
Недавно к одной заметке про мониторинг содержимого сайта в комментариях скинули ссылку на обсуждение в stackoverflow тему парсинга HTML с помощью RegEx. Я сначала начал читать, не понял, в чём тут соль. Какая-то 14-ти летняя публикация, где не совсем понятно, о чём идёт речь. Потом немного вник в текст и прифигел от содержимого. Я так понял, это обсуждение заморозили и оставили на память потомкам в неизменном виде. Решил перевести сообщение и поделиться с вами.
⇨ https://stackoverflow.com/questions/1732348/
Вы не сможете парсить [X]HTML с помощью regex. Это не подходящий инструмент для подобного парсинга. Regex не сможет нормально распарсить HTML. Я уже неоднократно отвечал на вопросы по HTML и регулярным выражениям, использование регулярных выражений не позволит вам обрабатывать HTML. Регулярные выражения - это инструмент, который недостаточно гибок для распознавания конструкций, используемых в HTML. HTML не является обычным языком и, следовательно, не может быть проанализирован с помощью регулярных выражений. Регулярки не предназначены для извлечения значений из HTML. Даже усовершенствованные регулярные выражения, используемые в Perl, не справляются с задачей синтаксического анализа HTML. Вы никогда не убедите меня в обратном. HTML - язык настолько сложный, что его невозможно разобрать с помощью регулярных выражений. Даже Джон Скит не может разобрать HTML с помощью регулярных выражений. Каждый раз, когда вы пытаетесь разобрать HTML с помощью регулярных выражений, нечестивое дитя проливает кровь девственниц, а русские хакеры взламывают ваше веб-приложение. Разбор HTML с помощью регулярных выражений вызывает нечестивые души в мир живых. HTML и regex сочетаются так же, как любовь, брак и ритуальное детоубийство. <center> не может удержаться, уже слишком поздно. Сочетание регулярных выражений и HTML в одном концептуальном пространстве разрушит ваш разум, как жидкая шпатлёвка. Если вы парсите HTML с помощью регулярных выражений, вы поддаетесь Им и их богохульным способам, которые обрекают всех нас на нечеловеческий труд, ибо Тот, чье Имя невозможно выразить на Базовом многоязычном уровне, приходит. HTML-plus-regexp разрушает нервы любого живого существа. Пока вы будете наблюдать за этим, ваша психика будет изнемогать под натиском ужаса. HTML-анализаторы на основе регулярных выражений - это раковая опухоль, которая убивает StackOverflow, уже слишком поздно, слишком поздно, нас не спасти, проступок неразумного гарантирует, что регулярное выражение поглотит всю живую материю (за исключением HTML, который ему не под силу, как было сказано ранее) дорогой Господь, помоги нам, как можно пережить это бедствие, тот, кто использует регулярные выражение для парсинга HTML обрек человечество на вечность ужасных пыток и дыр в системе безопасности, использование regex в качестве инструмента для обработки HTML создает брешь между этим миром и ужасным царством повреждённых данных (таких как записи SGML, но еще более испорченные) простой взгляд на мир анализаторов регулярных выражений для HTML мгновенно перенесет сознание программиста в мир непрекращающихся криков: "он приходит", "зараза опасных регулярных выражений" поглотит ваш HTML-парсер, приложение и само существование навсегда, как Visual Basic, только хуже, он приходит, он приходит, не сопротивляйся, он приходит, его нечестивое сияние разрушает всё просветление, HTML-теги текут из твоих глаз, как жидкая боль., песня регулярных выражений для парсинга будет гасить голоса смертного человека из сферы, я вижу это, ты видишь это,î̩́t̲͎̩̱͔́̋̀ it is beautiful t he f
Конец уже не стал переводить 😁
#юмор
⇨ https://stackoverflow.com/questions/1732348/
Вы не сможете парсить [X]HTML с помощью regex. Это не подходящий инструмент для подобного парсинга. Regex не сможет нормально распарсить HTML. Я уже неоднократно отвечал на вопросы по HTML и регулярным выражениям, использование регулярных выражений не позволит вам обрабатывать HTML. Регулярные выражения - это инструмент, который недостаточно гибок для распознавания конструкций, используемых в HTML. HTML не является обычным языком и, следовательно, не может быть проанализирован с помощью регулярных выражений. Регулярки не предназначены для извлечения значений из HTML. Даже усовершенствованные регулярные выражения, используемые в Perl, не справляются с задачей синтаксического анализа HTML. Вы никогда не убедите меня в обратном. HTML - язык настолько сложный, что его невозможно разобрать с помощью регулярных выражений. Даже Джон Скит не может разобрать HTML с помощью регулярных выражений. Каждый раз, когда вы пытаетесь разобрать HTML с помощью регулярных выражений, нечестивое дитя проливает кровь девственниц, а русские хакеры взламывают ваше веб-приложение. Разбор HTML с помощью регулярных выражений вызывает нечестивые души в мир живых. HTML и regex сочетаются так же, как любовь, брак и ритуальное детоубийство. <center> не может удержаться, уже слишком поздно. Сочетание регулярных выражений и HTML в одном концептуальном пространстве разрушит ваш разум, как жидкая шпатлёвка. Если вы парсите HTML с помощью регулярных выражений, вы поддаетесь Им и их богохульным способам, которые обрекают всех нас на нечеловеческий труд, ибо Тот, чье Имя невозможно выразить на Базовом многоязычном уровне, приходит. HTML-plus-regexp разрушает нервы любого живого существа. Пока вы будете наблюдать за этим, ваша психика будет изнемогать под натиском ужаса. HTML-анализаторы на основе регулярных выражений - это раковая опухоль, которая убивает StackOverflow, уже слишком поздно, слишком поздно, нас не спасти, проступок неразумного гарантирует, что регулярное выражение поглотит всю живую материю (за исключением HTML, который ему не под силу, как было сказано ранее) дорогой Господь, помоги нам, как можно пережить это бедствие, тот, кто использует регулярные выражение для парсинга HTML обрек человечество на вечность ужасных пыток и дыр в системе безопасности, использование regex в качестве инструмента для обработки HTML создает брешь между этим миром и ужасным царством повреждённых данных (таких как записи SGML, но еще более испорченные) простой взгляд на мир анализаторов регулярных выражений для HTML мгновенно перенесет сознание программиста в мир непрекращающихся криков: "он приходит", "зараза опасных регулярных выражений" поглотит ваш HTML-парсер, приложение и само существование навсегда, как Visual Basic, только хуже, он приходит, он приходит, не сопротивляйся, он приходит, его нечестивое сияние разрушает всё просветление, HTML-теги текут из твоих глаз, как жидкая боль., песня регулярных выражений для парсинга будет гасить голоса смертного человека из сферы, я вижу это, ты видишь это,î̩́t̲͎̩̱͔́̋̀ it is beautiful t he f
inal snuffing of the lies of Man ALL IS LOŚ͖̩͇̗̪̏̈́T ALL IS LOST the pon̷y he comes he c̶̮omes he comes the ichor permeates all MY FACE MY FACE ᵒh god no NO NOO̼OO NΘ stop the an*̶͑̾̾̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̟̍ͫͥͨe̠̅s ͎a̧͈͖r̽̾̈́͒͑ not rè̑ͧ̌aͨl̘̝̙̃ͤ͂̾̆ ZA̡͊͠͝LGΌ ISͮ̂҉̯͈͕̹̘̱ TeO͇̹̺ͅƝ̴ȳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝эS̨̥̫͎̭ͯ̔̀ͅКонец уже не стал переводить 😁
#юмор
{kind=link}
🎓 Давно ничего не было на тему обучения. Я раньше старался об этом писать по выходным. Все хорошие полезные обучающие материалы я уже обозревал ранее. Для тех, кто пропустил, рекомендую мою подборку, где собрал в единый список известные мне бесплатные курсы и материалы, которые можно посоветовать для базового изучения тем, кто хочет начать движение в сторону системного администрирования Linux и DevOps от простого к сложному.
Это была одна из самых популярных публикаций за прошлый год:
💥 https://t.me/srv_admin/3345
Недавно один подписчик поделился полезной ссылкой, с которой я не знаком:
⇨ Learn the ways of Linux-fu, for free
Это серия хорошо оформленных и структурированных курсов по основам Linux в виде уроков с заданиями, ответы на которые проверяются автоматически. Исходный язык курсов - английский. На сайте заявлен и русский, но там перевод автоматический. Выглядит ужасно, так что не стоит внимания.
В уроках разобраны базовые темы:
◽Командная строка
◽Обработка текста
◽Управление пользователями и правами
◽Управление процессами
◽Управление пакетами
◽Различные устройства в Linux
◽Загрузка системы
◽Файловые системы
◽Ядро Linux
◽Логирование
◽Различные уроки по сетям
и .т.д
В общем, там база. Интересно будет только тем, кто осваивает Linux. Там навигация удобная. Если что, можно быстро подсмотреть какую-то тему.
Спасибо всем, кто мне присылает что-то полезное. Я всё смотрю, записываю, но не всё попадает в публикации. Очень много тем для заметок, большой список для будущих публикаций. Что-то там просто теряется и может найтись только через год. Много таких примеров было.
А ещё мне очень интересно. Кто-нибудь проходит бесплатные курсы? Публикации с ними всегда получают очень много сохранений и репостов. Как-будто все прям хотят или имеют потребность в учёбе. А на практике это кто-нибудь делает? Я вот честно скажу, из бесплатного почти ничего не проходил системно. На Stepik что-то начинал, но полностью не помню, чтобы прошёл. Исключение - бесплатный курс про Python. Собрался и осилил его полностью. Он даже с онлайн лекциями был. Какого-то простого бота написал, но всё забросил и в итоге не пригодилось. Хотя пайтоновский код нормально читаю и могу что-то править. Но это я и без курса мог.
#обучение
Это была одна из самых популярных публикаций за прошлый год:
💥 https://t.me/srv_admin/3345
Недавно один подписчик поделился полезной ссылкой, с которой я не знаком:
⇨ Learn the ways of Linux-fu, for free
Это серия хорошо оформленных и структурированных курсов по основам Linux в виде уроков с заданиями, ответы на которые проверяются автоматически. Исходный язык курсов - английский. На сайте заявлен и русский, но там перевод автоматический. Выглядит ужасно, так что не стоит внимания.
В уроках разобраны базовые темы:
◽Командная строка
◽Обработка текста
◽Управление пользователями и правами
◽Управление процессами
◽Управление пакетами
◽Различные устройства в Linux
◽Загрузка системы
◽Файловые системы
◽Ядро Linux
◽Логирование
◽Различные уроки по сетям
и .т.д
В общем, там база. Интересно будет только тем, кто осваивает Linux. Там навигация удобная. Если что, можно быстро подсмотреть какую-то тему.
Спасибо всем, кто мне присылает что-то полезное. Я всё смотрю, записываю, но не всё попадает в публикации. Очень много тем для заметок, большой список для будущих публикаций. Что-то там просто теряется и может найтись только через год. Много таких примеров было.
А ещё мне очень интересно. Кто-нибудь проходит бесплатные курсы? Публикации с ними всегда получают очень много сохранений и репостов. Как-будто все прям хотят или имеют потребность в учёбе. А на практике это кто-нибудь делает? Я вот честно скажу, из бесплатного почти ничего не проходил системно. На Stepik что-то начинал, но полностью не помню, чтобы прошёл. Исключение - бесплатный курс про Python. Собрался и осилил его полностью. Он даже с онлайн лекциями был. Какого-то простого бота написал, но всё забросил и в итоге не пригодилось. Хотя пайтоновский код нормально читаю и могу что-то править. Но это я и без курса мог.
#обучение
{kind=link}
Стал регулярно сталкиваться с одной проблемой. Есть сервер с бюджетными SSD дисками. Они для многих задач вполне подходят, несмотря на низкую стоимость и скорость записи. Последнее как раз их узкое место. Но если у вас в основном с дисков чтение, то можно существенно экономить, используя десктопные диски.
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
Ограничил скорость записи в 20 MiB/s через ключ
Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
# apt install pv# mysqldump --opt -v --single-transaction --databases db01 | pv -L 20m > /mnt/backup/db01.sqlОграничил скорость записи в 20 MiB/s через ключ
-L. Для того, чтобы посмотреть текущую скорость записи, используйте pv без ограничения:# mysqldump --opt -v --single-transaction --databases db01 | pv > /mnt/backup/db01.sql............................ 1319MiB 0:00:06 [ 205MiB/s]Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
Я тут такой классный сервис увидел в полезных ссылках одного сайта:
⇨ https://distrosea.com
Даже удивился, как это я про него раньше не слышал. Поискал по своему каналу и чату и увидел, что его ещё в ноябре кто-то посоветовал.
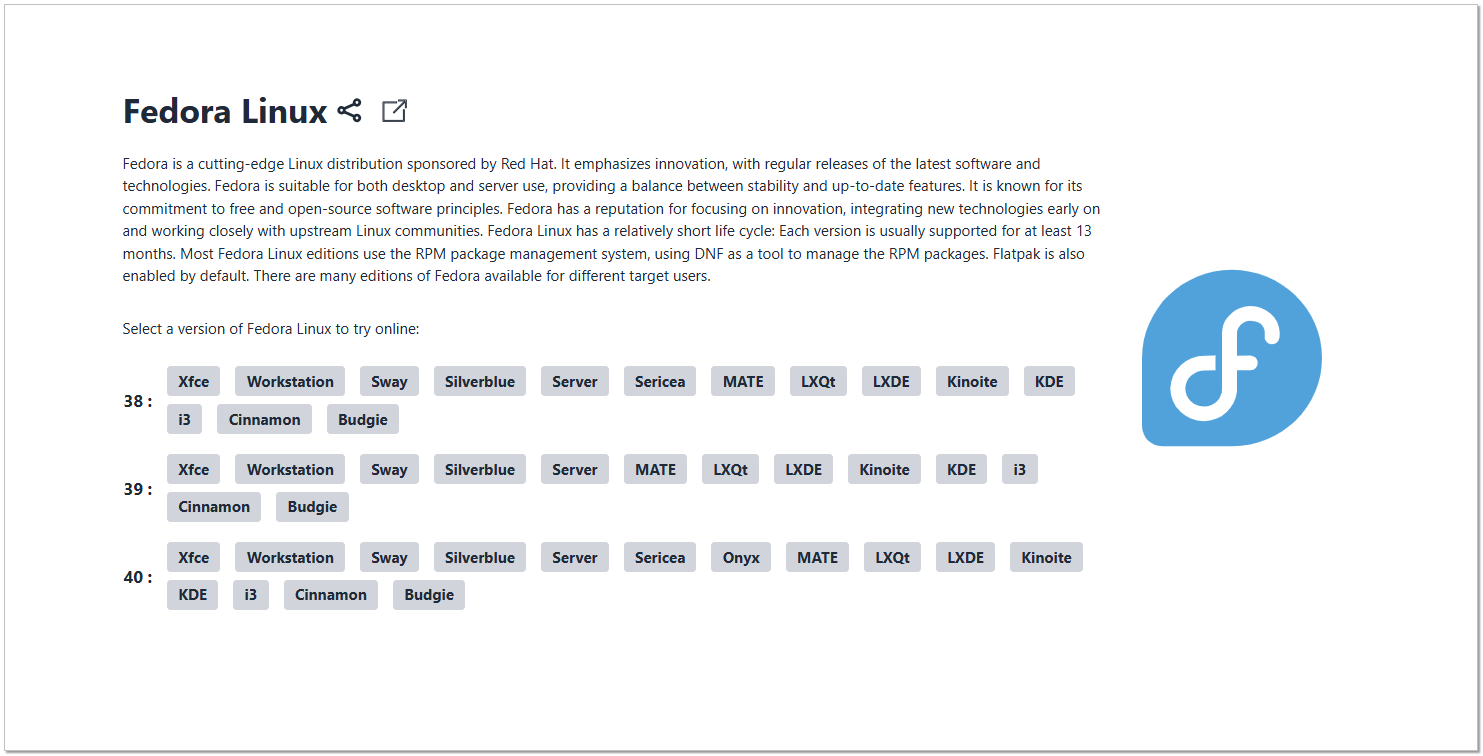
На этом сайте можно прямо в браузере протестировать различные версии операционных систем Linux и некоторые *BSD. Причём системы доступны с различными графическими оболочками. Можно в браузере быстро посмотреть, что тебе больше нравится.
Выбор дистрибутивов и оболочек очень большой. Пример для Fedora можно увидеть на прикреплённой картинке. Системы все без доступа в интернет. Я первым делом проверил это. Думаю, было бы круто, если бы там ещё и сёрфить в интернете можно было бы на них. Но нет. Запущены они, если я правильно понял, с LiveCD, физических дисков у них тоже нет.
#полезное
⇨ https://distrosea.com
Даже удивился, как это я про него раньше не слышал. Поискал по своему каналу и чату и увидел, что его ещё в ноябре кто-то посоветовал.
На этом сайте можно прямо в браузере протестировать различные версии операционных систем Linux и некоторые *BSD. Причём системы доступны с различными графическими оболочками. Можно в браузере быстро посмотреть, что тебе больше нравится.
Выбор дистрибутивов и оболочек очень большой. Пример для Fedora можно увидеть на прикреплённой картинке. Системы все без доступа в интернет. Я первым делом проверил это. Думаю, было бы круто, если бы там ещё и сёрфить в интернете можно было бы на них. Но нет. Запущены они, если я правильно понял, с LiveCD, физических дисков у них тоже нет.
#полезное
{kind=link}
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
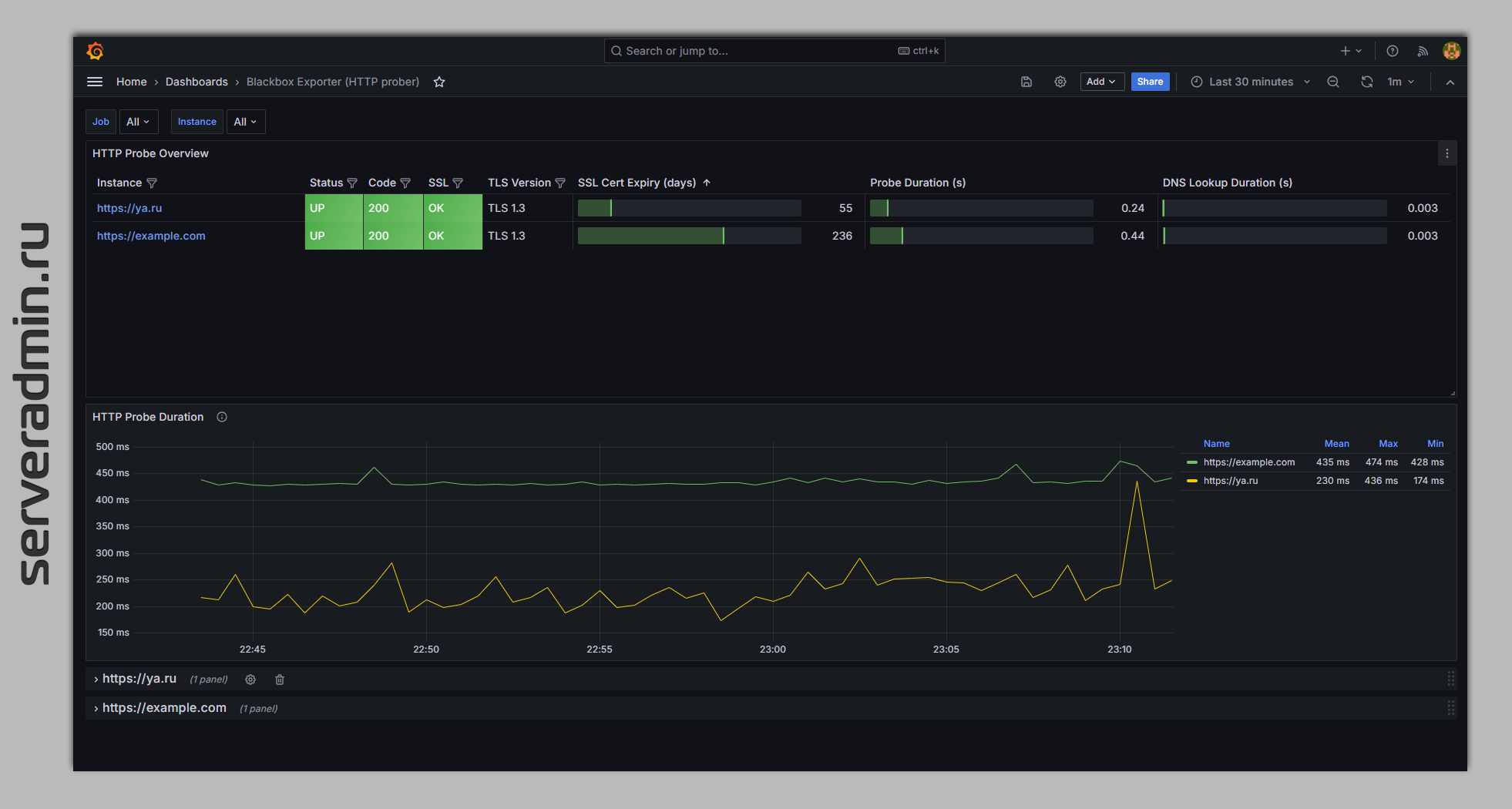
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}
prometheus+grafana+alertmanager+blackbox.zip
36.8 KB
Для того, чтобы публикация не зависела от внешних сервисов, прикрепляю все файлы от заметки выше сюда.
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
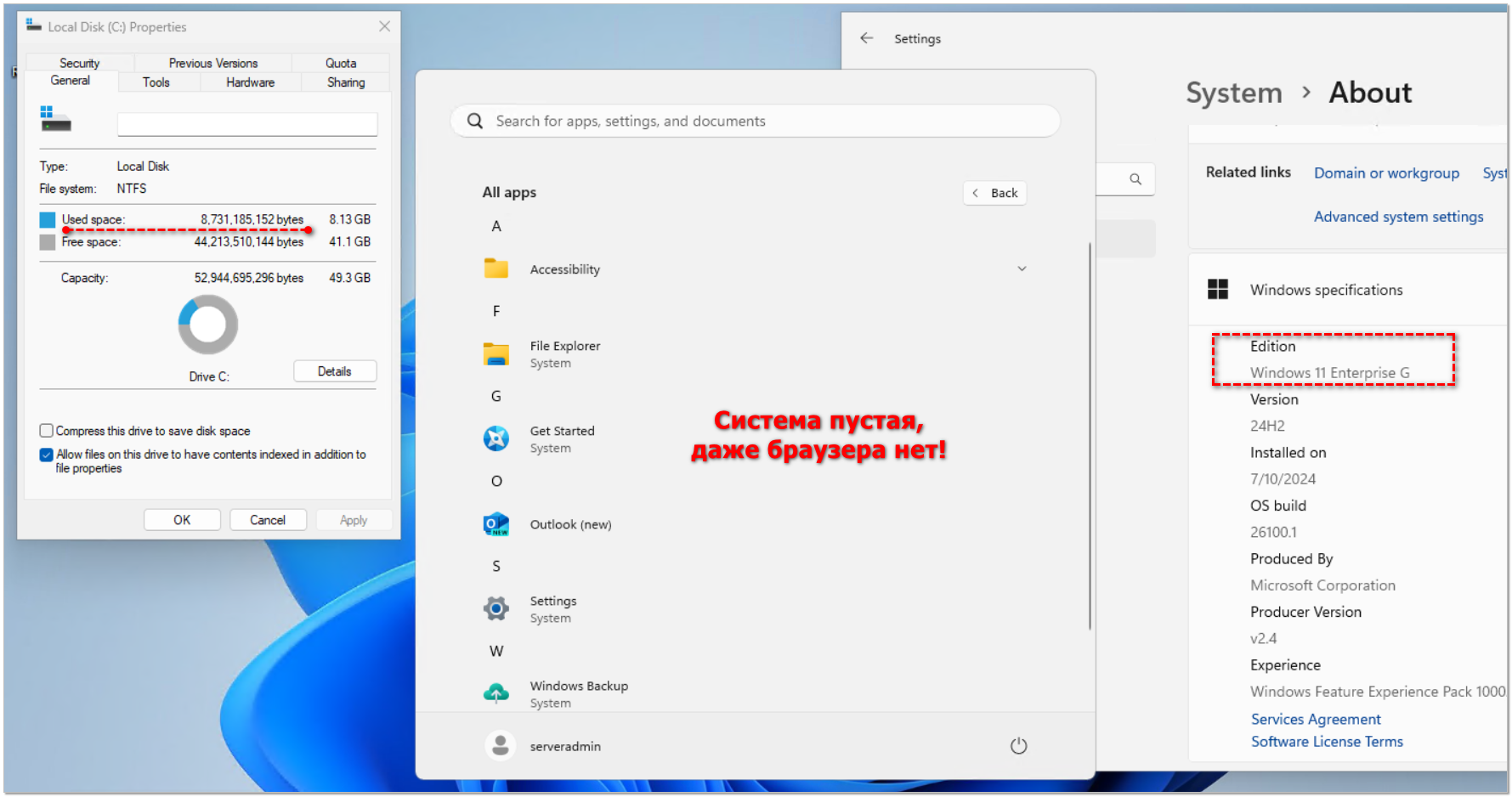
Пару недель назад по новостям проскочила информация об операционной системе Windows 11 Enterprise G. Я мельком прочитал, не вдаваясь в подробности, но заинтересовался. И только вчера нашёл время, чтобы во всём разобраться, проверить, в том числе как сделать самостоятельно образ. В итоге всё сделал, развернул у себя и потестировал. Сразу скажу, что это винда здорового человека, которая полностью рабочая, официальная, без твиков и изменений, и при этом в ней ничего лишнего. Расскажу обо всём по порядку.
В основе моего рассказа будет информация из статьи на хабре:
⇨ Windows 11 Enterprise G – Что за издание для правительства Китая и зачем оно вам?
📌 Основные особенности систем Windows 10 и Windows 11 Enterprise G:
🔹Выпускаются для китайского госсектора, удовлетворяя всем требованием китайского регулятора.
🔹Из этой версии вырезаны телеметрия, защитник, кортана, магазин, UWP приложения, браузер edge и многое другое.
🔹Доступна только на китайском и английском языках, но есть возможность обходным путём добавить русский.
🔹Система основана на редакции Professional. Подготовить образ Enterprise G можно самостоятельно на основе предоставляемых Microsoft инструментов, в частности ProductPolicy.
🔹Система нормально эксплуатируется, обновляется. То есть она полноценная, просто без лишнего софта, который не имеет отношения непосредственно к ОС.
Благодаря тому, что в системе нет практически ничего лишнего, она потребляет меньше оперативной памяти, меньше нагружает диск. Возможно и на HDD нормально заработает. После чистой установки занимает 8Гб на диске. После установки всех обновлений - 10,7Гб. Это я очистку не запускал. Просто всё обновил через параметры и посмотрел занимаемый объём.
В статье на хабре дана инструкция по созданию своего образа. Она очень запутанная, читается тяжело. Автор некоторые вещи повторяет, имена некоторых файлов не совпадают с тем, что можно скачать и т.д. Для того, кто не занимается сборкой своих образов, разобраться будет непросто, но реально. Я осилил благодаря в том числе комментариям, там есть пояснения.
У меня получилось собрать модифицированный install.wim по инструкции автора. Она рабочая, если ничего не напутать. Проблема в том, что оригинальная версия требует Secure Boot и TPM. Это тоже можно решить в своём образе, но мне в итоге надоело этим заниматься. Для теста я взял готовую сборку от автора статьи, где всё это уже решено. Она лежит на каком-то иностранном файлообменнике (❗️использовать на свой страх и риск):
⇨ https://mega.nz/folder/Id50xJBQ#JvuG3GOi0yoWyAV5JFD1gw
В директории ISO несколько готовых образов разных версий систем. Я взял вроде бы самую свежую 26100. Не очень разбираюсь в этой нумерации. Развернул у себя в тестовом Proxmox. Всё встало без проблем. Когда спросили ключ активации, сказал, что у меня его нет. После установки проверил обновления. Скачались и установились.
Система очень понравилась. Представьте, что это что-то вроде WinXP, где нет ничего лишнего, только это Win11. В разделе приложений пустота, нет даже браузера. Никаких ножниц, пейнтов и т.д. Всё это можно вручную поставить, если надо будет.
Оставил себе для теста эту виртуалку. У меня постоянно используются несколько тестовых вирталок с виндой для различных нужд. Если всё в порядке будет, переведу их тоже на эту версию.
Редакцию Enterprise G можно сделать для архитектуры x86. На текущий момент это будет идеальная современная система для старого железа. Если верить тестам автора статьи, то эта версия потребляет после 15 минут работы 702 МБ оперативной памяти.
Лицензии, понятное дело, для этой версии нет и не может быть. Она только для правительства China. Соответственно, решается этот вопрос точно так же, как и для всех остальных версий. Если не активировать, по идее должна работать, как и все остальные версии, с соответствующей надписью.
Интересно, что эта редакция существует уже много лет, а информация о ней всплыла совсем недавно. Я раньше ни разу не слышал о том, что она существует.
#windows
В основе моего рассказа будет информация из статьи на хабре:
⇨ Windows 11 Enterprise G – Что за издание для правительства Китая и зачем оно вам?
📌 Основные особенности систем Windows 10 и Windows 11 Enterprise G:
🔹Выпускаются для китайского госсектора, удовлетворяя всем требованием китайского регулятора.
🔹Из этой версии вырезаны телеметрия, защитник, кортана, магазин, UWP приложения, браузер edge и многое другое.
🔹Доступна только на китайском и английском языках, но есть возможность обходным путём добавить русский.
🔹Система основана на редакции Professional. Подготовить образ Enterprise G можно самостоятельно на основе предоставляемых Microsoft инструментов, в частности ProductPolicy.
🔹Система нормально эксплуатируется, обновляется. То есть она полноценная, просто без лишнего софта, который не имеет отношения непосредственно к ОС.
Благодаря тому, что в системе нет практически ничего лишнего, она потребляет меньше оперативной памяти, меньше нагружает диск. Возможно и на HDD нормально заработает. После чистой установки занимает 8Гб на диске. После установки всех обновлений - 10,7Гб. Это я очистку не запускал. Просто всё обновил через параметры и посмотрел занимаемый объём.
В статье на хабре дана инструкция по созданию своего образа. Она очень запутанная, читается тяжело. Автор некоторые вещи повторяет, имена некоторых файлов не совпадают с тем, что можно скачать и т.д. Для того, кто не занимается сборкой своих образов, разобраться будет непросто, но реально. Я осилил благодаря в том числе комментариям, там есть пояснения.
У меня получилось собрать модифицированный install.wim по инструкции автора. Она рабочая, если ничего не напутать. Проблема в том, что оригинальная версия требует Secure Boot и TPM. Это тоже можно решить в своём образе, но мне в итоге надоело этим заниматься. Для теста я взял готовую сборку от автора статьи, где всё это уже решено. Она лежит на каком-то иностранном файлообменнике (❗️использовать на свой страх и риск):
⇨ https://mega.nz/folder/Id50xJBQ#JvuG3GOi0yoWyAV5JFD1gw
В директории ISO несколько готовых образов разных версий систем. Я взял вроде бы самую свежую 26100. Не очень разбираюсь в этой нумерации. Развернул у себя в тестовом Proxmox. Всё встало без проблем. Когда спросили ключ активации, сказал, что у меня его нет. После установки проверил обновления. Скачались и установились.
Система очень понравилась. Представьте, что это что-то вроде WinXP, где нет ничего лишнего, только это Win11. В разделе приложений пустота, нет даже браузера. Никаких ножниц, пейнтов и т.д. Всё это можно вручную поставить, если надо будет.
Оставил себе для теста эту виртуалку. У меня постоянно используются несколько тестовых вирталок с виндой для различных нужд. Если всё в порядке будет, переведу их тоже на эту версию.
Редакцию Enterprise G можно сделать для архитектуры x86. На текущий момент это будет идеальная современная система для старого железа. Если верить тестам автора статьи, то эта версия потребляет после 15 минут работы 702 МБ оперативной памяти.
Лицензии, понятное дело, для этой версии нет и не может быть. Она только для правительства China. Соответственно, решается этот вопрос точно так же, как и для всех остальных версий. Если не активировать, по идее должна работать, как и все остальные версии, с соответствующей надписью.
Интересно, что эта редакция существует уже много лет, а информация о ней всплыла совсем недавно. Я раньше ни разу не слышал о том, что она существует.
#windows
{kind=link}
Регулярно приходится настраивать NFS сервер для различных прикладных задач. Причём в основном не на постоянное использование, а временное. На практике именно по nfs достигается максимальная скорость копирования, быстрее чем по scp, ssh, smb или http.
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
Устанавливаем пакет для nfs-server:
Добавляем в файл
Для всей подсети просто добавляем маску:
Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
Перезапускаем сервер
Проверяем работу:
Для работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
Проверяем, видит ли клиент что-то на сервере:
Всё в порядке, видим ресурс для нас. Монтируем его к себе:
Проверяем:
Смотрим версию протокола. Желательно, чтобы работало по v4:
Создаём файл:
При желании можно в fstab добавить на постоянку:
Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs
Обычно просто через поиск нахожу какую-то статью и делаю. Своей инструкции нет. Решил написать, уместив максимально кратко и ёмко в одну публикацию, чтобы можно было сохранить и использовать для быстрого копипаста.
Обычно всё хранение файлов под различные нужды делаю в разделе
/mnt:# mkdir /mnt/nfs# chown nobody:nogroup /mnt/nfsУстанавливаем пакет для nfs-server:
# apt install nfs-kernel-serverДобавляем в файл
/etc/exports описание экспортируемой файловой системы только для ip адреса 10.20.1.56:/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)Для всей подсети просто добавляем маску:
/mnt/nfs 10.20.1.56/24(rw,all_squash,no_subtree_check,crossmnt)Для нескольких IP адресов пишем их каждый в своей строке (так нагляднее, но можно и в одну писать):
/mnt/nfs 10.20.1.56(rw,all_squash,no_subtree_check,crossmnt)/mnt/nfs 10.20.1.52(rw,all_squash,no_subtree_check,crossmnt)Перезапускаем сервер
# systemctl restart nfs-serverПроверяем работу:
# systemctl status nfs-serverДля работы NFS сервера должен быть открыт TCP порт 2049. Если всё ок, переходим на клиент. Ставим туда необходимый пакет:
# apt install nfs-commonПроверяем, видит ли клиент что-то на сервере:
# showmount -e 10.20.1.36Export list for 10.20.1.36:/mnt/nfs 10.20.1.56Всё в порядке, видим ресурс для нас. Монтируем его к себе:
# mkdir /mnt/nfs# mount 10.20.1.36:/mnt/nfs /mnt/nfsПроверяем:
# df -h | grep nfs10.20.1.36:/mnt/nfs 48G 3.2G 43G 7% /mnt/nfsСмотрим версию протокола. Желательно, чтобы работало по v4:
# mount -t nfs410.20.1.36:/ on /mnt/nfs type nfs4 (rw,relatime,vers=4.2,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.20.1.56,local_lock=none,addr=10.20.1.36)Создаём файл:
# echo "test" > /mnt/nfs/testfileПри желании можно в fstab добавить на постоянку:
10.20.1.36:/mnt/nfs /mnt/nfs nfs4 defaults 0 0Не забудьте в конце поставить переход на новую строку. Либо подключайте через systemd unit. В моей заметке есть пример с NFS.
Похожие короткие инструкции для настройки SMB сервера:
◽на базе python
◽на базе ядерного ksmbd
#fileserver #nfs
На прошлой неделе делал опросы тут в канале и в группе VK. Сейчас, когда эти опросы собрали основную массу просмотров, можно подвести итоги. В целом, получилось плюс-минус как я и ожидал. В рабочих машинах больше винды, на серверах больше линукса. Единственное, думал, что доля линукса на рабочих машинах будет поменьше. На деле довольно много людей постоянно работают за Linux.
📌 Результаты в Telegram:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 66% - Windows
◽23% - Linux
◽10% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 63% - Linux
◽34% - Windows
◽1% - *BSD
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив? (можно было выбрать несколько вариантов)
🔴 47% - Debian
◽43% - Ubuntu
◽17% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽12% - один из российских дистрибутивов
◽5% - другое
📌 Результаты в VK:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 69% - Windows
◽23% - Linux
◽6% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 56% - Linux
◽ 40% - Windows
◽4% - другая
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив?
🔴 36% - Ubuntu
◽ 34% - Debian
◽8% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽13% - один из российских дистрибутивов
◽8% - другое
Результаты в TG и VK немного отличаются, но не кардинально. Для меня было немного странно видеть так много серверов под Ubuntu. То, что Debian будет в лидерах, предполагал. Я уже думал об этом, ещё когда объявили об изменениях с CentOS. Сейчас ожидал, что лидером будет Debian, а Ubuntu будет плюс минус как и форков RHEL. Но последние совсем потеряли позиции, судя по результатам. Не ожидал, что так сильно.
Довольно высокая доля отечественных дистрибутивов. Думал, будет в районе 5%, вышло 12% и 13%, что уже значительно. В итоге в серверах на базе Linux в России сейчас очень большой зоопарк. Если вы только начинаете всё это изучать, то выбирайте себе Debian. Это будет наиболее универсальным вариантом на сегодняшний день.
Постарался, как мог, усреднить и объединить результаты опросов в обоих сообществах. В VK нельзя было выбрать несколько ответов, а в TG в последнем опросе можно было. Это немного смазало картинку и итоговый результат третьего вопроса.
#разное
📌 Результаты в Telegram:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 66% - Windows
◽23% - Linux
◽10% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 63% - Linux
◽34% - Windows
◽1% - *BSD
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив? (можно было выбрать несколько вариантов)
🔴 47% - Debian
◽43% - Ubuntu
◽17% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽12% - один из российских дистрибутивов
◽5% - другое
📌 Результаты в VK:
1️⃣ Какая основная операционная система установлена на вашем рабочем компьютере или ноутбуке?
🔴 69% - Windows
◽23% - Linux
◽6% - MacOS
◽1% - всё остальное
2️⃣ Под вашим управлением больше всего серверов какой операционной системы?
🔴 56% - Linux
◽ 40% - Windows
◽4% - другая
3️⃣ Если на серверах у вас ОС Linux, то в основном какой это дистрибутив?
🔴 36% - Ubuntu
◽ 34% - Debian
◽8% - Форк RHEL (Rocky, Alma, Oracle и т.д.)
◽13% - один из российских дистрибутивов
◽8% - другое
Результаты в TG и VK немного отличаются, но не кардинально. Для меня было немного странно видеть так много серверов под Ubuntu. То, что Debian будет в лидерах, предполагал. Я уже думал об этом, ещё когда объявили об изменениях с CentOS. Сейчас ожидал, что лидером будет Debian, а Ubuntu будет плюс минус как и форков RHEL. Но последние совсем потеряли позиции, судя по результатам. Не ожидал, что так сильно.
Довольно высокая доля отечественных дистрибутивов. Думал, будет в районе 5%, вышло 12% и 13%, что уже значительно. В итоге в серверах на базе Linux в России сейчас очень большой зоопарк. Если вы только начинаете всё это изучать, то выбирайте себе Debian. Это будет наиболее универсальным вариантом на сегодняшний день.
Постарался, как мог, усреднить и объединить результаты опросов в обоих сообществах. В VK нельзя было выбрать несколько ответов, а в TG в последнем опросе можно было. Это немного смазало картинку и итоговый результат третьего вопроса.
#разное
{kind=link}
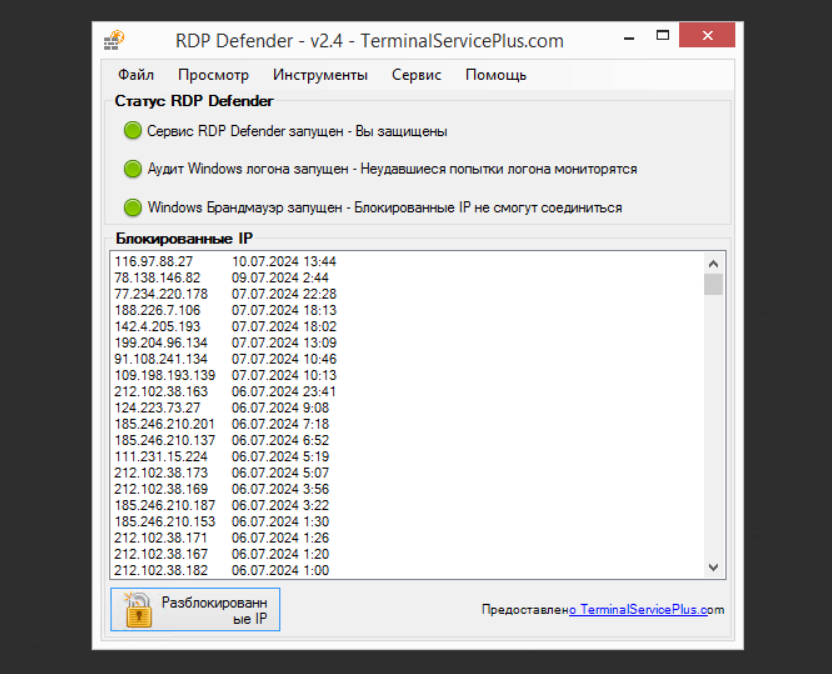
Периодически пишу про небольшие простые программы, которыми давно пользуюсь. Некоторые из них уже не развиваются, но не потеряли удобство и актуальность. Одной из таких программ является RDP Defender.
Я уже писал о ней года 3 назад. С тех пор продолжаю иногда пользоваться. На Windows Server 2019 нормально работает, выше не пробовал. Это небольшая программа, которая выполняет одну единственную функцию - анализирует журнал аудита Windows, если есть попытки перебора паролей, блокирует IP адрес переборщика с помощью встроенного файрвола Windows.
Программа маленькая, установщик меньше мегабайта весит. Уже давно нет сайта, на котором она лежала. Посмотреть на него можно через web.archive.org. Вот прямая ссылка на один из снимков сайта, где она выкладывалась. Оттуда же можно скачать и установщик, но там не самая последняя версия. В какой-то момент сайт ещё раз поменялся, и там уже была самая актуальная версия 2.4, которой я пользуюсь.
Решений этой задачи есть очень много, в том числе и встроенными средствами самой системы. Я в конце приведу ссылки. Напишу, почему по прежнему предпочитаю в простых случаях RDP Defender:
◽Простой и наглядный интерфейс
◽Сразу видно, запущены ли службы файрвола и аудита
◽Быстрый доступ к белым спискам
◽Информативный лог блокировок
С этой программой удобнее работать, чем с оснастками и скриптами Windows.
Отдельно скажу про RDP порт, смотрящий напрямую в интернет. Да, по возможности его не нужно выставлять. Но есть люди, которые готовы это делать, несмотря на связанные с этим риски. Какой-то особой опасности в этом нет. Если вы сейчас установите Windows Server со всеми обновлениями, откроете RDP порт на доступ из интернета и защитите его тем или иным способом от перебора паролей, то ничего с вами не случится. До тех пор, пока не будет найдена какая-то существенная уязвимость в протоколе, которая позволит обходить аутентификацию. Даже не совсем в протоколе RDP, до которого ещё надо добраться. Подключение по RDP в Windows на самом деле неплохо защищено.
На моей памяти последняя такая уязвимость была обнаружена лет 5-6 назад. Один из серверов под моим управлением был зашифрован. Так что нужно понимать этот риск. Может ещё лет 10 таких дыр не будет найдено, а может они уже есть, не афишируется, но используется втихую.
RDP Defender актуален не только для интернета, но и локальной сети. В бан запросто попадают завирусованные компы из локалки, или какие-то другие устройства. Например, сталкивался с тем, что какой-то софт от 1С неправильно аутентифицировался на сервере для доступа к сетевому диску и регулярно получал от него бан. Разбирались в итоге с программистами, почему так происходит. Оказалось, что там идёт перебор каких-то разных способов аутентификации и до рабочего дело не доходит, так как бан настигает раньше. Так что программу имеет смысл использовать и в локалке.
Аналоги RDP Defender:
▪️ IPBan
▪️ EvlWatcher
▪️ Cyberarms IDDS
▪️ Crowdsec
▪️ PowerShell скрипт
Положил программу на свой Яндекс.Диск:
⇨ https://disk.yandex.ru/d/gN6G9DZ01Fgr6Q
Посмотреть его разбор с точки зрения безопасности можно тут:
- virustotal
- joesandbox (доступ через vpn)
#windows #security
Я уже писал о ней года 3 назад. С тех пор продолжаю иногда пользоваться. На Windows Server 2019 нормально работает, выше не пробовал. Это небольшая программа, которая выполняет одну единственную функцию - анализирует журнал аудита Windows, если есть попытки перебора паролей, блокирует IP адрес переборщика с помощью встроенного файрвола Windows.
Программа маленькая, установщик меньше мегабайта весит. Уже давно нет сайта, на котором она лежала. Посмотреть на него можно через web.archive.org. Вот прямая ссылка на один из снимков сайта, где она выкладывалась. Оттуда же можно скачать и установщик, но там не самая последняя версия. В какой-то момент сайт ещё раз поменялся, и там уже была самая актуальная версия 2.4, которой я пользуюсь.
Решений этой задачи есть очень много, в том числе и встроенными средствами самой системы. Я в конце приведу ссылки. Напишу, почему по прежнему предпочитаю в простых случаях RDP Defender:
◽Простой и наглядный интерфейс
◽Сразу видно, запущены ли службы файрвола и аудита
◽Быстрый доступ к белым спискам
◽Информативный лог блокировок
С этой программой удобнее работать, чем с оснастками и скриптами Windows.
Отдельно скажу про RDP порт, смотрящий напрямую в интернет. Да, по возможности его не нужно выставлять. Но есть люди, которые готовы это делать, несмотря на связанные с этим риски. Какой-то особой опасности в этом нет. Если вы сейчас установите Windows Server со всеми обновлениями, откроете RDP порт на доступ из интернета и защитите его тем или иным способом от перебора паролей, то ничего с вами не случится. До тех пор, пока не будет найдена какая-то существенная уязвимость в протоколе, которая позволит обходить аутентификацию. Даже не совсем в протоколе RDP, до которого ещё надо добраться. Подключение по RDP в Windows на самом деле неплохо защищено.
На моей памяти последняя такая уязвимость была обнаружена лет 5-6 назад. Один из серверов под моим управлением был зашифрован. Так что нужно понимать этот риск. Может ещё лет 10 таких дыр не будет найдено, а может они уже есть, не афишируется, но используется втихую.
RDP Defender актуален не только для интернета, но и локальной сети. В бан запросто попадают завирусованные компы из локалки, или какие-то другие устройства. Например, сталкивался с тем, что какой-то софт от 1С неправильно аутентифицировался на сервере для доступа к сетевому диску и регулярно получал от него бан. Разбирались в итоге с программистами, почему так происходит. Оказалось, что там идёт перебор каких-то разных способов аутентификации и до рабочего дело не доходит, так как бан настигает раньше. Так что программу имеет смысл использовать и в локалке.
Аналоги RDP Defender:
▪️ IPBan
▪️ EvlWatcher
▪️ Cyberarms IDDS
▪️ Crowdsec
▪️ PowerShell скрипт
Положил программу на свой Яндекс.Диск:
⇨ https://disk.yandex.ru/d/gN6G9DZ01Fgr6Q
Посмотреть его разбор с точки зрения безопасности можно тут:
- virustotal
- joesandbox (доступ через vpn)
#windows #security
{kind=link}
У компании Canonical, авторов ОС Ubuntu, есть Open Source проект MAAS для автоматической раскатки систем на голое железо. Непривычная аббревиатура, которую они расшифровывают как Metal-As-A-Service, хотя иногда её можно увидеть как сокращение от Monitoring-As-A-Service.
С помощью MAAS можно настроить автоматическую установку любых подготовленных образов систем на голое железо. По сути это аналог таких проектов, как FOG Project, Cobbler, Foreman. В их основе лежат технологии сетевой загрузки PXE и TFTP. MAAS тут не исключение. На сегодняшний день это наиболее современное решение подобного типа, нацеленное на масштабное корпоративное применение. Но никто не мешает вам и рабочие станции с его помощью накатывать, а не только сервера и гипервизоры.
Расскажу на пальцах, как это работает. Современные сетевые карты поддерживают технологию PXE. Они могут выступать источником загрузки системы наравне с жёстким диском или usb устройством. Вы можете подготовить образ любой операционной системы, который автоматически выполнит установку на железо, не задавая вопросы. Этот образ нужно будет загрузить в систему, подобную MAAS. На DHCP сервере в локальной сети настраивается специальный параметр, который при загрузке сетевой карты с помощью PXE передаст ей адрес MAAS сервера, откуда будет взят образ ОС для загрузки.
Имя подготовленный сервер MAAS и настроив соответствующим образом DHCP, вам достаточно в биосе компьютера или сервера выбрать сетевую загрузку, чтобы автоматически подгрузить установочный образ и выполнить установку системы. Конкретно MAAS поддерживает интеграцию с Ansible, так что после установки системы сможет выполнить нужные настройки уже внутри неё. Всё это управляется через веб интерфейс, где имеется список машин, их технические характеристики и другая информация, в том числе о виртуальных машинах, если речь идёт о гипервизорах. Если на железе есть настройка WOL (Wake on Lan), то с помощью MAAS можно будет включать и выключать устройства.
Установка и базовая настройка MAAS относительно простая. Понадобится система Ubuntu. Развернуть MAAS можно как из snap, так и из привычных пакетов. Для этого есть отдельный репозиторий. Настройка и управление продукта могут выполняться через веб интерфейс, который приятен на вид и функционален. Если вас заинтересует эта система, захочется посмотреть и развернуть у себя, то вот тут подробный обзор на MAAS в связке с Packer:
▶️ Deploying Machines with MaaS and Packer - Metal as a Service + Hashicorp Packer Tutorial
Там прям пошаговая установка в соответствии с инструкцией. Повторить увиденное не составит большого труда. Автор подробно всё объясняет и показывает. Рассказывает нюансы с сетями, с настройкой DHCP и т.д. Очень доступно. Если не знаете английский, хватит синхронного перевода в Яндекс.Браузере.
Из всех продуктов подобного типа, что я тестировал, MAAS выглядит наиболее функциональным и целостным. Несмотря на то, что это изделие Canonical, никакой привязки к управляемым системам нет, кроме того, что устанавливать сам программный продукт лучше на сервер с Ubuntu. Разворачивать системы вы можете абсолютно любые: Linux, Windows, ESXI, Citrix и т.д.
⇨ Сайт / Исходники
#pxe
С помощью MAAS можно настроить автоматическую установку любых подготовленных образов систем на голое железо. По сути это аналог таких проектов, как FOG Project, Cobbler, Foreman. В их основе лежат технологии сетевой загрузки PXE и TFTP. MAAS тут не исключение. На сегодняшний день это наиболее современное решение подобного типа, нацеленное на масштабное корпоративное применение. Но никто не мешает вам и рабочие станции с его помощью накатывать, а не только сервера и гипервизоры.
Расскажу на пальцах, как это работает. Современные сетевые карты поддерживают технологию PXE. Они могут выступать источником загрузки системы наравне с жёстким диском или usb устройством. Вы можете подготовить образ любой операционной системы, который автоматически выполнит установку на железо, не задавая вопросы. Этот образ нужно будет загрузить в систему, подобную MAAS. На DHCP сервере в локальной сети настраивается специальный параметр, который при загрузке сетевой карты с помощью PXE передаст ей адрес MAAS сервера, откуда будет взят образ ОС для загрузки.
Имя подготовленный сервер MAAS и настроив соответствующим образом DHCP, вам достаточно в биосе компьютера или сервера выбрать сетевую загрузку, чтобы автоматически подгрузить установочный образ и выполнить установку системы. Конкретно MAAS поддерживает интеграцию с Ansible, так что после установки системы сможет выполнить нужные настройки уже внутри неё. Всё это управляется через веб интерфейс, где имеется список машин, их технические характеристики и другая информация, в том числе о виртуальных машинах, если речь идёт о гипервизорах. Если на железе есть настройка WOL (Wake on Lan), то с помощью MAAS можно будет включать и выключать устройства.
Установка и базовая настройка MAAS относительно простая. Понадобится система Ubuntu. Развернуть MAAS можно как из snap, так и из привычных пакетов. Для этого есть отдельный репозиторий. Настройка и управление продукта могут выполняться через веб интерфейс, который приятен на вид и функционален. Если вас заинтересует эта система, захочется посмотреть и развернуть у себя, то вот тут подробный обзор на MAAS в связке с Packer:
▶️ Deploying Machines with MaaS and Packer - Metal as a Service + Hashicorp Packer Tutorial
Там прям пошаговая установка в соответствии с инструкцией. Повторить увиденное не составит большого труда. Автор подробно всё объясняет и показывает. Рассказывает нюансы с сетями, с настройкой DHCP и т.д. Очень доступно. Если не знаете английский, хватит синхронного перевода в Яндекс.Браузере.
Из всех продуктов подобного типа, что я тестировал, MAAS выглядит наиболее функциональным и целостным. Несмотря на то, что это изделие Canonical, никакой привязки к управляемым системам нет, кроме того, что устанавливать сам программный продукт лучше на сервер с Ubuntu. Разворачивать системы вы можете абсолютно любые: Linux, Windows, ESXI, Citrix и т.д.
⇨ Сайт / Исходники
#pxe
{kind=link}
Открытый практикум DevOps by Rebrain: Шардирование elasticsearch
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
17 Июля (Среда) в 20:00 по МСК
Программа практикума:
🔹Репликация
🔹Шардирование
🔹Настройка кластера elasticsearch
Кто ведёт?
Андрей Буранов – Системный администратор в департаменте VK Play. 10+ лет опыта работы с ОС Linux. 8+ лет опыта преподавания. Входит в топ 3 лучших преподавателей образовательных порталов.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2VtzqvgsVUc
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
17 Июля (Среда) в 20:00 по МСК
Программа практикума:
🔹Репликация
🔹Шардирование
🔹Настройка кластера elasticsearch
Кто ведёт?
Андрей Буранов – Системный администратор в департаменте VK Play. 10+ лет опыта работы с ОС Linux. 8+ лет опыта преподавания. Входит в топ 3 лучших преподавателей образовательных порталов.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2VtzqvgsVUc
▶️ Всем хороших выходных. Желательно уже в отпуске в каком-то приятном месте, где можно отдохнуть и позалипать в ютуб. Как обычно, ниже те видео из моих подписок за последнее время (обычно беру период в 2 недели), что мне показались интересными и полезными.
⇨ Обновляем MariaDB c 10.11 на 11.4
Пошаговое обновление MariaDB на свежую ветку. В видео ничего особенного, просто наглядная демонстрация процесса на основе статьи по обновлению из документации.
⇨ Self-Hosted AI That's Actually Useful
Интересное и полезное видео с обзором AI движков, которые можно запустить на своём железе. Автор проделал это и пока кратко рассказал основное. Я так понял, будут дальше видео на эту тему.
⇨ pfSense Alternatives: Firewall Solutions for your Network
Автор разобрал альтернативы самому популярному бесплатному софтовому шлюзу: OPNsense, Untangle, Unifi Security Devices, Sophos UTM Home Edition, MikroTik RouterOS.
⇨ The Best Note-Taking App For Linux Users: Standard Notes Review
Обзор программы для хранения заметок Standard Notes. Впервые про неё услышал. Автор рассказывает про свои мытарства в этой стезе. Он тоже использовал Joplin, но отказался от него из-за багов. Пробовал все популярные решения, в том числе те, что я тут недавно упоминал и остановился на Standard Notes. По обзору реально выглядит неплохо. Визуально лучше Joplin. Придётся тоже пробовать.
⇨ Твой новый dashboard Homepage
Очень подборный обзор, установка и настройка очередного дашборда для серверов и сервисов на них. Интересная штука, есть интеграция с Proxmox, Mikrotik, Portainer, Traefik и многим другим популярным софтом. Это аналог Dashy или Heimdall, про которые я ранее писал. У автора интересные видео, всегда с удовольствием смотрю.
⇨ Uptime Kuma. Мониторим свои сервисы
Обзор системы мониторинга для тех, кто всё ещё про неё не знает. Рекомендую если не знакомы. Хотя я в итоге для легковесного мониторинга перешёл на Gatus.
⇨ Prometheus - Как мониторить Динамичное количество серверов на AWS ?
Пример настройки Prometheus для мониторинга динамических сред.
⇨ OpenVPN-сервер на Mikrotik: от подключения мобильных устройств до десктопов
Очень подробный разбор темы настройки OpenVPN на микротиках от известного тренера Романа Козлова.
⇨ Инструменты мониторинга трафика в Mikrotik
Короткое видео для новичков в Mikrotik. Автор наглядно показал 3 способа просмотра трафика в Микротике: torch, connections, sniffer.
⇨ Junior vs Middle vs Senior в чем отличие? Пример задач для Junior DevOps
Автор описал своё видение уровней должностей в современной IT индустрии. Информация для тех, кто не до конца понимает, что эти уровни значат.
⇨ Build a Jenkins Server on Ubuntu 24.04: Easy Setup Tutorial
Пошаговая инструкция по установке Jenkins. Честно говоря не знаю, для чего сейчас это может кому-то пригодиться. Если начинать с нуля изучать CI/CD, то Jenkins уже не очень актуален. Его время проходит. Тем не менее, инструкция актуальная и позволяет копипастом поднять всё то же самое.
⇨ Обзор и тестирование TerraMaster F4-424
Подробный обзор NAS сервера, про который я вообще раньше не слышал. Впервые увидел бренд TerraMaster. Бегло посмотрел видео. На вид попытка создать конкуренцию Synology. Под капотом тоже своя система, похожая по возможностям на SynologyOS. По ценам дешевле Synology, но всё равно дороговато выглядит. Автор в итоге xpenology поставил на это железо :) По факту дешевле собрать любой подходящий самосбор и установить туда xpenology.
#видео
⇨ Обновляем MariaDB c 10.11 на 11.4
Пошаговое обновление MariaDB на свежую ветку. В видео ничего особенного, просто наглядная демонстрация процесса на основе статьи по обновлению из документации.
⇨ Self-Hosted AI That's Actually Useful
Интересное и полезное видео с обзором AI движков, которые можно запустить на своём железе. Автор проделал это и пока кратко рассказал основное. Я так понял, будут дальше видео на эту тему.
⇨ pfSense Alternatives: Firewall Solutions for your Network
Автор разобрал альтернативы самому популярному бесплатному софтовому шлюзу: OPNsense, Untangle, Unifi Security Devices, Sophos UTM Home Edition, MikroTik RouterOS.
⇨ The Best Note-Taking App For Linux Users: Standard Notes Review
Обзор программы для хранения заметок Standard Notes. Впервые про неё услышал. Автор рассказывает про свои мытарства в этой стезе. Он тоже использовал Joplin, но отказался от него из-за багов. Пробовал все популярные решения, в том числе те, что я тут недавно упоминал и остановился на Standard Notes. По обзору реально выглядит неплохо. Визуально лучше Joplin. Придётся тоже пробовать.
⇨ Твой новый dashboard Homepage
Очень подборный обзор, установка и настройка очередного дашборда для серверов и сервисов на них. Интересная штука, есть интеграция с Proxmox, Mikrotik, Portainer, Traefik и многим другим популярным софтом. Это аналог Dashy или Heimdall, про которые я ранее писал. У автора интересные видео, всегда с удовольствием смотрю.
⇨ Uptime Kuma. Мониторим свои сервисы
Обзор системы мониторинга для тех, кто всё ещё про неё не знает. Рекомендую если не знакомы. Хотя я в итоге для легковесного мониторинга перешёл на Gatus.
⇨ Prometheus - Как мониторить Динамичное количество серверов на AWS ?
Пример настройки Prometheus для мониторинга динамических сред.
⇨ OpenVPN-сервер на Mikrotik: от подключения мобильных устройств до десктопов
Очень подробный разбор темы настройки OpenVPN на микротиках от известного тренера Романа Козлова.
⇨ Инструменты мониторинга трафика в Mikrotik
Короткое видео для новичков в Mikrotik. Автор наглядно показал 3 способа просмотра трафика в Микротике: torch, connections, sniffer.
⇨ Junior vs Middle vs Senior в чем отличие? Пример задач для Junior DevOps
Автор описал своё видение уровней должностей в современной IT индустрии. Информация для тех, кто не до конца понимает, что эти уровни значат.
⇨ Build a Jenkins Server on Ubuntu 24.04: Easy Setup Tutorial
Пошаговая инструкция по установке Jenkins. Честно говоря не знаю, для чего сейчас это может кому-то пригодиться. Если начинать с нуля изучать CI/CD, то Jenkins уже не очень актуален. Его время проходит. Тем не менее, инструкция актуальная и позволяет копипастом поднять всё то же самое.
⇨ Обзор и тестирование TerraMaster F4-424
Подробный обзор NAS сервера, про который я вообще раньше не слышал. Впервые увидел бренд TerraMaster. Бегло посмотрел видео. На вид попытка создать конкуренцию Synology. Под капотом тоже своя система, похожая по возможностям на SynologyOS. По ценам дешевле Synology, но всё равно дороговато выглядит. Автор в итоге xpenology поставил на это железо :) По факту дешевле собрать любой подходящий самосбор и установить туда xpenology.
#видео
YouTube
Обновляем MariaDB c 10.11 на 11.4
В видео рассмотрим процесс перехода на новую версию MariaDB, обратим внимание на потенциальные проблемы и их решения.
Этот канал посвящён теме поддержки сайтов: от технических аспектов системного администрирования до вопросов экономической эффективности…
Этот канал посвящён теме поддержки сайтов: от технических аспектов системного администрирования до вопросов экономической эффективности…
🎓 У хостера Selectel есть небольшая "академия", где в открытом доступе есть набор курсов. Они неплохого качества. Где-то по верхам в основном теория, а где-то полезные практические вещи. Я бы обратил внимание на два курса, которые показались наиболее полезными:
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
{kind=link}
Недавно очень крупно ошибся из-за невнимательности. Нужно было купить небольшой дедик под веб сервер, настроить и перенести туда сайты. И я жёстко ошибся с размерами дисков самого сервера и виртуалки, что доставило много хлопот на ровном месте. Расскажу обо всём по порядку.
Арендовал сервер с двумя SSD дисками 480 ГБ по описанию сервера. Автоматом выбрал шаблон Proxmox VE с mdadm в RAID1 и сразу получил настроенный гипервизор. Стандартный шаблон предлагает простую разбивку: 1 ГБ на /boot, 5 ГБ на swap и остальное на корень системы. Не стал ничего менять, оставил как есть.
Развернул гипервизор, быстро сделал некоторые настройки. На диски вообще не смотрел. Создал виртуалку с диском 450 ГБ типа qcow2 и дальше начал с ней работать. В голове прикинул, что диски 480 ГБ, система примерно 5 ГБ. Других виртуалок не будет. В целом нормально.
Всё настроил, данные закинул. Повозил их туда-сюда по серверу. Приходит уведомление от мониторинга, что на гипервизоре заканчивается место на диске. Причём там занято уже 98% было, на виртуалке реальных данных - 300 ГБ. Удивился. Захожу на гипервизор, смотрю. Там раздел под корень диска по факту вышел всего 440 ГБ. То есть заявленные характеристики диска 480 ГБ в реальном размере это 446 ГБ: 1 на /boot, 5 на swap, 440 на корень.
Тут я сразу понял всю глубину своей ошибки, так как простого решения у неё нет, кроме очередного переноса. Причём просто так не переедешь на другой гипервизор без перенастройки виртуалки. Следующая градация дисков на сервере для аренды - 960 ГБ, что почти в 2 раза дороже, но реально такой объём не нужен. А на диски 480 ГБ эта виртуалки уже не переедет.
Такая вот ошибка из-за невнимательности. Поторопился и не проверил. Даже мысли не возникло на эту тему, хотя всем известно, что объём диска из описания не соответствует реальному.
Но благодаря этой ошибке я придумал полную техническую реализацию исправления. Узнал некоторые вещи, о существовании которых даже не слышал. Кое-что потестил и проверил, как работает. Вечером отдельно всё расскажу с техническими подробностями. На самом деле всё можно ужать и вернуть в доступный объём. Для этого надо:
1️⃣ Уменьшить файловую систему на виртуалке.
2️⃣ Уменьшить размер раздела диска в виртуалке.
3️⃣ Уменьшить размер qcow2 файла.
Каждая из операций потенциально опасная, к тому же на виртуалке раздел один и он корень, отмонтировать на лету и ужать его не получится. Но решение есть.
#ошибка
Арендовал сервер с двумя SSD дисками 480 ГБ по описанию сервера. Автоматом выбрал шаблон Proxmox VE с mdadm в RAID1 и сразу получил настроенный гипервизор. Стандартный шаблон предлагает простую разбивку: 1 ГБ на /boot, 5 ГБ на swap и остальное на корень системы. Не стал ничего менять, оставил как есть.
Развернул гипервизор, быстро сделал некоторые настройки. На диски вообще не смотрел. Создал виртуалку с диском 450 ГБ типа qcow2 и дальше начал с ней работать. В голове прикинул, что диски 480 ГБ, система примерно 5 ГБ. Других виртуалок не будет. В целом нормально.
Всё настроил, данные закинул. Повозил их туда-сюда по серверу. Приходит уведомление от мониторинга, что на гипервизоре заканчивается место на диске. Причём там занято уже 98% было, на виртуалке реальных данных - 300 ГБ. Удивился. Захожу на гипервизор, смотрю. Там раздел под корень диска по факту вышел всего 440 ГБ. То есть заявленные характеристики диска 480 ГБ в реальном размере это 446 ГБ: 1 на /boot, 5 на swap, 440 на корень.
Тут я сразу понял всю глубину своей ошибки, так как простого решения у неё нет, кроме очередного переноса. Причём просто так не переедешь на другой гипервизор без перенастройки виртуалки. Следующая градация дисков на сервере для аренды - 960 ГБ, что почти в 2 раза дороже, но реально такой объём не нужен. А на диски 480 ГБ эта виртуалки уже не переедет.
Такая вот ошибка из-за невнимательности. Поторопился и не проверил. Даже мысли не возникло на эту тему, хотя всем известно, что объём диска из описания не соответствует реальному.
Но благодаря этой ошибке я придумал полную техническую реализацию исправления. Узнал некоторые вещи, о существовании которых даже не слышал. Кое-что потестил и проверил, как работает. Вечером отдельно всё расскажу с техническими подробностями. На самом деле всё можно ужать и вернуть в доступный объём. Для этого надо:
1️⃣ Уменьшить файловую систему на виртуалке.
2️⃣ Уменьшить размер раздела диска в виртуалке.
3️⃣ Уменьшить размер qcow2 файла.
Каждая из операций потенциально опасная, к тому же на виртуалке раздел один и он корень, отмонтировать на лету и ужать его не получится. Но решение есть.
#ошибка
Как уменьшить размер файловой системы с ext4?
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
Файловая система на разделе
Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
Добавляем ещё один исполняемый файл
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Напомню, что файловая система ext4 штатно поддерживает своё уменьшение, если на ней достаточно свободного места для сжимания. В отличие от xfs, которая уменьшение не поддерживает вообще. Для того, чтобы уменьшить ext4, её надо обязательно размонтировать. Наживую не получится. Если нужно уменьшить корневой раздел с системой, то в любом случае нужна перезагрузка.
В общем случае вам нужно загрузиться с какого-то LiveCD, примонтировать раздел с ext4 и выполнить одну команду:
# /sbin/resize2fs /dev/sda1 50GФайловая система на разделе
/dev/sda1 будет уменьшена до 50G, если там хватит свободного места для этого. То есть данных должно быть меньше. В общем случае перед выполнением операции и после рекомендуется проверить файловую систему на ошибки:# /sbin/e2fsck -yf /dev/sda1Если система смонтирована, то ни уменьшения размера, ни проверка не состоятся:
# /sbin/resize2fs /dev/sda1 50Gresize2fs 1.47.0 (5-Feb-2023)Filesystem at /dev/sda1 is mounted on /; on-line resizing required/sbin/resize2fs: On-line shrinking not supported# /sbin/e2fsck -yf /dev/sda1e2fsck 1.47.0 (5-Feb-2023)/dev/sda1 is mounted.e2fsck: Cannot continue, aborting.Если у вас есть возможность загрузиться с LiveCD, то никаких проблем. Загружайте и уменьшайте. А если нет? Я в интернете нашёл интересный трюк, ради которого и пишу эту заметку. Не для того, чтобы именно показать уменьшение файловой системы. Этим лучше вообще не заниматься без крайне нужды, проще переехать. Мне понравился сам подход.
Утилиту resize2fs можно добавить в образ initramfs, который загружается до загрузки основной системы. И выполнить всю работу там. Получается аналог LiveCD, только на базе вашей системы.
Настраивается это так. Создаём исполняемый (❗️) файл
/etc/initramfs-tools/hooks/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case $1 in
prereqs)
prereqs
exit 0
;;
esac
. /usr/share/initramfs-tools/hook-functions
copy_exec /sbin/e2fsck
copy_exec /sbin/resize2fs
exit 0
Добавляем ещё один исполняемый файл
/etc/initramfs-tools/scripts/local-premount/resizefs:#!/bin/sh
set -e
PREREQS=""
prereqs() { echo "$PREREQS"; }
case "$1" in
prereqs)
prereqs
exit 0
;;
esac
# simple device example
/sbin/e2fsck -yf /dev/sda1
/sbin/resize2fs /dev/sda1 50G
/sbin/e2fsck -yf /dev/sda1
Сначала копируем e2fsck и resize2fs в initramfs, потом запускаем проверку и уменьшение раздела.
Дальше нам нужно собрать новый initramfs с добавленными хуками. Для этого надо посмотреть список доступных ядер и собрать образ на основе одного из них. Возьму для примера самое свежее:
# ls /boot | grep configconfig-6.1.0-12-amd64config-6.1.0-13-amd64config-6.1.0-20-amd64config-6.1.0-22-amd64# update-initramfs -u -k 6.1.0-22-amd64update-initramfs: Generating /boot/initrd.img-6.1.0-22-amd64Ошибок быть не должно. Можно перезагружаться. Для того, чтобы наблюдать процесс, можно подключиться к консоли виртуалки. Если что-то пойдёт не так, то при повторной загрузке можно выбрать другое ядро, где initrams не меняли.
Способ рабочий. Я проверил несколько раз на тестовых виртуалках. Например, взял раздел 50G и ужал его до 5G, при том, что данных там было 3.2G. На проде рисковать не хочется. Не рекомендую такое проделывать, если есть какие-то другие варианты. Трогать файловую систему - опасная процедура.
Придумал я всё это не сам, подсмотрел вот тут:
⇨ https://serverfault.com/questions/528075/is-it-possible-to-on-line-shrink-a-ext4-volume-with-lvm
Раньше не знал, что с initramfs можно проделывать такие трюки, причём относительно просто. Для этого заметку и написал, чтобы поделиться информацией. Можно что-то ещё туда добавить и исполнить. Правда сходу не придумал, что это может быть. Может у вас есть идеи?
#linux
Если я где-то упоминаю о том, что настроил гипервизор и поднял на нём одну виртуальную машину, неизменно получаю вопросы, зачем так делать. В данном случае вроде как и смысла нет. Помню, что когда-то уже писал по этому поводу, но не смог найти заметку, поэтому пишу снова.
Итак, зачем поднимать гипервизор ради одной виртуалки? На первый взгляд логичнее всё сделать на железе и получить максимальную утилизацию ресурсов сервера. Дальше сугубо моё личное мнение. Не призываю делать именно так и не утверждаю, что это правильно.
1️⃣ Работа на гипервизоре отвязывает вас от железа. Вы без каких-либо проблем можете переехать на другой сервер с таким же гипервизором и без особых проблем на другой гипервизор. Перенести систему с железа хоть и тоже решаемая задача, но более трудоёмкая и длительная. Это существенный плюс. Просто покупаешь другой сервер и перекидываешь туда виртуалку. Никаких проблем.
2️⃣ Виртуальную машину проще бэкапить целиком с уровня гипервизора без остановки. Быстрее развернуть копию в другом месте. Удобнее автоматически проверять бэкапы. Быстрее делаются инкрементные копии. С этой стороны явные плюсы. Все гипервизоры имеют поддержку создания бэкапов со своего уровня.
3️⃣ Проще управлять ресурсами сервера. Если не занят весь диск, то возможно вам когда-то понадобится добавить виртуальные машины. Возможно нужно будет протестировать работу виртуалки в более зажатом состоянии по ресурсам, чтобы проверить, как она себя поведёт перед переездом в другое место. Может дорастёте до кластера и добавите этот гипервизор в кластер. Тут более широкое пространство для манёвра.
➖ Минус только один - вы немного теряете в производительности из-за лишней прослойки в виде виртуализации. По CPU и RAM разница минимальна, на уровне погрешности измерений. Для дисковых операций разница может быть более существенной, но не кардинально. Цифры могут сильно плавать в зависимости от гипервизоров, файловых систем, типов дисков и т.д. Если взять LXC контейнер, то там накладных расходов ещё меньше, практически нет. Но переносимость у такой системы будет хуже.
Таким образом, я уже очень давно всю полезную нагрузку запускаю только и исключительно в виртуальных машинах. Ничего на железо, кроме гипервизора, не ставлю, даже если одна виртуалка будет утилизировать все ресурсы сервера.
#виртуализация
Итак, зачем поднимать гипервизор ради одной виртуалки? На первый взгляд логичнее всё сделать на железе и получить максимальную утилизацию ресурсов сервера. Дальше сугубо моё личное мнение. Не призываю делать именно так и не утверждаю, что это правильно.
1️⃣ Работа на гипервизоре отвязывает вас от железа. Вы без каких-либо проблем можете переехать на другой сервер с таким же гипервизором и без особых проблем на другой гипервизор. Перенести систему с железа хоть и тоже решаемая задача, но более трудоёмкая и длительная. Это существенный плюс. Просто покупаешь другой сервер и перекидываешь туда виртуалку. Никаких проблем.
2️⃣ Виртуальную машину проще бэкапить целиком с уровня гипервизора без остановки. Быстрее развернуть копию в другом месте. Удобнее автоматически проверять бэкапы. Быстрее делаются инкрементные копии. С этой стороны явные плюсы. Все гипервизоры имеют поддержку создания бэкапов со своего уровня.
3️⃣ Проще управлять ресурсами сервера. Если не занят весь диск, то возможно вам когда-то понадобится добавить виртуальные машины. Возможно нужно будет протестировать работу виртуалки в более зажатом состоянии по ресурсам, чтобы проверить, как она себя поведёт перед переездом в другое место. Может дорастёте до кластера и добавите этот гипервизор в кластер. Тут более широкое пространство для манёвра.
➖ Минус только один - вы немного теряете в производительности из-за лишней прослойки в виде виртуализации. По CPU и RAM разница минимальна, на уровне погрешности измерений. Для дисковых операций разница может быть более существенной, но не кардинально. Цифры могут сильно плавать в зависимости от гипервизоров, файловых систем, типов дисков и т.д. Если взять LXC контейнер, то там накладных расходов ещё меньше, практически нет. Но переносимость у такой системы будет хуже.
Таким образом, я уже очень давно всю полезную нагрузку запускаю только и исключительно в виртуальных машинах. Ничего на железо, кроме гипервизора, не ставлю, даже если одна виртуалка будет утилизировать все ресурсы сервера.
#виртуализация
Открытый практикум Linux by Rebrain: HTTP-клиенты для Linux
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
24 Июля (Среда) в 19:00 по МСК
Программа практикума:
🔹Познакомимся с HTTP-клиентами: curl, httpie и другими
🔹Изучим отладочные опции
🔹Рассмотрим передачу параметров запроса к серверу
Кто ведёт?
Даниил Батурин – Основатель проекта VyOS. Основатель проекта VyOS, системы для корпоративных и провайдерских маршрутизаторов с открытым исходным кодом.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2Vtzqw86Gsj
Успевайте зарегистрироваться. Количество мест строго ограничено! Запись практикума “DevOps by Rebrain” в подарок за регистрацию!
👉Регистрация
Время проведения:
24 Июля (Среда) в 19:00 по МСК
Программа практикума:
🔹Познакомимся с HTTP-клиентами: curl, httpie и другими
🔹Изучим отладочные опции
🔹Рассмотрим передачу параметров запроса к серверу
Кто ведёт?
Даниил Батурин – Основатель проекта VyOS. Основатель проекта VyOS, системы для корпоративных и провайдерских маршрутизаторов с открытым исходным кодом.
Бесплатные практикумы по DevOps, Linux, Networks и Golang от REBRAIN каждую неделю. Подключайтесь!
Реклама. ООО "РЕБРЕИН". ИНН 7727409582 erid: 2Vtzqw86Gsj
Если вы используете динамический размер дисков под виртуальные машины, то рано или поздно возникнет ситуация, когда реально внутри VM данных будет условно 50 ГБ, а динамический диск размером в 100 ГБ будет занимать эти же 100 ГБ на гипервизоре.
Я раньше решал эту задачу для HyperV и виртуалок с Linux. Сейчас уже не помню точную реализацию, но смысл был в том, что незанятое пространство внутри VM надо было принудительно заполнить нулями и выполнить что-то со стороны гипервизора. Помню виртуалку в 500 ГБ, где реально использовалось 40 ГБ. Она была очень критичная, там был самописный call центр на базе Elastix. Интересно, кто-нибудь помнит его? Хороший был продукт для VOIP. Так вот, эта виртуалка занимала на диске гипервизора реальные 500 ГБ и не получалось её перенести в доступное для этого окно. Call центр почти круглые сутки работал. Ужать по размеру диска её не получилось, но когда она стала занимать реальные 40 ГБ, переносить её стало значительно проще и быстрее.
С Proxmox сейчас стало всё намного проще. Никаких ручных действий. Если у вас в виртуалках динамические диски, а это иногда оправданно для экономии места, когда есть возможность расселять виртуалки, когда на гипервизоре заканчивается место (так делают почти все хостеры VPS), то достаточно выполнить пару простых действий, чтобы виртуалки занимали тот объём, сколько реальных данных там есть.
Для этого можно воспользоваться официальным руководством:
⇨ Shrink Qcow2 Disk Files
Достаточно указать тип дискового контроллера Virtio-SCSI, а для самого диска установить параметр Discard. После этого внутри VM с Linux выполнить команду:
Все современные дистрибутивы Linux имеют systemd службу с fstrim и таймер для запуска. Диск на самом гипервизоре ужмётся до реального размера данных внутри VM. Проверить это можно так:
Если внутри витуалки добавить занимаемый объём, то это сразу же будет видно на гипервизоре:
Смотрим ещё раз на файл диска:
Удаляем в виртуалке файл:
Смотрим на размер диска:
Ничего не поменялось. А если сделаем fstrim внутри VM, реальный размер диска уменьшится.
То же самое можно сделать и с уровня гипервизора, но для этого нужно будет выключить виртуальную машину, что неудобно, но иногда тоже может пригодиться. Это можно сделать с помощью утилиты virt-sparsify из комплекта libguests-tools:
Для успешной работы этой команды, на диске гипервизора должно быть место для создания копии образа диска, так как по факту команда делает копию, работает с ней и потом заменяет основной файл.
#proxmox #виртуализация
Я раньше решал эту задачу для HyperV и виртуалок с Linux. Сейчас уже не помню точную реализацию, но смысл был в том, что незанятое пространство внутри VM надо было принудительно заполнить нулями и выполнить что-то со стороны гипервизора. Помню виртуалку в 500 ГБ, где реально использовалось 40 ГБ. Она была очень критичная, там был самописный call центр на базе Elastix. Интересно, кто-нибудь помнит его? Хороший был продукт для VOIP. Так вот, эта виртуалка занимала на диске гипервизора реальные 500 ГБ и не получалось её перенести в доступное для этого окно. Call центр почти круглые сутки работал. Ужать по размеру диска её не получилось, но когда она стала занимать реальные 40 ГБ, переносить её стало значительно проще и быстрее.
С Proxmox сейчас стало всё намного проще. Никаких ручных действий. Если у вас в виртуалках динамические диски, а это иногда оправданно для экономии места, когда есть возможность расселять виртуалки, когда на гипервизоре заканчивается место (так делают почти все хостеры VPS), то достаточно выполнить пару простых действий, чтобы виртуалки занимали тот объём, сколько реальных данных там есть.
Для этого можно воспользоваться официальным руководством:
⇨ Shrink Qcow2 Disk Files
Достаточно указать тип дискового контроллера Virtio-SCSI, а для самого диска установить параметр Discard. После этого внутри VM с Linux выполнить команду:
# fstrim -avВсе современные дистрибутивы Linux имеют systemd службу с fstrim и таймер для запуска. Диск на самом гипервизоре ужмётся до реального размера данных внутри VM. Проверить это можно так:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 1.32 GiBcluster_size: 65536Если внутри витуалки добавить занимаемый объём, то это сразу же будет видно на гипервизоре:
# dd if=/dev/urandom of=testfile bs=1M count=2048Смотрим ещё раз на файл диска:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 3.32 GiBcluster_size: 65536Удаляем в виртуалке файл:
# rm testfileСмотрим на размер диска:
# qemu-img info vm-100-disk-0.qcow2image: vm-100-disk-0.qcow2file format: qcow2virtual size: 20 GiB (21474836480 bytes)disk size: 3.32 GiBcluster_size: 65536Ничего не поменялось. А если сделаем fstrim внутри VM, реальный размер диска уменьшится.
То же самое можно сделать и с уровня гипервизора, но для этого нужно будет выключить виртуальную машину, что неудобно, но иногда тоже может пригодиться. Это можно сделать с помощью утилиты virt-sparsify из комплекта libguests-tools:
# virt-sparsify --in-place vm-100-disk-0.qcow2Для успешной работы этой команды, на диске гипервизора должно быть место для создания копии образа диска, так как по факту команда делает копию, работает с ней и потом заменяет основной файл.
#proxmox #виртуализация