
Матмодель показала - мобилизация масс работает иначе, чем мы думаем
Тот, кто знает, как мобилизовать массы, может добиться многого.
Но как устроен механизм мобилизации? Как он работает?
Только имея достоверные представления об этом, возможен эффективный процесс мобилизации масс.
И вот сюрприз – впервые в мире проведенное детальное исследование процессов мобилизации масс показало ошибочность существующих представлений об этом процессе.
Проведение данного исследования стало возможным исключительно благодаря цифровизации мира. В физическом мире процесс мобилизации непосредственно не отслеживаем, - регистрируемы только косвенные и итоговые характеристики.
В цифровом же мире есть замечательные возможности. Например, - подписание интернет-петиций, где:
— все «цифровые следы» каждой из подписей регистрируются;
— доступна полная статистика во всех разрезах, включая поминутную динамику процесса.
Не погружаясь в детали исследования (много букв и графиков вы найдете здесь https://epjdatascience.springeropen.com/articles/10.1140/epjds/s13688-017-0116-6) приведу лишь резюме результатов.
1) Детальный анализ статистики 22 тыс. интернет-госпетиций в Британии и США показал, что традиционное представление в экономике и политологии процесса мобилизации масс на коллективные действия в виде функции S-образной кривой ошибочно.
2) На самом деле, кривая развития процесса иная – быстрый рост и быстрое угасание.
Средний коэффициент охвата петиций очень быстро снижается (до 0,1% через 10 часов в Великобритании и через 30 часов в США). После дня или двух, судьба петиции фактически решена.
3) Результаты исследования заставляют пересмотреть взгляды не только на стратегии проведения интернет-госпетиций. То же касается любых мультипликативных социальных процессов: от процессов «социального заражения» и динамики инфокаскадов (в политике и маркетинге) до процессов, описывающих динамику популярности и е-демократию.
- - - - -
От себя добавлю. Удивительно, но факт.
Другой мультипликативный процесс – рост продолжительности войны, в найденной недавно «формуле войны» зависит от длительности 1го боестолкновения https://t.me/theworldisnoteasy/326
А при мобилизации общества – аналогичная зависимость, но от 1ых суток.
Получается, - что все коллективные действия в обществе (от любой социальной заразы до войны) описываются все той же «формулой жизни» https://goo.gl/NKy2C2
Данное исследование трансдисциплинарное.
#СетевыеВзаимодействия #БольшиеДанные #СоциальноеЗаражение #ДинамикаКоллективныхДействий #МультипликативныеПроцессы
Тот, кто знает, как мобилизовать массы, может добиться многого.
Но как устроен механизм мобилизации? Как он работает?
Только имея достоверные представления об этом, возможен эффективный процесс мобилизации масс.
И вот сюрприз – впервые в мире проведенное детальное исследование процессов мобилизации масс показало ошибочность существующих представлений об этом процессе.
Проведение данного исследования стало возможным исключительно благодаря цифровизации мира. В физическом мире процесс мобилизации непосредственно не отслеживаем, - регистрируемы только косвенные и итоговые характеристики.
В цифровом же мире есть замечательные возможности. Например, - подписание интернет-петиций, где:
— все «цифровые следы» каждой из подписей регистрируются;
— доступна полная статистика во всех разрезах, включая поминутную динамику процесса.
Не погружаясь в детали исследования (много букв и графиков вы найдете здесь https://epjdatascience.springeropen.com/articles/10.1140/epjds/s13688-017-0116-6) приведу лишь резюме результатов.
1) Детальный анализ статистики 22 тыс. интернет-госпетиций в Британии и США показал, что традиционное представление в экономике и политологии процесса мобилизации масс на коллективные действия в виде функции S-образной кривой ошибочно.
2) На самом деле, кривая развития процесса иная – быстрый рост и быстрое угасание.
Средний коэффициент охвата петиций очень быстро снижается (до 0,1% через 10 часов в Великобритании и через 30 часов в США). После дня или двух, судьба петиции фактически решена.
3) Результаты исследования заставляют пересмотреть взгляды не только на стратегии проведения интернет-госпетиций. То же касается любых мультипликативных социальных процессов: от процессов «социального заражения» и динамики инфокаскадов (в политике и маркетинге) до процессов, описывающих динамику популярности и е-демократию.
- - - - -
От себя добавлю. Удивительно, но факт.
Другой мультипликативный процесс – рост продолжительности войны, в найденной недавно «формуле войны» зависит от длительности 1го боестолкновения https://t.me/theworldisnoteasy/326
А при мобилизации общества – аналогичная зависимость, но от 1ых суток.
Получается, - что все коллективные действия в обществе (от любой социальной заразы до войны) описываются все той же «формулой жизни» https://goo.gl/NKy2C2
Данное исследование трансдисциплинарное.
#СетевыеВзаимодействия #БольшиеДанные #СоциальноеЗаражение #ДинамикаКоллективныхДействий #МультипликативныеПроцессы
SpringerOpen
Rapid rise and decay in petition signing - EPJ Data Science
Contemporary collective action, much of which involves social media and other Internet-based platforms, leaves a digital imprint which may be harvested to better understand the dynamics of mobilization. Petition signing is an example of collective action…
Конституции эволюционируют подобно живым организмам
Кто бы мог подумать, что самая влиятельная в мире – конституция Тайланда, самая богатая по числу списывавших с нее стран - конституция Парагвая, а «исторически уникальная» конституция СССР 1936 г. была списана с республиканской конституции Испании 1931 г.
На этой неделе отмечался День Конституции, и самое время открыть для себя поразительные свойства национальных конституций, открытые новым междисциплинарным исследованием.
Оказалось, что национальные конституции – это сложные культурные рекомбинанты.
Т.е. искусственно созданные носители социально-культурной информации, эволюционирующие, как живой организм, геном которого содержит интегрированный генетический материал другого организма.
Из этого следуют два практических вывода: первый – забавный, второй – весьма полезный для понимания национальной политико-правовой реальности различных стран:
1) вот уже 250 лет, как страны списывают тексты конституций друг у друга, как двоечники контрольную работу;
2) прослеживая историю и таксономию заимствований, можно проследить эволюцию конституционных идей, как на уровне каждой из стран, так и у всего человечества.
Новое междисциплинарное исследование посвящено построению эволюционной таксономии мировых конституций. Для этого авторы исследования применили технологии больших данных и машинного обучения по методикам, используемым в эпидемиологии, генетике, лингвистике и сетевых науках.
Целью исследования было – визуализировать и понять, как эволюционируют конституционные идеи и тексты в пространстве и времени.
На протяжении десятилетий исследователи предполагали, что эволюция национальных конституций идет путем, сходным с биологической эволюцией. Новое исследование доказало, что историческое развитие конституций соответствует Процессу Юла (модель эволюционной динамики, описывающей процесс рождения в биологии и физике).
Этот результат был получен при анализе текстов 591 национальной конституции, созданных с 1789 по 2008 г.
Построенная авторами диффузная сеть текстов конституций позволила:
- построить систематическую модель заимствований, начиная от Конституции США 1789 г;
- показать, что конституции являются сложными культурными рекомбинантами;
- обнаружить «биологическое» поведение текстов в моделях наследования;
- выявить небольшое число самых «влиятельных» конституций и критические узлы наследования идей и текстов.
Статья об исследовании https://goo.gl/npW1uu
#БольшиеДанные #МашинноеОбучение #Культура
Кто бы мог подумать, что самая влиятельная в мире – конституция Тайланда, самая богатая по числу списывавших с нее стран - конституция Парагвая, а «исторически уникальная» конституция СССР 1936 г. была списана с республиканской конституции Испании 1931 г.
На этой неделе отмечался День Конституции, и самое время открыть для себя поразительные свойства национальных конституций, открытые новым междисциплинарным исследованием.
Оказалось, что национальные конституции – это сложные культурные рекомбинанты.
Т.е. искусственно созданные носители социально-культурной информации, эволюционирующие, как живой организм, геном которого содержит интегрированный генетический материал другого организма.
Из этого следуют два практических вывода: первый – забавный, второй – весьма полезный для понимания национальной политико-правовой реальности различных стран:
1) вот уже 250 лет, как страны списывают тексты конституций друг у друга, как двоечники контрольную работу;
2) прослеживая историю и таксономию заимствований, можно проследить эволюцию конституционных идей, как на уровне каждой из стран, так и у всего человечества.
Новое междисциплинарное исследование посвящено построению эволюционной таксономии мировых конституций. Для этого авторы исследования применили технологии больших данных и машинного обучения по методикам, используемым в эпидемиологии, генетике, лингвистике и сетевых науках.
Целью исследования было – визуализировать и понять, как эволюционируют конституционные идеи и тексты в пространстве и времени.
На протяжении десятилетий исследователи предполагали, что эволюция национальных конституций идет путем, сходным с биологической эволюцией. Новое исследование доказало, что историческое развитие конституций соответствует Процессу Юла (модель эволюционной динамики, описывающей процесс рождения в биологии и физике).
Этот результат был получен при анализе текстов 591 национальной конституции, созданных с 1789 по 2008 г.
Построенная авторами диффузная сеть текстов конституций позволила:
- построить систематическую модель заимствований, начиная от Конституции США 1789 г;
- показать, что конституции являются сложными культурными рекомбинантами;
- обнаружить «биологическое» поведение текстов в моделях наследования;
- выявить небольшое число самых «влиятельных» конституций и критические узлы наследования идей и текстов.
Статья об исследовании https://goo.gl/npW1uu
#БольшиеДанные #МашинноеОбучение #Культура
Начало войны и ошибочный диагноз рака – следствие одного и того же.
Мир кардинально изменился. Но человечество пока этого не поняло. И это очень плохо.
Люди всегда были не очень сильны в оценке вероятностей. Но еще хуже они всегда были в принятии решений на основе таких оценок.
Сколько катастрофических ошибок для стран и народов делают политические лидеры, принимая военные решения, неверно трактовав оценку вероятности разных сценариев!
А сколько ошибок, катастрофических для конкретных людей и их близких, делают врачи, принимая ошибочное решение на основе оценки вероятности!
Но так было всегда.
Так в чем же дело? Почему это вдруг стало столь критично?
Об этом, а также об изменивших мир цифровизации и больших данных. И о том, как изменить мировоззрение людей, адаптировав его к условиям нового мира, я написал здесь (читать 4 мин)
https://goo.gl/kPMvtj
#БольшиеДанные #Вероятность #Неопределенность #ПринятиеРешений
Мир кардинально изменился. Но человечество пока этого не поняло. И это очень плохо.
Люди всегда были не очень сильны в оценке вероятностей. Но еще хуже они всегда были в принятии решений на основе таких оценок.
Сколько катастрофических ошибок для стран и народов делают политические лидеры, принимая военные решения, неверно трактовав оценку вероятности разных сценариев!
А сколько ошибок, катастрофических для конкретных людей и их близких, делают врачи, принимая ошибочное решение на основе оценки вероятности!
Но так было всегда.
Так в чем же дело? Почему это вдруг стало столь критично?
Об этом, а также об изменивших мир цифровизации и больших данных. И о том, как изменить мировоззрение людей, адаптировав его к условиям нового мира, я написал здесь (читать 4 мин)
https://goo.gl/kPMvtj
#БольшиеДанные #Вероятность #Неопределенность #ПринятиеРешений
Medium
Начало войны и ошибочный диагноз рака — следствие одного и того же
Мир кардинально изменился. Но человечество пока этого не поняло. И это очень плохо.
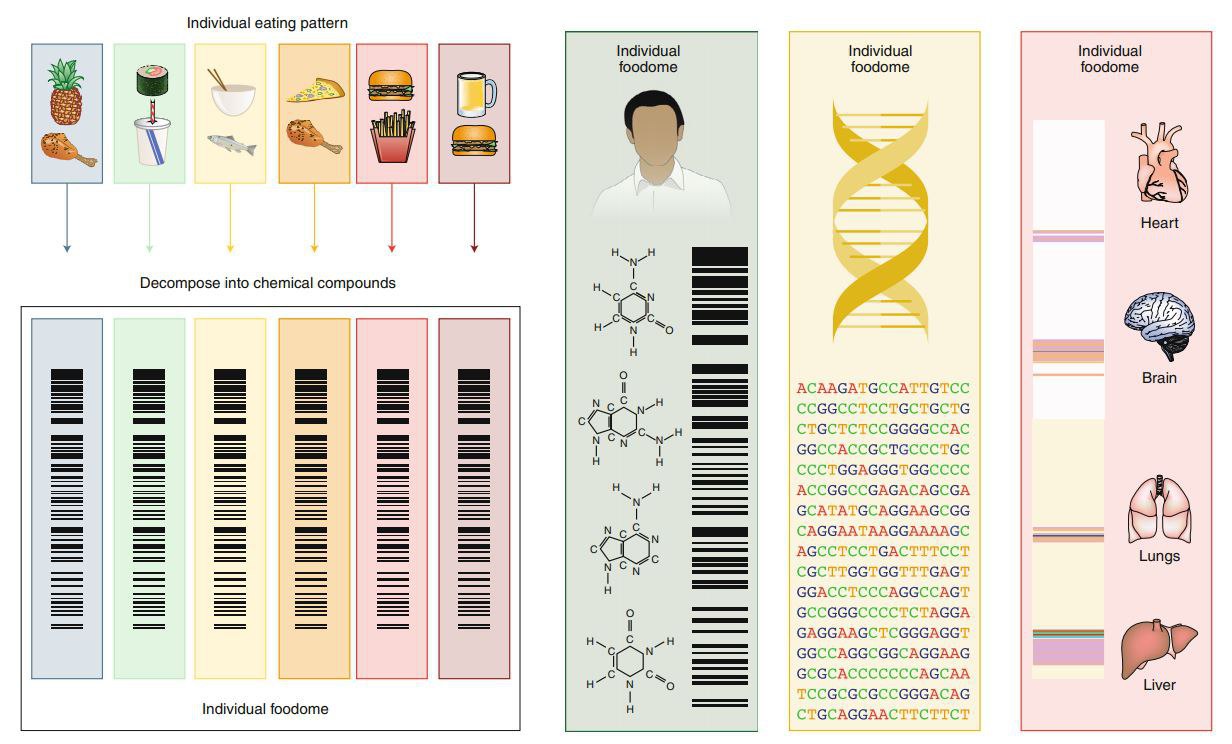
Тайна «темной материи», которую мы едим.
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на рисунке в заглавии поста).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
Эйнштейн 21 века задумал революцию в диетах.
Изречение «ты есть то, что ты ешь» сегодня, в эпоху современной медицины, еще более верно, чем 200 лет назад, когда это было сказано впервые.
Более того, современная наука расширила эту мысль до:
- «скажи мне, что ты ешь, и я скажу, кто ты», теперь относя смысл фразы не только к физической форме, но и к интеллектуальным способностям;
- «скажи мне, что ела твоя мать, когда вынашивала, а потом кормила тебя, и я скажу тебе ...».
Короче, еда для нас – это всё.
Но в том-то и жуткий сюрприз, что
при всех успехах диетологии и, в целом, медицинских наук, мы, оказывается, ни черта не знаем о том, как еда влияет на наше здоровье и интеллект.
Вот пример.
О безглютеновой диете известно более 100 лет, когда появилось понятие «целиакия» — аллергия на клейковину - дерматит, диарея, замедление роста. Сегодняшняя безглютеновая диета заменяет пшеницу, рожь, ячмень и овес мукой и крупой из кукурузы, риса, гречки и сои. Но скрытый глютен диетологи теперь находят в соусах, сосисках, сыре, чае…
Почему?
Да потому, что полный количественный состав биохимических веществ продуктов питания неизвестен!
Национальные стандарты, отслеживающие, как пища влияет на здоровье, основываются примерно на 150 пищевых компонентах.
А их, на самом деле, в пище более 26 тыс.
Многие из них имеют документально подтвержденные последствия для здоровья, но остаются неквантифицированными каким-либо систематическим образом для конкретных продуктов питания. Это и есть «темная материя» еды:
- составляющая минимум 2/3 того, что мы съедаем;
- и обладающая неквантифицированным, а то и, вообще, неизвестным влиянием на наше здоровье и интеллект.
Например, чеснок.
Масса людей знает про себя, что от чеснока им худо. Но почему, - никакой врач точно сказать не готов.
А вот почему.
1) Даже в самых продвинутых базах данных содержатся количественные сведения лишь о 67 питательных компонентах сырого чеснока (марганец, витамин В6, селен ...).
Однако, зубчик чеснока содержит 2300+ различных химических компонентов - от аллицина, соединения серы, отвечающего за отчетливый аромат, до лютеолина, флавона, обладающего защитным действием при сердечно-сосудистых заболеваниях.
2) Влияние каждого из элементов «темной материи» еды на индивидуальный организм уникально. Эта уникальность определяется уникальностью ДНК. Но связать квантифицированные данные о точном составе «темной материи» с индивидуальным кодом ДНК никто пока не брался.
И вот сенсация.
Альберт-Ласло Барабаши (которого я не без оснований назвал Эйнштейном 21 века) планирует в течение 10 лет произвести переворот в питании человечества.
Путем машинного обучения на Больших Данных, описывающих (1) полный биохимический состав высокого разрешения всех продуктов питания и (2) генетические коды конкретных людей, он собирается:
1) расшифровать «тайную материю» продуктов питания – произвести систематическое картирование полного биохимического состава пищи;
2) разработать полный биохимический спектр «дорожных карт» индивидуальных диет, чтобы питание могло конкурировать с генетикой по точности, охвату и влиянию.
Результатом станет индивидуальный питательно-химический «штрих-код» для каждого человека, определяющий оптимальный спектр индивидуально показанных пищевых продуктов (пример «штрих-кода» показан на рисунке в заглавии поста).
И будет людям здоровье и счастье. А лекарства – только в случаях, когда «штрих-код» засбоит, и нужно будет это подправить.
Да, еще кое-что. Это здорово улучшит ожидаемую продолжительность жизни. Как будто люди перестанут заправлять бензобаки своих авто загрязненным и разбавленным ослиной мочой низкосортным бензином АИ-80 и перейдут на лучшие сорта топлива высокой очистки, да еще и оптимизированное под тип двигателя.
Подробней – The unmapped chemical complexity of our diet
#МашинноеОбучение #БольшиеДанные #Диета #Геном
{kind=link}
Данные – это новый мусор.
Объемы данных не дают стратегических преимуществ.
Китай и США сделали ставку на военные приложения ИИ. Причина этого кажется очевидной и политикам, и военным. Все они повторяют мантру из книги «Супердержавы ИИ» Кай-Фу Ли - «В век ИИ, когда данные - это новая нефть, Китай - новая Саудовская Аравия». Но реальность гораздо сложнее. Все далеко не так просто в обретении военного превосходства в ИИ-системах.
Новый отчет CSET не открывает новых истин, а всего лишь резюмирует – объемы данных имеют такое же значение для обретения военного преимущества, как объемы производимого страной мусора.
Кому придет в голову делать вывод о национальном технологическом превосходстве, если страна – мировой чемпион по мусору? А ведь с данными еще хуже, ибо данные грязнее любого мусора.
Отчет резюмирует.
1. Объемы необработанных данных вообще не о чем не говорят.
2. Ценность имеют лишь очищенные, преобразованные, маркированные данные, оптимизированные для обучения конкретными алгоритмами машинного обучения.
3. Коммерческие данные из п. 2, хотя и полезны, но мало актуальны для военного оперативного ИИ. Данные подбираются под конкретные задачи, а ценность коммерческих данных и моделей машинного обучения для военных приложений крайне мала.
4. Синтетическая генерация данных (типа той, что делал DeepMind для триумфа AlphaZero в настольных играх), будучи сделана с умом, в тысячу крат ценнее, чем горы данных, произведенных 1.4 миллиардом китайцев, звонящих по телефонам и оплачивающих покупки онлайн.
Ключевой вывод в том, что будущее ИИ (и в том числе военного ИИ) не в больших данных.
А политикам, военным (да и бизнесменам) пора понять – «супердержавой ИИ» станет не страна с горами мусорных данных. А страна, что научится превращать их в еду, питье, энергию и стратегическое военное преимущество.
Китай и США в этом пока не сильно преуспели. И в этой игре никто не проиграл, пока никто не выиграл.
https://cset.georgetown.edu/research/messier-than-oil-assessing-data-advantage-in-military-ai/
#ИИгонка #БольшиеДанные #Китай #США
Объемы данных не дают стратегических преимуществ.
Китай и США сделали ставку на военные приложения ИИ. Причина этого кажется очевидной и политикам, и военным. Все они повторяют мантру из книги «Супердержавы ИИ» Кай-Фу Ли - «В век ИИ, когда данные - это новая нефть, Китай - новая Саудовская Аравия». Но реальность гораздо сложнее. Все далеко не так просто в обретении военного превосходства в ИИ-системах.
Новый отчет CSET не открывает новых истин, а всего лишь резюмирует – объемы данных имеют такое же значение для обретения военного преимущества, как объемы производимого страной мусора.
Кому придет в голову делать вывод о национальном технологическом превосходстве, если страна – мировой чемпион по мусору? А ведь с данными еще хуже, ибо данные грязнее любого мусора.
Отчет резюмирует.
1. Объемы необработанных данных вообще не о чем не говорят.
2. Ценность имеют лишь очищенные, преобразованные, маркированные данные, оптимизированные для обучения конкретными алгоритмами машинного обучения.
3. Коммерческие данные из п. 2, хотя и полезны, но мало актуальны для военного оперативного ИИ. Данные подбираются под конкретные задачи, а ценность коммерческих данных и моделей машинного обучения для военных приложений крайне мала.
4. Синтетическая генерация данных (типа той, что делал DeepMind для триумфа AlphaZero в настольных играх), будучи сделана с умом, в тысячу крат ценнее, чем горы данных, произведенных 1.4 миллиардом китайцев, звонящих по телефонам и оплачивающих покупки онлайн.
Ключевой вывод в том, что будущее ИИ (и в том числе военного ИИ) не в больших данных.
А политикам, военным (да и бизнесменам) пора понять – «супердержавой ИИ» станет не страна с горами мусорных данных. А страна, что научится превращать их в еду, питье, энергию и стратегическое военное преимущество.
Китай и США в этом пока не сильно преуспели. И в этой игре никто не проиграл, пока никто не выиграл.
https://cset.georgetown.edu/research/messier-than-oil-assessing-data-advantage-in-military-ai/
#ИИгонка #БольшиеДанные #Китай #США
Center for Security and Emerging Technology
Messier than Oil: Assessing Data Advantage in Military AI | Center for Security and Emerging Technology
Both China and the United States seek to develop military applications enabled by artificial intelligence. This issue brief reviews the obstacles to assessing data competitiveness and provides metrics for measuring data advantage.