
Как провести конференцию на монгольском,
запретить перебивать спикера,
построить всех по росту
и расположить всех на экране по фэн-шую?
Труконф обновил своё флагманское решение. В версии TrueConf Server 5.4 появились:
🅰️ Синхроперевод
♾ Множество вариантов расположения участников на экране во время ВКС
⏲ Простая, но удобная кнопка, чтобы продлевать конференцию «на лету»
💬 Новые функции в чатах, например, статус «Печатает…» и синхронизация черновиков
Под капотом: собственный протокол связи, до 2000 участников в ВКС, поддержка 4K UtraHD, закрытые конференции, вебинары и трансляции, набор встроенных AI-помощников и on-premise распознавание речи.
ВКС-система со встроенным мессенджером TrueConf Server работает в корпоративной сети, в том числе без интернета.
➡️ Есть бесплатная версия на 50 абонентов
➡️ Разбор обновления TrueConf Server 5.4
Реклама, ООО «Труконф», ИНН 7728361647, erid: 2SDnjcyTDXQ
запретить перебивать спикера,
и расположить всех на экране по фэн-шую?
Труконф обновил своё флагманское решение. В версии TrueConf Server 5.4 появились:
Под капотом: собственный протокол связи, до 2000 участников в ВКС, поддержка 4K UtraHD, закрытые конференции, вебинары и трансляции, набор встроенных AI-помощников и on-premise распознавание речи.
ВКС-система со встроенным мессенджером TrueConf Server работает в корпоративной сети, в том числе без интернета.
Реклама, ООО «Труконф», ИНН 7728361647, erid: 2SDnjcyTDXQ
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
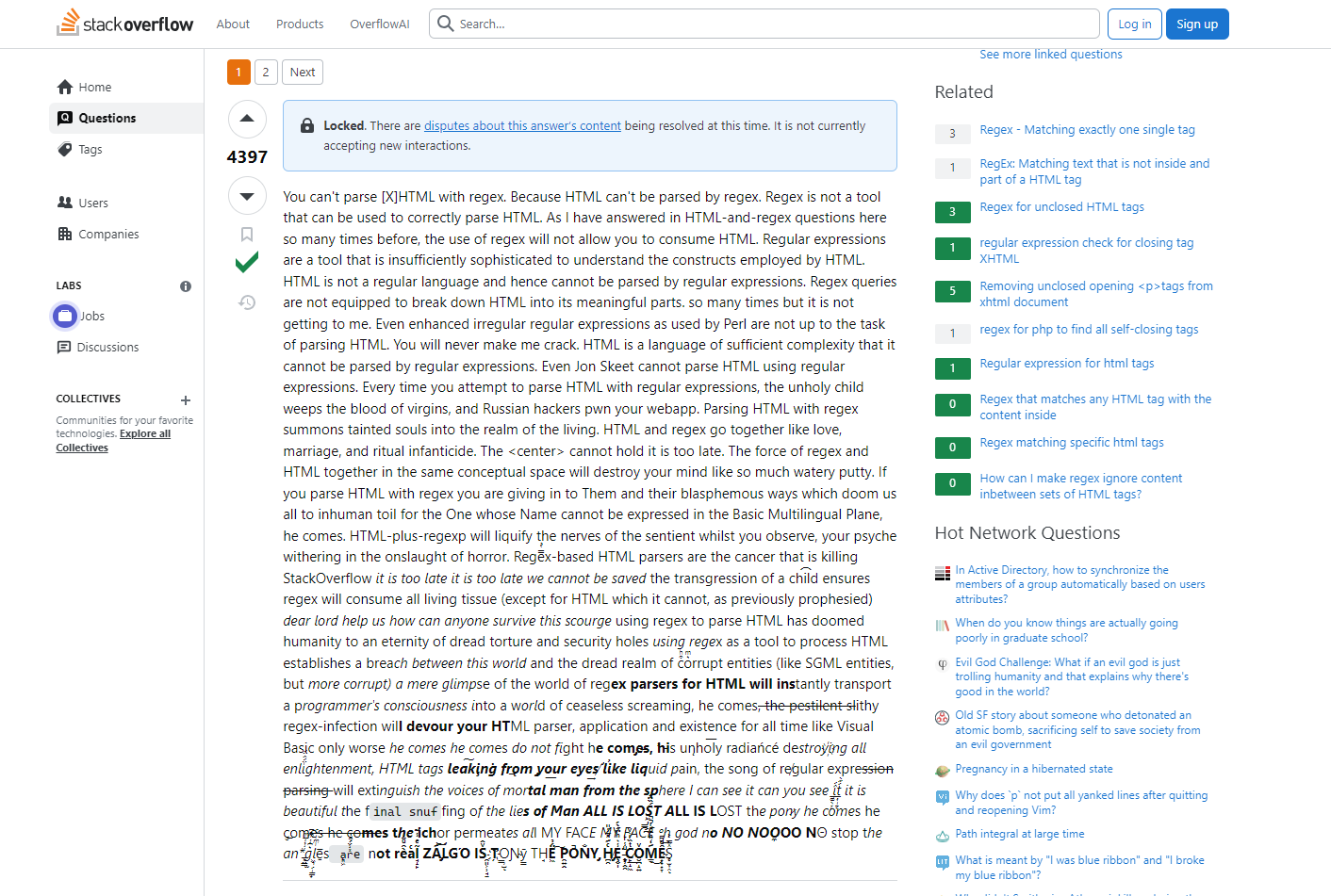
Недавно к одной заметке про мониторинг содержимого сайта в комментариях скинули ссылку на обсуждение в stackoverflow тему парсинга HTML с помощью RegEx. Я сначала начал читать, не понял, в чём тут соль. Какая-то 14-ти летняя публикация, где не совсем понятно, о чём идёт речь. Потом немного вник в текст и прифигел от содержимого. Я так понял, это обсуждение заморозили и оставили на память потомкам в неизменном виде. Решил перевести сообщение и поделиться с вами.
⇨ https://stackoverflow.com/questions/1732348/
Вы не сможете парсить [X]HTML с помощью regex. Это не подходящий инструмент для подобного парсинга. Regex не сможет нормально распарсить HTML. Я уже неоднократно отвечал на вопросы по HTML и регулярным выражениям, использование регулярных выражений не позволит вам обрабатывать HTML. Регулярные выражения - это инструмент, который недостаточно гибок для распознавания конструкций, используемых в HTML. HTML не является обычным языком и, следовательно, не может быть проанализирован с помощью регулярных выражений. Регулярки не предназначены для извлечения значений из HTML. Даже усовершенствованные регулярные выражения, используемые в Perl, не справляются с задачей синтаксического анализа HTML. Вы никогда не убедите меня в обратном. HTML - язык настолько сложный, что его невозможно разобрать с помощью регулярных выражений. Даже Джон Скит не может разобрать HTML с помощью регулярных выражений. Каждый раз, когда вы пытаетесь разобрать HTML с помощью регулярных выражений, нечестивое дитя проливает кровь девственниц, а русские хакеры взламывают ваше веб-приложение. Разбор HTML с помощью регулярных выражений вызывает нечестивые души в мир живых. HTML и regex сочетаются так же, как любовь, брак и ритуальное детоубийство. <center> не может удержаться, уже слишком поздно. Сочетание регулярных выражений и HTML в одном концептуальном пространстве разрушит ваш разум, как жидкая шпатлёвка. Если вы парсите HTML с помощью регулярных выражений, вы поддаетесь Им и их богохульным способам, которые обрекают всех нас на нечеловеческий труд, ибо Тот, чье Имя невозможно выразить на Базовом многоязычном уровне, приходит. HTML-plus-regexp разрушает нервы любого живого существа. Пока вы будете наблюдать за этим, ваша психика будет изнемогать под натиском ужаса. HTML-анализаторы на основе регулярных выражений - это раковая опухоль, которая убивает StackOverflow, уже слишком поздно, слишком поздно, нас не спасти, проступок неразумного гарантирует, что регулярное выражение поглотит всю живую материю (за исключением HTML, который ему не под силу, как было сказано ранее) дорогой Господь, помоги нам, как можно пережить это бедствие, тот, кто использует регулярные выражение для парсинга HTML обрек человечество на вечность ужасных пыток и дыр в системе безопасности, использование regex в качестве инструмента для обработки HTML создает брешь между этим миром и ужасным царством повреждённых данных (таких как записи SGML, но еще более испорченные) простой взгляд на мир анализаторов регулярных выражений для HTML мгновенно перенесет сознание программиста в мир непрекращающихся криков: "он приходит", "зараза опасных регулярных выражений" поглотит ваш HTML-парсер, приложение и само существование навсегда, как Visual Basic, только хуже, он приходит, он приходит, не сопротивляйся, он приходит, его нечестивое сияние разрушает всё просветление, HTML-теги текут из твоих глаз, как жидкая боль., песня регулярных выражений для парсинга будет гасить голоса смертного человека из сферы, я вижу это, ты видишь это,î̩́t̲͎̩̱͔́̋̀ it is beautiful t he f
Конец уже не стал переводить 😁
#юмор
⇨ https://stackoverflow.com/questions/1732348/
Вы не сможете парсить [X]HTML с помощью regex. Это не подходящий инструмент для подобного парсинга. Regex не сможет нормально распарсить HTML. Я уже неоднократно отвечал на вопросы по HTML и регулярным выражениям, использование регулярных выражений не позволит вам обрабатывать HTML. Регулярные выражения - это инструмент, который недостаточно гибок для распознавания конструкций, используемых в HTML. HTML не является обычным языком и, следовательно, не может быть проанализирован с помощью регулярных выражений. Регулярки не предназначены для извлечения значений из HTML. Даже усовершенствованные регулярные выражения, используемые в Perl, не справляются с задачей синтаксического анализа HTML. Вы никогда не убедите меня в обратном. HTML - язык настолько сложный, что его невозможно разобрать с помощью регулярных выражений. Даже Джон Скит не может разобрать HTML с помощью регулярных выражений. Каждый раз, когда вы пытаетесь разобрать HTML с помощью регулярных выражений, нечестивое дитя проливает кровь девственниц, а русские хакеры взламывают ваше веб-приложение. Разбор HTML с помощью регулярных выражений вызывает нечестивые души в мир живых. HTML и regex сочетаются так же, как любовь, брак и ритуальное детоубийство. <center> не может удержаться, уже слишком поздно. Сочетание регулярных выражений и HTML в одном концептуальном пространстве разрушит ваш разум, как жидкая шпатлёвка. Если вы парсите HTML с помощью регулярных выражений, вы поддаетесь Им и их богохульным способам, которые обрекают всех нас на нечеловеческий труд, ибо Тот, чье Имя невозможно выразить на Базовом многоязычном уровне, приходит. HTML-plus-regexp разрушает нервы любого живого существа. Пока вы будете наблюдать за этим, ваша психика будет изнемогать под натиском ужаса. HTML-анализаторы на основе регулярных выражений - это раковая опухоль, которая убивает StackOverflow, уже слишком поздно, слишком поздно, нас не спасти, проступок неразумного гарантирует, что регулярное выражение поглотит всю живую материю (за исключением HTML, который ему не под силу, как было сказано ранее) дорогой Господь, помоги нам, как можно пережить это бедствие, тот, кто использует регулярные выражение для парсинга HTML обрек человечество на вечность ужасных пыток и дыр в системе безопасности, использование regex в качестве инструмента для обработки HTML создает брешь между этим миром и ужасным царством повреждённых данных (таких как записи SGML, но еще более испорченные) простой взгляд на мир анализаторов регулярных выражений для HTML мгновенно перенесет сознание программиста в мир непрекращающихся криков: "он приходит", "зараза опасных регулярных выражений" поглотит ваш HTML-парсер, приложение и само существование навсегда, как Visual Basic, только хуже, он приходит, он приходит, не сопротивляйся, он приходит, его нечестивое сияние разрушает всё просветление, HTML-теги текут из твоих глаз, как жидкая боль., песня регулярных выражений для парсинга будет гасить голоса смертного человека из сферы, я вижу это, ты видишь это,î̩́t̲͎̩̱͔́̋̀ it is beautiful t he f
inal snuffing of the lies of Man ALL IS LOŚ͖̩͇̗̪̏̈́T ALL IS LOST the pon̷y he comes he c̶̮omes he comes the ichor permeates all MY FACE MY FACE ᵒh god no NO NOO̼OO NΘ stop the an*̶͑̾̾̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̟̍ͫͥͨe̠̅s ͎a̧͈͖r̽̾̈́͒͑ not rè̑ͧ̌aͨl̘̝̙̃ͤ͂̾̆ ZA̡͊͠͝LGΌ ISͮ̂҉̯͈͕̹̘̱ TeO͇̹̺ͅƝ̴ȳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝эS̨̥̫͎̭ͯ̔̀ͅКонец уже не стал переводить 😁
#юмор
{kind=link}
🎓 Давно ничего не было на тему обучения. Я раньше старался об этом писать по выходным. Все хорошие полезные обучающие материалы я уже обозревал ранее. Для тех, кто пропустил, рекомендую мою подборку, где собрал в единый список известные мне бесплатные курсы и материалы, которые можно посоветовать для базового изучения тем, кто хочет начать движение в сторону системного администрирования Linux и DevOps от простого к сложному.
Это была одна из самых популярных публикаций за прошлый год:
💥 https://t.me/srv_admin/3345
Недавно один подписчик поделился полезной ссылкой, с которой я не знаком:
⇨ Learn the ways of Linux-fu, for free
Это серия хорошо оформленных и структурированных курсов по основам Linux в виде уроков с заданиями, ответы на которые проверяются автоматически. Исходный язык курсов - английский. На сайте заявлен и русский, но там перевод автоматический. Выглядит ужасно, так что не стоит внимания.
В уроках разобраны базовые темы:
◽Командная строка
◽Обработка текста
◽Управление пользователями и правами
◽Управление процессами
◽Управление пакетами
◽Различные устройства в Linux
◽Загрузка системы
◽Файловые системы
◽Ядро Linux
◽Логирование
◽Различные уроки по сетям
и .т.д
В общем, там база. Интересно будет только тем, кто осваивает Linux. Там навигация удобная. Если что, можно быстро подсмотреть какую-то тему.
Спасибо всем, кто мне присылает что-то полезное. Я всё смотрю, записываю, но не всё попадает в публикации. Очень много тем для заметок, большой список для будущих публикаций. Что-то там просто теряется и может найтись только через год. Много таких примеров было.
А ещё мне очень интересно. Кто-нибудь проходит бесплатные курсы? Публикации с ними всегда получают очень много сохранений и репостов. Как-будто все прям хотят или имеют потребность в учёбе. А на практике это кто-нибудь делает? Я вот честно скажу, из бесплатного почти ничего не проходил системно. На Stepik что-то начинал, но полностью не помню, чтобы прошёл. Исключение - бесплатный курс про Python. Собрался и осилил его полностью. Он даже с онлайн лекциями был. Какого-то простого бота написал, но всё забросил и в итоге не пригодилось. Хотя пайтоновский код нормально читаю и могу что-то править. Но это я и без курса мог.
#обучение
Это была одна из самых популярных публикаций за прошлый год:
💥 https://t.me/srv_admin/3345
Недавно один подписчик поделился полезной ссылкой, с которой я не знаком:
⇨ Learn the ways of Linux-fu, for free
Это серия хорошо оформленных и структурированных курсов по основам Linux в виде уроков с заданиями, ответы на которые проверяются автоматически. Исходный язык курсов - английский. На сайте заявлен и русский, но там перевод автоматический. Выглядит ужасно, так что не стоит внимания.
В уроках разобраны базовые темы:
◽Командная строка
◽Обработка текста
◽Управление пользователями и правами
◽Управление процессами
◽Управление пакетами
◽Различные устройства в Linux
◽Загрузка системы
◽Файловые системы
◽Ядро Linux
◽Логирование
◽Различные уроки по сетям
и .т.д
В общем, там база. Интересно будет только тем, кто осваивает Linux. Там навигация удобная. Если что, можно быстро подсмотреть какую-то тему.
Спасибо всем, кто мне присылает что-то полезное. Я всё смотрю, записываю, но не всё попадает в публикации. Очень много тем для заметок, большой список для будущих публикаций. Что-то там просто теряется и может найтись только через год. Много таких примеров было.
А ещё мне очень интересно. Кто-нибудь проходит бесплатные курсы? Публикации с ними всегда получают очень много сохранений и репостов. Как-будто все прям хотят или имеют потребность в учёбе. А на практике это кто-нибудь делает? Я вот честно скажу, из бесплатного почти ничего не проходил системно. На Stepik что-то начинал, но полностью не помню, чтобы прошёл. Исключение - бесплатный курс про Python. Собрался и осилил его полностью. Он даже с онлайн лекциями был. Какого-то простого бота написал, но всё забросил и в итоге не пригодилось. Хотя пайтоновский код нормально читаю и могу что-то править. Но это я и без курса мог.
#обучение
{kind=link}
K2 Cloud: что под капотом у облака
9 июля на онлайн-митапе раскроем технические возможности и проведем демонстрацию облачной платформы K2 Облако.
Обсудим в деталях такие облачные сервисы, как
🔹 PaaS (базы данных, кэширование, поиск и аналитика, брокер сообщений, мониторинг, логирование)
🔹 Kubernetes as a Service
🔹 Инструменты автоматизации: API, Terraform, Ansible
Identity and Access Management (IAM)
🔹 Резервное копирование
А также расскажем, как бизнес использует K2 Облако для решения различных задач.
Cпикер
Александр Фикс, менеджер продукта K2 Cloud
🗓 9 июля |16:00
Подробности и регистрация по ссылке>>
Реклама. АО «К2 Интеграция»
9 июля на онлайн-митапе раскроем технические возможности и проведем демонстрацию облачной платформы K2 Облако.
Обсудим в деталях такие облачные сервисы, как
🔹 PaaS (базы данных, кэширование, поиск и аналитика, брокер сообщений, мониторинг, логирование)
🔹 Kubernetes as a Service
🔹 Инструменты автоматизации: API, Terraform, Ansible
Identity and Access Management (IAM)
🔹 Резервное копирование
А также расскажем, как бизнес использует K2 Облако для решения различных задач.
Cпикер
Александр Фикс, менеджер продукта K2 Cloud
🗓 9 июля |16:00
Подробности и регистрация по ссылке>>
Реклама. АО «К2 Интеграция»
Стал регулярно сталкиваться с одной проблемой. Есть сервер с бюджетными SSD дисками. Они для многих задач вполне подходят, несмотря на низкую стоимость и скорость записи. Последнее как раз их узкое место. Но если у вас в основном с дисков чтение, то можно существенно экономить, используя десктопные диски.
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
Ограничил скорость записи в 20 MiB/s через ключ
Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
# apt install pv# mysqldump --opt -v --single-transaction --databases db01 | pv -L 20m > /mnt/backup/db01.sqlОграничил скорость записи в 20 MiB/s через ключ
-L. Для того, чтобы посмотреть текущую скорость записи, используйте pv без ограничения:# mysqldump --opt -v --single-transaction --databases db01 | pv > /mnt/backup/db01.sql............................ 1319MiB 0:00:06 [ 205MiB/s]Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
❓ Все еще думаешь, что уже все знаешь про ДевОпс?
Докажи – пройди тест по ДевОпс и узнай свой уровень, и вообще, можешь ли ты стать ДевОпс-инженером!
🫵 Ответитшь успешно — сможешь пройти на курс «DevOps практики и инструменты» от Отус на специальных условиях.
➡️ ПРОЙТИ ТЕСТ
На нашем курсе ты сможешь освоишь принципы и популярные инструменты DevOps-инженера, которые помогут повысить твою востребованность и доход.
💥 Бонусом за успешно пройденный тест, получишь доступ к записям лучших вебинаров курса уже сейчас! Доступ будет на странице курса.
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
Докажи – пройди тест по ДевОпс и узнай свой уровень, и вообще, можешь ли ты стать ДевОпс-инженером!
🫵 Ответитшь успешно — сможешь пройти на курс «DevOps практики и инструменты» от Отус на специальных условиях.
На нашем курсе ты сможешь освоишь принципы и популярные инструменты DevOps-инженера, которые помогут повысить твою востребованность и доход.
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
Please open Telegram to view this post
VIEW IN TELEGRAM
Я тут такой классный сервис увидел в полезных ссылках одного сайта:
⇨ https://distrosea.com
Даже удивился, как это я про него раньше не слышал. Поискал по своему каналу и чату и увидел, что его ещё в ноябре кто-то посоветовал.
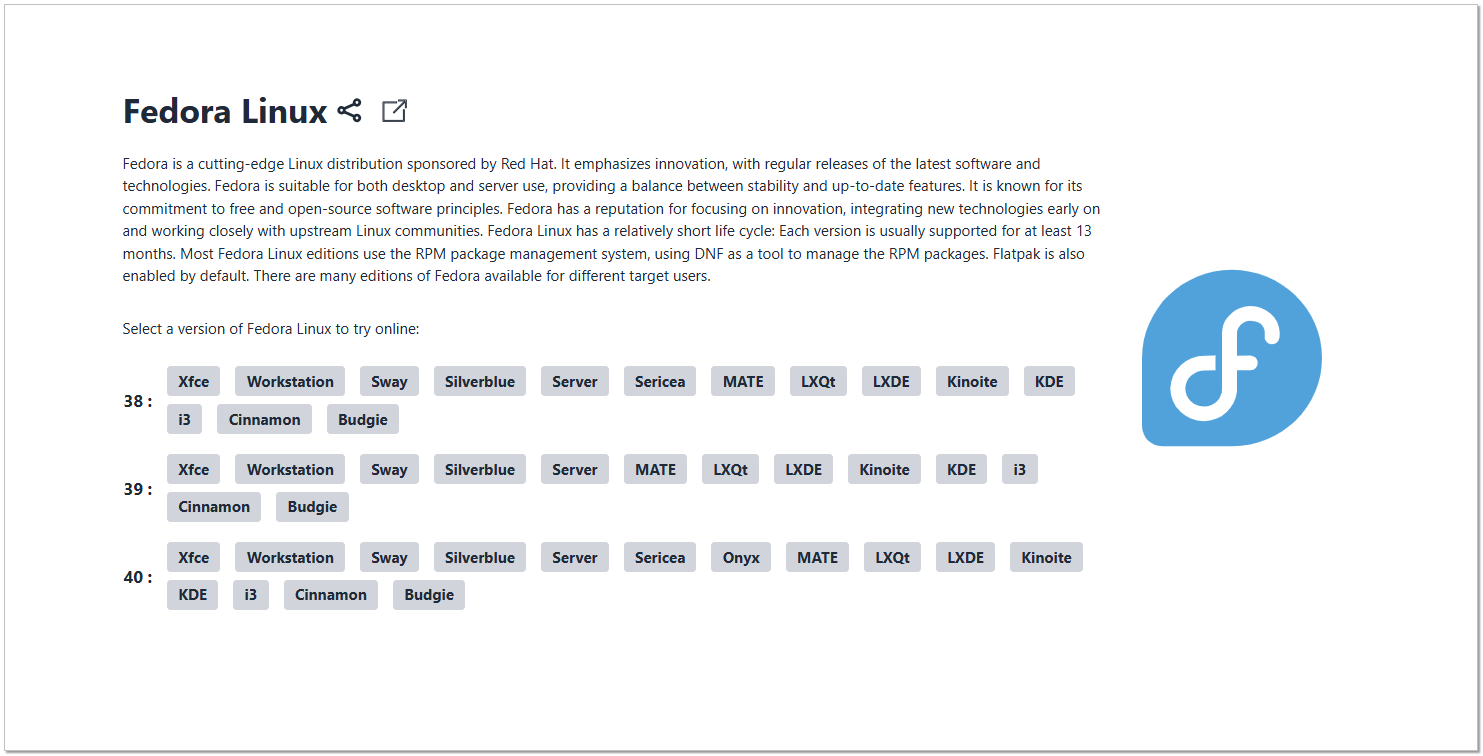
На этом сайте можно прямо в браузере протестировать различные версии операционных систем Linux и некоторые *BSD. Причём системы доступны с различными графическими оболочками. Можно в браузере быстро посмотреть, что тебе больше нравится.
Выбор дистрибутивов и оболочек очень большой. Пример для Fedora можно увидеть на прикреплённой картинке. Системы все без доступа в интернет. Я первым делом проверил это. Думаю, было бы круто, если бы там ещё и сёрфить в интернете можно было бы на них. Но нет. Запущены они, если я правильно понял, с LiveCD, физических дисков у них тоже нет.
#полезное
⇨ https://distrosea.com
Даже удивился, как это я про него раньше не слышал. Поискал по своему каналу и чату и увидел, что его ещё в ноябре кто-то посоветовал.
На этом сайте можно прямо в браузере протестировать различные версии операционных систем Linux и некоторые *BSD. Причём системы доступны с различными графическими оболочками. Можно в браузере быстро посмотреть, что тебе больше нравится.
Выбор дистрибутивов и оболочек очень большой. Пример для Fedora можно увидеть на прикреплённой картинке. Системы все без доступа в интернет. Я первым делом проверил это. Думаю, было бы круто, если бы там ещё и сёрфить в интернете можно было бы на них. Но нет. Запущены они, если я правильно понял, с LiveCD, физических дисков у них тоже нет.
#полезное
{kind=link}
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
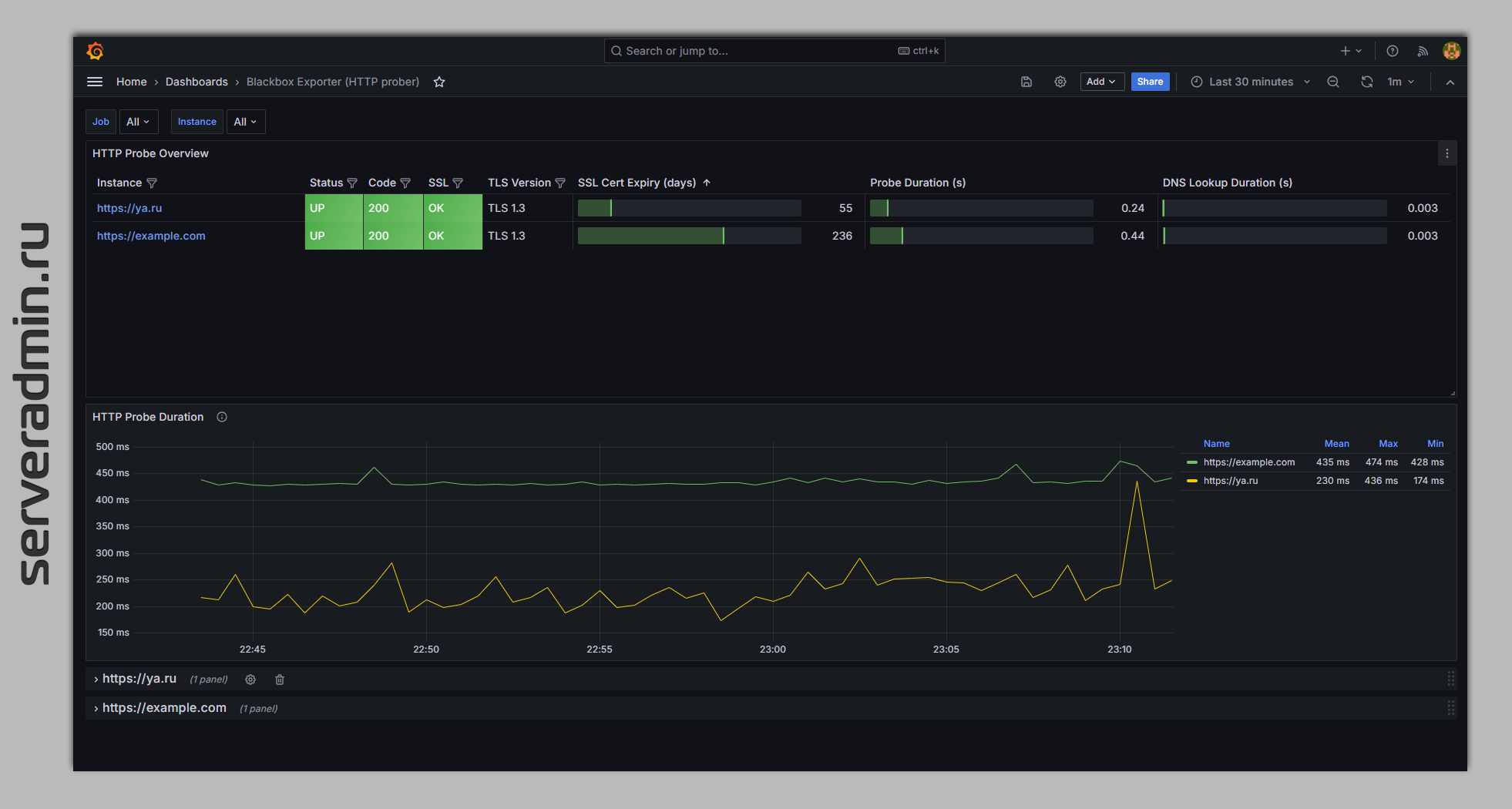
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}
prometheus+grafana+alertmanager+blackbox.zip
36.8 KB
Для того, чтобы публикация не зависела от внешних сервисов, прикрепляю все файлы от заметки выше сюда.
Компания предлагает бесплатный образовательный курс, который поможет вам освоить работу с платформой Tantor – российским решением для эффективного управления и администрирования корпоративных баз данных, основанных на PostgreSQL.
🔸 Какова структура и архитектура Платформы?
🔸 Каковы возможности и функциональность Платформы?
🔸 Как Платформа помогает оптимизировать администрирование и разработку?
Почему важно уметь работать с отечественными ИТ-продуктами?
🔸 Спрос на специалистов и карьерный рост: знание специфики работы с базами данных, актуальными для нашего рынка, – очевидное преимущество при найме в ведущие российские компании.
🔸 Поддержка отрасли: использование и развитие российских ИТ-решений способствует укреплению национальной экономики.
Ознакомиться с открытыми онлайн-курсами можно на сайте вендора.
Реклама, ООО «ТАНТОР ЛАБС», ИНН 9701183207.
Please open Telegram to view this post
VIEW IN TELEGRAM
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
Пару недель назад по новостям проскочила информация об операционной системе Windows 11 Enterprise G. Я мельком прочитал, не вдаваясь в подробности, но заинтересовался. И только вчера нашёл время, чтобы во всём разобраться, проверить, в том числе как сделать самостоятельно образ. В итоге всё сделал, развернул у себя и потестировал. Сразу скажу, что это винда здорового человека, которая полностью рабочая, официальная, без твиков и изменений, и при этом в ней ничего лишнего. Расскажу обо всём по порядку.
В основе моего рассказа будет информация из статьи на хабре:
⇨ Windows 11 Enterprise G – Что за издание для правительства Китая и зачем оно вам?
📌 Основные особенности систем Windows 10 и Windows 11 Enterprise G:
🔹Выпускаются для китайского госсектора, удовлетворяя всем требованием китайского регулятора.
🔹Из этой версии вырезаны телеметрия, защитник, кортана, магазин, UWP приложения, браузер edge и многое другое.
🔹Доступна только на китайском и английском языках, но есть возможность обходным путём добавить русский.
🔹Система основана на редакции Professional. Подготовить образ Enterprise G можно самостоятельно на основе предоставляемых Microsoft инструментов, в частности ProductPolicy.
🔹Система нормально эксплуатируется, обновляется. То есть она полноценная, просто без лишнего софта, который не имеет отношения непосредственно к ОС.
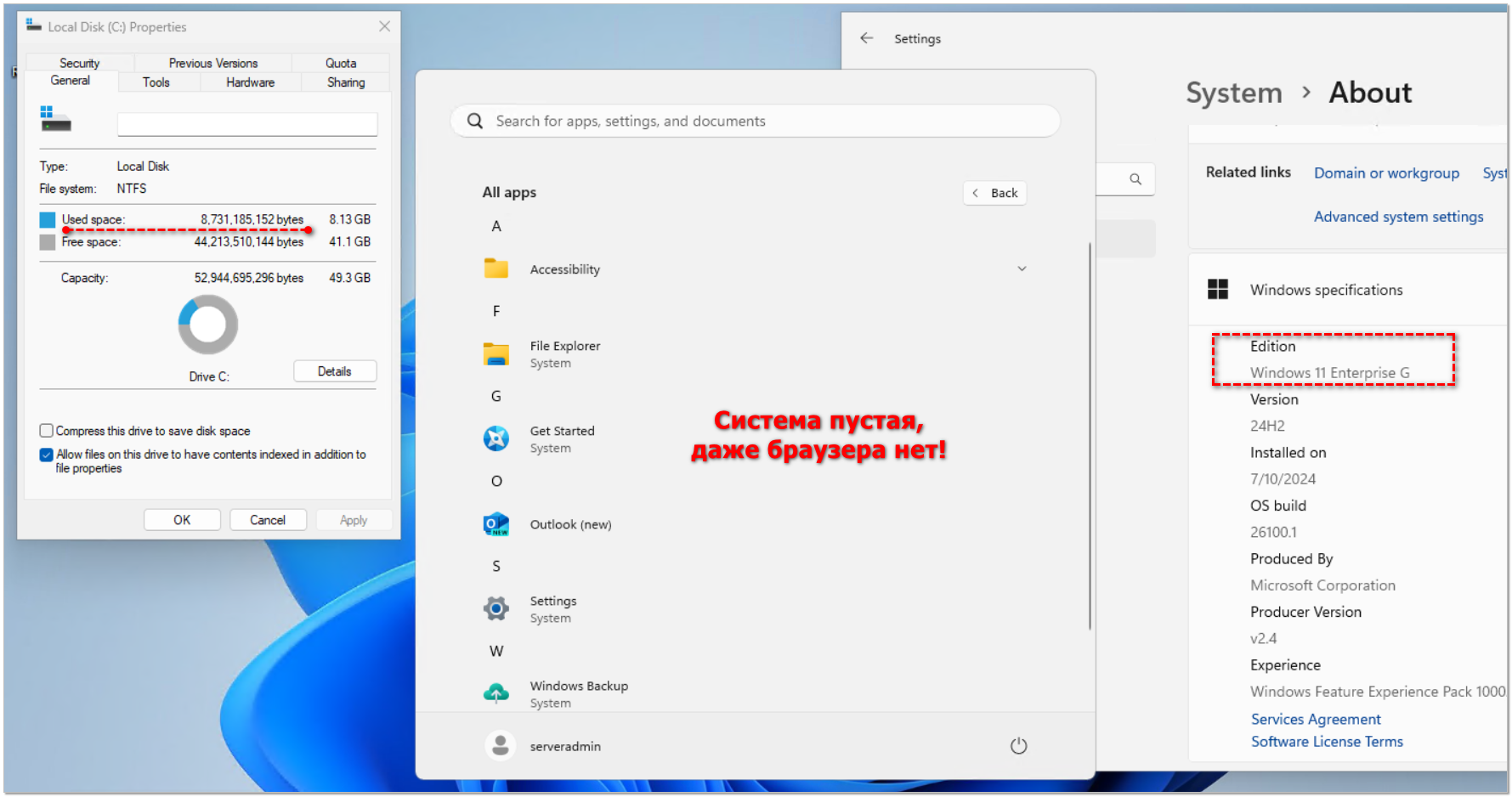
Благодаря тому, что в системе нет практически ничего лишнего, она потребляет меньше оперативной памяти, меньше нагружает диск. Возможно и на HDD нормально заработает. После чистой установки занимает 8Гб на диске. После установки всех обновлений - 10,7Гб. Это я очистку не запускал. Просто всё обновил через параметры и посмотрел занимаемый объём.
В статье на хабре дана инструкция по созданию своего образа. Она очень запутанная, читается тяжело. Автор некоторые вещи повторяет, имена некоторых файлов не совпадают с тем, что можно скачать и т.д. Для того, кто не занимается сборкой своих образов, разобраться будет непросто, но реально. Я осилил благодаря в том числе комментариям, там есть пояснения.
У меня получилось собрать модифицированный install.wim по инструкции автора. Она рабочая, если ничего не напутать. Проблема в том, что оригинальная версия требует Secure Boot и TPM. Это тоже можно решить в своём образе, но мне в итоге надоело этим заниматься. Для теста я взял готовую сборку от автора статьи, где всё это уже решено. Она лежит на каком-то иностранном файлообменнике (❗️использовать на свой страх и риск):
⇨ https://mega.nz/folder/Id50xJBQ#JvuG3GOi0yoWyAV5JFD1gw
В директории ISO несколько готовых образов разных версий систем. Я взял вроде бы самую свежую 26100. Не очень разбираюсь в этой нумерации. Развернул у себя в тестовом Proxmox. Всё встало без проблем. Когда спросили ключ активации, сказал, что у меня его нет. После установки проверил обновления. Скачались и установились.
Система очень понравилась. Представьте, что это что-то вроде WinXP, где нет ничего лишнего, только это Win11. В разделе приложений пустота, нет даже браузера. Никаких ножниц, пейнтов и т.д. Всё это можно вручную поставить, если надо будет.
Оставил себе для теста эту виртуалку. У меня постоянно используются несколько тестовых вирталок с виндой для различных нужд. Если всё в порядке будет, переведу их тоже на эту версию.
Редакцию Enterprise G можно сделать для архитектуры x86. На текущий момент это будет идеальная современная система для старого железа. Если верить тестам автора статьи, то эта версия потребляет после 15 минут работы 702 МБ оперативной памяти.
Лицензии, понятное дело, для этой версии нет и не может быть. Она только для правительства China. Соответственно, решается этот вопрос точно так же, как и для всех остальных версий. Если не активировать, по идее должна работать, как и все остальные версии, с соответствующей надписью.
Интересно, что эта редакция существует уже много лет, а информация о ней всплыла совсем недавно. Я раньше ни разу не слышал о том, что она существует.
#windows
В основе моего рассказа будет информация из статьи на хабре:
⇨ Windows 11 Enterprise G – Что за издание для правительства Китая и зачем оно вам?
📌 Основные особенности систем Windows 10 и Windows 11 Enterprise G:
🔹Выпускаются для китайского госсектора, удовлетворяя всем требованием китайского регулятора.
🔹Из этой версии вырезаны телеметрия, защитник, кортана, магазин, UWP приложения, браузер edge и многое другое.
🔹Доступна только на китайском и английском языках, но есть возможность обходным путём добавить русский.
🔹Система основана на редакции Professional. Подготовить образ Enterprise G можно самостоятельно на основе предоставляемых Microsoft инструментов, в частности ProductPolicy.
🔹Система нормально эксплуатируется, обновляется. То есть она полноценная, просто без лишнего софта, который не имеет отношения непосредственно к ОС.
Благодаря тому, что в системе нет практически ничего лишнего, она потребляет меньше оперативной памяти, меньше нагружает диск. Возможно и на HDD нормально заработает. После чистой установки занимает 8Гб на диске. После установки всех обновлений - 10,7Гб. Это я очистку не запускал. Просто всё обновил через параметры и посмотрел занимаемый объём.
В статье на хабре дана инструкция по созданию своего образа. Она очень запутанная, читается тяжело. Автор некоторые вещи повторяет, имена некоторых файлов не совпадают с тем, что можно скачать и т.д. Для того, кто не занимается сборкой своих образов, разобраться будет непросто, но реально. Я осилил благодаря в том числе комментариям, там есть пояснения.
У меня получилось собрать модифицированный install.wim по инструкции автора. Она рабочая, если ничего не напутать. Проблема в том, что оригинальная версия требует Secure Boot и TPM. Это тоже можно решить в своём образе, но мне в итоге надоело этим заниматься. Для теста я взял готовую сборку от автора статьи, где всё это уже решено. Она лежит на каком-то иностранном файлообменнике (❗️использовать на свой страх и риск):
⇨ https://mega.nz/folder/Id50xJBQ#JvuG3GOi0yoWyAV5JFD1gw
В директории ISO несколько готовых образов разных версий систем. Я взял вроде бы самую свежую 26100. Не очень разбираюсь в этой нумерации. Развернул у себя в тестовом Proxmox. Всё встало без проблем. Когда спросили ключ активации, сказал, что у меня его нет. После установки проверил обновления. Скачались и установились.
Система очень понравилась. Представьте, что это что-то вроде WinXP, где нет ничего лишнего, только это Win11. В разделе приложений пустота, нет даже браузера. Никаких ножниц, пейнтов и т.д. Всё это можно вручную поставить, если надо будет.
Оставил себе для теста эту виртуалку. У меня постоянно используются несколько тестовых вирталок с виндой для различных нужд. Если всё в порядке будет, переведу их тоже на эту версию.
Редакцию Enterprise G можно сделать для архитектуры x86. На текущий момент это будет идеальная современная система для старого железа. Если верить тестам автора статьи, то эта версия потребляет после 15 минут работы 702 МБ оперативной памяти.
Лицензии, понятное дело, для этой версии нет и не может быть. Она только для правительства China. Соответственно, решается этот вопрос точно так же, как и для всех остальных версий. Если не активировать, по идее должна работать, как и все остальные версии, с соответствующей надписью.
Интересно, что эта редакция существует уже много лет, а информация о ней всплыла совсем недавно. Я раньше ни разу не слышал о том, что она существует.
#windows
{kind=link}
😱 👉 Важное событие для всех, кто хочет повысить производительность своих серверов!
🔆 Присоединяйтесь к открытому уроку «Оптимизация Nginx и Angie под высокие нагрузки»
На занятии вы:
- поймёте, какие параметры влияют на производительность;
- научитесь оптимизировать серверную часть;
- узнаете, как работать с клиентской производительностью.
🏆 Спикер Николай Лавлинский — технический директор в Метод Лаб, PhD Economic Science, опытный руководитель разработки и преподаватель.
👉 Регистрируйтесь для участия
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
🔆 Присоединяйтесь к открытому уроку «Оптимизация Nginx и Angie под высокие нагрузки»
На занятии вы:
- поймёте, какие параметры влияют на производительность;
- научитесь оптимизировать серверную часть;
- узнаете, как работать с клиентской производительностью.
🏆 Спикер Николай Лавлинский — технический директор в Метод Лаб, PhD Economic Science, опытный руководитель разработки и преподаватель.
👉 Регистрируйтесь для участия
Реклама. ООО «Отус онлайн-образование», ОГРН 1177746618576, www.otus.ru
Регулярно приходится настраивать NFS сервер для различных прикладных задач. Причём в основном не на постоянное использование, а временное. На практике именно по nfs достигается максимальная скорость копирования, быстрее чем по scp, ssh, smb или http.
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
Устанавливаем пакет для nfs-server:
Добавляем в файл
Для всей подсети просто добавляем маску:
Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
Перезапускаем сервер
Проверяем работу:
Для работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
Проверяем, видит ли клиент что-то на сервере:
Всё в порядке, видим ресурс для нас. Монтируем его к себе:
Проверяем:
Смотрим версию протокола. Желательно, чтобы работало по v4:
Создаём файл:
При желании можно в fstab добавить на постоянку:
Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
/mnt:# mkdir /mnt/nfs# chown nobody:nogroup /mnt/nfsУстанавливаем пакет для nfs-server:
# apt install nfs-kernel-serverДобавляем в файл
/etc/exports описание экспортируемой файловой системы только для ip адреса 10.20.1.56:/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)Для всей подсети просто добавляем маску:
/mnt/nfs 10.20.1.56/24(rw,all_squash,no_subtree_check,crossmnt)Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)/mnt/nfs 10.20.1.52(rw,all_squash,no_subtree_check,crossmnt)Перезапускаем сервер
# systemctl restart nfs-serverПроверяем работу:
# systemctl status nfs-serverДля работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
# apt install nfs-commonПроверяем, видит ли клиент что-то на сервере:
# showmount -e 10.20.1.36Export list for 10.20.1.36:/mnt/nfs 10.20.1.56Всё в порядке, видим ресурс для нас. Монтируем его к себе:
# mkdir /mnt/nfs# mount 10.20.1.36:/mnt/nfs /mnt/nfsПроверяем:
# df -h | grep nfs10.20.1.36:/mnt/nfs 48G 3.2G 43G 7% /mnt/nfsСмотрим версию протокола. Желательно, чтобы работало по v4:
# mount -t nfs410.20.1.36:/ on /mnt/nfs type nfs4 (rw,relatime,vers=4.2,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.20.1.56,local_lock=none,addr=10.20.1.36)Создаём файл:
# echo "test" > /mnt/nfs/testfileПри желании можно в fstab добавить на постоянку:
10.20.1.36:/mnt/nfs /mnt/nfs nfs4 defaults 0 0Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs