
Мы все привыкли к тому, что интерфейс MC — это синий цвет двух панелей. Я когда-то давно узнал, что у популярного файлового менеджера можно выбрать другую цветовую тему оформления. Немного поигрался и забросил это дело. Но с тех времён у меня до сих пор осталась одна виртуальная машина с тёмной темой MC. Решил рассказать об этом. Наверняка многие не знают, что у Midnight Commander есть разные темы оформления.
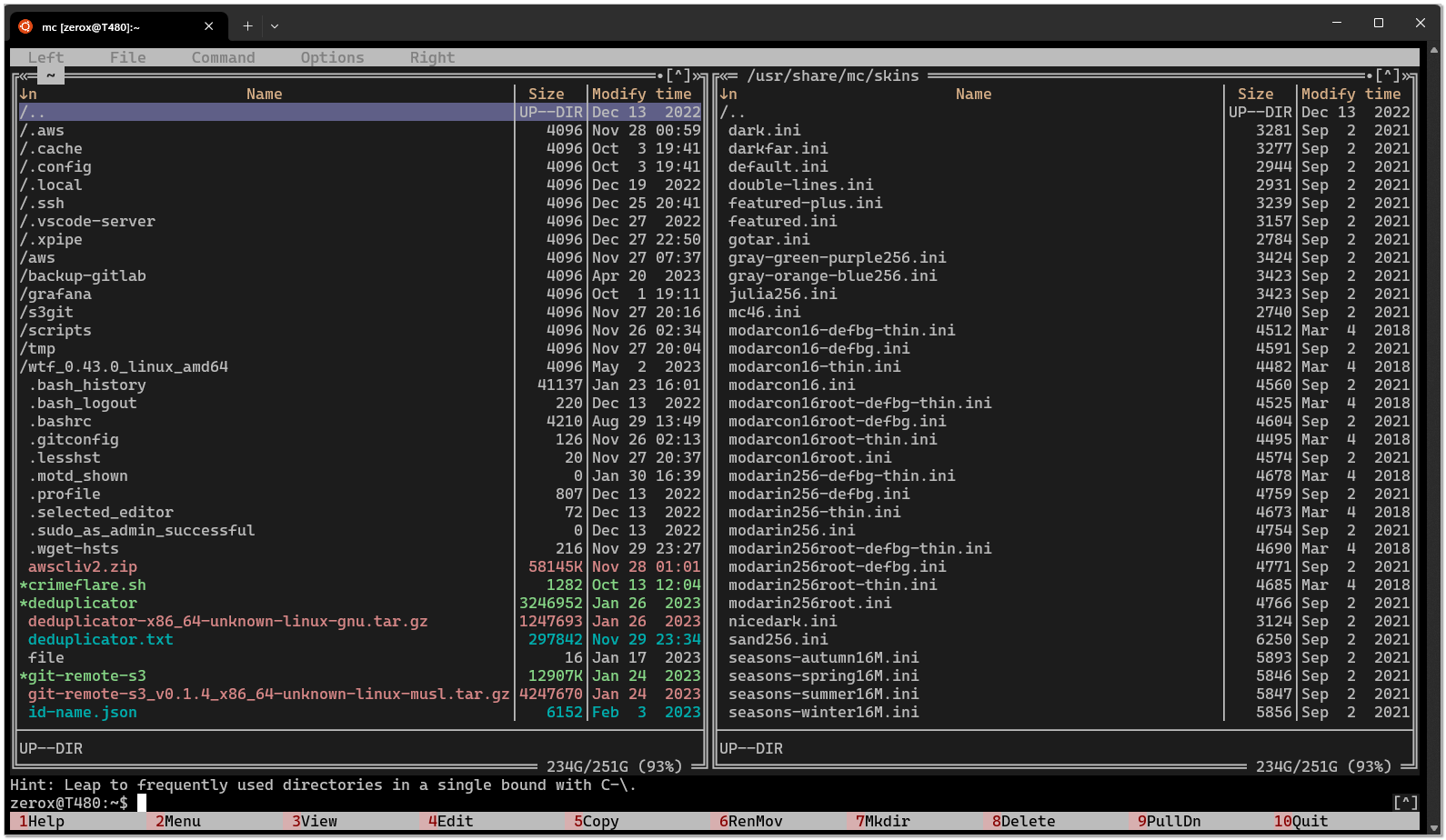
В составе пакета MC есть большой набор различных тем. Живут они в
Если тема понравилась, то можно установить её по умолчанию. Для этого нужно выключить MC, открыть файл конфигурации
на
Теперь MC будет запускаться с выбранной темой. Если выбираете тему с 256 цветами, то убедитесь, что ваш терминал поддерживает 256 цветов. Настроить это можно в
Если регулярно пользуетесь файловым менеджером, то разные темы могут служить дополнительным отличием разных классов серверов, либо пользователей в них. Их можно различать в том числе и по этому изменяемому признаку.
Сам я обычно оставляю тему по умолчанию. Но после того, как написал эту заметку, решил поменять у себя в WSL тему на xoria256.
❗️Ну и раз уж речь зашла о MC, добавлю информацию о настройке, которую я делаю всегда по умолчанию сразу после установки этого пакета на сервере:
Я копирую правила подсветки синтаксиса для файлов
Большие лог файлы иногда начинают подтормаживать при открытии с подсветкой. Тогда она быстро отключается комбинацией клавиш Ctrl + S.
#linux #mc
В составе пакета MC есть большой набор различных тем. Живут они в
/usr/share/mc/skins. Чтобы быстро посмотреть, как выглядит файловый менеджер с любой из тем, достаточно указать нужную тему отдельным ключом:# mc -S darkfarЕсли тема понравилась, то можно установить её по умолчанию. Для этого нужно выключить MC, открыть файл конфигурации
~/.config/mc/ini редактором, отличным от mcedit и изменить параметр с skin=defaultна
skin=darkfarТеперь MC будет запускаться с выбранной темой. Если выбираете тему с 256 цветами, то убедитесь, что ваш терминал поддерживает 256 цветов. Настроить это можно в
.bashrc или .bash_profile, добавив туда:export TERM=xterm-256colorЕсли регулярно пользуетесь файловым менеджером, то разные темы могут служить дополнительным отличием разных классов серверов, либо пользователей в них. Их можно различать в том числе и по этому изменяемому признаку.
Сам я обычно оставляю тему по умолчанию. Но после того, как написал эту заметку, решил поменять у себя в WSL тему на xoria256.
❗️Ну и раз уж речь зашла о MC, добавлю информацию о настройке, которую я делаю всегда по умолчанию сразу после установки этого пакета на сервере:
# cp /usr/share/mc/syntax/sh.syntax /usr/share/mc/syntax/unknown.syntaxЯ копирую правила подсветки синтаксиса для файлов
.sh на все неопознанные форматы файлов. Сюда будут относиться в основном лог файлы и файлы конфигураций без расширений. Чаще всего для них как раз актуален стандартный синтаксис скриптов sh.Большие лог файлы иногда начинают подтормаживать при открытии с подсветкой. Тогда она быстро отключается комбинацией клавиш Ctrl + S.
#linux #mc
{kind=link}
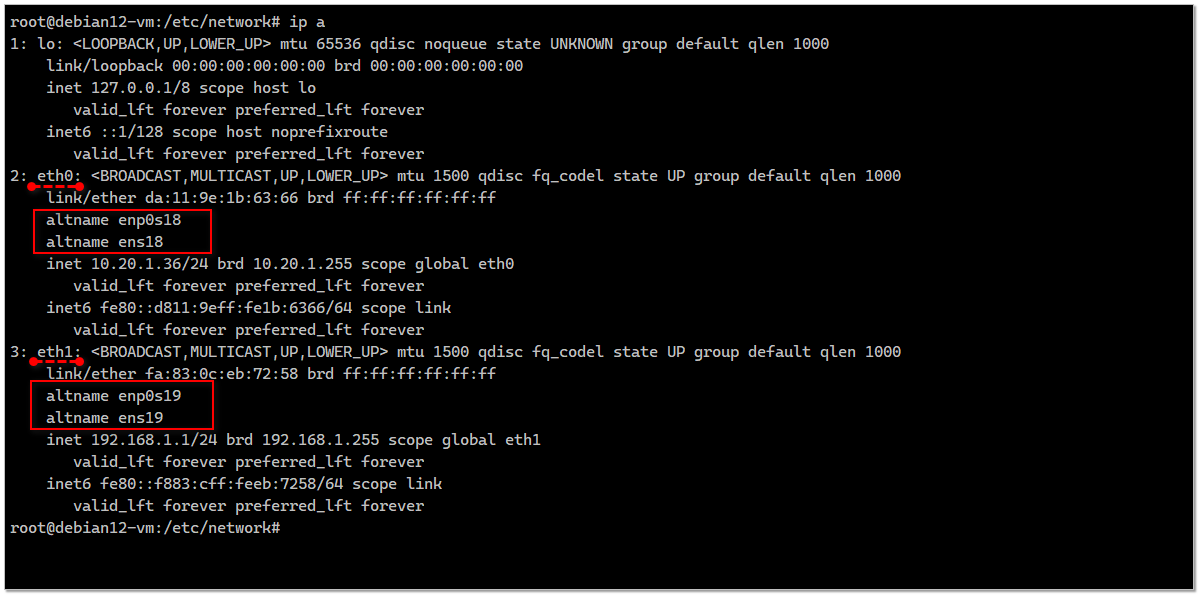
Если вам по какой-то причине не нравится современное именование сетевых интерфейсов в Linux вида ens18, enp0s18 и т.д. то вы можете довольно просто вернуться к привычным названиям eth0, eth1 и т.д. Только сразу предупрежу, что не стоит это делать на уже работающем сервере. Если уж вам так хочется переименовать сетевые интерфейсы, то делайте это сразу после установки системы.
Итак, если вам хочется вернуть старое именование интерфейсов, то в файле конфигурации grub
У вас уже могут быть указаны какие-то другие значения. Новые добавьте через пробел. Изначально их вообще может не быть, а параметр указан вот так:
Или могут быть какие-то другие значения:
После этого нужно обновить загрузчик. В зависимости от дистрибутива, это может выглядеть по-разному. В deb дистрибутивах то выглядит так:
В rpm уже точно не помню, специально не проверял, но вроде бы раньше это выглядело так:
Как в современных версиях уже не знаю, так как не использую их.
После этого нужно везде в сетевых настройках изменить имена интерфейсов со старых на новые. Для Debian достаточно отредактировать
Теперь можно перезагружать сервер. Загрузится он со старыми названиями сетевых интерфейсов.
Попутно задам вопрос, на который у меня нет ответа. Я не понимаю, почему в некоторых виртуалках по умолчанию используется старое именование сетевых интерфейсов, а в некоторых новое. Причём, это не зависит от версии ОС. У меня прямо сейчас есть две одинаковые Debian 11, где на одной eth0, а на другой ens18. Первая на HyperV, вторая на Proxmox. Подозреваю, что это зависит от типа эмулируемой сетевухи и драйвера, который используется в системе.
#linux #network
Итак, если вам хочется вернуть старое именование интерфейсов, то в файле конфигурации grub
/etc/default/grub добавьте в параметр GRUB_CMDLINE_LINUX дополнительные значения net.ifnames и biosdevname:GRUB_CMDLINE_LINUX="net.ifnames=0 biosdevname=0"У вас уже могут быть указаны какие-то другие значения. Новые добавьте через пробел. Изначально их вообще может не быть, а параметр указан вот так:
GRUB_CMDLINE_LINUX=""Или могут быть какие-то другие значения:
GRUB_CMDLINE_LINUX="crashkernel=auto rhgb quiet"После этого нужно обновить загрузчик. В зависимости от дистрибутива, это может выглядеть по-разному. В deb дистрибутивах то выглядит так:
# dpkg-reconfigure grub-pc В rpm уже точно не помню, специально не проверял, но вроде бы раньше это выглядело так:
# grub2-mkconfig -o /boot/grub2/grub.cfgКак в современных версиях уже не знаю, так как не использую их.
После этого нужно везде в сетевых настройках изменить имена интерфейсов со старых на новые. Для Debian достаточно отредактировать
/etc/network/interfaces. Не забудьте про firewall, если у вас правила привязаны к именам интерфейсов. Теперь можно перезагружать сервер. Загрузится он со старыми названиями сетевых интерфейсов.
Попутно задам вопрос, на который у меня нет ответа. Я не понимаю, почему в некоторых виртуалках по умолчанию используется старое именование сетевых интерфейсов, а в некоторых новое. Причём, это не зависит от версии ОС. У меня прямо сейчас есть две одинаковые Debian 11, где на одной eth0, а на другой ens18. Первая на HyperV, вторая на Proxmox. Подозреваю, что это зависит от типа эмулируемой сетевухи и драйвера, который используется в системе.
#linux #network
{kind=link}
Разберу ещё один объёмный вопрос из собеседований специалистов со знанием Linux, то бишь девопсов и линукс админов. Он хорошо показывает обзорное знание системы, так как затрагивает многие её инструменты.
Как и где посмотреть список регулярно выполняемых заданий в ОС на базе Linux?
📌 Начнём с традиционного cron. Его задания раскиданы по всей системе. Смотреть их надо в:
Это условно можно отнести к системным файлам конфигурации. Есть ещё пользовательские в
У каждого пользователя будет свой файл с задачами.
📌 Переходим к systemd timers. Это сейчас база для современных ОС, так что вполне уместно начинать именно с них. Там сейчас все системные повторяемые задачи, типа logrotate, apt-daily, anacron и т.д. Посмотреть список всех таймеров:
Только активных:
Более подробная информация о таймерах:
📌 И ещё один инструмент для запланированных задач — at. Это очень старая утилита для выполнения разовых запланированных задач. Раньше она была частью базовой системы, так как я лично ей пользовался. Проверил в Debian 11 и 12, в системе её уже нет. А, например, в Centos 7 и 8 (форках RHEL) всё ещё есть. В общем, про неё легко забыть, так как мало кто знает и пользуется, но для общего образования знать не помешает. Её могут использовать какие-то зловреды, чтобы добавлять свои задания, потому что там их будут искать в последнюю очередь.
Посмотреть очередь задач at:
Пример добавления задачи на выключение системы:
Задачи хранятся в текстовых файлах в директории
#linux
Как и где посмотреть список регулярно выполняемых заданий в ОС на базе Linux?
📌 Начнём с традиционного cron. Его задания раскиданы по всей системе. Смотреть их надо в:
- /etc/crontab- /etc/cron.d/- /etc/cron.daily/, /etc/cron.hourly/, /etc/cron.monthly/Это условно можно отнести к системным файлам конфигурации. Есть ещё пользовательские в
/var/spool/cron/crontabs. Смотреть их можно как напрямую, открывая текстовые файлы, так и командой:# crontab -u user01 -lУ каждого пользователя будет свой файл с задачами.
📌 Переходим к systemd timers. Это сейчас база для современных ОС, так что вполне уместно начинать именно с них. Там сейчас все системные повторяемые задачи, типа logrotate, apt-daily, anacron и т.д. Посмотреть список всех таймеров:
# systemctl list-timers --allТолько активных:
# systemctl list-timersБолее подробная информация о таймерах:
# systemctl status *timer📌 И ещё один инструмент для запланированных задач — at. Это очень старая утилита для выполнения разовых запланированных задач. Раньше она была частью базовой системы, так как я лично ей пользовался. Проверил в Debian 11 и 12, в системе её уже нет. А, например, в Centos 7 и 8 (форках RHEL) всё ещё есть. В общем, про неё легко забыть, так как мало кто знает и пользуется, но для общего образования знать не помешает. Её могут использовать какие-то зловреды, чтобы добавлять свои задания, потому что там их будут искать в последнюю очередь.
Посмотреть очередь задач at:
# atqПример добавления задачи на выключение системы:
# echo "shutdown -h now" | at -m 10:20Задачи хранятся в текстовых файлах в директории
/var/spool/cron/atjobs/или /var/spool/at/. Одно из напрашивающихся применений этой утилиты — разовая задача на восстановление правил firewall через короткий промежуток времени после применения новых. Ставите задачу на восстановление старых правил, применяете новые. Если связь потеряли, через 3 минуты будут восстановлены старые правила. Если всё ОК, то сами отключаете задачу на восстановление.#linux
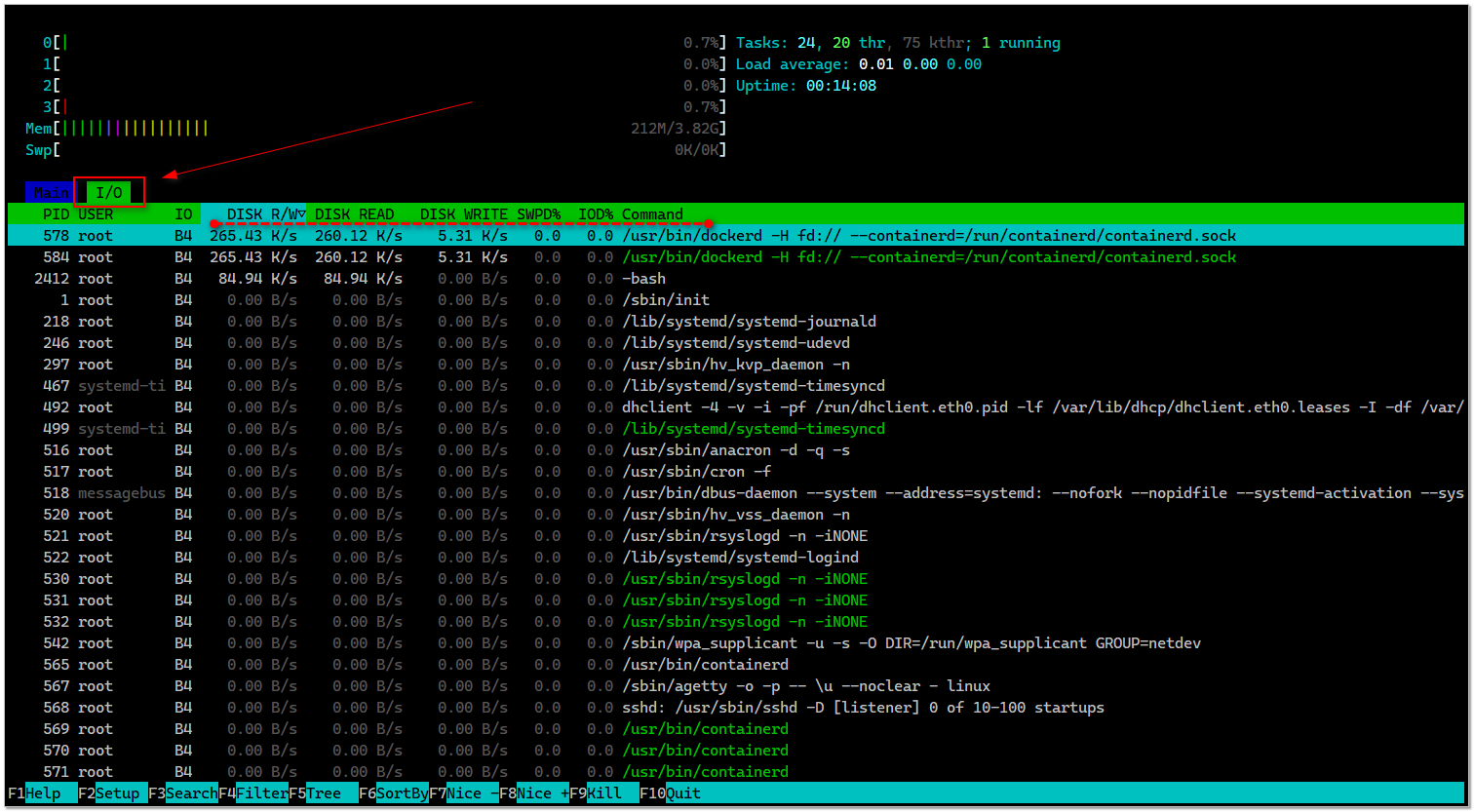
Делал сегодня чистую установку системы Debian 12 и очень удивился, когда установив htop, увидел у него новую вкладку I/O. Потёр глаза, посмотрел повнимательнее. Реально новая вкладка. Сразу понял, как на неё переключиться - с помощью клавиши tab. На вкладке показана нагрузка на диск каждого сервиса.
Htop - это утилита, которую я по умолчанию ставлю на все сервера, которые настраиваю, как замену стандартному top. Я вижу её каждый день. Но сегодня впервые увидел эту вкладку. Для проверки открыл несколько других серверов, на которых бываю регулярно, там этой вкладки нет. То есть это не я такой невнимательный. Её реально раньше не было.
Полез искать в инете информацию и узнал, что, начиная с версии 3.2.0, появилась настройка (войти по F2) Show tabs for screen, которая включает эту вкладку с I/O. В Debian 12 из базового репозитория ставится версия 3.2.2 и там эта опция включена по умолчанию. Увидел мнение, что якобы последнее время активно ведётся разработка и развитие htop.
Такое вот полезное нововведение. Обновляйте или ставьте htop, если ещё не поставили и пользуйтесь новыми возможностями. Они реально полезны и заменяют многие консольные утилиты, которые показывают примерно то же самое.
Это только я такой слоупок? Вы знали об этом нововведении?
#linux #htop
Htop - это утилита, которую я по умолчанию ставлю на все сервера, которые настраиваю, как замену стандартному top. Я вижу её каждый день. Но сегодня впервые увидел эту вкладку. Для проверки открыл несколько других серверов, на которых бываю регулярно, там этой вкладки нет. То есть это не я такой невнимательный. Её реально раньше не было.
Полез искать в инете информацию и узнал, что, начиная с версии 3.2.0, появилась настройка (войти по F2) Show tabs for screen, которая включает эту вкладку с I/O. В Debian 12 из базового репозитория ставится версия 3.2.2 и там эта опция включена по умолчанию. Увидел мнение, что якобы последнее время активно ведётся разработка и развитие htop.
Такое вот полезное нововведение. Обновляйте или ставьте htop, если ещё не поставили и пользуйтесь новыми возможностями. Они реально полезны и заменяют многие консольные утилиты, которые показывают примерно то же самое.
Это только я такой слоупок? Вы знали об этом нововведении?
#linux #htop
{kind=link}
Протокол ipv6 получил уже довольно широкое распространение по миру. Но конкретно в нашей стране, а тем более в локальной инфраструктуре он присутствует примерно нигде. По крайней мере я ни сам не видел его, ни упоминания о том, что кто-то использует его в своих локальных сетях. В этом просто нет смысла. Это в интернете заканчиваются IP адреса, а не в наших локалках.
С такими вводными оставлять включенным протокол ipv6 не имеет большого смысла. Его надо отдельно настраивать, следить за безопасностью, совместимостью и т.д. Как минимум, надо не забывать настраивать файрвол для него. Если ipv6 вам не нужен, то логично его просто отключить. В Linux это можно сделать разными способами:
1. Через настройки sysctl.
2. Через параметры GRUB.
3. Через сетевые настройки конкретного интерфейса.
Я не знаю, какой из них оптимальный.
В разное время и в разных ситуациях я действую по обстоятельствам. Если система уже настроена и введена в эксплуатацию, то системные настройки трогать уже не буду. Просто отключу на всех сервисах, что слушают ipv6 интерфейс, его работу.
Если же система только настраивается, то можно в GRUB отключить использование ipv6. Это глобальный метод, который гарантированно отключает во всей системе ipv6. Для этого в его конфиг (
После этого нужно обновить загрузчик. В зависимости от системы выглядеть это может по-разному:
Первые три варианта с большей вероятностью подойдут для deb дистрибутивов (для Debian 12 точно подойдут), последняя для rpm. Лучше отдельно уточнить этот момент для вашей системы.
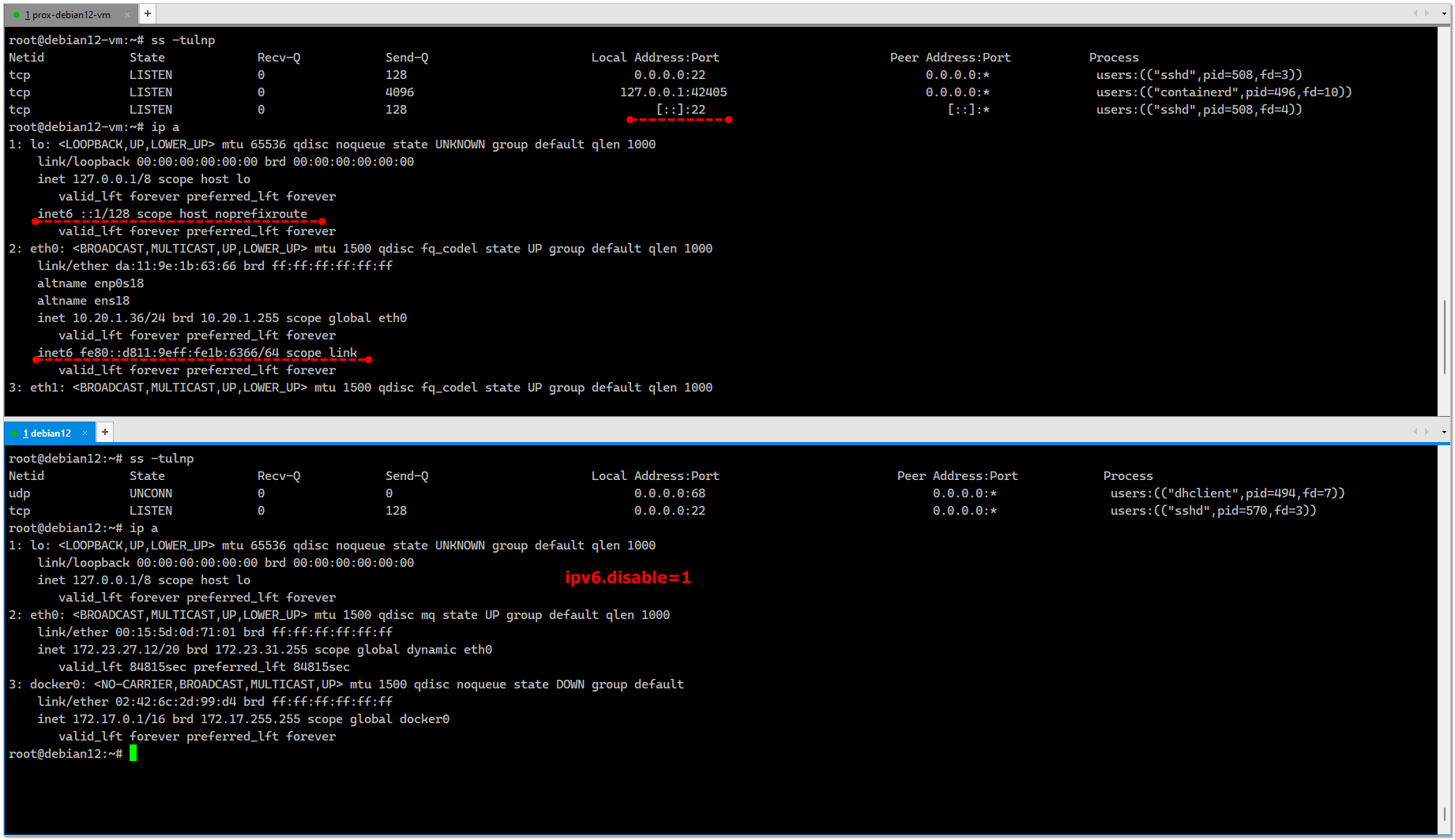
После этого нужно перезагрузить систему и проверить результат. В настройках сетевых интерфейсов не должно быть ipv6 адресов, как и в открытых портах:
Для Windows такую рекомендацию не могу дать, так как слышал информацию, что отключение ipv6 там может привести к проблемам с системой. Так что лучше этот протокол не трогать. Деталей не знаю, подробно не изучал тему, но что-то там ломается без ipv6.
Отключаете у себя ipv6?
#linux #network #ipv6
С такими вводными оставлять включенным протокол ipv6 не имеет большого смысла. Его надо отдельно настраивать, следить за безопасностью, совместимостью и т.д. Как минимум, надо не забывать настраивать файрвол для него. Если ipv6 вам не нужен, то логично его просто отключить. В Linux это можно сделать разными способами:
1. Через настройки sysctl.
2. Через параметры GRUB.
3. Через сетевые настройки конкретного интерфейса.
Я не знаю, какой из них оптимальный.
В разное время и в разных ситуациях я действую по обстоятельствам. Если система уже настроена и введена в эксплуатацию, то системные настройки трогать уже не буду. Просто отключу на всех сервисах, что слушают ipv6 интерфейс, его работу.
Если же система только настраивается, то можно в GRUB отключить использование ipv6. Это глобальный метод, который гарантированно отключает во всей системе ipv6. Для этого в его конфиг (
/etc/default/grub), конкретно в параметр GRUB_CMDLINE_LINUX, нужно добавить значение ipv6.disable=1. Если там уже указаны другие значения, то перечислены они должны быть через пробел. Примерно так:GRUB_CMDLINE_LINUX="crashkernel=auto rhgb quiet ipv6.disable=1"После этого нужно обновить загрузчик. В зависимости от системы выглядеть это может по-разному:
# dpkg-reconfigure grub-pc# update-grub# grub-mkconfig -o /boot/grub/grub.cfg# grub2-mkconfig -o /boot/grub2/grub.cfgПервые три варианта с большей вероятностью подойдут для deb дистрибутивов (для Debian 12 точно подойдут), последняя для rpm. Лучше отдельно уточнить этот момент для вашей системы.
После этого нужно перезагрузить систему и проверить результат. В настройках сетевых интерфейсов не должно быть ipv6 адресов, как и в открытых портах:
# ip a# ss -tulnpДля Windows такую рекомендацию не могу дать, так как слышал информацию, что отключение ipv6 там может привести к проблемам с системой. Так что лучше этот протокол не трогать. Деталей не знаю, подробно не изучал тему, но что-то там ломается без ipv6.
Отключаете у себя ipv6?
#linux #network #ipv6
{kind=link}
За всю мою трудовую деятельность на поприще администрирования серверов Linux мне не приходилось сбрасывать пароль системного root. От mysql серверов приходилось и не раз, а вот системный не было нужды. Всегда доставались сервера с известными учётками, а сам я их не забывал никогда.
Решил посмотреть как это делается и вам рассказать. Это типовая задача для собеседований, либо для базовой сертификации Redhat, типа RHCE и RHCSA. Если не ошибаюсь, какая-то из этих сертификаций начинается с того, что вам надо сбросить пароль root. Где-то слышал об этом, но могу ошибаться, так как сам эти экзамены не сдавал.
Задача оказалась простейшая. Я даже не ожидал, что настолько. Правда, есть нюансы. В общем случае, вам нужно включить машину, дождаться загрузочного меню GRUB и нажать латинскую
Всё реально просто, в инете масса инструкций. Но, к примеру, с Hyper-V у меня не получилось провернуть такой трюк. Не знаю по какой причине, но с указанной настройкой ядра система загружается, но потом вообще не реагирует на нажатия клавиатуры. Наглухо повисает управление. И так, и сяк пробовал, ничего не получилось. Остаётся только один путь - загружаться с какого-то livecd, монтировать корень системы и сбрасывать пароль там. При этом с Proxmox таких проблем не возникло.
В принципе, запоминать всё это не имеет большого смысла, так как гуглится за 5 минут. Достаточно просто знать, что для сброса пароля root необходимо:
1️⃣ Иметь прямой доступ к консоли сервера.
2️⃣ Изменить сценарий загрузки ядра, добавив туда прямой запуск командной оболочки через параметр init.
3️⃣ Загрузиться с изменённым init и штатно задать пароль root.
А что вообще в итоге происходит? Что означает этот init? В unix-подобных системах init является первым запускаемым процессом, который будет родителем всех остальных процессов. Он обычно живёт в
Для форков RHEL инструкция будет немного другая. Там команда ядра, которую надо добавить будет не
. Ну а смысл тот же самый.
В Windows процедура сброса пароля администратора более замороченная.
#linux
Решил посмотреть как это делается и вам рассказать. Это типовая задача для собеседований, либо для базовой сертификации Redhat, типа RHCE и RHCSA. Если не ошибаюсь, какая-то из этих сертификаций начинается с того, что вам надо сбросить пароль root. Где-то слышал об этом, но могу ошибаться, так как сам эти экзамены не сдавал.
Задача оказалась простейшая. Я даже не ожидал, что настолько. Правда, есть нюансы. В общем случае, вам нужно включить машину, дождаться загрузочного меню GRUB и нажать латинскую
e. Попадёте в окно с настройкой параметров загрузки ядра. Ищите строку, которая начинается с Linux, и в самый конец дописываете: rw init=/bin/bash. Дальше жмёте ctrl+x или F10 и начинается стандартная загрузка. В конце вы сразу же окажитесь в командной строке под пользователем root без ввода какого-либо пароля. Теперь его можно сбросить командой passwd.Всё реально просто, в инете масса инструкций. Но, к примеру, с Hyper-V у меня не получилось провернуть такой трюк. Не знаю по какой причине, но с указанной настройкой ядра система загружается, но потом вообще не реагирует на нажатия клавиатуры. Наглухо повисает управление. И так, и сяк пробовал, ничего не получилось. Остаётся только один путь - загружаться с какого-то livecd, монтировать корень системы и сбрасывать пароль там. При этом с Proxmox таких проблем не возникло.
В принципе, запоминать всё это не имеет большого смысла, так как гуглится за 5 минут. Достаточно просто знать, что для сброса пароля root необходимо:
1️⃣ Иметь прямой доступ к консоли сервера.
2️⃣ Изменить сценарий загрузки ядра, добавив туда прямой запуск командной оболочки через параметр init.
3️⃣ Загрузиться с изменённым init и штатно задать пароль root.
А что вообще в итоге происходит? Что означает этот init? В unix-подобных системах init является первым запускаемым процессом, который будет родителем всех остальных процессов. Он обычно живёт в
/sbin/init. В современных системах это ссылка на systemd, так как именно она управляет загрузкой системы. С помощью параметра ядра init мы заменяем системный init, который загружается при стандартном запуске системы, на оболочку bash. Ну и получаем её загрузку самой первой. Это если на пальцах, как я это понимаю. В документацию специально не углублялся.Для форков RHEL инструкция будет немного другая. Там команда ядра, которую надо добавить будет не
rw init=/bin/bash, а rw rd.break enforcing=0. Ну а смысл тот же самый.
В Windows процедура сброса пароля администратора более замороченная.
#linux
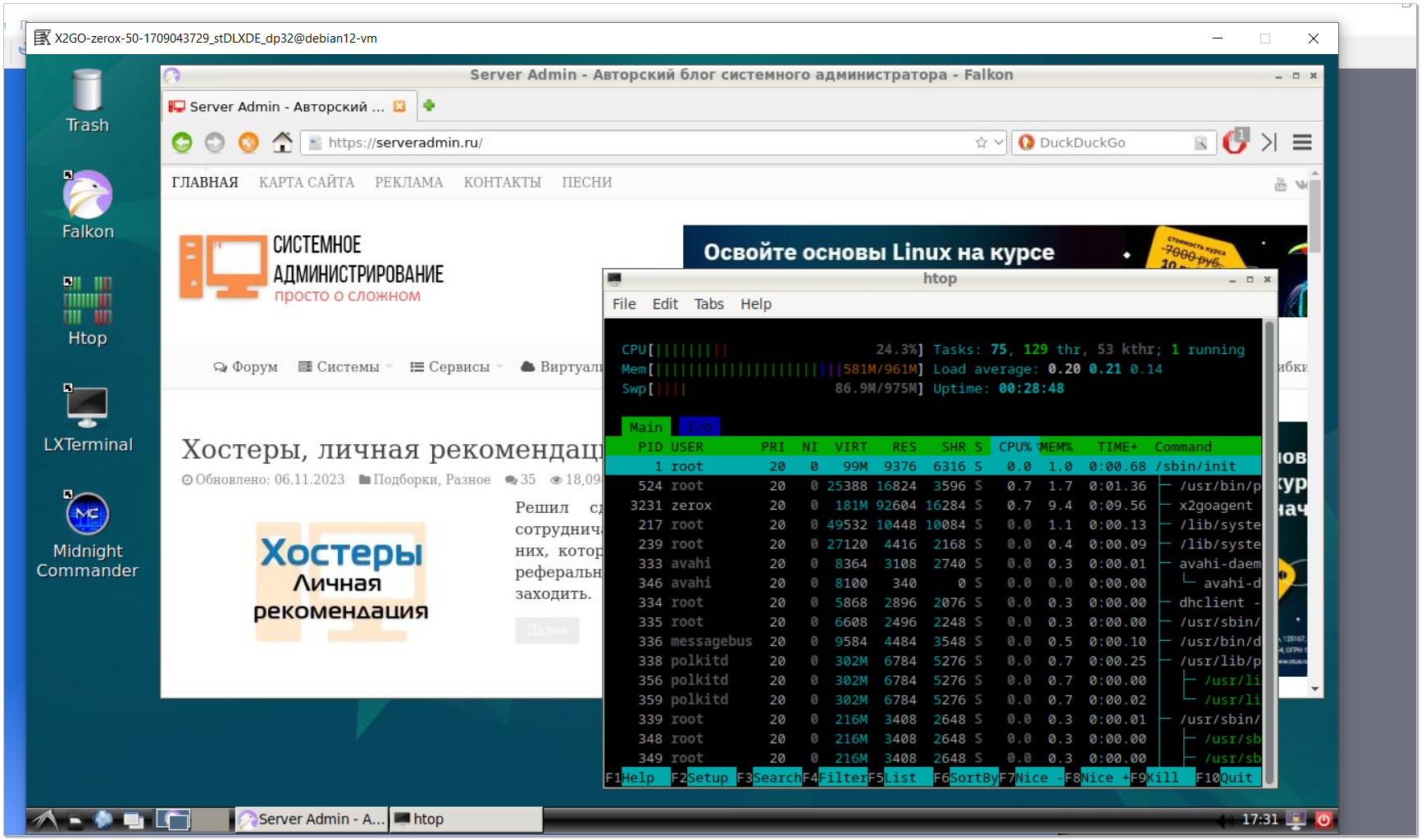
Решил проверить, на какой минимальной VPS можно поднять Linux с рабочим столом и браузером, чтобы можно было подключаться к нему и работать удалённо. Это актуально для тех, у кого есть потребность в рабочем месте, где гарантированно будет нигде не засвеченный ранее твой IP адрес. Если использовать VPN или прокси на основной машине, рано или поздно всё равно спалишь свой IP из-за каких-нибудь ошибок. И получишь блок акка.
Взял VPS 1CPU, 1Gb RAM, 10Gb SSD и у меня всё получилось. Использовал:
▪ Debian 12 minimal в качестве системы
▪ Lxde-core в качестве графического окружения
▪ X2Go в качестве удалённого доступа к системе
Настройка максимально простая, осилит каждый. Устанавливаем lxde-core и x2go:
Уже можно подключаться, скачав клиент x2go под свою систему. В качестве аутентификации используется локальная учётка пользователя, не root, с правами подключения по ssh.
Далее можно установить любой браузер. Я вычитал, что Falkon наименее прожорливый и поставил его:
Понятное дело, что с такими ресурсами всё это работает не очень быстро, но пользоваться можно. Если пользоваться предполагается активно, то надо добавить ещё ядро CPU и еще гиг памяти. Тогда вообще нормально будет.
Я так понимаю, подобную связку lxde-core и falkon можно использовать на старом железе. Можно наверное ещё всё это как-то ужать, используя более специализированные системы и софт, но мне хотелось использовать именно базу, чтобы без заморочек взять и развернуть на стандартном ПО.
#linux
Взял VPS 1CPU, 1Gb RAM, 10Gb SSD и у меня всё получилось. Использовал:
▪ Debian 12 minimal в качестве системы
▪ Lxde-core в качестве графического окружения
▪ X2Go в качестве удалённого доступа к системе
Настройка максимально простая, осилит каждый. Устанавливаем lxde-core и x2go:
# apt install x2goserver x2goserver-xsession lxde-coreУже можно подключаться, скачав клиент x2go под свою систему. В качестве аутентификации используется локальная учётка пользователя, не root, с правами подключения по ssh.
Далее можно установить любой браузер. Я вычитал, что Falkon наименее прожорливый и поставил его:
# apt install falkonПонятное дело, что с такими ресурсами всё это работает не очень быстро, но пользоваться можно. Если пользоваться предполагается активно, то надо добавить ещё ядро CPU и еще гиг памяти. Тогда вообще нормально будет.
Я так понимаю, подобную связку lxde-core и falkon можно использовать на старом железе. Можно наверное ещё всё это как-то ужать, используя более специализированные системы и софт, но мне хотелось использовать именно базу, чтобы без заморочек взять и развернуть на стандартном ПО.
#linux
{kind=link}
В ОС на базе ядра Linux реализован механизм изоляции системных вызовов под названием namespace. С его помощью каждое приложение может быть изолировано от других средствами самого ядра, без сторонних инструментов. Попробую простыми словами рассказать, что это такое.
Покажу сразу на простом примере. Запустим оболочку bash с отдельными namespace PID и mount. То есть мы получим изолированную среду на уровне процессов и точек монтирования. Новый процесс bash в этом namespace получит id 1.
Теперь на условном примере покажу изоляцию mount. Здесь же в изолированных namespaces добавляем монтирование:
При этом на самом хосте вы этого mount не увидите. Если в изолированном namespace создать что-то в /tmp/dir1, оно появится в /mnt/dir1, а если на хосте зайти в /mnt/dir1 там будет пусто, потому что для хоста этого монтирования не существует.
Посмотреть существующие namespaces можно командой
Там будет видно в том числе созданные нами namespaces для форка bash. Это будут mnt и pid. Если у вас на хосте запущены контейнеры, то здесь же их и увидите. Работа контейнеров основана на этом механизме ядра.
Из показанного примера видно, что использовать изоляцию можно и без контейнеров. Можно создавать юниты systemd с использованием namespaces. Базово в системе уже есть некоторые юниты, работающие в своём пространстве. Их видно по
С помощью утилиты nsenter можно запускать процессы в произвольных namespaces. Откроем отдельную консоль и запустим процесс в созданном ранее namespace с bash. Для этого с помощью
#
Возвращаемся в консоль с unshare и смотрим список процессов:
Видим процесс со sleep. Базово всё это попробовать довольно просто, но на самом деле там очень много нюансов. Поэтому все и пользуются готовыми решениями на базе этой технологии, типа Docker.
Всего существует следующий набор namespaces:
- mount - изоляция на уровне монтирования файловых систем;
- UTS - изоляция hostname и domainname, т.е. в каждом ns может быть своё имя хоста;
- IPC - изоляция межпроцессорного взаимодействия (Inter-process communication);
- network - свои сетевые настройки для разных ns, включая ip адреса, маршруты, правила файрволов;
- PID - изоляция процессов;
- user - изоляция пользовательских UIDs и GIDs;
- cgroup - ограничивает потребляемый объём аппаратных ресурсов, cpu, ram, io и т.д.;
- time - изоляция некоторых параметров времени, а конкретно только MONOTONIC и BOOTTIME, установить разное текущее время в разных ns нельзя.
Все эти ns можно использовать с помощью утилит unshare и nsenter. Также существует отдельный продукт systemd-nspawn, один из компонентов systemd, который реализует возможности для создания легковесных контейнеров. Он как-то не особо распространён, не знаю почему. По идее, благодаря тесной интеграции с systemd это должно быть удобно, так как systemd сейчас везде.
#linux
Покажу сразу на простом примере. Запустим оболочку bash с отдельными namespace PID и mount. То есть мы получим изолированную среду на уровне процессов и точек монтирования. Новый процесс bash в этом namespace получит id 1.
# unshare --pid --fork --mount-proc --mount /bin/bash# ps ax PID TTY STAT TIME COMMAND 1 pts/0 S 0:00 /bin/bash 45 pts/0 R+ 0:00 ps axТеперь на условном примере покажу изоляцию mount. Здесь же в изолированных namespaces добавляем монтирование:
# mkdir /tmp/dir1 /mnt/dir1# mount --bind /tmp/dir1 /mnt/dir1# mount | grep dir1/dev/sda2 on /mnt/dir1 type ext4 (rw,relatime,errors=remount-ro)При этом на самом хосте вы этого mount не увидите. Если в изолированном namespace создать что-то в /tmp/dir1, оно появится в /mnt/dir1, а если на хосте зайти в /mnt/dir1 там будет пусто, потому что для хоста этого монтирования не существует.
Посмотреть существующие namespaces можно командой
lsns:# lsns................................................4026532129 mnt 2 853 root unshare --pid --fork --mount-proc --mount /bin/bash4026532130 pid 1 854 root └─/bin/bash.................................................Там будет видно в том числе созданные нами namespaces для форка bash. Это будут mnt и pid. Если у вас на хосте запущены контейнеры, то здесь же их и увидите. Работа контейнеров основана на этом механизме ядра.
Из показанного примера видно, что использовать изоляцию можно и без контейнеров. Можно создавать юниты systemd с использованием namespaces. Базово в системе уже есть некоторые юниты, работающие в своём пространстве. Их видно по
lsns. С помощью утилиты nsenter можно запускать процессы в произвольных namespaces. Откроем отдельную консоль и запустим процесс в созданном ранее namespace с bash. Для этого с помощью
lsns узнаём pid процесса в ns pid и подцепляем к нему, к примеру, команду sleep.# lsns | grep /bin/bash4026532129 mnt 2 853 root unshare --pid --fork --mount-proc --mount /bin/bash4026532130 pid 1 854 root └─/bin/bash#
nsenter -t 854 -m -p sleep 60Возвращаемся в консоль с unshare и смотрим список процессов:
# ps ax PID TTY STAT TIME COMMAND 1 pts/0 S 0:00 /bin/bash 50 pts/2 S+ 0:00 sleep 60 51 pts/0 R+ 0:00 ps axВидим процесс со sleep. Базово всё это попробовать довольно просто, но на самом деле там очень много нюансов. Поэтому все и пользуются готовыми решениями на базе этой технологии, типа Docker.
Всего существует следующий набор namespaces:
- mount - изоляция на уровне монтирования файловых систем;
- UTS - изоляция hostname и domainname, т.е. в каждом ns может быть своё имя хоста;
- IPC - изоляция межпроцессорного взаимодействия (Inter-process communication);
- network - свои сетевые настройки для разных ns, включая ip адреса, маршруты, правила файрволов;
- PID - изоляция процессов;
- user - изоляция пользовательских UIDs и GIDs;
- cgroup - ограничивает потребляемый объём аппаратных ресурсов, cpu, ram, io и т.д.;
- time - изоляция некоторых параметров времени, а конкретно только MONOTONIC и BOOTTIME, установить разное текущее время в разных ns нельзя.
Все эти ns можно использовать с помощью утилит unshare и nsenter. Также существует отдельный продукт systemd-nspawn, один из компонентов systemd, который реализует возможности для создания легковесных контейнеров. Он как-то не особо распространён, не знаю почему. По идее, благодаря тесной интеграции с systemd это должно быть удобно, так как systemd сейчас везде.
#linux
{kind=link}
▶️ Очередная подборка авторских IT роликов, которые я лично посмотрел и посчитал интересными/полезными. Как раз к выходным.
▪ Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox
Новое прохождение задания на Hackthebox по взлому операционной системы. Не буду подробно описывать видео. Оно по структуре и тематике такое же как прошлое, где я подробно разобрал, о чём там речь. Только тут задача посложнее и подольше. Смотреть интересно, но только если понимаешь, что там происходит. В целом, контент очень качественный, рекомендую.
▪ Как в Synology просто и быстро развернуть несколько сайтов в пару кликов
Автор рассказывает, как в Synology настроить веб сервер и захостить там сайты. Когда-то давным-давно мой сайт некоторое время жил у меня в квартире на Synology. В целом, работал нормально, но мне быстро надоел постоянно работающий сервер. Убрал сайт на хостинг, а NAS стал периодически выключать.
▪ Организация компьютерных сетей
▪ Терминология сетей
Андрей Созыкин начал работу над новой актуальной версией курса по компьютерным сетям. Первые уроки уже смонтированы, можно посмотреть.
▪ Proxmox Установка и обзор функций WebUI
Простая установка и разбор возможностей веб интерфейса Proxmox. Конкретно в этом видео ничего особо нового и интересного нет. Автор обещает дальше настройку кластера, настройку бэкапов в PBS. Так что имеет смысл подписаться и следить, если интересна эта тема.
▪ Monitor Storage S.M.A.R.T With ZABBIX - Tutorial
Инструкция от Dmitry Lambert о том, как мониторить показатели SMART с помощью Zabbix agent 2. В инструкции он показывает на примере системы Windows. То есть это решение в основном для мониторинга за рабочими станциями.
🔥Running Windows in a Docker Container!
История о том, как на Linux запустить любую версию Windows с помощью Docker контейнера и зайти в неё через браузер. Сначала подумал, что за магия? На самом деле никакой магии. Контейнер поднимает KVM, создаёт виртуалку и запускает. Весь процесс автоматизирован. По этой теме имеет смысл сделать отдельную публикацию с описанием. Очень интересное решение получилось. Я пока только посмотрел, сам не пробовал запускать.
Если посмотрите видео, то не забудьте зайти в комментарии и поблагодарить авторов. Вам это ничего не стоит, а им приятно.
#видео
▪ Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox
Новое прохождение задания на Hackthebox по взлому операционной системы. Не буду подробно описывать видео. Оно по структуре и тематике такое же как прошлое, где я подробно разобрал, о чём там речь. Только тут задача посложнее и подольше. Смотреть интересно, но только если понимаешь, что там происходит. В целом, контент очень качественный, рекомендую.
▪ Как в Synology просто и быстро развернуть несколько сайтов в пару кликов
Автор рассказывает, как в Synology настроить веб сервер и захостить там сайты. Когда-то давным-давно мой сайт некоторое время жил у меня в квартире на Synology. В целом, работал нормально, но мне быстро надоел постоянно работающий сервер. Убрал сайт на хостинг, а NAS стал периодически выключать.
▪ Организация компьютерных сетей
▪ Терминология сетей
Андрей Созыкин начал работу над новой актуальной версией курса по компьютерным сетям. Первые уроки уже смонтированы, можно посмотреть.
▪ Proxmox Установка и обзор функций WebUI
Простая установка и разбор возможностей веб интерфейса Proxmox. Конкретно в этом видео ничего особо нового и интересного нет. Автор обещает дальше настройку кластера, настройку бэкапов в PBS. Так что имеет смысл подписаться и следить, если интересна эта тема.
▪ Monitor Storage S.M.A.R.T With ZABBIX - Tutorial
Инструкция от Dmitry Lambert о том, как мониторить показатели SMART с помощью Zabbix agent 2. В инструкции он показывает на примере системы Windows. То есть это решение в основном для мониторинга за рабочими станциями.
🔥Running Windows in a Docker Container!
История о том, как на Linux запустить любую версию Windows с помощью Docker контейнера и зайти в неё через браузер. Сначала подумал, что за магия? На самом деле никакой магии. Контейнер поднимает KVM, создаёт виртуалку и запускает. Весь процесс автоматизирован. По этой теме имеет смысл сделать отдельную публикацию с описанием. Очень интересное решение получилось. Я пока только посмотрел, сам не пробовал запускать.
Если посмотрите видео, то не забудьте зайти в комментарии и поблагодарить авторов. Вам это ничего не стоит, а им приятно.
#видео
YouTube
Прохождение #Linux-машины DRIVE.HTB, сложного уровня | #HackTheBox | КАК ПРОЙТИ #DRIVE.HTB
Как решить машину DRIVE на HackTheBox?
Drive — это сложная(средняя) машина Linux, которая включает в себя сервис обмена файлами, подверженный уязвимости #IDOR (Insecure Direct Object Reference), через который обнаруживается простой текстовый пароль, приводящий…
Drive — это сложная(средняя) машина Linux, которая включает в себя сервис обмена файлами, подверженный уязвимости #IDOR (Insecure Direct Object Reference), через который обнаруживается простой текстовый пароль, приводящий…
В Linux относительно просто назначить выполнение того или иного процесса на заданном количестве ядер процессора. Для этого используется утилита taskset. Она может "сажать" на указанные ядра как запущенный процесс, так и запустить новый с заданными параметрами.
1️⃣ Покажу сразу на примерах. Допустим, у вас есть какой-то процесс, который по умолчанию может занимать ресурсы всех ядер процессора. Допустим, вы хотите разрешить ему работать только на первых двух. Для того, чтобы это сделать, нам необходимо узнать pid процесса:
Выбирайте любой способ, какой больше нравится. Смотрим, какие у нас процессоры и ядра в системе:
Видим четыре CPU с 0 по 3. Посадим наш процесс на первые два ядра:
Где 927 - это pid процесса. Видим, что привязка изменилась с 0-3 на 0,1.
2️⃣ Менять привязку уже запущенных процессов мне кажется не таким полезным, как иметь возможность запустить процесс с заданными параметрами. Это более практичная возможность, для которой нетрудно придумать реальный пример.
Я активно использую архиватор pigz, который умеет жать всеми доступными ядрами. Ему можно задать ограничение на использование ядер, но он будет случайным образом занимать ядра и почти всегда нулевое будет занято. А его желательно оставить свободным для остальных задач. Особенно если вы снимаете дампы СУБД и сразу жмёте в каком-то нагруженном сервере. В таком случае можно явно во время запуска указать pigz, какие ядра использовать.
Для этого нужно запустить программу через taskset, указав ядра, на которых она будет работать. К сожалению, для этого не получится использовать простой список ядер, типа 1,2,3. Нужно использовать bitmask в полном или сокращённом виде. Например, использование только 0-го ядра будет выглядеть вот так:
или просто
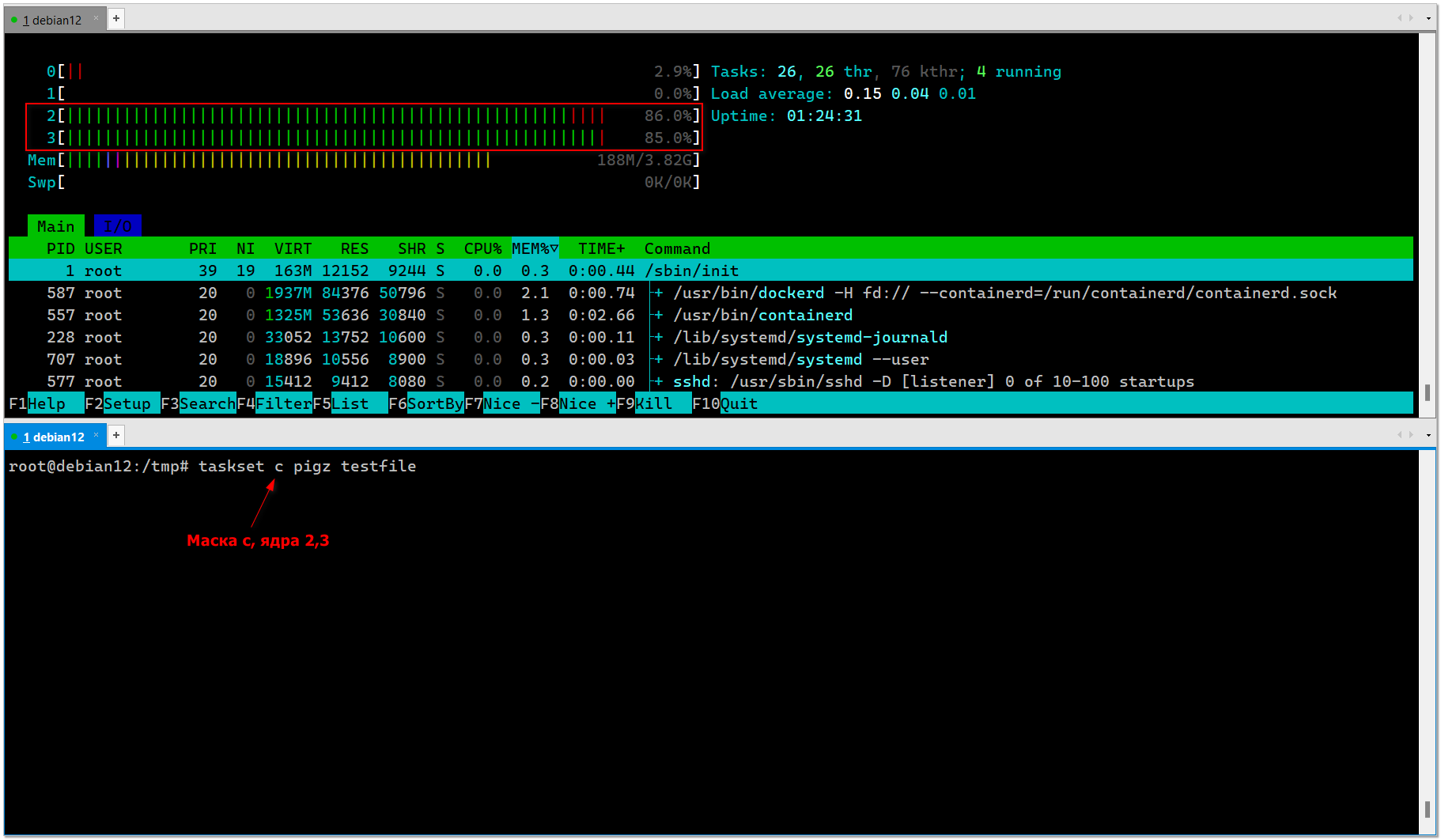
Pigz будет жать только одним, нулевым ядром. Я до конца не разобрался, как быстро понять, какая маска тебе нужна. Самый простой способ это узнать, проверить на каком-то работающем процессе. Ему можно задать список ядер не маской, а явно. Допустим, нам нужна запустить архиватор только на 2 и 3 ядре. Для этого назначим, к примеру, эти ядра для htop и посмотрим нужную маску:
Маска
Я взял для примера именно pigz, потому что на нём наглядно видны все настройки. Какие ядра задал, такие он и использует. Для этого достаточно создать небольшой тестовый файл и понаблюдать через htop его поведение:
Список масок, которые имеют отношение к первым 4-м ядрам:
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
◽
#linux #system
1️⃣ Покажу сразу на примерах. Допустим, у вас есть какой-то процесс, который по умолчанию может занимать ресурсы всех ядер процессора. Допустим, вы хотите разрешить ему работать только на первых двух. Для того, чтобы это сделать, нам необходимо узнать pid процесса:
# ps ax | grep mc# ps -T -C mc | awk '{print $2}' | grep -E '[0-9]'# pidof mcВыбирайте любой способ, какой больше нравится. Смотрим, какие у нас процессоры и ядра в системе:
# lscpu | grep -i CPU\(s\)# lscpu | grep -i numaNUMA node(s): 1NUMA node0 CPU(s): 0-3Видим четыре CPU с 0 по 3. Посадим наш процесс на первые два ядра:
# taskset -pc 0-1 927pid 927's current affinity list: 0-3pid 927's new affinity list: 0,1Где 927 - это pid процесса. Видим, что привязка изменилась с 0-3 на 0,1.
2️⃣ Менять привязку уже запущенных процессов мне кажется не таким полезным, как иметь возможность запустить процесс с заданными параметрами. Это более практичная возможность, для которой нетрудно придумать реальный пример.
Я активно использую архиватор pigz, который умеет жать всеми доступными ядрами. Ему можно задать ограничение на использование ядер, но он будет случайным образом занимать ядра и почти всегда нулевое будет занято. А его желательно оставить свободным для остальных задач. Особенно если вы снимаете дампы СУБД и сразу жмёте в каком-то нагруженном сервере. В таком случае можно явно во время запуска указать pigz, какие ядра использовать.
Для этого нужно запустить программу через taskset, указав ядра, на которых она будет работать. К сожалению, для этого не получится использовать простой список ядер, типа 1,2,3. Нужно использовать bitmask в полном или сокращённом виде. Например, использование только 0-го ядра будет выглядеть вот так:
# taskset 0x00000001 pigz testfileили просто
# taskset 1 pigz testfilePigz будет жать только одним, нулевым ядром. Я до конца не разобрался, как быстро понять, какая маска тебе нужна. Самый простой способ это узнать, проверить на каком-то работающем процессе. Ему можно задать список ядер не маской, а явно. Допустим, нам нужна запустить архиватор только на 2 и 3 ядре. Для этого назначим, к примеру, эти ядра для htop и посмотрим нужную маску:
# taskset -pc 2-3 `pidof htop`pid 984's current affinity list: 0-3pid 984's new affinity list: 2,3Смотрим маску:# taskset -p `pidof htop`pid 984's current affinity mask: cМаска
c. Запускаем pigz с этой маской, чтобы он жал только на 2 и 3 ядрах, оставив первые два свободными:# taskset c pigz testfileЯ взял для примера именно pigz, потому что на нём наглядно видны все настройки. Какие ядра задал, такие он и использует. Для этого достаточно создать небольшой тестовый файл и понаблюдать через htop его поведение:
# dd if=/dev/zero of=/tmp/testfile bs=1024 count=2000000# taskset 6 pigz testfileСписок масок, которые имеют отношение к первым 4-м ядрам:
◽
1 - ядро 0◽
2 - ядро 1◽
3 - ядра 0,1◽
4 - ядро 2◽
5 - ядра 0,2◽
6 - ядра 1,2◽
7 - ядра 1,2,3◽
8 - ядро 3◽
9 - ядра 0,3◽
a - ядра 1,3◽
b - ядра 0,1,3◽
с - ядра 2,3◽
d - ядра 0,2,3#linux #system
{kind=link}