
Simple, Scalable Adaptation for Neural Machine Translation
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. Researchers from Google propose a simple yet efficient approach for adaptation in #NMT. Their proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously.
Guess it can be applied not only in #NMT but in many other #NLP, #NLU and #NLG tasks.
Paper: https://arxiv.org/pdf/1909.08478.pdf
#BERT #NMT #FineTuning
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. Researchers from Google propose a simple yet efficient approach for adaptation in #NMT. Their proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously.
Guess it can be applied not only in #NMT but in many other #NLP, #NLU and #NLG tasks.
Paper: https://arxiv.org/pdf/1909.08478.pdf
#BERT #NMT #FineTuning
Communication-based Evaluation for Natural Language Generation (#NLG) that's dramatically out-performed standard n-gram-based methods.
Have you ever think that n-gram overlap measures like #BLEU or #ROUGE is not good enough for #NLG evaluation and human based evaluation is too expensive? Researchers from Stanford University also think so. The main shortcoming of #BLEU or #ROUGE methods is that they fail to take into account the communicative function of language; a speaker's goal is not only to produce well-formed expressions, but also to convey relevant information to a listener.
Researchers propose approach based on color reference game. In this game, a speaker and a listener see a set of three colors. The speaker is told one color is the target and tries to communicate the target to the listener using a natural language utterance. A good utterance is more likely to lead the listener to select the target, while a bad utterance is less likely to do so. In turn, effective metrics should assign high scores to good utterances and low scores to bad ones.
Paper: https://arxiv.org/pdf/1909.07290.pdf
Code: https://github.com/bnewm0609/comm-eval
#NLP #NLU
Have you ever think that n-gram overlap measures like #BLEU or #ROUGE is not good enough for #NLG evaluation and human based evaluation is too expensive? Researchers from Stanford University also think so. The main shortcoming of #BLEU or #ROUGE methods is that they fail to take into account the communicative function of language; a speaker's goal is not only to produce well-formed expressions, but also to convey relevant information to a listener.
Researchers propose approach based on color reference game. In this game, a speaker and a listener see a set of three colors. The speaker is told one color is the target and tries to communicate the target to the listener using a natural language utterance. A good utterance is more likely to lead the listener to select the target, while a bad utterance is less likely to do so. In turn, effective metrics should assign high scores to good utterances and low scores to bad ones.
Paper: https://arxiv.org/pdf/1909.07290.pdf
Code: https://github.com/bnewm0609/comm-eval
#NLP #NLU
GitHub
GitHub - bnewm0609/comm-eval: Communication-based Evaluation for Natural Language Generation
Communication-based Evaluation for Natural Language Generation - GitHub - bnewm0609/comm-eval: Communication-based Evaluation for Natural Language Generation
What GPT-2 thinks of the future
Link: https://worldin.economist.com/article/17521/edition2020artificial-intelligence-predicts-future
#NLU #NLP #NLG #GPT2
Link: https://worldin.economist.com/article/17521/edition2020artificial-intelligence-predicts-future
#NLU #NLP #NLG #GPT2
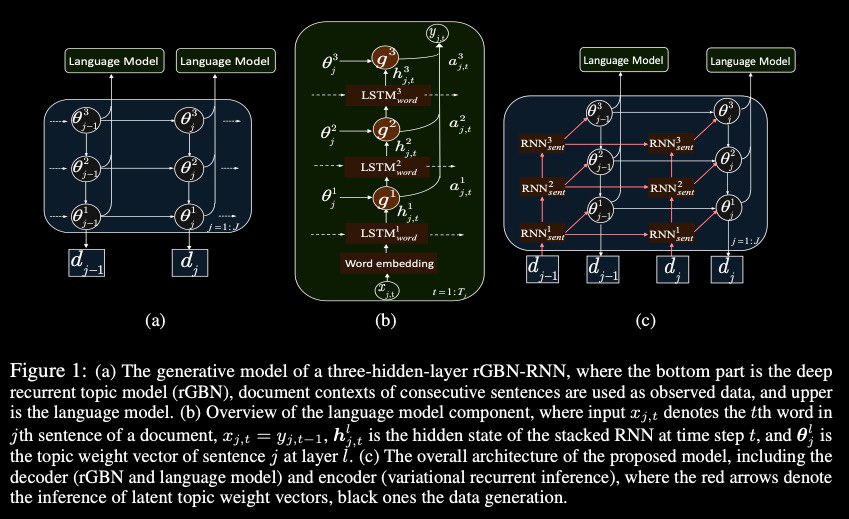
Recurrent Hierarchical Topic-Guided Neural Language Models
The authors propose a recurrent gamma belief network (rGBN) guided neural language modeling framework, a novel method to learn a language model and a deep recurrent topic model simultaneously.
For scalable inference, they develop hybrid SG-MCMC and recurrent autoencoding variational inference, allowing efficient end-to-end training.
Experiments results conducted on real-world corpora demonstrate that the proposed models outperform a variety of shallow-topic-model-guided neural language models, and effectively generate the sentences from the designated multi-level topics or noise while inferring the interpretable hierarchical latent topic structure of the document and hierarchical multiscale structures of sequences.
paper: https://openreview.net/forum?id=Byl1W1rtvH
#ICLR2020 #nlm #nlg
The authors propose a recurrent gamma belief network (rGBN) guided neural language modeling framework, a novel method to learn a language model and a deep recurrent topic model simultaneously.
For scalable inference, they develop hybrid SG-MCMC and recurrent autoencoding variational inference, allowing efficient end-to-end training.
Experiments results conducted on real-world corpora demonstrate that the proposed models outperform a variety of shallow-topic-model-guided neural language models, and effectively generate the sentences from the designated multi-level topics or noise while inferring the interpretable hierarchical latent topic structure of the document and hierarchical multiscale structures of sequences.
paper: https://openreview.net/forum?id=Byl1W1rtvH
#ICLR2020 #nlm #nlg
{kind=link}
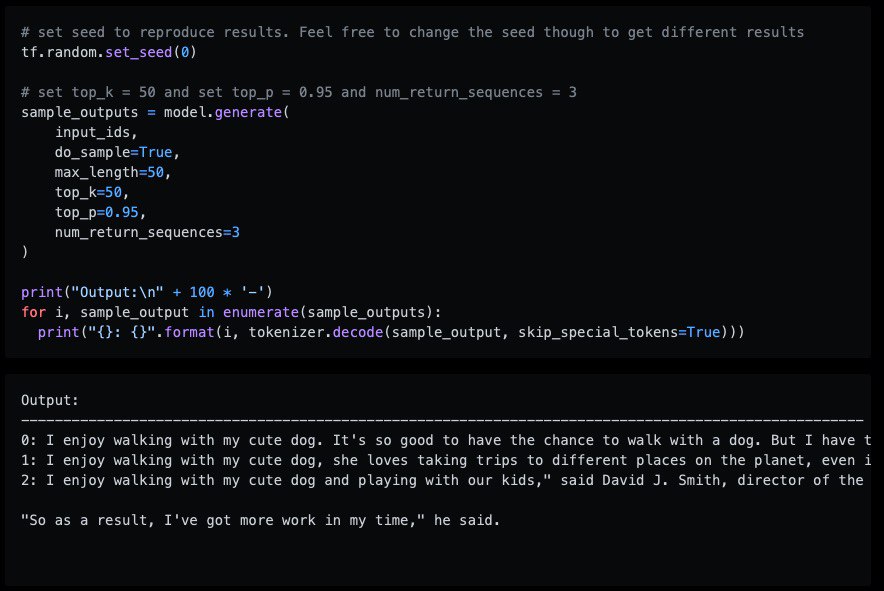
How to generate text: using different decoding methods for language generation with Transformers
by huggingface
in this blog, the author talk about how to generate text and compared some approaches like:
– greedy search
– beam search
– top-K sampling
– top-p (nucleus) sampling
blog post: https://huggingface.co/blog/how-to-generate
#nlp #nlg #transformers
by huggingface
in this blog, the author talk about how to generate text and compared some approaches like:
– greedy search
– beam search
– top-K sampling
– top-p (nucleus) sampling
blog post: https://huggingface.co/blog/how-to-generate
#nlp #nlg #transformers
{kind=link}
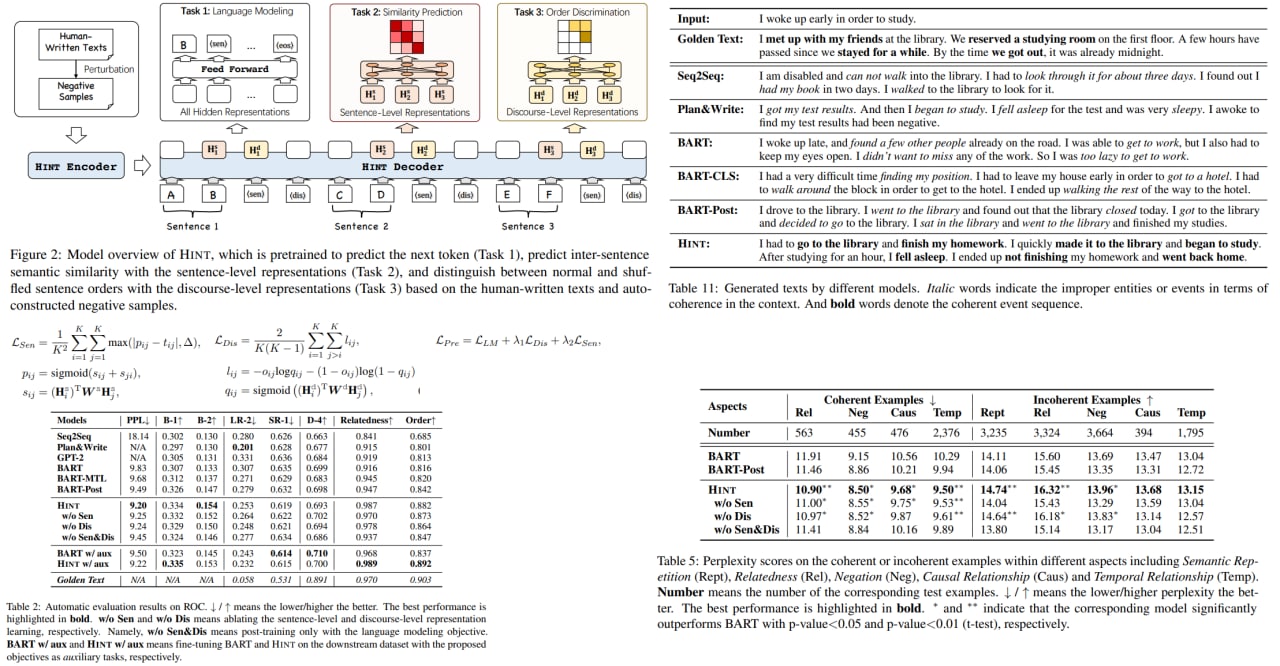
Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues such as story generation. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than state-of-the-art baselines.
Paper: https://arxiv.org/abs/2105.08963
Code: https://github.com/thu-coai/HINT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hint
#deeplearning #nlp #nlg #pretraining
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues such as story generation. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than state-of-the-art baselines.
Paper: https://arxiv.org/abs/2105.08963
Code: https://github.com/thu-coai/HINT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hint
#deeplearning #nlp #nlg #pretraining
{kind=link}