
Когда настраиваете сервер или кластер PostgreSQL, перед тем, как нагрузить его рабочей нагрузкой, хочется как-то протестировать его и посмотреть, как он себя поведёт под нагрузкой или в случае каких-то ошибок. Особенно это актуально, если у вас ещё и мониторинг настроен. Хочется на деле посмотреть, как он отработает.
Сделать подобное тестирование с имитацией рабочей нагрузки и ошибок можно с помощью утилиты Noisia. Она написала на Gо, есть в виде бинарника или rpm, deb пакета. Забрать можно из репозитория. Либо запустить через Docker.
Автор утилиты подробно рассказывает про принцип работы и функциональность на онлайн вебинаре — Noisia - генератор аварийных и нештатных ситуаций в PostgreSQL (текстовая расшифровка). Там описаны основные возможности и параметры для использования.
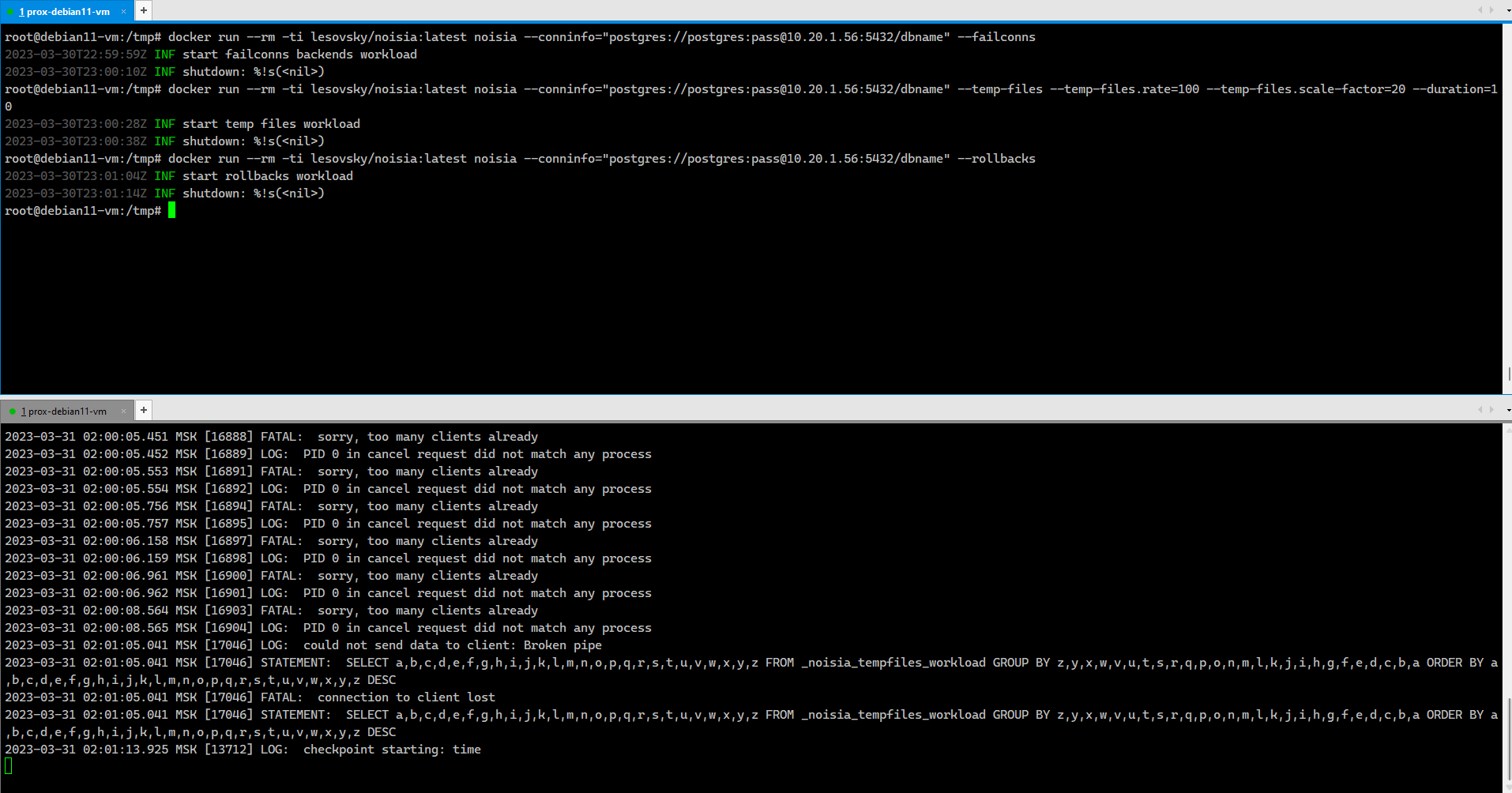
Вот простой пример исчерпания всех доступных подключений к базе, которые обязательно должны мониториться, чтобы своевременно увеличить лимит подключений, или разобраться, куда они все ушли.
Не забудьте настроить удалённые подключения к базе, либо запускайте нагрузку локально, не через docker.
Запуск транзакций, которые завершаются откатом (ROLLBACK), то есть заканчиваются с ошибкой. За ними обычно тоже следят (pg_stat_database.xact_rollback).
Ну и так далее. Все параметры можно посмотреть в help:
#postgresql
Сделать подобное тестирование с имитацией рабочей нагрузки и ошибок можно с помощью утилиты Noisia. Она написала на Gо, есть в виде бинарника или rpm, deb пакета. Забрать можно из репозитория. Либо запустить через Docker.
Автор утилиты подробно рассказывает про принцип работы и функциональность на онлайн вебинаре — Noisia - генератор аварийных и нештатных ситуаций в PostgreSQL (текстовая расшифровка). Там описаны основные возможности и параметры для использования.
Вот простой пример исчерпания всех доступных подключений к базе, которые обязательно должны мониториться, чтобы своевременно увеличить лимит подключений, или разобраться, куда они все ушли.
# docker run --rm -ti lesovsky/noisia:latest noisia \--conninfo="postgres://postgres:pass@10.20.1.56:5432/dbname" \--failconnsНе забудьте настроить удалённые подключения к базе, либо запускайте нагрузку локально, не через docker.
Запуск транзакций, которые завершаются откатом (ROLLBACK), то есть заканчиваются с ошибкой. За ними обычно тоже следят (pg_stat_database.xact_rollback).
# docker run --rm -ti lesovsky/noisia:latest noisia \--conninfo="postgres://postgres:pass@10.20.1.56:5432/dbname" \--rollbacks \--rollbacks.min-rate=10 \--jobs=3 \--duration=20Ну и так далее. Все параметры можно посмотреть в help:
# docker run --rm -ti lesovsky/noisia:latest noisia --help#postgresql
{kind=link}
👍64👎2
Пока занимался с PostgreSQL, вспомнил про простой и быстрый способ посмотреть статистику по запросам, который я использовал очень давно. Ещё во времена, когда не пользовался централизованными системами по сбору и анализу логов. Проверил методику, на удивление всё работает до сих пор, так что расскажу вам.
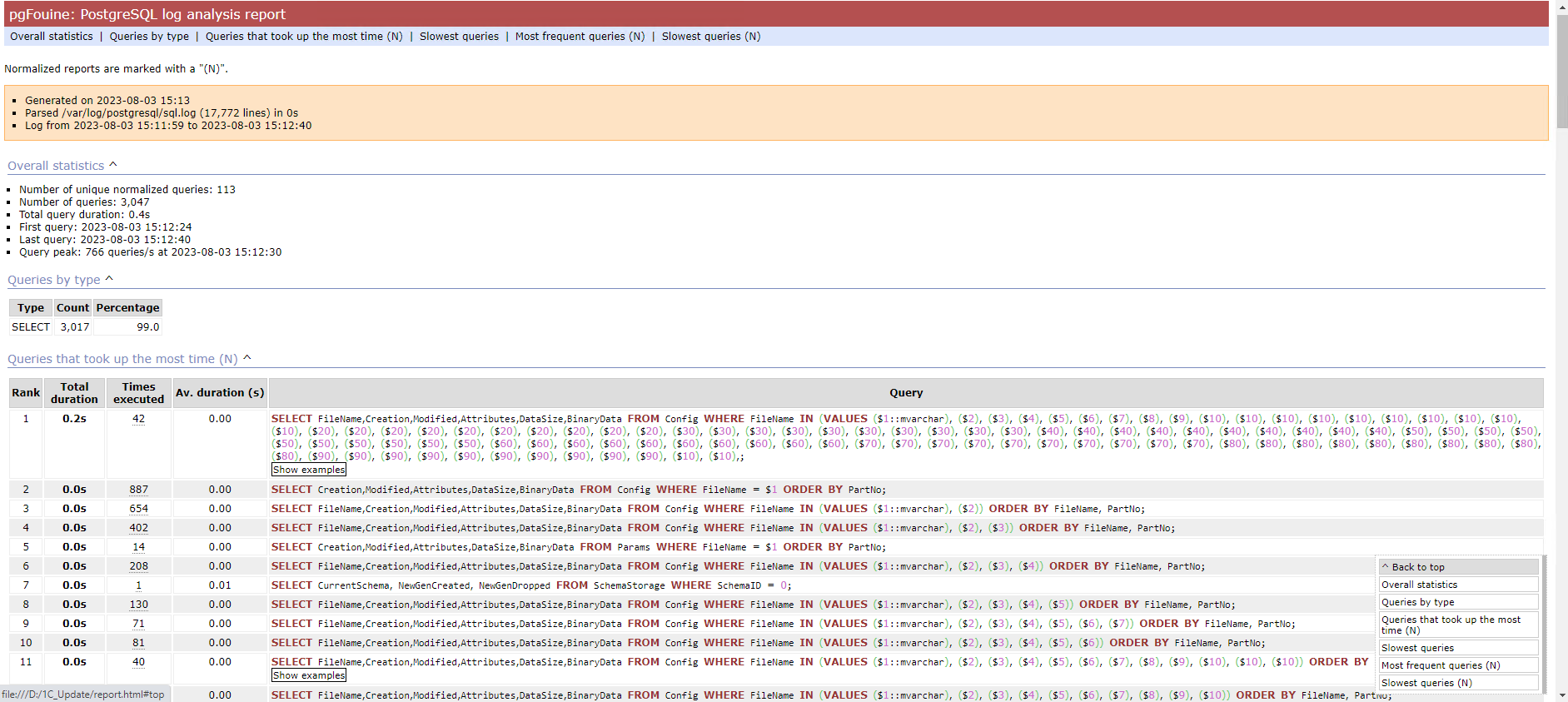
Речь пойдёт про анализатор запросов pgFouine. Продукт старый, последняя версия от 2010-го года. Обновление есть только для совместимости с версией php 7. Сам анализатор - это одиночный скрипт на php, который на входе берёт лог с запросами, а на выходе формирует одну html страницу со статистикой, которая включает в себя:
◽общую статистику по запросам, в том числе по их типам
◽запросы, которые занимают больше всего времени СУБД
◽топ медленных запросов
◽счётчик повторяющихся запросов
Для того, чтобы включить сбор логов, в конфигурационный файл PostgreSQL нужно добавить следующие параметры:
Это мы собираем только медленные запросы, дольше трех секунд. Если указать
Имеет смысл также отключить запись этих логов в общий лог, добавив
Перезапускаем сервисы:
Ждём, когда заполнится лог и отправляем его в pgFouine. Для этого достаточно скопировать себе файл pgfouine.php или весь репозиторий:
Теперь файл report.html можно открыть в браузере и посмотреть статистику. Предварительно нужно установить php, либо передать лог с запросами на машину, где php установлен. У меня нормально отработал на версии php 7.4.
Такой вот олдскул. Сейчас не знаю, кто так статистику смотрит. Есть парсеры логов для ELK или Graylog. Но для этого у вас должны быть эти системы. Надо туда отправить логи, распарсить, собрать дашборды. Это пуд соли съесть. А подобный разовый анализ можно сделать за 10 минут.
#postgresql
Речь пойдёт про анализатор запросов pgFouine. Продукт старый, последняя версия от 2010-го года. Обновление есть только для совместимости с версией php 7. Сам анализатор - это одиночный скрипт на php, который на входе берёт лог с запросами, а на выходе формирует одну html страницу со статистикой, которая включает в себя:
◽общую статистику по запросам, в том числе по их типам
◽запросы, которые занимают больше всего времени СУБД
◽топ медленных запросов
◽счётчик повторяющихся запросов
Для того, чтобы включить сбор логов, в конфигурационный файл PostgreSQL нужно добавить следующие параметры:
log_destination = 'syslog'syslog_facility = 'LOCAL0'syslog_ident = 'postgres'log_min_duration_statement = 3000 # 3000 мс = 3 секундыlog_duration = offlog_statement = 'none'Это мы собираем только медленные запросы, дольше трех секунд. Если указать
log_min_duration_statement = 0, будут логироваться все запросы. Логи будут писаться в syslog. Имеет смысл поместить их в отдельный файл. Для этого добавляем в конфигурационный файл rsyslog:LOCAL0.* -/var/log/postgresql/sql.logИмеет смысл также отключить запись этих логов в общий лог, добавив
LOCAL0.none:*.*;auth,authpriv.none;LOCAL0.none -/var/log/syslog*.=info;*.=notice;*.=warn;\ auth,authpriv.none;\ cron,daemon.none;\ mail,news.none;\ LOCAL0.none -/var/log/messagesПерезапускаем сервисы:
# systemctl restart postgresql# systemctl restart rsyslogЖдём, когда заполнится лог и отправляем его в pgFouine. Для этого достаточно скопировать себе файл pgfouine.php или весь репозиторий:
# git clone https://github.com/milo/pgFouine# cd pgFouine# php pgfouine.php -file /var/log/postgresql/sql.log > report.htmlТеперь файл report.html можно открыть в браузере и посмотреть статистику. Предварительно нужно установить php, либо передать лог с запросами на машину, где php установлен. У меня нормально отработал на версии php 7.4.
Такой вот олдскул. Сейчас не знаю, кто так статистику смотрит. Есть парсеры логов для ELK или Graylog. Но для этого у вас должны быть эти системы. Надо туда отправить логи, распарсить, собрать дашборды. Это пуд соли съесть. А подобный разовый анализ можно сделать за 10 минут.
#postgresql
{kind=link}
👍57👎1
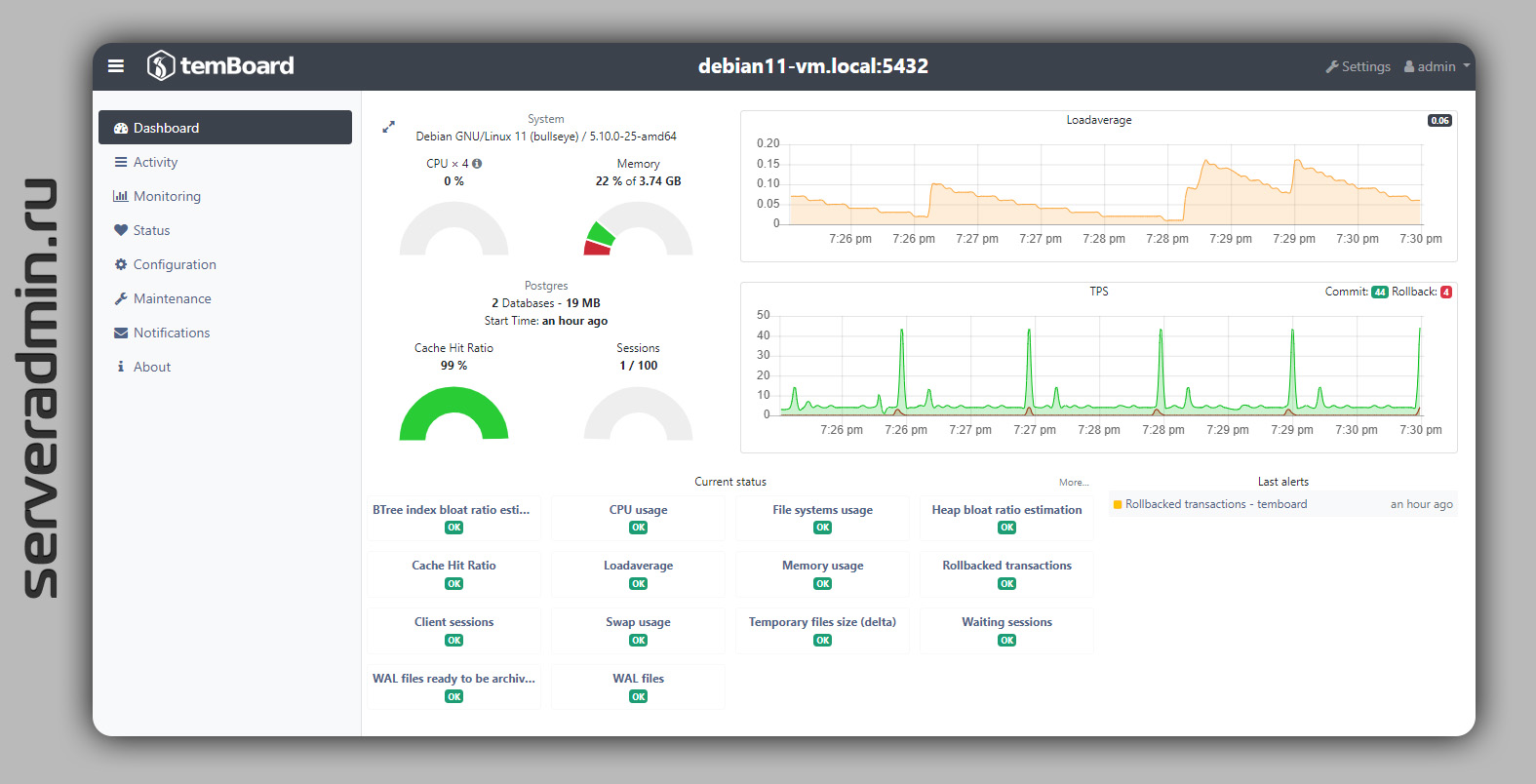
Существует удобный веб интерфейс для управления и мониторинга СУБД Postgresql - temBoard. Он по смыслу напоминает специализированный мониторинг Percona Monitoring and Management (PMM). Но почему-то не очень популярен, хотя написан людьми, которые контрибьютят в PostgreSQL. Есть новость на сайте postgresql от них с анонсом очередного релиза.
У меня есть несколько одиночных серверов PostgreSQL для работы с 1С, так что я решил проверить работу сразу с ними. В сети нет готовых инструкций по настройке temBoard, а с учётом того, что сборка PostgreSQL для 1С не совсем типовая, пришлось немного повозиться с настройкой. В итоге всё получилось.
С помощью temBoard можно:
◽подключить множество экземпляров СУБД в единую веб панель;
◽смотреть основные метрики мониторинга серверов;
◽управлять активными сеансами пользователей;
◽запускать операции vacuum, reindex, analyze;
◽отслеживать запросы к СУБД;
◽выполнять некоторые настройки СУБД.
С учётом перечисленных возможностей понятно, что у панели есть почти полный доступ к СУБД, так что использовать её надо аккуратно. Это может быть точкой отказа или утечки данных.
Для установки temBoard необходимо установить веб интерфейс и настроить хранение данных в одной из баз данных PostgreSQL, существующей или отдельной. На хосты с СУБД ставится небольшой агент. Для temBoard есть репозитории разработчиков, так что установка не представляет особых сложностей, но есть нюансы.
Я развернул всё на Debian 11. В моём случае наблюдаемый сервер PostgreSQL будет стоять на этом же хосте. Нужно убедиться, что все хосты имеют FQDN имена. Без них ничего не заработает, так как будут выпущены сертификаты. А скрипты генерации сертификатов ожидают FQDN имена, без них будут ошибки.
Для установки использовал официальную инструкцию. Ставим утилиты, которые пригодятся:
Подключаем репозиторий и устанавливаем temBoard:
Теперь нужно запустить скрипт настройки. Он берёт все значения PostgreSQL по умолчанию. Если используете сборку от Postgrespro для 1С, то сокет для подключения она открывает в
Скрипт генерирует сертификаты, конфиги, службу systemd, создаёт себе базу данных в СУБД и что-то ещё, соответственно, в
Если всё прошло без ошибок, то можно открывать веб интерфейс https://temboard.local:8888, учётка - admin / admin. Там будет пусто, так как нет ни одного подключенного хоста.
Теперь нужно установить агента. Если это одна и та же машина, то пакет ставится из того же репозитория. Если хост другой, то подключите туда репозиторий:
Запускаем скрипт для конфигурирования агента:
Тут он у меня постоянно вываливался с неинформативной ошибкой. Анализируя скрипт понял, что идёт проверка доступности ключа
Если доступа нет, настройте. После этого всё получится. Далее забираем ключ с сервера, запускаем агента и регистрируемся на сервере:
Идём в веб интерфейс и наблюдаем там свой хост.
⇨ Сайт / Исходники
#монитроинг #postgresql
У меня есть несколько одиночных серверов PostgreSQL для работы с 1С, так что я решил проверить работу сразу с ними. В сети нет готовых инструкций по настройке temBoard, а с учётом того, что сборка PostgreSQL для 1С не совсем типовая, пришлось немного повозиться с настройкой. В итоге всё получилось.
С помощью temBoard можно:
◽подключить множество экземпляров СУБД в единую веб панель;
◽смотреть основные метрики мониторинга серверов;
◽управлять активными сеансами пользователей;
◽запускать операции vacuum, reindex, analyze;
◽отслеживать запросы к СУБД;
◽выполнять некоторые настройки СУБД.
С учётом перечисленных возможностей понятно, что у панели есть почти полный доступ к СУБД, так что использовать её надо аккуратно. Это может быть точкой отказа или утечки данных.
Для установки temBoard необходимо установить веб интерфейс и настроить хранение данных в одной из баз данных PostgreSQL, существующей или отдельной. На хосты с СУБД ставится небольшой агент. Для temBoard есть репозитории разработчиков, так что установка не представляет особых сложностей, но есть нюансы.
Я развернул всё на Debian 11. В моём случае наблюдаемый сервер PostgreSQL будет стоять на этом же хосте. Нужно убедиться, что все хосты имеют FQDN имена. Без них ничего не заработает, так как будут выпущены сертификаты. А скрипты генерации сертификатов ожидают FQDN имена, без них будут ошибки.
Для установки использовал официальную инструкцию. Ставим утилиты, которые пригодятся:
# apt install gnupg curl sudoПодключаем репозиторий и устанавливаем temBoard:
# echo deb http://apt.dalibo.org/labs $(lsb_release -cs)-dalibo main \> /etc/apt/sources.list.d/dalibo-labs.list# curl https://apt.dalibo.org/labs/debian-dalibo.asc | apt-key add -# apt update# apt install temboardТеперь нужно запустить скрипт настройки. Он берёт все значения PostgreSQL по умолчанию. Если используете сборку от Postgrespro для 1С, то сокет для подключения она открывает в
/tmp, а не в /var/run. Нужно это передать скрипту. Сразу покажу и переменную для tcp порта postgresql, если у вас используется нестандартный.# PGPORT=5432 PGHOST=/tmp /usr/share/temboard/auto_configure.shСкрипт генерирует сертификаты, конфиги, службу systemd, создаёт себе базу данных в СУБД и что-то ещё, соответственно, в
pg_hba.conf нужно настроить доступ для юзера postgres. После того, как скрипт отработает, запускаем службу:# systemctl enable --now temboardЕсли всё прошло без ошибок, то можно открывать веб интерфейс https://temboard.local:8888, учётка - admin / admin. Там будет пусто, так как нет ни одного подключенного хоста.
Теперь нужно установить агента. Если это одна и та же машина, то пакет ставится из того же репозитория. Если хост другой, то подключите туда репозиторий:
# apt install temboard-agentЗапускаем скрипт для конфигурирования агента:
# /usr/share/temboard-agent/auto_configure.sh https://temboard.local:8888Тут он у меня постоянно вываливался с неинформативной ошибкой. Анализируя скрипт понял, что идёт проверка доступности ключа
/etc/ssl/private/ssl-cert-snakeoil.key пользователем postgresql. Проверить так:# sudo -u postgres cat /etc/ssl/private/ssl-cert-snakeoil.key Если доступа нет, настройте. После этого всё получится. Далее забираем ключ с сервера, запускаем агента и регистрируемся на сервере:
# sudo -u postgres temboard-agent -c \/etc/temboard-agent/15/pg5432/temboard-agent.conf fetch-key# systemctl enable --now temboard-agent@15-pg5432# sudo -u postgres temboard-agent -c \/etc/temboard-agent/15/pg5432/temboard-agent.conf register --groups defaultИдём в веб интерфейс и наблюдаем там свой хост.
⇨ Сайт / Исходники
#монитроинг #postgresql
{kind=link}
👍70👎2
Для бэкапа баз PostgreSQL существует много различных подходов и решений. Я вам хочу предложить ещё одно, отметив его особенности и преимущества. Да и в целом это одна из самых известных программ для этих целей. А в конце приведу список того, чем ещё можно бэкапить PostgreSQL.
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
Дальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
Сейчас речь пойдёт об open source продукте pgBackRest. Сразу перечислю основные возможности:
◽умеет бэкапить как локально, так и удалённо, подключаясь по SSH
◽умеет параллелить свою работу и сжимать на ходу с помощью lz4 и zstd, что обеспечивает максимальное быстродействие
◽умеет полные, инкрементные, разностные бэкапы
◽поддерживает локальное и удалённое (в том числе S3) размещение архивов с разными политиками хранения
◽умеет проверять консистентность данных
◽может докачивать бэкапы на том месте, где остановился, а не начинать заново при разрывах связи
Несмотря на то, что продукт довольно старый (написан на C и Perl), он активно поддерживается и обновляется. Плохо только то, что в репозитории нет ни бинарников, ни пакетов. Только исходники, которые предлагается собрать самостоятельно. В целом, это не проблема, так как в Debian и Ubuntu есть уже собранные пакеты в репозиториях, но не самых свежих версий. Свежие придётся самим собирать.
# apt install pgbackrestДальше настройка стандартная для подобных приложений. Рисуете конфиг, где описываете хранилища, указываете объекты для бэкапа, параметры бэкапа и куда складывать логи. Они информативные, можно анализировать при желании.
Подробное описание работы pgBackRest, а так же подходы к созданию резервных копий PostgreSQL и их проверке подробно описаны в ▶️ выступлении Дэвид Стили на PGConf.Online.
❓Чем ещё можно бэкапить PostgreSQL?
🔹pg_dump - встроенная утилита для создания логической копии базы. Подходит только для небольших малонагруженных баз
🔹pg_basebackup - встроенная утилита для создания бинарных бэкапов на уровне файлов всего сервера или кластера. Нельзя делать выборочный бэкап отдельных баз или таблиц.
🔹Barman - наиболее известный продукт для бэкапа PostgreSQL. Тут я могу ошибаться, но по моим представлениям это большой продукт для крупных компаний и нагруженных серверов. Barman размещают на отдельное железо и бэкапаят весь парк своих кластеров. Его часто сравнивают с pgBackrest и выбирают, что лучше.
🔹WAL-G - более молодой продукт по сравнению с Barman и pgBackrest. Написан на GO и поддерживает в том числе MySQL/MariaDB и MS SQL Server. Возможности сопоставимы с первыми двумя, но есть и свои особенности.
Если перед вами стоит задача по бэкапу PostgreSQL, а вы не знаете с чего начать, так как для вас это новая тема, посмотрите выступление с HighLoad++:
▶️ Инструменты создания бэкапов PostgreSQL / Андрей Сальников (Data Egret)
#backup #postgresql
{kind=link}
👍74👎1
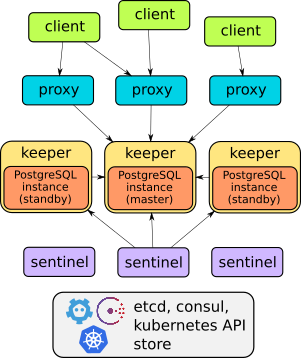
Stolon и Patroni — два наиболее известных решения для построения кластера PostgreSQL типа Leader-Followers. Про Patroni я уже как-то рассказывал. Для него есть готовый плейбук ansible — postgresql_cluster, с помощью которого можно легко и быстро развернуть нужную конфигурацию кластера.
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
{kind=link}
👍44👎2
Попереживал тут на днях из-за своей неаккуратности. Настроил сервер 1С примерно так же, как описано у меня в статье:
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
3️⃣ Проверяю, создалась ли база:
4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
⇨ Установка и настройка 1С на Debian с PostgreSQL
Сразу настроил бэкапы в виде обычных дампов sql, сделанных с помощью pg_dump. Положил их в два разных места. Сделал проверки. Всё, как описано в статье. Потом случилось то, что 1С убрали возможность запускать сервер на Linux без серверной лицензии. И вся моя схема проверки бэкапов сломалась, когда я восстанавливал дампы на копии сервера и там делал выгрузку в dt. И считал, что всё в порядке, если дамп восстановился, dt выгрузился и нигде не было ошибок. На основном сервере я не хочу делать такие проверочные восстановления.
Я всё откладывал проработку этого вопроса, так как надо разобраться с получением лицензии для разработчиков 1С, изучить нюансы, проработать новую схему и т.д. Всё никак время не находил.
И тут меня попросили восстановить одну базу, откатившись на несколько дней назад. Я понимаю, что дампы я не проверяю и на самом деле хз, реально ли они рабочие. По идее да, так как дампы делались и ошибок не было. Но если ты не восстанавливался из них, то не факт, что всё пройдёт успешно, тем более с 1С, где есть свои нюансы.
В итоге всё прошло успешно. Восстановиться из бэкапов в виде дампов довольно просто. За это их люблю и если размер позволяет, то использую именно их. Последовательность такая:
1️⃣ Находим и распаковываем нужный дамп.
2️⃣ Создаём новую базу в PostgreSQL. Я всегда в новую восстанавливаю, а не в текущую. Если всё ОК и старая база не нужна, то просто удаляю её, а новую делаю основной.
# sudo -u postgres /usr/bin/createdb -U postgres -T template0 base1C-restored3️⃣ Проверяю, создалась ли база:
# sudo -u postgres /usr/bin/psql -U postgres -l4️⃣ Восстанавливаю базу из дампа в только что созданную. ❗️Не ошибитесь с именем базы.
# sudo -u postgres /usr/bin/psql -U postgres base1C-restored < /tmp/backup.sql5️⃣ Иду в консоль 1С и добавляю восстановленную базу base1C-restored.
Если сначала создать базу через консоль 1С и восстановить в неё бэкап, будут какие-то проблемы. Не помню точно, какие, но у меня так не работало. Сначала создаём и восстанавливаем базу, потом подключаем её к 1С.
Мораль какая. Бэкапы надо восстанавливать и проверять, чтобы лишний раз не дёргаться. Я без этого немного переживаю. Поэтому люблю бэкапы в виде сырых файлов или дампов. По ним сразу видно, что всё в порядке, всё на месте. А если у тебя бинарные бэкапы, сделанные каким-то софтом, то проверяешь ты их тоже каким-то софтом и надеешься, что он нормально всё проверил. Либо делать полное восстановление, на что не всегда есть ресурсы и возможности, если речь идёт о больших виртуалках.
#1С #postgresql
Server Admin
Установка 1С на Linux (Debian) + PostgreSQL
Пошаговое руководство по настройке Сервера 1С на Debian + PostgreSQL с примерами эксплуатации: мониторинг, бэкапы и т.д.
👍131👎2
Я уже делал серию заметок про CIS (Center for Internet Security). Это некоммерческая организация, которая разрабатывает собственные рекомендации по обеспечению безопасности различных систем. Я проработал рекомендации для:
- Nginx
- MySQL 5.7
- Apache 2.4
- Debian 11
- Docker
- Ubuntu 22.04 LTS
Основная проблема этих рекомендаций - они составлены в огромные pdf книги, иногда до 800 страниц и покрывают очень широкий вектор атак. Выбрать из них то, что вам нужно, довольно хлопотно. Я выделяю основные рекомендации, которые стоит учесть при базовом использовании стреднестатиcтической системы. В этот раз разобрал рекомендации для PostgreSQL 16.
🔹Убедитесь, что настроено логирование ошибок. Задаётся параметром
🔹Для повышения возможностей аудита имеет смысл включить логирование подключений и отключений клиентов. Параметры
🔹Если вам необходимо отслеживать активность в базе данных, то имеет смысл настроить параметр
🔹Для расширенного аудита используйте отдельный модуль pgAudit. Обычно ставится в виде отдельного пакета. Для расширенного контроля за действиями superuser используйте расширение set_user.
🔹Если есть необходимость работать с postgresql в консоли, установите и настройте утилиту sudo, чтобы можно было контролировать и отслеживать действия различных пользователей.
🔹Рекомендованным методом аутентификации соединения является scram-sha-256, а не популярный md5, у которого есть уязвимость (it is vulnerable to packet replay attacks). Настраивается в pg_hba.conf.
🔹Настройте работу СУБД на том сетевом интерфейсе, на котором она будет принимать соединения. Параметр
🔹Если есть необходимость шифровать TCP трафик от и к серверу, то не забудьте настроить TLS. За это отвечает параметр
🔹Для репликации создавайте отдельных пользователей. Не используйте существующих или superuser.
🔹Не забудьте проверить и настроить создание бэкапов. Используйте pg_basebackup для создания полных бэкапов и копии WAL журналов для бэкапа транзакций.
Остальные рекомендации были в основном связаны с ролями, правами доступа и т.д. Это уже особенности конкретной эксплуатации. Не стал о них писать.
Сам файл с рекомендациями живёт тут. Для доступа нужна регистрация.
#cis #postgresql
- Nginx
- MySQL 5.7
- Apache 2.4
- Debian 11
- Docker
- Ubuntu 22.04 LTS
Основная проблема этих рекомендаций - они составлены в огромные pdf книги, иногда до 800 страниц и покрывают очень широкий вектор атак. Выбрать из них то, что вам нужно, довольно хлопотно. Я выделяю основные рекомендации, которые стоит учесть при базовом использовании стреднестатиcтической системы. В этот раз разобрал рекомендации для PostgreSQL 16.
🔹Убедитесь, что настроено логирование ошибок. Задаётся параметром
log_destination. По умолчанию пишет в системный поток stderr. Считается, что это ненадёжный способ, поэтому рекомендуется отдельно настроить logging_collector и отправлять логи через него. По умолчанию он отключен. Если настроено сохранение логов в файлы, то не забыть закрыть доступ к ним и настроить ротацию средствами postgresql (log_truncate_on_rotation, log_rotation_age и т.д.)🔹Для повышения возможностей аудита имеет смысл включить логирование подключений и отключений клиентов. Параметры
log_connections и log_disconnections. По умолчанию отключено. 🔹Если вам необходимо отслеживать активность в базе данных, то имеет смысл настроить параметр
log_statement. Значение ddl позволит собирать информацию о действиях CREATE, ALTER, DROP. 🔹Для расширенного аудита используйте отдельный модуль pgAudit. Обычно ставится в виде отдельного пакета. Для расширенного контроля за действиями superuser используйте расширение set_user.
🔹Если есть необходимость работать с postgresql в консоли, установите и настройте утилиту sudo, чтобы можно было контролировать и отслеживать действия различных пользователей.
🔹Рекомендованным методом аутентификации соединения является scram-sha-256, а не популярный md5, у которого есть уязвимость (it is vulnerable to packet replay attacks). Настраивается в pg_hba.conf.
🔹Настройте работу СУБД на том сетевом интерфейсе, на котором она будет принимать соединения. Параметр
listen_addresses, по умолчанию указан только localhost. Если используется внешний сетевой интерфейс, не забудьте ограничить к нему доступ средствами firewall.🔹Если есть необходимость шифровать TCP трафик от и к серверу, то не забудьте настроить TLS. За это отвечает параметр
hostssl в pg_hba.conf и параметры ssl, ssl_cert_file, ssl_key_file в postgresql.conf. Поддерживается работа с self-signed сертификатами.🔹Для репликации создавайте отдельных пользователей. Не используйте существующих или superuser.
🔹Не забудьте проверить и настроить создание бэкапов. Используйте pg_basebackup для создания полных бэкапов и копии WAL журналов для бэкапа транзакций.
Остальные рекомендации были в основном связаны с ролями, правами доступа и т.д. Это уже особенности конкретной эксплуатации. Не стал о них писать.
Сам файл с рекомендациями живёт тут. Для доступа нужна регистрация.
#cis #postgresql
{kind=link}
👍90👎3
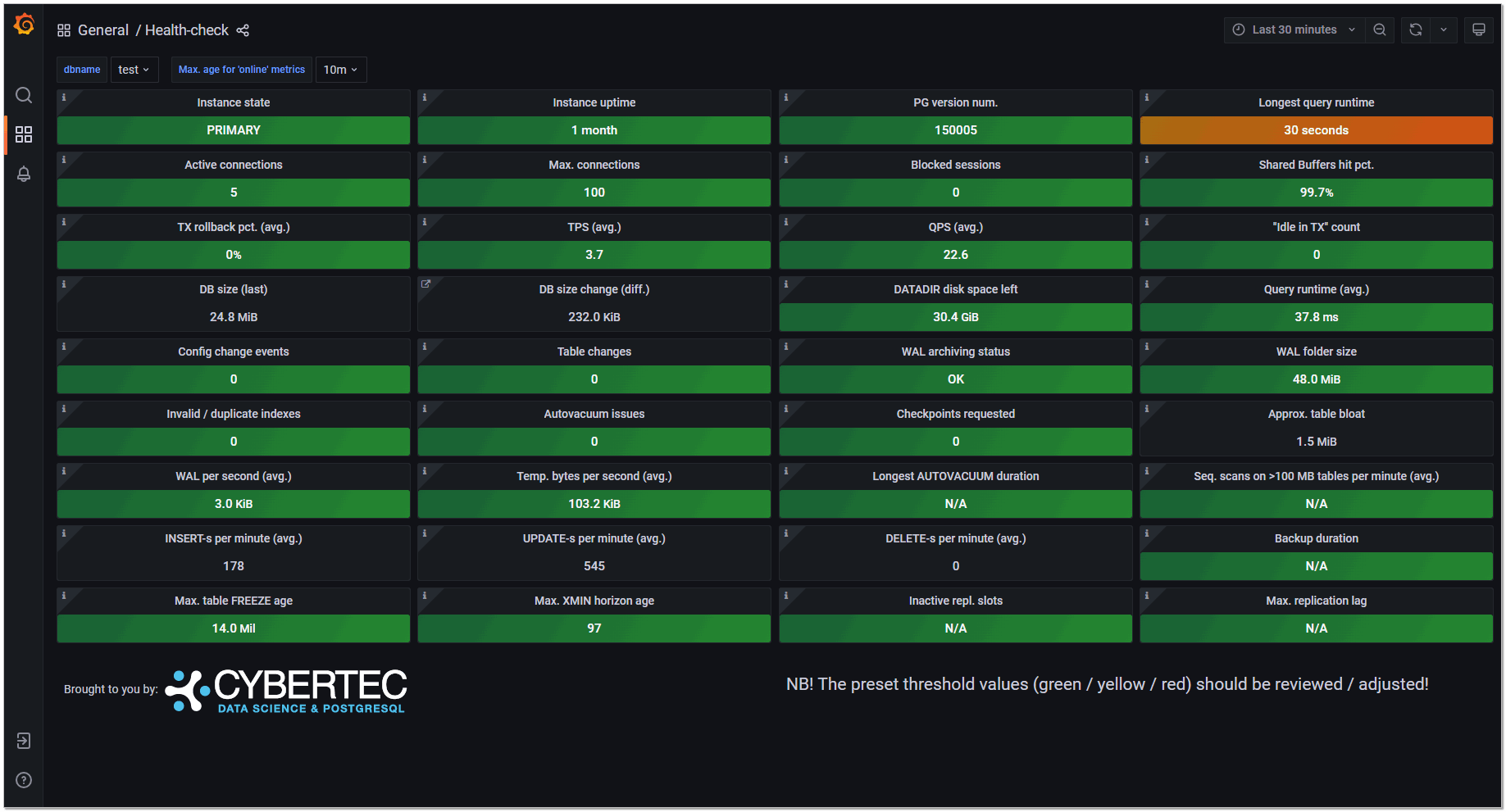
Для мониторинга СУБД PostgreSQL существует много вариантов настройки. Собственно, как и для всего остального. Тема мониторинга очень хорошо развита в IT. Есть из чего выбирать, чему отдать предпочтение.
Одним из наиболее простых и быстрых для внедрения инструментов именно для psql является Pgwatch2. Это известная штука, для которой много инструкций и руководств. Есть обзоры на youtube. Отдельно отмечу, что если вы используете систему мониторинга Zabbix, то искать что-то ещё, большого смысла нет. У неё есть хороший встроенный шаблон, который собирает много различных метрик. В общем случае этого мониторинга будет за глаза.
Если вы не знаете Zabbix, у вас его нет и ставить не планируете, то закрыть вопрос с мониторингом PostgreSQL можно с помощью Pgwatch2. Этот продукт состоит из следующих компонентов:
▪ Хранилище метрик. В его качестве может выступать сама PostgreSQL, в том числе с расширением TimescaleDB. Также метрики можно хранить в InfluxDB. Либо их можно отправить в Prometheus, а он положит куда-то у себя.
▪ Сборщик метрик, написанный на GO.
▪ Веб интерфейс для управления, написанный на Python
▪ Grafana для просмотра дашбордов с метриками.
Всё это есть в готовом виде, упакованное в Docker. Если использовать для хранения метрик PostgreSQL, достаточно создать базу для хранения и пользователя для доступа к метрикам. Далее указать эти данные и запустить контейнеры. Процесс подробно описан в документации.
Посмотреть, как выглядит итоговый мониторинг, можно в публичном DEMO. Там из коробки настроено много дашбордов, не забудьте их посмотреть. Информацию по конкретной базе удобно смотреть в дашборде DB overview.
⇨ Исходники / Документация / Demo / Видеобозор (на русском)
#postgresql #monitoring
Одним из наиболее простых и быстрых для внедрения инструментов именно для psql является Pgwatch2. Это известная штука, для которой много инструкций и руководств. Есть обзоры на youtube. Отдельно отмечу, что если вы используете систему мониторинга Zabbix, то искать что-то ещё, большого смысла нет. У неё есть хороший встроенный шаблон, который собирает много различных метрик. В общем случае этого мониторинга будет за глаза.
Если вы не знаете Zabbix, у вас его нет и ставить не планируете, то закрыть вопрос с мониторингом PostgreSQL можно с помощью Pgwatch2. Этот продукт состоит из следующих компонентов:
▪ Хранилище метрик. В его качестве может выступать сама PostgreSQL, в том числе с расширением TimescaleDB. Также метрики можно хранить в InfluxDB. Либо их можно отправить в Prometheus, а он положит куда-то у себя.
▪ Сборщик метрик, написанный на GO.
▪ Веб интерфейс для управления, написанный на Python
▪ Grafana для просмотра дашбордов с метриками.
Всё это есть в готовом виде, упакованное в Docker. Если использовать для хранения метрик PostgreSQL, достаточно создать базу для хранения и пользователя для доступа к метрикам. Далее указать эти данные и запустить контейнеры. Процесс подробно описан в документации.
Посмотреть, как выглядит итоговый мониторинг, можно в публичном DEMO. Там из коробки настроено много дашбордов, не забудьте их посмотреть. Информацию по конкретной базе удобно смотреть в дашборде DB overview.
⇨ Исходники / Документация / Demo / Видеобозор (на русском)
#postgresql #monitoring
{kind=link}
👍62👎1
🎓 У компании Postgres Professional есть очень качественные бесплатные курсы по СУБД PostgreSQL. Не припоминаю, чтобы у каких-то других коммерческих компаний были бы курсы в таком же формате. Вы можете пройти обучение в авторизованных учебных центрах с помощью преподавателей, либо изучать материалы курса самостоятельно. Они полностью бесплатны:
⇨ https://postgrespro.ru/education/courses
Доступны следующие курсы для администраторов PostgreSQL:
▪ DBA1. Администрирование PostgreSQL. Базовый курс
▪ DBA2. Администрирование PostgreSQL. Настройка и мониторинг
▪ DBA3. Администрирование PostgreSQL. Резервное копирование и репликация
▪ QPT. Оптимизация запросов
▪ PGPRO. Возможности Postgres Pro Enterprise
Каждый курс - это набор подробных текстовых презентаций и видеоуроков к каждой теме. Причём не обязательно курсы проходить последовательно. Можно обращаться к конкретной теме, которая вас интересует в данный момент.
Например, вам надо обновить сервер или кластер серверов на новую ветку. Идём на курс Администрирование PostgreSQL 13. Настройка и мониторинг, смотрим тему 17. Обновление сервера. Для экономии времени достаточно посмотреть презентацию. Там будет и теория по теме, и точные команды в консоли для выполнения тех или иных действий. Если хочется более подробную информацию с комментариями преподавателя, то можно посмотреть видео.
То же самое про бэкап. Хотите разобраться - открываете курс Администрирование PostgreSQL 13. Резервное копирование и репликация, тема 2. Базовая резервная копия. Там вся теория и примеры по холодным, горячим копиям, плюсы и минусы разных подходов, инструменты для бэкапа, как их проверять. Не пересказы каких-то блогеров или спикеров конференций, а первичка от разработчиков.
Сейчас почти все сервера 1С, да и многое другое, использует PostgreSQL, так что тема актуальна. Я и Zabbix Server все уже года два поднимаю с PostgreSQL, а не MySQL, как раньше.
#обучение #postgresql
⇨ https://postgrespro.ru/education/courses
Доступны следующие курсы для администраторов PostgreSQL:
▪ DBA1. Администрирование PostgreSQL. Базовый курс
▪ DBA2. Администрирование PostgreSQL. Настройка и мониторинг
▪ DBA3. Администрирование PostgreSQL. Резервное копирование и репликация
▪ QPT. Оптимизация запросов
▪ PGPRO. Возможности Postgres Pro Enterprise
Каждый курс - это набор подробных текстовых презентаций и видеоуроков к каждой теме. Причём не обязательно курсы проходить последовательно. Можно обращаться к конкретной теме, которая вас интересует в данный момент.
Например, вам надо обновить сервер или кластер серверов на новую ветку. Идём на курс Администрирование PostgreSQL 13. Настройка и мониторинг, смотрим тему 17. Обновление сервера. Для экономии времени достаточно посмотреть презентацию. Там будет и теория по теме, и точные команды в консоли для выполнения тех или иных действий. Если хочется более подробную информацию с комментариями преподавателя, то можно посмотреть видео.
То же самое про бэкап. Хотите разобраться - открываете курс Администрирование PostgreSQL 13. Резервное копирование и репликация, тема 2. Базовая резервная копия. Там вся теория и примеры по холодным, горячим копиям, плюсы и минусы разных подходов, инструменты для бэкапа, как их проверять. Не пересказы каких-то блогеров или спикеров конференций, а первичка от разработчиков.
Сейчас почти все сервера 1С, да и многое другое, использует PostgreSQL, так что тема актуальна. Я и Zabbix Server все уже года два поднимаю с PostgreSQL, а не MySQL, как раньше.
#обучение #postgresql
postgrespro.ru
Учебные курсы
Postgres Professional - российская компания, разработчик систем управления базами данных
👍213👎2
Запуская СУБД PostgreSQL в работу, необходимо в обязательном порядке выполнить хотя бы базовую начальную настройку, которая будет соответствовать количеству ядер и оперативной памяти сервера, а также профилю нагрузки. Это нетривиальная задача, так как там очень много нюансов, а тюнингом баз данных обычно занимаются отдельные специалисты - DBA (Database administrator).
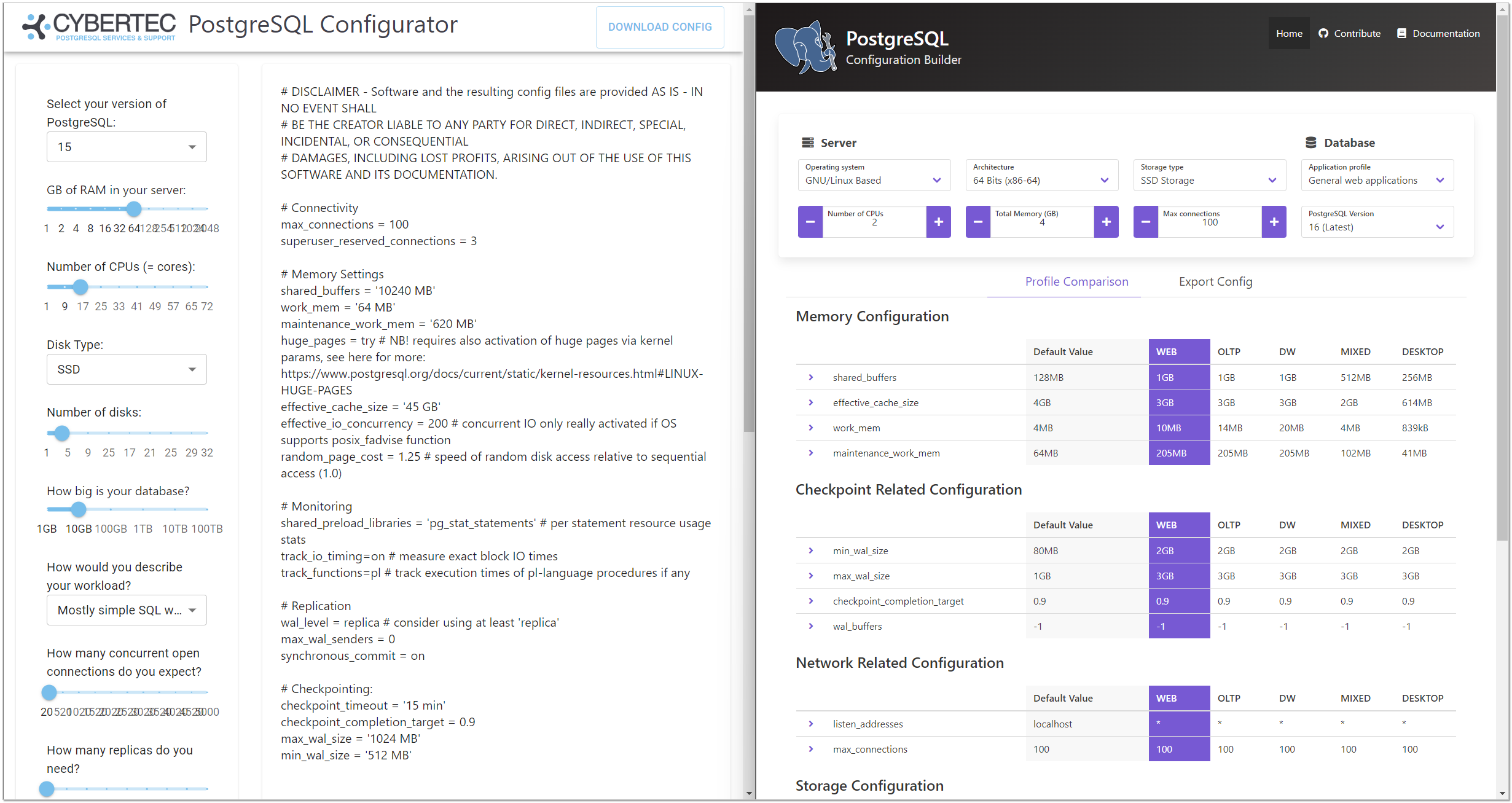
Если у вас такого специалиста нет, а сами вы не особо разбираетесь в этой теме, то можно воспользоваться готовым конфигуратором, который в целом выдаст адекватную настройку для типового использования. Я знаю два таких конфигуратора:
⇨ https://pgconfigurator.cybertec.at
⇨ https://www.pgconfig.org
Первый предлагает немного больше настроек, но во втором есть подробное описание каждой. В целом, у них плюс-минус похожие конфигурации получаются. Можно использовать оба сайта. Если не разбираетесь в настройках, лучше воспользоваться ими.
Отдельно отмечу, что если вы устанавливаете сборку СУБД PostgreSQL для 1C от компании PostgresPro, то там базовые оптимизации уже выполнены. Вы можете увидеть их в самом конце файла
Например, для 1С в сборках PostgresPro неизменно установлен параметр:
Я это проверил и на старом сервере 13-й версии и на более свежем 15-й. В общем случае в 0 его ставить не рекомендуется. Он и дефолтный не 0, и все оптимизаторы его не ставят в 0. Но для 1С рекомендуется именно 0. Я не знаю, в чём тут нюанс, а параметр это важный. Так что для 1С надо быть аккуратным при настройке PostgreSQL. Я из-за этого всегда использую сборки от PostgresPro. Там умные люди уже подумали над оптимизацией.
#postgresql
Если у вас такого специалиста нет, а сами вы не особо разбираетесь в этой теме, то можно воспользоваться готовым конфигуратором, который в целом выдаст адекватную настройку для типового использования. Я знаю два таких конфигуратора:
⇨ https://pgconfigurator.cybertec.at
⇨ https://www.pgconfig.org
Первый предлагает немного больше настроек, но во втором есть подробное описание каждой. В целом, у них плюс-минус похожие конфигурации получаются. Можно использовать оба сайта. Если не разбираетесь в настройках, лучше воспользоваться ими.
Отдельно отмечу, что если вы устанавливаете сборку СУБД PostgreSQL для 1C от компании PostgresPro, то там базовые оптимизации уже выполнены. Вы можете увидеть их в самом конце файла
postgresql.conf. Там более 30-ти изменённых параметров. В этом случае использовать какие-то сторонние конфигураторы не стоит, так как настройки могут отличаться принципиально. Например, для 1С в сборках PostgresPro неизменно установлен параметр:
max_parallel_workers_per_gather = 0Я это проверил и на старом сервере 13-й версии и на более свежем 15-й. В общем случае в 0 его ставить не рекомендуется. Он и дефолтный не 0, и все оптимизаторы его не ставят в 0. Но для 1С рекомендуется именно 0. Я не знаю, в чём тут нюанс, а параметр это важный. Так что для 1С надо быть аккуратным при настройке PostgreSQL. Я из-за этого всегда использую сборки от PostgresPro. Там умные люди уже подумали над оптимизацией.
#postgresql
{kind=link}
👍140
Для тестирования производительности PostgreSQL есть относительно простая утилита pgbench, которая входит в состав установки PostgreSQL. Ставить отдельно не придётся. Даже если вы несильно разбираетесь в тюнинге СУБД и не собираетесь им заниматься, pgbench хотя бы базово позволит сравнить разные конфигурации VM, разных хостеров, разное железо. Например, сравнить, на какой файловой системе или на каком дисковом хранилище будут лучше показатели быстродействия. Просто создайте две разные виртуалки и сравните.
Тест выполняет на существующей базе данных. В ней создаются служебные таблицы и наполняются данными. Покажу, как это выглядит на практике. Ставим postgresql:
Проверяем, что работает:
Создаём базу данных:
Наполняем тестовую базу данными, увеличив стандартный набор в 10 раз:
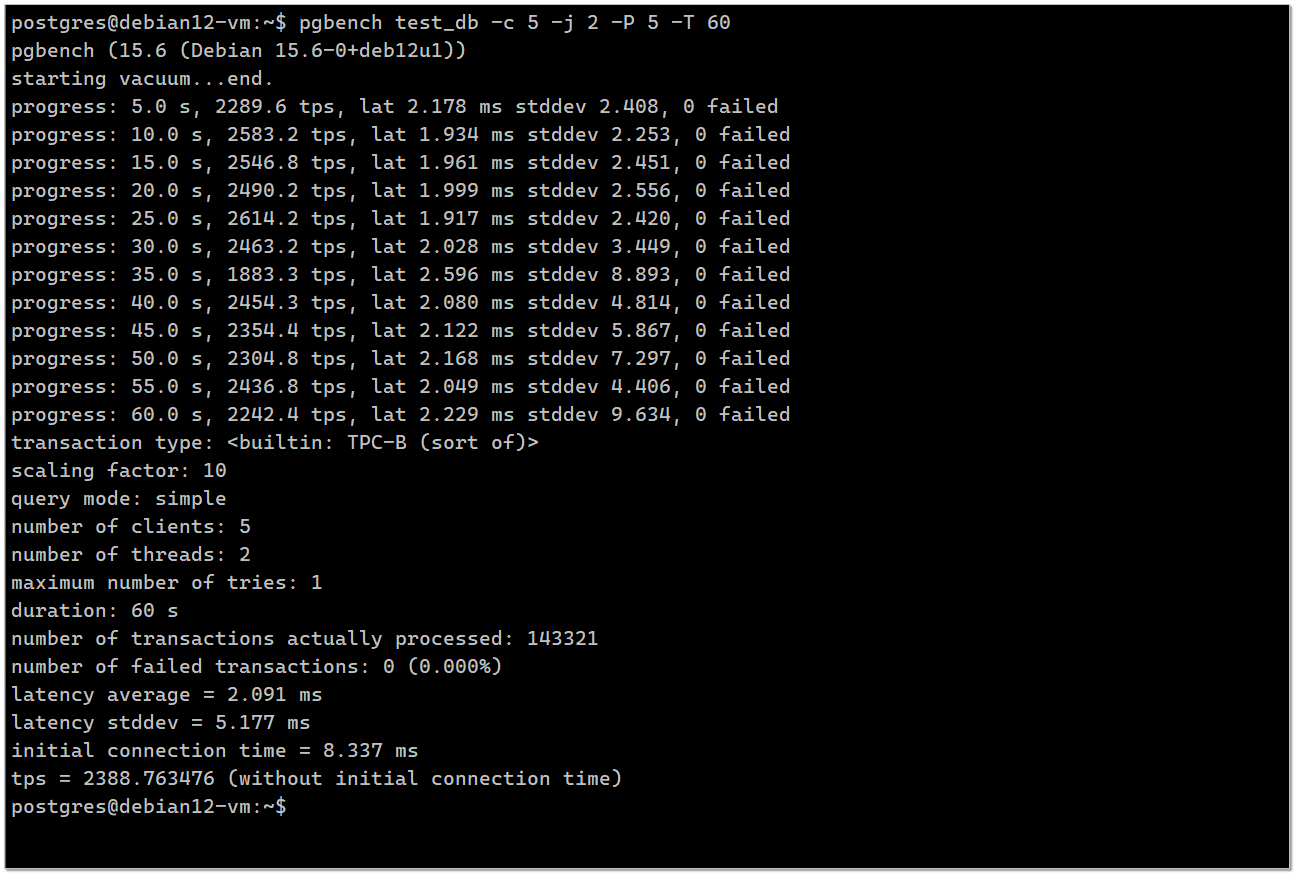
Запускаем тест в 5 клиентов, в 2 рабочих потока, на 60 секунд с отсечкой результата каждые 5 секунд, чтобы в консоли интересно наблюдать было. Если будете в файл выводить результаты, то это делать не надо.
СУБД обработала 219950 транзакций со средней скоростью 3665.930847 транзакций в секунду. Эти данные и стоит сравнивать.
По умолчанию pgbench запускает смешанный TPC-B (Transaction Processing Performance Council) тест, который состоит из пяти команд
Из любопытства перекинул тестовую виртуалку с обычного одиночного SSD на RAID10 из 4-х HDD. Настройки в Proxmox те же, кэширование гипервизора отключено (Default (No cache)). Прогнал этот же тест.
Получилось на ~40% медленнее при идентичных настройках.
#postgresql
Тест выполняет на существующей базе данных. В ней создаются служебные таблицы и наполняются данными. Покажу, как это выглядит на практике. Ставим postgresql:
# apt install postgresqlПроверяем, что работает:
# systemctl status postgresqlСоздаём базу данных:
# su - postgres$ psql$ create database test_db;$ \qНаполняем тестовую базу данными, увеличив стандартный набор в 10 раз:
$ pgbench -i test_db -s 10Запускаем тест в 5 клиентов, в 2 рабочих потока, на 60 секунд с отсечкой результата каждые 5 секунд, чтобы в консоли интересно наблюдать было. Если будете в файл выводить результаты, то это делать не надо.
$ pgbench test_db -c 5 -j 2 -P 5 -T 60transaction type: <builtin: TPC-B (sort of)>scaling factor: 10query mode: simplenumber of clients: 5number of threads: 2maximum number of tries: 1 duration: 60 snumber of transactions actually processed: 219950number of failed transactions: 0 (0.000%)latency average = 1.362 mslatency stddev = 0.661 msinitial connection time = 8.368 mstps = 3665.930847 (without initial connection time)СУБД обработала 219950 транзакций со средней скоростью 3665.930847 транзакций в секунду. Эти данные и стоит сравнивать.
По умолчанию pgbench запускает смешанный TPC-B (Transaction Processing Performance Council) тест, который состоит из пяти команд
SELECT, UPDATE и INSERT в одной транзакции. Сценарий можно менять, создавая собственные скрипты для тестирования. Все возможности pgbench подробно описаны на русском языке в документации от postgrespro.Из любопытства перекинул тестовую виртуалку с обычного одиночного SSD на RAID10 из 4-х HDD. Настройки в Proxmox те же, кэширование гипервизора отключено (Default (No cache)). Прогнал этот же тест.
tps = 2262.544160Получилось на ~40% медленнее при идентичных настройках.
#postgresql
{kind=link}
👍110👎3
🎓 У хостера Selectel есть небольшая "академия", где в открытом доступе есть набор курсов. Они неплохого качества. Где-то по верхам в основном теория, а где-то полезные практические вещи. Я бы обратил внимание на два курса, которые показались наиболее полезными:
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
{kind=link}
👍123👎7
При обновлении кода сайта или веб сервиса легко сделать проверку изменений или выполнить откат в случае каких-то проблем. Задача сильно усложняется, когда обновление затрагивает изменение в структуре базы данных. Если вы накатили изменение, которое затрагивает базу данных, не получится просто откатить всё назад на уровне кода. Нужно откатывать и состояние базы. Для таких ситуация придумали миграции базы данных.
Сразу покажу на примере, как это работает. Существует популярная open source утилита для этих целей - migrate. Она поддерживает все наиболее распространённые СУБД. Миграции можно выполнять с помощью готовой библиотеки на Go, либо в консоли через CLI. Я буду использовать CLI, СУБД PostgreSQL и ОС Debian 12.
Для Migrate собран deb пакет, хотя по своей сути это одиночный бинарник. Можно скачать только его. Для порядка ставим из пакета, который берём в репозитории:
Для удобства добавим строку на подключение к локальной базе данных в переменную:
Я подключаюсь без ssl к базе данных test_migrations под учёткой postgres с паролем pass123. С рабочей базой так делать не надо, чтобы пароль не улетел в history.
Принцип работы migrate в том, что создаются 2 файла с sql командами. Первый файл выполняется, когда мы применяем обновление, а второй - когда мы откатываем. В своём примере я добавлю таблицу test01 с простой структурой, а потом удалю её в случае отката.
В директории были созданы 2 файла. В первый файл с up в имени добавим sql код создания таблицы test01:
А во второй с down - удаление:
Проверим, как это работает:
Смотрим, появилась ли таблица:
Вы должны увидеть структуру таблицы test01. Теперь откатим наше изменение:
Проверяем:
Таблицы нет. Принцип тут простой - пишем SQL код, который исполняем. На деле, конечно, изменения бывают сложные, особенно когда не добавляются или удаляются таблицы, а меняется структура существующих таблиц с данными. Инструменты типа migrate позволяют описать все изменения и проработать процесс обновления/отката в тестовых средах. В простых случаях можно обойтись и своими bash скриптами, но migrate упрощает эту задачу, так как, во-первых поддерживает множество СУБД. Во-вторых, автоматически нумерует миграции и исполняет последовательно. В-третьих, может, к примеру, забирать миграции напрямую из git репозитория.
Для каждой СУБД в репозитории Migrate есть примеры настройки миграций.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
⇨ Исходники
#postgresql #mysql
Сразу покажу на примере, как это работает. Существует популярная open source утилита для этих целей - migrate. Она поддерживает все наиболее распространённые СУБД. Миграции можно выполнять с помощью готовой библиотеки на Go, либо в консоли через CLI. Я буду использовать CLI, СУБД PostgreSQL и ОС Debian 12.
Для Migrate собран deb пакет, хотя по своей сути это одиночный бинарник. Можно скачать только его. Для порядка ставим из пакета, который берём в репозитории:
# wget https://github.com/golang-migrate/migrate/releases/download/v4.18.1/migrate.linux-amd64.deb# dpkg -i migrate.linux-amd64.debДля удобства добавим строку на подключение к локальной базе данных в переменную:
# export POSTGRESQL_URL='postgres://postgres:pass123@localhost:5432/test_migrations?sslmode=disable'Я подключаюсь без ssl к базе данных test_migrations под учёткой postgres с паролем pass123. С рабочей базой так делать не надо, чтобы пароль не улетел в history.
Принцип работы migrate в том, что создаются 2 файла с sql командами. Первый файл выполняется, когда мы применяем обновление, а второй - когда мы откатываем. В своём примере я добавлю таблицу test01 с простой структурой, а потом удалю её в случае отката.
# cd ~ && mkdir migrations# migrate create -ext sql -dir migrations -seq create_test01_table~/migrations/000001_create_test01_table.up.sql~/migrations/000001_create_test01_table.down.sqlВ директории были созданы 2 файла. В первый файл с up в имени добавим sql код создания таблицы test01:
CREATE TABLE IF NOT EXISTS test01(
user_id serial PRIMARY KEY,
username VARCHAR (50) UNIQUE NOT NULL,
password VARCHAR (50) NOT NULL,
email VARCHAR (300) UNIQUE NOT NULL
);
А во второй с down - удаление:
DROP TABLE IF EXISTS test01;
Проверим, как это работает:
# migrate -database ${POSTGRESQL_URL} -path migrations up1/u create_test01_table (24.160815ms)Смотрим, появилась ли таблица:
# psql ${POSTGRESQL_URL} -c "\d test01"Вы должны увидеть структуру таблицы test01. Теперь откатим наше изменение:
# migrate -database ${POSTGRESQL_URL} -path migrations downAre you sure you want to apply all down migrations? [y/N]yApplying all down migrations1/d create_test01_table (15.851045ms)Проверяем:
# psql ${POSTGRESQL_URL} -c "\d test01"Did not find any relation named "test01".Таблицы нет. Принцип тут простой - пишем SQL код, который исполняем. На деле, конечно, изменения бывают сложные, особенно когда не добавляются или удаляются таблицы, а меняется структура существующих таблиц с данными. Инструменты типа migrate позволяют описать все изменения и проработать процесс обновления/отката в тестовых средах. В простых случаях можно обойтись и своими bash скриптами, но migrate упрощает эту задачу, так как, во-первых поддерживает множество СУБД. Во-вторых, автоматически нумерует миграции и исполняет последовательно. В-третьих, может, к примеру, забирать миграции напрямую из git репозитория.
Для каждой СУБД в репозитории Migrate есть примеры настройки миграций.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
⇨ Исходники
#postgresql #mysql
2👍96👎4
Для тех, кто много работает с базами данных, есть простой и удобный инструмент для их проектирования – dbdiagram.io. Мы не разработчики, тем не менее, покажу, как этот сервис может быть полезен. У него удобная визуализация структуры базы данных. Намного удобнее, чем, к примеру, в привычном phpmyadmin.
Можно выгрузить обычный дам из СУБД без данных и загрузить его в dbdiagram. Получите наглядную схему базы. При желании, её можно отредактировать, или просто экспортнуть в виде картинки. Покажу на примере MySQL. Выгружаем дамп базы postfix без данных, только структуру:
Передаём к себе на комп полученный дамп. В dbdiagram.io открываем Import ⇨ From MySQL ⇨ Upload .sql ⇨ Submit. Наблюдаем схему базы данных со всеми связями. Причём она сразу отформатирована по таблицам так, что все их наглядно видно.
При желании можно что-то изменить в структуре и выгрузить новый sql файл уже с изменениями. Если выбрать Export ⇨ To PNG, то сразу же получите аккуратную картинку со схемой, без лишних вопросов. Очень быстро и удобно, если нужно куда-то приложить схему базы данных.
⇨ 🌐 Сайт
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mysql #postgresql
Можно выгрузить обычный дам из СУБД без данных и загрузить его в dbdiagram. Получите наглядную схему базы. При желании, её можно отредактировать, или просто экспортнуть в виде картинки. Покажу на примере MySQL. Выгружаем дамп базы postfix без данных, только структуру:
# mysqldump --no-data -u dbuser -p postfix > ~/schema.sqlПередаём к себе на комп полученный дамп. В dbdiagram.io открываем Import ⇨ From MySQL ⇨ Upload .sql ⇨ Submit. Наблюдаем схему базы данных со всеми связями. Причём она сразу отформатирована по таблицам так, что все их наглядно видно.
При желании можно что-то изменить в структуре и выгрузить новый sql файл уже с изменениями. Если выбрать Export ⇨ To PNG, то сразу же получите аккуратную картинку со схемой, без лишних вопросов. Очень быстро и удобно, если нужно куда-то приложить схему базы данных.
⇨ 🌐 Сайт
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#mysql #postgresql
3👍173👎5
Расскажу про парочку инструментов, которые упростят обслуживание сервера PostgreSQL. Начну с наиболее простого - pgBadger. Это анализатор лога, который на его основе генерирует отчёты в формате html. На выходе получаются одиночные html файлы, которые можно просто открыть в браузере. Сделано всё аккуратно и добротно, легко настраивается, отчёты наглядные и информационные.
🔹Чтобы было что анализировать, необходимо включить логирование интересующих вас событий. Для разовой отладки это всё можно включать на ходу, либо постоянно через файл конфигурации
Вся включенная статистика стала писаться в общий лог-файл
Анализируем лог файл:
Тут же в директории, где его запускали, увидите файл out.html. Забирайте его к себе и смотрите. Там будет информация с общей статистикой сервера, информация по запросам и их типам, времени исполнения, подключениям, по пользователям, базам и хостам откуда подключались и много всего остального.
PgBadger удобен тем, что по сути это одиночный скрипт на Perl. Можно включить логирование в конфигурации, применить её через
🔹Второй инструмент - PgHero, он показывает примерно то же самое, только в режиме реального времени и работает в виде веб сервиса. Для него уже надо создавать пользователя, настраивать доступ, отдельную базу. Немного другой подход. Надо будет дёргать сервер с СУБД.
Надо перейти в консоль и создать необходимые сущности:
Разрешаем этому пользователю подключаться. Добавляем в
172.17.0.0/24 - подсеть, из которой будет подключаться PgHero. В данном случае это Docker контейнер, запущенный на этом же хосте. PostgreSQL должен принимать запросы с локального IP адреса, к которому будет доступ из Docker сети. Можно добавить в конфиг
Перезапускаем PotgreSQL:
Запускаем PgHero в Docker контейнере:
Идём на порт севера 8080, где запущен контейнер и смотрим информацию о PostgreSQL. Если у вас не настроено расширение pg_stat_statements, которое использует PgHero для сбора статистики, то установите его. Для этого в конфигурацию
Перезапустите Postgresql и выполните в консоли СУБД:
Теперь можно возвращаться в веб интерфейс и смотреть информацию. По умолчанию, пользователь pghero не будет видеть запросы других пользователей, если ему не дать права superuser. Это можно исправить, выдав ему набор прав и ролей из этой инструкции.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql
🔹Чтобы было что анализировать, необходимо включить логирование интересующих вас событий. Для разовой отладки это всё можно включать на ходу, либо постоянно через файл конфигурации
postgresql.conf и перезапуск сервера. Он обычно хорошо прокомментирован. Вас будут интересовать параметры, начинающие с log_*. Они собраны все в отдельном блоке. Для примера я включил почти всё:log_min_duration_statement = 0log_checkpoints = onlog_connections = onlog_disconnections = onlog_duration = onlog_line_prefix = '%m [%p] %q%u@%d 'log_lock_waits = onlog_temp_files = 0log_timezone = 'Europe/Moscow'Вся включенная статистика стала писаться в общий лог-файл
/var/log/postgresql/postgresql-17-main.log. С ним и будем работать. Устанавливаем pgBadger:# wget https://github.com/darold/pgbadger/archive/refs/tags/v13.1.tar.gz# tar xzvf v13.1.tar.gz# cd pgbadger-*# apt install make# make && make installАнализируем лог файл:
# pgbadger /var/log/postgresql/postgresql-17-main.logТут же в директории, где его запускали, увидите файл out.html. Забирайте его к себе и смотрите. Там будет информация с общей статистикой сервера, информация по запросам и их типам, времени исполнения, подключениям, по пользователям, базам и хостам откуда подключались и много всего остального.
PgBadger удобен тем, что по сути это одиночный скрипт на Perl. Можно включить логирование в конфигурации, применить её через
SELECT pg_reload_conf(); без перезапуска сервера СУБД. Пособирать некоторое время данные, забрать лог и анализировать его. Логирование отключить и снова перечитать конфиг. В итоге всё будет сделано без перезапуска сервера.🔹Второй инструмент - PgHero, он показывает примерно то же самое, только в режиме реального времени и работает в виде веб сервиса. Для него уже надо создавать пользователя, настраивать доступ, отдельную базу. Немного другой подход. Надо будет дёргать сервер с СУБД.
Надо перейти в консоль и создать необходимые сущности:
# su postgres# psql> CREATE USER pghero WITH PASSWORD 'pgheropass';> CREATE DATABASE pgherodb OWNER pghero;> \qРазрешаем этому пользователю подключаться. Добавляем в
pg_hba.conf строку:host pgherodb pghero 172.17.0.0/24 md5172.17.0.0/24 - подсеть, из которой будет подключаться PgHero. В данном случае это Docker контейнер, запущенный на этом же хосте. PostgreSQL должен принимать запросы с локального IP адреса, к которому будет доступ из Docker сети. Можно добавить в конфиг
postgresql.conf параметр:listen_addresses = 'localhost,172.17.0.1'Перезапускаем PotgreSQL:
# systemctl restart postgresqlЗапускаем PgHero в Docker контейнере:
# docker run -ti -e DATABASE_URL=postgres://pghero:pgheropass@172.17.0.1:5432/pgherodb -p 8080:8080 ankane/pgheroИдём на порт севера 8080, где запущен контейнер и смотрим информацию о PostgreSQL. Если у вас не настроено расширение pg_stat_statements, которое использует PgHero для сбора статистики, то установите его. Для этого в конфигурацию
postgresql.conf добавьте параметры:shared_preload_libraries = 'pg_stat_statements'pg_stat_statements.track = allpg_stat_statements.max = 10000track_activity_query_size = 2048Перезапустите Postgresql и выполните в консоли СУБД:
> CREATE EXTENSION IF NOT EXISTS pg_stat_statements;> GRANT pg_read_all_stats TO pghero;Теперь можно возвращаться в веб интерфейс и смотреть информацию. По умолчанию, пользователь pghero не будет видеть запросы других пользователей, если ему не дать права superuser. Это можно исправить, выдав ему набор прав и ролей из этой инструкции.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql
👍107👎4
На прошлой неделе смотрел видео и читал статью про веб панель управления бэкапами PostgreSQL. А если точнее, то только бэкапами в виде дампов. Сразу понятно, что это инструмент для небольших баз данных. Большие базы дампами бэкапить неудобно, так как это, во-первых, может длиться непрогнозируемо долго, во-вторых, это всегда только полные бэкапы, а для больших баз хочется инкрементных копий.
Речь пойдёт о Postgresus. Основные возможности:
◽️Веб интерфейс для управления заданиями и отчётами
◽️Расписание бэкапов
◽️Сжатие, автоочистка старых бэкапов
◽️Хранение локально или в S3, Google Drive
◽️Уведомления по Email, Telegram
◽️Запускается в Docker Compose
По сути это замена самописным bash скриптам в кроне. Именно их я и использую для таких задач 🤖 Решил упростить себе задачу. Забегая вперёд, скажу, что эта панель реально заменяет эти скрипты, не более.
Postgresus состоит из двух Docker контейнеров: непосредственно сама панель и локальный экземпляр postgresql сервера для хранения собственных настроек. Запустить можно вручную из предложенного в репозитории файла
Скрипт ставит докер и стартует с этим же docker-compose.yml. Я вручную запустил. После запуска можно сразу идти в веб интерфейс на порт сервера 4005 и там всё настраивать. Не рекомендую запускать подобные вещи непосредственно на сервере с СУБД. Я сделал отдельную небольшую виртуалку и открыл для неё доступ к базам.
Дальнейшее управление осуществляется через веб интерфейс. Там всё максимально просто и наглядно:
1️⃣ Настраиваем хранилище для бэкапов. Я использовал локальную директорию. После тестов примонтирую туда отдельно большой диск.
2️⃣ Добавляем приёмник для уведомлений. Telegram сразу заработал, нужно указать токен своего бота и ID чата. С почтой не получилось, так как отправка по умолчанию настраивается по TLS, а у меня там локальный сервер стоял без него. Перенастраивать не захотелось. Жаль, что автор не оставил такой возможности.
3️⃣ Добавляем подключение к базе данных и настраиваем параметры её бэкапа.
Бэкап выполняется не особо быстро. Скриптами локально я базу на 5ГБ бэкаплю секунд 30. Из соседней виртуалки с помощью Postgresus бэкапится 12 минут. В целом мне некритично, так как для этого сервера бэкапы выполняются раз в сутки по ночам. Времени достаточно, хотя с такой скоростью это растянется часа на полтора.
Архивы хранятся локально в виде дампов со случайными именами вида
Восстановление возможно тут же через веб интерфейс, причём на любой сервер, а не только исходный. Это удобно для ручного тестирования бэкапов. Можно создать тестовый сервер и там периодически проверять дампы или выгружать их для каких-то других задач, не нагружая основной сервер.
В общем и целом панель нормальная. Для небольших серверов будет удобным решением в качестве замены самописных скриптов. Плюс, тут дополнительно работает мониторинг доступности баз данных и уведомления и для бэкапов, и для этого мониторинга. Сделано всё аккуратно и красиво. Посмотрим, как покажет себя в реальной эксплуатации. Мне возможно не будет удобным это решение, так как на скриптах я обычно сразу и на другие сервера передаю бэкапы, и формирую дневные, недельные, месячные наборы для долгосрочного хранения. На базе этой панели это делать неудобно. Возможно, останется как дополнительный инструмент, в котором можно быстро сделать бэкап и восстановить где-то в другом месте.
⇨ 🌐 Сайт / Исходники
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql #backup
Речь пойдёт о Postgresus. Основные возможности:
◽️Веб интерфейс для управления заданиями и отчётами
◽️Расписание бэкапов
◽️Сжатие, автоочистка старых бэкапов
◽️Хранение локально или в S3, Google Drive
◽️Уведомления по Email, Telegram
◽️Запускается в Docker Compose
По сути это замена самописным bash скриптам в кроне. Именно их я и использую для таких задач 🤖 Решил упростить себе задачу. Забегая вперёд, скажу, что эта панель реально заменяет эти скрипты, не более.
Postgresus состоит из двух Docker контейнеров: непосредственно сама панель и локальный экземпляр postgresql сервера для хранения собственных настроек. Запустить можно вручную из предложенного в репозитории файла
docker-compose.yml, либо воспользоваться скриптом от разработчика:# curl -sSL https://raw.githubusercontent.com/RostislavDugin/postgresus/refs/heads/main/install-postgresus.sh | bashСкрипт ставит докер и стартует с этим же docker-compose.yml. Я вручную запустил. После запуска можно сразу идти в веб интерфейс на порт сервера 4005 и там всё настраивать. Не рекомендую запускать подобные вещи непосредственно на сервере с СУБД. Я сделал отдельную небольшую виртуалку и открыл для неё доступ к базам.
Дальнейшее управление осуществляется через веб интерфейс. Там всё максимально просто и наглядно:
Бэкап выполняется не особо быстро. Скриптами локально я базу на 5ГБ бэкаплю секунд 30. Из соседней виртуалки с помощью Postgresus бэкапится 12 минут. В целом мне некритично, так как для этого сервера бэкапы выполняются раз в сутки по ночам. Времени достаточно, хотя с такой скоростью это растянется часа на полтора.
Архивы хранятся локально в виде дампов со случайными именами вида
a8bc8814-c548-4f9a-ba0c-97d3b1e107fc. Не очень удобно, если захочется куда-то дублировать их. Скачать дамп можно через веб интерфейс и вручную восстановить с помощью pg_restore. Я заглянул внутрь дампа. Он отличается от того, что делаю я с помощью pg_dump. Скорее всего используются какие-то дополнительные ключи. Я обычно делаю чистый дамп только данных.Восстановление возможно тут же через веб интерфейс, причём на любой сервер, а не только исходный. Это удобно для ручного тестирования бэкапов. Можно создать тестовый сервер и там периодически проверять дампы или выгружать их для каких-то других задач, не нагружая основной сервер.
В общем и целом панель нормальная. Для небольших серверов будет удобным решением в качестве замены самописных скриптов. Плюс, тут дополнительно работает мониторинг доступности баз данных и уведомления и для бэкапов, и для этого мониторинга. Сделано всё аккуратно и красиво. Посмотрим, как покажет себя в реальной эксплуатации. Мне возможно не будет удобным это решение, так как на скриптах я обычно сразу и на другие сервера передаю бэкапы, и формирую дневные, недельные, месячные наборы для долгосрочного хранения. На базе этой панели это делать неудобно. Возможно, останется как дополнительный инструмент, в котором можно быстро сделать бэкап и восстановить где-то в другом месте.
⇨ 🌐 Сайт / Исходники
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql #backup
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍85👎7
Вчера рассмотрел Postgresus - веб панель для бэкапов баз Postgresql. У неё есть очень близкий и более старый аналог – PG Back Web. Панели похожи по функциональности и архитектуре. Автор Postgresus наверняка знаком с ней, потому что многие вещи реализованы схожим образом. Но есть и отличия. Каждый, судя по всему, реализовал настройки и управление так, как ему казалось более удобным. Расскажу по порядку.
1️⃣ Установка выполняется так же, как и у Postgresus – готовый
2️⃣ В Pgbackweb сущности в виде баз данных и заданий для бэкапа разделены. Отдельно добавляется база, отдельно для неё создаётся задание для бэкапа. Соответственно, для одной и той же базы могут быть созданы разные задачи с бэкапом и параметрами хранения. В Postgresus настройки базы и бэкапа для неё объединены в одну сущность.
3️⃣ Создаваемый в Pgbackweb дамп тут же на лету жмётся в zip. А в самом архиве лежит чистый дамп в текстовом формате, который можно открыть, посмотреть, изменить. Создание дампа в Pgbackweb примерно в 2-2,5 раза дольше, чем у Postgresus. Последний жмёт средствами самого pg_dump, если я правильно понял из исходников, то есть использует ключи
К сожалению, обе панели не дают возможность самому задавать эти параметры. А иногда бывает нужно либо так, либо эдак. Например, если тебе важна скорость, то лучше жать встроенными средствами. Но из такого дампа потом неудобно извлекать отдельную таблицу, если она понадобится. А из текстового дампа это сделать очень просто. Лично я, когда создаю дампы баз данных, выгружаю их в обычном текстовом формате и жму сам с помощью pigz в многопоточном режиме. Получается и быстро, и удобно. Потом распаковал и делай с ним, что хочешь.
4️⃣ Pgbackweb предлагает сохранять бэкапы либо локально, либо в S3. Больше у неё ничего нет для хранения. Формат путей вида
5️⃣ Сохранённый дамп можно самому скачать и восстановить вручную, либо воспользоваться веб интерфейсом. Базу можно восстановить как в исходную, так и в другую, в том числе на другом сервере. Здесь возможности обеих панелей совпадают.
6️⃣ В качестве уведомлений Pgbackweb предлагает только вебхуки, что слабовато по сравнению с готовой интеграцией с Telegram, Email, Slack, Discord в Postgresus.
В общем и целом панели сильно похожи и выполняют одни и те же задачи. Разница в некоторых мелочах, которые кому-то могут быть критичны, кому-то нет. Мне лично больше понравилась Postgresus за её внешний вид и внутреннюю логику. Сжатые дампы делает намного быстрее, что уже на базах в 5-10 ГБ становится критично. Так как, к примеру, 15 минут против 35 для 10 ГБ – это существенная разница.
⇨🌐 Исходники / ▶️ Видеобзор
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql #backup
docker-compose.yaml в репозитории для запуска двух контейнеров: сама веб панель и локальная Postgresql для сохранения настроек и состояния. Достаточно запустить docker compose и можно идти на порт 8085 сервера и пользоваться панелью. В консоли больше делать нечего.-Fc (custom-format) -Z 6 (compression level). К сожалению, обе панели не дают возможность самому задавать эти параметры. А иногда бывает нужно либо так, либо эдак. Например, если тебе важна скорость, то лучше жать встроенными средствами. Но из такого дампа потом неудобно извлекать отдельную таблицу, если она понадобится. А из текстового дампа это сделать очень просто. Лично я, когда создаю дампы баз данных, выгружаю их в обычном текстовом формате и жму сам с помощью pigz в многопоточном режиме. Получается и быстро, и удобно. Потом распаковал и делай с ним, что хочешь.
/backups/dbase01/2025/07/21. Это удобно, если захочется забирать готовые дампы куда-то ещё и складывать их в архивы по каким-то датам. В Postgresus такой возможности нет. Там ни в пути, ни в имени файла нет никаких временных меток и упоминания имени базы.В общем и целом панели сильно похожи и выполняют одни и те же задачи. Разница в некоторых мелочах, которые кому-то могут быть критичны, кому-то нет. Мне лично больше понравилась Postgresus за её внешний вид и внутреннюю логику. Сжатые дампы делает намного быстрее, что уже на базах в 5-10 ГБ становится критично. Так как, к примеру, 15 минут против 35 для 10 ГБ – это существенная разница.
⇨
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql #backup
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
👍63👎3
Раз уж я рассмотрел панели для управления бэкапами (Postgresus и Pgbackweb) в виде дампов в Postgresql, было бы логично рассмотреть и вариант со своими велосипедами на bash. Поделюсь тем, что использую я.
Сначала полный текст скрипта для бэкапа:
Рассказываю, что тут происходит:
1️⃣ Завожу в переменную BASES список баз, которые мы будем бэкапить. Их можно указывать вручную, примерно так:
Можно использовать обратный подход. Бэкапить все базы, но вручную или по маске задавать исключения. Примерно так:
2️⃣ База дампится с помощью
3️⃣ В дампе проверяем наличие строки
Соответственно, если строки присутствуют, пишем в лог файл, что Backup is OK, если есть проблемы, то Backup is corrupted. Дальше этот файл забирает либо мониторинг, либо хранилка логов. И если они видят фразу corrupted, то срабатывает триггер.
4️⃣ Если с дампом всё в порядке, то он жмётся архиватором
Получается автоматическая максимально простая и эффективная схема работы. Я вчера добавлял базы в веб панель. Честно говоря, меня это утомило. Если баз 1-2, то не проблема. А 15 штук добавлять уже надоедает. Бывает и больше. Плюс, надо вручную следить за ними, добавлять, отключать ненужные и т.д. Так что панель вроде и выглядит удобно, но если баз много, то удобства уже сомнительные.
Дальше у меня работает ещё один простой скрипт, который забирает эти дампы на тестовый сервер, распаковывает и заливает в СУБД. Расскажу о нём в следующей заметке.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql #backup #script
Сначала полный текст скрипта для бэкапа:
#!/bin/bash
BASES=`/opt/pgpro/1c-16/bin/psql -U postgres -l | grep "_buh\|_zup" | awk '{print $1}'`
DATA=`date +"%Y-%m-%d_%H-%M"`
LOGDIR=/var/lib/pgpro/service_logs
BACKUPDIR=/var/lib/pgpro/backup
for i in ${BASES};
do
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start backup $i" >> $LOGDIR/backup.log
/opt/pgpro/1c-16/bin/pg_dump -U postgres $i > $BACKUPDIR/$DATA-$i.sql 2>> $LOGDIR/dump.log
BEGIN=`head -n 2 $BACKUPDIR/$DATA-$i.sql | grep ^'-- PostgreSQL database dump' | wc -l`
END=`tail -n 3 $BACKUPDIR/$DATA-$i.sql | grep ^'-- PostgreSQL database dump complete' | wc -l`
if [ "$BEGIN" == "1" ];then
if [ "$END" == "1" ];then
echo "Backup ${i} is OK" >> $LOGDIR/backup.log
/usr/bin/pigz -c $BACKUPDIR/$DATA-$i.sql > $BACKUPDIR/$DATA-$i.sql.gz
/usr/bin/rm $BACKUPDIR/$DATA-$i.sql
else
echo "Backup ${i} is corrupted" >> $LOGDIR/backup.log
fi
else
echo "Backup ${i} is corrupted" >> $LOGDIR/backup.log
fi
echo "`date +"%Y-%m-%d_%H-%M-%S"` End backup $i" >> $LOGDIR/backup.log
echo "=========================================" >> $LOGDIR/backup.log
done
Рассказываю, что тут происходит:
BASES=("db01_zup" "db02_buh"). Можно брать список всех баз. В данном случае на сервере я маркирую базы метками _buh и _zup в названиях баз, чтобы по ним делать выборку. Если базу не нужно бэкапить, то эта метка не ставится. Можно придумать любую свою метку, например _back. Это позволяет автоматически бэкапить все нужные базы, не следя за их составом. Очень актуально, если создаёте и удаляете базы не вы, но вам нужны все бэкапы баз. Можно использовать обратный подход. Бэкапить все базы, но вручную или по маске задавать исключения. Примерно так:
/opt/pgpro/1c-15/bin/psql -U postgres -l | grep -wv 'template0\|template1\|test-base\|_test' | sed -e '1,3d' | head -n -2 | awk '{print $1}'`pg_dump без каких-либо дополнительных параметров. На выходе имеем обычный несжатый текстовый дамп.-- PostgreSQL database dump в начале дампа и -- PostgreSQL database dump complete в конце. Поэтому нам важно иметь дамп в текстовом формате. Если процесс снятия дампа прошёл без ошибок и в дампе присутствуют эти строки, то с большой долей вероятности с ним всё в порядке. Я ни разу не сталкивался с обратной ситуацией.Соответственно, если строки присутствуют, пишем в лог файл, что Backup is OK, если есть проблемы, то Backup is corrupted. Дальше этот файл забирает либо мониторинг, либо хранилка логов. И если они видят фразу corrupted, то срабатывает триггер.
pigz. Он работает многопоточно всеми доступными ядрами процессора. Если не хотите нагружать так плотно сервер, то количество потоков можно ограничить ключами. Я обычно снимаю дампы ночью и жму на всю катушку, чтобы побыстрее завершилось. Дампы потом ещё передавать надо. Это уже отдельная процедура и запускается с сервера бэкапов. С самого сервера СУБД к бэкапам доступа нет. Получается автоматическая максимально простая и эффективная схема работы. Я вчера добавлял базы в веб панель. Честно говоря, меня это утомило. Если баз 1-2, то не проблема. А 15 штук добавлять уже надоедает. Бывает и больше. Плюс, надо вручную следить за ними, добавлять, отключать ненужные и т.д. Так что панель вроде и выглядит удобно, но если баз много, то удобства уже сомнительные.
Дальше у меня работает ещё один простой скрипт, который забирает эти дампы на тестовый сервер, распаковывает и заливает в СУБД. Расскажу о нём в следующей заметке.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#postgresql #backup #script
Please open Telegram to view this post
VIEW IN TELEGRAM
4👍161👎3
Утром рассказал, как делаю бэкапы баз Postgresql с помощью скриптов и
Первым делом надо забрать дампы с исходного сервера. Для этого беру простой скрипт, который забирает по SSH только свежие файлы за прошлый день. Если забрать сразу только нужные файлы, то потом не придётся делать в них выборку:
Использую rsync, а список файлов для копирования формирую сразу в выражении ключа, подключившись к нужному хосту по SSH и отсортировав файлы по дате, взяв не старше суток. В данном случае файл timestamp через
Ну а дальше дело техники. По очереди выполняю набор команд для удаления старой базы, создания новой, распаковки и заливки дампа. Перед первым запуском этого скрипта вручную создаю все восстанавливаемые базы и выборочно проверяю восстановление. Потом формирую итоговый список команд:
Сразу говорю, что я тут ничего не оптимизировал, никаких проверок не делал. Если просто взять и запустить, то скорее всего у вас вывалятся какие-то ошибки или что-то пойдёт не так. Я просто показываю идею. У меня уже давно и структура каталогов одна и та же, и подход к именованию баз, бэкапов и т.д. Это всё сделано под меня и работает так уже много лет. Меня устраивает.
В данном скрипте нет никаких проверок успешной работы и оповещений, потому что это не последний этап проверок. Далее в зависимости от того, где эта база используется, запускаются свои проверки. Для баз 1С выполняется автоматическая выгрузка в dt с помощью отдельного скрипта. Если она проходит успешно, то считается, что дамп базы живой и нормально восстановился.
Если же это база от веб проекта, то параллельно из другого бэкапа восстанавливаются исходники в тестовый веб сервер, подключается восстановленная база и работает стандартная веб проверка в Zabbix Server, которая ищет какие-то данные на странице, которые без работающей базы не будут показаны. Если веб проверки проходят успешно, то считается, что база восстановилась, да и в целом бэкап живой.
Более сложные проверки в восстановленных базах я не делаю. Мой опыт в обслуживаемых инфраструктурах показывает, что этого достаточно. Ни разу не сталкивался, что всё прошло успешно, а с базой проблемы. Обычно проблемы возникают сразу в снятии дампа. Если он корректно выполнен, то дальше уже все отрабатывает нормально.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#backup #postgresql #script
pg_dump. Сейчас покажу, как я их проверяю. Для этого обычно держу небольшой тестовый сервер с той же версией Postgresql. В идеале это должна быть копия прода, но не всегда это возможно. На нём же зачастую проверяю обновления.Первым делом надо забрать дампы с исходного сервера. Для этого беру простой скрипт, который забирает по SSH только свежие файлы за прошлый день. Если забрать сразу только нужные файлы, то потом не придётся делать в них выборку:
#!/bin/bash
/usr/bin/rsync -av --progress --files-from=<(ssh root@10.20.5.10 '/usr/bin/find /var/lib/pgpro/backup -type f -mtime -1 -exec basename {} \; | egrep -v timestamp') root@10.20.5.10:/var/lib/pgpro/backup/ /data/backup/
Использую rsync, а список файлов для копирования формирую сразу в выражении ключа, подключившись к нужному хосту по SSH и отсортировав файлы по дате, взяв не старше суток. В данном случае файл timestamp через
egrep -v добавлен в исключения. У меня там метка времени последнего бэкапа хранится для нужд мониторинга.Ну а дальше дело техники. По очереди выполняю набор команд для удаления старой базы, создания новой, распаковки и заливки дампа. Перед первым запуском этого скрипта вручную создаю все восстанавливаемые базы и выборочно проверяю восстановление. Потом формирую итоговый список команд:
#!/bin/bash
BASES=`/opt/pgpro/1c-16/bin/psql -U postgres -l | grep "_buh\|_zup" | awk '{print $1}'`
BACKUP_DIR="/data/backup"
for i in ${BASES};
do
echo "`date +"%Y-%m-%d_%H-%M-%S"` Drop database ${i}"
/opt/pgpro/1c-16/bin/dropdb -U postgres ${i}
echo "`date +"%Y-%m-%d_%H-%M-%S"` Create database ${i}"
/opt/pgpro/1c-16/bin/createdb -U postgres -T template0 ${i}
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start extract $i"
/usr/bin/find /data/backup -type f -name *${i}* -exec /usr/bin/unpigz '{}' \;
echo "`date +"%Y-%m-%d_%H-%M-%S"` End extract $i"
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start restore $i"
/opt/pgpro/1c-16/bin/psql -U postgres ${i} < ${BACKUP_DIR}/`ls ${BACKUP_DIR} | grep ${i}` 1>/dev/null
echo "`date +"%Y-%m-%d_%H-%M-%S"` End restore $i"
echo "`date +"%Y-%m-%d_%H-%M-%S"` rm dump ${i}"
/usr/bin/rm ${BACKUP_DIR}/`ls ${BACKUP_DIR} | grep ${i}`
done
Сразу говорю, что я тут ничего не оптимизировал, никаких проверок не делал. Если просто взять и запустить, то скорее всего у вас вывалятся какие-то ошибки или что-то пойдёт не так. Я просто показываю идею. У меня уже давно и структура каталогов одна и та же, и подход к именованию баз, бэкапов и т.д. Это всё сделано под меня и работает так уже много лет. Меня устраивает.
В данном скрипте нет никаких проверок успешной работы и оповещений, потому что это не последний этап проверок. Далее в зависимости от того, где эта база используется, запускаются свои проверки. Для баз 1С выполняется автоматическая выгрузка в dt с помощью отдельного скрипта. Если она проходит успешно, то считается, что дамп базы живой и нормально восстановился.
Если же это база от веб проекта, то параллельно из другого бэкапа восстанавливаются исходники в тестовый веб сервер, подключается восстановленная база и работает стандартная веб проверка в Zabbix Server, которая ищет какие-то данные на странице, которые без работающей базы не будут показаны. Если веб проверки проходят успешно, то считается, что база восстановилась, да и в целом бэкап живой.
Более сложные проверки в восстановленных базах я не делаю. Мой опыт в обслуживаемых инфраструктурах показывает, что этого достаточно. Ни разу не сталкивался, что всё прошло успешно, а с базой проблемы. Обычно проблемы возникают сразу в снятии дампа. Если он корректно выполнен, то дальше уже все отрабатывает нормально.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#backup #postgresql #script
Telegram
ServerAdmin.ru
Раз уж я рассмотрел панели для управления бэкапами (Postgresus и Pgbackweb) в виде дампов в Postgresql, было бы логично рассмотреть и вариант со своими велосипедами на bash. Поделюсь тем, что использую я.
Сначала полный текст скрипта для бэкапа:
#!/bin/bash…
Сначала полный текст скрипта для бэкапа:
#!/bin/bash…
👍108👎4
backup-postgresql-restic.sh
2.1 KB
🔥 Бэкап баз postgresql с помощью restic!
Вновь возвращаюсь к очень удобному инструменту для бэкапов restic. Последнее время часто стал его использовать. Дальше вы поймёте, почему. На создание бэкапов баз данных с его помощью меня навела вот эта статья:
⇨ Restic: эффективное резервное копирование из Stdin
Автор с помощью restic дампит базы данных в Kubernetes. Я немного переделал его решение для своих локальных бэкапов. Основная проблема, которая там решена - корректная отработка ошибок снятия дампа. Я до этого сам не догадался, правда не сильно и пытался, поэтому дампил по старинке сначала в файл, проверял, а потом уже куда-то на хранение отправлял.
Но можно всё это сделать на лету и с проверкой ошибок. То есть делается дамп и тут же через pipe отправляется в restic. Этот способ удобен по нескольким причинам:
1️⃣ Самое основное - сырые дампы в restic очень хорошо дедуплицируются и экономят место. Если между дампами небольшие изменения, то даже хранение большого количества файлов за разные дни не съедает место на хранилище в отличие от обычного хранения в исходном виде на файловой системе.
2️⃣ Прямая отправка данных с pg_dump в restic исключает промежуточное сохранение, что существенно экономит ресурс SSD дисков, если у вас много баз приличного размера. Да и банально быстрее получается.
3️⃣ Если во время снятия дампа будет ошибка, то такой бэкап помечается отдельным тэгом и по этому тэгу вы сможете понять, что у вас какая-то проблема. Я специально проверил этот момент. Отрабатывает корректно. Если дамп прерывается по какой-то причине и не завершается без ошибок, то этот бэкап помечается отдельным тэгом.
В статье у автора подробно всё рассказано, не буду на этом останавливаться. Покажу свой итоговый скрипт, который бэкапит дампы условно локально, а не в S3. Если надо в S3 или куда-то ещё, то просто измените переменную
Надо убрать ключ
Это, как я понял, связано с тем, что ключ
И ещё важный момент. Не забудьте сохранить пароль от репозитория, который тоже задаётся в скрипте. Так как пароль передаётся в виде переменной окружения, его можно хранить где-то отдельно и подгружать перед запуском основного скрипта. Я в предыдущей заметке про restic упоминал об этом и показывал пример в конце.
Сам скрипт прикрепил к сообщению. Также продублировал его в публичный репозиторий. Не забудьте поменять переменные под свои нужды и окружение.
Полезные материалы по теме:
▪️Описание Restic с примерами
▪️Мониторинг Restic с помощью Zabbix и Prometheus
▪️Бэкап с помощью Restic в S3 на примере Selectel
Restic очень удобный инструмент для бэкапов. Рекомендую присмотреться.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#backup #postgresql #restic
Вновь возвращаюсь к очень удобному инструменту для бэкапов restic. Последнее время часто стал его использовать. Дальше вы поймёте, почему. На создание бэкапов баз данных с его помощью меня навела вот эта статья:
⇨ Restic: эффективное резервное копирование из Stdin
Автор с помощью restic дампит базы данных в Kubernetes. Я немного переделал его решение для своих локальных бэкапов. Основная проблема, которая там решена - корректная отработка ошибок снятия дампа. Я до этого сам не догадался, правда не сильно и пытался, поэтому дампил по старинке сначала в файл, проверял, а потом уже куда-то на хранение отправлял.
Но можно всё это сделать на лету и с проверкой ошибок. То есть делается дамп и тут же через pipe отправляется в restic. Этот способ удобен по нескольким причинам:
В статье у автора подробно всё рассказано, не буду на этом останавливаться. Покажу свой итоговый скрипт, который бэкапит дампы условно локально, а не в S3. Если надо в S3 или куда-то ещё, то просто измените переменную
REPO_PREFIX в скрипте и добавьте переменных для доступа к бакетам. Плюс, я поменял формат хранения данных. Вместо tar выгружаю в текстовый sql файл. Мне так удобнее. Ещё исправил там небольшую ошибку, которую выявил во время тестов. В строке:restic forget -r "${REPO_PREFIX}/$db" --group-by=tags --keep-tag "completed"Надо убрать ключ
--group-by=tags, иначе команда на очистку будет возвращать ошибку:refusing to delete last snapshot of snapshot group "tags [job-8dd4f544]"Это, как я понял, связано с тем, что ключ
--keep-tag не позволяет удалить при группировке по тэгам полную группу тэгов, если в ней не останется хотя бы одного снепшота. А так как у нас все тэги с job уникальны, все проблемные снепшоты будут с уникальными тэгами и по сути одни в группе. Поэтому группировку --group-by=tags надо убрать. По крайней мере у меня, когда я убрал, ошибка ушла и очистка стала нормально отрабатывать. В доках это так объясняется: "The forget command will exit with an error if all snapshots in a snapshot group would be removed as none of them have the specified tags."И ещё важный момент. Не забудьте сохранить пароль от репозитория, который тоже задаётся в скрипте. Так как пароль передаётся в виде переменной окружения, его можно хранить где-то отдельно и подгружать перед запуском основного скрипта. Я в предыдущей заметке про restic упоминал об этом и показывал пример в конце.
Сам скрипт прикрепил к сообщению. Также продублировал его в публичный репозиторий. Не забудьте поменять переменные под свои нужды и окружение.
Полезные материалы по теме:
▪️Описание Restic с примерами
▪️Мониторинг Restic с помощью Zabbix и Prometheus
▪️Бэкап с помощью Restic в S3 на примере Selectel
Restic очень удобный инструмент для бэкапов. Рекомендую присмотреться.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#backup #postgresql #restic
Please open Telegram to view this post
VIEW IN TELEGRAM
2👍109👎1