
If you happen to be in Moscow in the next couple of weeks, we invite you to take part in Moscow Data Science Major on August 31st at Mail.ru Group office!
It’s like OpenDataScience’s Data Fest, but a mini version (in terms of duration, not content density). It’s like 1st of October, but 31st of August.
MDSM gather all researchers, engineers and developers around Data Science and Machine Learning:
- Top speakers and talks, zero bullshit
- Lots of new insights, skills and know-hows
- Best networking with the community
Link: https://datafest.ru/major/
Registration link: https://corp.mail.ru/ru/press/events/mdsm_aug19/
It’s like OpenDataScience’s Data Fest, but a mini version (in terms of duration, not content density). It’s like 1st of October, but 31st of August.
MDSM gather all researchers, engineers and developers around Data Science and Machine Learning:
- Top speakers and talks, zero bullshit
- Lots of new insights, skills and know-hows
- Best networking with the community
Link: https://datafest.ru/major/
Registration link: https://corp.mail.ru/ru/press/events/mdsm_aug19/
Здесь говорят о трафике
Как привлечь, приумножить и хорошо зарабатывать на трафике
GPT-2: 6-Month Follow-Up
#OpenAI released the 774 million parameter #GPT2 language model.
Link: https://openai.com/blog/gpt-2-6-month-follow-up/
#NLU #NLP
#OpenAI released the 774 million parameter #GPT2 language model.
Link: https://openai.com/blog/gpt-2-6-month-follow-up/
#NLU #NLP
Openai
GPT-2: 6-month follow-up
We’re releasing the 774 million parameter GPT-2 language model after the release of our small 124M model in February, staged release of our medium 355M model in May, and subsequent research with partners and the AI community into the model’s potential for…
Applying machine learning optimization methods to the production of a quantum gas
#DeepMind developed machine learning techniques to optimise the production of a Bose-Einstein condensate, a quantum-mechanical state of matter that can be used to test predictions of theories of many-body physics.
ArXiV: https://arxiv.org/abs/1908.08495
#Physics #DL #BEC
#DeepMind developed machine learning techniques to optimise the production of a Bose-Einstein condensate, a quantum-mechanical state of matter that can be used to test predictions of theories of many-body physics.
ArXiV: https://arxiv.org/abs/1908.08495
#Physics #DL #BEC
Testing Robustness Against Unforeseen Adversaries
OpenAI developed a method to assess whether a neural network classifier can reliably defend against adversarial attacks not seen during training. The method yields a new metric, #UAR (Unforeseen Attack Robustness), which evaluates the robustness of a single model against an unanticipated attack, and highlights the need to measure performance across a more diverse range of unforeseen attacks.
Link: https://openai.com/blog/testing-robustness/
ArXiV: https://arxiv.org/abs/1908.08016
Code: https://github.com/ddkang/advex-uar
#GAN #Adversarial #OpenAI
OpenAI developed a method to assess whether a neural network classifier can reliably defend against adversarial attacks not seen during training. The method yields a new metric, #UAR (Unforeseen Attack Robustness), which evaluates the robustness of a single model against an unanticipated attack, and highlights the need to measure performance across a more diverse range of unforeseen attacks.
Link: https://openai.com/blog/testing-robustness/
ArXiV: https://arxiv.org/abs/1908.08016
Code: https://github.com/ddkang/advex-uar
#GAN #Adversarial #OpenAI
OpenGPT-2: We Replicated GPT-2 Because You Can Too
Article about replication of famous #GPT2. This replication project trained a 1.5B parameter «OpenGPT-2» model on OpenWebTextCorpus, a 38GB dataset similar to the original, and showed comparable results to original GPT-2 on various benchmarks.
Link: https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc
Google colab: https://colab.research.google.com/drive/1esbpDOorf7DQJV8GXWON24c-EQrSKOit
OpenWebCorpus: https://skylion007.github.io/OpenWebTextCorpus/
#NLU #NLP
Article about replication of famous #GPT2. This replication project trained a 1.5B parameter «OpenGPT-2» model on OpenWebTextCorpus, a 38GB dataset similar to the original, and showed comparable results to original GPT-2 on various benchmarks.
Link: https://medium.com/@vanya_cohen/opengpt-2-we-replicated-gpt-2-because-you-can-too-45e34e6d36dc
Google colab: https://colab.research.google.com/drive/1esbpDOorf7DQJV8GXWON24c-EQrSKOit
OpenWebCorpus: https://skylion007.github.io/OpenWebTextCorpus/
#NLU #NLP
Medium
OpenGPT-2: We Replicated GPT-2 Because You Can Too
By Aaron Gokaslan* and Vanya Cohen*
Open-sourcing hyperparameter autotuning for fastText
Facebook AI researchers are releasing a new feature for the fastText library which provides hyper-parameter autotuning for more efficient text classifiers.
Link: https://ai.facebook.com/blog/fasttext-blog-post-open-source-in-brief/
#FacebookAI #Facebook #FastText #NLU #NLP
Facebook AI researchers are releasing a new feature for the fastText library which provides hyper-parameter autotuning for more efficient text classifiers.
Link: https://ai.facebook.com/blog/fasttext-blog-post-open-source-in-brief/
#FacebookAI #Facebook #FastText #NLU #NLP
Meta
Open-sourcing hyperparameter autotuning for fastText
Facebook AI researchers are releasing a new feature for the fastText library that provides hyperparameter autotuning for more efficient text classifiers.
Data Science by ODS.ai 🦜
Open-sourcing hyperparameter autotuning for fastText Facebook AI researchers are releasing a new feature for the fastText library which provides hyper-parameter autotuning for more efficient text classifiers. Link: https://ai.facebook.com/blog/fasttext-blog…
This media is not supported in your browser
VIEW IN TELEGRAM
The infinite gift
is an interesting object where the side of the nth box is 1/√n. As n→+∞, the gift has infinite surface area and length but finite volume!
is an interesting object where the side of the nth box is 1/√n. As n→+∞, the gift has infinite surface area and length but finite volume!
{kind=link}
Exploring Weight Agnostic Neural Networks
Exploration of agents that can already perform well in their environment without the need to learn weight parameters.
Link: https://ai.googleblog.com
Code: https://github.com/google/brain-tokyo-workshop/tree/master/WANNRelease
Exploration of agents that can already perform well in their environment without the need to learn weight parameters.
Link: https://ai.googleblog.com
Code: https://github.com/google/brain-tokyo-workshop/tree/master/WANNRelease
Neural net to enhance old or low-quality video to HD (TS -> HD).
It is so surprising that noone had yet released a model for that. People have lots of old video recordings, which will definately benefit from quality enhancement. And we all have to hope movie pirates won’t use it to enhance stolen copies.
Link: https://news.developer.nvidia.com/researchers-at-videogorillas-use-ai-to-remaster-archived-content-to-4k-resolution-and-above/
More demos: https://videogorillas.com/bigfoot/
#SuperResolution #CV #DL
It is so surprising that noone had yet released a model for that. People have lots of old video recordings, which will definately benefit from quality enhancement. And we all have to hope movie pirates won’t use it to enhance stolen copies.
Link: https://news.developer.nvidia.com/researchers-at-videogorillas-use-ai-to-remaster-archived-content-to-4k-resolution-and-above/
More demos: https://videogorillas.com/bigfoot/
#SuperResolution #CV #DL
{kind=link}
ODS breakfast in Paris! See you this Saturday at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.
Forwarded from Just links
http://rescience.github.io/
Tl;dr:
Reproducibility is important. Publishing a paper which results can't be used by any reader is more or less useless. However, while everybody talks about reproducibility, but nobody accepts papers about reproduction of the existing research for publication, let alone the fact of publishing non-reproducible research (not enough details, no open dataset, etc.), which is OK sometimes, but usually is not.
Moreover, what people usually mean when they say "reproducibility" (possibility of repeating the exact experiment described in paper and achieving same results) is "replicability" (possibility of conducting similar experiments with similar results).
This journal aims to be an open access and open source platform to publish replication computational research (which is easier to both replicate and verify).
Tl;dr:
Reproducibility is important. Publishing a paper which results can't be used by any reader is more or less useless. However, while everybody talks about reproducibility, but nobody accepts papers about reproduction of the existing research for publication, let alone the fact of publishing non-reproducible research (not enough details, no open dataset, etc.), which is OK sometimes, but usually is not.
Moreover, what people usually mean when they say "reproducibility" (possibility of repeating the exact experiment described in paper and achieving same results) is "replicability" (possibility of conducting similar experiments with similar results).
This journal aims to be an open access and open source platform to publish replication computational research (which is easier to both replicate and verify).
rescience.github.io
ReScience C
Reproducible Science is good.
Replicated Science is better.
Replicated Science is better.
🚨😭STOP talking bad about different Data SPECIALTIES😭🚨
Data Science is EXCITING
Frequentist Statistics is RELIABLE
Software Engineering is CRUCIAL
Bayesian Statistics
Machine Learning is POWERFUL
Data Science is EXCITING
Frequentist Statistics is RELIABLE
Software Engineering is CRUCIAL
Bayesian Statistics
Machine Learning is POWERFUL
New fastMRI challenge from #FacebookAI team
Submission deadline: September 19
Announcement link: https://ai.facebook.com/blog/fastmri-challenge/
Competition link: https://fastmri.org/
#Competition #NotOnlyKaggle #Facebook #CV #DL
Submission deadline: September 19
Announcement link: https://ai.facebook.com/blog/fastmri-challenge/
Competition link: https://fastmri.org/
#Competition #NotOnlyKaggle #Facebook #CV #DL
{kind=link}
Nice article on non-official jupyter notebook extensions
Warning: there is a checkbox, saying «disable configuration for nbextensions without explicit compatibility (they may break your notebook environment, but can be useful to show for nbextension development)». So it is better to test the extensions in separate environment.
And correct way to install is extension support is:
Link: https://towardsdatascience.com/setting-up-a-data-science-environment-using-windows-subsystem-for-linux-wsl-c4b390803dd
#jupyter #tipsandtrics
Warning: there is a checkbox, saying «disable configuration for nbextensions without explicit compatibility (they may break your notebook environment, but can be useful to show for nbextension development)». So it is better to test the extensions in separate environment.
And correct way to install is extension support is:
pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install --user
Link: https://towardsdatascience.com/setting-up-a-data-science-environment-using-windows-subsystem-for-linux-wsl-c4b390803dd
#jupyter #tipsandtrics
Medium
Setting up a Data Science environment using Windows Subsystem for Linux (WSL) and Jupyter
A Python environment in Linux on Windows, full admin rights & custom Jupyter Notebooks.. Sounds good? Give this a read!
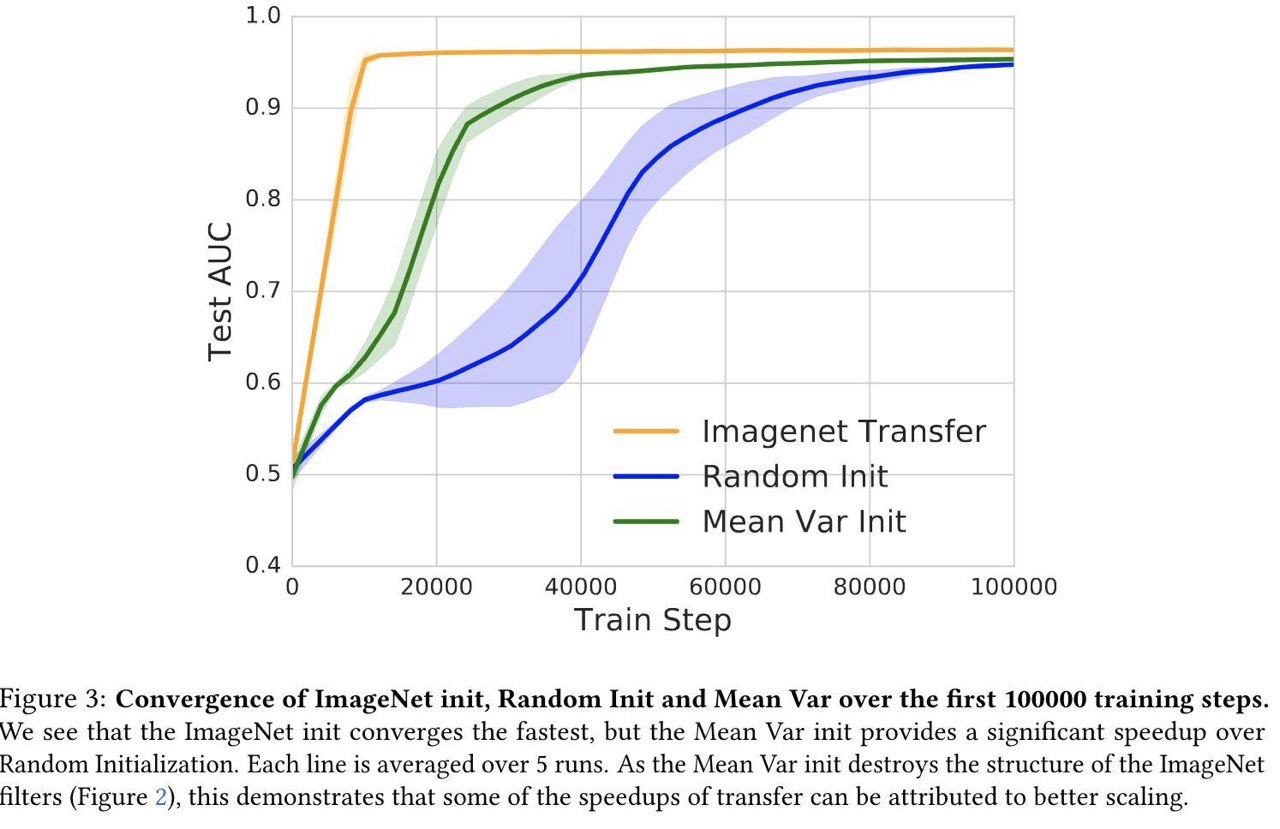
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
Researchers at Facebook AI Research found a way to compress neural networks with minimal sacrifice in accuracy.
Works only on fully connected and CNN only for now.
Link: https://arxiv.org/abs/1907.05686
#nn #DL #minimization #compresson
Researchers at Facebook AI Research found a way to compress neural networks with minimal sacrifice in accuracy.
Works only on fully connected and CNN only for now.
Link: https://arxiv.org/abs/1907.05686
#nn #DL #minimization #compresson
{kind=link}
Great collection and reviews for top online machine and deep learning courses
Post covers short reviews and suggested order in which course could be taken, along with the links at great prerequisites.
Link: http://thegrandjanitor.com/2016/08/15/learning-deep-learning-my-top-five-resource/
#DL #ML #MOOC #novice #entrylevel
Post covers short reviews and suggested order in which course could be taken, along with the links at great prerequisites.
Link: http://thegrandjanitor.com/2016/08/15/learning-deep-learning-my-top-five-resource/
#DL #ML #MOOC #novice #entrylevel
Posture detector running on #tensorflowjs
Great example of learning project for common good. Detects posture and blurs screen if posture is not right.
Link: https://fix-posture.glitch.me
Design: https://www.figma.com/file/hvYOl9g4oO2UaTpVOqRwcF/AI-experiments-by-me-Good-posture?node-id=0%3A1
Code: https://glitch.com/~fix-posture
#posenet #poseestimation
Great example of learning project for common good. Detects posture and blurs screen if posture is not right.
Link: https://fix-posture.glitch.me
Design: https://www.figma.com/file/hvYOl9g4oO2UaTpVOqRwcF/AI-experiments-by-me-Good-posture?node-id=0%3A1
Code: https://glitch.com/~fix-posture
#posenet #poseestimation
Figma
AI experiments by me || Good posture
Created with Figma
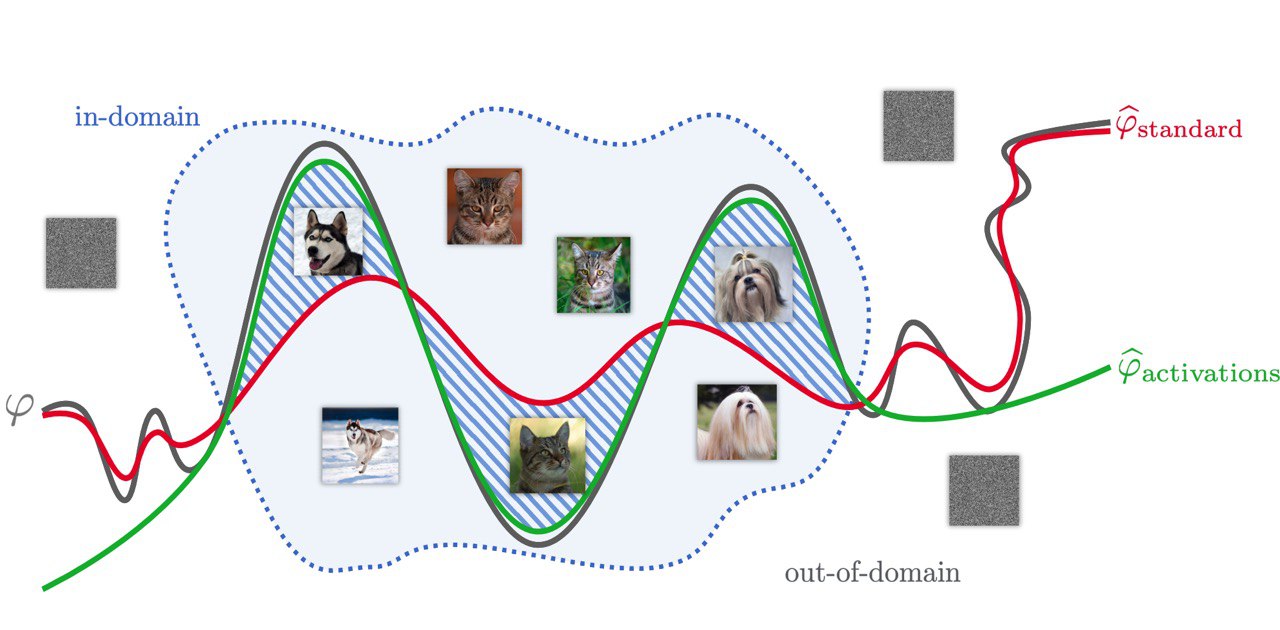
Understanding Transfer Learning for Medical Imaging
ArXiV: https://arxiv.org/abs/1902.07208
#biolearning #dl #transferlearning
ArXiV: https://arxiv.org/abs/1902.07208
#biolearning #dl #transferlearning
{kind=link}
ODS breakfast in Paris! See you this Saturday (Tomorrow) at 10:30 at Malongo Café, 50 Rue Saint-André des Arts.