
Словил сегодня неприятную ошибку на web сервере под CentOS 7. Уже начал потихоньку кирпичи откладывать, но в итоге отделался легким испугом. Поделюсь с вами решением этой неприятной ошибки, когда система просто не загружается. А так же расскажу подробности насколько можно в художественной форме :)
https://serveradmin.ru/kernel-panic-not-syncing-vfs-unable-to-mount-root-fs/
#ошибка #centos
https://serveradmin.ru/kernel-panic-not-syncing-vfs-unable-to-mount-root-fs/
#ошибка #centos
Server Admin
Kernel panic not syncing: VFS: Unable to mount root fs |...
Решение проблемы, когда сервер не загружается и показывает ошибку Kernel panic not syncing: VFS: Unable to mount root fs.
Продолжение предыдущей темы. Исправление работы панели phpmyadmin при работе с клиентами через proxy по https, но при этом запросы на бэкенд идут по http.
https://serveradmin.ru/oshibka-phpmyadmin-sushhestvuet-nesootvetstvie-mezhdu-https-ukazannym-na-servere-i-kliente/
#ошибка #webserver
https://serveradmin.ru/oshibka-phpmyadmin-sushhestvuet-nesootvetstvie-mezhdu-https-ukazannym-na-servere-i-kliente/
#ошибка #webserver
Server Admin
Ошибка phpmyadmin - Существует несоответствие между HTTPS...
Настраивал сегодня очередной web сервер с внешним балансировщиком на базе nginx и столкнулся с небольшой ошибкой в phpmyadmin. Панель была русская, текст ошибки соответственно тоже русский. В...
Небольшая заметка по настройке русской locale в Centos 8. Столкнулся при переносе Zabbix с Centos 7 на 8. Старые методы добавления локали не сработали, сделал по-другому и записал на память.
https://serveradmin.ru/centos-8-locale-for-language-ru_ru-is-not-found-on-the-server/
#ошибка #zabbix #centos
https://serveradmin.ru/centos-8-locale-for-language-ru_ru-is-not-found-on-the-server/
#ошибка #zabbix #centos
Server Admin
Centos 8 - Locale for language "ru_RU" is not found on the server...
Столкнулся с ошибкой русской локали на Centos 8. Неожиданностью было то, что все способы добавления русской локали, которые использовал раньше, не помогали. Делюсь информацией о том, как добавить...
Небольшая заметка по настройке русской locale в Centos 8. Столкнулся при переносе Zabbix с Centos 7 на 8. Старые методы добавления локали не сработали, сделал по-другому и записал на память.
https://serveradmin.ru/centos-8-locale-for-language-ru_ru-is-not-found-on-the-server/
#ошибка #centos
https://serveradmin.ru/centos-8-locale-for-language-ru_ru-is-not-found-on-the-server/
#ошибка #centos
Server Admin
Centos 8 - Locale for language "ru_RU" is not found on the server...
Столкнулся с ошибкой русской локали на Centos 8. Неожиданностью было то, что все способы добавления русской локали, которые использовал раньше, не помогали. Делюсь информацией о том, как добавить...
Предупреждаю всех, кто будет ставить апдейты на винду. Обновление KB4532920 иногда приводит к циклической перезагрузке сервера. Я словил это на Windows Server 2012 (не R2). В англоязычном гугле полно статей на эту тему. Я два часа провозился, вместо того, чтобы лечь спать :( пока не восстановил работу сервера. Мне помогло удаление файла c:\windows\winsxs\pending.xml. Для этого пришлось загрузиться в командной строке. Кому-то помогает простая загрузка в Safe Mode и штатный ребут. Мне это не помогло. Обновление в итоге не поставилось, я его просто скрыл.
Сервер старый, но все еще в работе, важный и труднопереносимый (лицензии привязаны к железу). Рекомендую держать серваки в виртуалках и делать снепшоты либо бэкапы перед установкой обновлений, чтобы спать потом спокойно, а не заниматься ерундой. И молиться, когда обновляете сами гипервизоры :)
#заметка #ошибка #windows
Сервер старый, но все еще в работе, важный и труднопереносимый (лицензии привязаны к железу). Рекомендую держать серваки в виртуалках и делать снепшоты либо бэкапы перед установкой обновлений, чтобы спать потом спокойно, а не заниматься ерундой. И молиться, когда обновляете сами гипервизоры :)
#заметка #ошибка #windows
Небольшая заметка про не очевидную ошибку синхронизации времени, когда недоступны сервера времени, но явно об этом не говорится.
https://serveradmin.ru/chrony-ne-sinhroniziruet-vremya/
#ошибка #centos
https://serveradmin.ru/chrony-ne-sinhroniziruet-vremya/
#ошибка #centos
Server Admin
Не работает синхронизация времени в chrony | serveradmin.ru
Не первый раз сталкиваюсь с ситуацией, когда не работает синхронизация времени на сервере. На конкретном примере рассмотрю, как разрешить эту ситуацию при использовании службы синхронизации...
Небольшая заметка с полей про ошибку установки Openvpn, с которой столкнулся впервые, несмотря на то, что использую эту программу много лет.
https://serveradmin.ru/openvpn-an-error-occurred-installing-the-tap-device-driver/
#ошибка #openvpn
https://serveradmin.ru/openvpn-an-error-occurred-installing-the-tap-device-driver/
#ошибка #openvpn
Server Admin
OpenVPN - An error occurred installing the TAP device driver |...
Столкнулся сегодня с неожиданной проблемой при установке клиента популярной реализации vpn. Не устанавливался openvpn клиент на Windows 10, выдавая ошибку установки TAP интерфейса: "An error...
Небольшая заметка с полей по исправлению ошибки с кодировкой таблиц в zabbix. Сталкиваюсь не первый раз, поэтому решил оформить в публикацию.
https://serveradmin.ru/oshibka-v-zabbix-nepodderzhivaemaya-kodovaya-stranicza/
#ошибка #zabbix
https://serveradmin.ru/oshibka-v-zabbix-nepodderzhivaemaya-kodovaya-stranicza/
#ошибка #zabbix
Server Admin
Ошибка в Zabbix - Неподдерживаемая кодовая страница | serveradmin.ru
Некоторое время назад столкнулся с ошибкой в web интерфейсе Zabbix после очередного обновления сервера. Текст ошибки в веб интерфейсе - Неподдерживаемая кодовая страница или тип сравнения для...
Небольшая заметка по ошибке в работе cron. Гуглится проблема не очень хорошо, поэтому решил оформить в статью.
https://serveradmin.ru/crond-error-getpwnam-failed/
#ошибка #centos
https://serveradmin.ru/crond-error-getpwnam-failed/
#ошибка #centos
Server Admin
Crond ERROR (getpwnam() failed) | serveradmin.ru
Столкнулся сегодня с ошибкой в работе системного Cron. Текст ошибки совершенно не информативный, так что не понятно, в чем конкретно проблема. Начал разбираться самостоятельно, так как по выдаче...
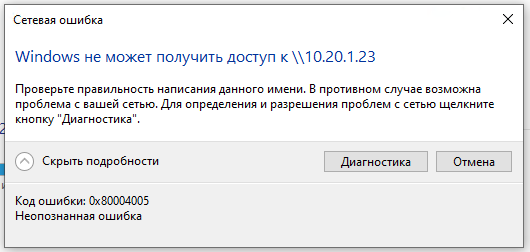
Столкнулся с неожиданной для себя новостью. В современных Windows 10 не получится зайти на сетевую шару без авторизации.
Нужно было быстро получить доступ к файлам на сервере. Поднял самбу и сделал минимальную настройку, открыв доступ для всех к определенной директории.
Очень сильно расстроился, когда не смог зайти на эту шару с Windows 10. Тупо получал ошибку: Error Code 0x80004005 Unspecified error. Ни в логах винды, ни на самбе не было никаких подсказок. Зашел с сервера Windows Server 2012R2, без проблем попал в нужную директорию.
Даже не знал, с чего начать решение проблемы, так как никаких зацепок не было. Просто загуглил ошибку и через некоторое время нашел решение. Оказывается, теперь винда блокирует доступ к шарам без авторизации. Чтобы все-таки зайти на подобный сетевой ресурс, необходимо внести изменения в реестр.
Через консоль с правами администратора проблема решается следующим образом:
reg add "HKLM\SYSTEM\CurrentControlSet\Services\LanmanWorkstation\Parameters" /v AllowInsecureGuestAuth /t REG_DWORD /d 1
net stop LanmanWorkstation && net start LanmanWorkstation
После этого на шару зашел. Знали об этом? Странно, но я не слышал. Походу какое-то недавнее нововведение.
#windows #ошибка
Нужно было быстро получить доступ к файлам на сервере. Поднял самбу и сделал минимальную настройку, открыв доступ для всех к определенной директории.
Очень сильно расстроился, когда не смог зайти на эту шару с Windows 10. Тупо получал ошибку: Error Code 0x80004005 Unspecified error. Ни в логах винды, ни на самбе не было никаких подсказок. Зашел с сервера Windows Server 2012R2, без проблем попал в нужную директорию.
Даже не знал, с чего начать решение проблемы, так как никаких зацепок не было. Просто загуглил ошибку и через некоторое время нашел решение. Оказывается, теперь винда блокирует доступ к шарам без авторизации. Чтобы все-таки зайти на подобный сетевой ресурс, необходимо внести изменения в реестр.
Через консоль с правами администратора проблема решается следующим образом:
reg add "HKLM\SYSTEM\CurrentControlSet\Services\LanmanWorkstation\Parameters" /v AllowInsecureGuestAuth /t REG_DWORD /d 1
net stop LanmanWorkstation && net start LanmanWorkstation
После этого на шару зашел. Знали об этом? Странно, но я не слышал. Походу какое-то недавнее нововведение.
#windows #ошибка
{kind=link}
Решил понемногу переезжать на Debian там, где относительно безопасно можно обновлять версию релизов. Например, в файловых серверах. Создал виртуальную машину с диском на 4Tb и поставил туда Debian.
Сделал дефолтную установку с автоматической разбивкой диска, когда только один корневой раздел. Перезагружаюсь и попадаю в grub rescue. Удивился. Подумал, что наверное установщик не добавил раздел bios_boot. Выполнил еще раз установку и убедился, что раздел на месте, а grub установлен на диск. Но после установки система все равно не грузится с диска, хотя на вид все было сделано правильно. Начал разбираться.
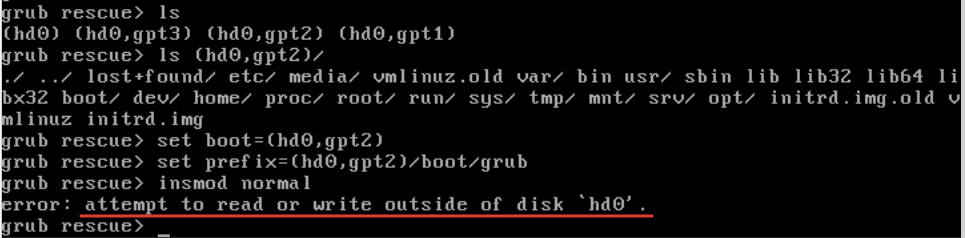
В целом, я понимаю, что надо делать в grub rescue, так как много раз сталкивался и успешно решал проблемы загрузки системы. Есть статья на эту тему. Проверяем список разделов вручную и пытаемся загрузиться с раздела, где живет grub. Выполняю в консоли:
Вижу, что это системный раздел, где живет в том числе и /boot. Указываю его загрузочным и пытаюсь с него загрузиться.
Получаю ошибку:
error: attempt to read or write outside of disk hd0
Гугл быстро выдал решение. Нужно /boot раздел сделать отдельно самым первым. Из-за того, что системный диск большой, а boot на нем, возникает эта ошибка. Смысл понятен, не понятно только, что за глюк. Почему эта ошибка в принципе существует, а установщик не может ее автоматически пофиксить.
Запустил еще раз установку, сам разбил диск, отдав под /boot первый гигабайт диска, остальное в единый раздел 4Tb под корень / . Система успешно установилась и загрузилась после установки.
Сейчас не буду придумывать, что в Centos такой проблемы нет с автоматической разбивкой, не проверял. Я не помню, делал ли там большие диски одним разделом. Такие виртуалки не так часто нужны. А еще я частенько делаю системный раздел небольшого размера, а уже потом отдельно монтирую большой диск под данные. Но то, что Debian автоматически не разруливает эту ситуацию, для меня странно. Фикс этой ошибки не такой уж и очевидный и требует уверенных знаний Linux для быстрого решения.
#grub #ошибка
Сделал дефолтную установку с автоматической разбивкой диска, когда только один корневой раздел. Перезагружаюсь и попадаю в grub rescue. Удивился. Подумал, что наверное установщик не добавил раздел bios_boot. Выполнил еще раз установку и убедился, что раздел на месте, а grub установлен на диск. Но после установки система все равно не грузится с диска, хотя на вид все было сделано правильно. Начал разбираться.
В целом, я понимаю, что надо делать в grub rescue, так как много раз сталкивался и успешно решал проблемы загрузки системы. Есть статья на эту тему. Проверяем список разделов вручную и пытаемся загрузиться с раздела, где живет grub. Выполняю в консоли:
> ls> ls (hd0,gpt2)/Вижу, что это системный раздел, где живет в том числе и /boot. Указываю его загрузочным и пытаюсь с него загрузиться.
> set boot=(hd0,gpt2)> set prefix=(hd0,gpt2)/boot/grub> insmod normalПолучаю ошибку:
error: attempt to read or write outside of disk hd0
Гугл быстро выдал решение. Нужно /boot раздел сделать отдельно самым первым. Из-за того, что системный диск большой, а boot на нем, возникает эта ошибка. Смысл понятен, не понятно только, что за глюк. Почему эта ошибка в принципе существует, а установщик не может ее автоматически пофиксить.
Запустил еще раз установку, сам разбил диск, отдав под /boot первый гигабайт диска, остальное в единый раздел 4Tb под корень / . Система успешно установилась и загрузилась после установки.
Сейчас не буду придумывать, что в Centos такой проблемы нет с автоматической разбивкой, не проверял. Я не помню, делал ли там большие диски одним разделом. Такие виртуалки не так часто нужны. А еще я частенько делаю системный раздел небольшого размера, а уже потом отдельно монтирую большой диск под данные. Но то, что Debian автоматически не разруливает эту ситуацию, для меня странно. Фикс этой ошибки не такой уж и очевидный и требует уверенных знаний Linux для быстрого решения.
#grub #ошибка
{kind=link}
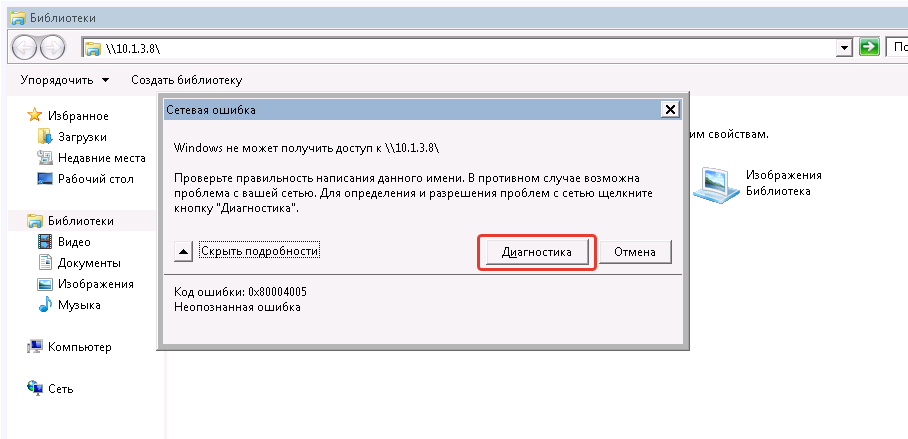
Скажите, есть хоть один человек, которому помогла бы решить проблему Диагностика сетевой ошибки Windows? Я когда вижу подобную ошибку, сразу становится грустно. Никогда точно не знаешь, из-за чего она. Надо доставать бубен, стучать по нему, перезагружать комп и надеяться, что всё получится.
В данном случае я даже не стал заморачиваться, так как это старая Win 7, которую я запустил для теста. С других компов на шару нормально заходит. Помню вал таких ошибок, когда только вышла Windows 10. Нельзя было просто взять и расшарить на ней папку, чтобы можно было зайти с Win 7. В половине случаев это заканчивалось подобной ошибкой. Я уже тогда особо не админил виндовые сетки и даже не помню, как решал эти проблемы. Старался просто перекинуть файлы каким-то другим способом, не тратя время на решение этой проблемы.
#ошибка #windows
В данном случае я даже не стал заморачиваться, так как это старая Win 7, которую я запустил для теста. С других компов на шару нормально заходит. Помню вал таких ошибок, когда только вышла Windows 10. Нельзя было просто взять и расшарить на ней папку, чтобы можно было зайти с Win 7. В половине случаев это заканчивалось подобной ошибкой. Я уже тогда особо не админил виндовые сетки и даже не помню, как решал эти проблемы. Старался просто перекинуть файлы каким-то другим способом, не тратя время на решение этой проблемы.
#ошибка #windows
{kind=link}
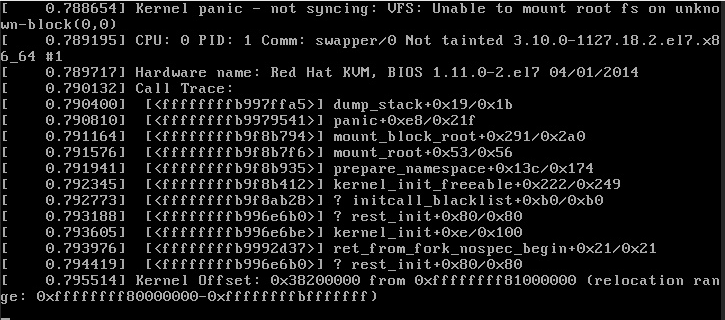
На днях в комментариях к статье по обновлению Debian 10 до 11 отписался человек, у которого отключился ноут в середине обновления. В итоге система умерла и сама загружаться не хотела.
Ситуация типовая, так как я сам неоднократно сталкивался с тем, что рвалось ssh соединение в момент обновления системы. Если было что-то важное, вроде обновления ядра, то есть большой шанс получить проблемы при последующей загрузке системы. Так что я всем рекомендую всегда обновлять систему только в screen или tmux.
Я предположил, что ошибка была связана с тем, что ядро успело обновиться, а initramfs не успела собраться под него. Это обычно происходит в самом конце обновления и занимает значительное время. Чаще всего при обрыве связи и нарушении процесса обновления, initramfs не успевает собраться.
В итоге во время очередной загрузки системы вы увидите порой непонятные и неочевидные ошибки. В моем случае всё решалось тем, что я загружался с предыдущим ядром Linux. Такая возможность есть во всех дистрибутивах. Обычно перед загрузкой системы появляется меню на 3-5 секунд, где можно выбрать предыдущее ядро.
Ровно это и помогло в данном случае с Debian. Удалось загрузиться на предыдущем ядре и успешно завершить обновление. Система Linux довольно живуча. У меня еще ни разу не было ситуации, чтобы я не смог её восстановить в случае каких-то проблем.
#ошибка
Ситуация типовая, так как я сам неоднократно сталкивался с тем, что рвалось ssh соединение в момент обновления системы. Если было что-то важное, вроде обновления ядра, то есть большой шанс получить проблемы при последующей загрузке системы. Так что я всем рекомендую всегда обновлять систему только в screen или tmux.
Я предположил, что ошибка была связана с тем, что ядро успело обновиться, а initramfs не успела собраться под него. Это обычно происходит в самом конце обновления и занимает значительное время. Чаще всего при обрыве связи и нарушении процесса обновления, initramfs не успевает собраться.
В итоге во время очередной загрузки системы вы увидите порой непонятные и неочевидные ошибки. В моем случае всё решалось тем, что я загружался с предыдущим ядром Linux. Такая возможность есть во всех дистрибутивах. Обычно перед загрузкой системы появляется меню на 3-5 секунд, где можно выбрать предыдущее ядро.
Ровно это и помогло в данном случае с Debian. Удалось загрузиться на предыдущем ядре и успешно завершить обновление. Система Linux довольно живуча. У меня еще ни разу не было ситуации, чтобы я не смог её восстановить в случае каких-то проблем.
#ошибка
{kind=link}
Я на прошлой неделе возился дома с домашней лабой на proxmox. Обновил старый nettop, который лежал без дела. Поставил в него ssd диск и 16 gb памяти. Решил добавить к кластеру proxmox. Для тестовых vm будет самое то - не шумит, мало места занимает, электричества крохи ест.
Но вот незадача. Стандартный драйвер Realtek в ядре Linux не заработал со встроенной сетевухой. Пришлось качать альтернативный и собирать его локально. Основная сложность в том, что когда не работает сеть, ты как без рук. Я уже отвык от такого режима работы. Пришлось файлы и репозитории на флешке таскать на этот nettop и вспоминать, как работать на сервере без сети.
Сначала хотел плюнуть и забить на это дело. Поставить на неттоп винду и оставить его как рабочую станцию. Но потом всё-таки решил разобраться. В итоге всё получилось. Написал статью, чтобы не забыть и другим помочь. Судя по гуглению, проблема популярная.
https://serveradmin.ru/r8169-rtl_rxtx_empty_cond-0-loop-42-delay-100/
#proxmox #ошибка
Но вот незадача. Стандартный драйвер Realtek в ядре Linux не заработал со встроенной сетевухой. Пришлось качать альтернативный и собирать его локально. Основная сложность в том, что когда не работает сеть, ты как без рук. Я уже отвык от такого режима работы. Пришлось файлы и репозитории на флешке таскать на этот nettop и вспоминать, как работать на сервере без сети.
Сначала хотел плюнуть и забить на это дело. Поставить на неттоп винду и оставить его как рабочую станцию. Но потом всё-таки решил разобраться. В итоге всё получилось. Написал статью, чтобы не забыть и другим помочь. Судя по гуглению, проблема популярная.
https://serveradmin.ru/r8169-rtl_rxtx_empty_cond-0-loop-42-delay-100/
#proxmox #ошибка
Server Admin
R8169 rtl_rxtx_empty_cond == 0 (loop: 42, delay: 100) | serveradmin.ru
[01448.532276] r8169 0000:09:00.0 enp3s0: rtl_rxtx_empty_cond == 0 (loop: 42, delay: 100). [01458.532277] r8169 0000:09:00.0 enp3s0: rtl_rxtx_empty_cond == 0 (loop: 42, delay: 100). [01468.532278]...
Продолжаю тему Zabbix. Последнее время много им занимаюсь. Но до сих пор не смог победить один глюк. После обновления одного из серверов мониторинга перестали работать Web проверки. Точнее они работают, но Zabbix Server не видит проверочной строки на сайте, хотя она там есть.
По ходу разбирательства узнал одну интересную фишку, про которую не слышал ранее. Чтобы понять, как именно Zabbix видит сайт, можно увеличить уровень логирования http poller и посмотреть всю подробную информацию в логе сервера.
Повышаем уровень логирования прямо на ходу:
После первого повышения в логе появится отладочная информация. Если повысить ещё раз:
То увидите исходный код сайта так, как его видит Zabbix. Что самое удивительное, я в коде сайта, который отражён в логе, вижу проверочную строку, но сама проверка выдаёт ошибку с сообщением о том, что искомая строка не найдена. Я и строку менял, и цифры вместо слов ставил в проверку, и какие-то тэги разметки. Ничего не помогает.
Похоже на какой-то баг, но очень хитрый. На данном сервере мониторятся 18 сайтов с разных веб серверов и только с конкретного веб сервера не работают проверки. Точнее веб сервера два, но коннекты на них идут через общий nginx proxy. Локализовать проблему так и не получилось. Сломались эти проверки после обновления на 6.0. Раньше все работали корректно.
Вернуть уровень логирования на место можно так:
Не забудьте это сделать, иначе лог будет очень быстро расти в размерах, особенно если веб проверок много.
#zabbix #ошибка
По ходу разбирательства узнал одну интересную фишку, про которую не слышал ранее. Чтобы понять, как именно Zabbix видит сайт, можно увеличить уровень логирования http poller и посмотреть всю подробную информацию в логе сервера.
Повышаем уровень логирования прямо на ходу:
# zabbix_server -R log_level_increase="http poller"После первого повышения в логе появится отладочная информация. Если повысить ещё раз:
# zabbix_server -R log_level_increase="http poller"То увидите исходный код сайта так, как его видит Zabbix. Что самое удивительное, я в коде сайта, который отражён в логе, вижу проверочную строку, но сама проверка выдаёт ошибку с сообщением о том, что искомая строка не найдена. Я и строку менял, и цифры вместо слов ставил в проверку, и какие-то тэги разметки. Ничего не помогает.
Похоже на какой-то баг, но очень хитрый. На данном сервере мониторятся 18 сайтов с разных веб серверов и только с конкретного веб сервера не работают проверки. Точнее веб сервера два, но коннекты на них идут через общий nginx proxy. Локализовать проблему так и не получилось. Сломались эти проверки после обновления на 6.0. Раньше все работали корректно.
Вернуть уровень логирования на место можно так:
# zabbix_server -R log_level_decrease="http poller"# zabbix_server -R log_level_decrease="http poller"Не забудьте это сделать, иначе лог будет очень быстро расти в размерах, особенно если веб проверок много.
#zabbix #ошибка
{kind=link}
Из личного недавнего опыта история про импорт сертификата в Windows. Вообще, эта тема очень мной нелюбимая, потому что непонятная и глючная. Решил даже статью написать, потому что знаю, многим она поможет. У меня статья с переносом сертификатов Крипто Про уже несколько лет одна из самых популярных на сайте.
Стал недоступен комп, где установлен сертификат для сервисов контура, потому что ими не пользовались давно. Но серт стал нужен, чтобы зайти в личный кабинет ИП в налоговой. У меня был бэкап в виде запароленного pfx файла с контейнером закрытого ключа и самим сертификатом в формате cer.
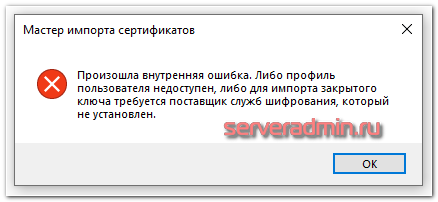
Делаю как обычно импорт и получаю неинформативную ошибку: "Произошла внутренняя ошибка. Либо профиль пользователя недоступен, либо для импорта закрытого ключа требуется поставщик служб шифрования, который не установлен." Профиль на месте, Крипто Про установлена. Я ей пользовался раньше. Не понятно, в чём проблема.
Расскажу сразу, что в итоге помогло и в чём была проблема. Либо в лицензии Крипто Про, либо в версии. Лицензия у меня давно протухла, потому что для работы с сертификатами, которые выпускает сам Контур, лицензия не нужна. Она как-то хитро зашита в сами сертификаты и когда ими пользуешься, всё работает нормально. Но вот конкретно импорт не хотел работать и давал ошибку.
Я зашел на help.kontur.ru, сделал проверку рабочего места. Проверка предложила обновить Крипто Про и установить лицензию. Сделал это и сертификат успешно установился. Потом пришлось ещё прилично повозиться, чтобы зайти в ЛК налоговой по нему, но это уже отдельная тема.
Как я рад, что уже почти не занимаюсь этими сертификатами, только своими, либо знакомым помогаю. Как вспомню все эти личные кабинеты, тендерные площадки и т.д., так сразу хочется в домике спрятаться. С ними вечно были какие-то проблемы. То не экспортируется, то проверка не проходит, то пин потеряли, то версия браузера нужна какая-то конкретная, то кто-то просит на комп его скопировать, а это небезопасно, то ещё что-то. Знал человека, который работал на должности тех. поддержки по работе с этими площадками. Он только сертификатами на работе занимался и доступами по ним.
https://serveradmin.ru/import-pfx-sertifikata-proizoshla-vnutrennyaya-oshibka/
#разное #ошибка
Стал недоступен комп, где установлен сертификат для сервисов контура, потому что ими не пользовались давно. Но серт стал нужен, чтобы зайти в личный кабинет ИП в налоговой. У меня был бэкап в виде запароленного pfx файла с контейнером закрытого ключа и самим сертификатом в формате cer.
Делаю как обычно импорт и получаю неинформативную ошибку: "Произошла внутренняя ошибка. Либо профиль пользователя недоступен, либо для импорта закрытого ключа требуется поставщик служб шифрования, который не установлен." Профиль на месте, Крипто Про установлена. Я ей пользовался раньше. Не понятно, в чём проблема.
Расскажу сразу, что в итоге помогло и в чём была проблема. Либо в лицензии Крипто Про, либо в версии. Лицензия у меня давно протухла, потому что для работы с сертификатами, которые выпускает сам Контур, лицензия не нужна. Она как-то хитро зашита в сами сертификаты и когда ими пользуешься, всё работает нормально. Но вот конкретно импорт не хотел работать и давал ошибку.
Я зашел на help.kontur.ru, сделал проверку рабочего места. Проверка предложила обновить Крипто Про и установить лицензию. Сделал это и сертификат успешно установился. Потом пришлось ещё прилично повозиться, чтобы зайти в ЛК налоговой по нему, но это уже отдельная тема.
Как я рад, что уже почти не занимаюсь этими сертификатами, только своими, либо знакомым помогаю. Как вспомню все эти личные кабинеты, тендерные площадки и т.д., так сразу хочется в домике спрятаться. С ними вечно были какие-то проблемы. То не экспортируется, то проверка не проходит, то пин потеряли, то версия браузера нужна какая-то конкретная, то кто-то просит на комп его скопировать, а это небезопасно, то ещё что-то. Знал человека, который работал на должности тех. поддержки по работе с этими площадками. Он только сертификатами на работе занимался и доступами по ним.
https://serveradmin.ru/import-pfx-sertifikata-proizoshla-vnutrennyaya-oshibka/
#разное #ошибка
{kind=link}
На днях разбирался с одной проблемой на Bitrix, читал форумы. Случайно попал в тему с жуткой историей 😱. Хотя она типичная. Человек скопировал команду и применил в терминале, но не удостоверился в том, что конкретно он делает.
История такая. Нужно было очистить директории с инвентарём и ролями ansible и скачать их заново:
Кто-то сделал это, ему помогло. Он процитировал код и прокомментировал, что ему помогло. Другой горе-администратор не заметил, что движок форума добавил пробелов в команду при цитировании и применил её в таком виде:
Как думаете, что произошло? Из-за предательских пробелов он грохнул себе всё в директории /etc/ 🙄
Вот из-за этого я никогда не пишу команды так, что их можно просто скопировать и сразу применить. Ни в Telegram, ни на сайте в статьях. Всегда добавляю # в начало. Так хоть какой-то шанс есть, что человек задумается и посмотрит, что он делает.
Вот эта тема, про которую я написал:
https://dev.1c-bitrix.ru/support/forum/forum32/topic84971/?PAGEN_1=2
Не копируйте команды напрямую в терминал. Я сначала вообще их в текстовый файл копирую, чтобы точно увидеть, что будет вставлено. А только потом уже из текстового файла в терминал. Давняя привычка.
#ошибка #совет
История такая. Нужно было очистить директории с инвентарём и ролями ansible и скачать их заново:
# rm -rf /etc/ansible/host* /etc/ansible/group_vars/ /etc/ansible/ansible-rolesКто-то сделал это, ему помогло. Он процитировал код и прокомментировал, что ему помогло. Другой горе-администратор не заметил, что движок форума добавил пробелов в команду при цитировании и применил её в таком виде:
# rm -rf /etc/ansible/host* /etc/ ansible/group_vars/ /etc/ ansible/ansible-rolesКак думаете, что произошло? Из-за предательских пробелов он грохнул себе всё в директории /etc/ 🙄
Вот из-за этого я никогда не пишу команды так, что их можно просто скопировать и сразу применить. Ни в Telegram, ни на сайте в статьях. Всегда добавляю # в начало. Так хоть какой-то шанс есть, что человек задумается и посмотрит, что он делает.
Вот эта тема, про которую я написал:
https://dev.1c-bitrix.ru/support/forum/forum32/topic84971/?PAGEN_1=2
Не копируйте команды напрямую в терминал. Я сначала вообще их в текстовый файл копирую, чтобы точно увидеть, что будет вставлено. А только потом уже из текстового файла в терминал. Давняя привычка.
#ошибка #совет
Расскажу вам про решение проблемы с Openvpn Client на Windows, которая меня донимала последний год примерно, может чуть меньше. Вчера терпение лопнуло и я разобрался с ней раз и навсегда.
Проблема плавающая и выражалась она в том, что время от времени одно из настроенных подключений openvpn не подключалось. Ошибка была примерно такая:
Ошибка возникала случайным образом на различных соединениях.
По тексту не очень понятно, в чём дело. Первое, что приходит в голову - указанный порт уже кем-то занят. Но netstat показывает, что ничего не занято. При этом любое другое подключение openvpn сработает нормально. А какое-то одно ни в какую. У меня около 5-ти подключений используется в разное время. Помогает только перезагрузка. Несколько раз пытался разобраться, но так как ошибка не очень информативна, быстро решить вопрос не получалось. Спасала банальная перезагрузка. Я думал, что она возможно как-то связана с тем, что у меня добавлено несколько сетевых интерфейсов для openvpn, а в дефолте обычно только одно устанавливается.
Дело вот в чём. После какого-то обновления Windows, она стала резервировать некоторые диапазоны портов для работы Hyper-V. Посмотреть эти диапазоны можно командой:
И как оказалось, там есть диапазон локальных портов, который пересекается с диапазоном, который использует OpenVPN. Решение вопроса - изменить его в OpenVPN GUI:
Settings ⇨ Advanced ⇨ Management interface ⇨ Port offset.
После этого проблема исчезла.
Такая вот ерунда сожрала кучу моего времени. В логах самой винды никакой информации нет. По логу openvpn невозможно понять, в чём дело. А оказывается винда каким-то своим механизмом бронирует целые диапазоны портов и не даёт их использовать. При этом никак в системе не помечает их занятыми, иначе бы ошибка была другая. Что-то в духе
#openvpn #windows #ошибка
Проблема плавающая и выражалась она в том, что время от времени одно из настроенных подключений openvpn не подключалось. Ошибка была примерно такая:
MANAGEMENT: Socket bind failed on local address [AF_INET]127.0.0.1:25349Ошибка возникала случайным образом на различных соединениях.
По тексту не очень понятно, в чём дело. Первое, что приходит в голову - указанный порт уже кем-то занят. Но netstat показывает, что ничего не занято. При этом любое другое подключение openvpn сработает нормально. А какое-то одно ни в какую. У меня около 5-ти подключений используется в разное время. Помогает только перезагрузка. Несколько раз пытался разобраться, но так как ошибка не очень информативна, быстро решить вопрос не получалось. Спасала банальная перезагрузка. Я думал, что она возможно как-то связана с тем, что у меня добавлено несколько сетевых интерфейсов для openvpn, а в дефолте обычно только одно устанавливается.
Дело вот в чём. После какого-то обновления Windows, она стала резервировать некоторые диапазоны портов для работы Hyper-V. Посмотреть эти диапазоны можно командой:
# netsh int ipv4 show excludedportrange tcpИ как оказалось, там есть диапазон локальных портов, который пересекается с диапазоном, который использует OpenVPN. Решение вопроса - изменить его в OpenVPN GUI:
Settings ⇨ Advanced ⇨ Management interface ⇨ Port offset.
После этого проблема исчезла.
Такая вот ерунда сожрала кучу моего времени. В логах самой винды никакой информации нет. По логу openvpn невозможно понять, в чём дело. А оказывается винда каким-то своим механизмом бронирует целые диапазоны портов и не даёт их использовать. При этом никак в системе не помечает их занятыми, иначе бы ошибка была другая. Что-то в духе
local address [AF_INET]127.0.0.1:25349 is busy. А тут просто ошибка, которая говорит о том, что сокет не поднимается. Причин этому может быть много. Банальная нехватка прав или что-то ещё.#openvpn #windows #ошибка
Расскажу вам небольшую историю про расследование внезапной перезагрузки сервера, которая вывела меня на самого себя. Попутно я наполню статью командами, которые конкретно мне не помогли, но могут пригодиться в похожей ситуации, чтобы статья получилась полезной шпаргалкой.
Случайно заметил, что один гипервизор Proxmox недавно перезагрузился. Причём это закрытый контур и доступ к нему сильно ограничен. Перезагрузка гипервизора всегда нештатная ситуация и просто так не делается. Более того, сам я редко их перезагружаю, только для необходимых обновлений. Ещё и время странное было — 2:17 ночи. Я сразу как-то напрягся.
Стал вспоминать, что я делал в тот день. Вспомнил, что работал с виртуалками на этом гипервизоре. Их как раз обновлял и перезагружал. Пошёл проверять мониторинг и заметил, что в нём перезагрузка гипервизора отражена. Но так как в тот день было много перезагрузок серверов, я не обратил на это внимание, а когда закончил работы, все сообщения мониторинга от этого сервера пометил прочитанными.
Первым делом пошёл в консоль гипервизора и посмотрел системный лог /var/log/syslog. Там как минимум увидел, что перезагрузка была штатная. Но в логе вообще никаких намёков на то, почему она произошла и кто её инициировал. Просто начали останавливаться службы. Если перезагрузка аварийная, или инициирована нажатием кнопки питания, то об этом в логе информация есть. Значит тут причина не в этом.
Далее я сразу же посмотрел лог SSH соединений в /var/log/auth.log. Увидел там авторизацию рутом, причём с IP адреса VPN сети. Проверил IP адрес — мой. Тут я немного расслабился, но до сих пор не понимал, что происходит. Запустил ещё пару команд для информации о последней перезагрузке:
Тут я начал понимать, что происходит. Проверил у себя в SSH клиенте лог подключений. Я одно время записывал содержимое всех сессий, но потом отключил, потому что хранится всё это в открытом виде. А в логе сессий много чувствительной информации. Решил, что лучше её не собирать. Да и нужно очень редко.
Глянул на сервере историю команд:
Тут уже всё понял. В общем, под конец работ, уже ночью, я перепутал сервера. И вместо очередной виртуальной машины обновил и перезагрузил гипервизор. Причём это была виртуалка дублёр без полезного функционала. Я просто зашёл и на автомате обновил. У неё было похожее имя с гипервизором.❗️Это, кстати, важный момент. Всегда следите за названиями серверов. Что самое интересное, когда я настроил этот сервер, по какой-то причине не смог нормально проименовать все виртуалки. Не придумал удобную схему и сделал в лоб. Получилось плохо. Я сразу это заметил, но стало лень переделывать, так как настроил мониторинг, сбор логов, документацию. В итоге это сыграло со мной злую шутку.
Ну и в целом ночью устаёшь уже. Это существенный минус работы в IT. Периодически приходится что-то делать ночью. Я очень это не люблю, но полностью обойтись без ночных работ не получается. Я на ночь специально не откладываю, стараюсь хотя бы вечером всё сделать. Но не всегда получается.
Ещё полезные команды по теме:
#linux #ошибка
Случайно заметил, что один гипервизор Proxmox недавно перезагрузился. Причём это закрытый контур и доступ к нему сильно ограничен. Перезагрузка гипервизора всегда нештатная ситуация и просто так не делается. Более того, сам я редко их перезагружаю, только для необходимых обновлений. Ещё и время странное было — 2:17 ночи. Я сразу как-то напрягся.
Стал вспоминать, что я делал в тот день. Вспомнил, что работал с виртуалками на этом гипервизоре. Их как раз обновлял и перезагружал. Пошёл проверять мониторинг и заметил, что в нём перезагрузка гипервизора отражена. Но так как в тот день было много перезагрузок серверов, я не обратил на это внимание, а когда закончил работы, все сообщения мониторинга от этого сервера пометил прочитанными.
Первым делом пошёл в консоль гипервизора и посмотрел системный лог /var/log/syslog. Там как минимум увидел, что перезагрузка была штатная. Но в логе вообще никаких намёков на то, почему она произошла и кто её инициировал. Просто начали останавливаться службы. Если перезагрузка аварийная, или инициирована нажатием кнопки питания, то об этом в логе информация есть. Значит тут причина не в этом.
Далее я сразу же посмотрел лог SSH соединений в /var/log/auth.log. Увидел там авторизацию рутом, причём с IP адреса VPN сети. Проверил IP адрес — мой. Тут я немного расслабился, но до сих пор не понимал, что происходит. Запустил ещё пару команд для информации о последней перезагрузке:
# who -b system boot 2023-07-14 02:17# last -x | headroot pts/0 10.20.140.6 Mon Jul 17 11:24 still logged inrunlevel (to lvl 5) 5.15.39-3-pve Fri Jul 14 02:17 still runningreboot system boot 5.15.39-3-pve Fri Jul 14 02:17 still runningshutdown system down 5.15.39-3-pve Fri Jul 14 02:16 - 02:17 (00:00)root pts/0 10.20.140.6 Fri Jul 14 00:58 - down (01:17)Тут я начал понимать, что происходит. Проверил у себя в SSH клиенте лог подключений. Я одно время записывал содержимое всех сессий, но потом отключил, потому что хранится всё это в открытом виде. А в логе сессий много чувствительной информации. Решил, что лучше её не собирать. Да и нужно очень редко.
Глянул на сервере историю команд:
# history 380 apt update 381 apt upgrade 382 w 383 rebootТут уже всё понял. В общем, под конец работ, уже ночью, я перепутал сервера. И вместо очередной виртуальной машины обновил и перезагрузил гипервизор. Причём это была виртуалка дублёр без полезного функционала. Я просто зашёл и на автомате обновил. У неё было похожее имя с гипервизором.❗️Это, кстати, важный момент. Всегда следите за названиями серверов. Что самое интересное, когда я настроил этот сервер, по какой-то причине не смог нормально проименовать все виртуалки. Не придумал удобную схему и сделал в лоб. Получилось плохо. Я сразу это заметил, но стало лень переделывать, так как настроил мониторинг, сбор логов, документацию. В итоге это сыграло со мной злую шутку.
Ну и в целом ночью устаёшь уже. Это существенный минус работы в IT. Периодически приходится что-то делать ночью. Я очень это не люблю, но полностью обойтись без ночных работ не получается. Я на ночь специально не откладываю, стараюсь хотя бы вечером всё сделать. Но не всегда получается.
Ещё полезные команды по теме:
# journalctl --list-boots# journalctl -b 0# last reboot#linux #ошибка
Недавно очень крупно ошибся из-за невнимательности. Нужно было купить небольшой дедик под веб сервер, настроить и перенести туда сайты. И я жёстко ошибся с размерами дисков самого сервера и виртуалки, что доставило много хлопот на ровном месте. Расскажу обо всём по порядку.
Арендовал сервер с двумя SSD дисками 480 ГБ по описанию сервера. Автоматом выбрал шаблон Proxmox VE с mdadm в RAID1 и сразу получил настроенный гипервизор. Стандартный шаблон предлагает простую разбивку: 1 ГБ на /boot, 5 ГБ на swap и остальное на корень системы. Не стал ничего менять, оставил как есть.
Развернул гипервизор, быстро сделал некоторые настройки. На диски вообще не смотрел. Создал виртуалку с диском 450 ГБ типа qcow2 и дальше начал с ней работать. В голове прикинул, что диски 480 ГБ, система примерно 5 ГБ. Других виртуалок не будет. В целом нормально.
Всё настроил, данные закинул. Повозил их туда-сюда по серверу. Приходит уведомление от мониторинга, что на гипервизоре заканчивается место на диске. Причём там занято уже 98% было, на виртуалке реальных данных - 300 ГБ. Удивился. Захожу на гипервизор, смотрю. Там раздел под корень диска по факту вышел всего 440 ГБ. То есть заявленные характеристики диска 480 ГБ в реальном размере это 446 ГБ: 1 на /boot, 5 на swap, 440 на корень.
Тут я сразу понял всю глубину своей ошибки, так как простого решения у неё нет, кроме очередного переноса. Причём просто так не переедешь на другой гипервизор без перенастройки виртуалки. Следующая градация дисков на сервере для аренды - 960 ГБ, что почти в 2 раза дороже, но реально такой объём не нужен. А на диски 480 ГБ эта виртуалки уже не переедет.
Такая вот ошибка из-за невнимательности. Поторопился и не проверил. Даже мысли не возникло на эту тему, хотя всем известно, что объём диска из описания не соответствует реальному.
Но благодаря этой ошибке я придумал полную техническую реализацию исправления. Узнал некоторые вещи, о существовании которых даже не слышал. Кое-что потестил и проверил, как работает. Вечером отдельно всё расскажу с техническими подробностями. На самом деле всё можно ужать и вернуть в доступный объём. Для этого надо:
1️⃣ Уменьшить файловую систему на виртуалке.
2️⃣ Уменьшить размер раздела диска в виртуалке.
3️⃣ Уменьшить размер qcow2 файла.
Каждая из операций потенциально опасная, к тому же на виртуалке раздел один и он корень, отмонтировать на лету и ужать его не получится. Но решение есть.
#ошибка
Арендовал сервер с двумя SSD дисками 480 ГБ по описанию сервера. Автоматом выбрал шаблон Proxmox VE с mdadm в RAID1 и сразу получил настроенный гипервизор. Стандартный шаблон предлагает простую разбивку: 1 ГБ на /boot, 5 ГБ на swap и остальное на корень системы. Не стал ничего менять, оставил как есть.
Развернул гипервизор, быстро сделал некоторые настройки. На диски вообще не смотрел. Создал виртуалку с диском 450 ГБ типа qcow2 и дальше начал с ней работать. В голове прикинул, что диски 480 ГБ, система примерно 5 ГБ. Других виртуалок не будет. В целом нормально.
Всё настроил, данные закинул. Повозил их туда-сюда по серверу. Приходит уведомление от мониторинга, что на гипервизоре заканчивается место на диске. Причём там занято уже 98% было, на виртуалке реальных данных - 300 ГБ. Удивился. Захожу на гипервизор, смотрю. Там раздел под корень диска по факту вышел всего 440 ГБ. То есть заявленные характеристики диска 480 ГБ в реальном размере это 446 ГБ: 1 на /boot, 5 на swap, 440 на корень.
Тут я сразу понял всю глубину своей ошибки, так как простого решения у неё нет, кроме очередного переноса. Причём просто так не переедешь на другой гипервизор без перенастройки виртуалки. Следующая градация дисков на сервере для аренды - 960 ГБ, что почти в 2 раза дороже, но реально такой объём не нужен. А на диски 480 ГБ эта виртуалки уже не переедет.
Такая вот ошибка из-за невнимательности. Поторопился и не проверил. Даже мысли не возникло на эту тему, хотя всем известно, что объём диска из описания не соответствует реальному.
Но благодаря этой ошибке я придумал полную техническую реализацию исправления. Узнал некоторые вещи, о существовании которых даже не слышал. Кое-что потестил и проверил, как работает. Вечером отдельно всё расскажу с техническими подробностями. На самом деле всё можно ужать и вернуть в доступный объём. Для этого надо:
1️⃣ Уменьшить файловую систему на виртуалке.
2️⃣ Уменьшить размер раздела диска в виртуалке.
3️⃣ Уменьшить размер qcow2 файла.
Каждая из операций потенциально опасная, к тому же на виртуалке раздел один и он корень, отмонтировать на лету и ужать его не получится. Но решение есть.
#ошибка