
Machine Learning for Everyone.
The best general intro post about Machine Learning, covering everything you need to know not to get overxcited about SkyNet and to get general understanding of all #ML / #AI hype. You can surely save this post into «Saved messages» and forward it to your friends to make them familiar with the subject
Link: https://vas3k.com/blog/machine_learning/
#entrylevel #novice #general
The best general intro post about Machine Learning, covering everything you need to know not to get overxcited about SkyNet and to get general understanding of all #ML / #AI hype. You can surely save this post into «Saved messages» and forward it to your friends to make them familiar with the subject
Link: https://vas3k.com/blog/machine_learning/
#entrylevel #novice #general
Vas3K
Machine Learning for Everyone
None
Using AI to balance a card game on the example of Hearthstone
Hearthstone — complex CCG by Blizzard with hundreds of cards. Paper is about balancing the game through multiobjective evolutionary algorithms. Authors show how to rebalance the game while making minimal card changes.
Link: https://arxiv.org/abs/1907.01623
#AI #Blizzard #Hearthstone #balance #linearprogramming #ccg
Hearthstone — complex CCG by Blizzard with hundreds of cards. Paper is about balancing the game through multiobjective evolutionary algorithms. Authors show how to rebalance the game while making minimal card changes.
Link: https://arxiv.org/abs/1907.01623
#AI #Blizzard #Hearthstone #balance #linearprogramming #ccg
{kind=link}
Critics: AI competitions don’t produce useful models
Post, suggesting a viewpoint that AI competitions never seem to lead to products, how the one can overfit on a hold out test set, and why #Imagenet results since the mid-2010s are suspect.
Link: https://lukeoakdenrayner.wordpress.com/2019/09/19/ai-competitions-dont-produce-useful-models/
#critics #meta #AI #kaggle #imagenet #lenet
Post, suggesting a viewpoint that AI competitions never seem to lead to products, how the one can overfit on a hold out test set, and why #Imagenet results since the mid-2010s are suspect.
Link: https://lukeoakdenrayner.wordpress.com/2019/09/19/ai-competitions-dont-produce-useful-models/
#critics #meta #AI #kaggle #imagenet #lenet
Luke Oakden-Rayner
AI competitions don’t produce useful models
Ai competitions are fun, community building, talent scouting, brand promoting, and attention grabbing. But competitions are not intended to develop useful models.
The 2019 AI Index report!
Stanford University Human-Centered Artificial Intelligence released an annual report about the state of #AI this year. 160 pages of text with various metrics and measurements. Good to read with a cup of coffee ;)
TL;DR by TheVerge in the picture but inside report more interesting!
site of the report: https://hai.stanford.edu/ai-index/2019
Stanford University Human-Centered Artificial Intelligence released an annual report about the state of #AI this year. 160 pages of text with various metrics and measurements. Good to read with a cup of coffee ;)
TL;DR by TheVerge in the picture but inside report more interesting!
site of the report: https://hai.stanford.edu/ai-index/2019
{kind=link}
AI Career Pathways: Put Yourself on the Right Track
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
{kind=link}
Martin Calvino's AI-inspired art is such an evoking meta-narrative of "art imitating tech imitating art"
https://www.martincalvino.co/paintings
#ai #art #abstract
https://www.martincalvino.co/paintings
#ai #art #abstract
{kind=link}
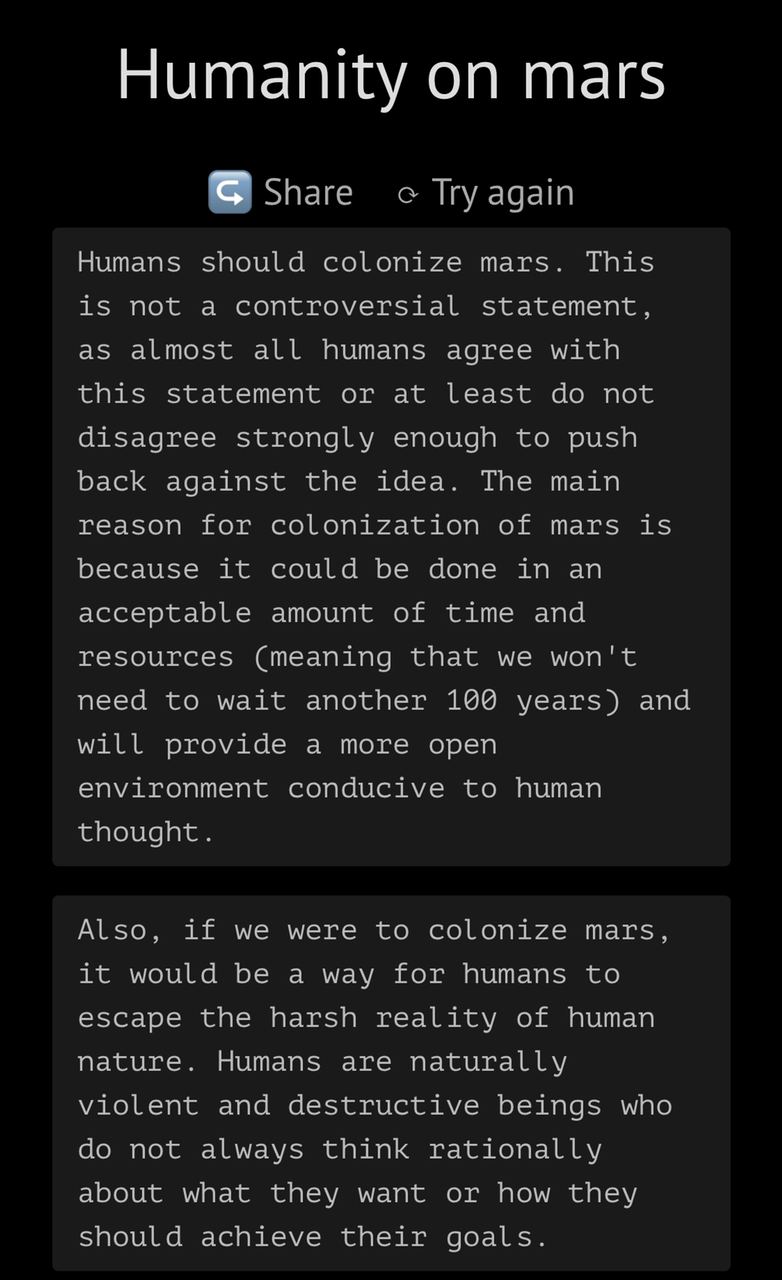
Philosopher AI — website to generate text with #GPT3
Tool to generate text on different topics. Sensible topics such as sex, religion or even nationality are blocked.
Great way to spread the awareness on #ai and to show nontechnical friends that #Skynet is not a problem to be concerned with yet.
Website: https://philosopherai.com/philosopher/humanity-on-mars-73ac00
#nlu #nlp
Tool to generate text on different topics. Sensible topics such as sex, religion or even nationality are blocked.
Great way to spread the awareness on #ai and to show nontechnical friends that #Skynet is not a problem to be concerned with yet.
Website: https://philosopherai.com/philosopher/humanity-on-mars-73ac00
#nlu #nlp
{kind=link}
State of AI Report 2022 - ONLINE.pdf
22.9 MB
State of AI Report 2022
TLDR: We are moving forward and effective international collaboration is the key to progress.
Major Themes:
* New independent research labs are rapidly open sourcing the closed source output of major labs
* Safety is gaining awareness among major AI research entities
* The China-US AI research gap has continued to widen
* AI-driven scientific research continues to lead to breakthroughs
Website: https://www.stateof.ai
#report #stateofai #AI
TLDR: We are moving forward and effective international collaboration is the key to progress.
Major Themes:
* New independent research labs are rapidly open sourcing the closed source output of major labs
* Safety is gaining awareness among major AI research entities
* The China-US AI research gap has continued to widen
* AI-driven scientific research continues to lead to breakthroughs
Website: https://www.stateof.ai
#report #stateofai #AI
Forwarded from Kirill from TOP
Some might have wondered what application will #Midjourney and #ChatGPT have.
What products will creators to build with them?
Here is one of examples of such human-AI collaboration — short illustrated story on TikTok having millions of views.
https://vt.tiktok.com/ZS8MENP51/
#AI_tools
What products will creators to build with them?
Here is one of examples of such human-AI collaboration — short illustrated story on TikTok having millions of views.
https://vt.tiktok.com/ZS8MENP51/
#AI_tools
Left picture is one generated by #Midjourney with a
Right one was generated with a
Looks like Midjourney is not aware of concept of distributions yet.
#AI #AGI #vizualization
bell curve with mu = 18 sigma = 4 request.Right one was generated with a
bell curve with mu = 18 sigma = 1 request.Looks like Midjourney is not aware of concept of distributions yet.
#AI #AGI #vizualization
Forwarded from Kirill from TOP
GPT-3 for self-therapy
Just came across an interesting article about using #GPT-3 to analyze past journal entries and summarize therapy sessions for gaining new perspectives on personal struggles. Dan Shipper loaded person journal into the neural network so he could ask different questions, including asking about his own Myers-Briggs personality type (INTJ for those who wondered).
It's a powerful example of how AI tools can help individuals become more productive, effective, and happy. As we continue to see the integration of #AI in various industries, it's important for modern blue collar workers to learn how to properly work with these tools in order to stay at the peak of efficiency.
Let's embrace the future and learn to use AI to our advantage rather than to spread FUD about AI replacing workforce. It won’t but it will enable some people to achieve more and be way more productive.
Link: https://every.to/chain-of-thought/can-gpt-3-explain-my-past-and-tell-me-my-future
#aiusecase #toolsnotactors
Just came across an interesting article about using #GPT-3 to analyze past journal entries and summarize therapy sessions for gaining new perspectives on personal struggles. Dan Shipper loaded person journal into the neural network so he could ask different questions, including asking about his own Myers-Briggs personality type (INTJ for those who wondered).
It's a powerful example of how AI tools can help individuals become more productive, effective, and happy. As we continue to see the integration of #AI in various industries, it's important for modern blue collar workers to learn how to properly work with these tools in order to stay at the peak of efficiency.
Let's embrace the future and learn to use AI to our advantage rather than to spread FUD about AI replacing workforce. It won’t but it will enable some people to achieve more and be way more productive.
Link: https://every.to/chain-of-thought/can-gpt-3-explain-my-past-and-tell-me-my-future
#aiusecase #toolsnotactors
ReBotNet: Fast Real-time Video Enhancement
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
{kind=link}
🔥 Say Goodbye to LoRA, Hello to DoRA 🤩🤩
DoRA consistently outperforms LoRA with various tasks (LLM, LVLM, etc.) and backbones (LLaMA, LLaVA, etc.)
[Paper] https://arxiv.org/abs/2402.09353
[Code] https://github.com/NVlabs/DoRA
#Nvidia
#icml #PEFT #lora #ML #ai
@opendatascience
DoRA consistently outperforms LoRA with various tasks (LLM, LVLM, etc.) and backbones (LLaMA, LLaVA, etc.)
[Paper] https://arxiv.org/abs/2402.09353
[Code] https://github.com/NVlabs/DoRA
#Nvidia
#icml #PEFT #lora #ML #ai
@opendatascience
Forwarded from Machinelearning
FoleyCrafter - методика, разработанная для автоматического создания звуковых эффектов, синхронизированных с целевым видеорядом
Архитектура метода построена на основе предварительно обученной модели преобразования текста в аудио (Text2Audio). Система состоит из двух ключевых компонентов:
Оба компонента являются обучаемыми модулями, которые принимают видео в качестве входных данных для синтеза аудио. При этом модель Text2Audio остается фиксированной для сохранения ее способности к синтезу аудио постоянного качества.
Разработчики FoleyCrafter провели количественные и качественные эксперименты на наборах данных VGGSound и AVSync15 по метрикам семантического соответствия MKL, CLIP Score, FID и временной синхронизации Onset ACC, Onset AP.
По сравнению с существующими методами Text2Audio (SpecVQGAN, Diff-Foley и V2A-Mapper) FoleyCrafter показал лучшие результаты.
# Clone the Repository
git clone https://github.com/open-mmlab/foleycrafter.git
# Navigate to the Repository
cd projects/foleycrafter
# Create Virtual Environment with Conda & Install Dependencies
conda create env create -f requirements/environment.yaml
conda activate foleycrafter
# Install GiT LFS
conda install git-lfs
git lfs install
# Download checkpoints
git clone https://huggingface.co/auffusion/auffusion-full-no-adapter checkpoints/auffusion
git clone https://huggingface.co/ymzhang319/FoleyCrafter checkpoints/
# Run Gradio
python app.py --share
🔗 Лицензирование: Apache-2.0
🔗Страница проекта
🔗Arxiv
🔗Модели на HF
🔗Demo
🔗Github [ Stars: 272 | Issues: 4 | Forks: 15]
@ai_machinelearning_big_data
#AI #Text2Audio #FoleyCrafter #ML
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
ControlNet++ - это набор моделей ControlNet, собранный на новой архитектуре и упакованный в один единый файл без необходимости скачивать дополнительные препроцессоры и наборы моделей.
Обновление ProMaх включает в себя весь существующий набор ControlNet Union, в который были добавлены возможности комбинации нескольких типов ControlNet к одному исходному изображению и новые функции Tile Deblur, Tile Superresolution, Tile Variation, Inpaint и Outpaint.
C учетом обновления, набор ControlNet ProMax выполняет 12 функций и 5 дополнительных методик редактирования изображений:
В архитектуре ControlNet++ были разработаны два новых модуля: Condition Transformer и Control Encoder, которые улучшают представление и обработку условий в модели.
Каждому условию назначается уникальный идентификатор типа управления, который преобразуется в эмбеддинги.
Condition Transformer позволяет обрабатывать несколько условий одновременно, используя один кодировщик и включает слой трансформера для обмена информацией между исходным изображением и условными изображениями.
Condition Encoder увеличивает количество каналов свертки для повышения представительной способности, сохраняя оригинальную архитектуру.
Также была использована единая стратегия обучения, которая одновременно оптимизировала сходимость для одиночных условий и управляла слиянием множественных условий, повышая устойчивость сети и ее способность к генерации качественных изображений.
ControlNet Pro Max поддерживает работу с любой генеративной моделью семейства Stable Diffusion XL. Поддержка семейства Stable Diffusion 3 находится в разработке.
@ai_machinelearning_big_data
#AI #ControlNet #ML #Diffusers #SDXL
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
Qwen2-Audio - аудио-языковых модель, которая способна принимать аудио и текст на вход и генерировать текст на выходе.
Предусмотрено два режима взаимодействия:
Обе опубликованные модели поддерживают 8 языков и диалектов: китайский, английский, кантонский, французский, итальянский, испанский, немецкий и японский:
Инференс на transformers в cli возможен в нескольких режимах:
# Ensure you have latest Hugging face transformers
pip install git+https://github.com/huggingface/transformers
# to build a web UI demoinstall the following packages
pip install -r requirements_web_demo.txt
# run Gradio web UI
python demo/web_demo_audio.py
@ai_machinelearning_big_data
#AI #LLM #ML #Qwen2
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
В Яндексе подробно рассказали про новую технологию, которую стали использовать в Яндекс Погоде. OmniCast работает на основе нейросетей, которые рассчитывают температуру воздуха, учитывая множество факторов, в том числе один совершенно новый — любительские метеостанции.
OmniCast помогает решать проблему точности прогноза в разных локальных районах мегаполисов. Подробнее про то, как работает метод, написано в статье.
▪️Хабр
@ai_machinelearning_big_data
#AI #ML #OmniCast
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
PuLID (Pure and Lightning ID Customization) - метод генерации на основе внешности для диффузных моделей с управлением текстовым промптом. Ключевое преимущество PuLID состоит в его способности генерировать изображения с высокой степенью соответствия заданной личности, следуя заданным стилю и композиции.
PuLID для SD существует относительно давно и неплохо работал с моделями SDXL. Теперь этот метод стал доступен для FLUX-dev:
--aggressive_offload, но генерация будет выполняться очень, очень, очень медленно.В PuLID for FLUX есть два критически важных гиперпараметра:
timestep to start inserting ID. Этот параметр управляет там, в какой момент ID (лицо с входного изображения) будет вставлен в DIT (значение 0 - ID будет вставляться с первого шага). Градация: чем меньше значение - тем более похожим на исходный портрет будет результат. Рекомендованное значение для фотореализма - 4.true CFG scale. Параметр, модулирующий CFG-значение. Исходный процесс CFG метода PuLID, который требовал удвоенного количества этапов вывода, преобразован в шкалу управления чтобы имитировать истинный процесс CFG с половиной шагов инференса.Для возможности гибкой настройки результатов, разработчик оставил оба гиперпараметра : CFG FLUX и true CFG scale. Фотореализм получается лучше с применением true CFG scale, но если финальное сходство внешности с оригиналом не устраивает - вы можете перейти на обычный CFG.
Запуск возможен несколькими способами: GradioUI, Google Collab (free tier), Google Collab (pro tier) или с одним из имплементаций для среды ComfyUI:
⚠️ Важно!
# clone PuLID repo
git clone https://github.com/ToTheBeginning/PuLID.git
cd PuLID
# create conda env
conda create --name pulid python=3.10
# activate env
conda activate pulid
# Install dependent packages
# 1. For SDXL or Flux-bf16, install the following
pip install -r requirements.txt
# 2. For Flux-fp8, install this
pip install -r requirements_fp8.txt
# Run Gradio UI
python app.py
@ai_machinelearning_big_data
#AI #ML #FLUX #GenAI #PuLID
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
В Google рассказали про схему итеративного взвешивания плотности (iterative density weighting scheme, IDW), которая помогает равномерно распределять интересы пользователя.
Она уменьшает влияние дисбалансированных данных и улучшает кластеризацию элементов, анализируя плотность предметов в пространстве представлений.
В подробном разборе статьи от ml-спецов Яндекса рассказали про устройство IDW и кратко привели результаты эксперимента.
@ai_machinelearning_big_data
#AI #ML #tech
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM