
На прошлой неделе делал опросы тут в канале и в группе VK. Сейчас, когда эти опросы собрали основную массу просмотров, можно подвести итоги. В целом, получилось плюс-минус как я и ожидал. В рабочих машинах больше винды, на серверах больше линукса. Единственное, думал, что доля линукса на рабочих машинах будет поменьше. На деле довольно много людей постоянно работают за Linux.
📌 Результаты в Telegram:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 66% - Windows
◽23% - Linux
◽10% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 63% - Linux
◽34% - Windows
◽1% - *BSD
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив? (можно было выбрать несколько вариантов)
🔴 47% - Debian
◽43% - Ubuntu
◽17% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽12% - один из российских дистрибутивов
◽5% - другое
📌 Результаты в VK:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 69% - Windows
◽23% - Linux
◽6% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 56% - Linux
◽ 40% - Windows
◽4% - другая
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив?
🔴 36% - Ubuntu
◽ 34% - Debian
◽8% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽13% - один из российских дистрибутивов
◽8% - другое
Результаты в TG и VK немного отличаются, но не кардинально. Для меня было немного странно видеть так много серверов под Ubuntu. То, что Debian будет в лидерах, предполагал. Я уже думал об этом, ещё когда объявили об изменениях с CentOS. Сейчас ожидал, что лидером будет Debian, а Ubuntu будет плюс минус как и форков RHEL. Но последние совсем потеряли позиции, судя по результатам. Не ожидал, что так сильно.
Довольно высокая доля отечественных дистрибутивов. Думал, будет в районе 5%, вышло 12% и 13%, что уже значительно. В итоге в серверах на базе Linux в России сейчас очень большой зоопарк. Если вы только начинаете всё это изучать, то выбирайте себе Debian. Это будет наиболее универсальным вариантом на сегодняшний день.
Постарался, как мог, усреднить и объединить результаты опросов в обоих сообществах. В VK нельзя было выбрать несколько ответов, а в TG в последнем опросе можно было. Это немного смазало картинку и итоговый результат третьего вопроса.
#разное
📌 Результаты в Telegram:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 66% - Windows
◽23% - Linux
◽10% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 63% - Linux
◽34% - Windows
◽1% - *BSD
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив? (можно было выбрать несколько вариантов)
🔴 47% - Debian
◽43% - Ubuntu
◽17% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽12% - один из российских дистрибутивов
◽5% - другое
📌 Результаты в VK:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 69% - Windows
◽23% - Linux
◽6% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 56% - Linux
◽ 40% - Windows
◽4% - другая
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив?
🔴 36% - Ubuntu
◽ 34% - Debian
◽8% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽13% - один из российских дистрибутивов
◽8% - другое
Результаты в TG и VK немного отличаются, но не кардинально. Для меня было немного странно видеть так много серверов под Ubuntu. То, что Debian будет в лидерах, предполагал. Я уже думал об этом, ещё когда объявили об изменениях с CentOS. Сейчас ожидал, что лидером будет Debian, а Ubuntu будет плюс минус как и форков RHEL. Но последние совсем потеряли позиции, судя по результатам. Не ожидал, что так сильно.
Довольно высокая доля отечественных дистрибутивов. Думал, будет в районе 5%, вышло 12% и 13%, что уже значительно. В итоге в серверах на базе Linux в России сейчас очень большой зоопарк. Если вы только начинаете всё это изучать, то выбирайте себе Debian. Это будет наиболее универсальным вариантом на сегодняшний день.
Постарался, как мог, усреднить и объединить результаты опросов в обоих сообществах. В VK нельзя было выбрать несколько ответов, а в TG в последнем опросе можно было. Это немного смазало картинку и итоговый результат третьего вопроса.
#разное
{kind=link}
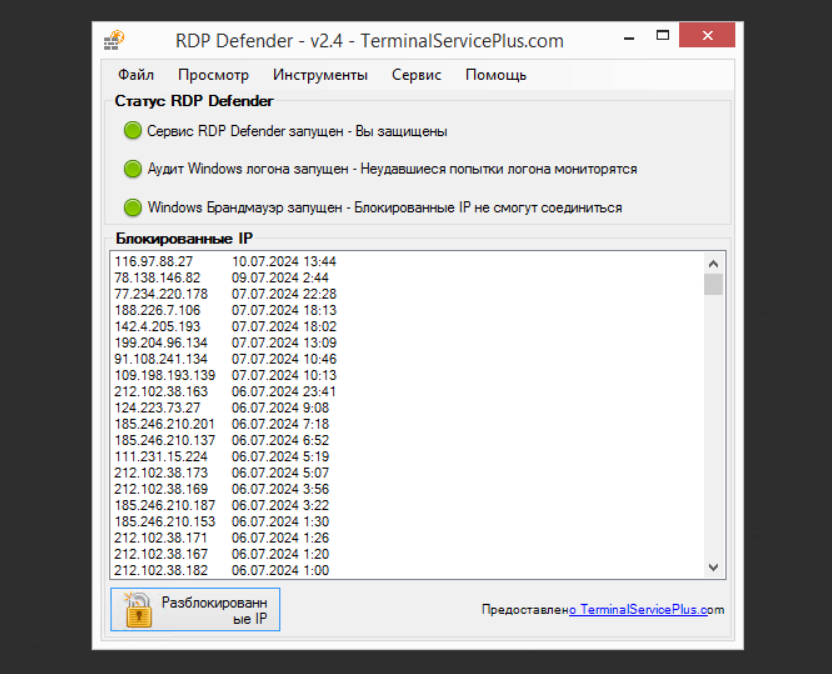
Периодически пишу про небольшие простые программы, которыми давно пользуюсь. Некоторые из них уже не развиваются, но не потеряли удобство и актуальность. Одной из таких программ является RDP Defender.
Я уже писал о ней года 3 назад. С тех пор продолжаю иногда пользоваться. На Windows Server 2019 нормально работает, выше не пробовал. Это небольшая программа, которая выполняет одну единственную функцию - анализирует журнал аудита Windows, если есть попытки перебора паролей, блокирует IP адрес переборщика с помощью встроенного файрвола Windows.
Программа маленькая, установщик меньше мегабайта весит. Уже давно нет сайта, на котором она лежала. Посмотреть на него можно через web.archive.org. Вот прямая ссылка на один из снимков сайта, где она выкладывалась. Оттуда же можно скачать и установщик, но там не самая последняя версия. В какой-то момент сайт ещё раз поменялся, и там уже была самая актуальная версия 2.4, которой я пользуюсь.
Решений этой задачи есть очень много, в том числе и встроенными средствами самой системы. Я в конце приведу ссылки. Напишу, почему по прежнему предпочитаю в простых случаях RDP Defender:
◽Простой и наглядный интерфейс
◽Сразу видно, запущены ли службы файрвола и аудита
◽Быстрый доступ к белым спискам
◽Информативный лог блокировок
С этой программой удобнее работать, чем с оснастками и скриптами Windows.
Отдельно скажу про RDP порт, смотрящий напрямую в интернет. Да, по возможности его не нужно выставлять. Но есть люди, которые готовы это делать, несмотря на связанные с этим риски. Какой-то особой опасности в этом нет. Если вы сейчас установите Windows Server со всеми обновлениями, откроете RDP порт на доступ из интернета и защитите его тем или иным способом от перебора паролей, то ничего с вами не случится. До тех пор, пока не будет найдена какая-то существенная уязвимость в протоколе, которая позволит обходить аутентификацию. Даже не совсем в протоколе RDP, до которого ещё надо добраться. Подключение по RDP в Windows на самом деле неплохо защищено.
На моей памяти последняя такая уязвимость была обнаружена лет 5-6 назад. Один из серверов под моим управлением был зашифрован. Так что нужно понимать этот риск. Может ещё лет 10 таких дыр не будет найдено, а может они уже есть, не афишируется, но используется втихую.
RDP Defender актуален не только для интернета, но и локальной сети. В бан запросто попадают завирусованные компы из локалки, или какие-то другие устройства. Например, сталкивался с тем, что какой-то софт от 1С неправильно аутентифицировался на сервере для доступа к сетевому диску и регулярно получал от него бан. Разбирались в итоге с программистами, почему так происходит. Оказалось, что там идёт перебор каких-то разных способов аутентификации и до рабочего дело не доходит, так как бан настигает раньше. Так что программу имеет смысл использовать и в локалке.
Аналоги RDP Defender:
▪️ IPBan
▪️ EvlWatcher
▪️ Cyberarms IDDS
▪️ Crowdsec
▪️ PowerShell скрипт
Положил программу на свой Яндекс.Диск:
⇨ https://disk.yandex.ru/d/gN6G9DZ01Fgr6Q
Посмотреть его разбор с точки зрения безопасности можно тут:
- virustotal
- joesandbox (доступ через vpn)
#windows #security
Я уже писал о ней года 3 назад. С тех пор продолжаю иногда пользоваться. На Windows Server 2019 нормально работает, выше не пробовал. Это небольшая программа, которая выполняет одну единственную функцию - анализирует журнал аудита Windows, если есть попытки перебора паролей, блокирует IP адрес переборщика с помощью встроенного файрвола Windows.
Программа маленькая, установщик меньше мегабайта весит. Уже давно нет сайта, на котором она лежала. Посмотреть на него можно через web.archive.org. Вот прямая ссылка на один из снимков сайта, где она выкладывалась. Оттуда же можно скачать и установщик, но там не самая последняя версия. В какой-то момент сайт ещё раз поменялся, и там уже была самая актуальная версия 2.4, которой я пользуюсь.
Решений этой задачи есть очень много, в том числе и встроенными средствами самой системы. Я в конце приведу ссылки. Напишу, почему по прежнему предпочитаю в простых случаях RDP Defender:
◽Простой и наглядный интерфейс
◽Сразу видно, запущены ли службы файрвола и аудита
◽Быстрый доступ к белым спискам
◽Информативный лог блокировок
С этой программой удобнее работать, чем с оснастками и скриптами Windows.
Отдельно скажу про RDP порт, смотрящий напрямую в интернет. Да, по возможности его не нужно выставлять. Но есть люди, которые готовы это делать, несмотря на связанные с этим риски. Какой-то особой опасности в этом нет. Если вы сейчас установите Windows Server со всеми обновлениями, откроете RDP порт на доступ из интернета и защитите его тем или иным способом от перебора паролей, то ничего с вами не случится. До тех пор, пока не будет найдена какая-то существенная уязвимость в протоколе, которая позволит обходить аутентификацию. Даже не совсем в протоколе RDP, до которого ещё надо добраться. Подключение по RDP в Windows на самом деле неплохо защищено.
На моей памяти последняя такая уязвимость была обнаружена лет 5-6 назад. Один из серверов под моим управлением был зашифрован. Так что нужно понимать этот риск. Может ещё лет 10 таких дыр не будет найдено, а может они уже есть, не афишируется, но используется втихую.
RDP Defender актуален не только для интернета, но и локальной сети. В бан запросто попадают завирусованные компы из локалки, или какие-то другие устройства. Например, сталкивался с тем, что какой-то софт от 1С неправильно аутентифицировался на сервере для доступа к сетевому диску и регулярно получал от него бан. Разбирались в итоге с программистами, почему так происходит. Оказалось, что там идёт перебор каких-то разных способов аутентификации и до рабочего дело не доходит, так как бан настигает раньше. Так что программу имеет смысл использовать и в локалке.
Аналоги RDP Defender:
▪️ IPBan
▪️ EvlWatcher
▪️ Cyberarms IDDS
▪️ Crowdsec
▪️ PowerShell скрипт
Положил программу на свой Яндекс.Диск:
⇨ https://disk.yandex.ru/d/gN6G9DZ01Fgr6Q
Посмотреть его разбор с точки зрения безопасности можно тут:
- virustotal
- joesandbox (доступ через vpn)
#windows #security
{kind=link}
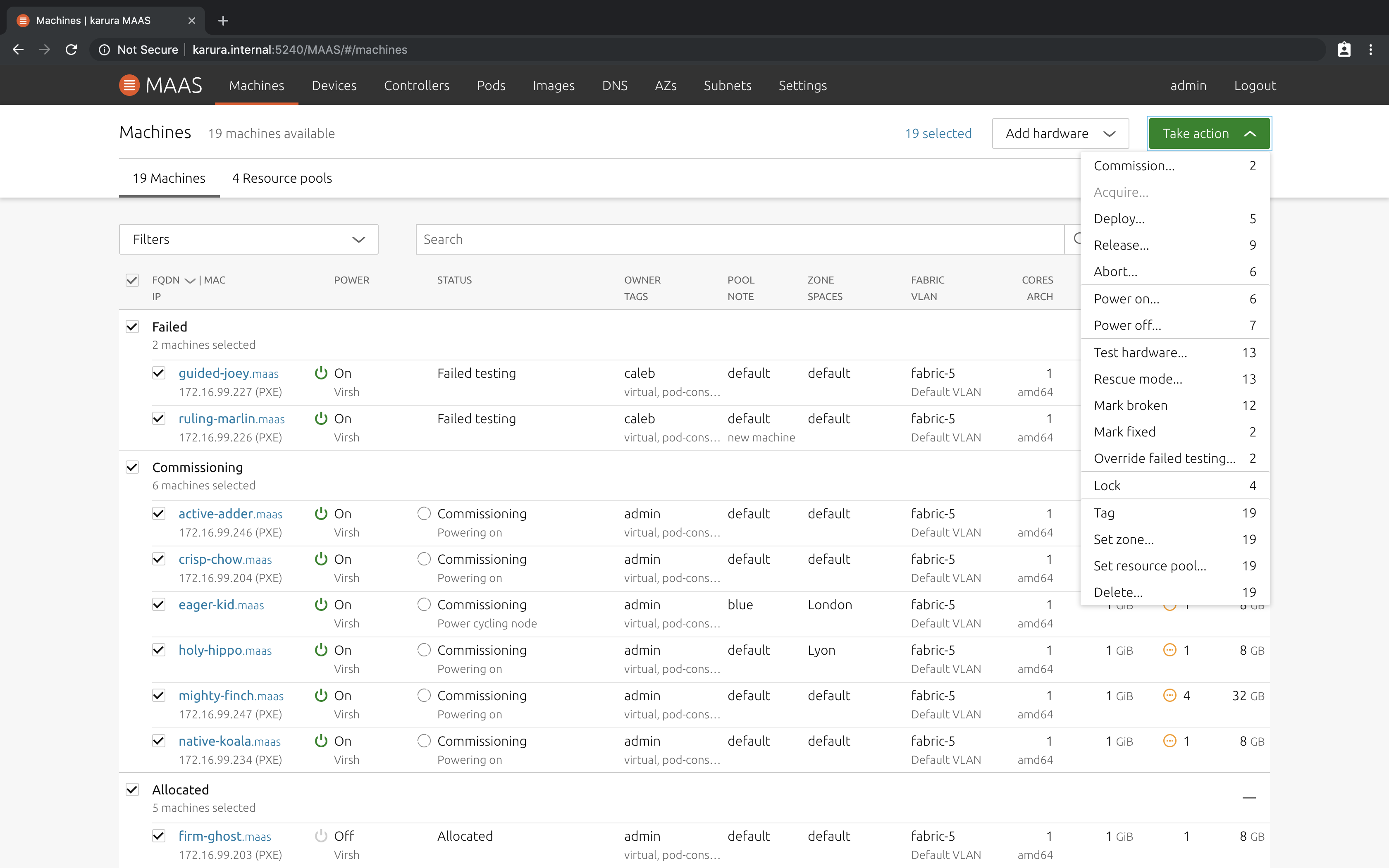
У компании Canonical, авторов ОС Ubuntu, есть Open Source проект MAAS для автоматической раскатки систем на голое железо. Непривычная аббревиатура, которую они расшифровывают как Metal-As-A-Service, хотя иногда её можно увидеть как сокращение от Monitoring-As-A-Service.
С помощью MAAS можно настроить автоматическую установку любых подготовленных образов систем на голое железо. По сути это аналог таких проектов, как FOG Project, Cobbler, Foreman. В их основе лежат технологии сетевой загрузки PXE и TFTP. MAAS тут не исключение. На сегодняшний день это наиболее современное решение подобного типа, нацеленное на масштабное корпоративное применение. Но никто не мешает вам и рабочие станции с его помощью накатывать, а не только сервера и гипервизоры.
Расскажу на пальцах, как это работает. Современные сетевые карты поддерживают технологию PXE. Они могут выступать источником загрузки системы наравне с жёстким диском или usb устройством. Вы можете подготовить образ любой операционной системы, который автоматически выполнит установку на железо, не задавая вопросы. Этот образ нужно будет загрузить в систему, подобную MAAS. На DHCP сервере в локальной сети настраивается специальный параметр, который при загрузке сетевой карты с помощью PXE передаст ей адрес MAAS сервера, откуда будет взят образ ОС для загрузки.
Имя подготовленный сервер MAAS и настроив соответствующим образом DHCP, вам достаточно в биосе компьютера или сервера выбрать сетевую загрузку, чтобы автоматически подгрузить установочный образ и выполнить установку системы. Конкретно MAAS поддерживает интеграцию с Ansible, так что после установки системы сможет выполнить нужные настройки уже внутри неё. Всё это управляется через веб интерфейс, где имеется список машин, их технические характеристики и другая информация, в том числе о виртуальных машинах, если речь идёт о гипервизорах. Если на железе есть настройка WOL (Wake on Lan), то с помощью MAAS можно будет включать и выключать устройства.
Установка и базовая настройка MAAS относительно простая. Понадобится система Ubuntu. Развернуть MAAS можно как из snap, так и из привычных пакетов. Для этого есть отдельный репозиторий. Настройка и управление продукта могут выполняться через веб интерфейс, который приятен на вид и функционален. Если вас заинтересует эта система, захочется посмотреть и развернуть у себя, то вот тут подробный обзор на MAAS в связке с Packer:
▶️ Deploying Machines with MaaS and Packer - Metal as a Service + Hashicorp Packer Tutorial
Там прям пошаговая установка в соответствии с инструкцией. Повторить увиденное не составит большого труда. Автор подробно всё объясняет и показывает. Рассказывает нюансы с сетями, с настройкой DHCP и т.д. Очень доступно. Если не знаете английский, хватит синхронного перевода в Яндекс.Браузере.
Из всех продуктов подобного типа, что я тестировал, MAAS выглядит наиболее функциональным и целостным. Несмотря на то, что это изделие Canonical, никакой привязки к управляемым системам нет, кроме того, что устанавливать сам программный продукт лучше на сервер с Ubuntu. Разворачивать системы вы можете абсолютно любые: Linux, Windows, ESXI, Citrix и т.д.
⇨ Сайт / Исходники
#pxe
С помощью MAAS можно настроить автоматическую установку любых подготовленных образов систем на голое железо. По сути это аналог таких проектов, как FOG Project, Cobbler, Foreman. В их основе лежат технологии сетевой загрузки PXE и TFTP. MAAS тут не исключение. На сегодняшний день это наиболее современное решение подобного типа, нацеленное на масштабное корпоративное применение. Но никто не мешает вам и рабочие станции с его помощью накатывать, а не только сервера и гипервизоры.
Расскажу на пальцах, как это работает. Современные сетевые карты поддерживают технологию PXE. Они могут выступать источником загрузки системы наравне с жёстким диском или usb устройством. Вы можете подготовить образ любой операционной системы, который автоматически выполнит установку на железо, не задавая вопросы. Этот образ нужно будет загрузить в систему, подобную MAAS. На DHCP сервере в локальной сети настраивается специальный параметр, который при загрузке сетевой карты с помощью PXE передаст ей адрес MAAS сервера, откуда будет взят образ ОС для загрузки.
Имя подготовленный сервер MAAS и настроив соответствующим образом DHCP, вам достаточно в биосе компьютера или сервера выбрать сетевую загрузку, чтобы автоматически подгрузить установочный образ и выполнить установку системы. Конкретно MAAS поддерживает интеграцию с Ansible, так что после установки системы сможет выполнить нужные настройки уже внутри неё. Всё это управляется через веб интерфейс, где имеется список машин, их технические характеристики и другая информация, в том числе о виртуальных машинах, если речь идёт о гипервизорах. Если на железе есть настройка WOL (Wake on Lan), то с помощью MAAS можно будет включать и выключать устройства.
Установка и базовая настройка MAAS относительно простая. Понадобится система Ubuntu. Развернуть MAAS можно как из snap, так и из привычных пакетов. Для этого есть отдельный репозиторий. Настройка и управление продукта могут выполняться через веб интерфейс, который приятен на вид и функционален. Если вас заинтересует эта система, захочется посмотреть и развернуть у себя, то вот тут подробный обзор на MAAS в связке с Packer:
▶️ Deploying Machines with MaaS and Packer - Metal as a Service + Hashicorp Packer Tutorial
Там прям пошаговая установка в соответствии с инструкцией. Повторить увиденное не составит большого труда. Автор подробно всё объясняет и показывает. Рассказывает нюансы с сетями, с настройкой DHCP и т.д. Очень доступно. Если не знаете английский, хватит синхронного перевода в Яндекс.Браузере.
Из всех продуктов подобного типа, что я тестировал, MAAS выглядит наиболее функциональным и целостным. Несмотря на то, что это изделие Canonical, никакой привязки к управляемым системам нет, кроме того, что устанавливать сам программный продукт лучше на сервер с Ubuntu. Разворачивать системы вы можете абсолютно любые: Linux, Windows, ESXI, Citrix и т.д.
⇨ Сайт / Исходники
#pxe
{kind=link}
Открытый практикум DevOps by Rebrain: Шардирование elasticsearch
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
17 Июля (Среда) в 20:00 по МСК
Программа практикума:
🔹Репликация
🔹Шардирование
🔹Настройка кластера elasticsearch
Кто ведёт?
Андрей Буранов – Системный администратор в департаменте VK Play. 10+ лет опыта работы с ОС Linux. 8+ лет опыта преподавания. Входит в топ 3 лучших преподавателей образовательных порталов.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2VtzqvgsVUc
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
17 Июля (Среда) в 20:00 по МСК
Программа практикума:
🔹Репликация
🔹Шардирование
🔹Настройка кластера elasticsearch
Кто ведёт?
Андрей Буранов – Системный администратор в департаменте VK Play. 10+ лет опыта работы с ОС Linux. 8+ лет опыта преподавания. Входит в топ 3 лучших преподавателей образовательных порталов.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2VtzqvgsVUc
▶️ Всем хороших выходных. Желательно уже в отпуске в каком-то приятном месте, где можно отдохнуть и позалипать в ютуб. Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными и полезными.
⇨ Обновляем MariaDB c 10.11 на 11.4
Пошаговое обновление MariaDB на свежую ветку. В видео ничего особенного, просто наглядная демонстрация процесса на основе статьи по обновлению из документации.
⇨ Self-Hosted AI That's Actually Useful
Интересное и полезное видео с обзором AI движков, которые можно запустить на своём железе. Автор проделал это и пока кратко рассказал основное. Я так понял, будут дальше видео на эту тему.
⇨ pfSense Alternatives: Firewall Solutions for your Network
Автор разобрал альтернативы самому популярному бесплатному софтовому шлюзу: OPNsense, Untangle, Unifi Security Devices, Sophos UTM Home Edition, MikroTik RouterOS.
⇨ The Best Note-Taking App For Linux Users: Standard Notes Review
Обзор программы для хранения заметок Standard Notes. Впервые про неё услышал. Автор рассказывает про свои мытарства в этой стезе. Он тоже использовал Joplin, но отказался от него из-за багов. Пробовал все популярные решения, в том числе те, что я тут недавно упоминал и остановился на Standard Notes. По обзору реально выглядит неплохо. Визуально лучше Joplin. Придётся тоже пробовать.
⇨ Твой новый dashboard Homepage
Очень подборный обзор, установка и настройка очередного дашборда для серверов и сервисов на них. Интересная штука, есть интеграция с Proxmox, Mikrotik, Portainer, Traefik и многим другим популярным софтом. Это аналог Dashy или Heimdall, про которые я ранее писал. У автора интересные видео, всегда с удовольствием смотрю.
⇨ Uptime Kuma. Мониторим свои сервисы
Обзор системы мониторинга для тех, кто всё ещё про неё не знает. Рекомендую если не знакомы. Хотя я в итоге для легковесного мониторинга перешёл на Gatus.
⇨ Prometheus - Как мониторить Динамичное количество серверов на AWS ?
Пример настройки Prometheus для мониторинга динамических сред.
⇨ OpenVPN-сервер на Mikrotik: от подключения мобильных устройств до десктопов
Очень подробный разбор темы настройки OpenVPN на микротиках от известного тренера Романа Козлова.
⇨ Инструменты мониторинга трафика в Mikrotik
Короткое видео для новичков в Mikrotik. Автор наглядно показал 3 способа просмотра трафика в Микротике: torch, connections, sniffer.
⇨ Junior vs Middle vs Senior в чем отличие? Пример задач для Junior DevOps
Автор описал своё видение уровней должностей в современной IT индустрии. Информация для тех, кто не до конца понимает, что эти уровни значат.
⇨ Build a Jenkins Server on Ubuntu 24.04: Easy Setup Tutorial
Пошаговая инструкция по установке Jenkins. Честно говоря не знаю, для чего сейчас это может кому-то пригодиться. Если начинать с нуля изучать CI/CD, то Jenkins уже не очень актуален. Его время проходит. Тем не менее, инструкция актуальная и позволяет копипастом поднять всё то же самое.
⇨ Обзор и тестирование TerraMaster F4-424
Подробный обзор NAS сервера, про который я вообще раньше не слышал. Впервые увидел бренд TerraMaster. Бегло посмотрел видео. На вид попытка создать конкуренцию Synology. Под капотом тоже своя система, похожая по возможностям на SynologyOS. По ценам дешевле Synology, но всё равно дороговато выглядит. Автор в итоге xpenology поставил на это железо :) По факту дешевле собрать любой подходящий самосбор и установить туда xpenology.
#видео
⇨ Обновляем MariaDB c 10.11 на 11.4
Пошаговое обновление MariaDB на свежую ветку. В видео ничего особенного, просто наглядная демонстрация процесса на основе статьи по обновлению из документации.
⇨ Self-Hosted AI That's Actually Useful
Интересное и полезное видео с обзором AI движков, которые можно запустить на своём железе. Автор проделал это и пока кратко рассказал основное. Я так понял, будут дальше видео на эту тему.
⇨ pfSense Alternatives: Firewall Solutions for your Network
Автор разобрал альтернативы самому популярному бесплатному софтовому шлюзу: OPNsense, Untangle, Unifi Security Devices, Sophos UTM Home Edition, MikroTik RouterOS.
⇨ The Best Note-Taking App For Linux Users: Standard Notes Review
Обзор программы для хранения заметок Standard Notes. Впервые про неё услышал. Автор рассказывает про свои мытарства в этой стезе. Он тоже использовал Joplin, но отказался от него из-за багов. Пробовал все популярные решения, в том числе те, что я тут недавно упоминал и остановился на Standard Notes. По обзору реально выглядит неплохо. Визуально лучше Joplin. Придётся тоже пробовать.
⇨ Твой новый dashboard Homepage
Очень подборный обзор, установка и настройка очередного дашборда для серверов и сервисов на них. Интересная штука, есть интеграция с Proxmox, Mikrotik, Portainer, Traefik и многим другим популярным софтом. Это аналог Dashy или Heimdall, про которые я ранее писал. У автора интересные видео, всегда с удовольствием смотрю.
⇨ Uptime Kuma. Мониторим свои сервисы
Обзор системы мониторинга для тех, кто всё ещё про неё не знает. Рекомендую если не знакомы. Хотя я в итоге для легковесного мониторинга перешёл на Gatus.
⇨ Prometheus - Как мониторить Динамичное количество серверов на AWS ?
Пример настройки Prometheus для мониторинга динамических сред.
⇨ OpenVPN-сервер на Mikrotik: от подключения мобильных устройств до десктопов
Очень подробный разбор темы настройки OpenVPN на микротиках от известного тренера Романа Козлова.
⇨ Инструменты мониторинга трафика в Mikrotik
Короткое видео для новичков в Mikrotik. Автор наглядно показал 3 способа просмотра трафика в Микротике: torch, connections, sniffer.
⇨ Junior vs Middle vs Senior в чем отличие? Пример задач для Junior DevOps
Автор описал своё видение уровней должностей в современной IT индустрии. Информация для тех, кто не до конца понимает, что эти уровни значат.
⇨ Build a Jenkins Server on Ubuntu 24.04: Easy Setup Tutorial
Пошаговая инструкция по установке Jenkins. Честно говоря не знаю, для чего сейчас это может кому-то пригодиться. Если начинать с нуля изучать CI/CD, то Jenkins уже не очень актуален. Его время проходит. Тем не менее, инструкция актуальная и позволяет копипастом поднять всё то же самое.
⇨ Обзор и тестирование TerraMaster F4-424
Подробный обзор NAS сервера, про который я вообще раньше не слышал. Впервые увидел бренд TerraMaster. Бегло посмотрел видео. На вид попытка создать конкуренцию Synology. Под капотом тоже своя система, похожая по возможностям на SynologyOS. По ценам дешевле Synology, но всё равно дороговато выглядит. Автор в итоге xpenology поставил на это железо :) По факту дешевле собрать любой подходящий самосбор и установить туда xpenology.
#видео
YouTube
Обновляем MariaDB c 10.11 на 11.4
В видео рассмотрим процесс перехода на новую версию MariaDB, обратим внимание на потенциальные проблемы и их решения.
Этот канал посвящён теме поддержки сайтов: от технических аспектов системного администрирования до вопросов экономической эффективности…
Этот канал посвящён теме поддержки сайтов: от технических аспектов системного администрирования до вопросов экономической эффективности…
🎓 У хостера Selectel есть небольшая "академия", где в открытом доступе есть набор курсов. Они неплохого качества. Где-то по верхам в основном теория, а где-то полезные практические вещи. Я бы обратил внимание на два курса, которые показались наиболее полезными:
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
{kind=link}
Недавно очень крупно ошибся из-за невнимательности. Нужно было купить небольшой дедик под веб сервер, настроить и перенести туда сайты. И я жёстко ошибся с размерами дисков самого сервера и виртуалки, что доставило много хлопот на ровном месте. Расскажу обо всём по порядку.
Арендовал сервер с двумя SSD дисками 480 ГБ по описанию сервера. Автоматом выбрал шаблон Proxmox VE с mdadm в RAID1 и сразу получил настроенный гипервизор. Стандартный шаблон предлагает простую разбивку: 1 ГБ на /boot, 5 ГБ на swap и остальное на корень системы. Не стал ничего менять, оставил как есть.
Развернул гипервизор, быстро сделал некоторые настройки. На диски вообще не смотрел. Создал виртуалку с диском 450 ГБ типа qcow2 и дальше начал с ней работать. В голове прикинул, что диски 480 ГБ, система примерно 5 ГБ. Других виртуалок не будет. В целом нормально.
Всё настроил, данные закинул. Повозил их туда-сюда по серверу. Приходит уведомление от мониторинга, что на гипервизоре заканчивается место на диске. Причём там занято уже 98% было, на виртуалке реальных данных - 300 ГБ. Удивился. Захожу на гипервизор, смотрю. Там раздел под корень диска по факту вышел всего 440 ГБ. То есть заявленные характеристики диска 480 ГБ в реальном размере это 446 ГБ: 1 на /boot, 5 на swap, 440 на корень.
Тут я сразу понял всю глубину своей ошибки, так как простого решения у неё нет, кроме очередного переноса. Причём просто так не переедешь на другой гипервизор без перенастройки виртуалки. Следующая градация дисков на сервере для аренды - 960 ГБ, что почти в 2 раза дороже, но реально такой объём не нужен. А на диски 480 ГБ эта виртуалки уже не переедет.
Такая вот ошибка из-за невнимательности. Поторопился и не проверил. Даже мысли не возникло на эту тему, хотя всем известно, что объём диска из описания не соответствует реальному.
Но благодаря этой ошибке я придумал полную техническую реализацию исправления. Узнал некоторые вещи, о существовании которых даже не слышал. Кое-что потестил и проверил, как работает. Вечером отдельно всё расскажу с техническими подробностями. На самом деле всё можно ужать и вернуть в доступный объём. Для этого надо:
1️⃣ Уменьшить файловую систему на виртуалке.
2️⃣ Уменьшить размер раздела диска в виртуалке.
3️⃣ Уменьшить размер qcow2 файла.
Каждая из операций потенциально опасная, к тому же на виртуалке раздел один и он корень, отмонтировать на лету и ужать его не получится. Но решение есть.
#ошибка
Арендовал сервер с двумя SSD дисками 480 ГБ по описанию сервера. Автоматом выбрал шаблон Proxmox VE с mdadm в RAID1 и сразу получил настроенный гипервизор. Стандартный шаблон предлагает простую разбивку: 1 ГБ на /boot, 5 ГБ на swap и остальное на корень системы. Не стал ничего менять, оставил как есть.
Развернул гипервизор, быстро сделал некоторые настройки. На диски вообще не смотрел. Создал виртуалку с диском 450 ГБ типа qcow2 и дальше начал с ней работать. В голове прикинул, что диски 480 ГБ, система примерно 5 ГБ. Других виртуалок не будет. В целом нормально.
Всё настроил, данные закинул. Повозил их туда-сюда по серверу. Приходит уведомление от мониторинга, что на гипервизоре заканчивается место на диске. Причём там занято уже 98% было, на виртуалке реальных данных - 300 ГБ. Удивился. Захожу на гипервизор, смотрю. Там раздел под корень диска по факту вышел всего 440 ГБ. То есть заявленные характеристики диска 480 ГБ в реальном размере это 446 ГБ: 1 на /boot, 5 на swap, 440 на корень.
Тут я сразу понял всю глубину своей ошибки, так как простого решения у неё нет, кроме очередного переноса. Причём просто так не переедешь на другой гипервизор без перенастройки виртуалки. Следующая градация дисков на сервере для аренды - 960 ГБ, что почти в 2 раза дороже, но реально такой объём не нужен. А на диски 480 ГБ эта виртуалки уже не переедет.
Такая вот ошибка из-за невнимательности. Поторопился и не проверил. Даже мысли не возникло на эту тему, хотя всем известно, что объём диска из описания не соответствует реальному.
Но благодаря этой ошибке я придумал полную техническую реализацию исправления. Узнал некоторые вещи, о существовании которых даже не слышал. Кое-что потестил и проверил, как работает. Вечером отдельно всё расскажу с техническими подробностями. На самом деле всё можно ужать и вернуть в доступный объём. Для этого надо:
1️⃣ Уменьшить файловую систему на виртуалке.
2️⃣ Уменьшить размер раздела диска в виртуалке.
3️⃣ Уменьшить размер qcow2 файла.
Каждая из операций потенциально опасная, к тому же на виртуалке раздел один и он корень, отмонтировать на лету и ужать его не получится. Но решение есть.
#ошибка
Как уменьшить размер файловой системы с ext4?
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
Файловая система на разделе
Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
Добавляем ещё один исполняемый файл
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
# /sbin/resize2fs /dev/sda1 50GФайловая система на разделе
/dev/sda1 будет уменьшена до 50G, если там хватит свободного места для этого. То есть данных должно быть меньше. В общем случае перед выполнением операции и после рекомендуется проверить файловую систему на ошибки:# /sbin/e2fsck -yf /dev/sda1Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
# /sbin/resize2fs /dev/sda1 50Gresize2fs 1.47.0 (5-Feb-2023)Filesystem at /dev/sda1 is mounted on /; on-line resizing required/sbin/resize2fs: On-line shrinking not supported# /sbin/e2fsck -yf /dev/sda1e2fsck 1.47.0 (5-Feb-2023)/dev/sda1 is mounted.e2fsck: Cannot continue, aborting.Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
/etc/initramfs-tools/hooks/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case $1 in
prereqs)
prereqs
exit 0
;;
esac
. /usr/share/initramfs-tools/hook-functions
copy_exec /sbin/e2fsck
copy_exec /sbin/resize2fs
exit 0
Добавляем ещё один исполняемый файл
/etc/initramfs-tools/scripts/local-premount/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case "$1" in
prereqs)
prereqs
exit 0
;;
esac
# simple device example
/sbin/e2fsck -yf /dev/sda1
/sbin/resize2fs /dev/sda1 50G
/sbin/e2fsck -yf /dev/sda1
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
# ls /boot | grep configconfig-6.1.0-12-amd64config-6.1.0-13-amd64config-6.1.0-20-amd64config-6.1.0-22-amd64# update-initramfs -u -k 6.1.0-22-amd64update-initramfs: Generating /boot/initrd.img-6.1.0-22-amd64Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Если я где-то упоминаю о том, что настроил гипервизор и поднял на нём одну виртуальную машину, неизменно получаю вопросы, зачем так делать. В данном случае вроде как и смысла нет. Помню, что когда-то уже писал по этому поводу, но не смог найти заметку, поэтому пишу снова.
Итак, зачем поднимать гипервизор ради одной виртуалки? На первый взгляд логичнее всё сделать на железе и получить максимальную утилизацию ресурсов сервера. Дальше сугубо моё личное мнение. Не призываю делать именно так и не утверждаю, что это правильно.
1️⃣ Работа на гипервизоре отвязывает вас от железа. Вы без каких-либо проблем можете переехать на другой сервер с таким же гипервизором и без особых проблем на другой гипервизор. Перенести систему с железа хоть и тоже решаемая задача, но более трудоёмкая и длительная. Это существенный плюс. Просто покупаешь другой сервер и перекидываешь туда виртуалку. Никаких проблем.
2️⃣ Виртуальную машину проще бэкапить целиком с уровня гипервизора без остановки. Быстрее развернуть копию в другом месте. Удобнее автоматически проверять бэкапы. Быстрее делаются инкрементные копии. С этой стороны явные плюсы. Все гипервизоры имеют поддержку создания бэкапов со своего уровня.
3️⃣ Проще управлять ресурсами сервера. Если не занят весь диск, то возможно вам когда-то понадобится добавить виртуальные машины. Возможно нужно будет протестировать работу виртуалки в более зажатом состоянии по ресурсам, чтобы проверить, как она себя поведёт перед переездом в другое место. Может дорастёте до кластера и добавите этот гипервизор в кластер. Тут более широкое пространство для манёвра.
➖ Минус только один - вы немного теряете в производительности из-за лишней прослойки в виде виртуализации. По CPU и RAM разница минимальна, на уровне погрешности измерений. Для дисковых операций разница может быть более существенной, но не кардинально. Цифры могут сильно плавать в зависимости от гипервизоров, файловых систем, типов дисков и т.д. Если взять LXC контейнер, то там накладных расходов ещё меньше, практически нет. Но переносимость у такой системы будет хуже.
Таким образом, я уже очень давно всю полезную нагрузку запускаю только и исключительно в виртуальных машинах. Ничего на железо, кроме гипервизора, не ставлю, даже если одна виртуалка будет утилизировать все ресурсы сервера.
#виртуализация
Итак, зачем поднимать гипервизор ради одной виртуалки? На первый взгляд логичнее всё сделать на железе и получить максимальную утилизацию ресурсов сервера. Дальше сугубо моё личное мнение. Не призываю делать именно так и не утверждаю, что это правильно.
1️⃣ Работа на гипервизоре отвязывает вас от железа. Вы без каких-либо проблем можете переехать на другой сервер с таким же гипервизором и без особых проблем на другой гипервизор. Перенести систему с железа хоть и тоже решаемая задача, но более трудоёмкая и длительная. Это существенный плюс. Просто покупаешь другой сервер и перекидываешь туда виртуалку. Никаких проблем.
2️⃣ Виртуальную машину проще бэкапить целиком с уровня гипервизора без остановки. Быстрее развернуть копию в другом месте. Удобнее автоматически проверять бэкапы. Быстрее делаются инкрементные копии. С этой стороны явные плюсы. Все гипервизоры имеют поддержку создания бэкапов со своего уровня.
3️⃣ Проще управлять ресурсами сервера. Если не занят весь диск, то возможно вам когда-то понадобится добавить виртуальные машины. Возможно нужно будет протестировать работу виртуалки в более зажатом состоянии по ресурсам, чтобы проверить, как она себя поведёт перед переездом в другое место. Может дорастёте до кластера и добавите этот гипервизор в кластер. Тут более широкое пространство для манёвра.
➖ Минус только один - вы немного теряете в производительности из-за лишней прослойки в виде виртуализации. По CPU и RAM разница минимальна, на уровне погрешности измерений. Для дисковых операций разница может быть более существенной, но не кардинально. Цифры могут сильно плавать в зависимости от гипервизоров, файловых систем, типов дисков и т.д. Если взять LXC контейнер, то там накладных расходов ещё меньше, практически нет. Но переносимость у такой системы будет хуже.
Таким образом, я уже очень давно всю полезную нагрузку запускаю только и исключительно в виртуальных машинах. Ничего на железо, кроме гипервизора, не ставлю, даже если одна виртуалка будет утилизировать все ресурсы сервера.
#виртуализация
Открытый практикум Linux by Rebrain: HTTP-клиенты для Linux
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
24 Июля (Среда) в 19:00 по МСК
Программа практикума:
🔹Познакомимся с HTTP-клиентами: curl, httpie и другими
🔹Изучим отладочные опции
🔹Рассмотрим передачу параметров запроса к серверу
Кто ведёт?
Даниил Батурин – Основатель проекта VyOS. Основатель проекта VyOS, системы для корпоративных и провайдерских маршрутизаторов с открытым исходным кодом.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2Vtzqw86Gsj
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
24 Июля (Среда) в 19:00 по МСК
Программа практикума:
🔹Познакомимся с HTTP-клиентами: curl, httpie и другими
🔹Изучим отладочные опции
🔹Рассмотрим передачу параметров запроса к серверу
Кто ведёт?
Даниил Батурин – Основатель проекта VyOS. Основатель проекта VyOS, системы для корпоративных и провайдерских маршрутизаторов с открытым исходным кодом.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2Vtzqw86Gsj
Если вы используете динамический размер дисков под виртуальные машины, то рано или поздно возникнет ситуация, когда реально внутри VM данных будет условно 50 ГБ, а динамический диск размером в 100 ГБ будет занимать эти же 100 ГБ на гипервизоре.
Я раньше решал эту задачу для HyperV и виртуалок с Linux. Сейчас уже не помню точную реализацию, но смысл был в том, что незанятое пространство внутри VM надо было принудительно заполнить нулями и выполнить что-то со стороны гипервизора. Помню виртуалку в 500 ГБ, где реально использовалось 40 ГБ. Она была очень критичная, там был самописный call центр на базе Elastix. Интересно, кто-нибудь помнит его? Хороший был продукт для VOIP. Так вот, эта виртуалка занимала на диске гипервизора реальные 500 ГБ и не получалось её перенести в доступное для этого окно. Call центр почти круглые сутки работал. Ужать по размеру диска её не получилось, но когда она стала занимать реальные 40 ГБ, переносить её стало значительно проще и быстрее.
С Proxmox сейчас стало всё намного проще. Никаких ручных действий. Если у вас в виртуалках динамические диски, а это иногда оправданно для экономии места, когда есть возможность расселять виртуалки, когда на гипервизоре заканчивается место (так делают почти все хостеры VPS), то достаточно выполнить пару простых действий, чтобы виртуалки занимали тот объём, сколько реальных данных там есть.
Для этого можно воспользоваться официальным руководством:
⇨ Shrink Qcow2 Disk Files
Достаточно указать тип дискового контроллера Virtio-SCSI, а для самого диска установить параметр Discard. После этого внутри VM с Linux выполнить команду:
Все современные дистрибутивы Linux имеют systemd службу с fstrim и таймер для запуска. Диск на самом гипервизоре ужмётся до реального размера данных внутри VM. Проверить это можно так:
Если внутри витуалки добавить занимаемый объём, то это сразу же будет видно на гипервизоре:
Смотрим ещё раз на файл диска:
Удаляем в виртуалке файл:
Смотрим на размер диска:
Ничего не поменялось. А если сделаем fstrim внутри VM, реальный размер диска уменьшится.
То же самое можно сделать и с уровня гипервизора, но для этого нужно будет выключить виртуальную машину, что неудобно, но иногда тоже может пригодиться. Это можно сделать с помощью утилиты virt-sparsify из комплекта libguests-tools:
Для успешной работы этой команды, на диске гипервизора должно быть место для создания копии образа диска, так как по факту команда делает копию, работает с ней и потом заменяет основной файл.
#proxmox #виртуализация
Я раньше решал эту задачу для HyperV и виртуалок с Linux. Сейчас уже не помню точную реализацию, но смысл был в том, что незанятое пространство внутри VM надо было принудительно заполнить нулями и выполнить что-то со стороны гипервизора. Помню виртуалку в 500 ГБ, где реально использовалось 40 ГБ. Она была очень критичная, там был самописный call центр на базе Elastix. Интересно, кто-нибудь помнит его? Хороший был продукт для VOIP. Так вот, эта виртуалка занимала на диске гипервизора реальные 500 ГБ и не получалось её перенести в доступное для этого окно. Call центр почти круглые сутки работал. Ужать по размеру диска её не получилось, но когда она стала занимать реальные 40 ГБ, переносить её стало значительно проще и быстрее.
С Proxmox сейчас стало всё намного проще. Никаких ручных действий. Если у вас в виртуалках динамические диски, а это иногда оправданно для экономии места, когда есть возможность расселять виртуалки, когда на гипервизоре заканчивается место (так делают почти все хостеры VPS), то достаточно выполнить пару простых действий, чтобы виртуалки занимали тот объём, сколько реальных данных там есть.
Для этого можно воспользоваться официальным руководством:
⇨ Shrink Qcow2 Disk Files
Достаточно указать тип дискового контроллера Virtio-SCSI, а для самого диска установить параметр Discard. После этого внутри VM с Linux выполнить команду:
# fstrim -avВсе современные дистрибутивы Linux имеют systemd службу с fstrim и таймер для запуска. Диск на самом гипервизоре ужмётся до реального размера данных внутри VM. Проверить это можно так:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 1.32 GiBcluster_size: 65536Если внутри витуалки добавить занимаемый объём, то это сразу же будет видно на гипервизоре:
# dd if=/dev/urandom of=testfile bs=1M count=2048Смотрим ещё раз на файл диска:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 3.32 GiBcluster_size: 65536Удаляем в виртуалке файл:
# rm testfileСмотрим на размер диска:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 3.32 GiBcluster_size: 65536Ничего не поменялось. А если сделаем fstrim внутри VM, реальный размер диска уменьшится.
То же самое можно сделать и с уровня гипервизора, но для этого нужно будет выключить виртуальную машину, что неудобно, но иногда тоже может пригодиться. Это можно сделать с помощью утилиты virt-sparsify из комплекта libguests-tools:
# virt-sparsify --in-place vm-100-disk-0.qcow2Для успешной работы этой команды, на диске гипервизора должно быть место для создания копии образа диска, так как по факту команда делает копию, работает с ней и потом заменяет основной файл.
#proxmox #виртуализация
Недавно делал заметку про ограничение использования диска при создании дампов базы данных, чтобы не вызывать замедление всех остальных процессов в системе. Использовал утилиту pv. Способ простой и рабочий, я его внедрил и оставил. Поставленную задачу решает.
Тем не менее, захотелось сделать это более изящно через использование приоритетов. Если диск не нагружен, то неплохо было бы его использовать с максимальной производительностью. А если нагружен, то отдать приоритет другим процесса. Это был бы наиболее рациональный и эффективный способ.
Я знаю утилиту ionice, которая в большинстве дистрибутивов есть по умолчанию. Она как раз существует для решения именно этой задачи. У неё не так много параметров, так что пользоваться ей просто. Приоритет можно передать через ключи. Для этого нужно задать режим работы:
◽Idle - идентификатор 1, процесс работает с диском только тогда, когда он не занят
◽Best effort - идентификатор 2, стандартный режим работы с возможностью выставления приоритета от 0 до 7 (0 - максимальный)
◽Real time - режим работы реального времени тоже с возможностью задавать приоритет от 0 до 7
На практике это выглядит примерно так:
Скопировали tempfile в домашний каталог в режиме idle. По идее, это то, что нужно. На практике этот приоритет не работает. Провёл разные тесты и убедился в том, что в Debian 12 ionice не работает вообще. Стал копать, почему так.
В Linux системах существуют разные планировщики процессов в отношении ввода-вывода. Раньше использовался Cfq, и ionice работает только с ним. В современных системах используется более эффективный планировщик Deadline. Проверить планировщик можно так:
Принципиальная разница этих планировщиков в том, что cfq равномерно распределяет процессы с операциями ввода-вывода, и это нормально подходит для hdd, а deadline отдаёт приоритет чтению в ущерб записи, что в целом уменьшает отклик для ssd дисков. С ними использовать его более рационально. Можно заставить работать ionice, но тогда придётся вернуть планировщик cfq, что не хочется делать, если у вас ssd диски.
Для планировщика deadline не смог найти простого и наглядного решения приоритизации процессов записи на диск. Стандартным решением по ограничению скорости, по типу того, что делает pv, является использование параметров systemd:
- IOReadBandwidthMax - объём данных, который сервису разрешается прочитать с блочных устройств за одну секунду;
- IOWriteBandwidthMax - объём данных, который сервису разрешается записать на блочные устройства за одну секунду.
Причём у него есть также параметр IODeviceWeight, что является примерно тем же самым, что и приоритет. Но работает он тоже только с cfq.
Для того, чтобы ограничить скорость записи на диск с помощью systemd, необходимо создать юнит для этого. Покажу на примере создания тестового файла с помощью dd с ограничением скорости записи в 20 мегабайт в секунду.
Запускаем:
Проверяем:
Это можно использовать как заготовку для реального задания. Если хочется потестировать в консоли, то запускайте так:
Простое рабочее решение без использования дополнительных утилит. Обращаю внимание, что если сработает кэширование записи, то визуально ограничение можно не увидеть. Я это наблюдал. И только с флагом sync её хорошо сразу же видно.
#systemd
Тем не менее, захотелось сделать это более изящно через использование приоритетов. Если диск не нагружен, то неплохо было бы его использовать с максимальной производительностью. А если нагружен, то отдать приоритет другим процесса. Это был бы наиболее рациональный и эффективный способ.
Я знаю утилиту ionice, которая в большинстве дистрибутивов есть по умолчанию. Она как раз существует для решения именно этой задачи. У неё не так много параметров, так что пользоваться ей просто. Приоритет можно передать через ключи. Для этого нужно задать режим работы:
◽Idle - идентификатор 1, процесс работает с диском только тогда, когда он не занят
◽Best effort - идентификатор 2, стандартный режим работы с возможностью выставления приоритета от 0 до 7 (0 - максимальный)
◽Real time - режим работы реального времени тоже с возможностью задавать приоритет от 0 до 7
На практике это выглядит примерно так:
# ionice -c 3 cp tempfile ~/Скопировали tempfile в домашний каталог в режиме idle. По идее, это то, что нужно. На практике этот приоритет не работает. Провёл разные тесты и убедился в том, что в Debian 12 ionice не работает вообще. Стал копать, почему так.
В Linux системах существуют разные планировщики процессов в отношении ввода-вывода. Раньше использовался Cfq, и ionice работает только с ним. В современных системах используется более эффективный планировщик Deadline. Проверить планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineПринципиальная разница этих планировщиков в том, что cfq равномерно распределяет процессы с операциями ввода-вывода, и это нормально подходит для hdd, а deadline отдаёт приоритет чтению в ущерб записи, что в целом уменьшает отклик для ssd дисков. С ними использовать его более рационально. Можно заставить работать ionice, но тогда придётся вернуть планировщик cfq, что не хочется делать, если у вас ssd диски.
Для планировщика deadline не смог найти простого и наглядного решения приоритизации процессов записи на диск. Стандартным решением по ограничению скорости, по типу того, что делает pv, является использование параметров systemd:
- IOReadBandwidthMax - объём данных, который сервису разрешается прочитать с блочных устройств за одну секунду;
- IOWriteBandwidthMax - объём данных, который сервису разрешается записать на блочные устройства за одну секунду.
Причём у него есть также параметр IODeviceWeight, что является примерно тем же самым, что и приоритет. Но работает он тоже только с cfq.
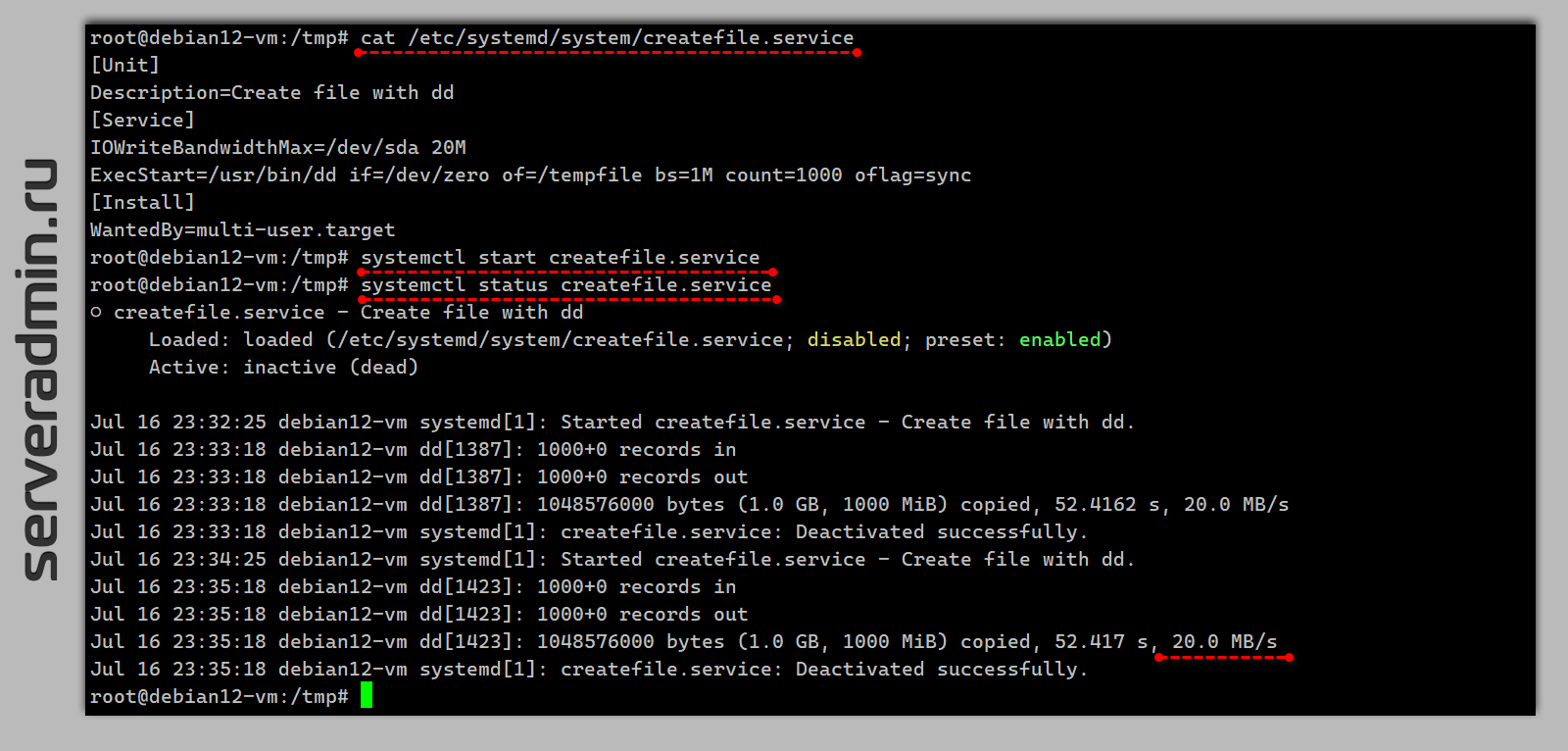
Для того, чтобы ограничить скорость записи на диск с помощью systemd, необходимо создать юнит для этого. Покажу на примере создания тестового файла с помощью dd с ограничением скорости записи в 20 мегабайт в секунду.
[Unit]Description=Create file with dd[Service]IOWriteBandwidthMax=/dev/sda 20MExecStart=/usr/bin/dd if=/dev/zero of=/tempfile bs=1M count=1000 oflag=sync[Install]WantedBy=multi-user.targetЗапускаем:
# systemctl start createfile.serviceПроверяем:
# systemctl status createfile.servicesystemd[1]: Started createfile.service - Create file with dd.dd[1423]: 1000+0 records indd[1423]: 1000+0 records outdd[1423]: 1048576000 bytes (1.0 GB, 1000 MiB) copied, 52.417 s, 20.0 MB/ssystemd[1]: createfile.service: Deactivated successfully.Это можно использовать как заготовку для реального задания. Если хочется потестировать в консоли, то запускайте так:
# systemd-run --scope -p IOWriteBandwidthMax='/dev/sda 20M' dd status=progress if=/dev/zero of=/tempfile bs=1M count=1000 oflag=syncПростое рабочее решение без использования дополнительных утилит. Обращаю внимание, что если сработает кэширование записи, то визуально ограничение можно не увидеть. Я это наблюдал. И только с флагом sync её хорошо сразу же видно.
#systemd
{kind=link}
Я смотрю почти все видео, что выпускает англоязычный IT блогер Christian Lempa. Его ролики регулярно попадают в мои обзоры. Недавно он рассказал в отдельном видео про свои репозитории, где он собирает кучу всевозможной информации по конфигам, шаблонам, настройкам различных популярных сервисов:
▶️ My Docker Compose *boilerplates* and update management
Тут он рассказывает только про один репозиторий - boilerplates, где собирает docker-compose популярных сервисов, шаблоны terraform, vagrant, packer для proxmox, роли ansible. Интересно и полезно посмотреть на работы другого человека.
Помимо этого у него есть и другие репозитории:
- Dotfiles - конфиги от его системы macOS
- Cheat-Sheets - подборка команд популярных консольных утилит
- Homelab - полное описание на уровне кода его домашней лаборатории
Последняя репа мне показалась наиболее интересной. Любопытно было глянуть, как у него там всё устроено. С учётом того, что за последний год-два я почти все его видео просмотрел.
Судя по коммитам, всё это регулярно обновляется и поддерживается.
#видео
▶️ My Docker Compose *boilerplates* and update management
Тут он рассказывает только про один репозиторий - boilerplates, где собирает docker-compose популярных сервисов, шаблоны terraform, vagrant, packer для proxmox, роли ansible. Интересно и полезно посмотреть на работы другого человека.
Помимо этого у него есть и другие репозитории:
- Dotfiles - конфиги от его системы macOS
- Cheat-Sheets - подборка команд популярных консольных утилит
- Homelab - полное описание на уровне кода его домашней лаборатории
Последняя репа мне показалась наиболее интересной. Любопытно было глянуть, как у него там всё устроено. С учётом того, что за последний год-два я почти все его видео просмотрел.
Судя по коммитам, всё это регулярно обновляется и поддерживается.
#видео
YouTube
BEST Docker Compose Templates + Update Process in Renovate
Get started with Mend Renovate: https://www.mend.io/mend-renovate/
In this video, I'll show you the latest updates on my famous boilerplates repository on GitHub. This project, which includes templates and config examples for technologies like Docker Compose…
In this video, I'll show you the latest updates on my famous boilerplates repository on GitHub. This project, which includes templates and config examples for technologies like Docker Compose…
Вчера в заметке я немного рассказал про планировщики процессов для блочных устройств в Linux и чуток ошибся. Тема новая и непростая, особо не погружался в неё, поэтому не совсем правильно понял. Немного больше её изучил, поэтому своими словами дам краткую выжимку того, что я по ней понял и узнал.
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
Тут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
Тут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
Загрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
А для применения планировщика создайте правило udev, например в отдельном файле
В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Наиболее актуальны сейчас следующие планировщики:
🔹mq-deadline - по умолчанию отдаёт приоритет запросам на чтение.
🔹kyber - более продвинутый вариант deadline, написанный под самые современные быстрые устройства, даёт ещё меньшую задержку на чтение, чем deadline.
🔹CFQ и BFQ - второй является усовершенствованной версией первого. Формируют очередь запросов по процессам и приоритетам. Дают возможность объединять запросы в классы, назначать приоритеты.
🔹none или noop - отсутствие какого-либо алгоритма обработки запросов, простая FIFO-очередь.
В современных системах на базе ядра Linux планировщик может выбираться автоматически в зависимости от используемых дисков. Разные дистрибутивы могут использовать разные подходы к выбору. Посмотреть текущий планировщик можно так:
# cat /sys/block/sda/queue/scheduler[none] mq-deadlineТут я вчера ошибся. Не понял, что в данном случае используется планировщик none. То, что выделено в квадратных скобках - используемый планировщик. Вот ещё пример:
# cat /sys/block/vda/queue/scheduler[mq-deadline] kyber bfq noneТут выбран планировщик mq-deadline. Поддержка планировщика реализована через модули ядра. Если вы хотите добавить отсутствующий планировщик, то загрузите соответствующий модуль.
# cat /sys/block/sda/queue/scheduler[none] mq-deadline# modprobe kyber-iosched# cat /sys/block/sda/queue/scheduler[none] mq-deadline kyber# echo kyber > /sys/block/sda/queue/scheduler# cat /sys/block/sda/queue/schedulermq-deadline [kyber] noneЗагрузили модуль kyber-iosched и активировали этот планировщик. Действовать это изменение будет до перезагрузки системы. Для постоянной работы нужно добавить загрузку этого модуля ядра. Добавьте в файл
/etc/modules-load.d/modules.conf название модуля:kyber-ioschedА для применения планировщика создайте правило udev, например в отдельном файле
/etc/udev/rules.d/schedulerset.rules:ACTION=="add|change", SUBSYSTEM=="block", KERNEL=="sd?", ATTR{queue/scheduler}="kyber"В виртуальных машинах чаще всего по умолчанию выставляется планировщик none и в общем случае это оправдано, так как реальной записью на диск управляет гипервизор, а если есть рейд контроллер, то он. К примеру, в Proxmox на диски автоматически устанавливается планировщик mq-deadline. По крайней мере у меня это так. Проверил на нескольких серверах. А вот в виртуалках с Debian 12 на нём автоматически устанавливается none. Хостеры на своих виртуальных машинах могут автоматически выставлять разные планировщики. Мне встретились none и mq-deadline. Другие не видел.
Теперь что всё это значит на практике. Оценить влияние различных планировщиков очень трудно, так как нужно чётко эмулировать рабочую нагрузку и делать замеры. Если вам нужно настроить приоритизацию, то выбор планировщика в сторону BFQ будет оправдан. Особенно если у вас какой-то проект или сетевой диск с кучей файлов, с которыми постоянно работают, а вам нужно часто снимать с него бэкапы или выполнять какие-либо ещё фоновые действия. Тогда будет удобно настроить минимальный приоритет для фоновых процессов, чтобы они не мешали основной нагрузке.
Если у вас быстрые современные диски, вам нужен приоритет и минимальный отклик для операций чтения, то имеет смысл использовать kyber. Если у вас обычный сервер общего назначения на обычный средних SSD дисках, то можно смело ставить none и не париться.
Некоторые полезные объёмные материалы, которые изучил:
🔥https://selectel.ru/blog/blk-mq-tests/ (много тестов)
⇨ https://habr.com/ru/articles/337102/
⇨ https://redos.red-soft.ru/base/arm/base-arm-hardware/disks/using-ssd/io-scheduler/
⇨ https://timeweb.cloud/blog/blk-mq-i-planirovschiki-vvoda-vyvoda
#linux #kernel #perfomance
Сейчас очень большая конкуренция на рынке хостинг услуг, в частности в аренде VPS/VDS. Выбрать из множества предложений лучшее - трудная задача. Я вам не скажу, как её решить, потому что сам не знаю, но дам некоторые комментарии и рекомендации на основе своего опыта.
Первое, с чего хочу начать, так это разделить аренду виртуалок на 2 принципиально разные услуги: выделенные одиночные VPS и аренда VPS у облачных провайдеров, типа yandex cloud, vk cloud и других вендоров, где помимо VPS наберётся несколько десятков услуг, которые могут быть объединены в единой платформе. Цены у облаков будут на первый взгляд намного выше и вызывать недоумение. Но это только на первый взгляд.
Арендованные услуги могут очень сильно отличаться по производительности, подчас раз в 5-10, если брать скорость записи на диск. У меня много разных хостеров постоянно в работе. Зашёл в 5 разных VPS у разных хостеров и просто посмотрел на процессоры и скорость записи на диск.
Последний самый дорогой, но он и по производительности на голову выше. Ещё и передаёт в виртуалку модель процессора. Это Xeon Gold 6254 CPU 3.10GHz. Я тут упоминал этого хостера мельком и видел комментарии на тему того, что у него дорого, есть дешевле.
Да, дешевле всегда есть, но дёшево быстро точно не будет. Как и нет гарантии, что за дорого будет быстро. Но шанс есть. Дёшево быстро точно не будет. Я для тестов выше не назвал имена компаний, потому что по большому счёту это не имеет смысла. Там в списке есть виртуалка, которая покупалась дороже рынка по отдельному тарифу и поначалу работала быстро. Как обычно бывает, купишь, проверишь, и она работает годами. Вот я сейчас проверил, и процессор по частоте уже не тот, и скорость записи на диск одна из самых низких. То есть виртуалка судя по всему переехала со временем на более слабую ноду.
Как вы видите, разброс по производительности солидный. А люди зачастую выбирают тупо по ценам и рассказывают потом, что я тут такую же виртуалку купил в 2 раза дешевле. Такую, да не такую. Я так примерно для себя знаю, у каких хостеров будет дёшево и медленно, а у кого дорого и быстро. Это всё актуально в моменте, так как может измениться. Дорого и хорошо у Serverspace, RuVDS. Дёшево и медленно у VDSina, IHor, Simplecloud.
Публикация выходит за лимит символов, так что продолжение ниже
(комментарии пишите ко второй заметке)
👇👇👇👇👇
#хостинг
Первое, с чего хочу начать, так это разделить аренду виртуалок на 2 принципиально разные услуги: выделенные одиночные VPS и аренда VPS у облачных провайдеров, типа yandex cloud, vk cloud и других вендоров, где помимо VPS наберётся несколько десятков услуг, которые могут быть объединены в единой платформе. Цены у облаков будут на первый взгляд намного выше и вызывать недоумение. Но это только на первый взгляд.
Арендованные услуги могут очень сильно отличаться по производительности, подчас раз в 5-10, если брать скорость записи на диск. У меня много разных хостеров постоянно в работе. Зашёл в 5 разных VPS у разных хостеров и просто посмотрел на процессоры и скорость записи на диск.
# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 2599.996# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB) copied, 57.8859 s, 74.2 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 3695.998# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 22.5497 s, 190 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 2249.998# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 45.4332 s, 94.5 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 2194.710# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 14.9843 s, 287 MB/s# cat /proc/cpuinfo | grep "cpu MHz"cpu MHz : 3100.000# dd status=progress if=/dev/zero of=/tempfile bs=1M count=4096 oflag=sync4294967296 bytes (4.3 GB, 4.0 GiB) copied, 7.25733 s, 592 MB/sПоследний самый дорогой, но он и по производительности на голову выше. Ещё и передаёт в виртуалку модель процессора. Это Xeon Gold 6254 CPU 3.10GHz. Я тут упоминал этого хостера мельком и видел комментарии на тему того, что у него дорого, есть дешевле.
Да, дешевле всегда есть, но дёшево быстро точно не будет. Как и нет гарантии, что за дорого будет быстро. Но шанс есть. Дёшево быстро точно не будет. Я для тестов выше не назвал имена компаний, потому что по большому счёту это не имеет смысла. Там в списке есть виртуалка, которая покупалась дороже рынка по отдельному тарифу и поначалу работала быстро. Как обычно бывает, купишь, проверишь, и она работает годами. Вот я сейчас проверил, и процессор по частоте уже не тот, и скорость записи на диск одна из самых низких. То есть виртуалка судя по всему переехала со временем на более слабую ноду.
Как вы видите, разброс по производительности солидный. А люди зачастую выбирают тупо по ценам и рассказывают потом, что я тут такую же виртуалку купил в 2 раза дешевле. Такую, да не такую. Я так примерно для себя знаю, у каких хостеров будет дёшево и медленно, а у кого дорого и быстро. Это всё актуально в моменте, так как может измениться. Дорого и хорошо у Serverspace, RuVDS. Дёшево и медленно у VDSina, IHor, Simplecloud.
Публикация выходит за лимит символов, так что продолжение ниже
(комментарии пишите ко второй заметке)
👇👇👇👇👇
#хостинг
Продолжение, начало выше 👆👆👆👆👆
Теперь ещё раз вернусь к облачным провайдерам. Почему у них дороже. Причин тут несколько. Их может не быть полным списком у кого-то одного, но так или иначе встречается у разных облаков.
1️⃣ Облака могут указывать конкретные модели процессоров, ядра которых вы арендуете. Чем современнее и быстрее, тем дороже. У обычных хостеров очень редко это указано. Только для каких-то отдельных тарифов на самых быстрых процессорах. Всё остальное будет безлико, берёте кота в мешке.
2️⃣ Облако может вам продать гарантированное ядро процессора, 20%, 50% от него. Градация может быть разной. Но смысл в том, что если вам оверселят процессор, то вы это знаете и это стоит дешевле. Хостеры обычных VPS все оверселят и вы никогда не узнаете до какой степени. Купить гарантированно одно ядро у них скорее всего не получится.
3️⃣ То же самое касается дисков. В облаке обычно на выбор даются разные вариантов дисков с разной гарантированной производительностью.
4️⃣ Облако предлагает набор дополнительных услуг, которые могут ничего не стоить. Например, программный маршрутизатор с файрволом, который умеет натить трафик в вашу локальную сеть из виртуалок. На нём могут висеть ваши внешние IP адреса, а виртуалки спокойно меняться, без потери IP адресов. Вы можете организовать локальную сеть из своих виртуальных машин, чего у обычных, особенно самых дешёвых хостеров, просто нет. Всё это ведёт к удорожанию услуги.
Если взять какое-то облако, купить там CPU с гарантированными 20% производительности самой низкой частоты, выбрать самый медленный диск, то окажется не сильно дороже какого-нибудь обычного хостера VPS. Будет скорее всего всё равно дороже, но уже не так сильно, как кажется на первый взгляд. Разница будет обусловлена дополнительными услугами облака.
Написал всё это к тому, чтобы вы не выбирали услуги тупо по стоимости. Любой хостинг имеет право на жизнь. И дорогой, и дешёвый. На каждую услугу найдётся запрос. Смотрите шире на эту тему, тестируйте то, что вы арендуете. Хотя, конечно, это не так просто сделать. Всё, что берётся на тест или покупается впервые, скорее всего получает какой-то приоритет по производительности, чтобы заманить клиента и оставить хорошее впечатление. И отзывы тут не помогут. Только свой опыт использования.
Для быстрого теста виртуалок удобно использовать какой-то софт. Например, утилиту stress. Я лично привык тупо проверять скорость записи на диск. Так как обычно это узкое место. Полной нагрузки по CPU или памяти у меня практически никогда не бывает.
#хостинг
Теперь ещё раз вернусь к облачным провайдерам. Почему у них дороже. Причин тут несколько. Их может не быть полным списком у кого-то одного, но так или иначе встречается у разных облаков.
1️⃣ Облака могут указывать конкретные модели процессоров, ядра которых вы арендуете. Чем современнее и быстрее, тем дороже. У обычных хостеров очень редко это указано. Только для каких-то отдельных тарифов на самых быстрых процессорах. Всё остальное будет безлико, берёте кота в мешке.
2️⃣ Облако может вам продать гарантированное ядро процессора, 20%, 50% от него. Градация может быть разной. Но смысл в том, что если вам оверселят процессор, то вы это знаете и это стоит дешевле. Хостеры обычных VPS все оверселят и вы никогда не узнаете до какой степени. Купить гарантированно одно ядро у них скорее всего не получится.
3️⃣ То же самое касается дисков. В облаке обычно на выбор даются разные вариантов дисков с разной гарантированной производительностью.
4️⃣ Облако предлагает набор дополнительных услуг, которые могут ничего не стоить. Например, программный маршрутизатор с файрволом, который умеет натить трафик в вашу локальную сеть из виртуалок. На нём могут висеть ваши внешние IP адреса, а виртуалки спокойно меняться, без потери IP адресов. Вы можете организовать локальную сеть из своих виртуальных машин, чего у обычных, особенно самых дешёвых хостеров, просто нет. Всё это ведёт к удорожанию услуги.
Если взять какое-то облако, купить там CPU с гарантированными 20% производительности самой низкой частоты, выбрать самый медленный диск, то окажется не сильно дороже какого-нибудь обычного хостера VPS. Будет скорее всего всё равно дороже, но уже не так сильно, как кажется на первый взгляд. Разница будет обусловлена дополнительными услугами облака.
Написал всё это к тому, чтобы вы не выбирали услуги тупо по стоимости. Любой хостинг имеет право на жизнь. И дорогой, и дешёвый. На каждую услугу найдётся запрос. Смотрите шире на эту тему, тестируйте то, что вы арендуете. Хотя, конечно, это не так просто сделать. Всё, что берётся на тест или покупается впервые, скорее всего получает какой-то приоритет по производительности, чтобы заманить клиента и оставить хорошее впечатление. И отзывы тут не помогут. Только свой опыт использования.
Для быстрого теста виртуалок удобно использовать какой-то софт. Например, утилиту stress. Я лично привык тупо проверять скорость записи на диск. Так как обычно это узкое место. Полной нагрузки по CPU или памяти у меня практически никогда не бывает.
#хостинг
В работе веб сервера иногда есть необходимость разработчикам получить доступ к исходникам сайта напрямую. Проще всего и безопаснее это сделать по протоколу sftp. Эта на первый взгляд простая задача на деле может оказаться не такой уж и простой с множеством нюансов. В зависимости от настроек веб сервера, может использоваться разный подход. Я сейчас рассмотрю один из них, а два других упомяну в самом конце. Подробно рассказывать обо всех методах очень длинно получится.
Для примера возьму классический стек на базе nginx (angie) + php-fpm. Допустим, у нас nginx и php-fpm работают от пользователя
Сразу предвижу комментарии на тему того, что так делать неправильно и в код лезть напрямую не надо. Я был бы только рад, если бы туда никто не лазил. Мне так проще управлять и настраивать. Но иногда надо и выбирать не приходится. Разработчиков выбираю не я, как и их методы работы.
Первым делом добавляю в систему нового пользователя, для которого не будет установлен shell. Подключаться он сможет только по sftp:
Теперь нам нужно настроить sshd таким образом, чтобы он разрешил только указанному пользователю подключаться по sftp, не пускал его дальше указанного каталога с сайтами, а так же сразу указывал необходимые нам права доступа через umask. Позже я поясню, зачем это надо.
Находим в файле
Вместо неё добавляем:
Перезапускаем sshd:
Если сейчас попробовать подключиться пользователем webdev, то ничего не получится. Особенность настройки ChrootDirectory в sshd в том, что у указанной директории владелец должен быть root, а у всех остальных не должно быть туда прав на запись. В данном случае нам это не помешает, но в некоторых ситуациях возникают неудобства. На остальных директориях внутри ChrootDirectory права доступа и владельцы могут быть любыми.
Теперь пользователь webdev может подключиться по sftp. Он сразу попадёт в директорию
Благодаря указанной umask 002 в настройках sshd все созданные пользователем webdev файлы будут иметь права 664 и каталоги 775. То есть будет полный доступ и у пользователя, и у группы. Так что веб сервер сможет нормально работать с этими файлами, и наоборот.
Способ немного корявый и в некоторых случаях может приводить к некоторым проблемам, но решаемым. Я придумал это сам по ходу дела, так как изначально к этим исходникам прямого доступа не должно было быть. Если кто-то знает, как сделать лучше, поделитесь.
Если же вы заранее планируете прямой доступ к исходникам сайта или сайтов разными людьми или сервисами, то сделать лучше по-другому. Сразу создавайте под каждый сайт отдельного системного пользователя. Запускайте под ним php-fpm пул. Для каждого сайта он будет свой. Владельцем исходников сайта делайте этого пользователя и его группу. А пользователя, под которым работает веб сервер, добавьте в группу этого пользователя. Это более удобный, практичный и безопасный способ. Я его описывал в своей статье.
Третий вариант - создавайте новых пользователей для доступа к исходникам с таким же uid, как и у веб сервера. Чрутьте их в свои домашние каталоги, а сайты им добавляйте туда же через mount bind. Я когда то давно этот способ тоже описывал в статье.
#webserver
Для примера возьму классический стек на базе nginx (angie) + php-fpm. Допустим, у нас nginx и php-fpm работают от пользователя
www-data, исходники сайта лежат в /var/www/html. Владельцем файлов и каталогов будет пользователь и группа www-data. Типичная ситуация. Нам надо дать доступ разработчику напрямую к исходникам, чтобы он мог вносить изменения в код сайта. Сразу предвижу комментарии на тему того, что так делать неправильно и в код лезть напрямую не надо. Я был бы только рад, если бы туда никто не лазил. Мне так проще управлять и настраивать. Но иногда надо и выбирать не приходится. Разработчиков выбираю не я, как и их методы работы.
Первым делом добавляю в систему нового пользователя, для которого не будет установлен shell. Подключаться он сможет только по sftp:
# useradd -s /sbin/nologin webdev# passwd webdevТеперь нам нужно настроить sshd таким образом, чтобы он разрешил только указанному пользователю подключаться по sftp, не пускал его дальше указанного каталога с сайтами, а так же сразу указывал необходимые нам права доступа через umask. Позже я поясню, зачем это надо.
Находим в файле
/etc/ssh/sshd_config строку и комментируем её:#Subsystem sftp /usr/lib/openssh/sftp-serverВместо неё добавляем:
Subsystem sftp internal-sftp -u 002Match User webdev ChrootDirectory /var/www ForceCommand internal-sftp -u 002Перезапускаем sshd:
# systemctl restart sshdЕсли сейчас попробовать подключиться пользователем webdev, то ничего не получится. Особенность настройки ChrootDirectory в sshd в том, что у указанной директории владелец должен быть root, а у всех остальных не должно быть туда прав на запись. В данном случае нам это не помешает, но в некоторых ситуациях возникают неудобства. На остальных директориях внутри ChrootDirectory права доступа и владельцы могут быть любыми.
# chown root:root /var/www# chmod 0755 /var/wwwТеперь пользователь webdev может подключиться по sftp. Он сразу попадёт в директорию
/var/www и не сможет из неё выйти дальше в систему. Осталось решить вопрос с правами. Я сделал так. Добавил пользователя webdev в группу www-data, а пользователя www-data в группу webdev:# usermod -aG www-data webdev# usermod -aG webdev www-dataБлагодаря указанной umask 002 в настройках sshd все созданные пользователем webdev файлы будут иметь права 664 и каталоги 775. То есть будет полный доступ и у пользователя, и у группы. Так что веб сервер сможет нормально работать с этими файлами, и наоборот.
Способ немного корявый и в некоторых случаях может приводить к некоторым проблемам, но решаемым. Я придумал это сам по ходу дела, так как изначально к этим исходникам прямого доступа не должно было быть. Если кто-то знает, как сделать лучше, поделитесь.
Если же вы заранее планируете прямой доступ к исходникам сайта или сайтов разными людьми или сервисами, то сделать лучше по-другому. Сразу создавайте под каждый сайт отдельного системного пользователя. Запускайте под ним php-fpm пул. Для каждого сайта он будет свой. Владельцем исходников сайта делайте этого пользователя и его группу. А пользователя, под которым работает веб сервер, добавьте в группу этого пользователя. Это более удобный, практичный и безопасный способ. Я его описывал в своей статье.
Третий вариант - создавайте новых пользователей для доступа к исходникам с таким же uid, как и у веб сервера. Чрутьте их в свои домашние каталоги, а сайты им добавляйте туда же через mount bind. Я когда то давно этот способ тоже описывал в статье.
#webserver
Юмор и не только на злобу дня. Думаю, все уже слышали сегодняшние новости про массовый BSOD на виндах. Пострадавшим, конечно, не до смеха. По факту получилось так, что ПО, которое должно защищать информационную систему, надёжно её положило получше всякого вируса.
Отец знакомого работает в Microsoft. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать всю технику, отключать автообновления и скачивать все драйвера на флешку. Сейчас едем куда-то далеко за город. Не знаю что происходит, но мне кажется, началось.
Комментарий с англоязычного форума (но это не точно): Microsoft restricted updates for Russia, so they're fine. We are completely fucked.
Перевод: Microsoft заблокировал обновления в России, так что у них всё в порядке. У нас полная жопа.
Много интересных комментариев прочёл в ветке на реддите:
https://www.reddit.com/r/crowdstrike/comments/1e6vmkf/bsod_error_in_latest_crowdstrike_update/
Multibillion dollar NSW infrastructure project, most of the office is down.
Перевод: Многомиллиардный инфраструктурный проект в Новом Южном Уэльсе, большая часть офиса закрыта.
Workstations and servers here in Aus... fleet of 50k+ - someone is going to have fun.
Перевод: Рабочие станции и серверы здесь, в Австралии, насчитывают более 50 тысяч единиц - у кого-то будет весело.
Time to log in and check if it hit us…oh god I hope not…350k endpoints.
EDIT: 210K BSODS all at 10:57 PST....and it keeps going up...this is bad....
Перевод: Пора зайти и проверить, дошло ли это до нас…о боже, я надеюсь, что нет... 350 тысяч конечных точек.
Добавлено: 210 тысяч BSOD в 10: 57 по восточному времени .... и оно продолжает увеличиваться... это плохо....
Жуть берёт от таких сообщений. Их же автоматом теперь не реанимировать. Надо либо руками там что-то править, либо накатывать заново из бэкапов. У кого-то будут напряжённые выходные. Хорошо ещё, что сегодня пятница, а не понедельник.
А вообще, всё это выглядит как репетиция к инфоциду.
Гигакорпорация MAGMA, став глобальным цифровым монополистом после захвата китайской IT-индустрии по итогам Последней мировой войны, много лет целенаправленно добивалась сосредоточения всей цифровой информации в мире на своих серверах.
.......
Кроме того, перенос данных на магмовские облачные серверы рекламировался как "безопасный", потому что "уж Магма-то слишком велика, чтобы рухнуть, и уж эти-то данные точно не пострадают ни при каких обстоятельствах". В итоге к началу 2070-х гг. практически вся информация на планете хранилась и обрабатывалась на северах MAGMA, за исключением немногих "пиратских" (нелегальных или полулегальных) автономных устройств, а также военных и прочих правительственных систем США и их главных союзников - но и они работали на программном обеспечении от MAGMA.
.........
Непосредственно Второму инфоциду предшествовал глобальный финансовый крах, докатившийся ко второй декаде марта до США: банкротство крупнейших банков и компаний, в том числе самой MAGMA, государственный дефолт США и банкротство Федерального резерва. Неизвестно, кто и с какой целью отдал приказ на тотальное уничтожение информации. На этот счёт существует множество равно неподтверждённых версий и теорий заговора.
...........
С точки простого пользователя Второй инфоцид выглядел так, что вся связь пропала, все его электронные устройства превратились в кирпичи, деньги на банковских счетах и прочие цифровые активы перестали существовать (наличных денег давно нигде не было), машины-автопилоты встали (других тоже давно не было), а вся инфраструктура жизнеобеспечения "умных домов" и "умных городов" отключилась. Городская индустриальная цивилизация в той форме, к какой она пришла ко второй половине XXI века, прекратила существование.
#разное
Отец знакомого работает в Microsoft. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать всю технику, отключать автообновления и скачивать все драйвера на флешку. Сейчас едем куда-то далеко за город. Не знаю что происходит, но мне кажется, началось.
Комментарий с англоязычного форума (но это не точно): Microsoft restricted updates for Russia, so they're fine. We are completely fucked.
Перевод: Microsoft заблокировал обновления в России, так что у них всё в порядке. У нас полная жопа.
Много интересных комментариев прочёл в ветке на реддите:
https://www.reddit.com/r/crowdstrike/comments/1e6vmkf/bsod_error_in_latest_crowdstrike_update/
Multibillion dollar NSW infrastructure project, most of the office is down.
Перевод: Многомиллиардный инфраструктурный проект в Новом Южном Уэльсе, большая часть офиса закрыта.
Workstations and servers here in Aus... fleet of 50k+ - someone is going to have fun.
Перевод: Рабочие станции и серверы здесь, в Австралии, насчитывают более 50 тысяч единиц - у кого-то будет весело.
Time to log in and check if it hit us…oh god I hope not…350k endpoints.
EDIT: 210K BSODS all at 10:57 PST....and it keeps going up...this is bad....
Перевод: Пора зайти и проверить, дошло ли это до нас…о боже, я надеюсь, что нет... 350 тысяч конечных точек.
Добавлено: 210 тысяч BSOD в 10: 57 по восточному времени .... и оно продолжает увеличиваться... это плохо....
Жуть берёт от таких сообщений. Их же автоматом теперь не реанимировать. Надо либо руками там что-то править, либо накатывать заново из бэкапов. У кого-то будут напряжённые выходные. Хорошо ещё, что сегодня пятница, а не понедельник.
А вообще, всё это выглядит как репетиция к инфоциду.
Гигакорпорация MAGMA, став глобальным цифровым монополистом после захвата китайской IT-индустрии по итогам Последней мировой войны, много лет целенаправленно добивалась сосредоточения всей цифровой информации в мире на своих серверах.
.......
Кроме того, перенос данных на магмовские облачные серверы рекламировался как "безопасный", потому что "уж Магма-то слишком велика, чтобы рухнуть, и уж эти-то данные точно не пострадают ни при каких обстоятельствах". В итоге к началу 2070-х гг. практически вся информация на планете хранилась и обрабатывалась на северах MAGMA, за исключением немногих "пиратских" (нелегальных или полулегальных) автономных устройств, а также военных и прочих правительственных систем США и их главных союзников - но и они работали на программном обеспечении от MAGMA.
.........
Непосредственно Второму инфоциду предшествовал глобальный финансовый крах, докатившийся ко второй декаде марта до США: банкротство крупнейших банков и компаний, в том числе самой MAGMA, государственный дефолт США и банкротство Федерального резерва. Неизвестно, кто и с какой целью отдал приказ на тотальное уничтожение информации. На этот счёт существует множество равно неподтверждённых версий и теорий заговора.
...........
С точки простого пользователя Второй инфоцид выглядел так, что вся связь пропала, все его электронные устройства превратились в кирпичи, деньги на банковских счетах и прочие цифровые активы перестали существовать (наличных денег давно нигде не было), машины-автопилоты встали (других тоже давно не было), а вся инфраструктура жизнеобеспечения "умных домов" и "умных городов" отключилась. Городская индустриальная цивилизация в той форме, к какой она пришла ко второй половине XXI века, прекратила существование.
#разное
{kind=link}
🎓 Сегодня будет очередная публикация с хорошими обучающими материалами по Linux, Asterisk, Zabbix. Публикация необычная, потому что я случайно посмотрел на автора материалов и понял, что я его знаю, причём не в качестве преподавателя и специалиста по Linux.
Итак, вот сайт:
⇨ https://wiki.koobik.net
Здесь 3 хороших структурированных курса в текстовом (❗️) виде с небольшой теорией и лабораторными работами. Я немного посмотрел их, формат понравился. Нигде не увидел дату курсов, но это не что-то сильно старое. Навскидку, где-то года 2-3 назад записаны, судя по скриншотам Zabbix и версиям Ubuntu.
Автор - преподаватель курсов в учебном центре Специалист. Я там когда-то давно учился. Это не тот формат, что сейчас представлен в большинстве онлайн курсов. Больше похоже на академическое обучение с посещением лекций, выполнением лабораторок и сдачей экзаменов. По крайней мере раньше было так. Как сейчас - не знаю. Я там сертификацию от Microsoft проходил. Получил MCP.
Я узнал этого человека в далёком 2011 году на общественных мероприятиях под названием Русские Пробежки. На первых порах он был одним из их организаторов. Я лично участвовал в этих пробежках практически с самого начала. Пропустил только самую первую и, возможно, вторую. Как увидел в соцсетях информацию об этом, сразу присоединился.
Сами пробежки представляли из себя собрания молодёжи, ведущей здоровый образ жизни, с целью пропагандирования этого здорового образа жизни и совместных тренировок на открытом воздухе. Движение очень быстро набрало популярность и разошлось по всем городам России. Я даже в своём районе устраивал эти пробежки. Мы бегали по парку, занимались на турниках, купались в проруби.
В то время власть зачем-то активно противодействовала всему этому. На пробежки вызывали ОМОН, перекрывали, проходы, задерживали и т.д. Мероприятия посещали люди в штатском, вели видеофиксацию лиц участников. Хотя движение не политизировалось и было полностью организовано снизу. Я просто сам всё это наблюдал. В обществе, особенно у молодёжи, был огромный запрос на трезвость, потому что постоянная реклама пива, прочего алкоголя, безнравственность, постоянное пьянство на улицах, в парках задолбало. Сейчас в этом плане всё значительно лучше.
В том числе такая массовая поддержка трезвости повлияла на то, что я в какой-то момент полностью отказался от алкоголя. Просто убрал его из своей жизни. Это случилось более 10-ти лет назад. Где-то как раз со времён этих пробежек. С тех пор алкоголь вообще не употребляю и не вижу в этом смысла.
Вообще, приятно было находиться в обществе трезвых, здоровых, молодых и физически развитых людей. Чувствовалось, что таким мужчина и должен быть: трезвым, здоровым, физически крепким и т.д. Потом появилось движение Русские спарринги. Я увлёкся единоборствами, занимался боксом, рукопашным и ножевым боем. Постоянно ходил на спарринги по выходным и там дрался с разными людьми. Было интересно и полезно. Считаю, что любой мужчина должен уметь драться. Это идёт ему на пользу, даже если драться ему нигде не придётся. Готовность ударить и идти до конца в отстаивании своих интересов зачастую решает многие вопросы и без драки. Когда мужчина боится из-за неуверенности, начинает мямлить и идти на попятную, выглядит это жалко. А в итоге он оказывается бит.
Так что будьте сильными и трезвыми. Особенно на пороге смутных времён, которые нам предстоит пройти и победить. На ум пришли строки из песни Цоя
«Ты должен быть сильным,
Ты должен уметь сказать:
Руки прочь, прочь от меня.
Ты должен быть сильным,
Иначе зачем тебе быть?
Что будут стоить тысячи слов,
Когда важна будет крепость руки?
И вот ты стоишь на берегу
И думаешь плыть или не плыть».
Нашёл видео из своего архива тех времён. Выглядит наивно, если смотреть с опыта прожитых лет. Но молодость есть молодость. Она всегда кажется наивной в зрелом возрсте:
▶️ https://disk.yandex.ru/i/kmteYLLxLk9sxA
#обучение
Итак, вот сайт:
⇨ https://wiki.koobik.net
Здесь 3 хороших структурированных курса в текстовом (❗️) виде с небольшой теорией и лабораторными работами. Я немного посмотрел их, формат понравился. Нигде не увидел дату курсов, но это не что-то сильно старое. Навскидку, где-то года 2-3 назад записаны, судя по скриншотам Zabbix и версиям Ubuntu.
Автор - преподаватель курсов в учебном центре Специалист. Я там когда-то давно учился. Это не тот формат, что сейчас представлен в большинстве онлайн курсов. Больше похоже на академическое обучение с посещением лекций, выполнением лабораторок и сдачей экзаменов. По крайней мере раньше было так. Как сейчас - не знаю. Я там сертификацию от Microsoft проходил. Получил MCP.
Я узнал этого человека в далёком 2011 году на общественных мероприятиях под названием Русские Пробежки. На первых порах он был одним из их организаторов. Я лично участвовал в этих пробежках практически с самого начала. Пропустил только самую первую и, возможно, вторую. Как увидел в соцсетях информацию об этом, сразу присоединился.
Сами пробежки представляли из себя собрания молодёжи, ведущей здоровый образ жизни, с целью пропагандирования этого здорового образа жизни и совместных тренировок на открытом воздухе. Движение очень быстро набрало популярность и разошлось по всем городам России. Я даже в своём районе устраивал эти пробежки. Мы бегали по парку, занимались на турниках, купались в проруби.
В то время власть зачем-то активно противодействовала всему этому. На пробежки вызывали ОМОН, перекрывали, проходы, задерживали и т.д. Мероприятия посещали люди в штатском, вели видеофиксацию лиц участников. Хотя движение не политизировалось и было полностью организовано снизу. Я просто сам всё это наблюдал. В обществе, особенно у молодёжи, был огромный запрос на трезвость, потому что постоянная реклама пива, прочего алкоголя, безнравственность, постоянное пьянство на улицах, в парках задолбало. Сейчас в этом плане всё значительно лучше.
В том числе такая массовая поддержка трезвости повлияла на то, что я в какой-то момент полностью отказался от алкоголя. Просто убрал его из своей жизни. Это случилось более 10-ти лет назад. Где-то как раз со времён этих пробежек. С тех пор алкоголь вообще не употребляю и не вижу в этом смысла.
Вообще, приятно было находиться в обществе трезвых, здоровых, молодых и физически развитых людей. Чувствовалось, что таким мужчина и должен быть: трезвым, здоровым, физически крепким и т.д. Потом появилось движение Русские спарринги. Я увлёкся единоборствами, занимался боксом, рукопашным и ножевым боем. Постоянно ходил на спарринги по выходным и там дрался с разными людьми. Было интересно и полезно. Считаю, что любой мужчина должен уметь драться. Это идёт ему на пользу, даже если драться ему нигде не придётся. Готовность ударить и идти до конца в отстаивании своих интересов зачастую решает многие вопросы и без драки. Когда мужчина боится из-за неуверенности, начинает мямлить и идти на попятную, выглядит это жалко. А в итоге он оказывается бит.
Так что будьте сильными и трезвыми. Особенно на пороге смутных времён, которые нам предстоит пройти и победить. На ум пришли строки из песни Цоя
«Ты должен быть сильным,
Ты должен уметь сказать:
Руки прочь, прочь от меня.
Ты должен быть сильным,
Иначе зачем тебе быть?
Что будут стоить тысячи слов,
Когда важна будет крепость руки?
И вот ты стоишь на берегу
И думаешь плыть или не плыть».
Нашёл видео из своего архива тех времён. Выглядит наивно, если смотреть с опыта прожитых лет. Но молодость есть молодость. Она всегда кажется наивной в зрелом возрсте:
▶️ https://disk.yandex.ru/i/kmteYLLxLk9sxA
#обучение
Нашёл очень функциональный инструмент для логирования действий пользователей в подключениях по SSH к серверам. Речь пойдёт про open sourse проект sshlog. Выглядит он так, как-будто хотели сделать на его основе коммерческий продукт, но в какой-то момент передумали и забросили. Сделан он добротно и целостно. Расскажу по порядку.
📌 С помощью sshlog можно:
▪️ Логировать все подключения и отключения по SSH.
▪️ Записывать всю активность пользователя в консоли, в том числе вывод.
▪️ Отправлять уведомления по различным каналам связи на события, связанные с SSH: подключение, отключение, запуск команды и т.д.
▪️ Отправлять все записанные события и сессии на Syslog сервер.
▪️ Собирать метрики по количествам подключений, отключений, выполненных команд и т.д.
▪️ Наблюдать за чьей-то сессией и подключаться к ней для просмотра или взаимодействия.
▪️ Расширять функциональность с помощью плагинов.
Сразу скажу важное замечание. Записывать события пользователя root нельзя. Только обычных пользователей, даже если они сделают
Установить sshlog можно из репозитория разработчиков:
Репозиторий для Ubuntu, но для Debian тоже подходит. После установки автоматически создаётся служба systemd. В директории
-
-
В директории
Функциональность sshlog расширяется плагинами. Они все находятся в отдельном разделе с описанием и принципом работы. Все оповещения реализованы в виде плагинов. Есть готовые для email, slack, syslog, webhook. Оповещения отправляются при срабатывании actions. Так же по этим событиям могут выполняться и другие действия, например, запуск какой-то команды.
В общем, продукт функциональный и целостный. Покрывает большой пласт задач по контролю за сессиями пользователей. Удобно всё это разом слать куда-то по syslog в централизованное хранилище. По простоте и удобству, если мне не изменяет память, это лучшее, что я видел. Есть, конечно, Tlog от RedHat, но он более просто выглядит по возможностям и сложнее в настройке по сравнению с sshlog.
В репозитории есть несколько обращений на тему большого потребления CPU при работе. Я лично не сталкивался с этим во время тестов, но имейте ввиду, что такое возможно. Судя по всему есть какой-то неисправленный баг.
⇨ Сайт / Исходники
#ssh #logs #security
📌 С помощью sshlog можно:
▪️ Логировать все подключения и отключения по SSH.
▪️ Записывать всю активность пользователя в консоли, в том числе вывод.
▪️ Отправлять уведомления по различным каналам связи на события, связанные с SSH: подключение, отключение, запуск команды и т.д.
▪️ Отправлять все записанные события и сессии на Syslog сервер.
▪️ Собирать метрики по количествам подключений, отключений, выполненных команд и т.д.
▪️ Наблюдать за чьей-то сессией и подключаться к ней для просмотра или взаимодействия.
▪️ Расширять функциональность с помощью плагинов.
Сразу скажу важное замечание. Записывать события пользователя root нельзя. Только обычных пользователей, даже если они сделают
sudo su. В описании нигде этого не сказано, но я сам на практике убедился. Плюс, увидел такие же комментарии в вопросах репозитория. Установить sshlog можно из репозитория разработчиков:
# curl https://repo.sshlog.com/sshlog-ubuntu/public.gpg | gpg --yes --dearmor -o /usr/share/keyrings/repo-sshlog-ubuntu.gpg# echo "deb [arch=any signed-by=/usr/share/keyrings/repo-sshlog-ubuntu.gpg] https://repo.sshlog.com/sshlog-ubuntu/ stable main" > /etc/apt/sources.list.d/repo-sshlog-ubuntu.list# apt update && apt install sshlogРепозиторий для Ubuntu, но для Debian тоже подходит. После установки автоматически создаётся служба systemd. В директории
/etc/sshlog/conf.d будут 2 файла конфигурации:-
log_all_sessions.yaml - запись ssh сессий в директорию /var/log/sshlog/sessions, каждая сессия в отдельном лог файле, сохраняется в том числе вывод в консоли, а не только введённые команды.-
log_events.yaml - запись событий: подключения, отключения, введённые команды, общий лог для всех.В директории
/etc/sshlog/samples будут примеры некоторых других настроек. Вся конфигурация в формате yaml, читается легко, интуитивно. Возможности программы большие. Можно логировать только какие-то конкретные события. Например, запуск sudo. Либо команды от отдельного пользователя. Это можно настроить либо в событиях, либо в исключениях. Подробно механизм описан отдельно: sshlog config.Функциональность sshlog расширяется плагинами. Они все находятся в отдельном разделе с описанием и принципом работы. Все оповещения реализованы в виде плагинов. Есть готовые для email, slack, syslog, webhook. Оповещения отправляются при срабатывании actions. Так же по этим событиям могут выполняться и другие действия, например, запуск какой-то команды.
В общем, продукт функциональный и целостный. Покрывает большой пласт задач по контролю за сессиями пользователей. Удобно всё это разом слать куда-то по syslog в централизованное хранилище. По простоте и удобству, если мне не изменяет память, это лучшее, что я видел. Есть, конечно, Tlog от RedHat, но он более просто выглядит по возможностям и сложнее в настройке по сравнению с sshlog.
В репозитории есть несколько обращений на тему большого потребления CPU при работе. Я лично не сталкивался с этим во время тестов, но имейте ввиду, что такое возможно. Судя по всему есть какой-то неисправленный баг.
⇨ Сайт / Исходники
#ssh #logs #security
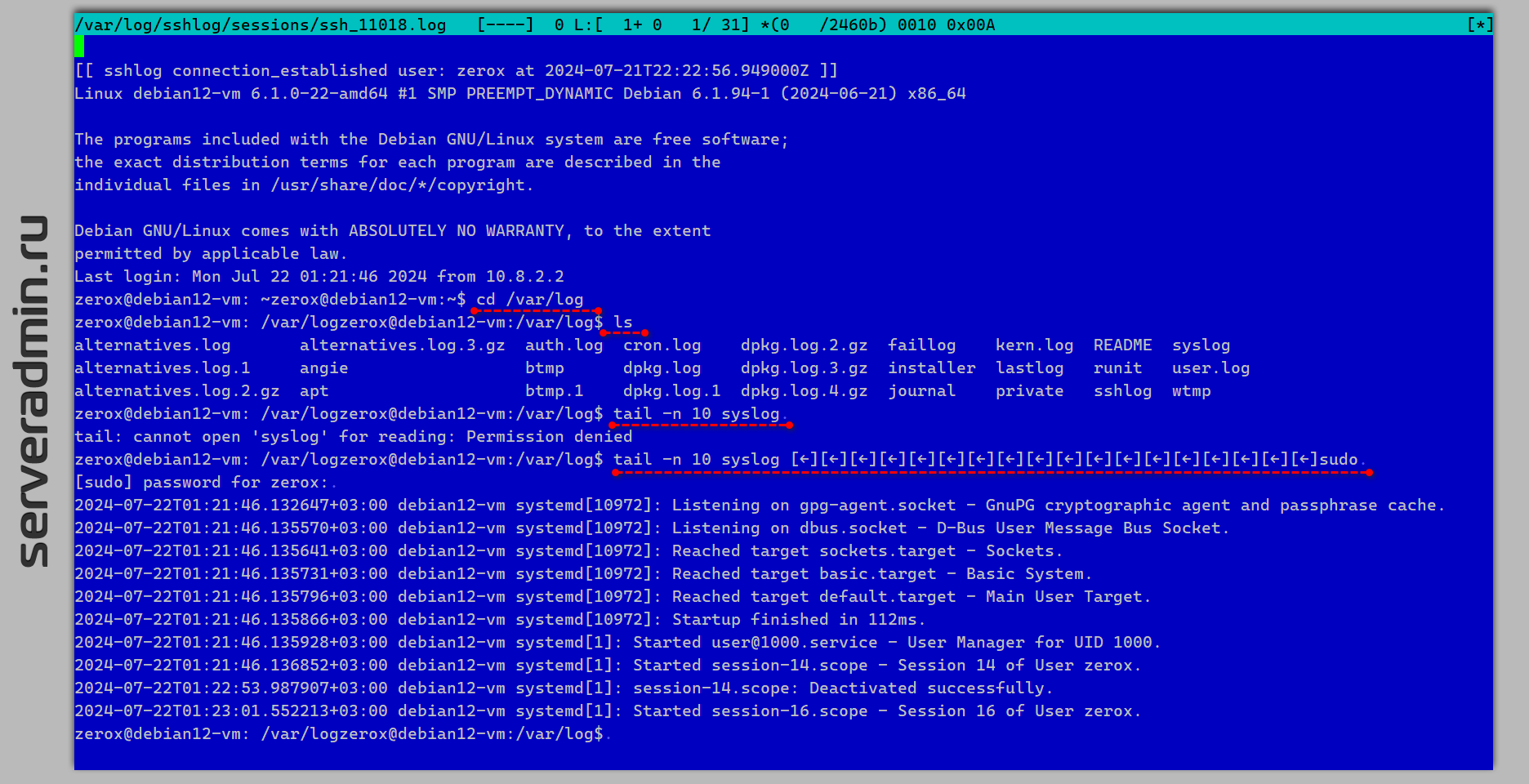{kind=link}