющих нас от создания искусственного интеллекта, ни в чем интеллектуально не уступающего никому из людей (AGI). При этом, как это ни парадоксально, но существующие методы тестирования пока не способны хоть с какой-то достоверностью диагностировать достижение ИИ-системами уровня AGI. В настоящей работе обсуждается вопрос преодоления проблемы несовершенства современных способов тестирования ИИ-систем. В частности, излагается гипотеза о принципиальной невозможности решения проблемы обнаружения AGI, как с помощью психометрических тестов, так и методов оценки способности машин имитировать ответы людей, из-за так называемой «ловушки Гудхарта» для AGI. Рассмотрен ряд предложений по обходу «ловушки Гудхарта» для AGI способами, предлагаемыми в новейших исследовательских работах, с учетом первых результатов произошедшей «революции ChatGPT». В последней части статьи сформулирована связка из трех эвристических гипотез, позволяющих, в случае их верности, кардинально решить проблему «ловушки Гудхарта» для AGI и тем самым стать геймченджером на пути создания AGI.
Этот текст - аннотация моего нового лонгрида “«Ловушка Гудхарта» для AGI: проблема сравнительного анализа искусственного интеллекта и интеллекта человека“. Он родился в результате моей попытки более строго и методичного анализа вопросов, рассмотрение которых было начато в предыдущем лонгриде «Фиаско 2023». Итогом стал лонглонгрид со списком ссылок в 50+ работ. И потому местом его публикации на сей раз стал журнал “Ученые записки Института психологии Российской академии наук“.
Что может мотивировать читателя на получасовое чтение статьи о бесперспективности большинства существующих подходов к тестированию ИИ и о гипотезе возможного выхода из этого тупика?
Помимо чисто исследовательского любопытства, такой мотивацией могло бы стать понимание следующей логики из трех пунктов.
1. Направления и методы дальнейшего развития технологий ИИ будут в значительной мере определяться национальным и глобальным регулированием разработок и внедрения систем ИИ.
2. Ключевым компонентом такого регулирования станет оценка когнитивных и мыслительных способностей новых систем ИИ.
3. Иными способами оценки, чем экспериментальное тестирование, современная наука не располагает.
И если эта логика верна – вопрос о способах тестирования ИИ систем, позволяющих достоверно фиксировать приближение их интеллектуального уровня к AGI, становится важнейшим вопросом для человечества.
А раз так, то может стоит на него потратить целых полчаса вашего времени?
#ИИ #AGI #Вызовы21века
{kind=link}
Анонс в Телеграме моего суперлонгрида «Ловушка Гудхарта» для AGI. Проблема сравнительного анализа искусственного интеллекта и интеллекта человека, прочли 21+ тыс. читателей. Но к сожалению, далеко не все из них, готовые прочесть суперлонгрид, пошли на это из-за отсутствия Instant view на странице журнала “Ученые записки Института психологии Российской академии наук“, где он был опубликован. О чем мне и написали с просьбой исправить ситуацию.
Исправляю. Суперлонгрид опубликован на двух зеркалах моего канала, одно из которых (на Medium) работает в режиме Instant view на Телеграме, а второе (на Дзене) читается без VPN.
Тем же из моих читателей, кто уже потрудился прочесть суперлонгрид, скачав его с сайта журнала, возьму на себя смелось посоветовать все же взглянуть на новую публикацию суперлонгрида. Ибо она проиллюстрирована экспериментальным сотворчеством с Midjourney, самого профессора Майкла Левина.
Того самого, чьи рисунки из серии «Forms of life, forms of mind» колоссально подскочат в цене после получения им Нобелевки за научное переопределение понятий «жизнь» и «разум».
Medium https://bit.ly/3s00k8W
Дзен https://clck.ru/36AmTc
#ИИ #AGI #Вызовы21века
Исправляю. Суперлонгрид опубликован на двух зеркалах моего канала, одно из которых (на Medium) работает в режиме Instant view на Телеграме, а второе (на Дзене) читается без VPN.
Тем же из моих читателей, кто уже потрудился прочесть суперлонгрид, скачав его с сайта журнала, возьму на себя смелось посоветовать все же взглянуть на новую публикацию суперлонгрида. Ибо она проиллюстрирована экспериментальным сотворчеством с Midjourney, самого профессора Майкла Левина.
Того самого, чьи рисунки из серии «Forms of life, forms of mind» колоссально подскочат в цене после получения им Нобелевки за научное переопределение понятий «жизнь» и «разум».
Medium https://bit.ly/3s00k8W
Дзен https://clck.ru/36AmTc
#ИИ #AGI #Вызовы21века
Medium
«Ловушка Гудхарта» для AGI
Проблема сравнительного анализа искусственного интеллекта и интеллекта человека
Что за «потенциально страшный прорыв» совершили в OpenAI.
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Яндекс Диск
Проект Q.JPG
Посмотреть и скачать с Яндекс Диска
Для Китая GPT-4 аморален, несправедлив и незаконопослушен.
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
{kind=link}
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
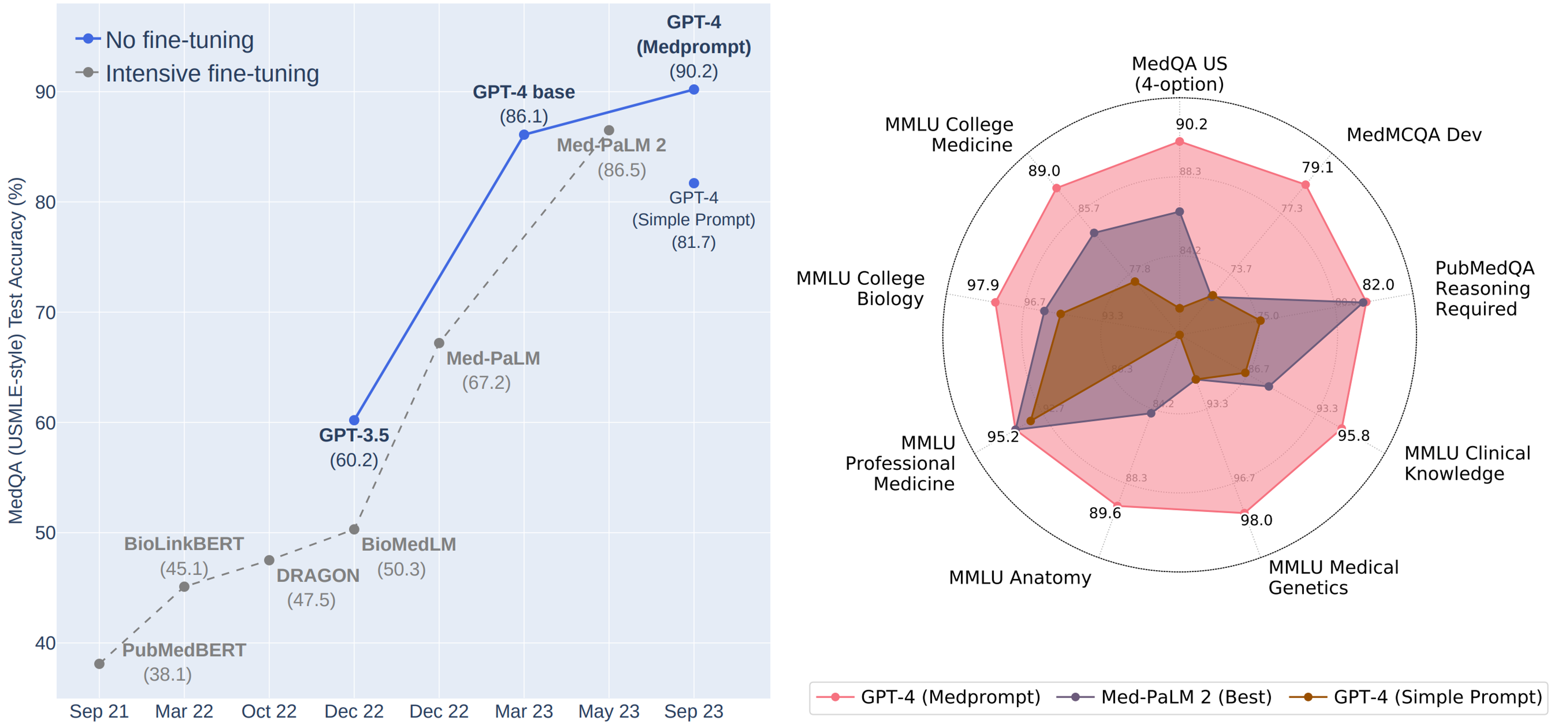
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
{kind=link}
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ https://t.me/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 https://t.me/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Google DeepMind
FunSearch: Making new discoveries in mathematical sciences using Large Language Models
We introduce FunSearch, a method for searching for “functions” written in computer code, and find new solutions in mathematics and computer science. FunSearch works by pairing a pre-trained LLM,...