
Алгоритмическое растление путем анестезии совести.
Алгокогнитивная культура способствует деградации морали
Новая статья в Nature, озаглавленная «Плохие машины портят добрую мораль» не упоминает термина алгокогнитивная культура (в германском институте им. Макса Планка этот термин еще не совсем прижился)), но рассказывает именно о её последствиях для отдельных людей и всего общества.
Авторы рассказывают, что «агенты ИИ» влияют на поведение людей способами, которые одновременно похожи и не похожи на то, как люди влияют друг на друга.
N.B. Авторы, следуя терминологическому мейнстриму, называют агентами ИИ «машины, работающие на основе ИИ». Но речь идет вовсе не о каких-то сверх-умных агентах, а о банальных анонимных алгоритмах машинного обучения поисковых, рекомендательных, социальных и профессиональных платформ и сервисов.
Одним из таких чисто алгоритмических влияний является растление общества, вследствие уникальной разлагающей сила алгоритмов. И поскольку об этом факторе влияния алгокогнитивной культуры я еще не писал, весьма рекомендую интересующимся вопросом прочесть работу Нильса Кёбиса, Жан-Франсуа Боннефона и Ияда Рахван (вход за пейвол по этой ссылке).
Авторы рассматривают четыре основные социальные роли, с помощью которых люди и алгоритмы могут влиять на этическое поведение:
• образец для подражания (role model) - решая, нарушать ли этические правила или придерживаться их, люди часто задумываются, как бы поступили на их месте их ролевые модели;
• советник (advisor) - люди могут оказывать более прямое развращающее влияние, чем ролевые модели, когда сами дают советы действовать неэтично, особенно, когда такие советы исходят от авторитетных фигур;
• активный партнер (active partner) – не менее чем неэтичными советниками, люди могут развращать друг друга, становясь партнерами в нарушении моральных норм;
• аутсорсер (delegate) – те, кому люди могут делегировать - передавать на выполнение неэтичные действия, как бы на аутсорсинг.
Ключевой вывод исследования таков.
✔️ Когда алгоритмы становятся инфлюенсерами (образцами для подражания или советниками), их развращающая сила не может превышать развращающую силу людей (но это лишь пока и, увы, довольно скоро пройдет).
✔️ Когда же алгоритмы выступают в роли потакателей (enablers) неэтичного поведения (будучи активным партнером или аутсорсером), они обладают уникальным потенциально особо опасным свойством.
Это свойство наиболее адекватно описывается термином «растление». Ибо оно позволяет людям получать выгоды от своих неэтичных действий и при этом чувствовать себя хорошо, не испытывая угрызений совести.
Примеров такой «анестезии совести» уже не счесть.
• студент, в партнерстве с GPT-3, замастыривающий фейковое эссе;
• ретейлер, передающий на аутсорсинг алгоритму процесс онлайн-прайсинга, приводящего к алгоритмическому сговору;
• кадровик, в партнерстве с алгоритмом оценки кандидата, отсеивающий «лицо кавказской национальности»;
• банковский клерк, передающий на аутсорсинг отказы в кредитовании многодетных семей;
• полицейский, юрист, врач, преподаватель, психоаналитик и т.д. и т.п.
Кроме того, мы даже не представляем себе потенциальные масштабы коррупции, которую могут индуцировать алгоритмы, в сравнении с коррупцией, вызванной действиями людей. Здесь вообще нет пока что каких-либо идей. Но есть подозрение, что алгоритмы могут любой вопрос «перетереть» и «порешать», совсем не отягощаясь моральными нормами.
Нужны эксперименты… Много экспериментов, прежде чем не только отдавать принятие решений алгоритмам, но и просто брать алгоритмы на роли партнеров и аутсорсеров.
И конечно же нужно обучать алгоритмы машинного обучения желательным поведенческим паттернам, а не слепо выбирать самые большие наборы данных, доступные для обучения.
Ну а в идеале, нужно разрабатывать иные методы машинного обучения для областей автоматизации неоднозначных решений, советов и результатов делегируемых действий (об этом, хорошо было бы написать отдельный пост).
#Мораль #АлгокогнитивнаяКультура #МашинноеОбучение #ИИ
Алгокогнитивная культура способствует деградации морали
Новая статья в Nature, озаглавленная «Плохие машины портят добрую мораль» не упоминает термина алгокогнитивная культура (в германском институте им. Макса Планка этот термин еще не совсем прижился)), но рассказывает именно о её последствиях для отдельных людей и всего общества.
Авторы рассказывают, что «агенты ИИ» влияют на поведение людей способами, которые одновременно похожи и не похожи на то, как люди влияют друг на друга.
N.B. Авторы, следуя терминологическому мейнстриму, называют агентами ИИ «машины, работающие на основе ИИ». Но речь идет вовсе не о каких-то сверх-умных агентах, а о банальных анонимных алгоритмах машинного обучения поисковых, рекомендательных, социальных и профессиональных платформ и сервисов.
Одним из таких чисто алгоритмических влияний является растление общества, вследствие уникальной разлагающей сила алгоритмов. И поскольку об этом факторе влияния алгокогнитивной культуры я еще не писал, весьма рекомендую интересующимся вопросом прочесть работу Нильса Кёбиса, Жан-Франсуа Боннефона и Ияда Рахван (вход за пейвол по этой ссылке).
Авторы рассматривают четыре основные социальные роли, с помощью которых люди и алгоритмы могут влиять на этическое поведение:
• образец для подражания (role model) - решая, нарушать ли этические правила или придерживаться их, люди часто задумываются, как бы поступили на их месте их ролевые модели;
• советник (advisor) - люди могут оказывать более прямое развращающее влияние, чем ролевые модели, когда сами дают советы действовать неэтично, особенно, когда такие советы исходят от авторитетных фигур;
• активный партнер (active partner) – не менее чем неэтичными советниками, люди могут развращать друг друга, становясь партнерами в нарушении моральных норм;
• аутсорсер (delegate) – те, кому люди могут делегировать - передавать на выполнение неэтичные действия, как бы на аутсорсинг.
Ключевой вывод исследования таков.
✔️ Когда алгоритмы становятся инфлюенсерами (образцами для подражания или советниками), их развращающая сила не может превышать развращающую силу людей (но это лишь пока и, увы, довольно скоро пройдет).
✔️ Когда же алгоритмы выступают в роли потакателей (enablers) неэтичного поведения (будучи активным партнером или аутсорсером), они обладают уникальным потенциально особо опасным свойством.
Это свойство наиболее адекватно описывается термином «растление». Ибо оно позволяет людям получать выгоды от своих неэтичных действий и при этом чувствовать себя хорошо, не испытывая угрызений совести.
Примеров такой «анестезии совести» уже не счесть.
• студент, в партнерстве с GPT-3, замастыривающий фейковое эссе;
• ретейлер, передающий на аутсорсинг алгоритму процесс онлайн-прайсинга, приводящего к алгоритмическому сговору;
• кадровик, в партнерстве с алгоритмом оценки кандидата, отсеивающий «лицо кавказской национальности»;
• банковский клерк, передающий на аутсорсинг отказы в кредитовании многодетных семей;
• полицейский, юрист, врач, преподаватель, психоаналитик и т.д. и т.п.
Кроме того, мы даже не представляем себе потенциальные масштабы коррупции, которую могут индуцировать алгоритмы, в сравнении с коррупцией, вызванной действиями людей. Здесь вообще нет пока что каких-либо идей. Но есть подозрение, что алгоритмы могут любой вопрос «перетереть» и «порешать», совсем не отягощаясь моральными нормами.
Нужны эксперименты… Много экспериментов, прежде чем не только отдавать принятие решений алгоритмам, но и просто брать алгоритмы на роли партнеров и аутсорсеров.
И конечно же нужно обучать алгоритмы машинного обучения желательным поведенческим паттернам, а не слепо выбирать самые большие наборы данных, доступные для обучения.
Ну а в идеале, нужно разрабатывать иные методы машинного обучения для областей автоматизации неоднозначных решений, советов и результатов делегируемых действий (об этом, хорошо было бы написать отдельный пост).
#Мораль #АлгокогнитивнаяКультура #МашинноеОбучение #ИИ
Nature
Bad machines corrupt good morals
Nature Human Behaviour - Köbis et al. outline how artificial intelligence (AI) agents can negatively influence human ethical behaviour. They discuss how this capacity of AI agents can cause...
Прорыв в ИИ может произойти уже до конца этого года.
Начинается всемирный поиск новых ИИ-моделей, в котором вы можете участвовать.
Речь идет об объявленном AIcrowd Facebook AI крауд-конкурсе проектирования и обучения альтернативных ИИ-агентов, работающих иначе, чем современный мейнстрим машинного обучения с подкреплением.
Недавно DeepMind объявил, что обучение с подкреплением — метод, когда ИИ-агент ничего не знает об окружающей среде, но может самообучаться, взаимодействуя с ней, - может позволить прорыв к ИИ человеческого уровня (AGI). Этот метод, действительно, весьма перспективен. Но он требует значительного объема вычислений и мощного компьютерного оборудования. А это, к сожалению, не очень подходит за пределами демонстрационных игр, когда цель – не удивить общественность, а решение практических задач в реальном мире.
Facebook решил попробовать обойти эту проблему, организовав всемирный поиск новых ИИ-моделей, позволяющих ИИ-агентам ориентироваться в сложных средах при низких вычислительных затратах.
В качестве супер-теста была выбрана NetHack — старая, но до сих пор одна из самых сложных игр. В ней игроки должны спуститься на 50+ уровней подземелья, чтобы найти магический амулет. Шансов выиграть в эту игру мало даже у ИИ-агентов, разгромивших людей в StarCraft II, Dota 2 и Minecraft. Ведь в этой игре игроки просто мрут, как мухи. А после каждой смерти подземелье полностью перестраивается, тем самым сводя почти что к нулю набранный опыт.
Единственный способ выиграть в таких адских условиях — каким-то образом суметь совместить нестандартное мышление, исследовательские навыки и удачу. Такой ИИ-агент должен уметь совмещать оптимальное применение уже имеющихся знаний со способностью исследовать совершенно неизученные области (т.е. сочетать exploitation & exploration).
Идея исследователей из Facebook проста. Авторитеты машинного обучения так пока и не преуспели в создании ИИ-агентов, способных учиться с малыми вычислительными затратами. Поэтому вместо того, чтобы самим пытаться поймать «золотую рыбку» прорывной ИИ-модели, Facebook решил провести открытый конкурс, пригласив участвовать всех желающих и предоставив каждому участнику высокотехнологическую «удочку». Ею будет специально разработанная учебная среда с открытым кодом - NetHack Learning Environment (NLE). Это масштабируемая, процедурно генерируемая, стохастическая, весьма сложная среда для исследования обучения с подкреплением в ходе игры ИИ-агента в NetHack.
Работая в среде NLE, участники смогут тратить больше времени на тестирование новых перспективных идей, а не на ожидание результатов длительных вычислений. Перед ними поставлена задача спроектировать и обучить своего агента каким угодно существующим или изобретенным способом - с машинным обучением или без него, с использованием любой внешней информации, любого метода обучения с любым вычислительным бюджетом.
Единственное требование – создать ИИ-агента, который может быть оценен жюри конкурса. О его результатах будут судить по тому, как часто этот агент выживает и поднимается из подземелья с Амулетом.
Среди альтернативных концепций создания моделей ИИ-агентов – имхо, самой перспективной является модель процесса активного вывода (active inference). Суть такого процесса в:
• статистической генерации предсказаний (бессознательных выводов об окружающем мире и самом себе на основе внутренней модели);
• проверке этих выводов на основе сенсорных данных;
• и постоянной минимизации ошибок предсказания.
Активный вывод и прогностическое кодирование, объединенные фундаментальным принципом свободной энергии Карла Фристона я называю «конституция биоматематики». Это, по сути, - высший закон, определяющий основной принцип жизни и разума (подробней см. мой пост).
А теперь о самом важном и интересном.
Дочитать (еще всего на 1 мин):
- на Medium https://bit.ly/3j9Qaf8
- на ЯДзен https://clck.ru/VgSju
#ИИ #МашинноеОбучение #ПринципСвободнойЭнергии #Фристон #АктивныйВывод
Начинается всемирный поиск новых ИИ-моделей, в котором вы можете участвовать.
Речь идет об объявленном AIcrowd Facebook AI крауд-конкурсе проектирования и обучения альтернативных ИИ-агентов, работающих иначе, чем современный мейнстрим машинного обучения с подкреплением.
Недавно DeepMind объявил, что обучение с подкреплением — метод, когда ИИ-агент ничего не знает об окружающей среде, но может самообучаться, взаимодействуя с ней, - может позволить прорыв к ИИ человеческого уровня (AGI). Этот метод, действительно, весьма перспективен. Но он требует значительного объема вычислений и мощного компьютерного оборудования. А это, к сожалению, не очень подходит за пределами демонстрационных игр, когда цель – не удивить общественность, а решение практических задач в реальном мире.
Facebook решил попробовать обойти эту проблему, организовав всемирный поиск новых ИИ-моделей, позволяющих ИИ-агентам ориентироваться в сложных средах при низких вычислительных затратах.
В качестве супер-теста была выбрана NetHack — старая, но до сих пор одна из самых сложных игр. В ней игроки должны спуститься на 50+ уровней подземелья, чтобы найти магический амулет. Шансов выиграть в эту игру мало даже у ИИ-агентов, разгромивших людей в StarCraft II, Dota 2 и Minecraft. Ведь в этой игре игроки просто мрут, как мухи. А после каждой смерти подземелье полностью перестраивается, тем самым сводя почти что к нулю набранный опыт.
Единственный способ выиграть в таких адских условиях — каким-то образом суметь совместить нестандартное мышление, исследовательские навыки и удачу. Такой ИИ-агент должен уметь совмещать оптимальное применение уже имеющихся знаний со способностью исследовать совершенно неизученные области (т.е. сочетать exploitation & exploration).
Идея исследователей из Facebook проста. Авторитеты машинного обучения так пока и не преуспели в создании ИИ-агентов, способных учиться с малыми вычислительными затратами. Поэтому вместо того, чтобы самим пытаться поймать «золотую рыбку» прорывной ИИ-модели, Facebook решил провести открытый конкурс, пригласив участвовать всех желающих и предоставив каждому участнику высокотехнологическую «удочку». Ею будет специально разработанная учебная среда с открытым кодом - NetHack Learning Environment (NLE). Это масштабируемая, процедурно генерируемая, стохастическая, весьма сложная среда для исследования обучения с подкреплением в ходе игры ИИ-агента в NetHack.
Работая в среде NLE, участники смогут тратить больше времени на тестирование новых перспективных идей, а не на ожидание результатов длительных вычислений. Перед ними поставлена задача спроектировать и обучить своего агента каким угодно существующим или изобретенным способом - с машинным обучением или без него, с использованием любой внешней информации, любого метода обучения с любым вычислительным бюджетом.
Единственное требование – создать ИИ-агента, который может быть оценен жюри конкурса. О его результатах будут судить по тому, как часто этот агент выживает и поднимается из подземелья с Амулетом.
Среди альтернативных концепций создания моделей ИИ-агентов – имхо, самой перспективной является модель процесса активного вывода (active inference). Суть такого процесса в:
• статистической генерации предсказаний (бессознательных выводов об окружающем мире и самом себе на основе внутренней модели);
• проверке этих выводов на основе сенсорных данных;
• и постоянной минимизации ошибок предсказания.
Активный вывод и прогностическое кодирование, объединенные фундаментальным принципом свободной энергии Карла Фристона я называю «конституция биоматематики». Это, по сути, - высший закон, определяющий основной принцип жизни и разума (подробней см. мой пост).
А теперь о самом важном и интересном.
Дочитать (еще всего на 1 мин):
- на Medium https://bit.ly/3j9Qaf8
- на ЯДзен https://clck.ru/VgSju
#ИИ #МашинноеОбучение #ПринципСвободнойЭнергии #Фристон #АктивныйВывод
{kind=link}
Обнаружен непреодолимый риск использования ИИ в медицине.
Обладающий недоступным для людей знанием ИИ потенциально опасен.
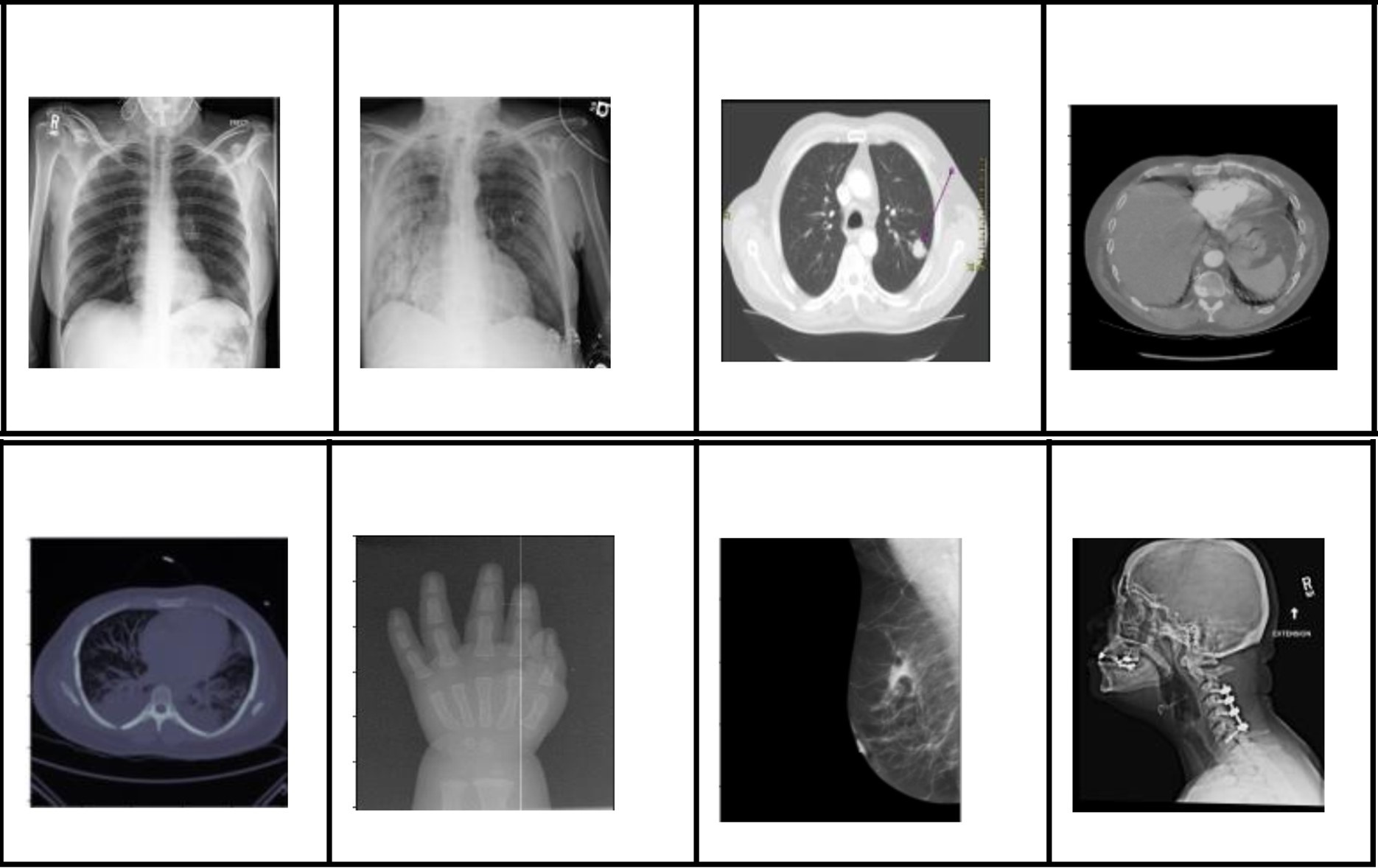
Посмотрите на рисунок с примерами различных медицинский изображений.
Сможете по ним определить расовую принадлежность пациента?
Увы, но даже самый опытный рентгенолог на Земле не в состоянии это сделать. А ИИ делает это запросто.
Из этого, казалось бы, не страшного факта (ведь никто не заморачивается от того, что ИИ, например, лучше людей играет в шахматы) можно прийти к выводу о серьезной опасности использования ИИ в задачах медицинской визуализации.
Логика здесь такова.
1) Распознавание медицинских изображений при принятии диагностических и лечебных решений – это одна из самых массовых и перспективных областей прикладного использования систем машинного обучения (далее ИИ).
2) Попытки использования ИИ для принятия решений в широком спектре применений, основанных на суждениях о людях (напр., социальные, кадровые, финансовые, полицейские системы оценки людей), столкнулись с серьезной проблемой расовой предвзятости ИИ, обусловленной данными, на которых эти ИИ учили.
3) В контексте 1 и 2, новое авторитетное совместное исследование 15 медицинских центров США, Канады, Австралии и Тайваня вызывает шок и потрясение.
Его выводы таковы:
– ИИ запросто учится распознавать расовую принадлежность пациентов практически по любым медицинским изображениям, и это прямой путь для воспроизведения или усугубления расовой дискриминации в медицинской практике;
– эксперты - люди не понимают, как ИИ это делают, ибо просто физически не видят на изображениях каких-либо маркеров национальной принадлежности; из чего следует, что человеческий надзор за такими ИИ для распознавания и смягчения данной проблемы имеет (мягко говоря) ограниченное применение, а по сути – человеческий надзор здесь невозможен;
– это создает огромный риск для развертываний практически всех (!) моделей ИИ в области медицинской визуализации: если ИИ «тайно» полагался на свою способность определять расовую принадлежность для принятия медицинских решений, но при этом некорректно (предвзято) провел классификацию (например, чернокожих пациентов), клинические рентгенологи (которые, как правило, не имеют доступа к расовой демографической информации) не смогут это увидеть и исправить.
Результаты данного исследования в общем контексте прикладного использования ИИ для принятия решений звучат почти как приговор:
Любой ИИ, обладающий недоступным для людей знанием, потенциально чрезвычайно опасен и потому не должен использоваться при принятии ответственных решений.
Но ведь именно в таких, недоступных нам знаниях и заключается наивысшая ценность ИИ. В противном случае, ИИ превратится просто в «интеллектуальный экскаватор», облегчающий людям процесс «интеллектуального копания» в проблемах при принятии решений.
И по этой причине, обнаруженным риском, скорее всего, пренебрегут, забив на непредсказуемые последствия.
https://arxiv.org/abs/2107.10356
#ИИ #МашинноеОбучение #ГлобальныеРиски
Обладающий недоступным для людей знанием ИИ потенциально опасен.
Посмотрите на рисунок с примерами различных медицинский изображений.
Сможете по ним определить расовую принадлежность пациента?
Увы, но даже самый опытный рентгенолог на Земле не в состоянии это сделать. А ИИ делает это запросто.
Из этого, казалось бы, не страшного факта (ведь никто не заморачивается от того, что ИИ, например, лучше людей играет в шахматы) можно прийти к выводу о серьезной опасности использования ИИ в задачах медицинской визуализации.
Логика здесь такова.
1) Распознавание медицинских изображений при принятии диагностических и лечебных решений – это одна из самых массовых и перспективных областей прикладного использования систем машинного обучения (далее ИИ).
2) Попытки использования ИИ для принятия решений в широком спектре применений, основанных на суждениях о людях (напр., социальные, кадровые, финансовые, полицейские системы оценки людей), столкнулись с серьезной проблемой расовой предвзятости ИИ, обусловленной данными, на которых эти ИИ учили.
3) В контексте 1 и 2, новое авторитетное совместное исследование 15 медицинских центров США, Канады, Австралии и Тайваня вызывает шок и потрясение.
Его выводы таковы:
– ИИ запросто учится распознавать расовую принадлежность пациентов практически по любым медицинским изображениям, и это прямой путь для воспроизведения или усугубления расовой дискриминации в медицинской практике;
– эксперты - люди не понимают, как ИИ это делают, ибо просто физически не видят на изображениях каких-либо маркеров национальной принадлежности; из чего следует, что человеческий надзор за такими ИИ для распознавания и смягчения данной проблемы имеет (мягко говоря) ограниченное применение, а по сути – человеческий надзор здесь невозможен;
– это создает огромный риск для развертываний практически всех (!) моделей ИИ в области медицинской визуализации: если ИИ «тайно» полагался на свою способность определять расовую принадлежность для принятия медицинских решений, но при этом некорректно (предвзято) провел классификацию (например, чернокожих пациентов), клинические рентгенологи (которые, как правило, не имеют доступа к расовой демографической информации) не смогут это увидеть и исправить.
Результаты данного исследования в общем контексте прикладного использования ИИ для принятия решений звучат почти как приговор:
Любой ИИ, обладающий недоступным для людей знанием, потенциально чрезвычайно опасен и потому не должен использоваться при принятии ответственных решений.
Но ведь именно в таких, недоступных нам знаниях и заключается наивысшая ценность ИИ. В противном случае, ИИ превратится просто в «интеллектуальный экскаватор», облегчающий людям процесс «интеллектуального копания» в проблемах при принятии решений.
И по этой причине, обнаруженным риском, скорее всего, пренебрегут, забив на непредсказуемые последствия.
https://arxiv.org/abs/2107.10356
#ИИ #МашинноеОбучение #ГлобальныеРиски
{kind=link}
Фиаско ИИ против COVID-19.
За 1,5 года созданы сотни ИИ-инструментов. Ни один не помог.
Согласно победным реляциям в медиа:
- «ИИ на треть сокращает время для диагностики COVID-19 на КТ-снимках»,
- «ИИ успешно прогнозирует риск ухудшения состояния заболевших COVID в приемных отделениях стационаров»,
- «ИИ научился диагностировать коронавирус по кашлю» и т.д.
Согласно научным отчетам и статьям об исследованиях, опубликованных в рецензируемых изданиях:
✔️ ИИ-инструменты практически не оказали никакого влияния в борьбе COVID-19 – отчет The Alan Turing Institute (1)
✔️ Ни один из сотен ИИ-инструментов прогнозирования COVID-19 не пригоден для клинического использования - ревю в British Medical Journal (2)
✔️ Ни одна из ИИ-моделей для обнаружения и прогнозирования COVID-19 с помощью рентгенограмм грудной клетки и компьютерной томографии не подходит для клинического использования из-за методологических недостатков и / или лежащих в основе систематических ошибок - ревю в Nature Machine Intelligence (3).
✔️ Эта пандемия стала большим испытанием для медицинского ИИ, и он не прошел это испытание. Вместо этого, пандемия привлекла внимание к сущностным проблемам медицинского ИИ, на которые мы уже не первый год закрываем глаза - MIT TechnologyReview (4)
Что пошло не так
1. Низкое качество данных (вкл. «наборы данных Франкенштейна» - когда данные из нескольких источников могут содержать дубликаты и тестирование ведется на тех же данных, на которых ИИ-инструмент был обучен)
Например:
А) Данные сканирования грудной клетки детей, у которых не было ковида, в качестве примеров того, как выглядят случаи не-ковида.
Однако, в результате ИИ научился определять не ковид, а детей.
Б) Данные сканирования включали пациентов в лежачем положении (с большей вероятностью эти пациенты были серьезно больны).
В результате ИИ научился неправильно предсказывать серьезность риска коронавируса, исходя из положения человека (а если пациент стоял, то серьезность поражение лёгких ИИ просто игнорировал).
В. ИИ научился ориентироваться на шрифт текста, используемый разными больницами для маркировки сканированных изображений.
В результате шрифты из больниц с более серьезной нагрузкой стали предикторами риска заражения коронавирусом.
2. Предвзятость инкорпорации (предвзятость вследствие маркировки данных)
Например:
Медицинские снимки помечаются в соответствии с тем, как их идентифицировал рентгенолог.
Результат этого включает любые предубеждения конкретных врачей, выдавая это в наборе данных за истину (надо было бы маркировать медицинское сканирование результатом теста ПЦР, а не мнением одного врача, но кто ж это делает).
3. У исследователей нет никаких стимулов делиться информацией (данными и моделями) – примеры см. в источниках.
4. Почти все ИИ-инструменты разрабатываются либо исследователями ИИ, которым не хватает медицинских знаний для выявления недостатков в данных, либо медиками, которым не хватает математических навыков, чтобы компенсировать эти недостатки – примеры см. в источниках.
Общий итог
Фиаско ИИ против COVID-19 лишь усугубило уже понятую главную проблему медицинского ИИ – используемые ИИ-инструменты должны объяснять логику, лежащую в основе их решений (5).
И это, увы, приближает новую «зиму ИИ».
Источники:
1, 2, 3, 4, 5
Фото В. Новикова. Пресс-служба Мэра и Правительства Москвы
#ИИ #МашинноеОбучение #Медицина
За 1,5 года созданы сотни ИИ-инструментов. Ни один не помог.
Согласно победным реляциям в медиа:
- «ИИ на треть сокращает время для диагностики COVID-19 на КТ-снимках»,
- «ИИ успешно прогнозирует риск ухудшения состояния заболевших COVID в приемных отделениях стационаров»,
- «ИИ научился диагностировать коронавирус по кашлю» и т.д.
Согласно научным отчетам и статьям об исследованиях, опубликованных в рецензируемых изданиях:
✔️ ИИ-инструменты практически не оказали никакого влияния в борьбе COVID-19 – отчет The Alan Turing Institute (1)
✔️ Ни один из сотен ИИ-инструментов прогнозирования COVID-19 не пригоден для клинического использования - ревю в British Medical Journal (2)
✔️ Ни одна из ИИ-моделей для обнаружения и прогнозирования COVID-19 с помощью рентгенограмм грудной клетки и компьютерной томографии не подходит для клинического использования из-за методологических недостатков и / или лежащих в основе систематических ошибок - ревю в Nature Machine Intelligence (3).
✔️ Эта пандемия стала большим испытанием для медицинского ИИ, и он не прошел это испытание. Вместо этого, пандемия привлекла внимание к сущностным проблемам медицинского ИИ, на которые мы уже не первый год закрываем глаза - MIT TechnologyReview (4)
Что пошло не так
1. Низкое качество данных (вкл. «наборы данных Франкенштейна» - когда данные из нескольких источников могут содержать дубликаты и тестирование ведется на тех же данных, на которых ИИ-инструмент был обучен)
Например:
А) Данные сканирования грудной клетки детей, у которых не было ковида, в качестве примеров того, как выглядят случаи не-ковида.
Однако, в результате ИИ научился определять не ковид, а детей.
Б) Данные сканирования включали пациентов в лежачем положении (с большей вероятностью эти пациенты были серьезно больны).
В результате ИИ научился неправильно предсказывать серьезность риска коронавируса, исходя из положения человека (а если пациент стоял, то серьезность поражение лёгких ИИ просто игнорировал).
В. ИИ научился ориентироваться на шрифт текста, используемый разными больницами для маркировки сканированных изображений.
В результате шрифты из больниц с более серьезной нагрузкой стали предикторами риска заражения коронавирусом.
2. Предвзятость инкорпорации (предвзятость вследствие маркировки данных)
Например:
Медицинские снимки помечаются в соответствии с тем, как их идентифицировал рентгенолог.
Результат этого включает любые предубеждения конкретных врачей, выдавая это в наборе данных за истину (надо было бы маркировать медицинское сканирование результатом теста ПЦР, а не мнением одного врача, но кто ж это делает).
3. У исследователей нет никаких стимулов делиться информацией (данными и моделями) – примеры см. в источниках.
4. Почти все ИИ-инструменты разрабатываются либо исследователями ИИ, которым не хватает медицинских знаний для выявления недостатков в данных, либо медиками, которым не хватает математических навыков, чтобы компенсировать эти недостатки – примеры см. в источниках.
Общий итог
Фиаско ИИ против COVID-19 лишь усугубило уже понятую главную проблему медицинского ИИ – используемые ИИ-инструменты должны объяснять логику, лежащую в основе их решений (5).
И это, увы, приближает новую «зиму ИИ».
Источники:
1, 2, 3, 4, 5
Фото В. Новикова. Пресс-служба Мэра и Правительства Москвы
#ИИ #МашинноеОбучение #Медицина
{kind=link}
Инструменты с лицензией на убийство.
Что общего у медицинского ИИ с автономным оружием.
Мои посты о неудачах медицинского ИИ вызвали два типа реакций (в духе стакан наполовину пуст или полон).
— Стакан наполовину пуст:
«В начале пандемии казалось, что пробил звездный час искусственного интеллекта в медицине. Но внезапно выясняется, что все не так просто, и пока еще человек, которого сначала долго учили медицине, а потом он еще много лет практиковался в своем деле, все еще лучше ИИ, которого обучил за пару месяцев непонятно кто на первых попавшихся данных».
— Стакан наполовину полон:
«Машинное обучение ещё не созрело для использования непрофессионалами, а хорошие специалисты по машинному обучению просто пока не работают над задачами про COVID».
И то, и другое верно.
Но такая трактовка вопроса о рисках медицинского ИИ - лишь вершина айсберга, закрывающего собой главную проблему: отсутствие консенсуса в ответах на следующие два вопроса.
✔️ Медицинский ИИ – это лишь инструмент врача или он может сам принимать важные решения?
✔️ Можно ли принимать важные решения, не обладая пониманием, а лишь из анализа статистики?
Сравним два кейса: медицинский ИИ и автономное оружие.
Дочитать (еще 3 мин.)
- на Medium https://bit.ly/3xsmqNY
- на Яндекс Дзен https://clck.ru/WeAnN
#ИИ #МашинноеОбучение #Медицина
Что общего у медицинского ИИ с автономным оружием.
Мои посты о неудачах медицинского ИИ вызвали два типа реакций (в духе стакан наполовину пуст или полон).
— Стакан наполовину пуст:
«В начале пандемии казалось, что пробил звездный час искусственного интеллекта в медицине. Но внезапно выясняется, что все не так просто, и пока еще человек, которого сначала долго учили медицине, а потом он еще много лет практиковался в своем деле, все еще лучше ИИ, которого обучил за пару месяцев непонятно кто на первых попавшихся данных».
— Стакан наполовину полон:
«Машинное обучение ещё не созрело для использования непрофессионалами, а хорошие специалисты по машинному обучению просто пока не работают над задачами про COVID».
И то, и другое верно.
Но такая трактовка вопроса о рисках медицинского ИИ - лишь вершина айсберга, закрывающего собой главную проблему: отсутствие консенсуса в ответах на следующие два вопроса.
✔️ Медицинский ИИ – это лишь инструмент врача или он может сам принимать важные решения?
✔️ Можно ли принимать важные решения, не обладая пониманием, а лишь из анализа статистики?
Сравним два кейса: медицинский ИИ и автономное оружие.
Дочитать (еще 3 мин.)
- на Medium https://bit.ly/3xsmqNY
- на Яндекс Дзен https://clck.ru/WeAnN
#ИИ #МашинноеОбучение #Медицина
Medium
Инструменты с лицензией на убийство
Что общего у медицинского ИИ с автономным оружием
Создана энергетическая модель понимания ИИ сложных сцен.
Это еще не человек, но уже и не совсем машина, ибо кое-что понимает.
Современный ИИ водит авто лучше большинства людей. Но при этом не понимает ничего из того что видит. ИИ-автопилот способен аккуратно обогнать грузовик, но не в состоянии по вашей команде «ехать за грузовиком с красной кабиной». Причина в том, что ИИ-автопилот научили ориентироваться среди объектов, встречающихся на дорогах, но он не понимает композитной структуры окружающего мира: их взаиморасположение, взаимосвязь и т.д. Из-за этого он не понимает, что это грузовик, у него есть кабина, она имеет цвет и может быть красной.
Есть два способа проверить понимание ИИ композитной структуры окружающего мира:
• Visual Relation Understanding: предлагать ИИ описать на естественном языке, что он видит;
• Language Guided Scene Generation: предлагать ему сгенерировать изображение сцен по их описанию на естественном языке.
Например, «понимающая» окружающий мир умная колонка со встроенной камерой может, на ваш вопрос «как расставлена мебель в комнате», ответить что-то типа: слева у окна письменный стол, а перед ним стул, справа книжный шкаф, а за ним этажерка, на окне бежевые шторы, а на подоконнике цветок в горшке.
Или, например, она способна сгенерировать верную 3D картинку по вашему описанию: на дворе трава, а на траве дрова.
Умеющему сделать такое ИИ будет еще далеко до человеческого понимания мироустройства. Но и сказать, что он совсем не понимает, как устроен окружающий его мир, уже будет не справедливо.
Новый весьма оригинальный способ обучения ИИ пониманию сложных композитных сцен из многих предметов и их взаимоотношений описан в только что опубликованной работе Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) MIT. Способ основан на «энергетической модели»: описание реляционной сцены отношений объектов, как произведение отдельных распределений вероятностей отношений между ними, причем каждое отдельное отношение определяется на изображении своим распределением вероятностей. Такая композиция позволяет моделировать взаимодействия между несколькими отношениями (популярно, научно).
Новый способ скоро позволит ИИ строить сцены по описаниям типа «на златом крыльце сидели: царь, царевич, король, королевич, сапожник, портной». И совсем не за горами понимание ИИ фраз типа «графиня изменившимся лицом бежит пруду».
Вместе с тем, даже столь обещающие перспективы «энергетической модели» не позволяют надеяться на понимание ИИ фраз типа «на меня наставлен сумрак ночи тысячью биноклей на оси». Ибо здесь, как с аффордансами, - проблема не в неисчислимости вариантов объектов и их отношений, а в неопределенности этих отношений (см. здесь). Это значит, что пока Борис Пастернак не создал этих отношений между объектами: «сумрак ночи», «тысяча биноклей» да еще и «на оси» в контексте «ощущения неотвратимости трагедии», - они просто не существуют в нашем мире.
И даже если они существуют в каком-то из иных миров Метаверса, люди уровня Бориса Пастернака умеют их оттуда извлекать, а алгоритмы ИИ – нет (т.к. преодолеть неопределенность с помощью вычислений нельзя).
#ИИ #МашинноеОбучение #Аффорданс
Это еще не человек, но уже и не совсем машина, ибо кое-что понимает.
Современный ИИ водит авто лучше большинства людей. Но при этом не понимает ничего из того что видит. ИИ-автопилот способен аккуратно обогнать грузовик, но не в состоянии по вашей команде «ехать за грузовиком с красной кабиной». Причина в том, что ИИ-автопилот научили ориентироваться среди объектов, встречающихся на дорогах, но он не понимает композитной структуры окружающего мира: их взаиморасположение, взаимосвязь и т.д. Из-за этого он не понимает, что это грузовик, у него есть кабина, она имеет цвет и может быть красной.
Есть два способа проверить понимание ИИ композитной структуры окружающего мира:
• Visual Relation Understanding: предлагать ИИ описать на естественном языке, что он видит;
• Language Guided Scene Generation: предлагать ему сгенерировать изображение сцен по их описанию на естественном языке.
Например, «понимающая» окружающий мир умная колонка со встроенной камерой может, на ваш вопрос «как расставлена мебель в комнате», ответить что-то типа: слева у окна письменный стол, а перед ним стул, справа книжный шкаф, а за ним этажерка, на окне бежевые шторы, а на подоконнике цветок в горшке.
Или, например, она способна сгенерировать верную 3D картинку по вашему описанию: на дворе трава, а на траве дрова.
Умеющему сделать такое ИИ будет еще далеко до человеческого понимания мироустройства. Но и сказать, что он совсем не понимает, как устроен окружающий его мир, уже будет не справедливо.
Новый весьма оригинальный способ обучения ИИ пониманию сложных композитных сцен из многих предметов и их взаимоотношений описан в только что опубликованной работе Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) MIT. Способ основан на «энергетической модели»: описание реляционной сцены отношений объектов, как произведение отдельных распределений вероятностей отношений между ними, причем каждое отдельное отношение определяется на изображении своим распределением вероятностей. Такая композиция позволяет моделировать взаимодействия между несколькими отношениями (популярно, научно).
Новый способ скоро позволит ИИ строить сцены по описаниям типа «на златом крыльце сидели: царь, царевич, король, королевич, сапожник, портной». И совсем не за горами понимание ИИ фраз типа «графиня изменившимся лицом бежит пруду».
Вместе с тем, даже столь обещающие перспективы «энергетической модели» не позволяют надеяться на понимание ИИ фраз типа «на меня наставлен сумрак ночи тысячью биноклей на оси». Ибо здесь, как с аффордансами, - проблема не в неисчислимости вариантов объектов и их отношений, а в неопределенности этих отношений (см. здесь). Это значит, что пока Борис Пастернак не создал этих отношений между объектами: «сумрак ночи», «тысяча биноклей» да еще и «на оси» в контексте «ощущения неотвратимости трагедии», - они просто не существуют в нашем мире.
И даже если они существуют в каком-то из иных миров Метаверса, люди уровня Бориса Пастернака умеют их оттуда извлекать, а алгоритмы ИИ – нет (т.к. преодолеть неопределенность с помощью вычислений нельзя).
#ИИ #МашинноеОбучение #Аффорданс
SciTechDaily
Artificial Intelligence That Understands Object Relationships – Enabling Machines To Learn More Like Humans Do
A new machine-learning model could enable robots to understand interactions in the world in the way humans do. When humans look at a scene, they see objects and the relationships between them. On top of your desk, there might be a laptop that is sitting to…
Ловушка ЕГЭ для обучения машин еще опасней, чем для людей.
Тед Чан о невозможности создать AGI, пренебрегая законами Гудхарта и Кэмпбелла.
Сегодня в 19:10 по Москве, возможно, лучший фантаст современности Тед Чан расскажет на семинаре ICLR 2022 («От клеток к социумам: коллективное обучение в разных масштабах») о своем видении перспектив цифрового образования для искусственных форм жизни. А этот мой пост – одновременно тизер и резюме предстоящего выступления Теда Чана.
Не удивляйтесь, что 1м из приглашенных спикеров престижного семинара с участием звезд междисциплинарной науки Дэвида Волперта, Михаила (ныне Майкла) Левина и Джессики Флак (все трое – многократные герои моих постов), будет писатель-фантаст. Это вполне заслуженно. Ибо доклад Чана будет развитием идей ставшей знаменитой на весь мир новеллы «Жизненный цикл программных объектов», признаваемой многими ИИ-миждисциплинарщиками мира самым глубоким и проникновенным описанием принципиальной сложности создания человекоподобного ИИ (AGI).
Продолжить чтение (еще 3 мин):
- на Medium https://bit.ly/37MjKEs
- на Яндекс Дзен https://clck.ru/ggnEA
#AGI #КоллективноеОбучение #МашинноеОбучение #ТедЧан
Тед Чан о невозможности создать AGI, пренебрегая законами Гудхарта и Кэмпбелла.
Сегодня в 19:10 по Москве, возможно, лучший фантаст современности Тед Чан расскажет на семинаре ICLR 2022 («От клеток к социумам: коллективное обучение в разных масштабах») о своем видении перспектив цифрового образования для искусственных форм жизни. А этот мой пост – одновременно тизер и резюме предстоящего выступления Теда Чана.
Не удивляйтесь, что 1м из приглашенных спикеров престижного семинара с участием звезд междисциплинарной науки Дэвида Волперта, Михаила (ныне Майкла) Левина и Джессики Флак (все трое – многократные герои моих постов), будет писатель-фантаст. Это вполне заслуженно. Ибо доклад Чана будет развитием идей ставшей знаменитой на весь мир новеллы «Жизненный цикл программных объектов», признаваемой многими ИИ-миждисциплинарщиками мира самым глубоким и проникновенным описанием принципиальной сложности создания человекоподобного ИИ (AGI).
Продолжить чтение (еще 3 мин):
- на Medium https://bit.ly/37MjKEs
- на Яндекс Дзен https://clck.ru/ggnEA
#AGI #КоллективноеОбучение #МашинноеОбучение #ТедЧан
Medium
Ловушка ЕГЭ для обучения машин еще опасней, чем для людей
Тед Чан о невозможности создать AGI, пренебрегая законами Гудхарта и Кэмпбелла
Четверо дышат в затылок Си, а 5й – может стать китайским Горбачевым.
Первый в истории ИИ-прогноз смены расклада сил во власти.
По влиянию на будущее планеты Китай еще не 1й, но уже и не 2й. А каким будет это влияние, решится в конце года на 20-м съезде КПК.
Сейчас эксперты и разведки мира ломают голову, прогнозируя новый расклад сил.
1) С №1 все ясно – им останется Си.
2) Но от того, кто войдет в Политбюро (25 чел) и его Постоянный комитет (7), будет зависеть очень многое (Си крайне редко самостоятельно принимает решения).
3) Кроме того, как показывает история, один из №№2-5 сменит Си (и кто знает, как скоро).
Прогнозов нового расклада сил много. Но все они противоречивы и малоубедительны. Ибо ни один экспертно-аналитический центр не в силах учесть мириады фактов, сложнейших сетевых взаимосвязей кандидатов и динамики социо-политического контекста, не говоря уж о схватках бульдогов под ковром.
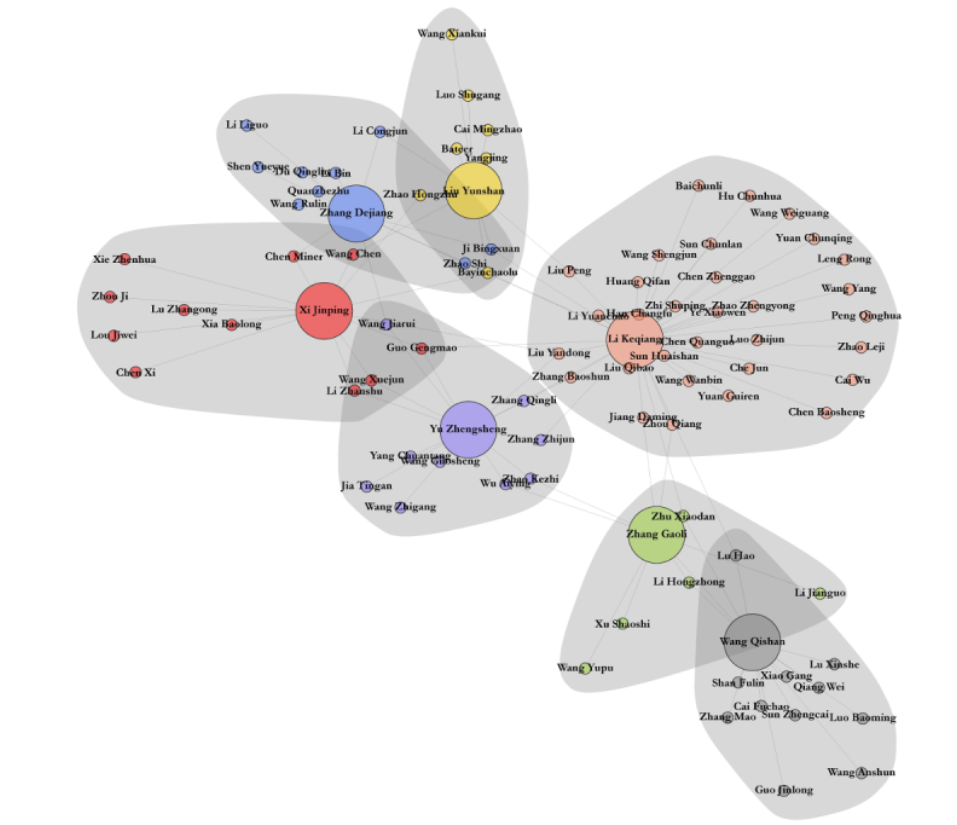
Первая в истории попытка учесть всё это предпринята в Центре международных исследований им. С. Раджаратнама Наньянского университета в Сингапуре. Впервые подобный прогноз сделан на основе анализа Больших данных с помощью машинного обучения.
Оригинальная ансамблевая модель синтезирует результаты 6и алгоритмов машинного обучения в единую многоуровневую модель, максимизируя общую точность прогнозирования. Модель учитывает 250+ факторов биографии, карьеры, контекста продвижений, сетевые взаимосвязи, фракционную конкуренции и др. Учитывается все особые механизмы отбора: правило «семь вверх, восемь вниз» (кандидаты в возрасте 68 лет и старше должны уйти в отставку с должностей национального уровня), разнообразные квоты (1 женщина, 2 слота военным) и множество хитросплетений персональных отношений.
Модель обучали на результатах предыдущих пленумов ЦК КПК. После обучения точность предсказаний составила 72% (что сильно лучше экспертных прогнозов).
Модель предсказывает много чего интересного:
1) Получены проранжированные по вероятности списки членов нового Политбюро и его Постоянного комитета.
2) Известны №№2-5: те, - кто с большой вероятностью, сменит Си:
- Ли Си (1956, член ПБ ЦК КПК 19 созыва)
- Ли Цян (1959, глава Шанхайского горкома КПК с 2017 года, кандидат в члены ЦК 18 созыва, скакнул в ПБ из кандидатов в кандидатов в ЦК)
- Чэнь Миньэр (1960, член ПБ ЦК КПК 19 созыва)
- Цай Ци (1955, глава Пекинского горкома КПК с 2017, до переезда в Пекин был активным микроблогером с более чем 10ю млн подписчиков, он стал членом ПБ минуя членство в ЦК, и подобного не было с 1992).
Особые шансы у Ху Чуньхуа (1963) – приглядитесь к этой фотографии (2): этот человек может стать китайским Горбачевым со всеми вытекающими последствиями.
Ху - самый молодой член 18го и 19го Политбюро. Он из китайского комсомола. После завершения службы в Коммунистическом союзе молодежи он работал во многих бедных провинциях, включая Тибет, Хэбэй и Внутреннюю Монголию (а опыт работы в слаборазвитых регионах считается особо важным для карьерного роста чиновника).
Подробней читайте здесь (1).
#Китай #МашинноеОбучение #Прогнозирование
1 2
Первый в истории ИИ-прогноз смены расклада сил во власти.
По влиянию на будущее планеты Китай еще не 1й, но уже и не 2й. А каким будет это влияние, решится в конце года на 20-м съезде КПК.
Сейчас эксперты и разведки мира ломают голову, прогнозируя новый расклад сил.
1) С №1 все ясно – им останется Си.
2) Но от того, кто войдет в Политбюро (25 чел) и его Постоянный комитет (7), будет зависеть очень многое (Си крайне редко самостоятельно принимает решения).
3) Кроме того, как показывает история, один из №№2-5 сменит Си (и кто знает, как скоро).
Прогнозов нового расклада сил много. Но все они противоречивы и малоубедительны. Ибо ни один экспертно-аналитический центр не в силах учесть мириады фактов, сложнейших сетевых взаимосвязей кандидатов и динамики социо-политического контекста, не говоря уж о схватках бульдогов под ковром.
Первая в истории попытка учесть всё это предпринята в Центре международных исследований им. С. Раджаратнама Наньянского университета в Сингапуре. Впервые подобный прогноз сделан на основе анализа Больших данных с помощью машинного обучения.
Оригинальная ансамблевая модель синтезирует результаты 6и алгоритмов машинного обучения в единую многоуровневую модель, максимизируя общую точность прогнозирования. Модель учитывает 250+ факторов биографии, карьеры, контекста продвижений, сетевые взаимосвязи, фракционную конкуренции и др. Учитывается все особые механизмы отбора: правило «семь вверх, восемь вниз» (кандидаты в возрасте 68 лет и старше должны уйти в отставку с должностей национального уровня), разнообразные квоты (1 женщина, 2 слота военным) и множество хитросплетений персональных отношений.
Модель обучали на результатах предыдущих пленумов ЦК КПК. После обучения точность предсказаний составила 72% (что сильно лучше экспертных прогнозов).
Модель предсказывает много чего интересного:
1) Получены проранжированные по вероятности списки членов нового Политбюро и его Постоянного комитета.
2) Известны №№2-5: те, - кто с большой вероятностью, сменит Си:
- Ли Си (1956, член ПБ ЦК КПК 19 созыва)
- Ли Цян (1959, глава Шанхайского горкома КПК с 2017 года, кандидат в члены ЦК 18 созыва, скакнул в ПБ из кандидатов в кандидатов в ЦК)
- Чэнь Миньэр (1960, член ПБ ЦК КПК 19 созыва)
- Цай Ци (1955, глава Пекинского горкома КПК с 2017, до переезда в Пекин был активным микроблогером с более чем 10ю млн подписчиков, он стал членом ПБ минуя членство в ЦК, и подобного не было с 1992).
Особые шансы у Ху Чуньхуа (1963) – приглядитесь к этой фотографии (2): этот человек может стать китайским Горбачевым со всеми вытекающими последствиями.
Ху - самый молодой член 18го и 19го Политбюро. Он из китайского комсомола. После завершения службы в Коммунистическом союзе молодежи он работал во многих бедных провинциях, включая Тибет, Хэбэй и Внутреннюю Монголию (а опыт работы в слаборазвитых регионах считается особо важным для карьерного роста чиновника).
Подробней читайте здесь (1).
#Китай #МашинноеОбучение #Прогнозирование
1 2
{kind=link}
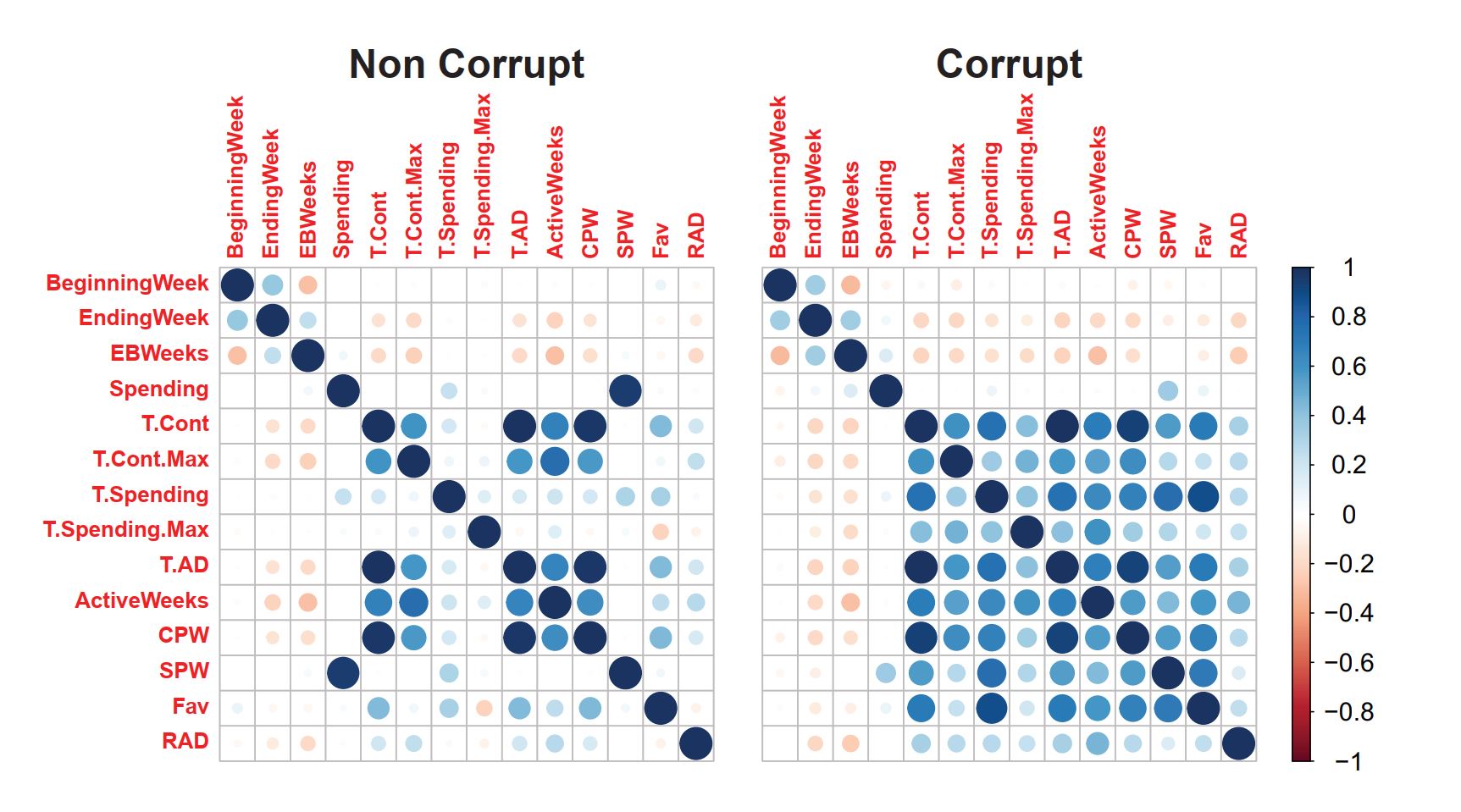
ИИ натаскали выявлять коррупцию на госзакупках.
Это оказалось просто, но … очевидно и бесперспективно.
Результаты первого в истории применения машинного обучения для построения модели выявления коррупционных контрактов при госзакупках принесли 2 новости.
1) ИИ запросто и с высокой точностью выявляет потенциально коррупционные контракты.
Модель, обученная на данных о госконтрактах Мексики за 2013-2020 (1,5+ млн контрактов, из которых 33+ тыс коррупционных по решению суда), научилась с 91%-ной точностью выявлять коррупционные контракты.
2) По заключению ИИ, коррупция на госзакупках – вовсе не результат хитрых схем и умного мошенничества, а банальный сговор находящихся в особо доверительных отношениях чиновников и бизнесменов (доминируют всего 3 из 19 потенциально коррупционных факторов).
Обобщая 1 и 2, можно сказать так.
Извести госкоррупцию не очень сложно, - было бы желание властей. Ну а если этого не происходит, - все вопросы опять же к властям, и никакой ИИ тут не поможет.
Люди давно это поняли. Но что к тому же выводу с первой попытки придет и ИИ, - удивительно.
Для справки. Коррупция на госзакупках – неиссякаемый источник обогащения в 2/3 стран мира. Согласно «Индексу восприятия коррупции», Россия – на 136 месте из 180, а Мексика чуть лучше (№124).
И кстати, авторы методики натаскивания ИИ на госкоррупцию уверяют, что методика универсальная. И натаскать их модель на другую страну можно запросто. Но опять же – было бы желание.
#МашинноеОбучение #Коррупция
Это оказалось просто, но … очевидно и бесперспективно.
Результаты первого в истории применения машинного обучения для построения модели выявления коррупционных контрактов при госзакупках принесли 2 новости.
1) ИИ запросто и с высокой точностью выявляет потенциально коррупционные контракты.
Модель, обученная на данных о госконтрактах Мексики за 2013-2020 (1,5+ млн контрактов, из которых 33+ тыс коррупционных по решению суда), научилась с 91%-ной точностью выявлять коррупционные контракты.
2) По заключению ИИ, коррупция на госзакупках – вовсе не результат хитрых схем и умного мошенничества, а банальный сговор находящихся в особо доверительных отношениях чиновников и бизнесменов (доминируют всего 3 из 19 потенциально коррупционных факторов).
Обобщая 1 и 2, можно сказать так.
Извести госкоррупцию не очень сложно, - было бы желание властей. Ну а если этого не происходит, - все вопросы опять же к властям, и никакой ИИ тут не поможет.
Люди давно это поняли. Но что к тому же выводу с первой попытки придет и ИИ, - удивительно.
Для справки. Коррупция на госзакупках – неиссякаемый источник обогащения в 2/3 стран мира. Согласно «Индексу восприятия коррупции», Россия – на 136 месте из 180, а Мексика чуть лучше (№124).
И кстати, авторы методики натаскивания ИИ на госкоррупцию уверяют, что методика универсальная. И натаскать их модель на другую страну можно запросто. Но опять же – было бы желание.
#МашинноеОбучение #Коррупция
{kind=link}
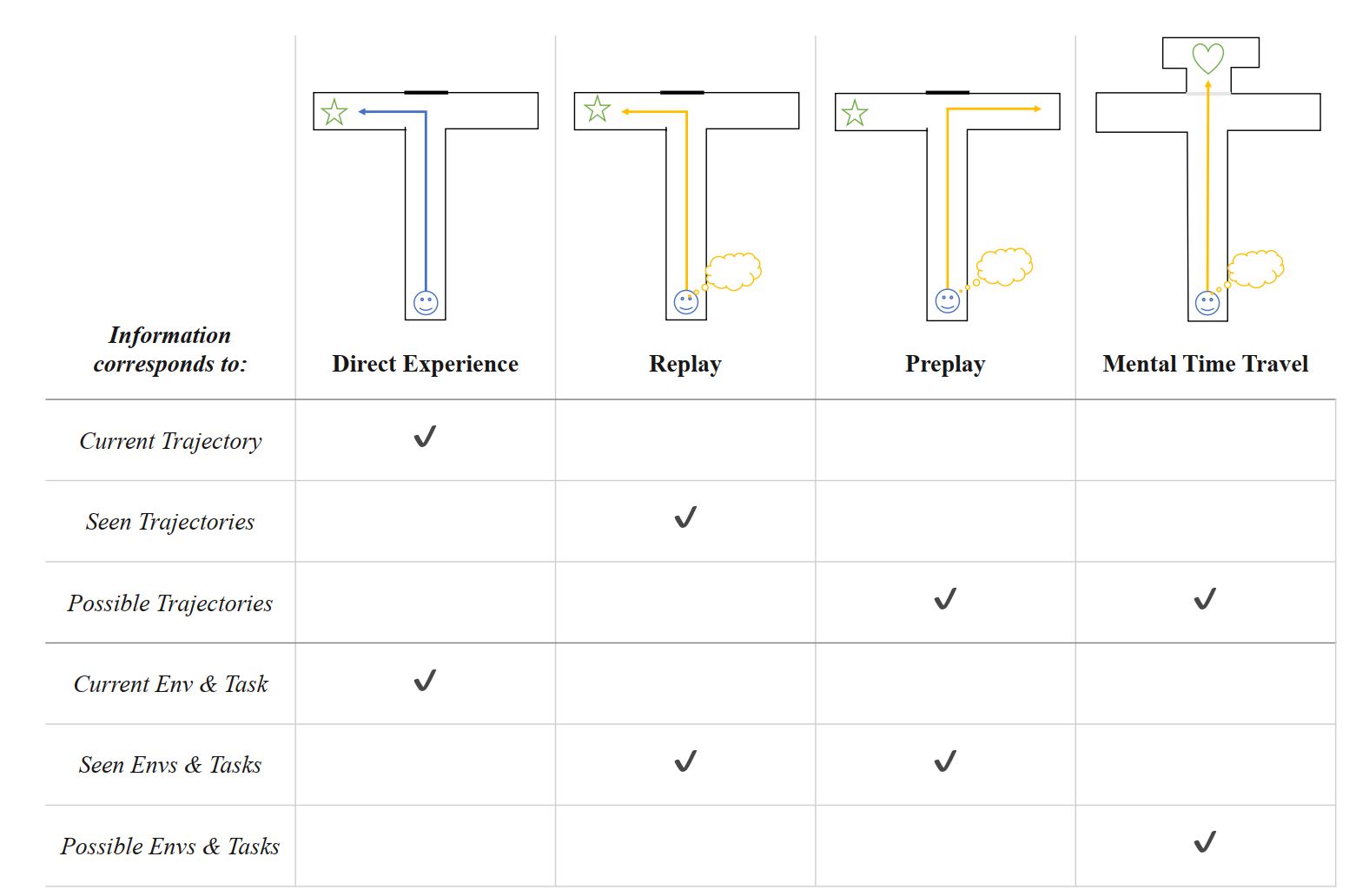
AI превратится в AGI, когда обретёт сознание.
И для этого ему потребуются задатки имажинавта.
О том, что 3 года назад писали лишь футурологи ИИ, сегодня пишут инженеры – практики солидных фирм.
В 2019 я написал пост на довольно важную для меня тему - про имажинавтов (людей со сверхразвитой способностью к ничем не ограниченным перемещениям в пространстве и времени по неисчерпаемой вселенной воображаемых миров). Эта способность, лежащая в основе креативности, базируется на т.н. дистальном моделировании, для которого в мозге задействован особый нейронный механизм — дорсомедиальная подсистема сети пассивного режима (подробней в моём посте).
Спустя 3 года совместными усилиями Microsoft Research и Araya Inc. (Япония), на мой взгляд, намечается прорыв.
Авторы исследования смогли увязать:
1. человеческую способность путешествовать во времени с сознанием;
2. три современные теории сознания с функциями общего (универсального) интеллекта (AGI);
3. современные методы глубокого обучения сначала с 2, а потом и с 1.
Тем самым исследователи Microsoft Research и Araya Inc. предлагают способ, с помощью которого понимание сознания в каждой из трех теорий можно объединить в единую унифицированную и реализуемую модель искусственных агентов, способных «мысленно» путешествовать во времени. Фишка такого похода в том, что, обладая этой возможностью, ИИ становится по-человечески креативным, и за счет этого у него появляется возможность развиваться до AGI человеческого уровня (естественно, при наличии опыта воплощенности или какого-то (пока не придуманного) его заменителя).
Насколько это круто, каждый может оценить самостоятельно.
Мне же это кажется очень-очень перспективным
.
✔️ Ибо обладающие способностями имажинавтов — это штучные люди, встречающиеся, преимущественно, в науке и в искусстве, хотя встречаются и в бизнесе. В последнем случае они кардинально меняют бизнес, монетизируя неопределенность и создавая новую бизнес-реальность, подобно Стиву Джобсу, создавшему для бизнеса новую реальность так же, как это сделал Эйнштейн для науки (подробней читай мой пост).
✔️ Ибо, по большому счету, весь сегодняшний мир создан имажинавтами. Именно им цивилизация обязана за все культурные достижения Homo sapiens, превратившие людей из животных в полубогов.
✔️Ибо способность мысленно путешествовать сквозь пространство и время – может статься, и есть тот золотой ключик, что откроет для современных методов глубокого обучения путь превращения в AGI, который в итоге обретёт сознание, став имажинавтом.
#Креативность #Воображение #Инновации #МашинноеОбучение #AGI
И для этого ему потребуются задатки имажинавта.
О том, что 3 года назад писали лишь футурологи ИИ, сегодня пишут инженеры – практики солидных фирм.
В 2019 я написал пост на довольно важную для меня тему - про имажинавтов (людей со сверхразвитой способностью к ничем не ограниченным перемещениям в пространстве и времени по неисчерпаемой вселенной воображаемых миров). Эта способность, лежащая в основе креативности, базируется на т.н. дистальном моделировании, для которого в мозге задействован особый нейронный механизм — дорсомедиальная подсистема сети пассивного режима (подробней в моём посте).
Спустя 3 года совместными усилиями Microsoft Research и Araya Inc. (Япония), на мой взгляд, намечается прорыв.
Авторы исследования смогли увязать:
1. человеческую способность путешествовать во времени с сознанием;
2. три современные теории сознания с функциями общего (универсального) интеллекта (AGI);
3. современные методы глубокого обучения сначала с 2, а потом и с 1.
Тем самым исследователи Microsoft Research и Araya Inc. предлагают способ, с помощью которого понимание сознания в каждой из трех теорий можно объединить в единую унифицированную и реализуемую модель искусственных агентов, способных «мысленно» путешествовать во времени. Фишка такого похода в том, что, обладая этой возможностью, ИИ становится по-человечески креативным, и за счет этого у него появляется возможность развиваться до AGI человеческого уровня (естественно, при наличии опыта воплощенности или какого-то (пока не придуманного) его заменителя).
Насколько это круто, каждый может оценить самостоятельно.
Мне же это кажется очень-очень перспективным
.
✔️ Ибо обладающие способностями имажинавтов — это штучные люди, встречающиеся, преимущественно, в науке и в искусстве, хотя встречаются и в бизнесе. В последнем случае они кардинально меняют бизнес, монетизируя неопределенность и создавая новую бизнес-реальность, подобно Стиву Джобсу, создавшему для бизнеса новую реальность так же, как это сделал Эйнштейн для науки (подробней читай мой пост).
✔️ Ибо, по большому счету, весь сегодняшний мир создан имажинавтами. Именно им цивилизация обязана за все культурные достижения Homo sapiens, превратившие людей из животных в полубогов.
✔️Ибо способность мысленно путешествовать сквозь пространство и время – может статься, и есть тот золотой ключик, что откроет для современных методов глубокого обучения путь превращения в AGI, который в итоге обретёт сознание, став имажинавтом.
#Креативность #Воображение #Инновации #МашинноеОбучение #AGI
{kind=link}
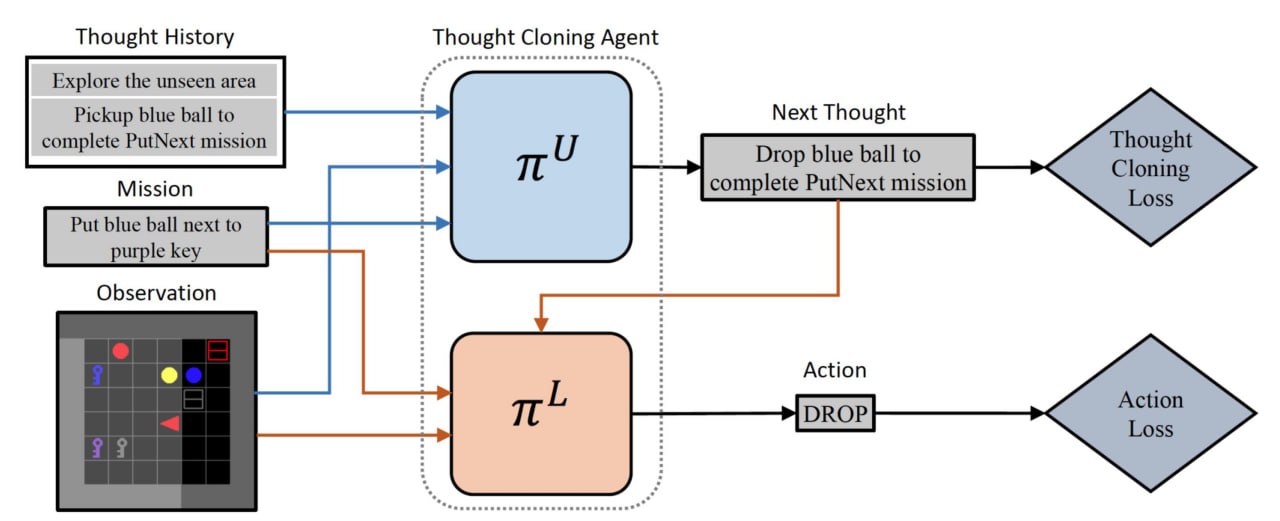
Клонирование мыслей.
Новый метод обучения ИИ думать как люди и самим себя «выдергивать из розетки» при появлении опасных для людей мыслей.
Это открывает две важнейшие прорывные перспективы:
• Качественный скачок в скорости и эффективности обучении ИИ.
• Столь необходимая для широкого внедрения ИИ, возможность профилактики и предотвращения преступлений ИИ (действий, способных принести людям зло).
Все сногсшибательные достижения ИИ больших языковых моделей (LLM) достигнуты за счет их сверхумения имитировать действия людей. Ибо именно действия людей (написанные ими разнообразные тексты от романов до монографий и от стихов до постов, нарисованные картинки, сделанные шахматные ходы или элементы выполнения задач в реальном мире) воплощены в оцифрованных данных, на которых учатся LLM.
Но у людей все несколько иначе. Люди еще и думают (мыслят) – т.е. осуществляют мыслительный процесс рассуждений, ведущий к тем или иным действиям (тексту, ходу в игре, действию в реальном мире и т.д.) Этот мыслительный процесс и обуславливает причины предпринимаемых действий.
Гипотеза авторов исследования «Клонирование мыслей: обучение мыслить в процессе действий, имитируя человеческое мышление» (Универ Британской Колумбии, Vector Institute и Canada CIFAR AI Chair) заключается в том, что если вы обучаете модель действиям и соответствующим им мыслям, то модель выучит правильные ассоциации между поведением и целями. И кроме того, модель также сможет генерировать и сообщать причины своих действий.
Чтобы достичь клонирования мыслей в моделях машинного обучения, авторы разработали метод предоставления модели нескольких потоков информации во время обучения.
• Одним из них является наблюдение за действиями, такими как ходы, которые игрок выполняет в игре.
• Второй — это поток мыслей, например, объяснение действия.
Например, в стратегической игре в реальном времени ИИ наблюдает, как игрок переместил несколько юнитов перед мостом. При этом он получает текстовое пояснение, в котором говорится что-то вроде «не допустить пересечения моста силами противника».
В рамках обучения клонированию мыслей агенты учатся воспроизводить мысли на естественном языке на каждом временном шаге и впоследствии обусловливают свои действия на основе этих сгенерированных мыслей. И мысли, и действия изучаются в процессе предварительного обучения посредством имитации обучения человеческим данным.
Вот видео элементарного игрового примера, как это может происходить.
Клонирование мыслей также способствует безопасности ИИ. Поскольку мы можем наблюдать за мыслями агента, мы можем (1) легче диагностировать, почему что-то идет не так, (2) направлять агента, корректируя его мышление, или (3) предотвращать выполнение им небезопасных действий, которые он планирует делать.
Этот раздел методики авторы назвали «Вмешательство до преступления» - некий ИИ аналог системы из культового фильма «Особое мнение». Он позволяет останавливать ИИ-агента при обнаружении у него опасных мыслей.
Подробней о реализации метода клонирования мыслей см. здесь:
- популярно
- препринт исследования
А здесь результаты на GitHub, включая веса модели, код для обучения модели и код для генерации данных для обучения и тестирования.
#ИИ #МашинноеОбучение
Новый метод обучения ИИ думать как люди и самим себя «выдергивать из розетки» при появлении опасных для людей мыслей.
Это открывает две важнейшие прорывные перспективы:
• Качественный скачок в скорости и эффективности обучении ИИ.
• Столь необходимая для широкого внедрения ИИ, возможность профилактики и предотвращения преступлений ИИ (действий, способных принести людям зло).
Все сногсшибательные достижения ИИ больших языковых моделей (LLM) достигнуты за счет их сверхумения имитировать действия людей. Ибо именно действия людей (написанные ими разнообразные тексты от романов до монографий и от стихов до постов, нарисованные картинки, сделанные шахматные ходы или элементы выполнения задач в реальном мире) воплощены в оцифрованных данных, на которых учатся LLM.
Но у людей все несколько иначе. Люди еще и думают (мыслят) – т.е. осуществляют мыслительный процесс рассуждений, ведущий к тем или иным действиям (тексту, ходу в игре, действию в реальном мире и т.д.) Этот мыслительный процесс и обуславливает причины предпринимаемых действий.
Гипотеза авторов исследования «Клонирование мыслей: обучение мыслить в процессе действий, имитируя человеческое мышление» (Универ Британской Колумбии, Vector Institute и Canada CIFAR AI Chair) заключается в том, что если вы обучаете модель действиям и соответствующим им мыслям, то модель выучит правильные ассоциации между поведением и целями. И кроме того, модель также сможет генерировать и сообщать причины своих действий.
Чтобы достичь клонирования мыслей в моделях машинного обучения, авторы разработали метод предоставления модели нескольких потоков информации во время обучения.
• Одним из них является наблюдение за действиями, такими как ходы, которые игрок выполняет в игре.
• Второй — это поток мыслей, например, объяснение действия.
Например, в стратегической игре в реальном времени ИИ наблюдает, как игрок переместил несколько юнитов перед мостом. При этом он получает текстовое пояснение, в котором говорится что-то вроде «не допустить пересечения моста силами противника».
В рамках обучения клонированию мыслей агенты учатся воспроизводить мысли на естественном языке на каждом временном шаге и впоследствии обусловливают свои действия на основе этих сгенерированных мыслей. И мысли, и действия изучаются в процессе предварительного обучения посредством имитации обучения человеческим данным.
Вот видео элементарного игрового примера, как это может происходить.
Клонирование мыслей также способствует безопасности ИИ. Поскольку мы можем наблюдать за мыслями агента, мы можем (1) легче диагностировать, почему что-то идет не так, (2) направлять агента, корректируя его мышление, или (3) предотвращать выполнение им небезопасных действий, которые он планирует делать.
Этот раздел методики авторы назвали «Вмешательство до преступления» - некий ИИ аналог системы из культового фильма «Особое мнение». Он позволяет останавливать ИИ-агента при обнаружении у него опасных мыслей.
Подробней о реализации метода клонирования мыслей см. здесь:
- популярно
- препринт исследования
А здесь результаты на GitHub, включая веса модели, код для обучения модели и код для генерации данных для обучения и тестирования.
#ИИ #МашинноеОбучение
{kind=link}