
Бэкап Шрёдингера
☝ Состояние любого бэкапа остаётся неизвестным до того, как его попробуют восстановить.
Услышал прикольную шутку. Даже любопытно стало почитать подробности оригинального мысленного эксперимента Шрёдингера с котом. Проникся. Для бэкапов этот эксперимент очень актуален. Бэкапы реально находятся в состоянии Шрёдингера до тех пор, пока не попытаешься выполнить восстановление. До этого они существуют и не существуют одновременно, так как если восстановить данные не получится, то это и не бэкап был.
Провели мысленный эксперимент со своими бэкапами?
#мем
☝ Состояние любого бэкапа остаётся неизвестным до того, как его попробуют восстановить.
Услышал прикольную шутку. Даже любопытно стало почитать подробности оригинального мысленного эксперимента Шрёдингера с котом. Проникся. Для бэкапов этот эксперимент очень актуален. Бэкапы реально находятся в состоянии Шрёдингера до тех пор, пока не попытаешься выполнить восстановление. До этого они существуют и не существуют одновременно, так как если восстановить данные не получится, то это и не бэкап был.
Провели мысленный эксперимент со своими бэкапами?
#мем
{kind=link}
Для тех, кто не знает, расскажу, что у меня на сайте есть статьи, где в одном месте собраны заметки по различным темам: бэкапы, мониторинг и т.д. Я наконец-то сделал отдельный раздел для них. А также полностью актуализировал, добавив свежие заметки за последний год.
▪ Топ бесплатных программ для бэкапа
▪ Топ бесплатных систем мониторинга
▪ Топ бесплатных HelpDesk систем
▪ Топ программ для инвентаризации оборудования
▪ Топ бесплатных программ для удалённого доступа
▪ Хостеры, личная рекомендация
Когда изначально делал подборки, не учёл, что буду их обновлять, поэтому цифры в названиях топа неактуальны. Программ стало значительно больше.
Подобные списки удобны, если первый раз подбираете продукт. Можно быстро оценить основные различия, посмотреть скриншоты программ. Плюс, к каждому описанию есть ссылка на заметку в канале с обсуждением, где много содержательных комментариев по теме.
#подборка
▪ Топ бесплатных программ для бэкапа
▪ Топ бесплатных систем мониторинга
▪ Топ бесплатных HelpDesk систем
▪ Топ программ для инвентаризации оборудования
▪ Топ бесплатных программ для удалённого доступа
▪ Хостеры, личная рекомендация
Когда изначально делал подборки, не учёл, что буду их обновлять, поэтому цифры в названиях топа неактуальны. Программ стало значительно больше.
Подобные списки удобны, если первый раз подбираете продукт. Можно быстро оценить основные различия, посмотреть скриншоты программ. Плюс, к каждому описанию есть ссылка на заметку в канале с обсуждением, где много содержательных комментариев по теме.
#подборка
{kind=link}
У меня в управлении много различных серверов. Я обычно не заморачивался с типом файловых систем. Выбирал то, что сервер ставит по умолчанию. Для серверов общего назначения особо нет разницы, будет это XFS или EXT4. А выбор обычно из них стоит. RPM дистрибутивы используют по умолчанию XFS, а DEB — EXT4.
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
Она вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
# mountОна вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
df есть нужный ключ:# df -TFilesystem Type 1K-blocks Used Available Use% Mounted onudev devtmpfs 1988408 0 1988408 0% /devtmpfs tmpfs 401244 392 400852 1% /run/dev/sda2 ext4 19948144 2548048 16361456 14% /tmpfs tmpfs 2006220 0 2006220 0% /dev/shmtmpfs tmpfs 5120 0 5120 0% /run/lock/dev/sda1 vfat 523244 5928 517316 2% /boot/efitmpfs tmpfs 401244 0 401244 0% /run/user/0И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
{kind=link}
Расскажу про известный сервис Cloudflare, который несмотря на все санкции, Россию не покинул, а продолжает оказывать услуги. Не знаю, что там с платными тарифами, и каким образом можно произвести оплату. Я использую бесплатный тариф, который у него не меняется уже много лет. Как-то серьезно привязываться к этому сервису не рекомендую в силу очевидных рисков, так как это американская компания. Но где-то по мелочи можно закрыть некоторые потребности, так как сервис удобный.
Я не буду его подробно описывать, так как специально не разбирался в его возможностях. Расскажу, как и для чего я его использую сам в одном из проектов.
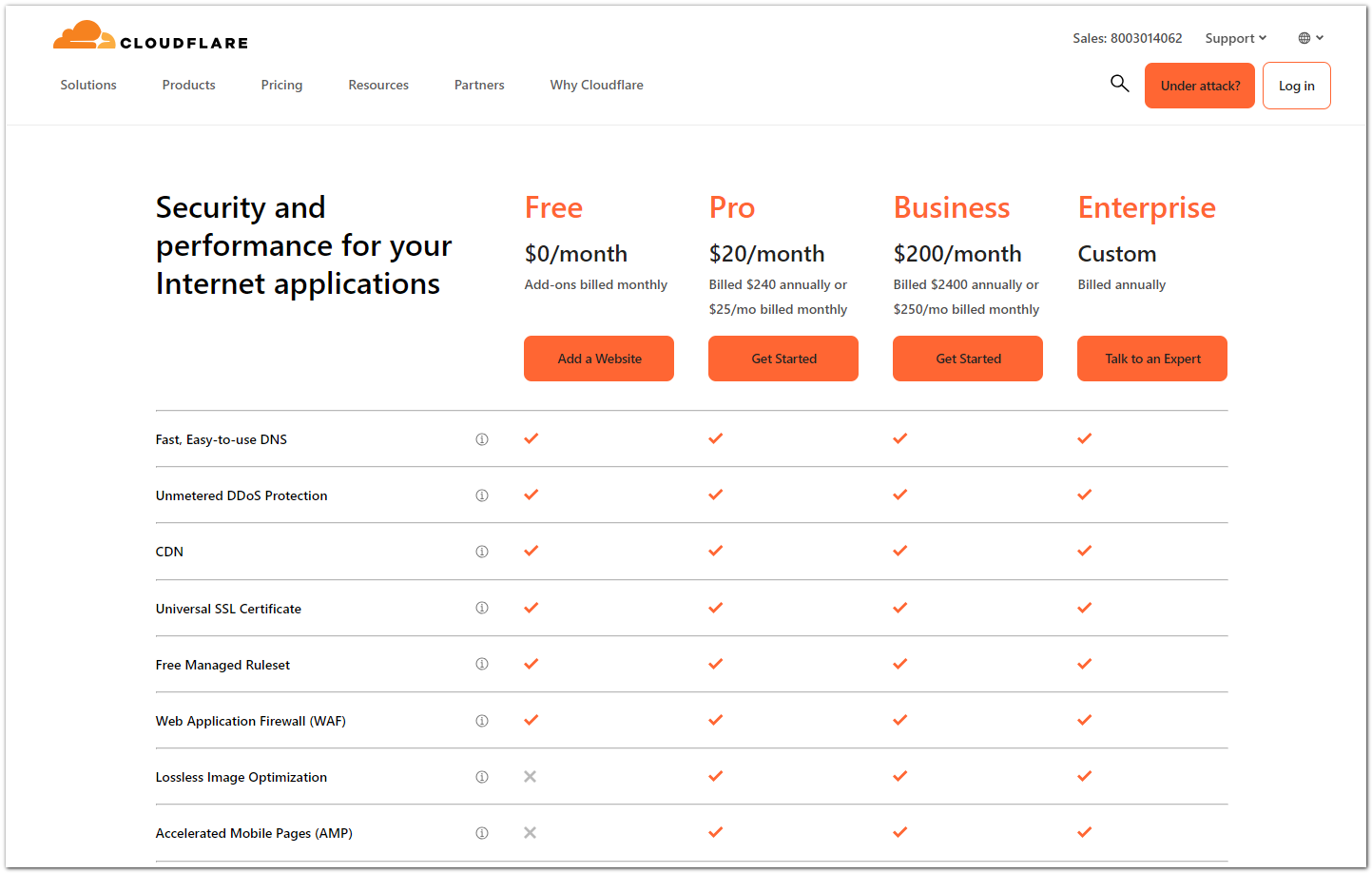
С помощью бесплатного тарифа Cloudflare можно использовать:
1️⃣ Бесплатные DNS сервера. Вы можете перенести управление своими доменами на DNS серверы Cloudflare.
2️⃣ DDOS защиту. Я не знаю, до какого масштаба ддоса можно пользоваться бесплатным тарифом, но от всех видов атак, с которыми сталкивался я, Cloudflare помогал. Но это были местечковые сайты, которые возможно случайно или без особого умысла ддосили.
3️⃣ Бесплатные TLS сертификаты. Включая ddos защиту для сайта, вы автоматически получаете TLS сертификаты, которые вообще не надо настраивать. Cloudflare всё делает сам.
4️⃣ Web Application Firewall (WAF). Бесплатный тарифный план также включает в себя некоторые возможности WAF.
В итоге получается вот что. У меня есть несколько старых сайтов, которые давно никто не обновляет и не обслуживает. Они располагаются на веб сервере организации, где на тех же IP адресах живут другие сервисы. Всё это не хочется светить в интернете.
Я для них подключил DDOS защиту, скрыл их реальные IP адреса. С помощью бесплатного тарифного плана можно скрыть связность сайтов, живущих на одном и том же сервере, так как Cloudflare скрывает реальные IP адреса, на которых хостятся сайты. На веб сервере запросы на 80-й порт разрешены только с серверов Cloudflare. Весь входящий трафик приходит на Cloudflare, где активны бесплатные TLS сертификаты. Настраивать их и как-то следить за актуальностью не надо. Сервис всё это делает сам.
Плюс Cloudflare защищает с помощью WAF от многих типовых и массовых атак, которые могут осуществляться по известным уязвимостям. На выходе я имею старый веб сервер со старыми сайтами на древней версии php. Веб сервер полностью скрыт от интернета, трафик к нему фильтруется и приходит чистым от ddos и многих уязвимостей. Для надёжности на входящей стороне у меня стоит сначала Nginx свежих версий, который регулярно обновляется, а потом уже старый веб сервер, который обновить нельзя из-за древних версий php.
В сумме получается удобно. Тут тебе и DNS, и TLS, и Antiddos, и всё в одном месте, и настраивать не надо. Достаточно через настройки DNS направить весь трафик в CF, а всё остальное сделать через веб интерфейс.
❗️Почти на 100% уверен, что Cloudflare шпионит за сайтами, пользователями и собирает биг дату, иначе зачем ему устраивать аттракцион такой щедрости. Так что имейте это ввиду и принимайте решение об использовании с учётом этого нюанса.
#сервис #бесплатно
Я не буду его подробно описывать, так как специально не разбирался в его возможностях. Расскажу, как и для чего я его использую сам в одном из проектов.
С помощью бесплатного тарифа Cloudflare можно использовать:
1️⃣ Бесплатные DNS сервера. Вы можете перенести управление своими доменами на DNS серверы Cloudflare.
2️⃣ DDOS защиту. Я не знаю, до какого масштаба ддоса можно пользоваться бесплатным тарифом, но от всех видов атак, с которыми сталкивался я, Cloudflare помогал. Но это были местечковые сайты, которые возможно случайно или без особого умысла ддосили.
3️⃣ Бесплатные TLS сертификаты. Включая ddos защиту для сайта, вы автоматически получаете TLS сертификаты, которые вообще не надо настраивать. Cloudflare всё делает сам.
4️⃣ Web Application Firewall (WAF). Бесплатный тарифный план также включает в себя некоторые возможности WAF.
В итоге получается вот что. У меня есть несколько старых сайтов, которые давно никто не обновляет и не обслуживает. Они располагаются на веб сервере организации, где на тех же IP адресах живут другие сервисы. Всё это не хочется светить в интернете.
Я для них подключил DDOS защиту, скрыл их реальные IP адреса. С помощью бесплатного тарифного плана можно скрыть связность сайтов, живущих на одном и том же сервере, так как Cloudflare скрывает реальные IP адреса, на которых хостятся сайты. На веб сервере запросы на 80-й порт разрешены только с серверов Cloudflare. Весь входящий трафик приходит на Cloudflare, где активны бесплатные TLS сертификаты. Настраивать их и как-то следить за актуальностью не надо. Сервис всё это делает сам.
Плюс Cloudflare защищает с помощью WAF от многих типовых и массовых атак, которые могут осуществляться по известным уязвимостям. На выходе я имею старый веб сервер со старыми сайтами на древней версии php. Веб сервер полностью скрыт от интернета, трафик к нему фильтруется и приходит чистым от ddos и многих уязвимостей. Для надёжности на входящей стороне у меня стоит сначала Nginx свежих версий, который регулярно обновляется, а потом уже старый веб сервер, который обновить нельзя из-за древних версий php.
В сумме получается удобно. Тут тебе и DNS, и TLS, и Antiddos, и всё в одном месте, и настраивать не надо. Достаточно через настройки DNS направить весь трафик в CF, а всё остальное сделать через веб интерфейс.
❗️Почти на 100% уверен, что Cloudflare шпионит за сайтами, пользователями и собирает биг дату, иначе зачем ему устраивать аттракцион такой щедрости. Так что имейте это ввиду и принимайте решение об использовании с учётом этого нюанса.
#сервис #бесплатно
{kind=link}
В своей практике во времена поддержки офисов, когда я работал как аутсорсер, пару раз сталкивался с ситуациями, когда у заказчиков воровали диски. Первую историю мне рассказали, когда я спросил, зачем вам зашифрованный корень на Linux. Оказалось, что у них приходящий админ стащил один из дисков hot-swap в сервере. Там был raid1, так что пропажу не сразу заметили. А он, судя по всему, знал, что уведомлений никаких нет, поэтому тиснул диск.
У другого заказчика кто-то стащил внешний USB диск, который использовался для бэкапов. Компания не очень большая, серверная (небольшая стойка) была не закрыта. Кто-то зашёл и забрал диск. После этого перенесли всё в отдельное помещение и стали закрывать. А до этого оборудование стояло в подсобном помещении в закутке без дверей.
Когда есть риск, что ваше хранилище с данными могут украсть, имеет смысл его зашифровать. Тут проще всего использовать LUKS (Linux Unified Key Setup), с помощью которого можно зашифровать раздел, а потом работать с ним как с обычной файловой системой.
Кратко покажу, как выглядит работа с LUKS. Устанавливаем в Debian:
Шифруем отдельный раздел. Если подключили чистый диск, то сначала этот раздел создайте с помощью
Подключаем этот раздел к системе, указывая любое имя:
В разделе
Я такие крайности не очень люблю, поэтому показываю на примере EXT4:
Теперь если кто-то тиснет диск, то не увидит его содержимое. Диск расшифровывается после команды
Для внешних устройств, которые используются как хранилища бэкапов, очень рекомендуется так делать. Можно не шифровать сами данные, которые на них льются, если не боитесь раздать их по дороге. Так как LUKS позволяет работать с шифрованным разделом, как с обычным блочным устройством, можно без проблем настроить шифрованный бэкап сервер. Например, собрать из нескольких дисков любой mdadm массив, зашифровать его и подключить к системе. А если потом нужны разные разделы на шифрованном диске, пустить поверх LVM и разбить этот массив на логические разделы.
#linux #security
У другого заказчика кто-то стащил внешний USB диск, который использовался для бэкапов. Компания не очень большая, серверная (небольшая стойка) была не закрыта. Кто-то зашёл и забрал диск. После этого перенесли всё в отдельное помещение и стали закрывать. А до этого оборудование стояло в подсобном помещении в закутке без дверей.
Когда есть риск, что ваше хранилище с данными могут украсть, имеет смысл его зашифровать. Тут проще всего использовать LUKS (Linux Unified Key Setup), с помощью которого можно зашифровать раздел, а потом работать с ним как с обычной файловой системой.
Кратко покажу, как выглядит работа с LUKS. Устанавливаем в Debian:
# apt install cryptsetupШифруем отдельный раздел. Если подключили чистый диск, то сначала этот раздел создайте с помощью
fdisk или parted.# cryptsetup luksFormat /dev/sdb1Подключаем этот раздел к системе, указывая любое имя:
# cryptsetup luksOpen /dev/sdb1 lukscryptВ разделе
/dev/mapper появится устройство lukscrypt. Дальше с ним можно работать, как с обычным устройством. Например, сделать LVM раздел или сразу же файловую систему создать. При желании, с помощью LUKS и BTRFS можно и корневой раздел поднять на этой связке. Видел такие инструкции для рабочего ноута. Для загрузки нужно будет интерактивно пароль вводить. Я такие крайности не очень люблю, поэтому показываю на примере EXT4:
# mkfs.ext4 /dev/mapper/lukscrypt# mkdir /mnt/crypt# mount /dev/mapper/lukscrypt /mnt/cryptТеперь если кто-то тиснет диск, то не увидит его содержимое. Диск расшифровывается после команды
cryptsetup luksOpen. После этого его можно смонтировать в систему и прочитать данные.Для внешних устройств, которые используются как хранилища бэкапов, очень рекомендуется так делать. Можно не шифровать сами данные, которые на них льются, если не боитесь раздать их по дороге. Так как LUKS позволяет работать с шифрованным разделом, как с обычным блочным устройством, можно без проблем настроить шифрованный бэкап сервер. Например, собрать из нескольких дисков любой mdadm массив, зашифровать его и подключить к системе. А если потом нужны разные разделы на шифрованном диске, пустить поверх LVM и разбить этот массив на логические разделы.
#linux #security
{kind=link}
Я написал очень подробный обзор нового почтового сервера от ГК Астра — RuPost:
⇨ Установка и настройка почтового сервера RuPost
Описал основные возможности, сделал пошаговую инструкцию по базовой настройке, подключился различными клиентами. Статья позволит получить общее представление, что это за система, из чего состоит и как с ней работать. В статье много пояснений и картинок для этого.
Кратко скажу следующее:
▪ RuPost построен на базе open source решений: haproxy, postfix, dovecot, sogo и др.
▪ Установка в несколько действий в консоли (установка deb пакета), управление в браузере через самописную админку.
▪ Поддерживается только ОС Astra 1.7.
▪ Интеграция и одновременная работа с несколькими службами каталогов – ALD Pro, Active Directory, FreeIPA.
▪ Почта хранится в формате maildir.
▪ Есть возможность организовать HA cluster.
▪ Настройка системы выполняется на основе шаблонов конфигураций, которые можно готовить заранее, сохранять, выгружать. Есть несколько готовых шаблонов от разработчиков. Формат шаблонов YAML.
▪ RuPost поддерживает общие адресные книги и календари.
▪ Есть механизм миграции с сервера Microsoft Exchange, есть плагин для MS Outlook для работы с календарями и адресными книгами в RuPost. Есть механизм работы одновременно с Exchange, чтобы выполнить поэтапный переход от одного сервера к другому.
Если всё аккуратно настроить, то получается удобный почтовый сервер с автоматической настройкой пользователей. Я проверял на примере Active Directory. Интеграция настраивается легко и быстро. Потом доменный пользователь без проблем запускает клиента, получает все настройки автоматически и работает с почтой через встроенную аутентификацию.
❗️Сразу скажу, что цен в открытом доступе нет и мне их не сообщили. Только по запросу. Так что обсуждать их не представляется возможным. Лицензирование по конечным пользователям. Сколько пользователей, столько надо лицензий. Сами сервера и подключения к ним не лицензируются.
#mailserver #отечественное
⇨ Установка и настройка почтового сервера RuPost
Описал основные возможности, сделал пошаговую инструкцию по базовой настройке, подключился различными клиентами. Статья позволит получить общее представление, что это за система, из чего состоит и как с ней работать. В статье много пояснений и картинок для этого.
Кратко скажу следующее:
▪ RuPost построен на базе open source решений: haproxy, postfix, dovecot, sogo и др.
▪ Установка в несколько действий в консоли (установка deb пакета), управление в браузере через самописную админку.
▪ Поддерживается только ОС Astra 1.7.
▪ Интеграция и одновременная работа с несколькими службами каталогов – ALD Pro, Active Directory, FreeIPA.
▪ Почта хранится в формате maildir.
▪ Есть возможность организовать HA cluster.
▪ Настройка системы выполняется на основе шаблонов конфигураций, которые можно готовить заранее, сохранять, выгружать. Есть несколько готовых шаблонов от разработчиков. Формат шаблонов YAML.
▪ RuPost поддерживает общие адресные книги и календари.
▪ Есть механизм миграции с сервера Microsoft Exchange, есть плагин для MS Outlook для работы с календарями и адресными книгами в RuPost. Есть механизм работы одновременно с Exchange, чтобы выполнить поэтапный переход от одного сервера к другому.
Если всё аккуратно настроить, то получается удобный почтовый сервер с автоматической настройкой пользователей. Я проверял на примере Active Directory. Интеграция настраивается легко и быстро. Потом доменный пользователь без проблем запускает клиента, получает все настройки автоматически и работает с почтой через встроенную аутентификацию.
❗️Сразу скажу, что цен в открытом доступе нет и мне их не сообщили. Только по запросу. Так что обсуждать их не представляется возможным. Лицензирование по конечным пользователям. Сколько пользователей, столько надо лицензий. Сами сервера и подключения к ним не лицензируются.
#mailserver #отечественное
Server Admin
Установка и настройка почтового сервера RuPost
Пошаговое руководство по установке и настройке почтового сервера RuPost, в том числе подключение клиентов, календарей, адресных книг.
К вчерашней заметке про CF как здесь, так и в VK, возникло обсуждение скрытия/раскрытия настоящего IP адреса веб сервера. Насколько я знаю, через нормальную защиту от ddos узнать IP адрес веб сервера нереально. Поясню на пальцах, как работает защита от ddos.
Если вас начали серьёзно ддосить и вы решили спрятаться за защиту, то действовать вы должны следующим образом:
1️⃣ Закрываете все входящие запросы к серверу с помощью файрвола. Разрешаете только HTTP запросы от сети защиты. Они вам предоставят свои адреса. У CF список доступен публично.
2️⃣ Меняете внешний IP адрес веб сервера. Обычно у всех хостеров есть такая услуга. Старый IP адрес отключаете.
3️⃣ Обновляете DNS записи для вашего сайта, указывая в качестве А записи IP адреса защиты. А в самой защите прописываете проксирование на ваш новый веб сервер.
Если вы всё сделали правильно, то реальный IP адрес вашего сайта вычислить не получится. Сервис защиты следит за этим, так как это важная часть его работы.
Все известные мне способы определить реальный IP адрес сайта, чтобы ддоснуть его в обход защиты следующие:
▪ Смотрится история DNS записей домена. Если вы не изменили внешний IP адрес, то вас всё равно могут отключить, даже если вы на своём файрволе заблокировали все соединения. Если поток запросов напрямую, мимо защиты будет слишком большой, вас отключит провайдер, чтобы не нагружать чрезмерно свою инфраструктуру.
▪ По спискам проверяются поддомены. Часто люди запускают их временно без защиты, прописывают реальные IP адреса веб сервера, которые остаются в истории навсегда. Даже если вы давно отключили этот поддомен, IP адрес засвечен. Так что реальный IP адрес прода светить нигде нельзя.
▪ Часто почта отправляется напрямую веб сервером. И даже если используется сторонний SMTP сервер, по заголовкам писем всё равно можно обнаружить IP адрес веб сервера. Почистить заголовки не всегда тривиальная задача и этим надо заниматься отдельно. На этом очень легко погореть.
▪ Теоретически какие-то данные можно засветить в HTTP заголовках, но я на практике не припоминаю, чтобы это происходило. Точно не знаю, кто может выдать там реальный IP веб сервера.
Если всё сделать правильно, то вы будете надёжно защищены сервисом от ддоса и все вопросы защиты будут касаться только сервиса. Сами вы ничего не сможете и не должны будете делать, кроме корректной настройки своего сайта через проксирование, а часто и кэширование. С этим могут быть проблемы и наверняка будут.
☝ Если запускаете новый проект и сразу планируете поместить его под защиту, проследите, чтобы нигде не засветился его IP адрес. Особенно это касается DNS записей.
#ddos
Если вас начали серьёзно ддосить и вы решили спрятаться за защиту, то действовать вы должны следующим образом:
1️⃣ Закрываете все входящие запросы к серверу с помощью файрвола. Разрешаете только HTTP запросы от сети защиты. Они вам предоставят свои адреса. У CF список доступен публично.
2️⃣ Меняете внешний IP адрес веб сервера. Обычно у всех хостеров есть такая услуга. Старый IP адрес отключаете.
3️⃣ Обновляете DNS записи для вашего сайта, указывая в качестве А записи IP адреса защиты. А в самой защите прописываете проксирование на ваш новый веб сервер.
Если вы всё сделали правильно, то реальный IP адрес вашего сайта вычислить не получится. Сервис защиты следит за этим, так как это важная часть его работы.
Все известные мне способы определить реальный IP адрес сайта, чтобы ддоснуть его в обход защиты следующие:
▪ Смотрится история DNS записей домена. Если вы не изменили внешний IP адрес, то вас всё равно могут отключить, даже если вы на своём файрволе заблокировали все соединения. Если поток запросов напрямую, мимо защиты будет слишком большой, вас отключит провайдер, чтобы не нагружать чрезмерно свою инфраструктуру.
▪ По спискам проверяются поддомены. Часто люди запускают их временно без защиты, прописывают реальные IP адреса веб сервера, которые остаются в истории навсегда. Даже если вы давно отключили этот поддомен, IP адрес засвечен. Так что реальный IP адрес прода светить нигде нельзя.
▪ Часто почта отправляется напрямую веб сервером. И даже если используется сторонний SMTP сервер, по заголовкам писем всё равно можно обнаружить IP адрес веб сервера. Почистить заголовки не всегда тривиальная задача и этим надо заниматься отдельно. На этом очень легко погореть.
▪ Теоретически какие-то данные можно засветить в HTTP заголовках, но я на практике не припоминаю, чтобы это происходило. Точно не знаю, кто может выдать там реальный IP веб сервера.
Если всё сделать правильно, то вы будете надёжно защищены сервисом от ддоса и все вопросы защиты будут касаться только сервиса. Сами вы ничего не сможете и не должны будете делать, кроме корректной настройки своего сайта через проксирование, а часто и кэширование. С этим могут быть проблемы и наверняка будут.
☝ Если запускаете новый проект и сразу планируете поместить его под защиту, проследите, чтобы нигде не засветился его IP адрес. Особенно это касается DNS записей.
#ddos
{kind=link}
В комментариях к заметке, где я рассказывал про неудобочитаемый вывод mount один человек посоветовал утилиту column, про которую я раньше вообще не слышал и не видел, чтобы ей пользовались. Не зря говорят: "Век живи, век учись". Ведение канала и сайта очень развивает. Иногда, когда пишу новый текст по трудной теме, чувствую, как шестерёнки в голове скрипят и приходится напрягаться. Это реально развивает мозг и поддерживает его в тонусе.
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
Получается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
Получается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
# mount | column -tПолучается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
# column -s ":" -t /etc/passwdПолучается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
# column -s ":" -t /etc/passwd | awk '{print $1}'Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
{kind=link}
Информация для пользователей Windows. Когда я перешёл на Windows 11, очень не нравилась панель задач. Меня не устраивали два момента:
1️⃣ Панель задач нельзя перенести на правую сторону. Я очень привык держать панель справа. Современные мониторы и экраны ноутбуков вытянуты по горизонтали. Для того, чтобы рабочая зона была больше по вертикали, особенно при просмотре веб сайтов, очевидно, что лучше панель задач перенести куда-то на боковую сторону. Я это практиковал много лет. В Windows 11 очень не хватало такой возможности.
2️⃣ Мне не нравится, когда на панели задач только значки. Более того, в Windows 11 эти значки, когда активны, слабо выделены. Я уже привык и смирился с этим, но по прежнему не считаю это удобным.
И вот случилось чудо. Я попробовал программу StartAllBack, которая решила все мои задачи.
Меню Пуск и панель задач стали именно такими, 1 в 1, как нужно мне, как я привык и считаю удобным.
Программа платная, стоит недорого (~500 р.) Триал на 100 дней, пока работает он. На сайте увидел возможность оплаты через paypal, который с РФ не работает, и прямой перевод на карту. Надеюсь, последний вариант сработает. Если нет, буду как-то решать, но пользоваться уже не перестану.
#windows
1️⃣ Панель задач нельзя перенести на правую сторону. Я очень привык держать панель справа. Современные мониторы и экраны ноутбуков вытянуты по горизонтали. Для того, чтобы рабочая зона была больше по вертикали, особенно при просмотре веб сайтов, очевидно, что лучше панель задач перенести куда-то на боковую сторону. Я это практиковал много лет. В Windows 11 очень не хватало такой возможности.
2️⃣ Мне не нравится, когда на панели задач только значки. Более того, в Windows 11 эти значки, когда активны, слабо выделены. Я уже привык и смирился с этим, но по прежнему не считаю это удобным.
И вот случилось чудо. Я попробовал программу StartAllBack, которая решила все мои задачи.
> winget install startallbackМеню Пуск и панель задач стали именно такими, 1 в 1, как нужно мне, как я привык и считаю удобным.
Программа платная, стоит недорого (~500 р.) Триал на 100 дней, пока работает он. На сайте увидел возможность оплаты через paypal, который с РФ не работает, и прямой перевод на карту. Надеюсь, последний вариант сработает. Если нет, буду как-то решать, но пользоваться уже не перестану.
#windows
{kind=link}
Среди всех инструментов для управления удалёнными компьютерами есть один, который сильно отличается от остальных - Parsec. Я, честно говоря, про него вообще не слышал, пока несколько раз не увидел упоминания в комментариях к тематическим заметкам. Решил это исправить и попробовать.
Parsec изначально разрабатывался для с прицелом на высокую производительность, чтобы можно было в том числе играть в игры на удалённом компьютере. Работает на всех популярных ОС (Windows, MacOS, Linux и Android). Можно подключаться как через отдельное приложение, так и через браузер.
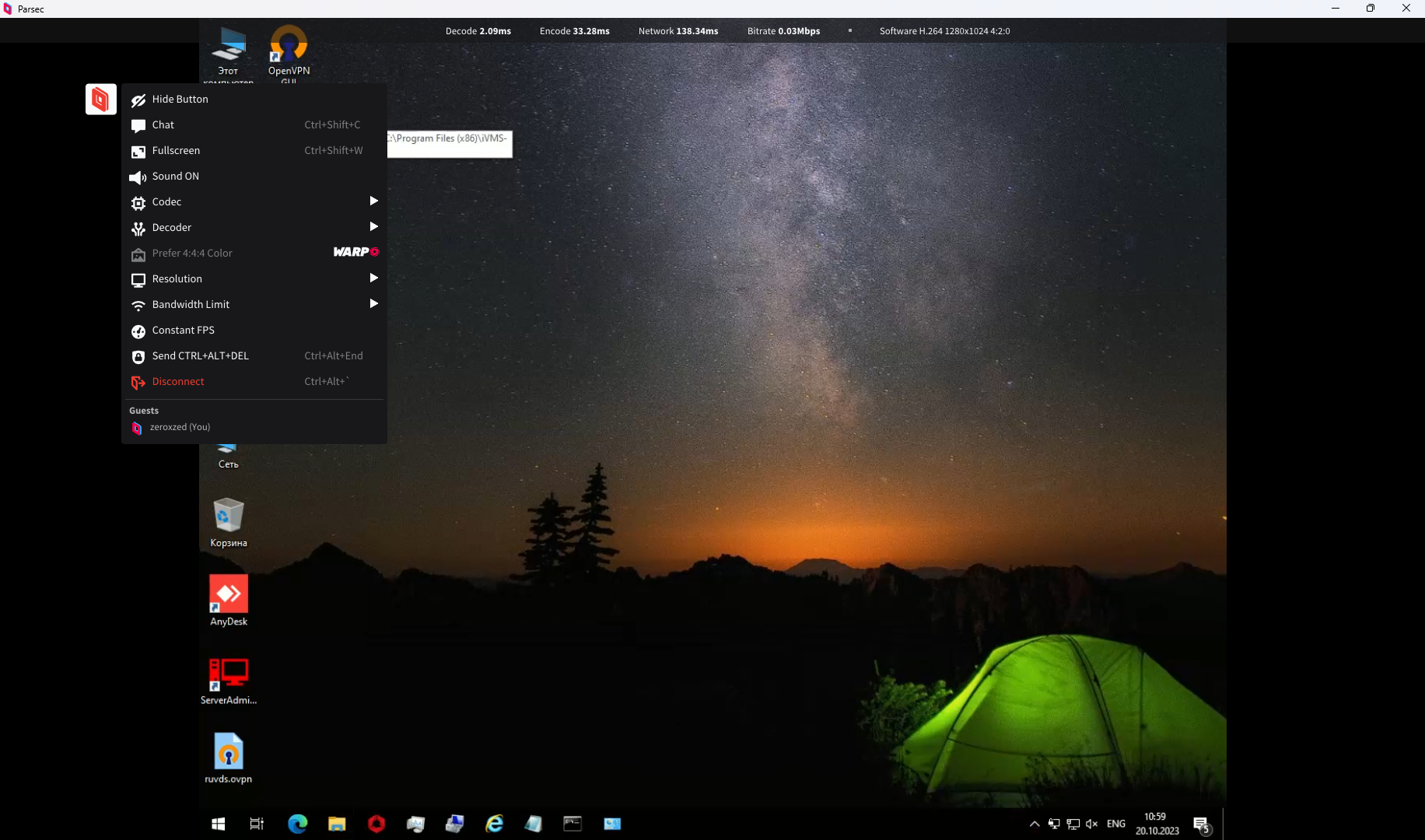
Основной принцип работы Parsec в том, что он захватывает необработанные кадры рабочего стола, кодирует их, отправляет по сети и декодирует на приёмнике. Для сжатия использует известные кодеки H.264 и H.265, а в качестве ресурсов может задействовать видеокарту. Если её нет, то используется программное декодирование на ресурсах процессора.
В игры я не играю, так что проверить их не смог. Но есть у меня видеосервер с камерами. Если открыть приложение с live потоком, то тормоза будут знатные, чем бы ты не подключался: rdp, anydesk, getscreen. Поставил туда Parsec и подключился. Я бы впечатлён. Он реально работает быстро и отзывчиво. Картинка с камер обновляется бодро, проверить можно по часам на каждой камере. Видно обновление каждой секунды. И при этом поток занимает примерно мегабит, когда я открыл экран с тремя камерами.
Parsec работает в виде сервиса с различными тарифными планами. Есть и бесплатный с самыми базовыми возможностями: поддерживается один монитор и одиночное подключение к компу. Насчёт устройств не увидел ограничения.
Есть только одна проблема. Судя по всему сервис соблюдает какие-то санкции, поэтому страничка с загрузкой клиента недоступна. Скачать можно через VPN, либо зайдя на эту же страницу через web.archive.org. Приложение весит буквально 3 Мб, можно скачать оттуда. Для подключения есть возможность использовать portable клиент. Дальше никаких ограничений ни с регистрацией, ни с подключением я не увидел.
Приложение классное. Странно, что я не слышал о нём раньше. Смущает только наличие ограничений с загрузкой. Как-то стрёмно с такими вводными пользоваться. Но если для личных нужд к каким-то некритичным сервисам, то пойдёт. Для своего видеосервера я приложение оставил, буду пользоваться. Там ничего критичного нет. Стоит в отдельной сетке с подключением по 4G.
⇨ Сайт
#remote
Parsec изначально разрабатывался для с прицелом на высокую производительность, чтобы можно было в том числе играть в игры на удалённом компьютере. Работает на всех популярных ОС (Windows, MacOS, Linux и Android). Можно подключаться как через отдельное приложение, так и через браузер.
Основной принцип работы Parsec в том, что он захватывает необработанные кадры рабочего стола, кодирует их, отправляет по сети и декодирует на приёмнике. Для сжатия использует известные кодеки H.264 и H.265, а в качестве ресурсов может задействовать видеокарту. Если её нет, то используется программное декодирование на ресурсах процессора.
В игры я не играю, так что проверить их не смог. Но есть у меня видеосервер с камерами. Если открыть приложение с live потоком, то тормоза будут знатные, чем бы ты не подключался: rdp, anydesk, getscreen. Поставил туда Parsec и подключился. Я бы впечатлён. Он реально работает быстро и отзывчиво. Картинка с камер обновляется бодро, проверить можно по часам на каждой камере. Видно обновление каждой секунды. И при этом поток занимает примерно мегабит, когда я открыл экран с тремя камерами.
Parsec работает в виде сервиса с различными тарифными планами. Есть и бесплатный с самыми базовыми возможностями: поддерживается один монитор и одиночное подключение к компу. Насчёт устройств не увидел ограничения.
Есть только одна проблема. Судя по всему сервис соблюдает какие-то санкции, поэтому страничка с загрузкой клиента недоступна. Скачать можно через VPN, либо зайдя на эту же страницу через web.archive.org. Приложение весит буквально 3 Мб, можно скачать оттуда. Для подключения есть возможность использовать portable клиент. Дальше никаких ограничений ни с регистрацией, ни с подключением я не увидел.
Приложение классное. Странно, что я не слышал о нём раньше. Смущает только наличие ограничений с загрузкой. Как-то стрёмно с такими вводными пользоваться. Но если для личных нужд к каким-то некритичным сервисам, то пойдёт. Для своего видеосервера я приложение оставил, буду пользоваться. Там ничего критичного нет. Стоит в отдельной сетке с подключением по 4G.
⇨ Сайт
#remote
{kind=link}
This media is not supported in your browser
VIEW IN TELEGRAM
▶️ На днях youtube подкинул в рекомендации забавный shorts. Автор неизвестный и канал у него не айтишный, но мне показался этот ролик забавным. Похоже, линуксоид делал.
https://www.youtube.com/shorts/_LShPDYLX2I
#юмор
https://www.youtube.com/shorts/_LShPDYLX2I
#юмор
Завожу очередную тему выходного дня, так как сам в выходные чаще всего провожу время с семьёй и детьми в частности. К прошлой заметке про развивающие игры для детей один из читателей оставил ссылку на проект piktomir.ru. Это бесплатная игра для детей младшего возраста.
ПиктоМир — свободно распространяемая программная система для изучения азов программирования дошкольниками и младшими школьниками. ПиктоМир позволяет ребенку "собрать" из пиктограмм на экране компьютера несложную программу, управляющую виртуальным исполнителем-роботом. ПиктоМир в первую очередь ориентирован на дошкольников, еще не умеющих писать, или на младшеклассников, не очень любящих писать.
Я поиграл со своим старшим сыном (9 лет). Ему понравилось. Насчёт дошкольников не уверен. Игра не сказать, что сильно простая. Да и в целом я не сторонник сажать за компьютер малышей.
В игре с помощью команд нужно запрограммировать последовательность действий робота, чтобы он закрасил в синий цвет неокрашенные квадраты. В игре никаких подсказок нет, так что я не сразу разобрался, что там делать. Пришлось посмотреть обзор. После него стало понятно, как играть. Начали проходить уровни.
Игра на самом деле интересна не только детям. Мне тоже понравилось проходить уровни. Судя по комментариям к игре в Яндексе, не только мне:
🗣 Очень познавательная и развивающая игра в плане программирования. Причём подходит не только для детей, как было заявлено. Даже я - программист со стажем - с трудом решаю некоторые задачки этой головоломки. Однозначно советую для развития конструктивного мышления.
🗣 Считаю неправильным называть эту программу игрой, так она носит скорее обучающий характер,чем развлекательный. Отлично подходит для начального обучения программированию, развивает логическое и пространственное мышление. Яркое оформление способствует дополнительной мотивации юных программистов.
Если у вас есть дети, обратите внимание. Мне кажется, это хорошая игра, чтобы вовлечь их в мир компьютера и ИТ технологий. Но, как я уже сказал, со школьного возраста. Дошкольников считаю, что нагружать компьютером не обязательно. Насидятся ещё за свою жизнь. Пока лучше пусть в песочнице играют.
#дети #игра
ПиктоМир — свободно распространяемая программная система для изучения азов программирования дошкольниками и младшими школьниками. ПиктоМир позволяет ребенку "собрать" из пиктограмм на экране компьютера несложную программу, управляющую виртуальным исполнителем-роботом. ПиктоМир в первую очередь ориентирован на дошкольников, еще не умеющих писать, или на младшеклассников, не очень любящих писать.
Я поиграл со своим старшим сыном (9 лет). Ему понравилось. Насчёт дошкольников не уверен. Игра не сказать, что сильно простая. Да и в целом я не сторонник сажать за компьютер малышей.
В игре с помощью команд нужно запрограммировать последовательность действий робота, чтобы он закрасил в синий цвет неокрашенные квадраты. В игре никаких подсказок нет, так что я не сразу разобрался, что там делать. Пришлось посмотреть обзор. После него стало понятно, как играть. Начали проходить уровни.
Игра на самом деле интересна не только детям. Мне тоже понравилось проходить уровни. Судя по комментариям к игре в Яндексе, не только мне:
🗣 Очень познавательная и развивающая игра в плане программирования. Причём подходит не только для детей, как было заявлено. Даже я - программист со стажем - с трудом решаю некоторые задачки этой головоломки. Однозначно советую для развития конструктивного мышления.
🗣 Считаю неправильным называть эту программу игрой, так она носит скорее обучающий характер,чем развлекательный. Отлично подходит для начального обучения программированию, развивает логическое и пространственное мышление. Яркое оформление способствует дополнительной мотивации юных программистов.
Если у вас есть дети, обратите внимание. Мне кажется, это хорошая игра, чтобы вовлечь их в мир компьютера и ИТ технологий. Но, как я уже сказал, со школьного возраста. Дошкольников считаю, что нагружать компьютером не обязательно. Насидятся ещё за свою жизнь. Пока лучше пусть в песочнице играют.
#дети #игра
{kind=link}
Во времена развития искусственного интеллекта сидеть и вспоминать команды и ключи консольных утилит Linux уже как-то не солидно. Пусть "вкалывают роботы, а не человек".
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
Извольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
Я не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
Идём на сайт https://www.askcommand.cppexpert.online и приказываем железным мозгам выполнять наши команды:
I want to delete 10 first lines in text file.
sed '1,10d' filenameИзвольте проверить. Команда работает. Правда, реально не удаляет строки, но выводит содержимое файла без первых десяти строк. Попробуем что-то посложнее:
I want to find all php files and replace one word there with another.
find ./ -name "*.php" -exec sed -i 's/old/new/g' {} +Опять сработало. Рабочий вариант предложил. Попробуем ещё усложнить:
I want to find the ten largest files older than thirty days and move them to another directory.
find /source/directory -type f -mtime +30 -exec ls -s {} \; \| sort -n -r | head -10 | awk '{print $2}' \| xargs -I '{}' mv '{}' /destination/directoryЯ не проверял этот вариант, но навскидку рабочий. Не вижу тут ошибок. Если английский не знаем, то напрягаем другого робота: https://translate.yandex.ru.
Немного запереживал о будущем, которое нас ждёт. На кого переучиваться предстоит? Таксисты и водители автобусов тоже будут не нужны. С программистами и так всё понятно. Тестировал плагин для IDE, который приказывает кремниевым мозгам писать код на JavaScript и, знаете, у него получается 😲.
#сервис #bash
{kind=link}
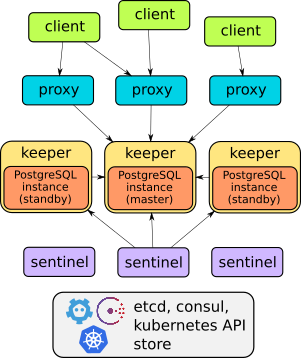
Stolon и Patroni — два наиболее известных решения для построения кластера PostgreSQL типа Leader-Followers. Про Patroni я уже как-то рассказывал. Для него есть готовый плейбук ansible — postgresql_cluster, с помощью которого можно легко и быстро развернуть нужную конфигурацию кластера.
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
Для Stolon я не знаю какого-то известного плейбука, хотя они и гуглятся в том или ином исполнении. В общем случае поднять кластер не трудно. В документации есть отдельная инструкция для поднятия Simple Cluster.
Для этого необходимо предварительно установить и настроить на узлах etcd. Так как его использует Kubernetes, инструкций в инете море. Настраивается легко и быстро. Потом надо закинуть бинарники Stolon на ноды. Готовых официальных пакетов нет. Дальше инициализируется кластер, запускается sentinel (агент-арбитр), затем запускается keeper (управляет postgres'ом), потом proxy (управляет соединениями). Дальше можно добавить ещё одну ноду, запустив на ней keeper с параметрами подключения к первому. Получится простейший кластер. Расширяется он для отказоустойчивости добавлением ещё арбитров, прокси и самих киперов с postgresql.
На тему кластеров Stolon и Patroni есть очень масштабное выступление от 2020 года на PgConf.Russia. Там разобрано очень много всего: теория, архитектура кластеров, практические примеры разворачивания и обработки отказа мастера, различия Stolon и Patroni, их плюсы и минусы:
▶️ Patroni и stolon: инсталляция и отработка падений
⇨ Текстовая расшифровка с картинками
Вот ещё одно выступление, где прямо и подробно разбирают различия Patroni и Stolon:
▶️ Обзор решений для PostgreSQL High Availability
Если выбирать какое-то решение, то я бы остановился на Patroini. Я его разворачивал, пробовал. Всё довольно просто и понятно. Про него и материалов больше в русскоязычном сегменте.
#postgresql
{kind=link}
Часто можно слышать рекомендацию, не использовать в рейд массивах диски одной серии, так как для них существует высокий шанс выйти из строя плюс-минус в одно время. Лично я с таким не сталкивался и по сериям никогда диски не разделял. Я просто не очень представляю практически, как это сделать. Чаще всего покупаешь сервер, к нему пачку дисков. Всё это приезжает, монтируешь, запускаешь. А тут получается диски надо в разных магазинах брать? Или вообще разных вендоров? Я никогда так не делаю. Всегда одинаковые беру.
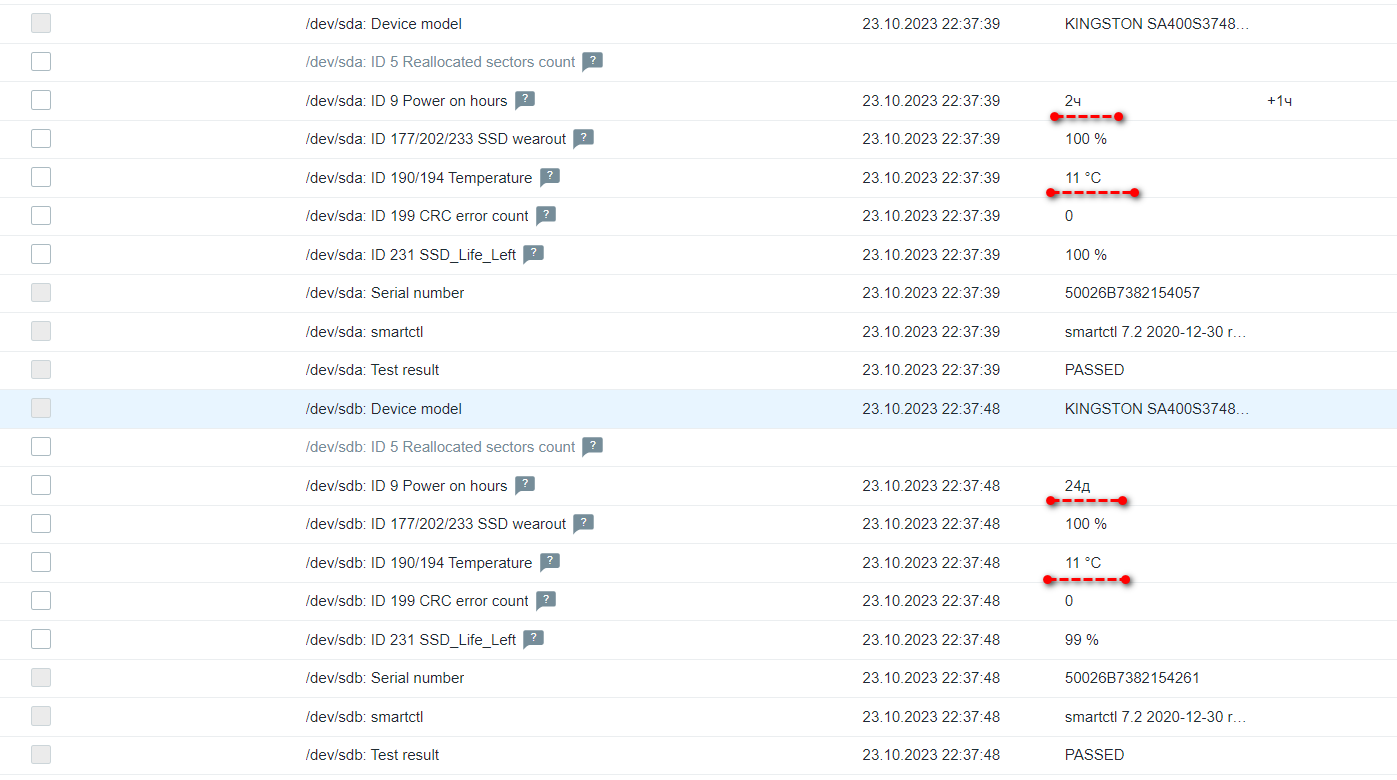
С арендными серверами то же самое. Обычно ставят одинаковые новые диски. Я недавно рассказывал про сервер, где вышел из строя один из идентичных SSD дисков в RAID1. Вот прошло 3 недели, и вышел из строя второй. В принципе, достаточно близко, но явно не одновременно. SMART, кстати, как обычно, не предвещал никаких проблем и не сигналил метриками. По смарту оставалось ещё 18% ресурса, но диск всё равно безвозвратно выпал из системы и перестал отвечать. Это к вопросу, нафиг вообще такой смарт нужен. С него кроме метрики температуры и серийного номера с моделью нечего смотреть. Практической ценности данные не представляют.
Забавно, что сотрудник техподдержки, который обрабатывал заявку, в этот раз уточнил, проверил ли я наличие загрузчика GRUB на живом диске. Судя по всему не раз сталкивался с тем, что люди про это забывают, а потом теряют доступ к серверу после замены единственного диска с загрузчиком. И им надо IP-KVM подключать. Проще заранее напомнить.
Про загрузчик я не забыл, так что в этот раз всё прошло штатно, как обычно по инструкции. После замены сразу же поставил загрузчик на новый диск:
Кстати, отмечу, что когда один диск из системы выпал, вышеприведённая команда не отрабатывала корректно. Завершалась с ошибкой, хотя умершего диска в списке уже не было и загрузчик я не пытался туда ставить. Так как я знал, что GRUB уже стоит на втором диске, на ошибку забил. Можно принудительно его поставить, чтобы наверняка:
Тут уже ошибок быть не должно. Если есть, надо разбираться, в чём проблема.
Теперь снова установлены 2 одинаковых диска, только уже с разницей в 23 дня. Интересно, почему в серверной Selectel так холодно? Если верить дискам, то у них температура 11 градусов сейчас. Под нагрузкой до 16 поднималась. А 3 недели назад первый диск после замены под нагрузкой до 50-ти градусов нагревался. Любопытно, как там серверная устроена, что такие разбросы по температуре.
#железо
С арендными серверами то же самое. Обычно ставят одинаковые новые диски. Я недавно рассказывал про сервер, где вышел из строя один из идентичных SSD дисков в RAID1. Вот прошло 3 недели, и вышел из строя второй. В принципе, достаточно близко, но явно не одновременно. SMART, кстати, как обычно, не предвещал никаких проблем и не сигналил метриками. По смарту оставалось ещё 18% ресурса, но диск всё равно безвозвратно выпал из системы и перестал отвечать. Это к вопросу, нафиг вообще такой смарт нужен. С него кроме метрики температуры и серийного номера с моделью нечего смотреть. Практической ценности данные не представляют.
Забавно, что сотрудник техподдержки, который обрабатывал заявку, в этот раз уточнил, проверил ли я наличие загрузчика GRUB на живом диске. Судя по всему не раз сталкивался с тем, что люди про это забывают, а потом теряют доступ к серверу после замены единственного диска с загрузчиком. И им надо IP-KVM подключать. Проще заранее напомнить.
Про загрузчик я не забыл, так что в этот раз всё прошло штатно, как обычно по инструкции. После замены сразу же поставил загрузчик на новый диск:
# dpkg-reconfigure grub-pcКстати, отмечу, что когда один диск из системы выпал, вышеприведённая команда не отрабатывала корректно. Завершалась с ошибкой, хотя умершего диска в списке уже не было и загрузчик я не пытался туда ставить. Так как я знал, что GRUB уже стоит на втором диске, на ошибку забил. Можно принудительно его поставить, чтобы наверняка:
# grub-install /dev/sdb Тут уже ошибок быть не должно. Если есть, надо разбираться, в чём проблема.
Теперь снова установлены 2 одинаковых диска, только уже с разницей в 23 дня. Интересно, почему в серверной Selectel так холодно? Если верить дискам, то у них температура 11 градусов сейчас. Под нагрузкой до 16 поднималась. А 3 недели назад первый диск после замены под нагрузкой до 50-ти градусов нагревался. Любопытно, как там серверная устроена, что такие разбросы по температуре.
#железо
{kind=link}
Последнее время частенько стали попадаться новости, связанные с известной программой для хранения паролей KeePass. Я уже ранее делал заметки по этому поводу. Сейчас попалась очередная новость:
⇨ Фальшивая реклама KeePass использует Punycode и домен, почти неотличимый от настоящего
И как раз недавно вышло обновление Keepass 2.55. Ко всему прочему это ещё и стабильный релиз, на который рекомендуется обновиться. Я сейчас внимательно проверяю все хэши скачанных файлов этой программы, хотя раньше как-то прохладно относился к таким проверкам. Да и вообще обновлял её крайне редко. Типа работает локально и ладно. Потом в какой-то момент почитал изменения новых версий, какие и в каком количестве там баги закрывают. И стал обновляться регулярно.
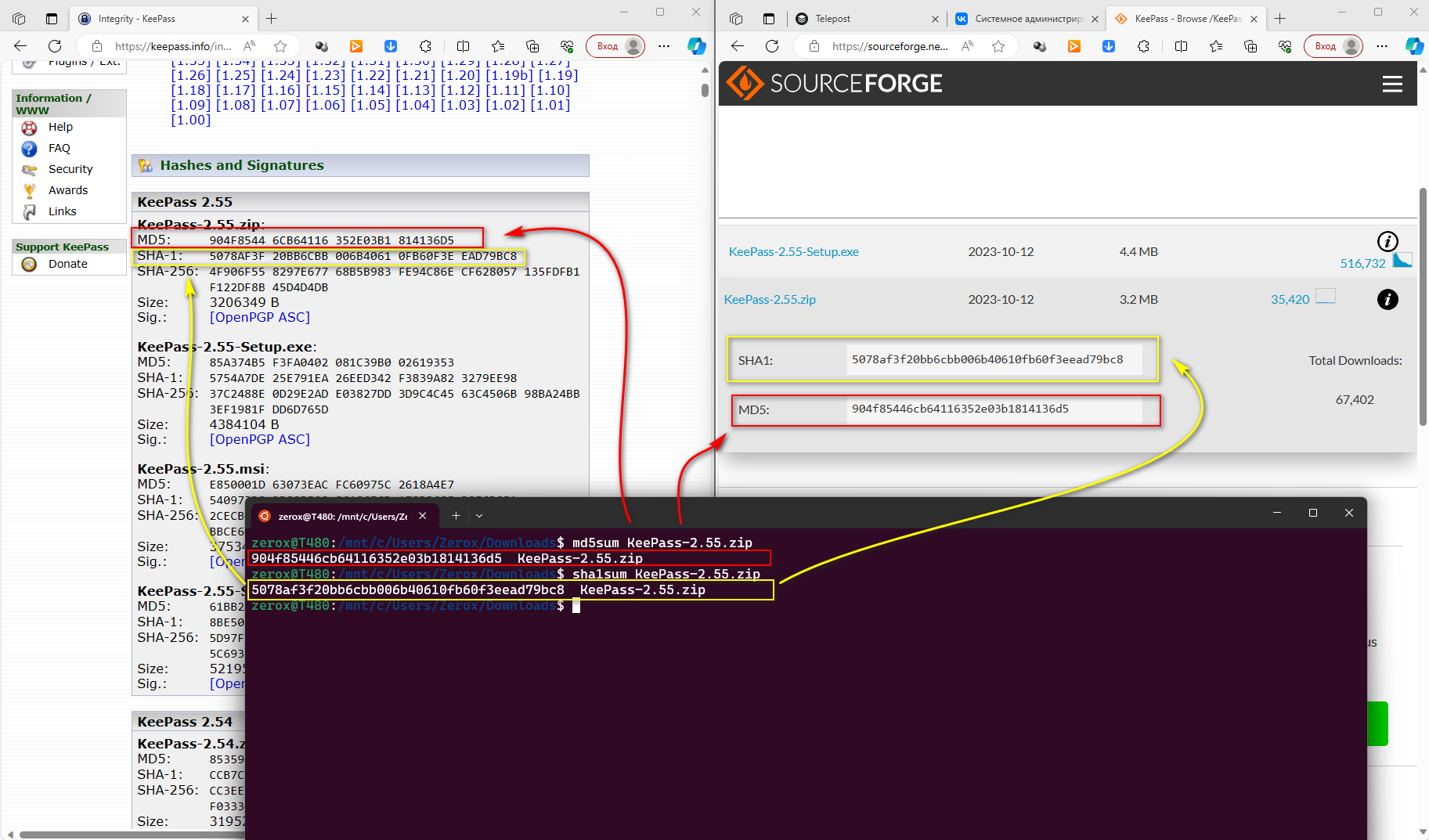
Файлы для загрузки KeePass лежат на sourceforge.net. Там есть возможность посмотреть хэши и сравнить с тем, что к тебе приехало, и с тем, что указано на сайте разработчиков. Я на всякий случай рекомендую делать сверку. В консоли это выполнить проще всего:
Если надо быстро сравнить, то делаем примерно так:
Берём хэш с сайта и выполняем проверку с локальным файлом через ключ
Проверяете файлы по контрольным суммам? Только честно.
#security
⇨ Фальшивая реклама KeePass использует Punycode и домен, почти неотличимый от настоящего
И как раз недавно вышло обновление Keepass 2.55. Ко всему прочему это ещё и стабильный релиз, на который рекомендуется обновиться. Я сейчас внимательно проверяю все хэши скачанных файлов этой программы, хотя раньше как-то прохладно относился к таким проверкам. Да и вообще обновлял её крайне редко. Типа работает локально и ладно. Потом в какой-то момент почитал изменения новых версий, какие и в каком количестве там баги закрывают. И стал обновляться регулярно.
Файлы для загрузки KeePass лежат на sourceforge.net. Там есть возможность посмотреть хэши и сравнить с тем, что к тебе приехало, и с тем, что указано на сайте разработчиков. Я на всякий случай рекомендую делать сверку. В консоли это выполнить проще всего:
# md5sum KeePass-2.55.zip# sha1sum KeePass-2.55.zipЕсли надо быстро сравнить, то делаем примерно так:
# echo "5078AF3F20BB6CBB006B40610FB60F3EEAD79BC8 KeePass-2.55.zip" \| sha1sum -cKeePass-2.55.zip: OKБерём хэш с сайта и выполняем проверку с локальным файлом через ключ
-c. Проверяете файлы по контрольным суммам? Только честно.
#security
{kind=link}
Вчера смотрел очень информативный вебинар Rebrain про оптимизацию запросов MySQL. Планирую сделать по нему заметку, когда запись появится в личном кабинете. Когда автор упомянул свой клиент MySQL Workbench, в чате начали присылать другие варианты клиентов. Я вспомнил, что несколько лет назад делал серию заметок по этой теме. Решил сформировать их в единый список. Думаю, будет полезно. С MySQL постоянно приходится работать в различных приложениях и сайтах.
🟢 MySQL клиенты в виде приложений:
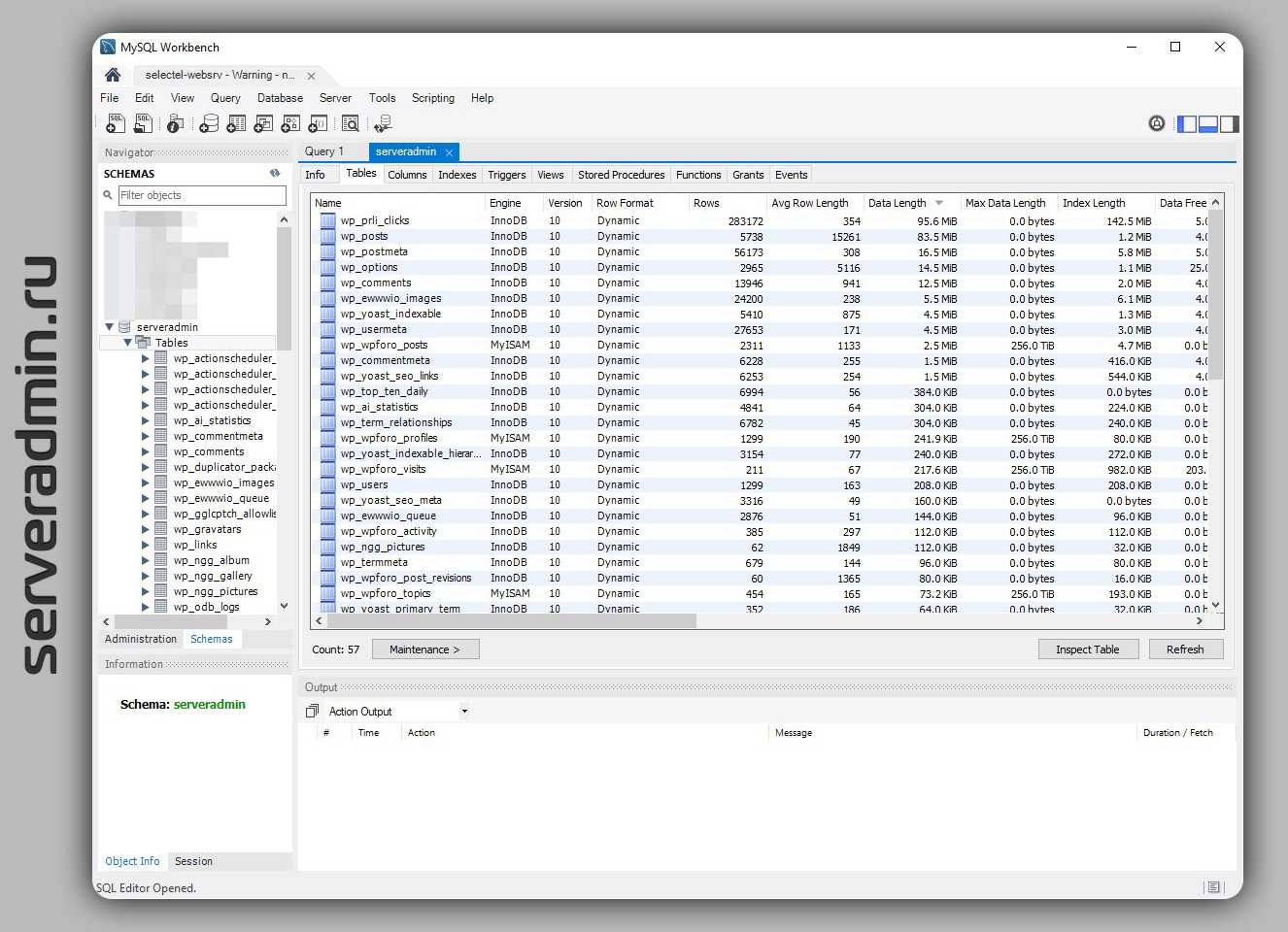
▪ MySQL Workbench - самый навороченный, функциональный и тормозной клиент от авторов непосредственно СУБД MySQL. Если нужен максимум возможностей, то это про него. В большинстве случаев всё это не надо, если вы не разработчик.
▪ HeidiSQL - маленький и шустрый клиент, есть портированная версия. Для типовых задач системного администратора будет достаточно. Я его последнее время использовал, когда нужно было. Но давно это было.
▪ Dbeaver - отличается в первую очередь хорошей поддержкой PostgreSQL и часто используется именно для неё. Если нужно только MySQL, то лучше взять HeidiSQL.
🟡 MySQL клиенты в виде скриптов:
▪ PhpMyAdmin - думаю, не нуждается в представлении. Я почти всегда использую именно его. Его же обычно просят и разработчики. В публичный доступ не рекомендую его выставлять. Если хочется разово запустить, но не хочется настраивать веб сервер, то можно быстро запустить через встроенный в php веб сервер.
▪ Adminer - простенький php скрипт из одного файла. Очень удобно, если не хочется ничего настраивать, а нужно быстро зайти в базу и что-то там сделать. Как закончишь, скрипт можно просто удалить.
Тру админы наверняка начнут сейчас писать в комментариях, что не надо никаких внешних клиентов. Заходим консольным клиентом и делаем всё, что надо. Иногда я так делаю, но приходится вспоминать синтаксис, так как нужен он редко. Время тратится больше. Тот же adminer быстрее закинуть, чем вспомнить, как правильно написать запрос на создание пользователя и выставление для него прав на базу. Другое дело, если копипастишь откуда-то команды. Тогда можно и в консольный клиент.
#mysql #подборка
🟢 MySQL клиенты в виде приложений:
▪ MySQL Workbench - самый навороченный, функциональный и тормозной клиент от авторов непосредственно СУБД MySQL. Если нужен максимум возможностей, то это про него. В большинстве случаев всё это не надо, если вы не разработчик.
▪ HeidiSQL - маленький и шустрый клиент, есть портированная версия. Для типовых задач системного администратора будет достаточно. Я его последнее время использовал, когда нужно было. Но давно это было.
▪ Dbeaver - отличается в первую очередь хорошей поддержкой PostgreSQL и часто используется именно для неё. Если нужно только MySQL, то лучше взять HeidiSQL.
🟡 MySQL клиенты в виде скриптов:
▪ PhpMyAdmin - думаю, не нуждается в представлении. Я почти всегда использую именно его. Его же обычно просят и разработчики. В публичный доступ не рекомендую его выставлять. Если хочется разово запустить, но не хочется настраивать веб сервер, то можно быстро запустить через встроенный в php веб сервер.
▪ Adminer - простенький php скрипт из одного файла. Очень удобно, если не хочется ничего настраивать, а нужно быстро зайти в базу и что-то там сделать. Как закончишь, скрипт можно просто удалить.
Тру админы наверняка начнут сейчас писать в комментариях, что не надо никаких внешних клиентов. Заходим консольным клиентом и делаем всё, что надо. Иногда я так делаю, но приходится вспоминать синтаксис, так как нужен он редко. Время тратится больше. Тот же adminer быстрее закинуть, чем вспомнить, как правильно написать запрос на создание пользователя и выставление для него прав на базу. Другое дело, если копипастишь откуда-то команды. Тогда можно и в консольный клиент.
#mysql #подборка
{kind=link}
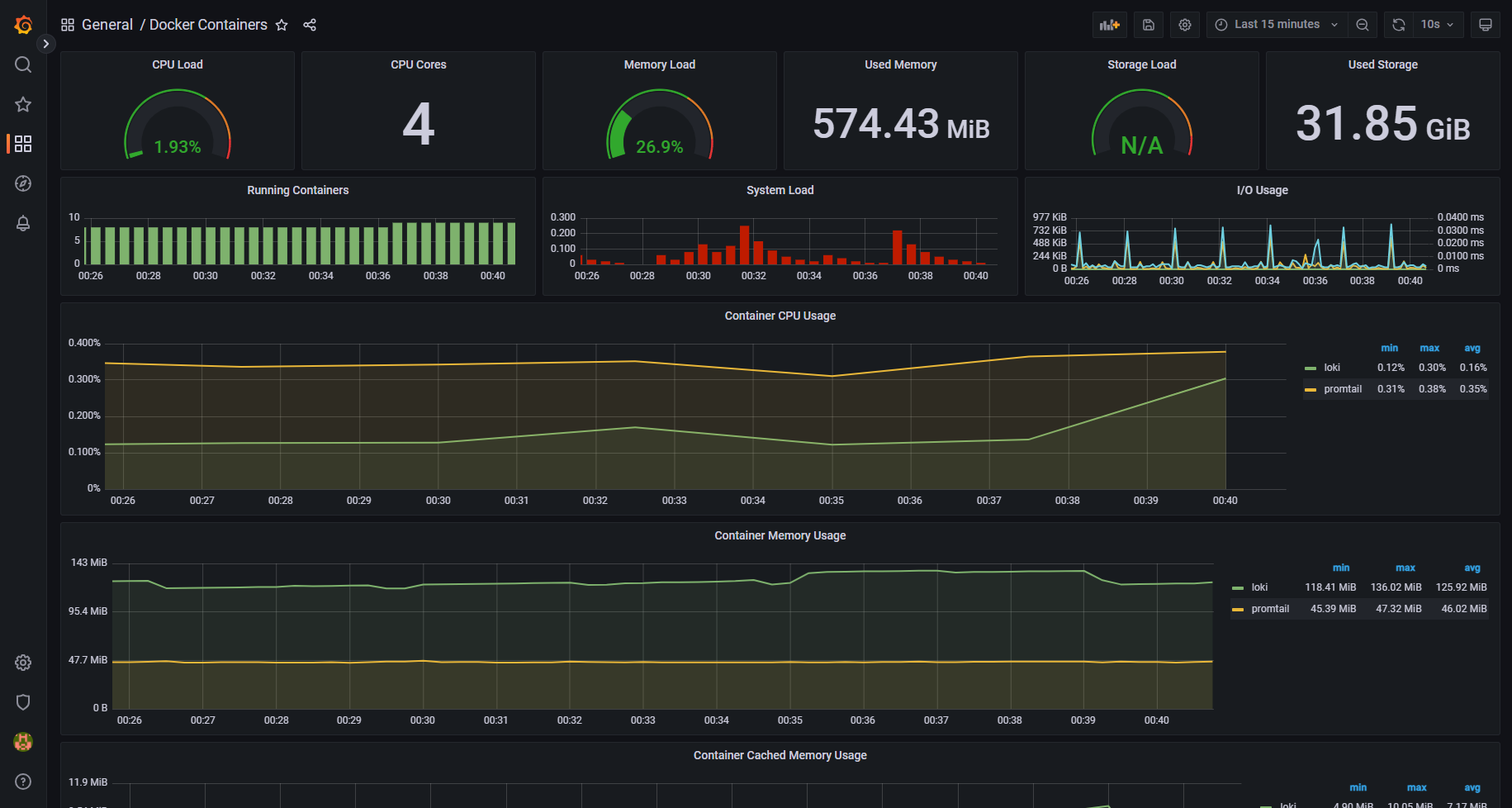
Предлагаю вашему вниманию любопытный проект по мониторингу одиночного хоста с Docker - domolo. Сразу скажу, что это продукт уровня курсовой работы с каких-нибудь курсов по DevOps на тему мониторинга. Он представляет из себя преднастроенный набор контейнеров на современном стеке.
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
Идём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
# git clone https://github.com/ductnn/domolo.git# cd domolo# docker-compose up -dИдём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
{kind=link}
Я посмотрел два больших информативных вебинара про оптимизацию запросов в MySQL. Понятно, что в формате заметки невозможно раскрыть тему, поэтому я сделаю выжимку основных этапов и инструментов, которые используются. Кому нужна будет эта тема, сможет раскрутить её на основе этих вводных.
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
Для детального разбора нужны будут и более тонкие настройки.
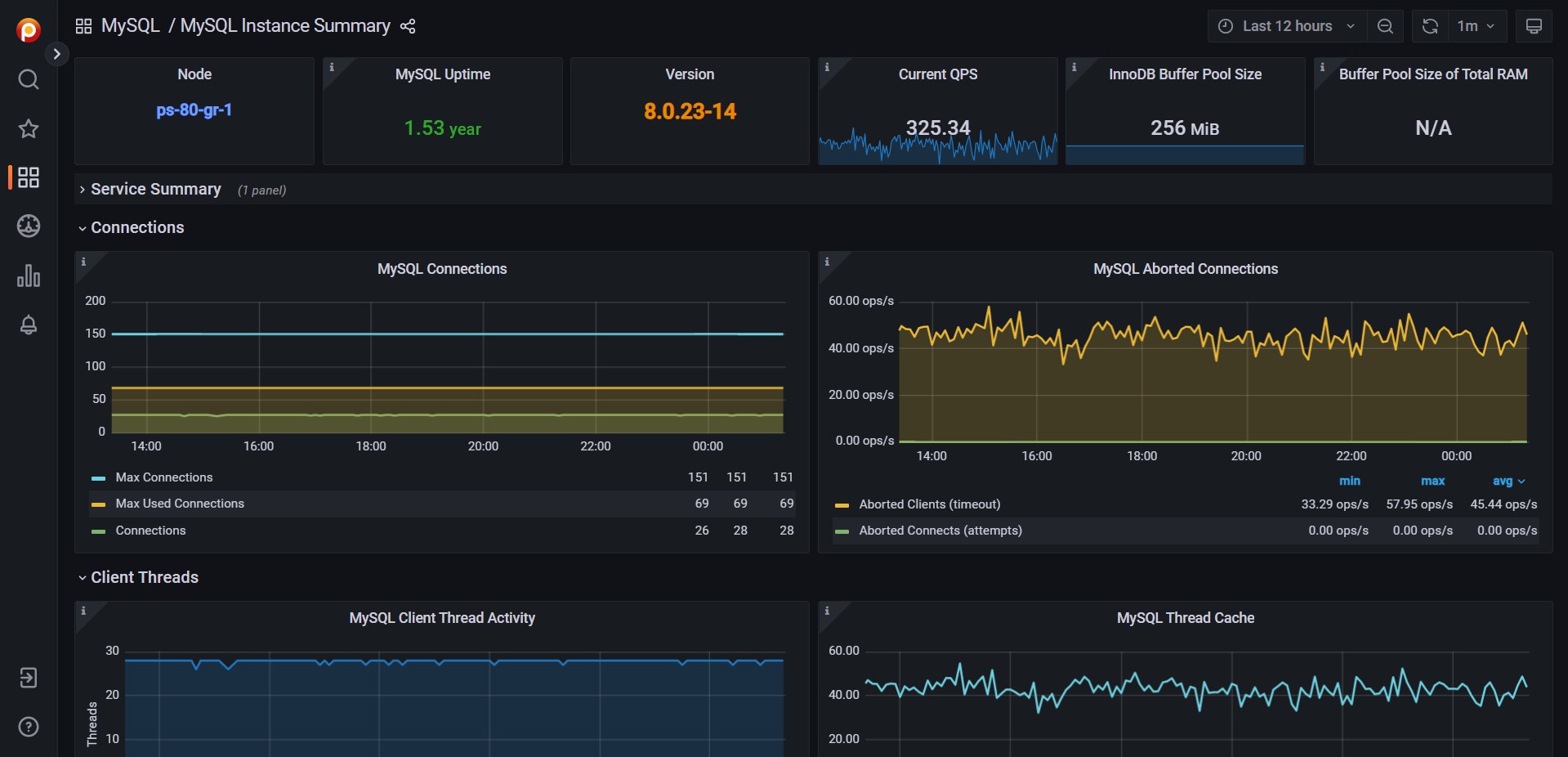
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
{kind=link}
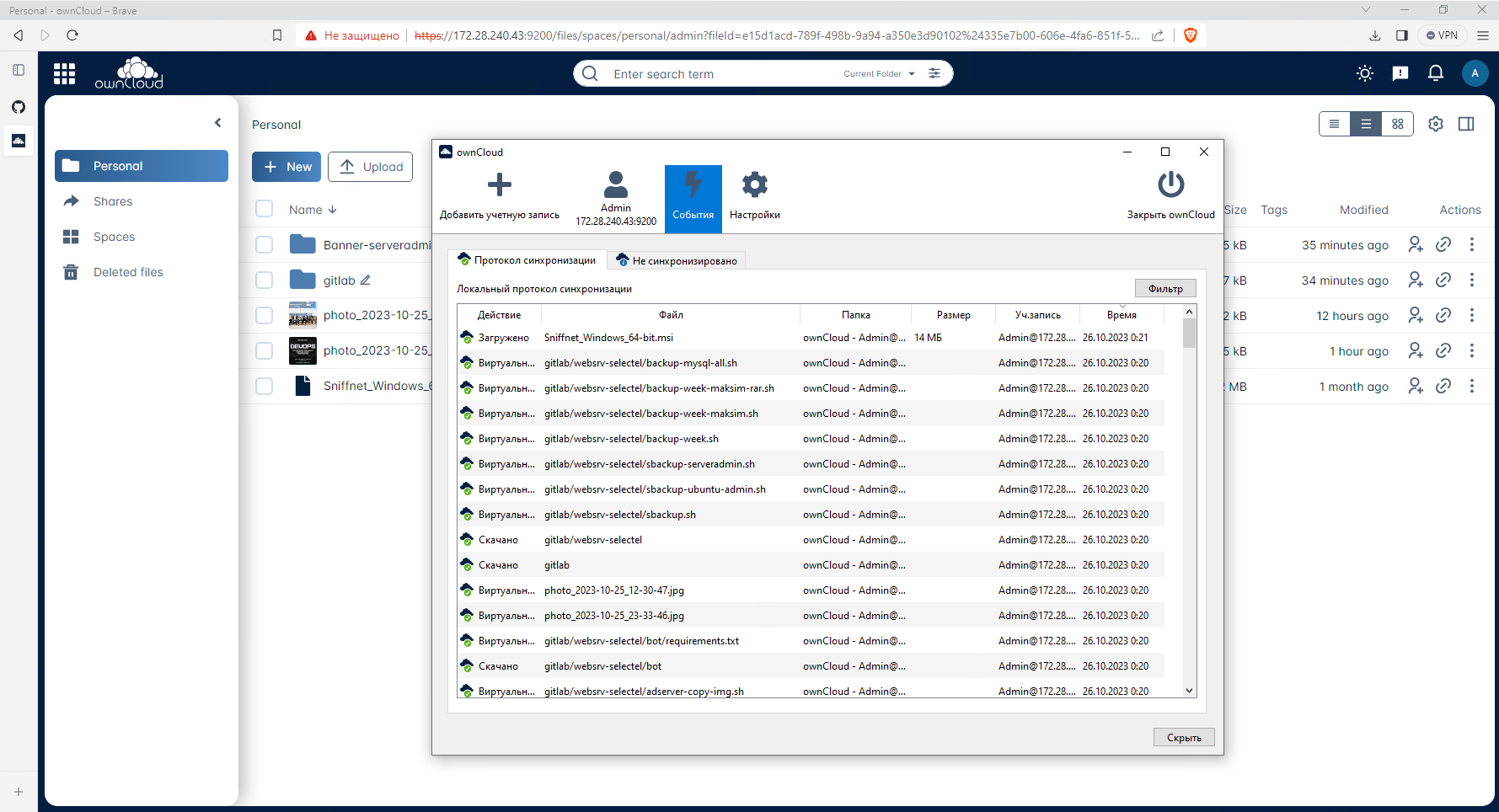
Кто-нибудь ещё помнит, использует такой продукт, как OwnCloud? Это прародитель файлового сервера Nextcloud, который появился после того, как часть разработчиков что-то не поделила в коллективе owncloud, отделилась и начала его развивать. С тех пор этот форк стал более популярен прародителя. А сам owncloud растерял всю свою популярность.
Недавно я случайно и с удивлением узнал, что оказывается OwnCloud выпустили новый продукт, написав его с нуля на Go (бэк) и Vue.js (фронт). Я не видел ни новостей, ни какой-то ещё информации на эту тему. Случайно прочитал в комментариях в каком-то обсуждении.
Заинтересовался и решил попробовать. Так как продукт относительно новый, функциональности там немного. Получился простой файловый сервер под Linux с клиентами под все популярные системы. Ну или не файловый сервер, а облачный, как их сейчас называют. Ставите себе клиентскую часть, и она автоматически синхронизирует заданные файлы с серверной частью, как яндекс.диск, dropbox, gdrive и т.д.
Основной упор сделан на производительность, отзывчивость, скорость работы. В целом, получилось неплохо. Так как ownCloud Infinite Scale 4.0, а именно так полностью называется продукт, написан на Go, то представляет из себя одиночный бинарник, который достаточно скачать и запустить:
Скачали, создали конфиг, передали некоторые переменные перед запуском и запустили сервер прямо в консоли. Для запуска в фоне нужно будет юнит systemd сделать или использовать Docker контейнер. Учётку для доступа увидите в консоли после
Я скачал и установил ownCloud client для Windows. Приложение небольшое, всего 21 мегабайт. Установил, указал IP сервера, подключился, синхронизировал файлы. Закинул туда несколько папок с 500 файлами. Переварил всё нормально и быстро, каких-то лагов, тормозов не заметил. Понятно, что объём и количество небольшое, но полноценные тесты проводить хлопотно и конкретно мне нет большого смысла.
В целом, впечатление неплохое производит. Из возможностей пока увидел только управление пользователями и создание совместных пространств для них. Подкупает лёгкость и простота установки, настройки, за счёт того, что это одиночный бинарник и единый конфиг формата yaml.
Продукт скорее всего сыроват и имеет баги. В русскоязычном интернете не нашёл вообще ни одного отзыва на него. Репозиторий продукта живой, много commits, issues. Обновления выходят регулярно. Может что и получится в итоге дельное.
⇨ Сайт / Исходники
#fileserver
Недавно я случайно и с удивлением узнал, что оказывается OwnCloud выпустили новый продукт, написав его с нуля на Go (бэк) и Vue.js (фронт). Я не видел ни новостей, ни какой-то ещё информации на эту тему. Случайно прочитал в комментариях в каком-то обсуждении.
Заинтересовался и решил попробовать. Так как продукт относительно новый, функциональности там немного. Получился простой файловый сервер под Linux с клиентами под все популярные системы. Ну или не файловый сервер, а облачный, как их сейчас называют. Ставите себе клиентскую часть, и она автоматически синхронизирует заданные файлы с серверной частью, как яндекс.диск, dropbox, gdrive и т.д.
Основной упор сделан на производительность, отзывчивость, скорость работы. В целом, получилось неплохо. Так как ownCloud Infinite Scale 4.0, а именно так полностью называется продукт, написан на Go, то представляет из себя одиночный бинарник, который достаточно скачать и запустить:
# wget -O /usr/local/bin/ocis \ https://download.owncloud.com/ocis/ocis/stable/4.0.2/ocis-4.0.2-linux-amd64# chmod +x /usr/local/bin/ocis# ocis init# OCIS_INSECURE=true \IDM_CREATE_DEMO_USERS=true \PROXY_HTTP_ADDR=0.0.0.0:9200 \OCIS_URL=https://172.28.240.43:9200 \ocis serverСкачали, создали конфиг, передали некоторые переменные перед запуском и запустили сервер прямо в консоли. Для запуска в фоне нужно будет юнит systemd сделать или использовать Docker контейнер. Учётку для доступа увидите в консоли после
ocis init. Дальше можно идти в веб интерфейс на порт хоста 9200. Я скачал и установил ownCloud client для Windows. Приложение небольшое, всего 21 мегабайт. Установил, указал IP сервера, подключился, синхронизировал файлы. Закинул туда несколько папок с 500 файлами. Переварил всё нормально и быстро, каких-то лагов, тормозов не заметил. Понятно, что объём и количество небольшое, но полноценные тесты проводить хлопотно и конкретно мне нет большого смысла.
В целом, впечатление неплохое производит. Из возможностей пока увидел только управление пользователями и создание совместных пространств для них. Подкупает лёгкость и простота установки, настройки, за счёт того, что это одиночный бинарник и единый конфиг формата yaml.
Продукт скорее всего сыроват и имеет баги. В русскоязычном интернете не нашёл вообще ни одного отзыва на него. Репозиторий продукта живой, много commits, issues. Обновления выходят регулярно. Может что и получится в итоге дельное.
⇨ Сайт / Исходники
#fileserver
{kind=link}
В это трудно поверить, но я никогда не проверял, что в реальности будет, если сделать
И вот решил на тестовой виртуалке посмотреть, а что реально произойдёт после
И всё реально удалилось, кроме раздела
Работают только те утилиты, что встроены в оболочку. Например echo, pwd, type, cd и т.д.:
То есть переместиться в /sys/module/ можно. А вот что-то сделать там - нет. Подключиться новой сессией или залогоиниться через терминал уже не получится. Даже команду
После перезагрузки отработает загрузчик в boot разделе, так как его мы не трогали, он вне корня / и увидим консоль grub rescue. Сделать там уже ничего не получится, потому что данных нет. Грузиться неоткуда. Хотя встроенные в grub утилиты тоже работают. Через ls можно увидеть разделы диска и даже оставшееся содержимое:
Некоторые директории выжили.
С виртуалкой больше делать нечего. Мы её гарантированно прибили.
#linux
rm -rf на весь корневой раздел. Однажды на заре карьеры я ошибся с удалением и запустил удаление по корню. Но это была не команда rm, а что-то другое. Уже не помню подробностей. Тогда ещё сервера были железные и это реально стало проблемой. Сервер ещё не ввели в прод, но я на нём уже что-настроил. Ошибку сразу заметил и отменил команду. Сначала подумал, что обошлось, но потом заметил, что пропали все символьные ссылки, хотя в целом система работала и нормально перезагружалась. Пришлось всё равно всё переделать. И вот решил на тестовой виртуалке посмотреть, а что реально произойдёт после
rm -rf /. В таком виде команда не отработала и попросила добавить ключ --no-preserve-root. Я это сделал:# rm -rf / --no-preserve-rootИ всё реально удалилось, кроме раздела
/dev и загруженных системных модулей в /sys/module/. Причём так буднично, без каких-то особых сообщений, фатальных ошибок или чего-то ещё. Сидишь в системе, где нет ничего, кроме того, что было загружено в память. Оболочка bash работает, можно что-то поделать, но не сильно много. Бинарников то нет. Работают только те утилиты, что встроены в оболочку. Например echo, pwd, type, cd и т.д.:
# type cdcd is a shell builtinТо есть переместиться в /sys/module/ можно. А вот что-то сделать там - нет. Подключиться новой сессией или залогоиниться через терминал уже не получится. Даже команду
reboot не сделать. Это бинарник, а его нет. Тем не менее, сервер всё ещё можно штатно отправить в reboot. Интересно, много ли людей знают, как это сделать? Пишите предложения в комментарии. Я потом напишу ответ, если его не будет. После перезагрузки отработает загрузчик в boot разделе, так как его мы не трогали, он вне корня / и увидим консоль grub rescue. Сделать там уже ничего не получится, потому что данных нет. Грузиться неоткуда. Хотя встроенные в grub утилиты тоже работают. Через ls можно увидеть разделы диска и даже оставшееся содержимое:
# ls (hd0,msdos1)/./ ../ var/ tmp/ dev/ proc/ run/ sys/Некоторые директории выжили.
С виртуалкой больше делать нечего. Мы её гарантированно прибили.
#linux
{kind=link}