
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
{kind=link}
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
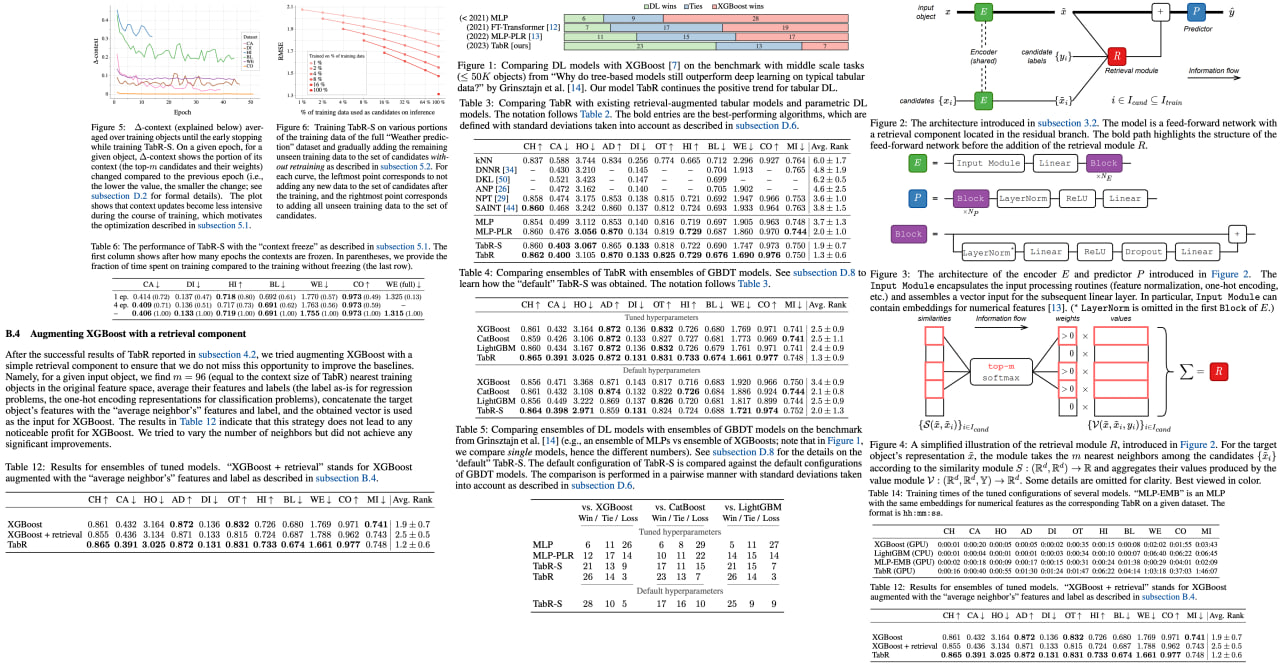
The deep learning arena is abuzz with the rise of models designed for tabular data problems, challenging the traditional dominance of gradient-boosted decision trees (GBDT) algorithms. Among these, retrieval-augmented tabular DL models, which gather relevant training data like nearest neighbors for better prediction, are gaining traction. However, these novel models have only shown marginal benefits over properly tuned retrieval-free baselines, sparking a debate on the effectiveness of the retrieval-based approach.
In response to this uncertainty, this groundbreaking work presents TabR, an innovative retrieval-based tabular DL model. This breakthrough was achieved by augmenting a simple feed-forward architecture with an attention-like retrieval component. Several overlooked aspects of the attention mechanism were highlighted, leading to major performance improvements. On a set of public benchmarks, TabR stole the show, demonstrating unparalleled average performance, becoming the new state-of-the-art on numerous datasets, and even outperforming GBDT models on a recent benchmark designed to favor them.
Code link: https://github.com/yandex-research/tabular-dl-tabr
Paper link: https://arxiv.org/abs/2307.14338
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tabr
#deeplearning #tabular
The deep learning arena is abuzz with the rise of models designed for tabular data problems, challenging the traditional dominance of gradient-boosted decision trees (GBDT) algorithms. Among these, retrieval-augmented tabular DL models, which gather relevant training data like nearest neighbors for better prediction, are gaining traction. However, these novel models have only shown marginal benefits over properly tuned retrieval-free baselines, sparking a debate on the effectiveness of the retrieval-based approach.
In response to this uncertainty, this groundbreaking work presents TabR, an innovative retrieval-based tabular DL model. This breakthrough was achieved by augmenting a simple feed-forward architecture with an attention-like retrieval component. Several overlooked aspects of the attention mechanism were highlighted, leading to major performance improvements. On a set of public benchmarks, TabR stole the show, demonstrating unparalleled average performance, becoming the new state-of-the-art on numerous datasets, and even outperforming GBDT models on a recent benchmark designed to favor them.
Code link: https://github.com/yandex-research/tabular-dl-tabr
Paper link: https://arxiv.org/abs/2307.14338
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tabr
#deeplearning #tabular
{kind=link}
Tracking Anything in High Quality
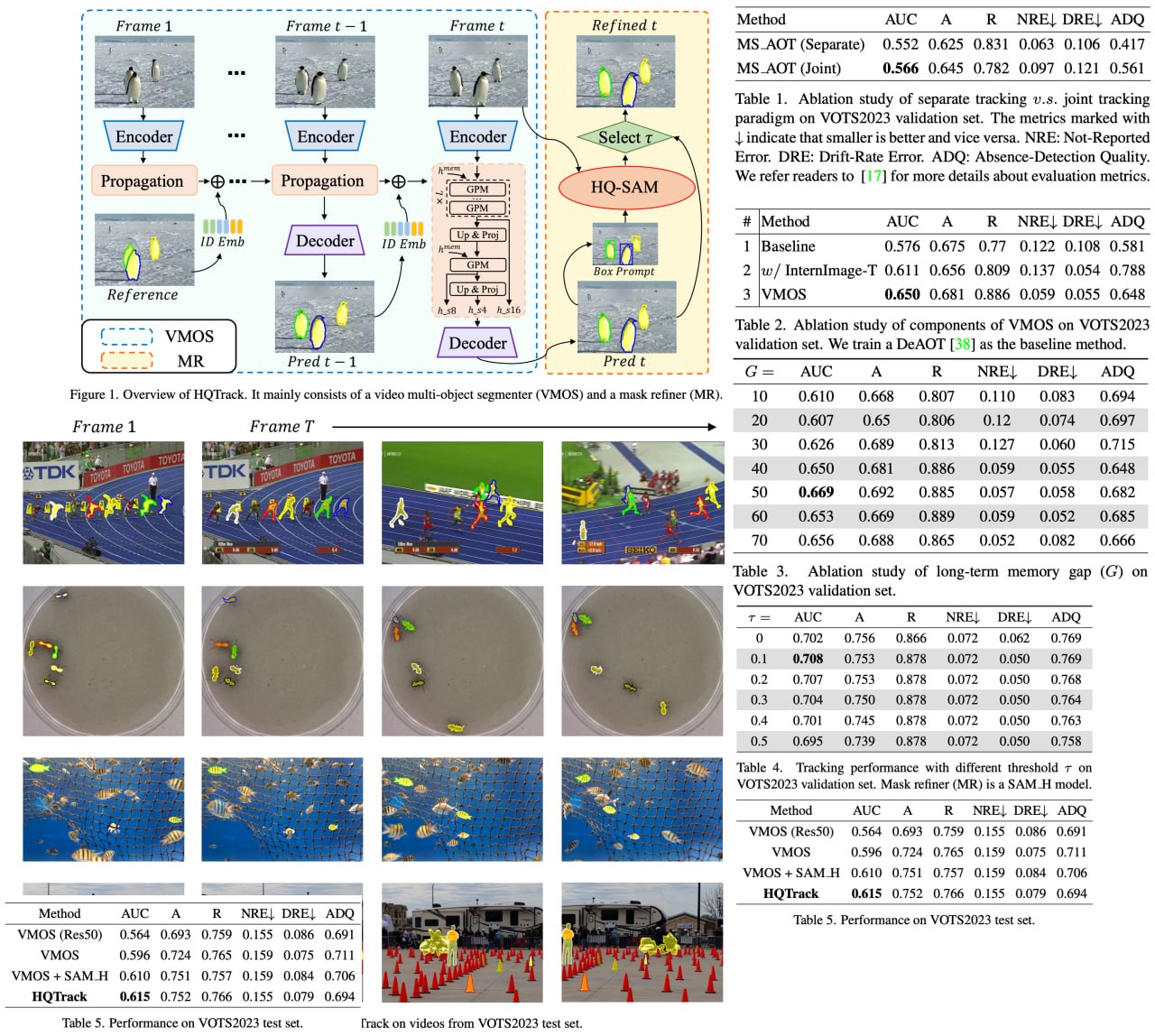
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
{kind=link}
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
{kind=link}
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
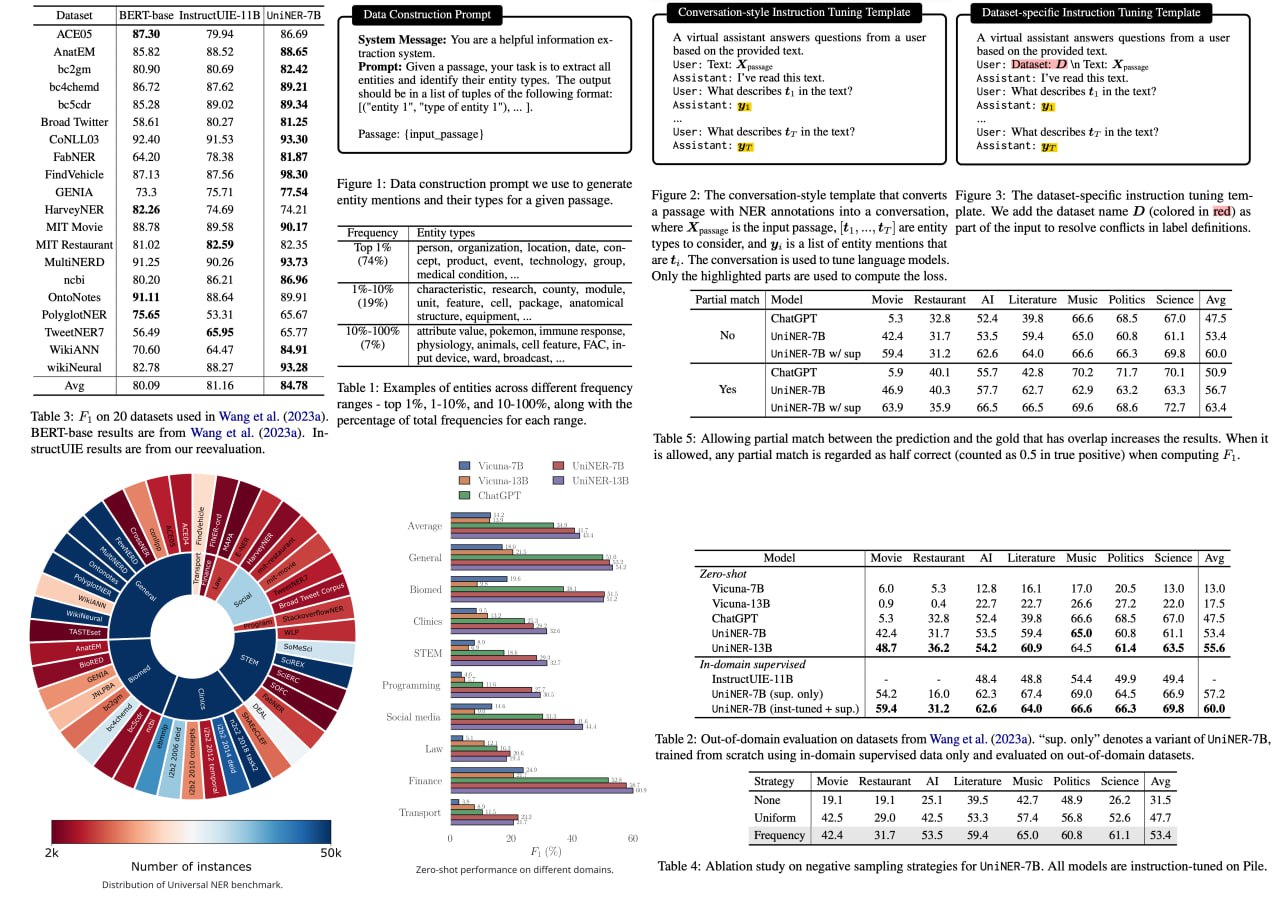
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
{kind=link}
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
{kind=link}
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
{kind=link}
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
{kind=link}
Giraffe: Adventures in Expanding Context Lengths in LLMs
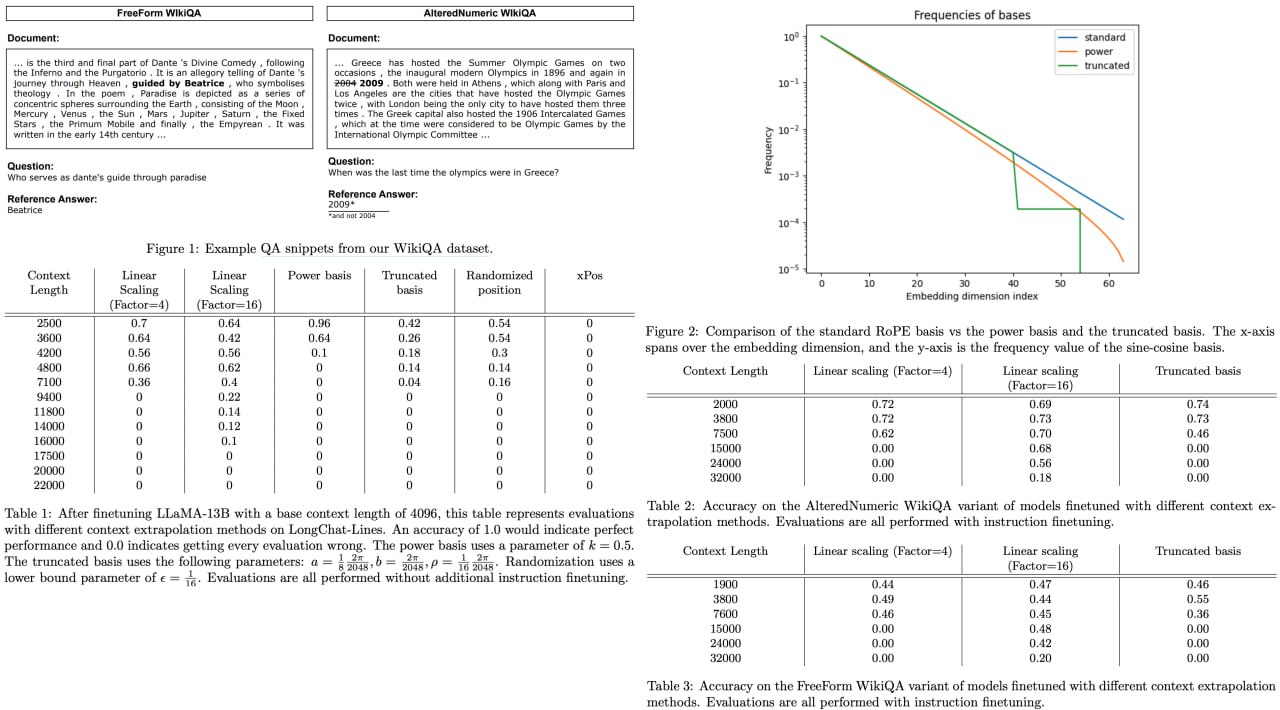
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
{kind=link}
CoTracker: It is Better to Track Together
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
{kind=link}
RecMind: Large Language Model Powered Agent For Recommendation
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
{kind=link}
TSMixer: An All-MLP Architecture for Time Series Forecasting
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
{kind=link}