
Думаю, все хорошо знают такой продукт, как Grafana. Оказывается, у них есть облачная версия сервиса с бесплатным тарифным планом. Причем там такие лимиты, которых хватит для некоторых полезных применений.
https://grafana.com/products/cloud/
Теперь рассказываю, как можно с пользой использовать этот сервис. Если у вас есть мониторинг от Zabbix, а тем более несколько серверов, вы можете без проблем установить плагин для Zabbix в графану. В облаке его не будет в списке доступных плагинов, но если перейти на https://grafana.com/grafana/plugins/alexanderzobnin-zabbix-app/ выбрать install, то там появится возможность установить его в свое облако.
Ну дальше настраиваете Data Source для своего Zabbix сервера, или даже нескольких. И делаете необходимые вам дашборды. К примеру, я все свои Zabbix сервера собираю на один дашборд и вывожу информацию по триггерам. Это позволяет быстро оценить проблемы на всех серверах, что я обслуживаю. Для этой задачи ограничения бесплатной версии вообще не доставляют неудобств.
Подробнее об этом рассказываю в отдельной статье - https://serveradmin.ru/nastrojka-intergaczii-zabbix-v-grafana/ В ней как раз можно воспользоваться описываемым облаком. Очень удобно. У меня для этих целей своя графана настроена, но если бы раньше узнал, что можно бесплатной воспользоваться, сделал бы это.
#zabbix #grafana #мониторинг
https://grafana.com/products/cloud/
Теперь рассказываю, как можно с пользой использовать этот сервис. Если у вас есть мониторинг от Zabbix, а тем более несколько серверов, вы можете без проблем установить плагин для Zabbix в графану. В облаке его не будет в списке доступных плагинов, но если перейти на https://grafana.com/grafana/plugins/alexanderzobnin-zabbix-app/ выбрать install, то там появится возможность установить его в свое облако.
Ну дальше настраиваете Data Source для своего Zabbix сервера, или даже нескольких. И делаете необходимые вам дашборды. К примеру, я все свои Zabbix сервера собираю на один дашборд и вывожу информацию по триггерам. Это позволяет быстро оценить проблемы на всех серверах, что я обслуживаю. Для этой задачи ограничения бесплатной версии вообще не доставляют неудобств.
Подробнее об этом рассказываю в отдельной статье - https://serveradmin.ru/nastrojka-intergaczii-zabbix-v-grafana/ В ней как раз можно воспользоваться описываемым облаком. Очень удобно. У меня для этих целей своя графана настроена, но если бы раньше узнал, что можно бесплатной воспользоваться, сделал бы это.
#zabbix #grafana #мониторинг
{kind=link}
Технический пост, который уже давно нужно было сделать, но всё руки не доходили. На канале много содержательных заметок по различным темам. Иногда сам через поиск ищу то, о чём писал. Ниже набор наиболее популярных тэгов по которым можно найти что-то полезное (и не очень).
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
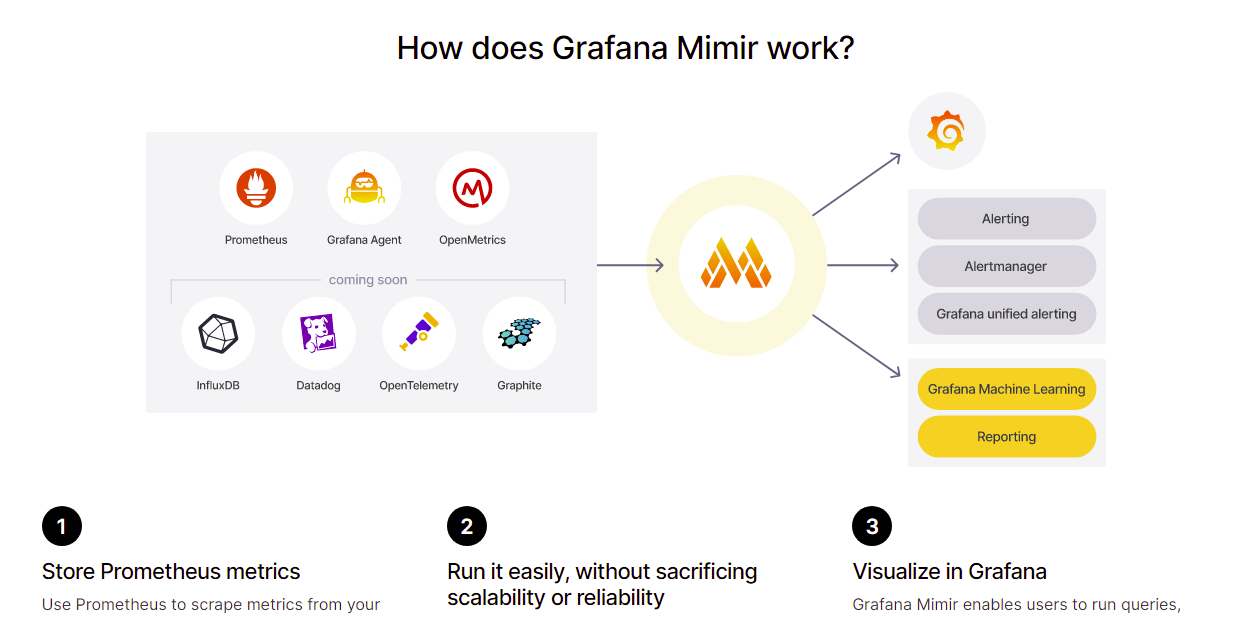
Долгосрочное хранение метрик всегда было одной из слабых сторон Prometheus. Изначально он был спроектирован для оперативного мониторинга, не подразумевающего хранение истории метрик на срок более двух недель. Сохранить в нём тренды месячных или годовых интервалов было отдельной задачей с привлечением внешних хранилищ и инструментов.
Весной Grafana анонсировала своё решение под названием Grafana Mimir, которое способно максимально просто, быстро и дёшево решить вопрос с долгосрочным хранением метрик в том числе с помощью S3 совместимого хранилища. В самом простом варианте может на файловую систему складывать данные. Одним из основных преимуществ указывается возможность быстро и просто настроить горизонтально масштабируемый high availability кластер хранения.
Настроить всё это дело реально очень просто.
1️⃣ Поднимаете в Docker сервер Mimir, указав в его конфиге бэкенд для хранения данных. В самом простом случае это может быть локальная директория.
2️⃣ Указываете в Prometheus в качестве remote_write сервер с Mimir.
3️⃣ В веб панели Grafana добавляете сервер Mimir в качестве Prometheus data source.
Авторы Mimir называют её самой производительной TSDB для долговременного хранения метрик Prometheus. Насколько это правда, трудно судить. Вот пример их нагрузочных тестов. Авторы конкурирующего хранилища из VictoriaMetrics собрали свои стенды с обоими продуктами и протестировали их производительность. В результате оказалось, что Mimir более требовательна к памяти, больше нагружает процессор и больше расходует места хранилища, но имеет ниже задержку в 50-м перцентиле и выше в 99-м. По результатам теста почти по всем параметрам Mimir хуже, причем с кратной разницей, что немного странно.
Ниже ссылка на get started, где в самом начале представлено наглядное видео по настройке связки Prometheus + Grafana + Mimir + MinIO.
Сайт - https://grafana.com/oss/mimir/
Исходники - https://github.com/grafana/mimir
Get started - https://grafana.com/docs/mimir/v2.3.x/operators-guide/get-started/
#prometheus #grafana #devops #мониторинг
Весной Grafana анонсировала своё решение под названием Grafana Mimir, которое способно максимально просто, быстро и дёшево решить вопрос с долгосрочным хранением метрик в том числе с помощью S3 совместимого хранилища. В самом простом варианте может на файловую систему складывать данные. Одним из основных преимуществ указывается возможность быстро и просто настроить горизонтально масштабируемый high availability кластер хранения.
Настроить всё это дело реально очень просто.
1️⃣ Поднимаете в Docker сервер Mimir, указав в его конфиге бэкенд для хранения данных. В самом простом случае это может быть локальная директория.
2️⃣ Указываете в Prometheus в качестве remote_write сервер с Mimir.
3️⃣ В веб панели Grafana добавляете сервер Mimir в качестве Prometheus data source.
Авторы Mimir называют её самой производительной TSDB для долговременного хранения метрик Prometheus. Насколько это правда, трудно судить. Вот пример их нагрузочных тестов. Авторы конкурирующего хранилища из VictoriaMetrics собрали свои стенды с обоими продуктами и протестировали их производительность. В результате оказалось, что Mimir более требовательна к памяти, больше нагружает процессор и больше расходует места хранилища, но имеет ниже задержку в 50-м перцентиле и выше в 99-м. По результатам теста почти по всем параметрам Mimir хуже, причем с кратной разницей, что немного странно.
Ниже ссылка на get started, где в самом начале представлено наглядное видео по настройке связки Prometheus + Grafana + Mimir + MinIO.
Сайт - https://grafana.com/oss/mimir/
Исходники - https://github.com/grafana/mimir
Get started - https://grafana.com/docs/mimir/v2.3.x/operators-guide/get-started/
#prometheus #grafana #devops #мониторинг
{kind=link}
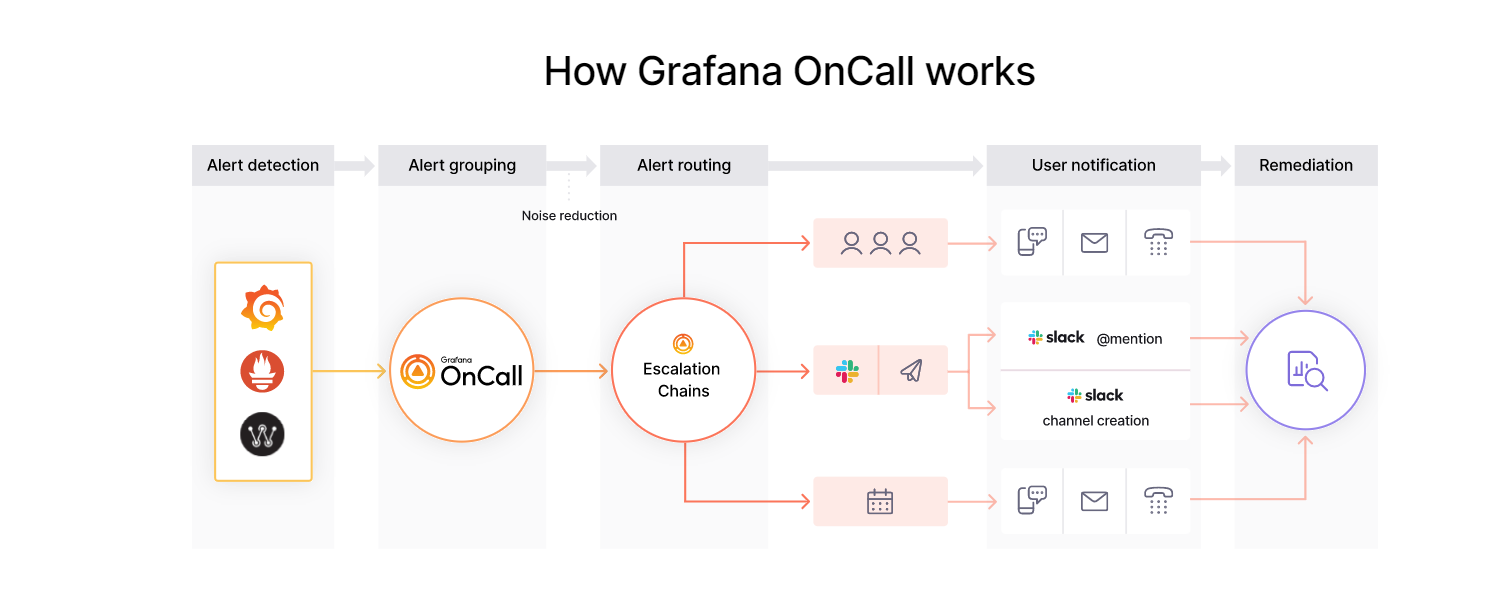
Приветствую всех любителей мониторинга. Если у вас используется несколько независимых систем мониторинга даже в рамках одного продукта, что бывает не так редко, то встаёт вопрос о централизованном управлении оповещениями. У всем известной компании Grafana есть готовое open source решение на этот счёт - OnCall.
С помощью OnCall можно собирать оповещения из Grafana, Prometheus, AlertManager и Zabbix, обрабатывать их по определённым правилам и отправлять настроенным получателям. В процессе обработки можно отбрасывать второстепенные оповещения или группировать повторяющиеся.
Обработанные события отправляются получателям по заранее настроенным маршрутам. Они могут распределяться в зависимости от занятости или рабочего времени специалиста, могут повторяться, дублироваться, отправляться по новым маршрутам в случае отсутствия решения проблемы в допустимом интервале.
Частично маршруты отправки можно реализовать и в Zabbix, но там это находится в зачаточном и не очень гибком состоянии. Например, можно настроить повторяющиеся оповещения. А если проблема не решена после нескольких отправленных оповещений через заданный интервал, можно оповестить какую-то дополнительную группу. Подробнее о возможностях можно посмотреть в описании на сайте.
В Grafana OnCall всё это реализовано очень масштабно и гибко. Куча готовых интеграций с системами оповещений (sms, почта, slack, telegram и т.д.), а сама платформа предоставляет API для интеграции с ней. Управление системой через Web интерфейс. Вот пример интеграции с Zabbix.
Для запуска есть готовый docker-compose, так что установка происходит очень просто и быстро. А далее всё делается через web интерфейс.
⇨ Сайт / Исходники / Обзор
#мониторинг #grafana
С помощью OnCall можно собирать оповещения из Grafana, Prometheus, AlertManager и Zabbix, обрабатывать их по определённым правилам и отправлять настроенным получателям. В процессе обработки можно отбрасывать второстепенные оповещения или группировать повторяющиеся.
Обработанные события отправляются получателям по заранее настроенным маршрутам. Они могут распределяться в зависимости от занятости или рабочего времени специалиста, могут повторяться, дублироваться, отправляться по новым маршрутам в случае отсутствия решения проблемы в допустимом интервале.
Частично маршруты отправки можно реализовать и в Zabbix, но там это находится в зачаточном и не очень гибком состоянии. Например, можно настроить повторяющиеся оповещения. А если проблема не решена после нескольких отправленных оповещений через заданный интервал, можно оповестить какую-то дополнительную группу. Подробнее о возможностях можно посмотреть в описании на сайте.
В Grafana OnCall всё это реализовано очень масштабно и гибко. Куча готовых интеграций с системами оповещений (sms, почта, slack, telegram и т.д.), а сама платформа предоставляет API для интеграции с ней. Управление системой через Web интерфейс. Вот пример интеграции с Zabbix.
Для запуска есть готовый docker-compose, так что установка происходит очень просто и быстро. А далее всё делается через web интерфейс.
⇨ Сайт / Исходники / Обзор
#мониторинг #grafana
{kind=link}
В одном выступлении вскользь увидел упоминание программы Grafana dashboard builder. С её помощью можно автоматически создавать дашборды графаны на основе файлов конфигураций в формате yaml. Идея интересная, поэтому решил посмотреть, как это на практике выглядит.
На то, чтобы установить, запустить и понять, как это работает, ушло довольно много времени. Программа есть в pip, но в Debian 11 просто так не ставится. Не получалось установить все зависимости. В итоге нашёл решение. Нужно было предварительно установить один пакет. В итоге установил вот так:
Далее склонировал репозиторий, чтобы взять оттуда примеры настроек и проектов:
Примеры лежат в директории
Для того, чтобы сгенерировать шаблоны на основе тестового проекта, необходимо в
В папке Example project будут сгенерированные дашборды в формате json.
Программа довольно замороченная, так что актуальна будет для очень больших инфраструктур, где надо автоматически создавать дашборды и сразу загружать их в Grafana. Экспорт в json это просто опция. Можно всё автоматизировать во время сборки.
Хотя, может и для небольших пригодится, если по какой-то причине дашборды часто меняются. При замороченность я условно написал. Просто на начальную настройку надо много времени потратить, так как сначала придётся вручную шаблоны создать.
⇨ Исходники
#grafana #devops
На то, чтобы установить, запустить и понять, как это работает, ушло довольно много времени. Программа есть в pip, но в Debian 11 просто так не ставится. Не получалось установить все зависимости. В итоге нашёл решение. Нужно было предварительно установить один пакет. В итоге установил вот так:
# apt install python3-pip# apt install heimdal-dev# pip3 install grafana-dashboard-builderДалее склонировал репозиторий, чтобы взять оттуда примеры настроек и проектов:
# git clone https://github.com/jakubplichta/grafana-dashboard-builderПримеры лежат в директории
samples. Для того, чтобы сгенерировать шаблоны на основе тестового проекта, необходимо в
config.yaml указать корректную output_folder. После этого можно запустить генерацию, находять в директории samples:# grafana-dashboard-builder -p project.yaml \--exporter file --config config.yamlВ папке Example project будут сгенерированные дашборды в формате json.
Программа довольно замороченная, так что актуальна будет для очень больших инфраструктур, где надо автоматически создавать дашборды и сразу загружать их в Grafana. Экспорт в json это просто опция. Можно всё автоматизировать во время сборки.
Хотя, может и для небольших пригодится, если по какой-то причине дашборды часто меняются. При замороченность я условно написал. Просто на начальную настройку надо много времени потратить, так как сначала придётся вручную шаблоны создать.
⇨ Исходники
#grafana #devops
{kind=link}
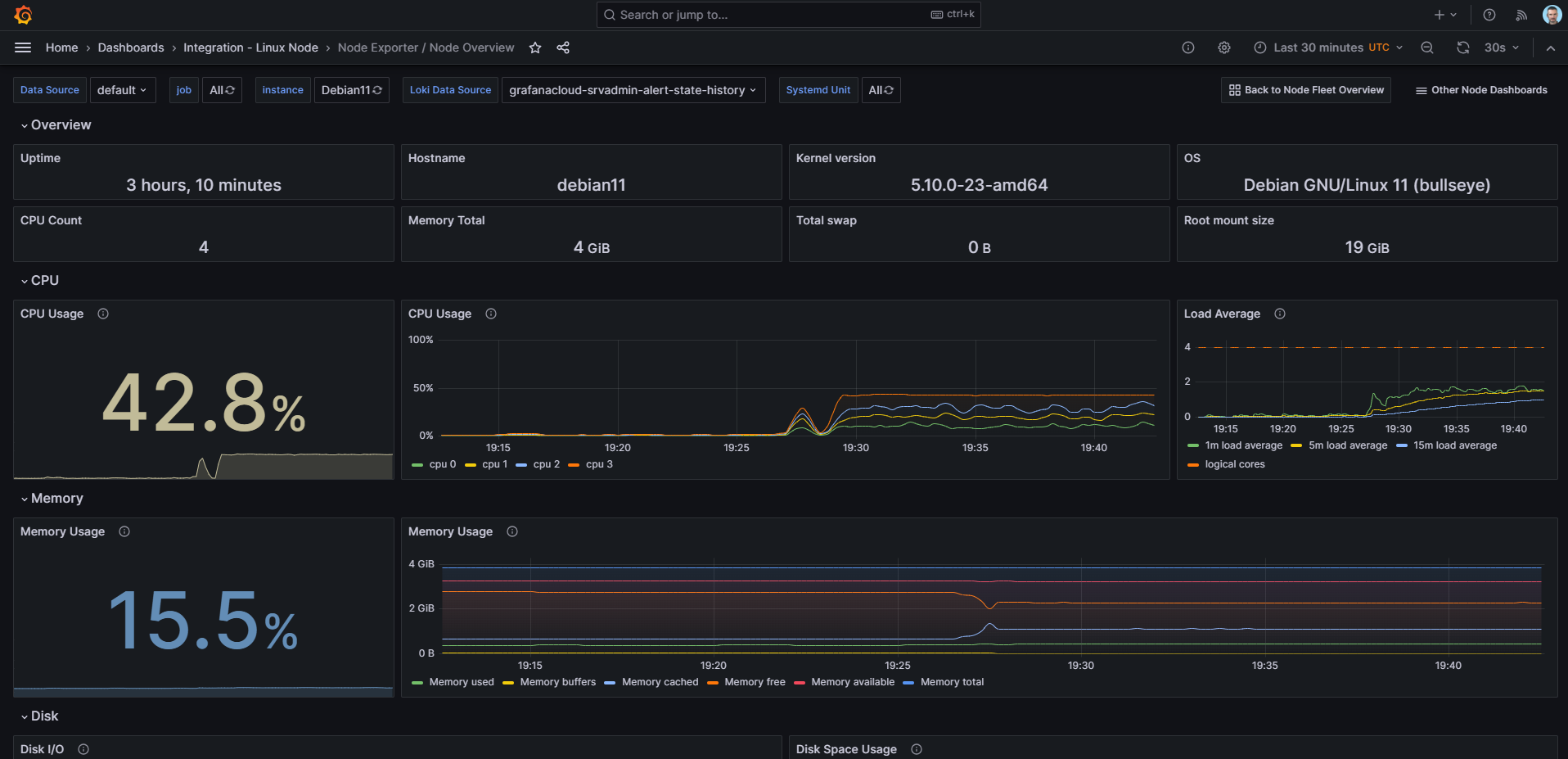
Напомню тем, кто не знает. У Grafana есть облачный сервис по мониторингу и сбору логов с бесплатным тарифным планом. Называется, как нетрудно догадаться - Grafana Cloud. Для регистрации не надо ничего, кроме адреса почты. Есть бесплатный тарифный план с комфортными ограничениями: 50 GB логов в месяц, 10k метрик.
Это отличный способ оценить все возможности системы. Например, хотите посмотреть, как работает мониторинг Linux хоста. Идёте в раздел Connections, добавляете новое соединение типа Linux Server. Открывается готовая инструкция по добавлению хоста:
1️⃣ Устанавливаете Grafana Agent: выбираете тип системы и архитектуру, создаёте API токен, копируете команду для установки агента с интегрированным токеном, запускаете её на хосте. Дожидаетесь установки, проверяете соединение.
2️⃣ Настраиваете интеграцию с облаком — добавляете в конфигурацию агента информацию по сбору метрик и логов. Всё, что необходимо добавить, копируете в готовом виде. Перезапускаете агента на хосте.
3️⃣ Устанавливаете необходимые дашборды. Достаточно жмакнуть на кнопку Install. Всё само установится.
4️⃣ Идёте в раздел Dashboards и смотрите необходимые панели, выбирая в выпадающем списке добавленный хост.
5️⃣ Для просмотра логов (он автоматом все подтягивает из journald и /var/log) идёте в раздел Explore, выбираете в выпадающем списке источник данных с окончанием -log и смотрите логи. Можно как текстовые логи из файлов смотреть, так и systemd с разбивкой на сервисы, уровни важности и т.д.
Таким образом в полуавтоматическом режиме можно добавить все поддерживаемые системы и сервисы: Docker, Nginx, MySQL, Redis, Ceph и т.д. Список огромный.
Grafana - это давно уже не только графики и дашборды, но и полноценная система мониторинга и сбора логов. И всё это в одном месте. Выглядит очень круто и удобно. Если честно, мне всё труднее и труднее объяснить кому-нибудь зачем ему Zabbix. Глядя на Графану, понимаешь, каким простым, красивым и удобным может быть мониторинг. Zabbix удерживает только безграничными возможностями привычного велосипедостроения. Если мониторить что-то типовое, то он давно уже не лучший вариант.
#мониторинг #grafana
Это отличный способ оценить все возможности системы. Например, хотите посмотреть, как работает мониторинг Linux хоста. Идёте в раздел Connections, добавляете новое соединение типа Linux Server. Открывается готовая инструкция по добавлению хоста:
1️⃣ Устанавливаете Grafana Agent: выбираете тип системы и архитектуру, создаёте API токен, копируете команду для установки агента с интегрированным токеном, запускаете её на хосте. Дожидаетесь установки, проверяете соединение.
2️⃣ Настраиваете интеграцию с облаком — добавляете в конфигурацию агента информацию по сбору метрик и логов. Всё, что необходимо добавить, копируете в готовом виде. Перезапускаете агента на хосте.
3️⃣ Устанавливаете необходимые дашборды. Достаточно жмакнуть на кнопку Install. Всё само установится.
4️⃣ Идёте в раздел Dashboards и смотрите необходимые панели, выбирая в выпадающем списке добавленный хост.
5️⃣ Для просмотра логов (он автоматом все подтягивает из journald и /var/log) идёте в раздел Explore, выбираете в выпадающем списке источник данных с окончанием -log и смотрите логи. Можно как текстовые логи из файлов смотреть, так и systemd с разбивкой на сервисы, уровни важности и т.д.
Таким образом в полуавтоматическом режиме можно добавить все поддерживаемые системы и сервисы: Docker, Nginx, MySQL, Redis, Ceph и т.д. Список огромный.
Grafana - это давно уже не только графики и дашборды, но и полноценная система мониторинга и сбора логов. И всё это в одном месте. Выглядит очень круто и удобно. Если честно, мне всё труднее и труднее объяснить кому-нибудь зачем ему Zabbix. Глядя на Графану, понимаешь, каким простым, красивым и удобным может быть мониторинг. Zabbix удерживает только безграничными возможностями привычного велосипедостроения. Если мониторить что-то типовое, то он давно уже не лучший вариант.
#мониторинг #grafana
{kind=link}
Я вчера рассказал, как собрать Nginx с модулем статистики vts. Расскажу теперь, как его настроить и собрать метрики в систему мониторинга Prometheus.
Для настройки статистики вам достаточно добавить в основной файл конфигурации
И в любой виртуальных хост ещё один location. Я обычно в default добавляю:
Теперь можно сходить по ip адресу сервера и посмотреть статистику прямо в браузере - http://10.20.1.56/status/. Сразу покажу ещё два важных и полезных урла: /status/format/json и /status/format/prometheus. По ним вы заберёте метрики в формате json или prometheus. Последняя ссылка нам будет нужна далее. Я покажу настройку мониторинга Nginx на примере Prometheus, так как это самый быстрый вариант. Имея все метрики в json формате, нетрудно и в Zabbix всё это закинуть через предобработку с помощью jsonpath, но времени побольше уйдёт.
Устанавливаем Prometheus. Нам нужен будет любой хост с Docker. Готовим конфиг, куда сразу добавим сервер с Nginx:
Это по сути стандартный конфиг, куда я добавил ещё один target nginx_vts. Запускаем Prometheus:
Идём на ip адрес хоста и порт 9090, где запущен Prometheus. Убеждаемся, что он работает, а в разделе Status -> Targets наш Endpoint nginx_vts доступен. Можете взять метрики со страницы /status/format/prometheus и подёргать их в Prometheus. Разбирать работу с ним не буду, так как это отдельная история.
Теперь ставим Grafana, можно на этот же хост с Prometheus:
Идём на ip адрес и порт 3000, видим интерфейс Графаны. Учётка по умолчанию admin / admin. Идём в раздел Administration -> Data sources и добавляем новый типа Prometheus. Из необходимых настроек достаточно указать только URL прома. В моём случае http://172.27.60.187:9090.
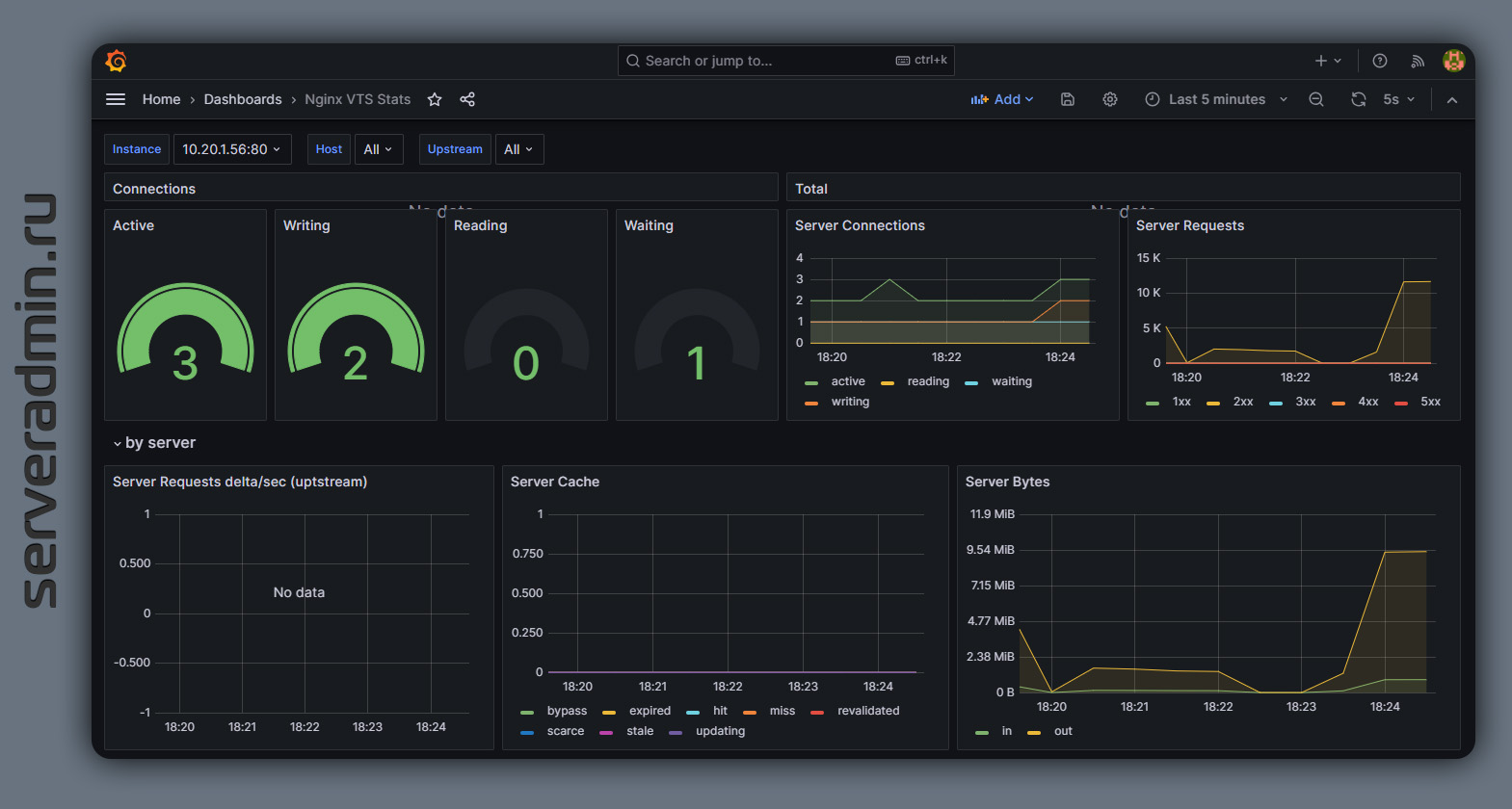
Теперь нам надо добавить готовый Dashboard для Nginx VTS. Их представлено штук 10 на сайте Grafana, но реально актуальный и работающий без доработки только один - https://grafana.com/grafana/dashboards/14824-nginx-vts-stats/. Соответственно, в разделе Dashboards Графаны нажимаем Import и указываем URL приведённого выше дашборда. Все основные метрики вы увидите на нём. Если надо добавить что-то ещё, то идёте на /status/format/prometheus, смотрите метрику и добавляете запрос с ней в Grafana.
Если с Prometheus не работали ранее, то подобное описание возможно не очень подробное, но в рамках заметки тему не раскрыть. Зато когда разберётесь и научитесь, настройка такого мониторинга будет занимать минут 10. Даже если в готовом дашборде что-то не будет работать, нетрудно подредактировать. Как Grafana, так и VTS модуль активно развиваются, поэтому старые дашборды в основном нерабочие. Но тут метрик не так много, так что не критично. Можно либо поправить, либо самому всё сделать.
На картинке всё не уместилось. Ниже ещё статистика по бэкендам будет. Примеры можно посмотреть в описании дашборда на сайте Grafana.
#nginx #мониторинг #prometheus #grafana
Для настройки статистики вам достаточно добавить в основной файл конфигурации
nginx.conf в секцию http:vhost_traffic_status_zone;И в любой виртуальных хост ещё один location. Я обычно в default добавляю:
server { listen 80; server_name localhost;.........................location /status { vhost_traffic_status_display; vhost_traffic_status_display_format html;}..................Теперь можно сходить по ip адресу сервера и посмотреть статистику прямо в браузере - http://10.20.1.56/status/. Сразу покажу ещё два важных и полезных урла: /status/format/json и /status/format/prometheus. По ним вы заберёте метрики в формате json или prometheus. Последняя ссылка нам будет нужна далее. Я покажу настройку мониторинга Nginx на примере Prometheus, так как это самый быстрый вариант. Имея все метрики в json формате, нетрудно и в Zabbix всё это закинуть через предобработку с помощью jsonpath, но времени побольше уйдёт.
Устанавливаем Prometheus. Нам нужен будет любой хост с Docker. Готовим конфиг, куда сразу добавим сервер с Nginx:
# mkdir prom_data && cd prom_data && touch prometheus.yamlglobal: scrape_interval: 5s evaluation_interval: 5srule_files:scrape_configs: - job_name: prometheus static_configs: - targets: ['localhost:9090'] - job_name: nginx_vts metrics_path: '/status/format/prometheus' static_configs: - targets: ['10.20.1.56:80']Это по сути стандартный конфиг, куда я добавил ещё один target nginx_vts. Запускаем Prometheus:
# docker run -p 9090:9090 -d --name=prom \-v ~/prom_data/prometheus.yaml:/etc/prometheus/prometheus.yml \ prom/prometheusИдём на ip адрес хоста и порт 9090, где запущен Prometheus. Убеждаемся, что он работает, а в разделе Status -> Targets наш Endpoint nginx_vts доступен. Можете взять метрики со страницы /status/format/prometheus и подёргать их в Prometheus. Разбирать работу с ним не буду, так как это отдельная история.
Теперь ставим Grafana, можно на этот же хост с Prometheus:
# docker run -p 3000:3000 -d --name=grafana grafana/grafanaИдём на ip адрес и порт 3000, видим интерфейс Графаны. Учётка по умолчанию admin / admin. Идём в раздел Administration -> Data sources и добавляем новый типа Prometheus. Из необходимых настроек достаточно указать только URL прома. В моём случае http://172.27.60.187:9090.
Теперь нам надо добавить готовый Dashboard для Nginx VTS. Их представлено штук 10 на сайте Grafana, но реально актуальный и работающий без доработки только один - https://grafana.com/grafana/dashboards/14824-nginx-vts-stats/. Соответственно, в разделе Dashboards Графаны нажимаем Import и указываем URL приведённого выше дашборда. Все основные метрики вы увидите на нём. Если надо добавить что-то ещё, то идёте на /status/format/prometheus, смотрите метрику и добавляете запрос с ней в Grafana.
Если с Prometheus не работали ранее, то подобное описание возможно не очень подробное, но в рамках заметки тему не раскрыть. Зато когда разберётесь и научитесь, настройка такого мониторинга будет занимать минут 10. Даже если в готовом дашборде что-то не будет работать, нетрудно подредактировать. Как Grafana, так и VTS модуль активно развиваются, поэтому старые дашборды в основном нерабочие. Но тут метрик не так много, так что не критично. Можно либо поправить, либо самому всё сделать.
На картинке всё не уместилось. Ниже ещё статистика по бэкендам будет. Примеры можно посмотреть в описании дашборда на сайте Grafana.
#nginx #мониторинг #prometheus #grafana
{kind=link}
Много раз в заметках упоминал про сервис по рисованию различных схем draw.io. Судя по отзывам, большая часть использует именно его в своей работе. Схемы из draw.io относительно легко можно наложить на мониторинг на базе Grafana. Если вы с ней работаете, то особых проблем не должно возникнуть. Если нет, то не скажу, что настройка будет простой. Но в целом, ничего особенного. Мне когда надо было, освоил Grafana за пару дней для простого мониторинга.
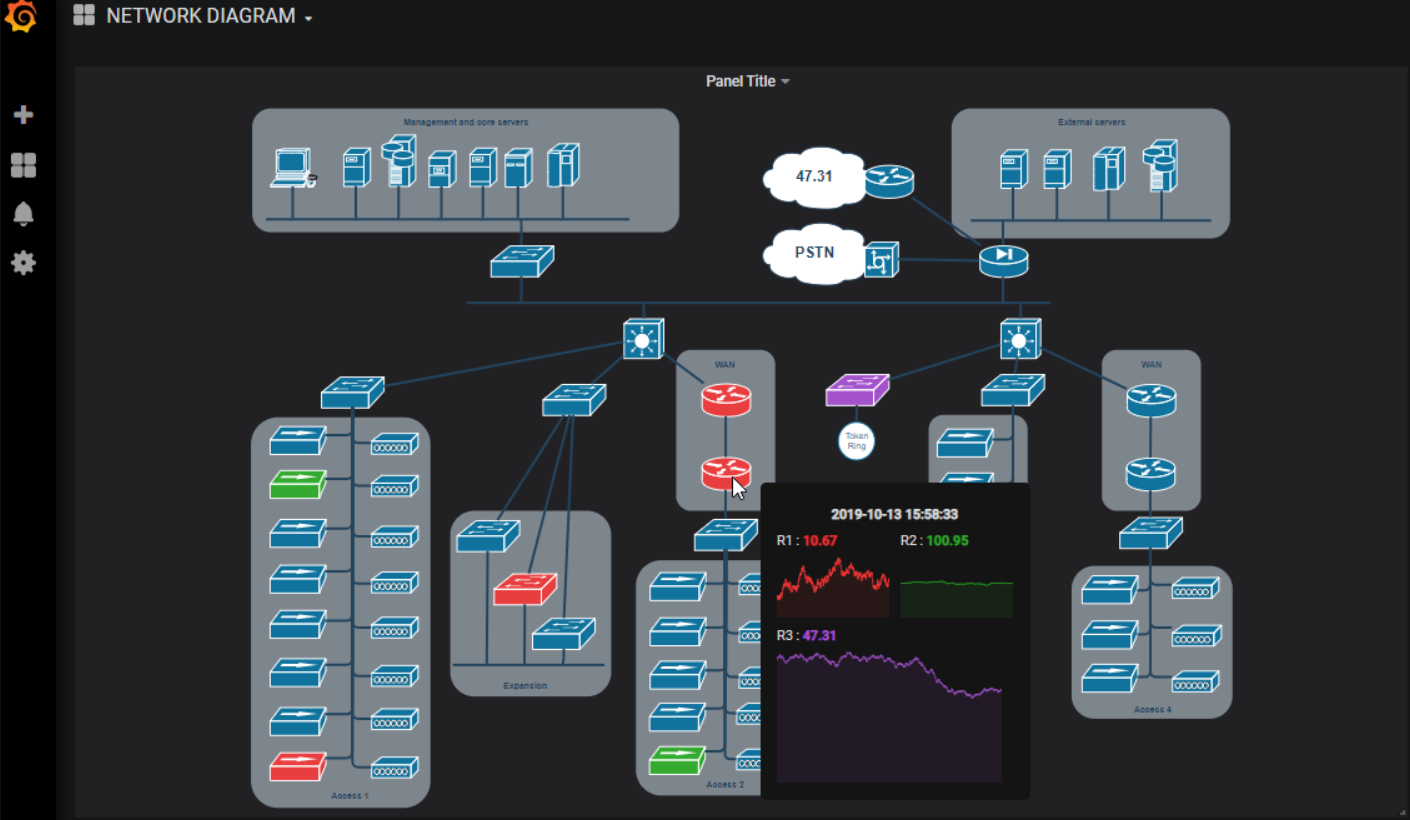
Речь пойдёт про плагин к Графане — flowcharting. Он есть в официальном списке плагинов на сайте, так что с его установкой вопросов не должно возникнуть. Сразу скажу, что с помощью этого плагина можно нарисовать схему и связать через через Графану его с мониторингом на Zabbix.
Последовательность настройки схемы с помощью плагина следующая:
1️⃣ Вы берёте схему в draw.io и выгружаете её в xml формате.
2️⃣ Создаёте dashboard в Grafana и добавляете туда панель flowcharting.
3️⃣ Загружаете xml код схемы в эту панель и получаете визуализацию.
4️⃣ Сопоставляете объекты на схеме с объектами в Графане, сразу переименовывая их так, чтобы было удобно.
5️⃣ Дальше к объектам можно добавлять метрики, как это обычно делается в Grafana. Соответственно, в качестве Data Source можно использовать тот же Zabbix.
Сразу приведу ссылки, которые помогут вам быстро начать действовать, если плагин заинтересовал.
⇨ Страница плагина в Grafana
⇨ Инструкция по настройке
▶️ Плейлист Flowcharting Grafana (29 видео)
Все видео в плейлисте на португальском языке. Можно включить перевод субтитров на русский. В целом, там важно смотреть, как и что он делает. А что говорит, не так важно. В плейлисте полностью раскрыта тема построения мониторинга с помощью этого плагина. В том числе и в связке с Zabbix (26-й ролик).
Плагин давно не обновлялся. Я не уверен, что он нормально заработает на свежих версиях, хотя, по идее должен. Я до сих пор пользуюсь 7-й версией. И там он работает.
#мониторинг #zabbix #grafana
Речь пойдёт про плагин к Графане — flowcharting. Он есть в официальном списке плагинов на сайте, так что с его установкой вопросов не должно возникнуть. Сразу скажу, что с помощью этого плагина можно нарисовать схему и связать через через Графану его с мониторингом на Zabbix.
Последовательность настройки схемы с помощью плагина следующая:
1️⃣ Вы берёте схему в draw.io и выгружаете её в xml формате.
2️⃣ Создаёте dashboard в Grafana и добавляете туда панель flowcharting.
3️⃣ Загружаете xml код схемы в эту панель и получаете визуализацию.
4️⃣ Сопоставляете объекты на схеме с объектами в Графане, сразу переименовывая их так, чтобы было удобно.
5️⃣ Дальше к объектам можно добавлять метрики, как это обычно делается в Grafana. Соответственно, в качестве Data Source можно использовать тот же Zabbix.
Сразу приведу ссылки, которые помогут вам быстро начать действовать, если плагин заинтересовал.
⇨ Страница плагина в Grafana
⇨ Инструкция по настройке
▶️ Плейлист Flowcharting Grafana (29 видео)
Все видео в плейлисте на португальском языке. Можно включить перевод субтитров на русский. В целом, там важно смотреть, как и что он делает. А что говорит, не так важно. В плейлисте полностью раскрыта тема построения мониторинга с помощью этого плагина. В том числе и в связке с Zabbix (26-й ролик).
Плагин давно не обновлялся. Я не уверен, что он нормально заработает на свежих версиях, хотя, по идее должен. Я до сих пор пользуюсь 7-й версией. И там он работает.
#мониторинг #zabbix #grafana
{kind=link}
Провёл аудит своих систем мониторинга Zabbix в связке с Grafana. У меня работают версии LTS 5.0 и 6.0. Промежуточные обычно только для теста ставлю где-то в одном месте. Разбирался в первую очередь с базовым шаблоном для Linux серверов.
У Zabbix есть особенность, что обновление сервера не касается самих шаблонов, а они тоже регулярно обновляются. У этого есть как плюсы, так и минусы. Плюс в том, что всё стабильно и никаких непредвиденных обновлений не будет. Если вы вносили правки в шаблон, они останутся и всё будет работать как раньше с новым сервером. А минус в том, что эти обновления надо проводить вручную.
В процессе аудита понял, что у меня на серверах используются 3 разных версии шаблона. На каких-то серверах все 3 одновременно. У этого есть много причин. Например, у вас есть какая-то удалённая площадка, подключенная по VPN. Я для неё делаю копию стандартного шаблона и в триггерах прописываю зависимость от состояния VPN, чтобы мне не сыпался спам из уведомлений, когда отвалится связь с площадкой. Когда таких изменений много, поддержание актуальной версии шаблонов становится непростой задачей.
Для серверов 6-й версии взял за основу шаблон Linux by Zabbix agent, не забыв указать ветку репозитория 6.0. Методика обновления может быть разной. Безопаснее всего текущий установленный шаблон переименовать, добавив, к примеру, к названию приписку OLD. Потом импортировать новый и вручную накидывать его на хосты, заменяя старый шаблон. Это немного муторно, так как ручной труд.
Проще всего всё сделать автоматом. Отцепить старый шаблон от хостов с удалением всех метрик и соответственно истории к ним. Это обнуляет всю историю метрик по данному шаблону. И потом накатить сверху новый шаблон. Минимум ручной работы, так как нет конфликтов слияния, но потеря всей истории. Если вам не критично, делайте так. Можно не затирая историю применять новый шаблон, перезаписывая старый, но там иногда возникают проблемы, которые нужно опять же вручную разрешать.
У меня хостов не так уж и много, я вручную всё сделал, отключая старый шаблон и подключая новый.
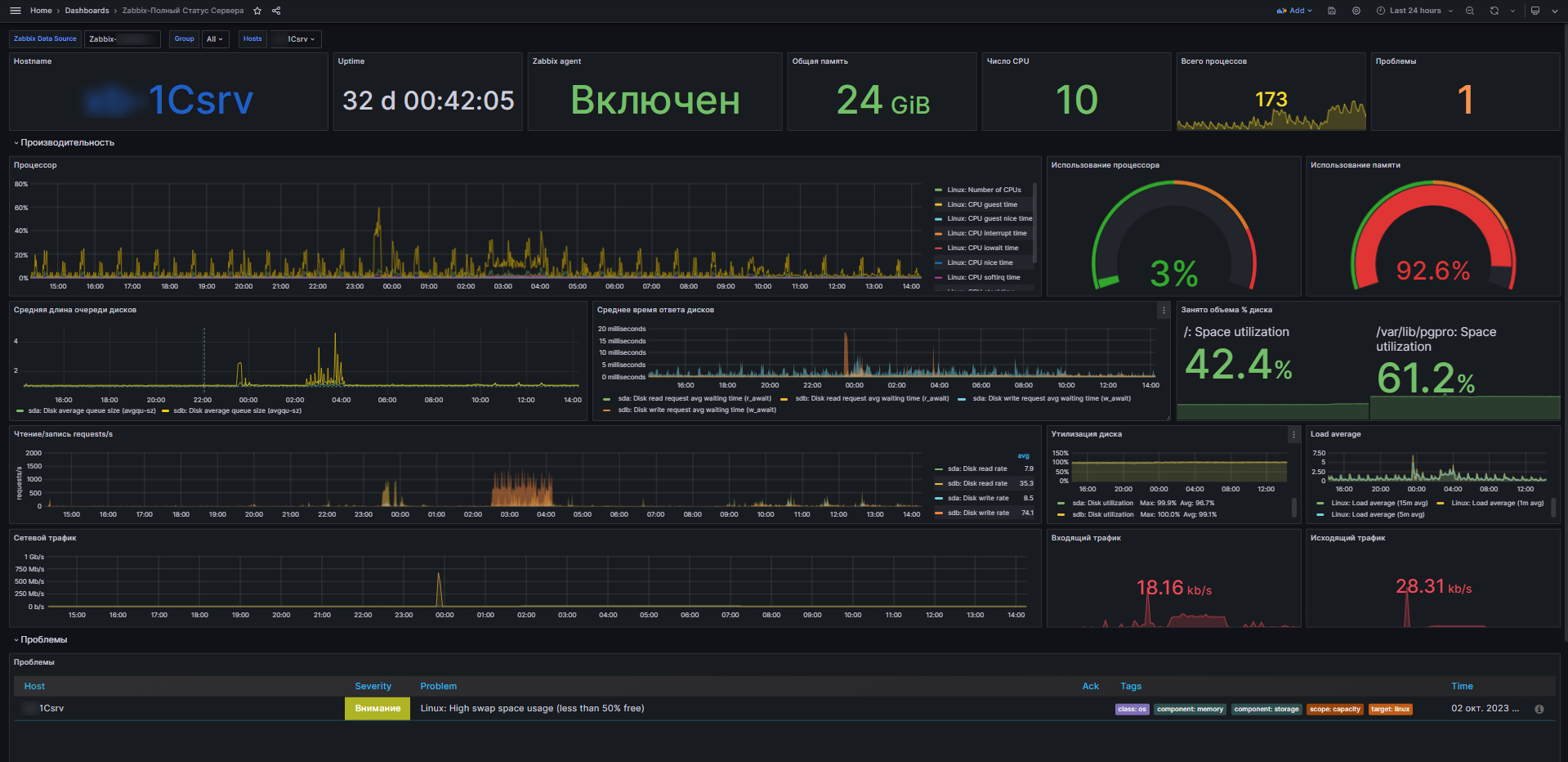
Единообразие шаблонов для Linux позволило сделать единый для всех серверов дашборд в Grafana, куда я вынес наиболее актуальные на мой взгляд метрики, чтобы можно было быстро оценить состояние хоста. Пример, как это выглядит, на картинке. Сам дашборд выложил на сайт, можно скачать. В шаблоне можно выбрать Datasource и конкретный хост. То есть с его помощью можно смотреть все подключенные хосты с такой же версией шаблона Linux. Это намного быстрее и удобнее, чем делать то же самое в самом Zabbix. По настройке Grafana с Zabbix у меня есть отдельная статья.
Ну и в завершении напомню, что обновление шаблонов приносит очень много мелких хлопот на местах, так как опять потребуется калибровка под конкретные хосты. Где-то не нужны какие-то триггеры, например на swap, на отсутствие свободной оперативы, где её и не должно быть, на скорость отклика дисков, потому что они медленные и т.д. Приходится макросы поправлять, триггеры отключать, какие-то изменения в шаблоны и хосты добавлять с зависимостями. Все tun интерфейсы почему-то определяются со скоростью 10 Мегабит в секунду, что приводит к срабатыванию триггеров на загрузку интерфейса. Пока не понял, как это решить, не отключая триггеры.
Из-за всех этих хлопот я всегда сильно откладываю обновление мониторингов, которые в целом и так работают и устраивают. Но всё равно бесконечно отставать от актуальной версии нельзя, приходится обновляться. Вечером будет заметка по обновлению Grafana.
#zabbix #grafana
У Zabbix есть особенность, что обновление сервера не касается самих шаблонов, а они тоже регулярно обновляются. У этого есть как плюсы, так и минусы. Плюс в том, что всё стабильно и никаких непредвиденных обновлений не будет. Если вы вносили правки в шаблон, они останутся и всё будет работать как раньше с новым сервером. А минус в том, что эти обновления надо проводить вручную.
В процессе аудита понял, что у меня на серверах используются 3 разных версии шаблона. На каких-то серверах все 3 одновременно. У этого есть много причин. Например, у вас есть какая-то удалённая площадка, подключенная по VPN. Я для неё делаю копию стандартного шаблона и в триггерах прописываю зависимость от состояния VPN, чтобы мне не сыпался спам из уведомлений, когда отвалится связь с площадкой. Когда таких изменений много, поддержание актуальной версии шаблонов становится непростой задачей.
Для серверов 6-й версии взял за основу шаблон Linux by Zabbix agent, не забыв указать ветку репозитория 6.0. Методика обновления может быть разной. Безопаснее всего текущий установленный шаблон переименовать, добавив, к примеру, к названию приписку OLD. Потом импортировать новый и вручную накидывать его на хосты, заменяя старый шаблон. Это немного муторно, так как ручной труд.
Проще всего всё сделать автоматом. Отцепить старый шаблон от хостов с удалением всех метрик и соответственно истории к ним. Это обнуляет всю историю метрик по данному шаблону. И потом накатить сверху новый шаблон. Минимум ручной работы, так как нет конфликтов слияния, но потеря всей истории. Если вам не критично, делайте так. Можно не затирая историю применять новый шаблон, перезаписывая старый, но там иногда возникают проблемы, которые нужно опять же вручную разрешать.
У меня хостов не так уж и много, я вручную всё сделал, отключая старый шаблон и подключая новый.
Единообразие шаблонов для Linux позволило сделать единый для всех серверов дашборд в Grafana, куда я вынес наиболее актуальные на мой взгляд метрики, чтобы можно было быстро оценить состояние хоста. Пример, как это выглядит, на картинке. Сам дашборд выложил на сайт, можно скачать. В шаблоне можно выбрать Datasource и конкретный хост. То есть с его помощью можно смотреть все подключенные хосты с такой же версией шаблона Linux. Это намного быстрее и удобнее, чем делать то же самое в самом Zabbix. По настройке Grafana с Zabbix у меня есть отдельная статья.
Ну и в завершении напомню, что обновление шаблонов приносит очень много мелких хлопот на местах, так как опять потребуется калибровка под конкретные хосты. Где-то не нужны какие-то триггеры, например на swap, на отсутствие свободной оперативы, где её и не должно быть, на скорость отклика дисков, потому что они медленные и т.д. Приходится макросы поправлять, триггеры отключать, какие-то изменения в шаблоны и хосты добавлять с зависимостями. Все tun интерфейсы почему-то определяются со скоростью 10 Мегабит в секунду, что приводит к срабатыванию триггеров на загрузку интерфейса. Пока не понял, как это решить, не отключая триггеры.
Из-за всех этих хлопот я всегда сильно откладываю обновление мониторингов, которые в целом и так работают и устраивают. Но всё равно бесконечно отставать от актуальной версии нельзя, приходится обновляться. Вечером будет заметка по обновлению Grafana.
#zabbix #grafana
{kind=link}
В процессе актуализации мониторинга обновил также и Grafana до последней 10-й версии. Расскажу, как это делаю я. Это не руководство к действию для вас, а только мой персональный опыт, основанный на том, что у меня немного дашбордов и Data sources.
Всю ценность в Grafana у меня представляют только настройки источников данных и несколько дашбордов, поэтому прорабатывать перенос данных или бэкап нет никакого смысла. Если что-то меняется, то я просто выгружаю json и сохраняю новую версию. А так как это происходит нечасто, меня такая схема устраивает.
Соответственно и обновление у меня выглядит максимально просто и быстро:
1️⃣ Выгружаю Data sources и Dashboards в json.
2️⃣ Обновляю Docker образ grafana:latest и запускаю новый контейнер с ним.
3️⃣ Переключаю на Nginx Proxy трафик на новый контейнер.
4️⃣ Захожу в него и импортирую свои данные.
Если что-то забыл, то заглядываю в старый контейнер, который остаётся некоторое время. Как это всё реализуется технически, описано в моей старой статье:
⇨ Обновление Grafana
В плане экспорта и импорта данных не поменялось ничего. Она полностью актуальна и по ней я переехал с 7-й версии на 10-ю. В конце статьи представлены примеры некоторых моих дашбордов. Они хоть и изменились с того времени, но это уже детали.
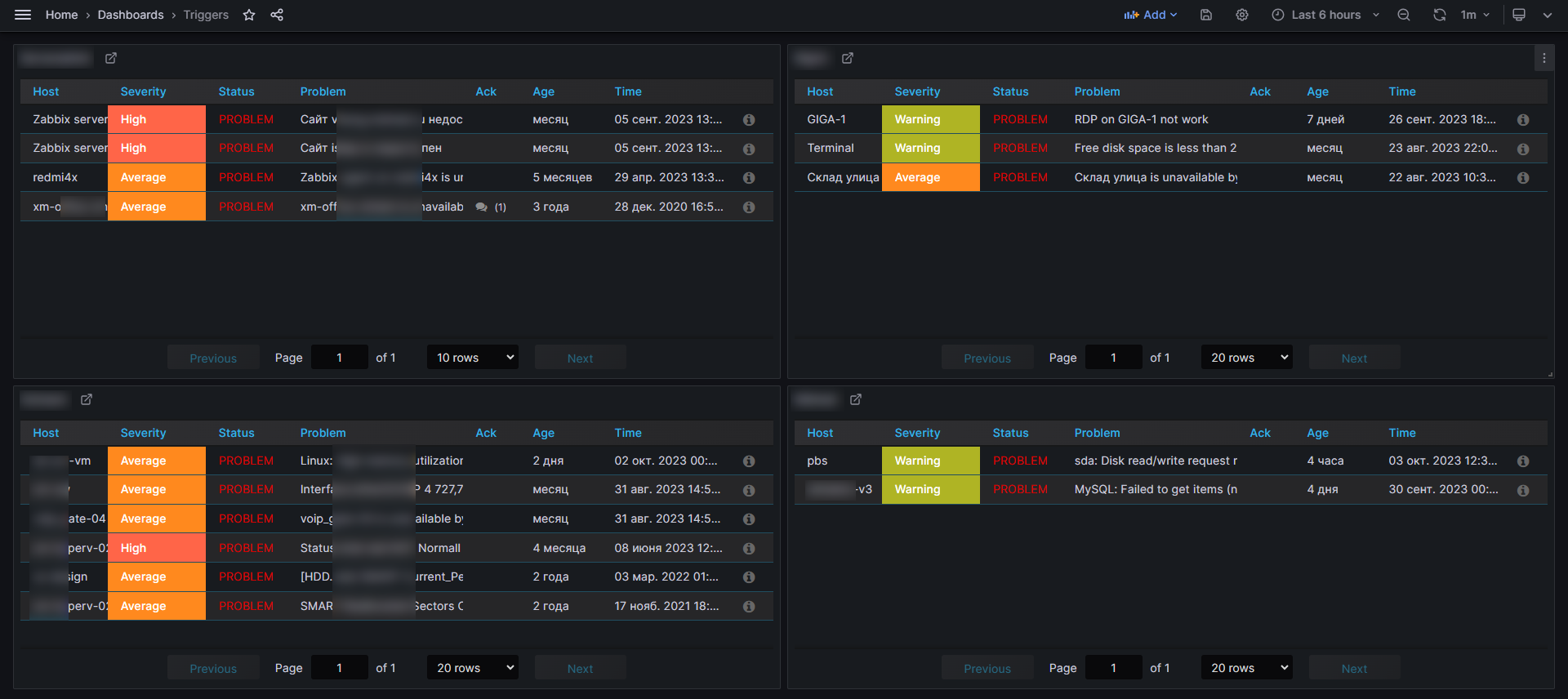
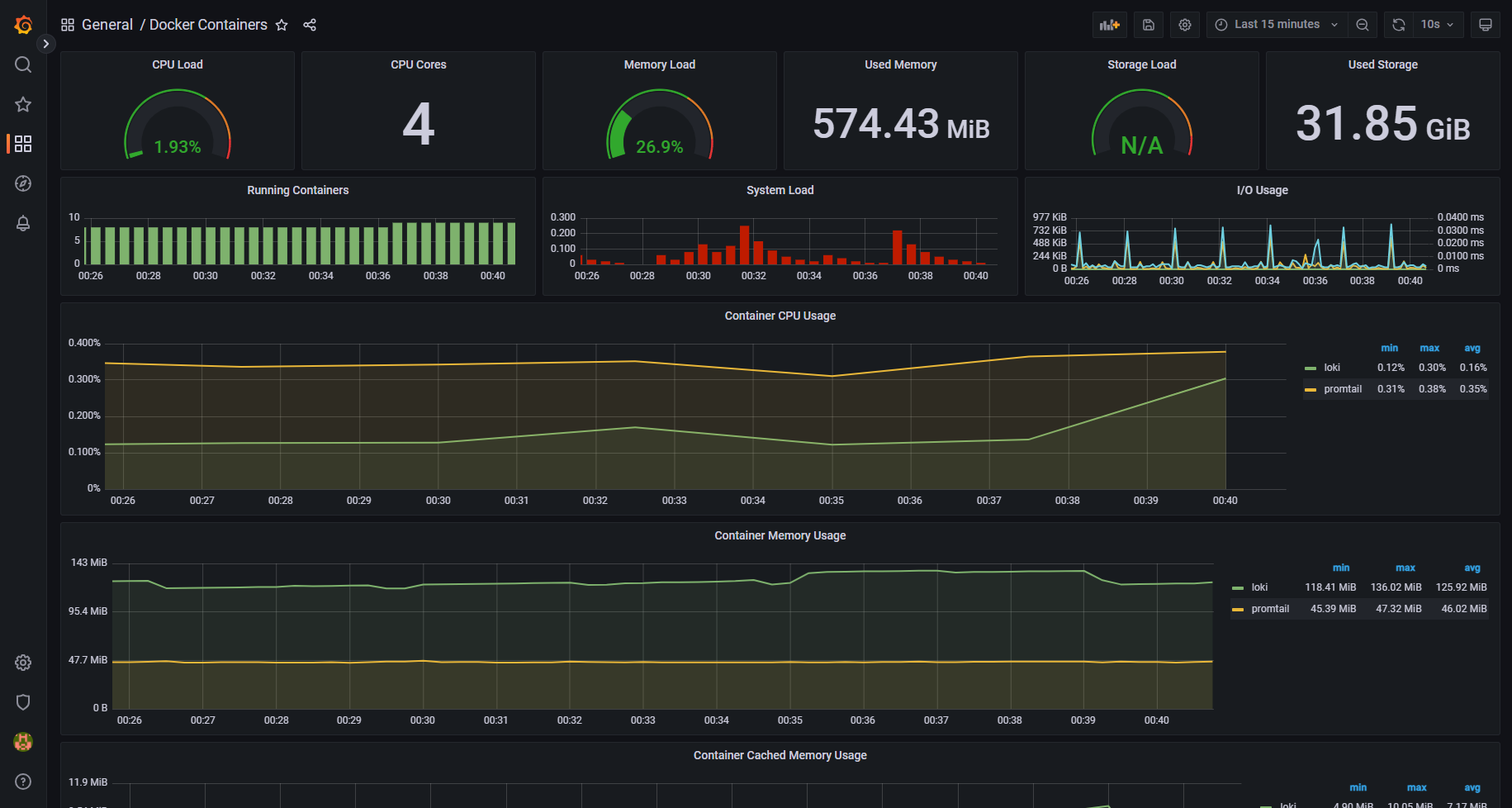
Предвещая вопросы, отвечу, что Grafana использую исключительно для более удобной и простой визуализации данных с Zabbix Server. А также для объединения на одном дашборде информации с разных серверов. Это актуально для триггеров. У меня есть обзорный дашборд с активными триггерами со всех своих серверов. Ну и дополнительно есть несколько дашбордов с другой необходимой мне информации. Один из таких дашбордов с обзорной информацией о сервере я показал в утренней заметке.
Ниже картинка с обзором триггеров.
#grafana #zabbix
Всю ценность в Grafana у меня представляют только настройки источников данных и несколько дашбордов, поэтому прорабатывать перенос данных или бэкап нет никакого смысла. Если что-то меняется, то я просто выгружаю json и сохраняю новую версию. А так как это происходит нечасто, меня такая схема устраивает.
Соответственно и обновление у меня выглядит максимально просто и быстро:
1️⃣ Выгружаю Data sources и Dashboards в json.
2️⃣ Обновляю Docker образ grafana:latest и запускаю новый контейнер с ним.
3️⃣ Переключаю на Nginx Proxy трафик на новый контейнер.
4️⃣ Захожу в него и импортирую свои данные.
Если что-то забыл, то заглядываю в старый контейнер, который остаётся некоторое время. Как это всё реализуется технически, описано в моей старой статье:
⇨ Обновление Grafana
В плане экспорта и импорта данных не поменялось ничего. Она полностью актуальна и по ней я переехал с 7-й версии на 10-ю. В конце статьи представлены примеры некоторых моих дашбордов. Они хоть и изменились с того времени, но это уже детали.
Предвещая вопросы, отвечу, что Grafana использую исключительно для более удобной и простой визуализации данных с Zabbix Server. А также для объединения на одном дашборде информации с разных серверов. Это актуально для триггеров. У меня есть обзорный дашборд с активными триггерами со всех своих серверов. Ну и дополнительно есть несколько дашбордов с другой необходимой мне информации. Один из таких дашбордов с обзорной информацией о сервере я показал в утренней заметке.
Ниже картинка с обзором триггеров.
#grafana #zabbix
{kind=link}
Предлагаю вашему вниманию любопытный проект по мониторингу одиночного хоста с Docker - domolo. Сразу скажу, что это продукт уровня курсовой работы с каких-нибудь курсов по DevOps на тему мониторинга. Он представляет из себя преднастроенный набор контейнеров на современном стеке.
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
Идём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
# git clone https://github.com/ductnn/domolo.git# cd domolo# docker-compose up -dИдём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
{kind=link}
На днях разработчики Angie анонсировали свой готовый Dashboard для мониторинга веб сервера через Prometheus и Grafana. Решил сразу его попробовать. Забегая вперёд скажу, что всё это существенно упрощает настройку мониторинга, который и так уже был на хорошем уровне в Angie. Стало просто отлично.
Напомню, что у Angie есть встроенный prometheus exporter. Включаем его так. Добавляем куда-нибудь location. Я обычно на ip адрес его вешаю в default сервер и ограничиваю доступ:
И добавляем в секцию http:
Далее добавляем в prometheus:
Только убедитесь, что ваш веб сервер отдаёт метрики по http://1.2.3.4/p8s. Либо какой-то другой url используйте, который настроили.
Вот и всё. Теперь идём в свою Grafana и добавляем готовый дашборд. Вот он:
⇨ https://grafana.com/grafana/dashboards/20719-angie-dashboard
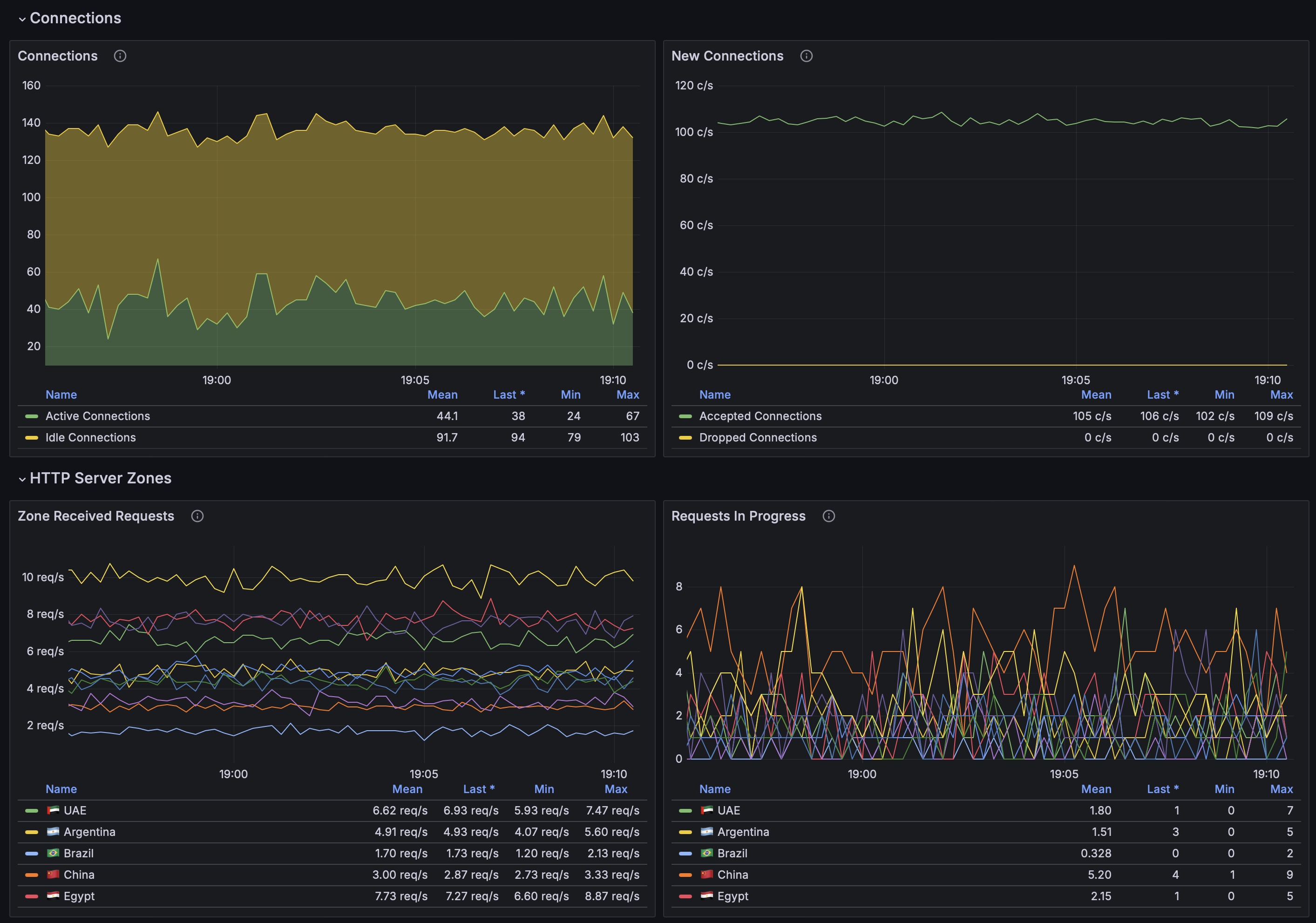
Дашборд полностью автоматизирован. Сам подхватывает все настройки из Angie. Покажу, как это работает. Допустим, вы хотите получать метрики по какому-то конкретному виртуальному хосту. Идём в него и добавляем в секцию server:
Перезапускаем Angie и переходим в Dashboard. В разделе HTTP Server Zones появится отдельная статистика по этому виртуальному хосту. То же самое можно сделать с отдельными location. Добавим отдельную зону в основной location и с php бэкендом:
или
Идём в раздел HTTP Location Zones и смотрим там статистику по указанным location.
Статистика по бэкендам, зонам с лимитами тоже подхватывается автоматически, если они у вас настроены, и сразу видна в дашборде.
Сделано всё очень удобно. Мониторинг веб сервера настраивается максимально быстро и при этом очень функционально.
Отдельно напомню, что у Angie вся эта же статистика видна в веб интерфейсе Console Light. И так же доступна через модуль API. Я через него сделал шаблон для Zabbix с основными метриками. Шаблон по ссылке стоит рассматривать только как пример создания. Он был сделан на скорую руку. Я его у себя немного доделал, но новую версию не выкладывал. Уже не помню, какие там отличия. С выходом этого дашборда для графаны мне шаблоном для Zabbix заниматься не хочется. Довольно хлопотно всё это реализовывать в нём и не особо имеет смысл, раз уже всё сделано за нас. Графаной я и так постоянно пользуюсь в связке с Zabbix, и Prometheus тоже использую.
📌 Ссылки по теме:
⇨ Настройка панели Prometheus
⇨ Модуль API
⇨ Директива status_zone
⇨ Web Console Demo
Как по мне, возможностей бесплатного веб сервера Angie на текущий момент существенно больше, чем у бесплатного Nginx. И речь не только о мониторинге. Там есть много других удобств. Разница в функциональности тянет уже на отдельную заметку.
#angie #мониторинг #grafana
Напомню, что у Angie есть встроенный prometheus exporter. Включаем его так. Добавляем куда-нибудь location. Я обычно на ip адрес его вешаю в default сервер и ограничиваю доступ:
location =/p8s { prometheus all; allow 127.0.0.1; allow 1.2.3.4; allow 4.3.2.1; deny all; }И добавляем в секцию http:
include prometheus_all.conf;Далее добавляем в prometheus:
scrape_configs: - job_name: "angie" scrape_interval: 15s metrics_path: "/p8s" static_configs: - targets: ["1.2.3.4:80"]Только убедитесь, что ваш веб сервер отдаёт метрики по http://1.2.3.4/p8s. Либо какой-то другой url используйте, который настроили.
Вот и всё. Теперь идём в свою Grafana и добавляем готовый дашборд. Вот он:
⇨ https://grafana.com/grafana/dashboards/20719-angie-dashboard
Дашборд полностью автоматизирован. Сам подхватывает все настройки из Angie. Покажу, как это работает. Допустим, вы хотите получать метрики по какому-то конкретному виртуальному хосту. Идём в него и добавляем в секцию server:
server { server_name serveradmin.ru; status_zone serveradmin.ru; ................}Перезапускаем Angie и переходим в Dashboard. В разделе HTTP Server Zones появится отдельная статистика по этому виртуальному хосту. То же самое можно сделать с отдельными location. Добавим отдельную зону в основной location и с php бэкендом:
location / { status_zone main; ...............}или
location ~ \.php$ { status_zone php; ...................}Идём в раздел HTTP Location Zones и смотрим там статистику по указанным location.
Статистика по бэкендам, зонам с лимитами тоже подхватывается автоматически, если они у вас настроены, и сразу видна в дашборде.
Сделано всё очень удобно. Мониторинг веб сервера настраивается максимально быстро и при этом очень функционально.
Отдельно напомню, что у Angie вся эта же статистика видна в веб интерфейсе Console Light. И так же доступна через модуль API. Я через него сделал шаблон для Zabbix с основными метриками. Шаблон по ссылке стоит рассматривать только как пример создания. Он был сделан на скорую руку. Я его у себя немного доделал, но новую версию не выкладывал. Уже не помню, какие там отличия. С выходом этого дашборда для графаны мне шаблоном для Zabbix заниматься не хочется. Довольно хлопотно всё это реализовывать в нём и не особо имеет смысл, раз уже всё сделано за нас. Графаной я и так постоянно пользуюсь в связке с Zabbix, и Prometheus тоже использую.
📌 Ссылки по теме:
⇨ Настройка панели Prometheus
⇨ Модуль API
⇨ Директива status_zone
⇨ Web Console Demo
Как по мне, возможностей бесплатного веб сервера Angie на текущий момент существенно больше, чем у бесплатного Nginx. И речь не только о мониторинге. Там есть много других удобств. Разница в функциональности тянет уже на отдельную заметку.
#angie #мониторинг #grafana
{kind=link}