
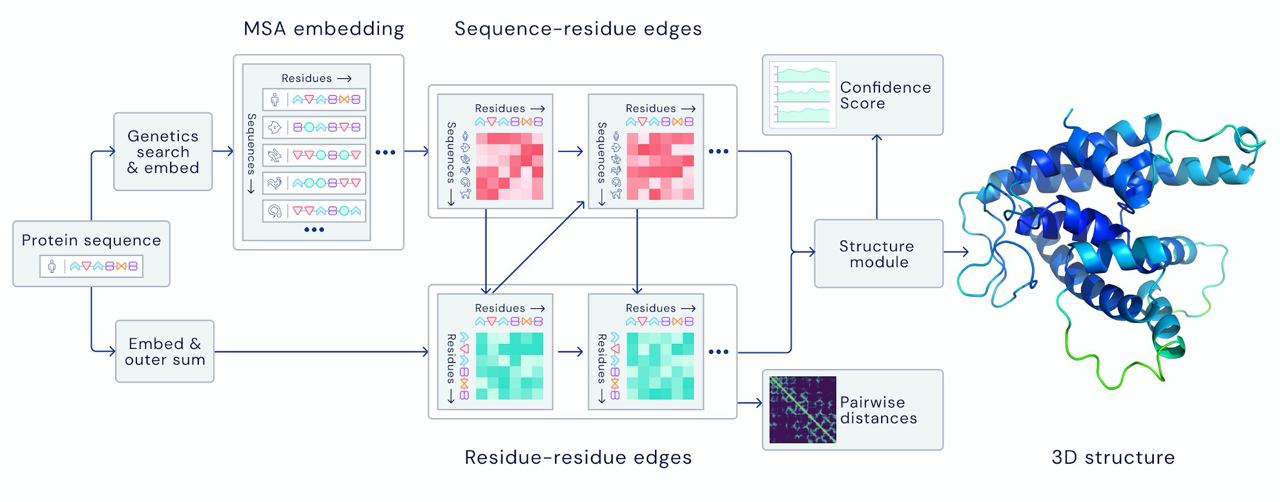
DeepMind significally (+100%) improved protein folding modelling
Why is this important: protein folding = protein structure = protein function = how protein works in the living speciment and what it does.
What this means: better vaccines, better meds, more curable diseases and more calamities easen by the medications or better understanding.
Dataset: ~170000 available protein structures from PDB
Hardware: 128 TPUv3 cores (roughly equivalent to ~100-200 GPUs)
Link: https://deepmind.com/blog/article/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology
#DL #NLU #proteinmodelling #bio #biolearning #insilico #deepmind #AlphaFold
Why is this important: protein folding = protein structure = protein function = how protein works in the living speciment and what it does.
What this means: better vaccines, better meds, more curable diseases and more calamities easen by the medications or better understanding.
Dataset: ~170000 available protein structures from PDB
Hardware: 128 TPUv3 cores (roughly equivalent to ~100-200 GPUs)
Link: https://deepmind.com/blog/article/alphafold-a-solution-to-a-50-year-old-grand-challenge-in-biology
#DL #NLU #proteinmodelling #bio #biolearning #insilico #deepmind #AlphaFold
{kind=link}
Supporting content decision makers with machine learning
#Netflix shared a post providing information about how they research and prepare data for new title production.
Link: https://netflixtechblog.com/supporting-content-decision-makers-with-machine-learning-995b7b76006f
#NLU #NLP #recommendation #embeddings
#Netflix shared a post providing information about how they research and prepare data for new title production.
Link: https://netflixtechblog.com/supporting-content-decision-makers-with-machine-learning-995b7b76006f
#NLU #NLP #recommendation #embeddings
{kind=link}
Blender Bot 2.0: An open source chatbot that builds long-term memory and searches the internet
Bot is capable of supporting a dialog and remembering the context of the sequential questions.
Blogpost: https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet
Github: https://github.com/facebookresearch/ParlAI
Paper 1: https://parl.ai/projects/sea
Paper 2: https://parl.ai/projects/msc
#chatbot #NLU #facebookai
Bot is capable of supporting a dialog and remembering the context of the sequential questions.
Blogpost: https://ai.facebook.com/blog/blender-bot-2-an-open-source-chatbot-that-builds-long-term-memory-and-searches-the-internet
Github: https://github.com/facebookresearch/ParlAI
Paper 1: https://parl.ai/projects/sea
Paper 2: https://parl.ai/projects/msc
#chatbot #NLU #facebookai
Program Synthesis with Large Language Models
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
{kind=link}
Summarizing Books with Human Feedback
#OpenAI fine-tuned #GPT3 to summarize books well enough to be human-readable. Main approach: recursively split text into parts and then meta-summarize summaries.
This is really important because once there will be a great summarization #SOTA we won't need editors to write posts for you. And researchers ultimatively will have some asisstance interpreting models' results.
BlogPost: https://openai.com/blog/summarizing-books/
ArXiV: https://arxiv.org/abs/2109.10862
#summarization #NLU #NLP
#OpenAI fine-tuned #GPT3 to summarize books well enough to be human-readable. Main approach: recursively split text into parts and then meta-summarize summaries.
This is really important because once there will be a great summarization #SOTA we won't need editors to write posts for you. And researchers ultimatively will have some asisstance interpreting models' results.
BlogPost: https://openai.com/blog/summarizing-books/
ArXiV: https://arxiv.org/abs/2109.10862
#summarization #NLU #NLP
{kind=link}
AI Generated Pokemon Sprites with GPT-2
Author trained #GPT2 model to generate #pokemon sprites, encoding them as the lines of characters (including color). Surprisingly, results were decent, so this leaves us wonder if #GPT3 results would be better.
YouTube: https://www.youtube.com/watch?v=Z9K3cwSL6uM
GitHub: https://github.com/MatthewRayfield/pokemon-gpt-2
Article: https://matthewrayfield.com/articles/ai-generated-pokemon-sprites-with-gpt-2/
Example: https://matthewrayfield.com/projects/ai-pokemon/
#NLU #NLP #generation #neuralart
Author trained #GPT2 model to generate #pokemon sprites, encoding them as the lines of characters (including color). Surprisingly, results were decent, so this leaves us wonder if #GPT3 results would be better.
YouTube: https://www.youtube.com/watch?v=Z9K3cwSL6uM
GitHub: https://github.com/MatthewRayfield/pokemon-gpt-2
Article: https://matthewrayfield.com/articles/ai-generated-pokemon-sprites-with-gpt-2/
Example: https://matthewrayfield.com/projects/ai-pokemon/
#NLU #NLP #generation #neuralart
{kind=link}
It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
YaTalks — Yandex's conference for IT community.
Yandex will host its traditional conference on 3-4 December (starting tomorrow). Registration is open.
One of the tracks is devoted to Machine/Deep Learning with the focus on content generation.
Featured reports:
📚How too train text model on the minimal corpus
🎙️How Yandex.Browser Machine Translation works
🤖 Facial Expressions Animation
Conference website: https://yatalks.yandex.ru/?from=tg_opendatascience
#conference #mt #nlu
Yandex will host its traditional conference on 3-4 December (starting tomorrow). Registration is open.
One of the tracks is devoted to Machine/Deep Learning with the focus on content generation.
Featured reports:
📚How too train text model on the minimal corpus
🎙️How Yandex.Browser Machine Translation works
🤖 Facial Expressions Animation
Conference website: https://yatalks.yandex.ru/?from=tg_opendatascience
#conference #mt #nlu
yatalks.yandex.ru
YaTalks 2023 — Yandex's premier conference for the IT community
On December 5-6, Moscow and Belgrade will host over 100 IT industry experts and scientists delivering technical presentations on development, ML, and giving popular science lectures.
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
TLDR: GPT-3 has unexpected application — modelling of socialogical studies. Average responses of a certain groups can be to some algorithmical accuracy predicted by in silico modelling.
What this means: sociologists won’t have to conduct costly live researches and will be able to run experiments in simulations. Marketers and politicians are getting their hands on cheap solution for modelling their slogans and value propositions. This enables people to check more hypothesis faster and to manipulate society with more efficiency.
ArXiV: https://arxiv.org/abs/2209.06899
#gpt3 #psychohistory #nlu #sociology
Please open Telegram to view this post
VIEW IN TELEGRAM
Amos: An Adam-style Optimizer with Adaptive Weight Decay towards Model-Oriented Scale
Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!
ArXiV: https://arxiv.org/abs/2210.11693
#NLU #NLP #optimizer
Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!Amos is a new optimizer that we propose to pre-train large language models. It is more efficient and converges faster than AdamW: ≤ 51% memory for slot variables, and better valid loss within ≤ 70% training time!
ArXiV: https://arxiv.org/abs/2210.11693
#NLU #NLP #optimizer
Data Science by ODS.ai 🦜