
Episodic Memory in Lifelong Language Learning
tl;dr – the model needs to learn from a stream of text examples without any dataset identifier.
The authors propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay & local adaptation to allow the model to continuously learn from new datasets.
Also, they show that the space complexity of the episodic memory module can be reduced significantly (∼50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. They consider an episodic memory component as a crucial building block of general linguistic intelligence and see the model as the first step in that direction.
paper: https://arxiv.org/abs/1906.01076
#nlp #bert #NeurIPSConf19
tl;dr – the model needs to learn from a stream of text examples without any dataset identifier.
The authors propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay & local adaptation to allow the model to continuously learn from new datasets.
Also, they show that the space complexity of the episodic memory module can be reduced significantly (∼50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. They consider an episodic memory component as a crucial building block of general linguistic intelligence and see the model as the first step in that direction.
paper: https://arxiv.org/abs/1906.01076
#nlp #bert #NeurIPSConf19
{kind=link}
Open invitation to student Olympiad
IT students from all over the world are invited to participate in Digital Economy International Olympiad held in Russia from January to March 2020. First two stages will held online via Stepik platform and finalists will go to Moscow at the expense of organizers to participate in the final stage and award ceremony!
Winners will be preferentially enrolled in the top Russian Universities and get job-offers from the best IT-companies.
Nominations include:
- Neurotechnology and artificial intelligence
- Data science
- Big data
- Parts of robotics and sensors
Link: https://olymp.digitaleconomy.world/index_en.html
IT students from all over the world are invited to participate in Digital Economy International Olympiad held in Russia from January to March 2020. First two stages will held online via Stepik platform and finalists will go to Moscow at the expense of organizers to participate in the final stage and award ceremony!
Winners will be preferentially enrolled in the top Russian Universities and get job-offers from the best IT-companies.
Nominations include:
- Neurotechnology and artificial intelligence
- Data science
- Big data
- Parts of robotics and sensors
Link: https://olymp.digitaleconomy.world/index_en.html
What we learned from NeurIPS 2019 data
x4 growth since 2014
21.6% acceptance rate
Takeaways:
1. No free-loader problem: Relatively few papers are submitted where none of the authors invited to participate in the review process accepted the invitation
2. Unclear how to rapidly filter papers prior to full review: Allowing for early desk rejects by ACs is unlikely to have a significant impact on reviewer load without producing inappropriate decisions. Likewise, the eagerness of reviewers to review a particular paper is not a strong signal, either.
3. No clear evidence that review quality as measured by length is lower for NeurIPS: NeurIPS is surprisingly not much different from other conferences of smaller sizes when it comes to review length.
4. Impact of engagement in rebuttal/discussion period: Overall engagement seemed to be higher than in 2018.
#Nips #NeurIPS #NIPS2019 #conference #meta
x4 growth since 2014
21.6% acceptance rate
Takeaways:
1. No free-loader problem: Relatively few papers are submitted where none of the authors invited to participate in the review process accepted the invitation
2. Unclear how to rapidly filter papers prior to full review: Allowing for early desk rejects by ACs is unlikely to have a significant impact on reviewer load without producing inappropriate decisions. Likewise, the eagerness of reviewers to review a particular paper is not a strong signal, either.
3. No clear evidence that review quality as measured by length is lower for NeurIPS: NeurIPS is surprisingly not much different from other conferences of smaller sizes when it comes to review length.
4. Impact of engagement in rebuttal/discussion period: Overall engagement seemed to be higher than in 2018.
#Nips #NeurIPS #NIPS2019 #conference #meta
{kind=link}
Low-variance Black-box Gradient Estimates for the Plackett-Luce Distribution
The authors consider models with #latent #permutations and propose control variates for the #PlackettLuce distribution. In particular, the control variates allow them to optimize #blackBox functions over permutations using stochastic gradient descent. To illustrate the approach, they consider a variety of causal structure learning tasks for continuous and discrete data.
They show that the method outperforms competitive relaxation-based optimization methods and is also applicable to non-differentiable score functions.
paper: https://arxiv.org/abs/1911.10036
tweet: https://twitter.com/bayesgroup/status/1199023536653950976?s=20
The authors consider models with #latent #permutations and propose control variates for the #PlackettLuce distribution. In particular, the control variates allow them to optimize #blackBox functions over permutations using stochastic gradient descent. To illustrate the approach, they consider a variety of causal structure learning tasks for continuous and discrete data.
They show that the method outperforms competitive relaxation-based optimization methods and is also applicable to non-differentiable score functions.
paper: https://arxiv.org/abs/1911.10036
tweet: https://twitter.com/bayesgroup/status/1199023536653950976?s=20
{kind=link}
Football performance modelling in python
An article with football game outcome analysis in #jupyter.
One of the key features to predict a football game turned out to be the best attacking player even though "A ferocious scream from the stands, a mistaken whistle from the ref’, or the shrimps on the lunch menu may jeopardise the whole outcome of the match."
Authors also highlighted improtance of amplitude of persistence diagrams as a key feature.
This is a suggested by the channel readers material. Don’t forget to thank them by giving claps 👏 on Medium and starring repository if you found a code useful.
Link: https://towardsdatascience.com/the-shape-of-football-games-1589dc4e652a
Code: https://github.com/giotto-ai/football-tda
#football #soccer #betting #readersmaterial
An article with football game outcome analysis in #jupyter.
One of the key features to predict a football game turned out to be the best attacking player even though "A ferocious scream from the stands, a mistaken whistle from the ref’, or the shrimps on the lunch menu may jeopardise the whole outcome of the match."
Authors also highlighted improtance of amplitude of persistence diagrams as a key feature.
This is a suggested by the channel readers material. Don’t forget to thank them by giving claps 👏 on Medium and starring repository if you found a code useful.
Link: https://towardsdatascience.com/the-shape-of-football-games-1589dc4e652a
Code: https://github.com/giotto-ai/football-tda
#football #soccer #betting #readersmaterial
Medium
The shape of football games
Modelling the outcome of football matches using player characteristics and topological data analysis
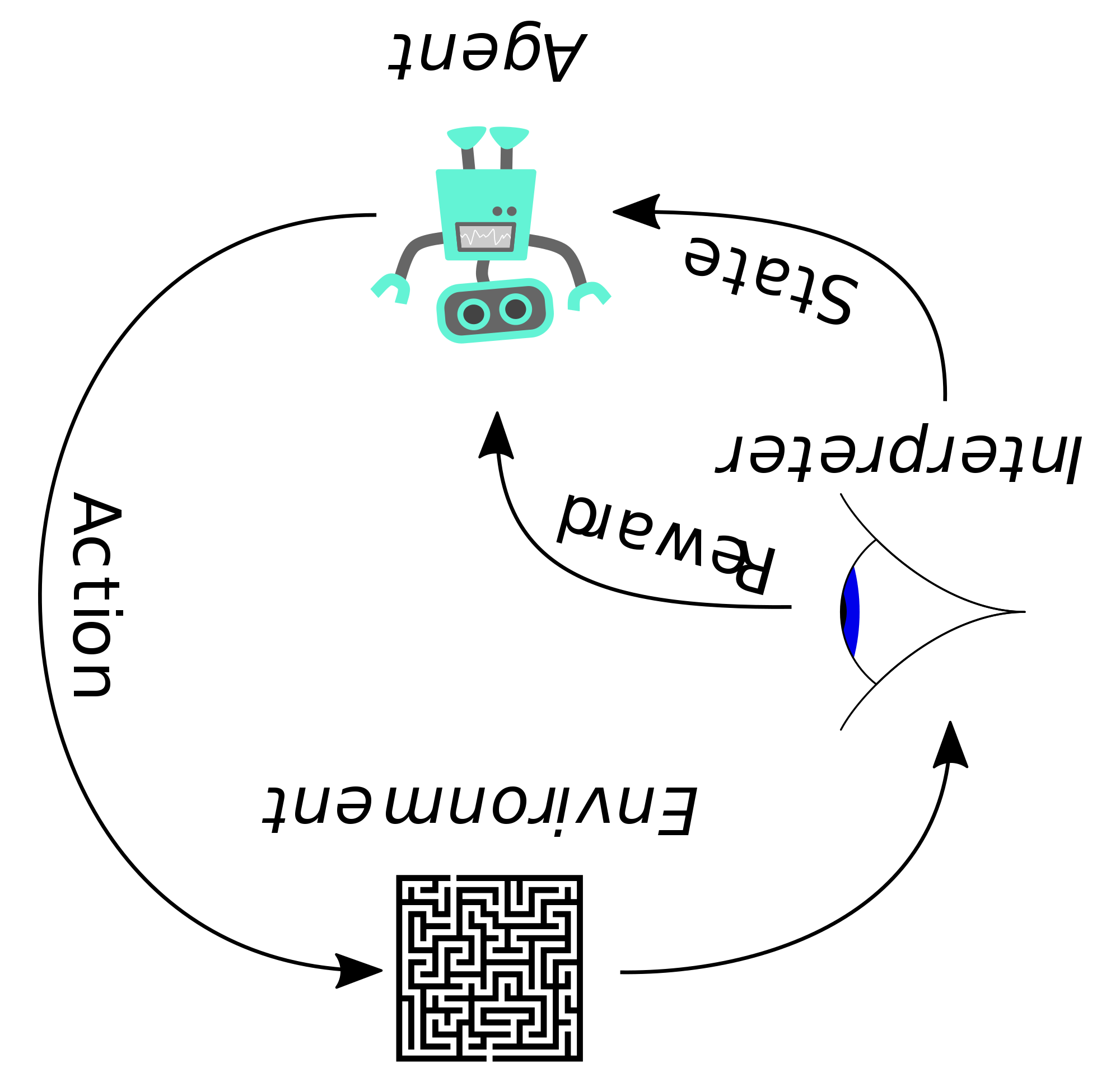
Reinforcement Learning Upside Down: Don't Predict Rewards – Just Map Them to Actions by Juergen Schmidhuber
Traditional #RL predicts rewards and uses a myriad of methods for translating those predictions into good actions. ꓶꓤ shortcuts this process, creating a direct mapping from rewards, time horizons and other inputs to actions.
Without depending on reward predictions, and without explicitly maximizing expected rewards, ꓶꓤ simply learn by gradient descent to map task specifications or commands (such as: get lots of reward within little time) to action probabilities. Its success depends on the generalization abilities of deep/recurrent neural nets. Its potential drawbacks are essentially those of traditional gradient-based learning: local minima, underfitting, overfitting, etc.
Nevertheless, experiments in a separate paper show that even them initial pilot version of ꓶꓤ can outperform traditional RL methods on certain challenging problems.
A closely related Imitate-Imitator approach is to imitate a robot, then let it learn to map its observations of the imitated behavior to its own behavior, then let it generalize, by demonstrating something new, to be imitated by the robot.
more at paper: https://arxiv.org/abs/1912.02875
Traditional #RL predicts rewards and uses a myriad of methods for translating those predictions into good actions. ꓶꓤ shortcuts this process, creating a direct mapping from rewards, time horizons and other inputs to actions.
Without depending on reward predictions, and without explicitly maximizing expected rewards, ꓶꓤ simply learn by gradient descent to map task specifications or commands (such as: get lots of reward within little time) to action probabilities. Its success depends on the generalization abilities of deep/recurrent neural nets. Its potential drawbacks are essentially those of traditional gradient-based learning: local minima, underfitting, overfitting, etc.
Nevertheless, experiments in a separate paper show that even them initial pilot version of ꓶꓤ can outperform traditional RL methods on certain challenging problems.
A closely related Imitate-Imitator approach is to imitate a robot, then let it learn to map its observations of the imitated behavior to its own behavior, then let it generalize, by demonstrating something new, to be imitated by the robot.
more at paper: https://arxiv.org/abs/1912.02875
{kind=link}
NeurIPS slides and presentations link
Link: https://slideslive.com/neurips/
Brief paper overview videos: https://nips.cc/Conferences/2019/Videos
#NeurIPS #NIPS #NIPS2019
Link: https://slideslive.com/neurips/
Brief paper overview videos: https://nips.cc/Conferences/2019/Videos
#NeurIPS #NIPS #NIPS2019
SlidesLive
NeurIPS
Neural Information Processing Systems (NeurIPS) is a multi-track machine learning and computational neuroscience conference that includes invited talks, demonstrations, symposia and oral and poster presentations of refereed papers. Following the conference…
🏆 Moscow ML Trainings meetup on the 14th of December
ML Trainings are based on Kaggle and other platform competitions and are held regularly with free attendance. Winners and top-performing participants discuss competition tasks, share their solutions, and results.
Program and the registration link - https://pao-megafon--org.timepad.ru/event/1137770/
* Note: the first talk will be in English and the rest will be in Russian
ML Trainings are based on Kaggle and other platform competitions and are held regularly with free attendance. Winners and top-performing participants discuss competition tasks, share their solutions, and results.
Program and the registration link - https://pao-megafon--org.timepad.ru/event/1137770/
* Note: the first talk will be in English and the rest will be in Russian
Not Enough Data? Deep Learning to the Rescue!
The authors use a powerful pre-trained #NLP NN model to artificially synthesize new #labeled #data for #supervised learning. They mainly focus on cases with scarce labeled data. Their method referred to as language-model-based data augmentation (#LAMBADA), involves fine-tuning a SOTA language generator to a specific task through an initial training phase on the existing (usually small) labeled data.
Using the fine-tuned model and given a class label, new sentences for the class are generated. Then they filter these new sentences by using a classifier trained on the original data.
In a series of experiments, they show that LAMBADA improves classifiers performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the SOTA techniques for data augmentation, specifically those applicable to text classification tasks with little data.
paper: https://arxiv.org/abs/1911.03118
The authors use a powerful pre-trained #NLP NN model to artificially synthesize new #labeled #data for #supervised learning. They mainly focus on cases with scarce labeled data. Their method referred to as language-model-based data augmentation (#LAMBADA), involves fine-tuning a SOTA language generator to a specific task through an initial training phase on the existing (usually small) labeled data.
Using the fine-tuned model and given a class label, new sentences for the class are generated. Then they filter these new sentences by using a classifier trained on the original data.
In a series of experiments, they show that LAMBADA improves classifiers performance on a variety of datasets. Moreover, LAMBADA significantly improves upon the SOTA techniques for data augmentation, specifically those applicable to text classification tasks with little data.
paper: https://arxiv.org/abs/1911.03118
{kind=link}
Media is too big
VIEW IN TELEGRAM
StyleGANv2 🎉:
- significantly better samples (better FID scores & reduced artifacts)
- no more progressive growing
- improved Style-mixing
- smoother interpolations (extra regularization)
- faster training
paper: https://arxiv.org/abs/1912.04958
code: https://github.com/NVlabs/stylegan2
origin video: https://www.youtube.com/watch?v=c-NJtV9Jvp0&feature=emb_logo
- significantly better samples (better FID scores & reduced artifacts)
- no more progressive growing
- improved Style-mixing
- smoother interpolations (extra regularization)
- faster training
paper: https://arxiv.org/abs/1912.04958
code: https://github.com/NVlabs/stylegan2
origin video: https://www.youtube.com/watch?v=c-NJtV9Jvp0&feature=emb_logo
AR-Net: A simple autoregressive NN for #timeSeries
AR-Net, has 2 distinct advantages over its traditional counterpart:
* scales well to large orders, making it possible to estimate long-range dependencies (important in high-resolution monitoring applications, such as those in the data center domain);
* automatically selects and estimates the important coefficients of a sparse AR process, eliminating the need to know the true order of the AR process
To overcome the scalability challenge, they train a NN with #SGD to learn the AR (#autoregression) coefficients. AR-Net effectively learns near-identical weights as classic AR implementations & is equally good at predicting the next value of the time series.
Also, AR-Net automatically learns the relevant weights, even if the underlying data is generated by a noisy & extremely sparse AR process.
blog: https://ai.facebook.com/blog/ar-net-a-simple-autoregressive-neural-network-for-time-series/
paper: https://arxiv.org/abs/1911.03118
AR-Net, has 2 distinct advantages over its traditional counterpart:
* scales well to large orders, making it possible to estimate long-range dependencies (important in high-resolution monitoring applications, such as those in the data center domain);
* automatically selects and estimates the important coefficients of a sparse AR process, eliminating the need to know the true order of the AR process
To overcome the scalability challenge, they train a NN with #SGD to learn the AR (#autoregression) coefficients. AR-Net effectively learns near-identical weights as classic AR implementations & is equally good at predicting the next value of the time series.
Also, AR-Net automatically learns the relevant weights, even if the underlying data is generated by a noisy & extremely sparse AR process.
blog: https://ai.facebook.com/blog/ar-net-a-simple-autoregressive-neural-network-for-time-series/
paper: https://arxiv.org/abs/1911.03118
ProteinNet: a standardized data set for machine learning of protein structure
Link: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-019-2932-0
Github: https://github.com/aqlaboratory/proteinnet
#biolearning #medical #dl
Link: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-019-2932-0
Github: https://github.com/aqlaboratory/proteinnet
#biolearning #medical #dl
BioMed Central
ProteinNet: a standardized data set for machine learning of protein structure - BMC Bioinformatics
Background Rapid progress in deep learning has spurred its application to bioinformatics problems including protein structure prediction and design. In classic machine learning problems like computer vision, progress has been driven by standardized data sets…
The 2019 AI Index report!
Stanford University Human-Centered Artificial Intelligence released an annual report about the state of #AI this year. 160 pages of text with various metrics and measurements. Good to read with a cup of coffee ;)
TL;DR by TheVerge in the picture but inside report more interesting!
site of the report: https://hai.stanford.edu/ai-index/2019
Stanford University Human-Centered Artificial Intelligence released an annual report about the state of #AI this year. 160 pages of text with various metrics and measurements. Good to read with a cup of coffee ;)
TL;DR by TheVerge in the picture but inside report more interesting!
site of the report: https://hai.stanford.edu/ai-index/2019
{kind=link}
A Deep Neural Network's Loss Surface Contains Every Low-dimensional Pattern
New work from #DeepMind built in top of Loss Landscape Sightseeing with Multi-Point Optimization
ArXiV: https://arxiv.org/abs/1912.07559
Predecessor’s github: https://github.com/universome/loss-patterns
New work from #DeepMind built in top of Loss Landscape Sightseeing with Multi-Point Optimization
ArXiV: https://arxiv.org/abs/1912.07559
Predecessor’s github: https://github.com/universome/loss-patterns