
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
High-quality #speechrecognition systems require large amounts of data—yet many languages have little data available. Check out new research into an end-to-end system trained as a single model allowing for real-time multilingual speech recognition.
Link: https://ai.googleblog.com/2019/09/large-scale-multilingual-speech.html
#speech #audio #DL #Google
High-quality #speechrecognition systems require large amounts of data—yet many languages have little data available. Check out new research into an end-to-end system trained as a single model allowing for real-time multilingual speech recognition.
Link: https://ai.googleblog.com/2019/09/large-scale-multilingual-speech.html
#speech #audio #DL #Google
Googleblog
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
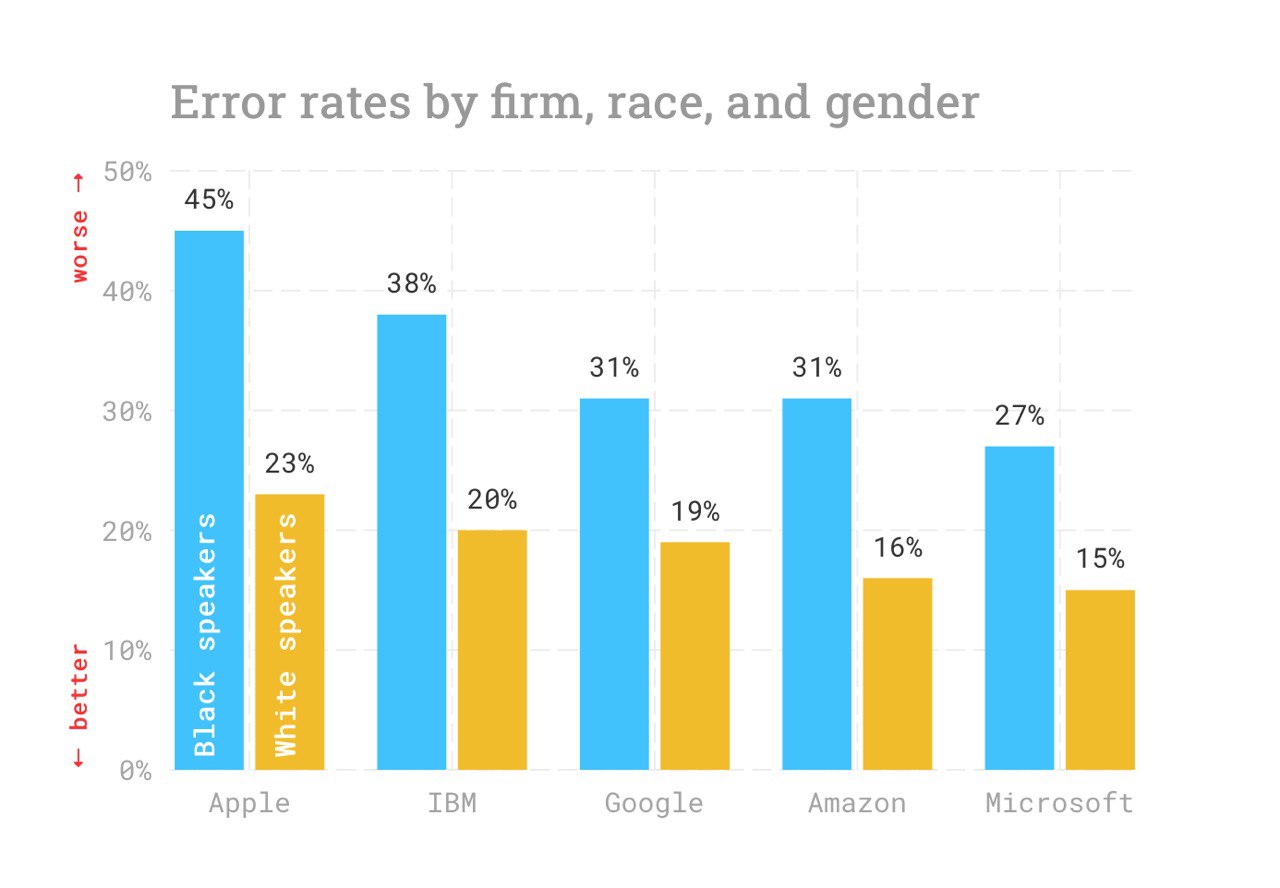
Racial Disparities in Automated Speech Recognition
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
To no surprise, speech recognition tools have #bias due to the lack of diversity in the datasets. Group of explorers addressed that issue and provided their’s research results as a paper and #reproducible research repo.
Project link: https://fairspeech.stanford.edu
Paper: https://www.pnas.org/cgi/doi/10.1073/pnas.1915768117
Github: https://github.com/stanford-policylab/asr-disparities
#speechrecognition #voice #audiolearning #dl #microsoft #google #apple #ibm #amazon
{kind=link}
S2IGAN — Speech-to-Image Generation via Adversarial Learning
Authors present a framework that translates speech to images bypassing text information, thus allowing unwritten languages to potentially benefit from this technology.
ArXiV: https://arxiv.org/abs/2005.06968
Project: https://xinshengwang.github.io/project/s2igan/
#DL #audiolearning #speechrecognition
Authors present a framework that translates speech to images bypassing text information, thus allowing unwritten languages to potentially benefit from this technology.
ArXiV: https://arxiv.org/abs/2005.06968
Project: https://xinshengwang.github.io/project/s2igan/
#DL #audiolearning #speechrecognition
王新升
S2IGAN | 王新升
A framework that translates speech descriptions to photo-realistic images without using any text information.
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
MMS: Scaling Speech Technology to 1000+ languages
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
Get ready for a breakthrough in speech technology that is set to revolutionize the world of communication! The field, which has so far been restricted to around a hundred languages, barely scratches the surface of the more than 7,000 languages spoken globally. The Massively Multilingual Speech (MMS) project is taking a monumental leap to bridge this gap, increasing the number of supported languages by an astounding 10 to 40 times, depending on the task. This unprecedented expansion will be a game-changer, significantly improving global access to information and creating a more inclusive digital landscape.
This incredible feat is achieved through the creation of a new dataset drawn from publicly available religious texts and the strategic implementation of self-supervised learning. The MMS project's achievements are staggering, including the development of pre-trained wav2vec 2.0 models for 1,406 languages, a single multilingual automatic speech recognition model for 1,107 languages, speech synthesis models for as many languages, and a language identification model for a whopping 4,017 languages. Even more impressive is the significant improvement in accuracy - our multilingual speech recognition model more than halves the word error rate of Whisper on 54 languages of the FLEURS benchmark, despite being trained on a significantly smaller dataset.
Paper link: https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
Blogpost link: https://ai.facebook.com/blog/multilingual-model-speech-recognition/
Code link: https://github.com/facebookresearch/fairseq/tree/main/examples/mms
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mms
#deeplearning #speechrecognition #tts #audio
{kind=link}