
Технический пост, который уже давно нужно было сделать, но всё руки не доходили. На канале много содержательных заметок по различным темам. Иногда сам через поиск ищу то, о чём писал. Ниже набор наиболее популярных тэгов по которым можно найти что-то полезное (и не очень).
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
Иногда возникает задача быстро удалить все таблицы в базе данных mysql, не удаляя саму базу данных. Доступ к базе через консоль. В общем случае удалить конкретную таблицу в базе db можно следующей командой:
Если таблиц немного, то можно поступить и так. Но если их много, то нужен какой-то другой способ. Можно изобрести или поискать какой-то готовый велосипед на bash. Я предлагаю вам свой 😁
Берём mysqldump и делаем дамп только структуры, добавляя информацию об удалении таблиц перед их созданием:
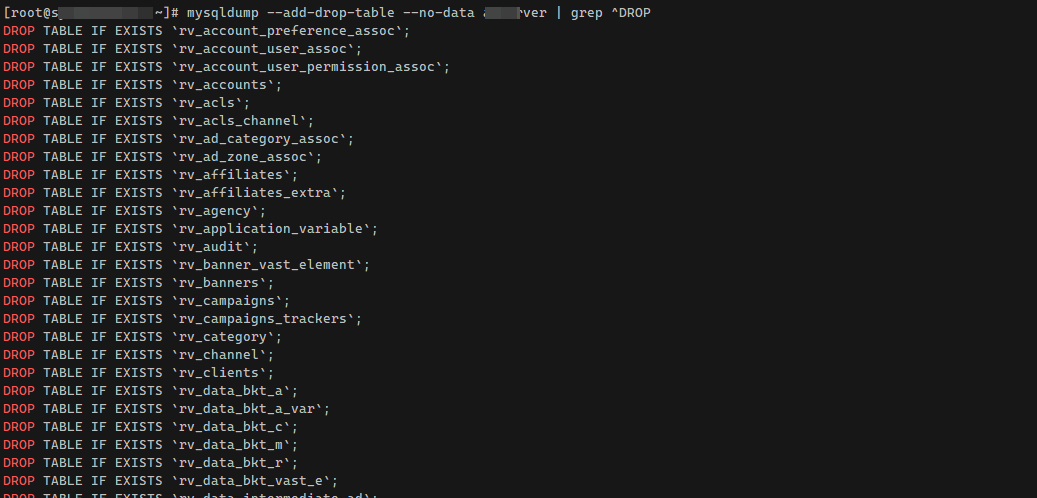
Теперь получить консольные команды на удаление всех таблиц базы данных проще простого. Грепаем получившийся дамп:
То есть выводим все строки, которые начинаются с DROP. Это как раз то, что нам нужно.
Далее можно либо взять только нужные строки с определёнными таблицами для удаления, либо сразу весь вывод отправить в консоль mysql и удалить все таблицы, оставив саму базу данных:
Не забудьте добавить авторизацию, если у вас она не настроена каким-то другим способом:
Таким простым способом, без скриптов, можно прямо в консоли сервера удалить все таблицы из базы данных mysql, не удаляя саму базу.
❓Может возникнуть вопрос, а почему не удалить всё же базу и не создать заново. Причин может быть несколько:
1️⃣ У вас нет прав на создание и удаление баз данных (наиболее частый случай).
2️⃣ Не помните точно параметры базы данных, не хочется вспоминать, искать, как создать новую базу данных с теми же параметрами, что стоят у текущей (мой случай).
Если у вас есть какое-то свое простое решение по удалению таблиц из базы, делитесь в комментариях.
#terminal #mysql
> use db;> drop table00 table01, table02;Если таблиц немного, то можно поступить и так. Но если их много, то нужен какой-то другой способ. Можно изобрести или поискать какой-то готовый велосипед на bash. Я предлагаю вам свой 😁
Берём mysqldump и делаем дамп только структуры, добавляя информацию об удалении таблиц перед их созданием:
# mysqldump --add-drop-table --no-data dbТеперь получить консольные команды на удаление всех таблиц базы данных проще простого. Грепаем получившийся дамп:
# mysqldump --add-drop-table --no-data db | grep ^DROPТо есть выводим все строки, которые начинаются с DROP. Это как раз то, что нам нужно.
Далее можно либо взять только нужные строки с определёнными таблицами для удаления, либо сразу весь вывод отправить в консоль mysql и удалить все таблицы, оставив саму базу данных:
# mysqldump --add-drop-table --no-data db | grep ^DROP | mysql dbНе забудьте добавить авторизацию, если у вас она не настроена каким-то другим способом:
# mysqldump -uuser -ppassword --add-drop-table --no-data db \| grep ^DROP | mysql -uuser -ppassword dbТаким простым способом, без скриптов, можно прямо в консоли сервера удалить все таблицы из базы данных mysql, не удаляя саму базу.
❓Может возникнуть вопрос, а почему не удалить всё же базу и не создать заново. Причин может быть несколько:
1️⃣ У вас нет прав на создание и удаление баз данных (наиболее частый случай).
2️⃣ Не помните точно параметры базы данных, не хочется вспоминать, искать, как создать новую базу данных с теми же параметрами, что стоят у текущей (мой случай).
Если у вас есть какое-то свое простое решение по удалению таблиц из базы, делитесь в комментариях.
#terminal #mysql
{kind=link}
Случилась на днях неприятная история, связанная с моей оплошностью. В связи с лихорадочным ценообразованием последних месяцев, приходится периодически делать какие-то переезды. Цены у хостеров стали сильно различаться, так что иногда приходится переезжать.
Один сайт после переезда со сменой ОС стал как-то подозрительно медленно работать в некоторых ситуациях. Пользовательский контент в основном закеширован, поэтому большое внимание проблеме не уделял. А вот в админке отдельные разделы с большими списками стали долго формироваться. Переехал на схожее по параметрам железо, поэтому не понимал, с чем связано такое проседание.
Предстоял разбор полётов, который я постоянно откладывал. Очень не люблю разбираться в производительности базы данных, потому что мало там понимаю. Это очень узкая ниша и без постоянной практики не так то просто ускорить запросы. Начал с просмотра базовой загрузки сервера. Там всё в порядке, никаких просадок нет, ресурсов более чем достаточно.
Потом заглянул в конфиги Mariadb и сначала не понял, а где вообще основная конфигурация. Всё пересмотрел и тут до меня дошло. Я забыл подтюнить СУБД под ресурсы сервера. В итоге MariaDB работала с дефолтными настройками. Если не ошибаюсь, там innodb_buffer_pool_size установлен в 128M. Это очень сильно влияет на производительность.
Скачал mysqltuner и выставил основные параметры в соответствии с объёмом оперативной памяти сервера. Этого оказалось достаточно, чтобы нормализовалась работа. Я этот тюнер использую как калькулятор. С его помощью удобно подобрать параметры innodb_buffer_pool_size и все сопутствующие настройки, а также буферы. И чтобы всё это не потребляло ресурсов больше, чем есть оперативной памяти под нужды СУБД. Если ошибиться, то можно словить OOM Killer, который будет прибивать базу данных.
Полезные ссылки по теме:
- Сравнение mysql vs mariadb
- На что обращать внимание при настройке Mysql
- Производительности Mysql сервера на файловой системе zfs
- индексы в Mysql
- Размещение субд в контейнерах
#mysql #website
Один сайт после переезда со сменой ОС стал как-то подозрительно медленно работать в некоторых ситуациях. Пользовательский контент в основном закеширован, поэтому большое внимание проблеме не уделял. А вот в админке отдельные разделы с большими списками стали долго формироваться. Переехал на схожее по параметрам железо, поэтому не понимал, с чем связано такое проседание.
Предстоял разбор полётов, который я постоянно откладывал. Очень не люблю разбираться в производительности базы данных, потому что мало там понимаю. Это очень узкая ниша и без постоянной практики не так то просто ускорить запросы. Начал с просмотра базовой загрузки сервера. Там всё в порядке, никаких просадок нет, ресурсов более чем достаточно.
Потом заглянул в конфиги Mariadb и сначала не понял, а где вообще основная конфигурация. Всё пересмотрел и тут до меня дошло. Я забыл подтюнить СУБД под ресурсы сервера. В итоге MariaDB работала с дефолтными настройками. Если не ошибаюсь, там innodb_buffer_pool_size установлен в 128M. Это очень сильно влияет на производительность.
Скачал mysqltuner и выставил основные параметры в соответствии с объёмом оперативной памяти сервера. Этого оказалось достаточно, чтобы нормализовалась работа. Я этот тюнер использую как калькулятор. С его помощью удобно подобрать параметры innodb_buffer_pool_size и все сопутствующие настройки, а также буферы. И чтобы всё это не потребляло ресурсов больше, чем есть оперативной памяти под нужды СУБД. Если ошибиться, то можно словить OOM Killer, который будет прибивать базу данных.
Полезные ссылки по теме:
- Сравнение mysql vs mariadb
- На что обращать внимание при настройке Mysql
- Производительности Mysql сервера на файловой системе zfs
- индексы в Mysql
- Размещение субд в контейнерах
#mysql #website
Хочу поделиться с вами очень приятной находкой в виде бесплатной программы для бэкапа SQL баз и обычных файлов - SQLBackupAndFTP. Программа работает под Windows и на самом деле платная, но есть функциональная бесплатная версия с некоторыми ограничениями.
SQLBackupAndFTP умеет:
◽ бэкапить вручную и по расписанию базы данных MSSQL, MySQL, PostgreSQL
◽ складывать бэкапы на FTP, SFTP, FTPS, локальную или сетевую папку, Yandex.Disk
◽ отправлять уведомления на почту
◽ писать лог выполняемых действий
◽ автоматически удалять старые бэкапы
◽ работать через прокси
◽ подключаться к sql серверу и выполнять там sql команды
Основное ограничение бесплатной версии - не более двух баз данных, добавленных в планировщик. Вручную запускать бэкапы можно для неограниченного количества баз. Ещё ограничения бесплатной версии: нет поддержки S3, только полные бэкапы, нет поддержки шифрования.
Я попробовал программу. Скачивается с сайта без всяких регистраций и других ужимок. Настройки очень простые и наглядные. Сама программа выглядит современно и удобно. Порадовала возможность снять бэкап mysql базы, подключившись к веб интерфейсу phpmyadmin. То есть не нужен прямой доступ к базе. Раньше нигде не видел такого функционала.
Программа оставила приятное впечатление. Если вам некритичны ограничения, то можно пользоваться. Уточню ещё раз, что вручную запускать бэкап можно неограниченного количества баз. Вы можете их добавить в интерфейс и запускать время от времени вручную по мере необходимости. Знаю людей, которые базы 1С вручную раз в неделю копируют на Яндекс.Диск. Эта программа может существенно упростить задачу, особенно людям, далёким от IT.
Сайт - https://sqlbackupandftp.com/
#backup #mysql #windows
SQLBackupAndFTP умеет:
◽ бэкапить вручную и по расписанию базы данных MSSQL, MySQL, PostgreSQL
◽ складывать бэкапы на FTP, SFTP, FTPS, локальную или сетевую папку, Yandex.Disk
◽ отправлять уведомления на почту
◽ писать лог выполняемых действий
◽ автоматически удалять старые бэкапы
◽ работать через прокси
◽ подключаться к sql серверу и выполнять там sql команды
Основное ограничение бесплатной версии - не более двух баз данных, добавленных в планировщик. Вручную запускать бэкапы можно для неограниченного количества баз. Ещё ограничения бесплатной версии: нет поддержки S3, только полные бэкапы, нет поддержки шифрования.
Я попробовал программу. Скачивается с сайта без всяких регистраций и других ужимок. Настройки очень простые и наглядные. Сама программа выглядит современно и удобно. Порадовала возможность снять бэкап mysql базы, подключившись к веб интерфейсу phpmyadmin. То есть не нужен прямой доступ к базе. Раньше нигде не видел такого функционала.
Программа оставила приятное впечатление. Если вам некритичны ограничения, то можно пользоваться. Уточню ещё раз, что вручную запускать бэкап можно неограниченного количества баз. Вы можете их добавить в интерфейс и запускать время от времени вручную по мере необходимости. Знаю людей, которые базы 1С вручную раз в неделю копируют на Яндекс.Диск. Эта программа может существенно упростить задачу, особенно людям, далёким от IT.
Сайт - https://sqlbackupandftp.com/
#backup #mysql #windows
{kind=link}
Решил упростить себе задачу и подготовить список настроек, которые надо обязательно проверить при настройке одиночного mysql/mariadb сервера. Я не буду давать описания настроек и советовать какие-то значения, потому что это очень большой объём информации. Вы сами сможете её найти в интернете и подогнать под свою ситуацию.
Первое, что надо сделать - сбалансировать потребление памяти сервером. Не обязательно делать это вручную. Можно воспользоваться скриптом mysqltuner. Перечислю параметры Global + Thread, из которых складывается потребление памяти:
Global:
Эти значения просто суммируются.
Thread:
Эти значения суммируются и умножаются на
Как я уже сказал, не обязательно их все править. Можно воспользоваться mysqltuner или оставить дефолтные значения, а вручную указать наиболее критичные - innodb_buffer_pool_size, max_connections. Остальные параметры mysqltuner подскажет, как подогнать под основные. Innodb_buffer_pool_size подбирают таким образом, чтобы с учётом всех остальных параметров суммарное потребление оперативной памяти не выходило за отведённые для Mysql Server пределы.
Обязательно проверяю:
Если не требуются подключения извне, привязываю к localhost.
Проверяю расположение логов и чаще всего сразу добавляю лог медленных запросов:
Указываю нужную кодировку. Сейчас вроде бы везде utf8mb4 по умолчанию стоит, раньше utf8 ставили.
Важные параметры, которые заметно влияют на производительность:
Они привязаны к количеству соединений и таблиц в базе. Для того же Bitrix эти параметры имеют высокие значения и часто упираются в системные лимиты ОС для отдельного процесса. Их нужно тоже увеличить. Например вот так:
Содержимое файла:
Ещё один параметр, на который стоит обратить внимание:
Он регулирует размер и рост файла с временным табличным пространством. Этот файл иногда может вырастать до огромных размеров и вызывать нехватку свободного места. Имеет смысл его сразу ограничить до разумных пределов. Вот пример ограничения размера в 2 ГБ и роста частями по 12 Мб
Это основное, на что я обращаю внимание. Более детальные настройки делаются, если возникают какие-то проблемы.
#mysql
Первое, что надо сделать - сбалансировать потребление памяти сервером. Не обязательно делать это вручную. Можно воспользоваться скриптом mysqltuner. Перечислю параметры Global + Thread, из которых складывается потребление памяти:
Global:
innodb_buffer_pool_sizeinnodb_log_file_sizekey_buffer_sizeinnodb_log_buffer_sizequery_cache_sizearia_pagecache_buffer_sizeЭти значения просто суммируются.
Thread:
sort_buffer_sizejoin_buffer_sizeread_buffer_sizeread_rnd_buffer_sizemax_allowed_packetthread_stackЭти значения суммируются и умножаются на
max_connections. Как я уже сказал, не обязательно их все править. Можно воспользоваться mysqltuner или оставить дефолтные значения, а вручную указать наиболее критичные - innodb_buffer_pool_size, max_connections. Остальные параметры mysqltuner подскажет, как подогнать под основные. Innodb_buffer_pool_size подбирают таким образом, чтобы с учётом всех остальных параметров суммарное потребление оперативной памяти не выходило за отведённые для Mysql Server пределы.
Обязательно проверяю:
bind-address = 127.0.0.1Если не требуются подключения извне, привязываю к localhost.
Проверяю расположение логов и чаще всего сразу добавляю лог медленных запросов:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Указываю нужную кодировку. Сейчас вроде бы везде utf8mb4 по умолчанию стоит, раньше utf8 ставили.
character-set-server = utf8mb4collation-server = utf8mb4_general_ciВажные параметры, которые заметно влияют на производительность:
open_files_limittable_open_cache Они привязаны к количеству соединений и таблиц в базе. Для того же Bitrix эти параметры имеют высокие значения и часто упираются в системные лимиты ОС для отдельного процесса. Их нужно тоже увеличить. Например вот так:
# mkdir /etc/systemd/system/mysqld.service.d# touch limit.confСодержимое файла:
[Service]LimitNOFILE=65535Ещё один параметр, на который стоит обратить внимание:
innodb_temp_data_file_pathОн регулирует размер и рост файла с временным табличным пространством. Этот файл иногда может вырастать до огромных размеров и вызывать нехватку свободного места. Имеет смысл его сразу ограничить до разумных пределов. Вот пример ограничения размера в 2 ГБ и роста частями по 12 Мб
innodb_temp_data_file_path = ibtmp1:12M:autoextend:max:2GЭто основное, на что я обращаю внимание. Более детальные настройки делаются, если возникают какие-то проблемы.
#mysql
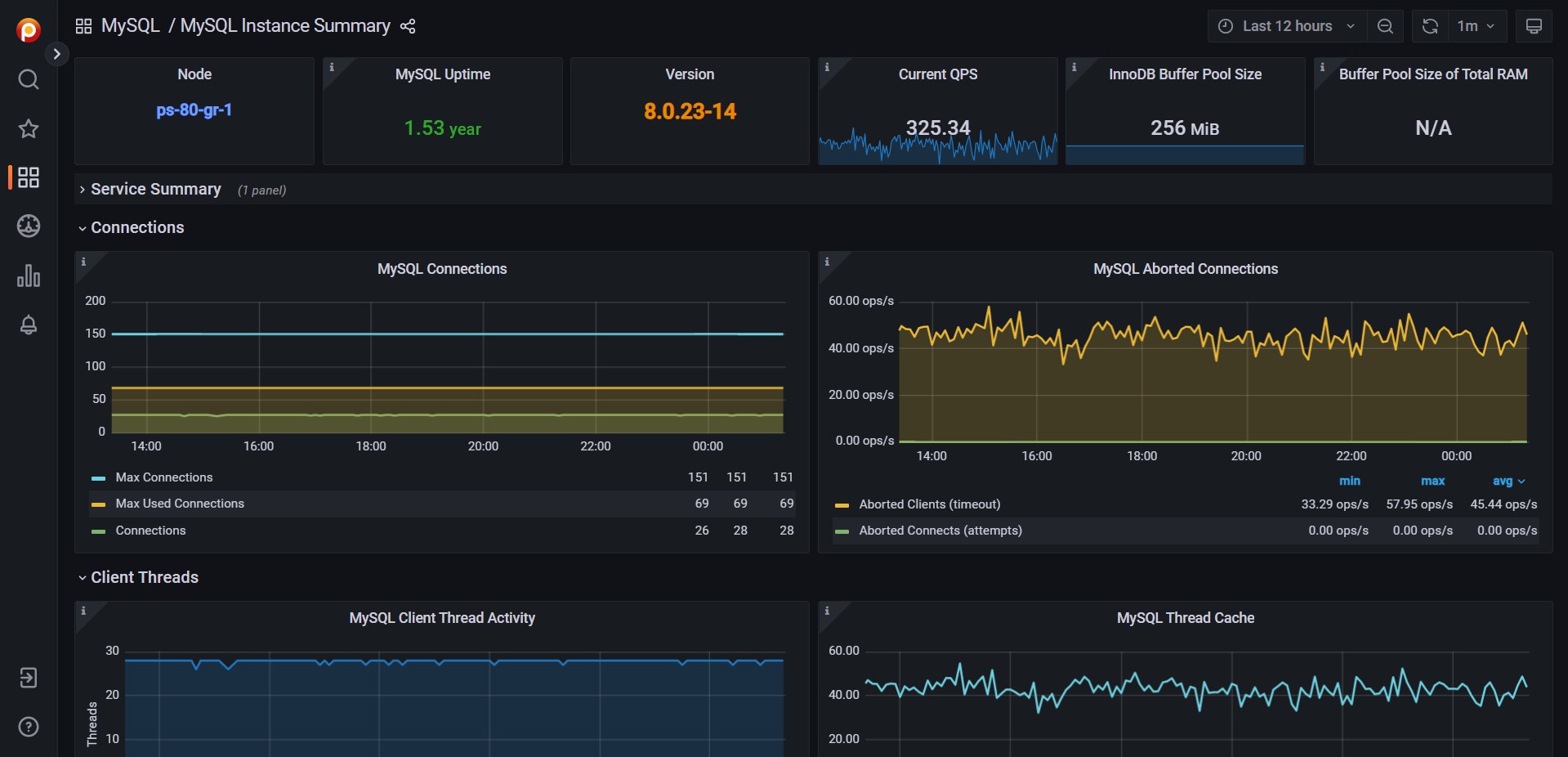
Существуют разные подходы к мониторингу. Можно настраивать одну универсальную систему и всё замыкать на неё. Это удобно в том плане, что всё в одном месте. Но мониторинг каждого отдельного элемента будет не самым лучшим.
Другой подход - для каждого продукта использовать тот мониторинг, который заточен именно под него. Например, такой мониторинг есть для Nginx - NGINX Amplify. Или мониторинг для баз данных от Percona - Percona Monitoring and Management (PMM). Про последний я и хочу сегодня рассказать.
Percona Monitoring and Management - open source мониторинг для баз данных MySQL, PostgreSQL и MongoDB. Построен на базе своего PMM Server и PMM Agent. Визуализация метрик реализована через Grafana.
Благодаря тому, что это узкоспециализированный продукт, его очень легко установить и настроить. По сути и настраивать то нечего. Достаточно установить сервер, агенты на хосты с БД и дальше смотреть метрики в готовых дашбордах Графаны.
Это не сравнится с тем, что предлагает Zabbix по мониторингу баз данных. Да, все те же метрики в него тоже можно передать. Но настроить всё это в готовую систему с метриками, триггерами, оповещениями, графиками и дашбордами очень хлопотно. А в PMM всё это работает сразу после установки. Времени нужно минимум, чтобы запустить мониторинг.
В принципе, если для вас важны базы данных, подобные мониторинги можно и отдельно разворачивать рядом с основным, а потом события со всех мониторингов собирать в одном месте. Например, с помощью OnCall.
Как я уже сказал, установить PMM очень просто. Можете сами оценить сложность и трудозатраты - Install Percona Monitoring and Management. Буквально 10 минут копипасты: ставим сервер, ставим клиент, соединяем клиента с сервером, добавляем в базу пользователя для сбора метрик. Если я правильно понял, то PMM построен на базе prometheus и использует метрики с его exporters.
Как всё это выглядит, можете посмотреть в публичном Demo. Там даже аутентификация не нужна. Помимо метрик баз данных PMM может собирать типовые метрики сервера Linux, HAProxy, выполнять внешние проверки tcp портов или забирать метрики по http.
Проект относительно свежий (2019 год) и очень активно развивается.
⇨ Сайт / Установка / Demo / Исходники
#мониторинг #mysql #postgresql
Другой подход - для каждого продукта использовать тот мониторинг, который заточен именно под него. Например, такой мониторинг есть для Nginx - NGINX Amplify. Или мониторинг для баз данных от Percona - Percona Monitoring and Management (PMM). Про последний я и хочу сегодня рассказать.
Percona Monitoring and Management - open source мониторинг для баз данных MySQL, PostgreSQL и MongoDB. Построен на базе своего PMM Server и PMM Agent. Визуализация метрик реализована через Grafana.
Благодаря тому, что это узкоспециализированный продукт, его очень легко установить и настроить. По сути и настраивать то нечего. Достаточно установить сервер, агенты на хосты с БД и дальше смотреть метрики в готовых дашбордах Графаны.
Это не сравнится с тем, что предлагает Zabbix по мониторингу баз данных. Да, все те же метрики в него тоже можно передать. Но настроить всё это в готовую систему с метриками, триггерами, оповещениями, графиками и дашбордами очень хлопотно. А в PMM всё это работает сразу после установки. Времени нужно минимум, чтобы запустить мониторинг.
В принципе, если для вас важны базы данных, подобные мониторинги можно и отдельно разворачивать рядом с основным, а потом события со всех мониторингов собирать в одном месте. Например, с помощью OnCall.
Как я уже сказал, установить PMM очень просто. Можете сами оценить сложность и трудозатраты - Install Percona Monitoring and Management. Буквально 10 минут копипасты: ставим сервер, ставим клиент, соединяем клиента с сервером, добавляем в базу пользователя для сбора метрик. Если я правильно понял, то PMM построен на базе prometheus и использует метрики с его exporters.
Как всё это выглядит, можете посмотреть в публичном Demo. Там даже аутентификация не нужна. Помимо метрик баз данных PMM может собирать типовые метрики сервера Linux, HAProxy, выполнять внешние проверки tcp портов или забирать метрики по http.
Проект относительно свежий (2019 год) и очень активно развивается.
⇨ Сайт / Установка / Demo / Исходники
#мониторинг #mysql #postgresql
{kind=link}
Решил для себя проработать ещё один документ от CIS на тему MySQL сервера. Взял версию 5.7, как наиболее универсальный вариант. Честно сказать, документ вообще не впечатлил. Показался набором очевидных банальностей. Ничего для себя оттуда не вынес, но так как потратил довольно много времени на прочтение и разбор, решил всё же сделать небольшую подборку для вас о тех вещах, что мне показались сколько-нибудь полезными.
📌 Mysql сервер должен запускать от непривилегированного пользователя без shell доступа к серверу. Все файлы и директории, с которыми работает сервер, должны принадлежать этому пользователю без доступа посторонних. Это же касается и лог файлов, особенно с ошибками.
📌 Если есть возможность использовать аутентификацию пользователей через unix сокет, оставьте только её, а остальные виды отключите. Речь идёт про плагин auth_socket для mysql или unix_socket для mariadb. Удалённые подключения к mysql серверу для безопасности стоит настроить по tls с помощью сертификатов.
📌 Обязательно ограничьте запуск сервера конкретным IP адресом, на котором он должен быть доступен. Например так:
Если используется внешний IP адрес, необходимо ограничить к нему доступ на уровне firewall.
📌 Если не используете символьные ссылки в файлах, с которыми работает сервер, то отключите их поддержку в my.cnf:
📌 Настройте ведение лога ошибок:
📌 При работе с mysql сервером через консольный клиент следует избегать ситуаций, когда пароль пользователя используется непосредственно в команде и остаётся в системной истории команд. Я, кстати, и сам так попадал, и на других серверах видел пароли mysql пользователей в истории bash. Стоит избегать вот таких конструкций:
Либо интерактивно вводите пароль, либо храните в отдельном файле .my.cnf с ограничением доступа.
Далее обобщил целый набор банальностей, которые разделены на множество подразделов и подробно описаны на десятках страниц. В общем и целом там вот что.
💡Необходимо устанавливать все обновления, удалить все тестовые данные, если они есть. Проверить всех пользователей и их права. Особенно обратить внимание на права SUPER, PROCESS, CREATE USER, GRANT OPTION. Они должны быть только у административных пользователей.
💡Необходимо следить за бэкапами, за учётными записями, от имени которых они выполняются. Не забывать про binlog, если вам нужна возможность восстановления между полными бэкапами.
💡Необходимо создать план восстановления данных в случае проблем, план проверки и восстановления из бэкапов. Необходимо не забыть добавить к бэкапу файлы конфигураций, tls сертификаты, если используются, логи аудита и т.д. Всё, что нужно для полноценной работы сервиса.
💡По возможности сервер должен быть изолирован от остальных служб на отдельной VPS или сервере.
#cis #mysql
📌 Mysql сервер должен запускать от непривилегированного пользователя без shell доступа к серверу. Все файлы и директории, с которыми работает сервер, должны принадлежать этому пользователю без доступа посторонних. Это же касается и лог файлов, особенно с ошибками.
📌 Если есть возможность использовать аутентификацию пользователей через unix сокет, оставьте только её, а остальные виды отключите. Речь идёт про плагин auth_socket для mysql или unix_socket для mariadb. Удалённые подключения к mysql серверу для безопасности стоит настроить по tls с помощью сертификатов.
📌 Обязательно ограничьте запуск сервера конкретным IP адресом, на котором он должен быть доступен. Например так:
bind_address=192.168.11.3Если используется внешний IP адрес, необходимо ограничить к нему доступ на уровне firewall.
📌 Если не используете символьные ссылки в файлах, с которыми работает сервер, то отключите их поддержку в my.cnf:
skip-symbolic-links = YES📌 Настройте ведение лога ошибок:
log-error = /var/log/mysql/error.log📌 При работе с mysql сервером через консольный клиент следует избегать ситуаций, когда пароль пользователя используется непосредственно в команде и остаётся в системной истории команд. Я, кстати, и сам так попадал, и на других серверах видел пароли mysql пользователей в истории bash. Стоит избегать вот таких конструкций:
# mysql -u admin -p passwordЛибо интерактивно вводите пароль, либо храните в отдельном файле .my.cnf с ограничением доступа.
Далее обобщил целый набор банальностей, которые разделены на множество подразделов и подробно описаны на десятках страниц. В общем и целом там вот что.
💡Необходимо устанавливать все обновления, удалить все тестовые данные, если они есть. Проверить всех пользователей и их права. Особенно обратить внимание на права SUPER, PROCESS, CREATE USER, GRANT OPTION. Они должны быть только у административных пользователей.
💡Необходимо следить за бэкапами, за учётными записями, от имени которых они выполняются. Не забывать про binlog, если вам нужна возможность восстановления между полными бэкапами.
💡Необходимо создать план восстановления данных в случае проблем, план проверки и восстановления из бэкапов. Необходимо не забыть добавить к бэкапу файлы конфигураций, tls сертификаты, если используются, логи аудита и т.д. Всё, что нужно для полноценной работы сервиса.
💡По возможности сервер должен быть изолирован от остальных служб на отдельной VPS или сервере.
#cis #mysql
{kind=link}
Если вам нужно точно знать, кто и что делает в базе данных MySQL, то настроить это относительно просто. В MySQL и её популярных форках существует встроенный модуль Audit Plugin, с помощью которого можно все действия с сервером баз данных записывать в лог-файл.
Я покажу на примере системы Debian и СУБД MariaDB, как настроить аудит всех действий с сервером. Это будет полная инструкция, по которой копированием команд можно всё настроить.
Ставим сервер и выполняем начальную настройку:
Заходим в консоль Mysql:
Устанавливаем плагин:
В Debian этот плагин присутствует по умолчанию. Проверить можно в директории /usr/lib/mysql/plugin наличие файла server_audit.so.
Смотрим информацию о плагине и его настройки:
По умолчанию аудит в СУБД отключён. За это отвечает параметр server_audit_logging. Активируем его:
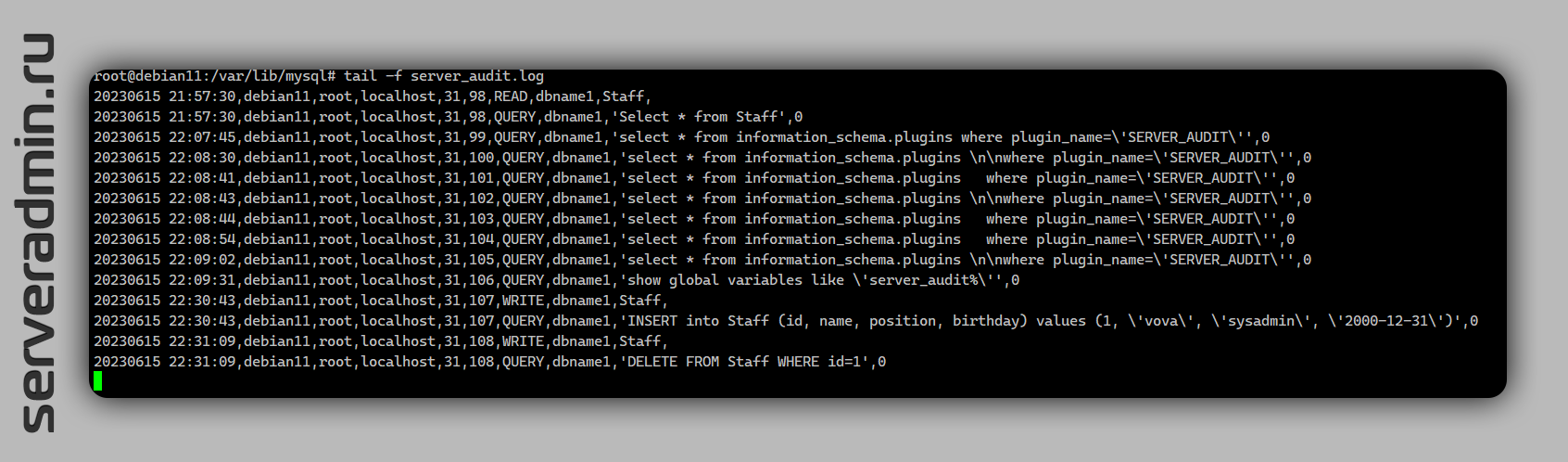
Теперь все действия на сервере СУБД будут записываться в лог файл, который по умолчанию будет создан в директории /var/lib/mysql в файле server_audit.log.
Записываться будут все действия для всех пользователей. Это можно изменить, задав явно параметр server_audit_events, который будет указывать, какие события записываем. Например так:
В этом параметре поддерживаются следующие значения: CONNECT, QUERY, TABLE, QUERY_DDL, QUERY_DML, QUERY_DCL, QUERY_DML_NO_SELECT.
Для пользователей можно настроить исключения. То есть указать, для какого пользователя мы не будем вести аудит. Список этих пользователей хранится в параметре server_audit_excl_users. Тут, в отличие от предыдущего параметра, мы указываем исключение. Управляется примерно так:
Все подробности по настройке плагина есть в официальной документации.
Дальше этот лог можно передать куда-то на хранение. Например в elasticsearch. Для него есть готовые grok фильтры для разбора лога аудита в Ingest ноде или Logstash. Вот пример подобного фильтра. После этого можно будет настроить какие-то оповещения в зависимости от ваших потребностей. Например, при превышении каким-то пользователем числа подключений или слишком больше количество каких-то операций в единицу времени.
Максимально просто и быстро мониторинг на события можно настроить и в Zabbix. К примеру, сделать отдельные айтемы для строк только с конкретными запросами, например UPDATE или DELETE, или записывать только коды выхода, отличные от 0. Далее для них настроить триггеры на превышение средних значений в интервал времени на какую-то величину. Если происходят всплески по этим строкам, получите уведомление. Но сразу предупрежу, что Zabbix не очень для этого подходит. Только если событий немного. Иначе лог аудита будет занимать очень много места в базе данных Zabbix. Это плохая практика.
Придумать тут можно много всего в зависимости от ваших потребностей. И всё это сделать относительно просто. Не нужны никакие дополнительные средства и программы.
#mysql #security
Я покажу на примере системы Debian и СУБД MariaDB, как настроить аудит всех действий с сервером. Это будет полная инструкция, по которой копированием команд можно всё настроить.
Ставим сервер и выполняем начальную настройку:
# apt install mariadb-server# mysql_secure_installationЗаходим в консоль Mysql:
# mysql -u root -pУстанавливаем плагин:
> install plugin server_audit soname 'server_audit.so';В Debian этот плагин присутствует по умолчанию. Проверить можно в директории /usr/lib/mysql/plugin наличие файла server_audit.so.
Смотрим информацию о плагине и его настройки:
> select * from information_schema.plugins where plugin_name='SERVER_AUDIT'\G> show global variables like 'server_audit%';По умолчанию аудит в СУБД отключён. За это отвечает параметр server_audit_logging. Активируем его:
> set global server_audit_logging=on;Теперь все действия на сервере СУБД будут записываться в лог файл, который по умолчанию будет создан в директории /var/lib/mysql в файле server_audit.log.
Записываться будут все действия для всех пользователей. Это можно изменить, задав явно параметр server_audit_events, который будет указывать, какие события записываем. Например так:
> set global server_audit_events='QUERY;В этом параметре поддерживаются следующие значения: CONNECT, QUERY, TABLE, QUERY_DDL, QUERY_DML, QUERY_DCL, QUERY_DML_NO_SELECT.
Для пользователей можно настроить исключения. То есть указать, для какого пользователя мы не будем вести аудит. Список этих пользователей хранится в параметре server_audit_excl_users. Тут, в отличие от предыдущего параметра, мы указываем исключение. Управляется примерно так:
> set global server_audit_excl_users='user01';Все подробности по настройке плагина есть в официальной документации.
Дальше этот лог можно передать куда-то на хранение. Например в elasticsearch. Для него есть готовые grok фильтры для разбора лога аудита в Ingest ноде или Logstash. Вот пример подобного фильтра. После этого можно будет настроить какие-то оповещения в зависимости от ваших потребностей. Например, при превышении каким-то пользователем числа подключений или слишком больше количество каких-то операций в единицу времени.
Максимально просто и быстро мониторинг на события можно настроить и в Zabbix. К примеру, сделать отдельные айтемы для строк только с конкретными запросами, например UPDATE или DELETE, или записывать только коды выхода, отличные от 0. Далее для них настроить триггеры на превышение средних значений в интервал времени на какую-то величину. Если происходят всплески по этим строкам, получите уведомление. Но сразу предупрежу, что Zabbix не очень для этого подходит. Только если событий немного. Иначе лог аудита будет занимать очень много места в базе данных Zabbix. Это плохая практика.
Придумать тут можно много всего в зависимости от ваших потребностей. И всё это сделать относительно просто. Не нужны никакие дополнительные средства и программы.
#mysql #security
{kind=link}
Рекомендую очень полезный скрипт для Mysql, который помогает настраивать параметры сервера в зависимости от имеющейся памяти. Я уже неоднократно писал в заметках примерный алгоритм действий для этого. Подробности можно посмотреть в статье про настройку сервера под Битрикс в разделе про Mysql. Можно вот эту заметку посмотреть, где я частично эту же тему поднимаю.
Скрипт простой в плане функциональности, так как только парсит внутреннюю статистику Mysql и выводит те параметры, что больше всего нужны для оптимизации потребления памяти. Но сделано аккуратно и удобно. Сразу показывает, сколько памяти потребляет каждое соединение.
Причём автор поддерживает этот скрипт. Я в апреле на одном из серверов заметил, что он даёт ошибку деления на ноль. Не стал разбираться, в чём там проблема. А сейчас зашёл и вижу, что автор внёс исправление как раз по этой части. Похоже, какое-то обновление Mysql сломало работу.
Вот прямая ссылка на код: mysql-stat.sh. Результат работы на картинке ниже. Добавить к нему нечего. Использовать так:
Не забудьте поставить пробел перед командой, чтобы она вместе с паролем не залетела в history. Либо почистите её после работы скрипта, так как пробел не всегда работает. Зависит от настроек. Это при условии, что у вас парольное подключение к MySQL.
#bash #script #mysql
Скрипт простой в плане функциональности, так как только парсит внутреннюю статистику Mysql и выводит те параметры, что больше всего нужны для оптимизации потребления памяти. Но сделано аккуратно и удобно. Сразу показывает, сколько памяти потребляет каждое соединение.
Причём автор поддерживает этот скрипт. Я в апреле на одном из серверов заметил, что он даёт ошибку деления на ноль. Не стал разбираться, в чём там проблема. А сейчас зашёл и вижу, что автор внёс исправление как раз по этой части. Похоже, какое-то обновление Mysql сломало работу.
Вот прямая ссылка на код: mysql-stat.sh. Результат работы на картинке ниже. Добавить к нему нечего. Использовать так:
# ./mysql-stat.sh --user root --password "superpass"Не забудьте поставить пробел перед командой, чтобы она вместе с паролем не залетела в history. Либо почистите её после работы скрипта, так как пробел не всегда работает. Зависит от настроек. Это при условии, что у вас парольное подключение к MySQL.
#bash #script #mysql
{kind=link}
Вчера слушал вебинар Rebrain по поводу бэкапов MySQL. Мне казалось, что я в целом всё знаю по этой теме. Это так и оказалось, кроме одного маленького момента. Существует более продвинутый аналог mysqldump для создания логических бэкапов — mydumper. Решил сразу сделать про него заметку, чтобы не забыть и самому запомнить инструмент.
Как вы, наверное, знаете, существуют два типа бэкапов MySQL:
1️⃣ Логические, или дампы, как их ещё называют. Это текстовые данные в виде sql команд, которые при восстановлении просто выполняются на сервере. Их обычно делают с помощью утилиты Mysqldump, которая идёт в комплекте с MySQL сервером. Их отличает простота создания и проверки. Из минусов — бэкапы только полные, долго создаются и долго восстанавливаются. В какой-то момент, в зависимости от размера базы и возможностей железа, их делать становится практически невозможно. (моя статья по теме)
2️⃣ Бинарные бэкапы на уровне непосредственно файлов базы данных. Наиболее популярное бесплатное средство для создания таких бэкапов — Percona XtraBackup. Позволяет делать полные и инкрементные бэкапы баз данных и всего сервера СУБД в целом. (моя статья по теме)
Mysqldump делает бэкапы в один поток и на выходе создаёт один файл дампа. Можно это обойти, делая скриптом бэкап таблиц по отдельности, но при таком подходе могут быть проблемы с целостностью итоговой базы. Отдельно таблицу из полного дампа можно вытянуть с помощью sed или awk. Пример потабличного бэкапа базы или вытаскивания отдельной таблицы из полного дампа я делал в заметке.
Так вот, с чего я начал. Есть утилита MyDumper, которая работает чуть лучше Mysqldump. Она делает логический дамп базы данных в несколько потоков и сразу складывает его в отдельные файлы по таблицам. И при этом контролирует целостность итогового бэкапа базы данных. Восстановление такого бэкапа выполняется с помощью MyLoader и тоже в несколько потоков.
Такой подход позволяет выполнять бэкап и восстановление базы в разы быстрее, чем с помощью Mysqldump, если, конечно, позволяет дисковая подсистема сервера. Использовать MyDumper не сложнее, чем Mysqldump. Это та же консольная утилита, которой можно передать параметры в виде ключей или заранее задать в конфигурационном файле. Примеры есть в репозитории.
Я не знал про существовании этой утилиты, хотя почти все свои сервера MySQL бэкаплю в виде логических бэкапов Mysqldump. Надо будет переходить на MyDumper.
#mysql #backup
Как вы, наверное, знаете, существуют два типа бэкапов MySQL:
1️⃣ Логические, или дампы, как их ещё называют. Это текстовые данные в виде sql команд, которые при восстановлении просто выполняются на сервере. Их обычно делают с помощью утилиты Mysqldump, которая идёт в комплекте с MySQL сервером. Их отличает простота создания и проверки. Из минусов — бэкапы только полные, долго создаются и долго восстанавливаются. В какой-то момент, в зависимости от размера базы и возможностей железа, их делать становится практически невозможно. (моя статья по теме)
2️⃣ Бинарные бэкапы на уровне непосредственно файлов базы данных. Наиболее популярное бесплатное средство для создания таких бэкапов — Percona XtraBackup. Позволяет делать полные и инкрементные бэкапы баз данных и всего сервера СУБД в целом. (моя статья по теме)
Mysqldump делает бэкапы в один поток и на выходе создаёт один файл дампа. Можно это обойти, делая скриптом бэкап таблиц по отдельности, но при таком подходе могут быть проблемы с целостностью итоговой базы. Отдельно таблицу из полного дампа можно вытянуть с помощью sed или awk. Пример потабличного бэкапа базы или вытаскивания отдельной таблицы из полного дампа я делал в заметке.
Так вот, с чего я начал. Есть утилита MyDumper, которая работает чуть лучше Mysqldump. Она делает логический дамп базы данных в несколько потоков и сразу складывает его в отдельные файлы по таблицам. И при этом контролирует целостность итогового бэкапа базы данных. Восстановление такого бэкапа выполняется с помощью MyLoader и тоже в несколько потоков.
Такой подход позволяет выполнять бэкап и восстановление базы в разы быстрее, чем с помощью Mysqldump, если, конечно, позволяет дисковая подсистема сервера. Использовать MyDumper не сложнее, чем Mysqldump. Это та же консольная утилита, которой можно передать параметры в виде ключей или заранее задать в конфигурационном файле. Примеры есть в репозитории.
Я не знал про существовании этой утилиты, хотя почти все свои сервера MySQL бэкаплю в виде логических бэкапов Mysqldump. Надо будет переходить на MyDumper.
#mysql #backup
{kind=link}
Вчера смотрел очень информативный вебинар Rebrain про оптимизацию запросов MySQL. Планирую сделать по нему заметку, когда запись появится в личном кабинете. Когда автор упомянул свой клиент MySQL Workbench, в чате начали присылать другие варианты клиентов. Я вспомнил, что несколько лет назад делал серию заметок по этой теме. Решил сформировать их в единый список. Думаю, будет полезно. С MySQL постоянно приходится работать в различных приложениях и сайтах.
🟢 MySQL клиенты в виде приложений:
▪ MySQL Workbench - самый навороченный, функциональный и тормозной клиент от авторов непосредственно СУБД MySQL. Если нужен максимум возможностей, то это про него. В большинстве случаев всё это не надо, если вы не разработчик.
▪ HeidiSQL - маленький и шустрый клиент, есть портированная версия. Для типовых задач системного администратора будет достаточно. Я его последнее время использовал, когда нужно было. Но давно это было.
▪ Dbeaver - отличается в первую очередь хорошей поддержкой PostgreSQL и часто используется именно для неё. Если нужно только MySQL, то лучше взять HeidiSQL.
🟡 MySQL клиенты в виде скриптов:
▪ PhpMyAdmin - думаю, не нуждается в представлении. Я почти всегда использую именно его. Его же обычно просят и разработчики. В публичный доступ не рекомендую его выставлять. Если хочется разово запустить, но не хочется настраивать веб сервер, то можно быстро запустить через встроенный в php веб сервер.
▪ Adminer - простенький php скрипт из одного файла. Очень удобно, если не хочется ничего настраивать, а нужно быстро зайти в базу и что-то там сделать. Как закончишь, скрипт можно просто удалить.
Тру админы наверняка начнут сейчас писать в комментариях, что не надо никаких внешних клиентов. Заходим консольным клиентом и делаем всё, что надо. Иногда я так делаю, но приходится вспоминать синтаксис, так как нужен он редко. Время тратится больше. Тот же adminer быстрее закинуть, чем вспомнить, как правильно написать запрос на создание пользователя и выставление для него прав на базу. Другое дело, если копипастишь откуда-то команды. Тогда можно и в консольный клиент.
#mysql #подборка
🟢 MySQL клиенты в виде приложений:
▪ MySQL Workbench - самый навороченный, функциональный и тормозной клиент от авторов непосредственно СУБД MySQL. Если нужен максимум возможностей, то это про него. В большинстве случаев всё это не надо, если вы не разработчик.
▪ HeidiSQL - маленький и шустрый клиент, есть портированная версия. Для типовых задач системного администратора будет достаточно. Я его последнее время использовал, когда нужно было. Но давно это было.
▪ Dbeaver - отличается в первую очередь хорошей поддержкой PostgreSQL и часто используется именно для неё. Если нужно только MySQL, то лучше взять HeidiSQL.
🟡 MySQL клиенты в виде скриптов:
▪ PhpMyAdmin - думаю, не нуждается в представлении. Я почти всегда использую именно его. Его же обычно просят и разработчики. В публичный доступ не рекомендую его выставлять. Если хочется разово запустить, но не хочется настраивать веб сервер, то можно быстро запустить через встроенный в php веб сервер.
▪ Adminer - простенький php скрипт из одного файла. Очень удобно, если не хочется ничего настраивать, а нужно быстро зайти в базу и что-то там сделать. Как закончишь, скрипт можно просто удалить.
Тру админы наверняка начнут сейчас писать в комментариях, что не надо никаких внешних клиентов. Заходим консольным клиентом и делаем всё, что надо. Иногда я так делаю, но приходится вспоминать синтаксис, так как нужен он редко. Время тратится больше. Тот же adminer быстрее закинуть, чем вспомнить, как правильно написать запрос на создание пользователя и выставление для него прав на базу. Другое дело, если копипастишь откуда-то команды. Тогда можно и в консольный клиент.
#mysql #подборка
{kind=link}
Я посмотрел два больших информативных вебинара про оптимизацию запросов в MySQL. Понятно, что в формате заметки невозможно раскрыть тему, поэтому я сделаю выжимку основных этапов и инструментов, которые используются. Кому нужна будет эта тема, сможет раскрутить её на основе этих вводных.
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
1️⃣ Включаем логирование запросов, всех или только медленных в зависимости от задач. В общем случае это делается примерно так:
log_error = /var/log/mysql/error.logslow_query_logslow_query_log_file = /var/log/mysql/slow.loglong_query_time = 2.0Для детального разбора нужны будут и более тонкие настройки.
2️⃣ Организуется, если нет, хотя бы базовый мониторинг MySQL, чтобы можно было как-то оценить результат и состояние сервера. Можно взять Zabbix, Percona Monitoring and Management, LPAR2RRD или что-то ещё.
3️⃣ Начинаем анализировать slow_query_log с помощью pt-query-digest из состава Percona Toolkit. Она выведет статистику по всем запросам, из которых один или несколько будут занимать большую часть времени работы СУБД. Возможно это будет вообще один единственный запрос, из-за которого тормозит весь сервер. Выбираем запросы и работаем дальше с ними. Уже здесь можно увидеть запрос от какого-то ненужного модуля, или какой-то забытой системы по собору статистики и т.д.
4️⃣ Если есть возможность, показываем запрос разработчикам или кому-то ещё, чтобы выполнили оптимизацию схемы БД: поработали с типами данных, индексами, внешними ключами, нормализацией и т.д. Если такой возможности нет, работаем с запросом дальше сами.
5️⃣ Смотрим план выполнения проблемного запроса, добавляя к нему в начало EXPLAIN и EXPLAIN ANALYZE. Можно воспользоваться визуализацией плана в MySQL Workbench. Если нет специальных знаний по анализу запросов, то кроме добавления индекса в какое-то место вряд ли что-то получится сделать. Если знания есть, то скорее всего и этот материал вам не нужен. Про индексы у меня была отдельная заметка. Понимая, как работают индексы, и глядя на медленные места запроса, где нет индекса, можно попробовать добавить туда индекс и оценить результат. Отдельно отмечу, что если у вас в запросе есть где-то полное сканирование большой таблицы, то это плохо. Этого нужно стараться избегать в том числе с помощью индексов.
6️⃣ После того, как закончите с запросами, проанализируйте в целом индексы в базе с помощью pt-duplicate-key-checker. Она покажет дубликаты индексов и внешних ключей. Если база большая и имеет много составных индексов, то вероятность появления дубликатов индексов немалая. А лишние индексы увеличивают количество записей на диск и снижают в целом производительность СУБД.
7️⃣ Оцените результат своей работы в мониторинге. Соберите ещё раз лог медленных запросов и оцените изменения, если они есть.
В целом, тема сложная и наскоком её не осилить, если нет базовой подготовки и понимания, как работает СУБД. Разработчики, по идее, должны разбираться лучше системных администраторов в этих вопросах, так как структуру базы данных и запросы к ней чаще всего делают именно они.
Теорию и практику в том виде, как я её представил в заметке, должен знать администратор сервера баз данных, чтобы предметно говорить по этой теме и передать проблему тому, в чьей зоне ответственности она находится. Если разработчики нагородили таких запросов, что сайт колом стоит, то им и решать эту задачу. Но если вы им не покажете факты в виде медленных запросов, то они будут говорить, что надо увеличить производительность сервера, потому что для них это проще всего.
Я лично не раз с этим сталкивался. Где-то даже команду поменяли, потому что они не могли обеспечить нормальную производительность сайта. Другие пришли и всё сделали быстро, потому что банально разбирались, как это делается. А если разработчик не может, то ничего не поделать. И все будут думать, что это сервер тормозит, если вы не докажете обратное.
#mysql #perfomance
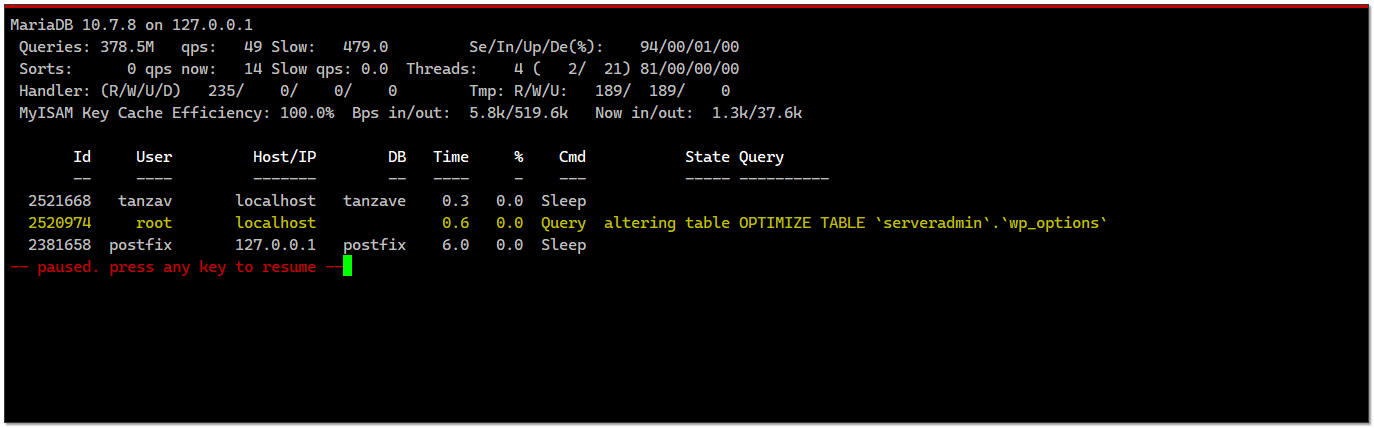
{kind=link}
Для мониторинга загрузки сервера MySQL в режиме реального времени есть старый и известный инструмент - Mytop. Из названия понятно, что это топоподобная консольная программа. С её помощью можно смотреть какие пользователи и какие запросы отправляют к СУБД. Как минимум, это удобнее и нагляднее, чем смотреть
Когда попытался установить mytop на Debian 11, удивился, не обнаружив её в репозиториях. Обычно жила там. Немного погуглил и понял, что отдельный пакет mytop убрали, потому что теперь он входит в состав mariadb-client. Если вы используете mariadb, то mytop у вас скорее всего уже установлен. Если у вас другая система, то попробуйте установить mytop через пакетный менеджер. В rpm дистрибутивах она точно была раньше в репах. В Freebsd, кстати, тоже есть.
Для того, чтобы программа могла смотреть информацию обо всех базах и пользователях, у неё должны быть ко всему этому права. Если будете смотреть информацию по отдельной базе данных, то можно создать отдельного пользователя для этого с доступом только к этой базе.
Mytop можно запустить, передав все параметры через ключи, либо создать файл конфигурации
Обращаю внимание, что если укажите localhost вместо 127.0.0.1, то скорее всего не подключитесь. Вообще, это распространённая проблема, так что я стараюсь всегда и везде писать именно адрес, а не имя хоста. Локалхост часто отвечает по ipv6, и не весь софт корректно это отрабатывает. Лучше явно прописывать 127.0.0.1.
Теперь можно запускать
◽d - выбрать конкретную базу данных
◽p - остановить обновление информации на экране
◽i - отобразить соединения в статусе Sleep
◽V - посмотреть параметры СУБД
Хорошая программа в копилку тех, кто работает с MySQL, наряду с:
🔹 mysqltuner
🔹 MyDumper
Ещё полезные ссылки по теме:
▪ Оптимизация запросов в MySQL
▪ MySQL клиенты
▪ Скрипт для оптимизации потребления памяти
▪ Аудит запросов и прочих действия в СУБД
▪ Рекомендации CIS по настройке MySQL
▪ Список настроек, обязательных к проверке
▪ Сравнение mysql vs mariadb
▪ Индексы в Mysql
▪ Полный и инкрементный бэкап MySQL
▪ Мониторинг MySQL с помощью Zabbix
#mysql
show full processlist;. Я обычно туда первым делом заглядываю, если на сервере намечаются какие-то проблемы. Когда попытался установить mytop на Debian 11, удивился, не обнаружив её в репозиториях. Обычно жила там. Немного погуглил и понял, что отдельный пакет mytop убрали, потому что теперь он входит в состав mariadb-client. Если вы используете mariadb, то mytop у вас скорее всего уже установлен. Если у вас другая система, то попробуйте установить mytop через пакетный менеджер. В rpm дистрибутивах она точно была раньше в репах. В Freebsd, кстати, тоже есть.
Для того, чтобы программа могла смотреть информацию обо всех базах и пользователях, у неё должны быть ко всему этому права. Если будете смотреть информацию по отдельной базе данных, то можно создать отдельного пользователя для этого с доступом только к этой базе.
Mytop можно запустить, передав все параметры через ключи, либо создать файл конфигурации
~/.mytop (не забудьте ограничить к нему доступ):user=rootpass=passwordhost=127.0.0.1port=3306color=1delay=3idle=0Обращаю внимание, что если укажите localhost вместо 127.0.0.1, то скорее всего не подключитесь. Вообще, это распространённая проблема, так что я стараюсь всегда и везде писать именно адрес, а не имя хоста. Локалхост часто отвечает по ipv6, и не весь софт корректно это отрабатывает. Лучше явно прописывать 127.0.0.1.
Теперь можно запускать
mytop и смотреть информацию по всем базам. Если набрать ?, то откроется справка. Там можно увидеть все возможности программы. Наиболее актуальны: ◽d - выбрать конкретную базу данных
◽p - остановить обновление информации на экране
◽i - отобразить соединения в статусе Sleep
◽V - посмотреть параметры СУБД
Хорошая программа в копилку тех, кто работает с MySQL, наряду с:
🔹 mysqltuner
🔹 MyDumper
Ещё полезные ссылки по теме:
▪ Оптимизация запросов в MySQL
▪ MySQL клиенты
▪ Скрипт для оптимизации потребления памяти
▪ Аудит запросов и прочих действия в СУБД
▪ Рекомендации CIS по настройке MySQL
▪ Список настроек, обязательных к проверке
▪ Сравнение mysql vs mariadb
▪ Индексы в Mysql
▪ Полный и инкрементный бэкап MySQL
▪ Мониторинг MySQL с помощью Zabbix
#mysql
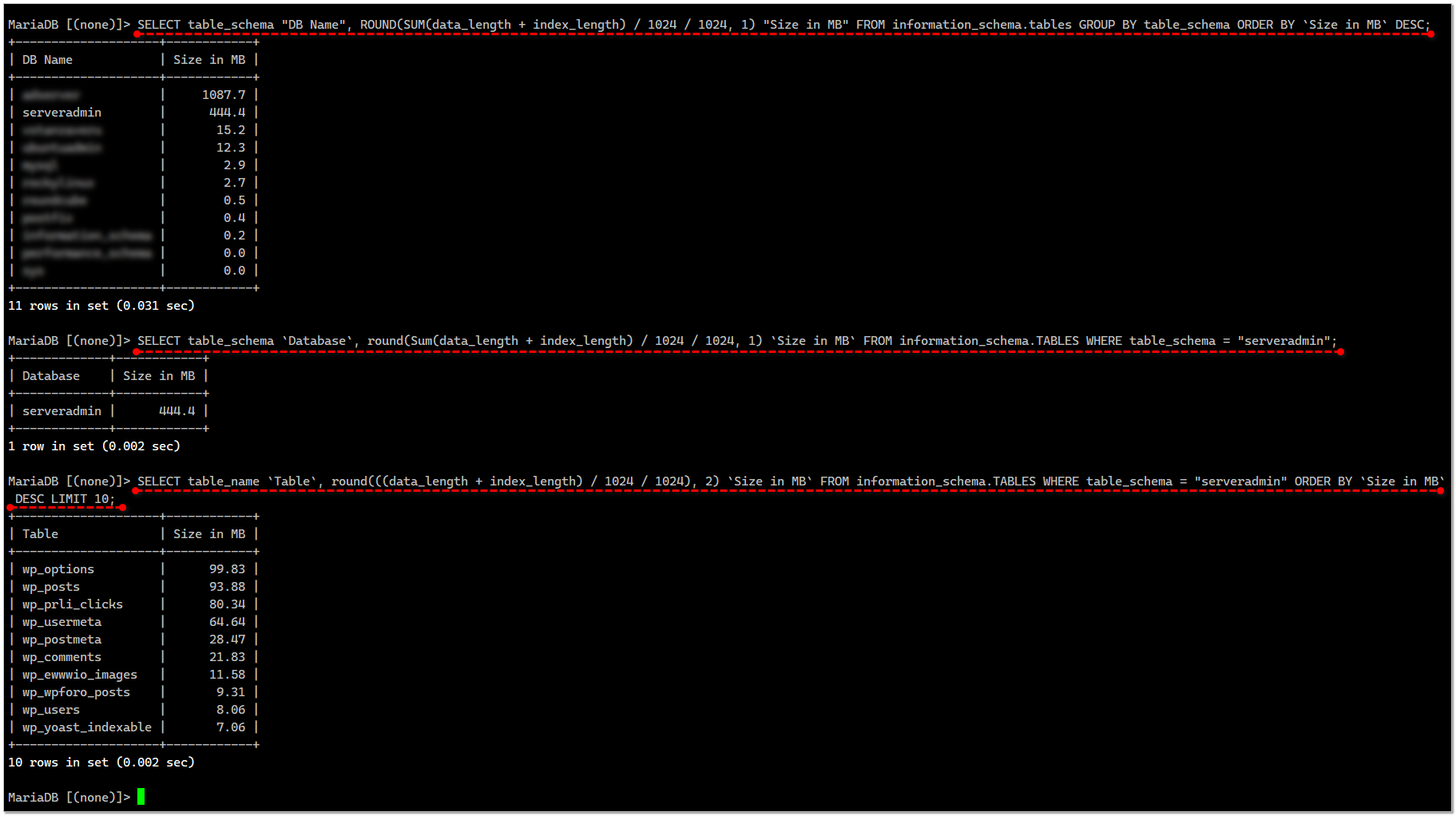
{kind=link}
Несколько полезных команд для консоли клиента mysql из практики, которыми пользуюсь сам.
📌 Посмотреть размер баз данных на сервере с сортировкой по размеру в мегабайтах:
📌 Посмотреть размер конкретной базы данных:
📌 Посмотреть размер самых больших таблиц в базе данных:
📌 Удалить все таблицы в базе данных, не удаляя саму базу. То есть полная очистка базы без удаления:
Последнюю команду посоветовали в комментариях к заметке, где я то же самое делаю своими костылями на bash. На самом деле эта, казалось бы простая задача, на деле не такая уж и простая. Я себе сохранил предложенный вариант. Он удобнее и проще моего.
Сами понимаете, что это идеальная заметка для того, чтобы её сохранить и использовать, когда будете работать с mysql.
#mysql
📌 Посмотреть размер баз данных на сервере с сортировкой по размеру в мегабайтах:
SELECT table_schema "DB Name", ROUND(SUM(data_length + index_length) / 1024 / 1024, 1) "Size in MB" FROM information_schema.tables GROUP BY table_schema ORDER BY `Size in MB` DESC;📌 Посмотреть размер конкретной базы данных:
SELECT table_schema `Database`, round(Sum(data_length + index_length) / 1024 / 1024, 1) `Size in MB` FROM information_schema.TABLES WHERE table_schema = "имя базы";📌 Посмотреть размер самых больших таблиц в базе данных:
SELECT table_name `Table`, round(((data_length + index_length) / 1024 / 1024), 2) `Size in MB` FROM information_schema.TABLES WHERE table_schema = "имя базы" ORDER BY `Size in MB` DESC LIMIT 10;📌 Удалить все таблицы в базе данных, не удаляя саму базу. То есть полная очистка базы без удаления:
SELECT CONCAT ('DROP TABLE ',GROUP_CONCAT(TABLE_NAME),';') INTO @qery FROM INFORMATION_SCHEMA.TABLES WHERE table_schema = "имя базы"; PREPARE drop_tables FROM @qery; EXECUTE drop_tables;Последнюю команду посоветовали в комментариях к заметке, где я то же самое делаю своими костылями на bash. На самом деле эта, казалось бы простая задача, на деле не такая уж и простая. Я себе сохранил предложенный вариант. Он удобнее и проще моего.
Сами понимаете, что это идеальная заметка для того, чтобы её сохранить и использовать, когда будете работать с mysql.
#mysql
{kind=link}
На днях столкнулся с ошибкой в эксплуатации и настройке MySQL сервера, о которой решил написать, чтобы самому не забыть решение, и с вами поделиться. Тема довольно распространённая, теория по которой будет полезна всем, кто работает с этой СУБД.
В MySQL есть настройка innodb_temp_data_file_path, которая отвечает за управление временным табличным пространством (temporary tablespace). Это место, где временно хранятся данные на протяжении сеанса пользователя, потом очищаются. В основном это пространство используется для операций сортировки, может чего-то ещё. Точно я не знаю.
По умолчанию этот параметр имеет значение autoextend и в некоторых случаях при такой настройке файл
Тут указано, что создаётся файл изначального размера 12 мегабайт с автоматическим увеличением до 2 гигабайт. Заранее предсказать, какого максимального объёма будет достаточно, трудно. Это зависит от многих факторов. Я такую настройку сделал несколько лет назад на одном сервере, который на днях засбоил.
Проблемы выражались в том, что существенно увеличилась запись на диск. Об этом отрапортовал Zabbix. Посмотрел статистику этой VM на гипервизоре, тоже видно, что нагрузка на диск выросла. В самой VM в логе MySQL примерно в то же время стали появляться ошибки:
Меня они сначала сбили с толку, так как подумал, что на сервере не хватает места. Но нет, с местом всё в порядке. Стал разбираться дальше и понял, что подобная ошибка означает не только недостаток места на диске, (а при нём будет такая же ошибка) но и нехватку выделенного места под temporary tablespace. Увеличил значение в innodb_temp_data_file_path и перезапустил MySQL сервер. Ошибка ушла, как и повышенная нагрузка на диск.
Это один из тех параметров, на который нужно обращать внимание при настройке MySQL сервера, иначе он может в какой-то момент преподнести сюрприз. Можно этот файл вынести на отдельный диск, или вообще указать 2 разных файла на разных дисках. В процессе написания заметки возникла идея, что может его и в память можно перенести. Но это надо погружаться в тему, чтобы понять, к чему это в итоге приведёт и стоит ли так делать. Если кто-то пробовал, напишите о своём опыте.
#mysql
В MySQL есть настройка innodb_temp_data_file_path, которая отвечает за управление временным табличным пространством (temporary tablespace). Это место, где временно хранятся данные на протяжении сеанса пользователя, потом очищаются. В основном это пространство используется для операций сортировки, может чего-то ещё. Точно я не знаю.
По умолчанию этот параметр имеет значение autoextend и в некоторых случаях при такой настройке файл
ibtmp1, в котором хранятся временные данные, может сожрать всё свободное место на сервере. У меня такое было не раз. Поэтому я всегда ограничиваю этот размер. Выглядит это примерно так:innodb_temp_data_file_path = ibtmp1:12M:autoextend:max:2GТут указано, что создаётся файл изначального размера 12 мегабайт с автоматическим увеличением до 2 гигабайт. Заранее предсказать, какого максимального объёма будет достаточно, трудно. Это зависит от многих факторов. Я такую настройку сделал несколько лет назад на одном сервере, который на днях засбоил.
Проблемы выражались в том, что существенно увеличилась запись на диск. Об этом отрапортовал Zabbix. Посмотрел статистику этой VM на гипервизоре, тоже видно, что нагрузка на диск выросла. В самой VM в логе MySQL примерно в то же время стали появляться ошибки:
[ERROR] /usr/sbin/mysqld: The table '/tmp/#sql_1c6f_1' is fullМеня они сначала сбили с толку, так как подумал, что на сервере не хватает места. Но нет, с местом всё в порядке. Стал разбираться дальше и понял, что подобная ошибка означает не только недостаток места на диске, (а при нём будет такая же ошибка) но и нехватку выделенного места под temporary tablespace. Увеличил значение в innodb_temp_data_file_path и перезапустил MySQL сервер. Ошибка ушла, как и повышенная нагрузка на диск.
Это один из тех параметров, на который нужно обращать внимание при настройке MySQL сервера, иначе он может в какой-то момент преподнести сюрприз. Можно этот файл вынести на отдельный диск, или вообще указать 2 разных файла на разных дисках. В процессе написания заметки возникла идея, что может его и в память можно перенести. Но это надо погружаться в тему, чтобы понять, к чему это в итоге приведёт и стоит ли так делать. Если кто-то пробовал, напишите о своём опыте.
#mysql
На днях триггер в Zabbix сработал на то, что дамп Mysql базы не создался. Это бывает редко, давно его не видел. Решил по этому поводу рассказать, как у меня устроена проверка создания дампов с контролем этого процесса через Zabbix. Здесь будет только теория в общих словах. Пример реализации описан у меня в статье:
⇨ https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
Она старя, что-то уже переделывалась, но общий смысл примерно тот же. К сожалению, нет времени обновлять и актуализировать статьи. Да и просмотров там не очень много. Тема узкая, не очень популярная. Хотя как по мне, без мониторинга этих дампов просто нельзя. Можно годами не знать, что у тебя дампы битые, если хотя бы не проверять их создание.
Описание ниже будет актуально для любых текстовых дампов sql серверов. Как минимум, один и тот же подход я применяю как к Mysql, так и Postgresql.
1️⃣ В любом дампе sql обычно есть служебные строки в начале и в конце. Для Mysql это обычно в начале
2️⃣ Если строки есть, пишу в отдельный лог файл что-то типа
3️⃣ В Zabbix настраиваю отдельный шаблон, где в айтем забираю этот лог. И делаю для него триггер, что если есть слово corrupted, то срабатывает триггер.
Вот и всё. Если срабатывает триггер, иду на сервер и смотрю результат работы дампа. Я его тоже в отдельный файл сохраняю. Можно и его забирать в Zabbix, но я не вижу большого смысла в этой информации, чтобы забивать ей базу заббикса.
В логе увидел ошибку:
Не знаю, с чем она была связана. Проверил лог mysql в это время, там тоже ошибка:
Проверил таблицу, там всё в порядке:
Следующий дамп прошёл уже без ошибок, так что я просто забил. Если повторится, буду разбираться детальнее.
Делать такую проверку можно как угодно. Я люблю всё замыкать на Zabbix, а он уже шлёт уведомления. Можно в скрипте с проверкой сразу отправлять информацию на почту, и, к примеру, мониторить почтовый ящик. Если кто-то тоже мониторит создание дампов, то расскажите, как это делаете вы.
Ну и не забываем, что это только мониторинг создания. Даже если не было ошибок, это ещё не гарантия того, что дамп реально рабочий, хотя лично я ни разу не сталкивался с тем, что корректно созданный дамп не восстанавливается.
Тем не менее, восстановление я тоже проверяю. Тут уже могут быть различные реализации в зависимости от инфраструктуры. Самый более ли менее приближённый к реальности вариант такой. Копируете этот дамп вместе с бэкапом исходников на запасной веб сервер, там скриптами разворачиваете и проверяете тем же Zabbix, что развёрнутый из бэкапов сайт работает и актуален по свежести. Пример, как это может выглядеть, я когда-то тоже описывал в старой статье.
#mysql #backup
⇨ https://serveradmin.ru/nastrojka-mysqldump-proverka-i-monitoring-bekapov-mysql/
Она старя, что-то уже переделывалась, но общий смысл примерно тот же. К сожалению, нет времени обновлять и актуализировать статьи. Да и просмотров там не очень много. Тема узкая, не очень популярная. Хотя как по мне, без мониторинга этих дампов просто нельзя. Можно годами не знать, что у тебя дампы битые, если хотя бы не проверять их создание.
Описание ниже будет актуально для любых текстовых дампов sql серверов. Как минимум, один и тот же подход я применяю как к Mysql, так и Postgresql.
1️⃣ В любом дампе sql обычно есть служебные строки в начале и в конце. Для Mysql это обычно в начале
-- MySQL dump и в конце -- Dump completed. После создания дампа я банальным grep проверяю, что там эти строки есть. 2️⃣ Если строки есть, пишу в отдельный лог файл что-то типа
${BASE01} backup is OK, если хоть одной строки нет, то ${BASE01} backup is corrupted.3️⃣ В Zabbix настраиваю отдельный шаблон, где в айтем забираю этот лог. И делаю для него триггер, что если есть слово corrupted, то срабатывает триггер.
Вот и всё. Если срабатывает триггер, иду на сервер и смотрю результат работы дампа. Я его тоже в отдельный файл сохраняю. Можно и его забирать в Zabbix, но я не вижу большого смысла в этой информации, чтобы забивать ей базу заббикса.
В логе увидел ошибку:
mysqldump: Error 2013: Lost connection to MySQL server during query when dumping table `b_stat_session_data` at row: 1479887Не знаю, с чем она была связана. Проверил лог mysql в это время, там тоже ошибка:
Aborted connection 1290694 to db: 'db01' user: 'user01' host: 'localhost' (Got timeout writing communication packets)Проверил таблицу, там всё в порядке:
> check table b_stat_session_data;Следующий дамп прошёл уже без ошибок, так что я просто забил. Если повторится, буду разбираться детальнее.
Делать такую проверку можно как угодно. Я люблю всё замыкать на Zabbix, а он уже шлёт уведомления. Можно в скрипте с проверкой сразу отправлять информацию на почту, и, к примеру, мониторить почтовый ящик. Если кто-то тоже мониторит создание дампов, то расскажите, как это делаете вы.
Ну и не забываем, что это только мониторинг создания. Даже если не было ошибок, это ещё не гарантия того, что дамп реально рабочий, хотя лично я ни разу не сталкивался с тем, что корректно созданный дамп не восстанавливается.
Тем не менее, восстановление я тоже проверяю. Тут уже могут быть различные реализации в зависимости от инфраструктуры. Самый более ли менее приближённый к реальности вариант такой. Копируете этот дамп вместе с бэкапом исходников на запасной веб сервер, там скриптами разворачиваете и проверяете тем же Zabbix, что развёрнутый из бэкапов сайт работает и актуален по свежести. Пример, как это может выглядеть, я когда-то тоже описывал в старой статье.
#mysql #backup
Server Admin
Настройка mysqldump, проверка и мониторинг бэкапов mysql |...
Создание и проверка бэкапов MySQL с помощью mysqldump. Мониторинг бэкапов в Zabbix с уведомлением об ошибках создания.
На канале накопилось много полезных материалов по MySQL, которые я использую сам, особенно во время настройки нового сервера. Чтобы упростить себе и вам задачу, решил объединить всё наиболее полезное в одну публикацию для удобной навигации.
📌 Настройка:
▪️ Базовые настройки сервера, которые нужно проконтроллировать при установке
▪️ MySQLTuner - помощник по подбору оптимальных параметров под железо и профиль нагрузки
▪️ Скрипт mysql-stat для упрощения выбора параметров в зависимости от доступной оперативы на сервере
▪️ Рекомендации по безопасности от CIS
▪️ Разбор параметра innodb_temp_data_file_path
▪️ Настройка Audit Plugin для отслеживания действий на сервере
▪️ Настройка репликации
📌 Бэкап:
▪️ Полный и инкрементный backup Mysql с помощью Percona XtraBackup
▪️ Mydumper - многопоточное создание дампов
▪️ SQLBackupAndFTP - приложение под Windows для бэкапа
▪️ Скрипт AutoMySQLBackup для автоматического бэкапа баз
▪️ Восстановление отдельной таблицы из дампа всей базы
📌 Мониторинг:
▪️ Мониторинг MySQL с помощью Zabbix
▪️ Консольный Mytop для мониторинга в режиме реального времени
▪️ Проверка успешности создания дампа
▪️ Мониторинг с помощью Percona Monitoring and Management
📌 Эксплуатация:
▪️ Пошаговый план оптимизации запросов MySQL сервера
▪️ Полезные консольные команды mysql клиента
▪️ Подборка MySQL клиентов для работы с СУБД
▪️ Удаление всех таблиц в базе без удаления самой базы
▪️ ProxySQL для проксирования и кэша SQL запросов
▪️ Краткая информация о том, что такое индексы в MySQL
#mysql #подборка
📌 Настройка:
▪️ Базовые настройки сервера, которые нужно проконтроллировать при установке
▪️ MySQLTuner - помощник по подбору оптимальных параметров под железо и профиль нагрузки
▪️ Скрипт mysql-stat для упрощения выбора параметров в зависимости от доступной оперативы на сервере
▪️ Рекомендации по безопасности от CIS
▪️ Разбор параметра innodb_temp_data_file_path
▪️ Настройка Audit Plugin для отслеживания действий на сервере
▪️ Настройка репликации
📌 Бэкап:
▪️ Полный и инкрементный backup Mysql с помощью Percona XtraBackup
▪️ Mydumper - многопоточное создание дампов
▪️ SQLBackupAndFTP - приложение под Windows для бэкапа
▪️ Скрипт AutoMySQLBackup для автоматического бэкапа баз
▪️ Восстановление отдельной таблицы из дампа всей базы
📌 Мониторинг:
▪️ Мониторинг MySQL с помощью Zabbix
▪️ Консольный Mytop для мониторинга в режиме реального времени
▪️ Проверка успешности создания дампа
▪️ Мониторинг с помощью Percona Monitoring and Management
📌 Эксплуатация:
▪️ Пошаговый план оптимизации запросов MySQL сервера
▪️ Полезные консольные команды mysql клиента
▪️ Подборка MySQL клиентов для работы с СУБД
▪️ Удаление всех таблиц в базе без удаления самой базы
▪️ ProxySQL для проксирования и кэша SQL запросов
▪️ Краткая информация о том, что такое индексы в MySQL
#mysql #подборка
{kind=link}
Возникла небольшая прикладная задача. Нужно было периодически с одного mysql сервера перекидывать дамп одной таблицы из базы на другой сервер в такую же базу. Решений этой задачи может быть много. Я взял и решил в лоб набором простых команд на bash. Делюсь с вами итоговым скриптом. Даже если он вам не нужен в рамках этой задачи, то можете взять какие-то моменты для использования в другой.
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
#!/bin/bash
# Дамп базы с заменой общего комплексного параметра --opt, где используется ключ --lock-tables на набор отдельных ключей, где вместо lock-tables используется --single-transaction
/usr/bin/mysqldump --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob --databases database01 -u'userdb' -p'password' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
# Из общего дампа вырезаю дамп только данных таблицы table01. Общий дамп тоже оставляю, потому что он нужен для других задач
/usr/bin/cat /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql | /usr/bin/awk '/LOCK TABLES `table01`/,/UNLOCK TABLES/' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Сжимаю оба дампа
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Копирую дамп таблицы на второй сервер, аутентификация по ключам
/usr/bin/scp /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql.gz sshuser@10.20.30.45:/tmp
# Выполняю на втором сервере ряд заданий в рамках ssh сессии: распаковываю дамп таблицы, очищаю таблицу на этом сервере, заливаю туда данные из дампа
/usr/bin/ssh sshuser@10.20.30.45 '/usr/bin/gunzip /tmp/"$(date +%Y-%m-%d)"-table01.sql.gz && /usr/bin/mysql -e "delete from database01.table01; use database01; source /tmp/"$(date +%Y-%m-%d)"-table01.sql;"'
# Удаляю дамп
/usr/bin/ssh sshuser@10.20.30.45 'rm /tmp/"$(date +%Y-%m-%d)"-table01.sql'
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
🎓 У хостера Selectel есть небольшая "академия", где в открытом доступе есть набор курсов. Они неплохого качества. Где-то по верхам в основном теория, а где-то полезные практические вещи. Я бы обратил внимание на два курса, которые показались наиболее полезными:
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
⇨ PostgreSQL для новичков
⇨ MySQL для новичков
Там небольшой структурированный материал по основам: установка, работа в консоли, бэкап/восстановление, сброс пароля и т.д. Ничего особенного, но в целом уровень выше, чем у обычной статьи в интернете от условного автора, типа меня, который подобное может написать из энтузиазма. Хотя последнее время вообще не встречаю в интернете подробные авторские статьи хоть от кого-нибудь. В основном на видео все переключились.
Вообще, мне нравится такой маркетинг, когда даётся реальная польза, а в материал вставлены уместные ссылки на свои сервисы, на базе которых написана статья. Это ситуация, которая понятна и не раздражает навязчивостью или заманухой. Хостера могу порекомендовать. У меня никто не просил писать этот пост и рефку свою не оставляю. Я давно с ним работаю, поэтому пишу искренне.
#обучение #mysql #postgresql
{kind=link}