
TOWARDS FEDERATED LEARNING AT SCALE: SYSTEM DESIGN
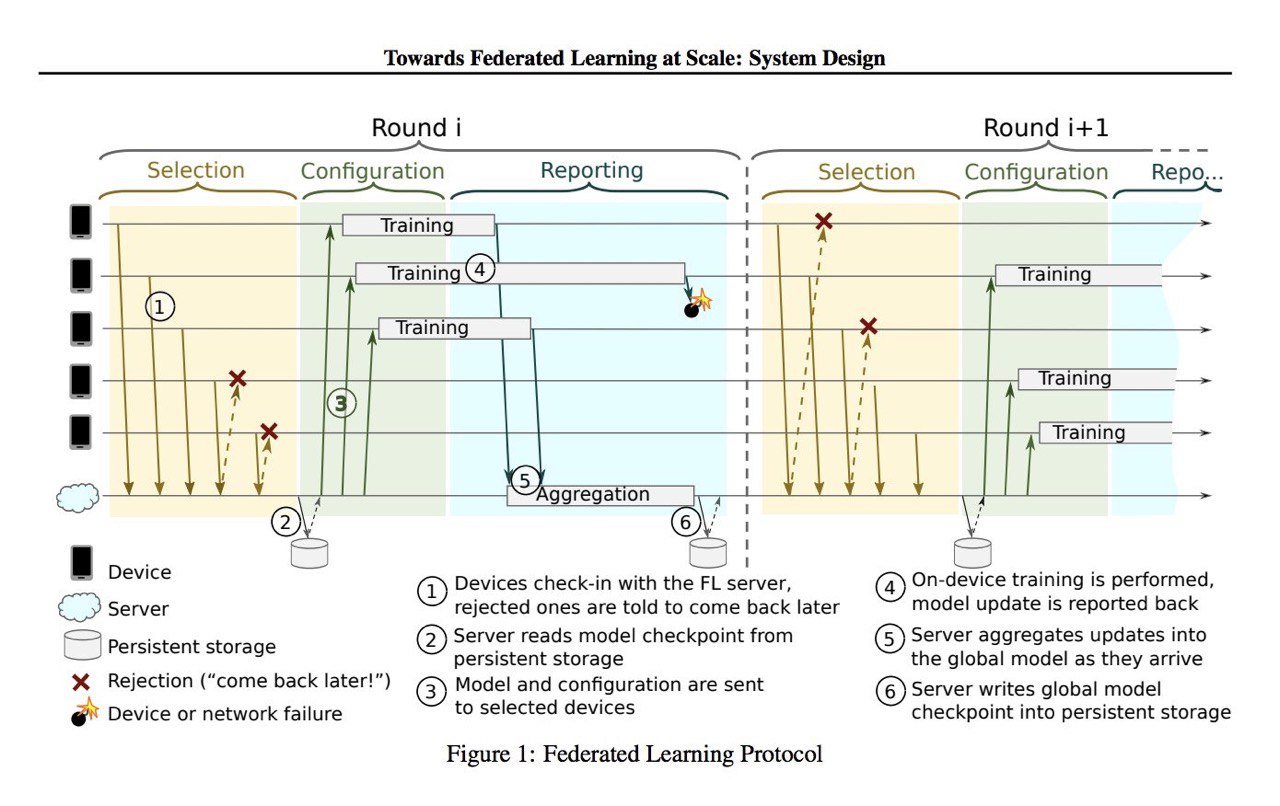
Google published how they do #FederatedLearning at scale on tens of millions of mobile phones. This is about training model on decentralized data.
ArXiV: https://arxiv.org/pdf/1902.01046.pdf
#Google #Privacy
Google published how they do #FederatedLearning at scale on tens of millions of mobile phones. This is about training model on decentralized data.
ArXiV: https://arxiv.org/pdf/1902.01046.pdf
#Google #Privacy
{kind=link}
#Google has open-sourced #FederatedLearning code
Step-by-step #tutorial showing how to perform Federated Learning using the same infrastructure Google
uses on 10s of millions of smartphones.
Link: https://medium.com/tensorflow/introducing-tensorflow-federated-a4147aa20041
Step-by-step #tutorial showing how to perform Federated Learning using the same infrastructure Google
uses on 10s of millions of smartphones.
Link: https://medium.com/tensorflow/introducing-tensorflow-federated-a4147aa20041
Medium
Introducing TensorFlow Federated
Posted by Alex Ingerman (Product Manager) and Krzys Ostrowski (Research Scientist)
Estimating the success of re-identifications in incomplete datasets using generative models
99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes, suggesting that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR.
This is a big concern about privacy and a problem for Data Engineering, especially for those working with anonymized personal information. Paper provides a way to re-identify person from anonymized dataset, this can be useful for people who work for government or security companies
https://www.reddit.com/r/science/comments/chko43/9998_of_americans_would_be_correctly_reidentified/
#privacy #gdpr #federatedlearning #ml
99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes, suggesting that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR.
This is a big concern about privacy and a problem for Data Engineering, especially for those working with anonymized personal information. Paper provides a way to re-identify person from anonymized dataset, this can be useful for people who work for government or security companies
https://www.reddit.com/r/science/comments/chko43/9998_of_americans_would_be_correctly_reidentified/
#privacy #gdpr #federatedlearning #ml
Reddit
From the science community on Reddit: 99.98% of Americans would be correctly re-identified in any dataset using 15 demographic…
Posted by FvDijk - 348 votes and 29 comments