
DEEP DOUBLE DESCENT
where bigger models and more data hurt
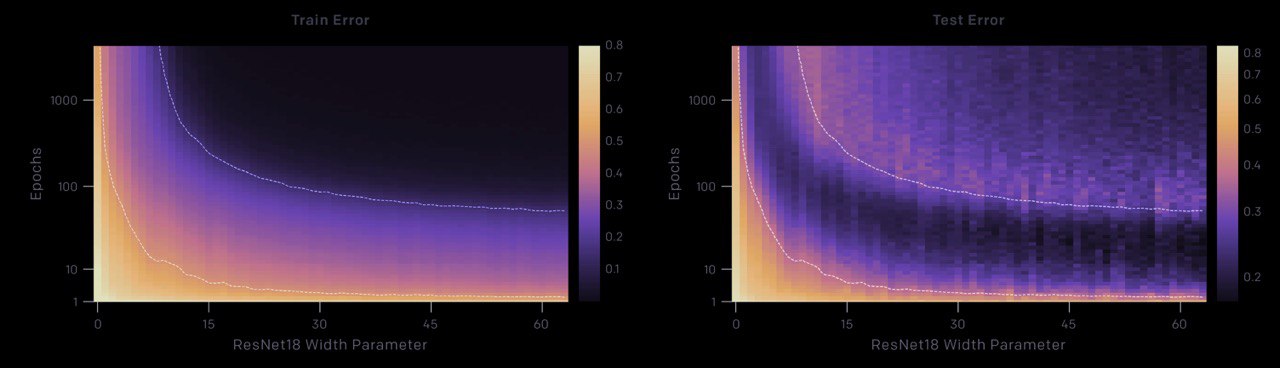
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
{kind=link}