
Research group at MIT discovered new way of tracking sleep phase. WiFi can interfere, but they used deep learning to clear the signal and to achieve 80% accuracy in sleep stage prediction, compapable with a lab equipment.
http://news.mit.edu/2017/new-ai-algorithm-monitors-sleep-radio-waves-0807
#timeseries #eeg #deep_learning #mit #sleep
http://news.mit.edu/2017/new-ai-algorithm-monitors-sleep-radio-waves-0807
#timeseries #eeg #deep_learning #mit #sleep
MIT News
New AI algorithm monitors sleep with radio waves
Researchers at MIT and Massachusetts General Hospital have devised a new way to monitor sleep without any kind of sensors attached to the body. Their sensor uses low-power radio waves that detect small changes in body movement caused by the patient’s breathing…
Andrew Ng has announced new Deep Learning course on Coursera:
“deeplearning.ai: Announcing new Deep Learning courses on Coursera” https://medium.com/@andrewng/deeplearning-ai-announcing-new-deep-learning-courses-on-coursera-43af0a368116
#coursera #deep_learning earning #dl #andrewng
“deeplearning.ai: Announcing new Deep Learning courses on Coursera” https://medium.com/@andrewng/deeplearning-ai-announcing-new-deep-learning-courses-on-coursera-43af0a368116
#coursera #deep_learning earning #dl #andrewng
Medium
deeplearning.ai: Announcing new Deep Learning courses on Coursera
Dear Friends,
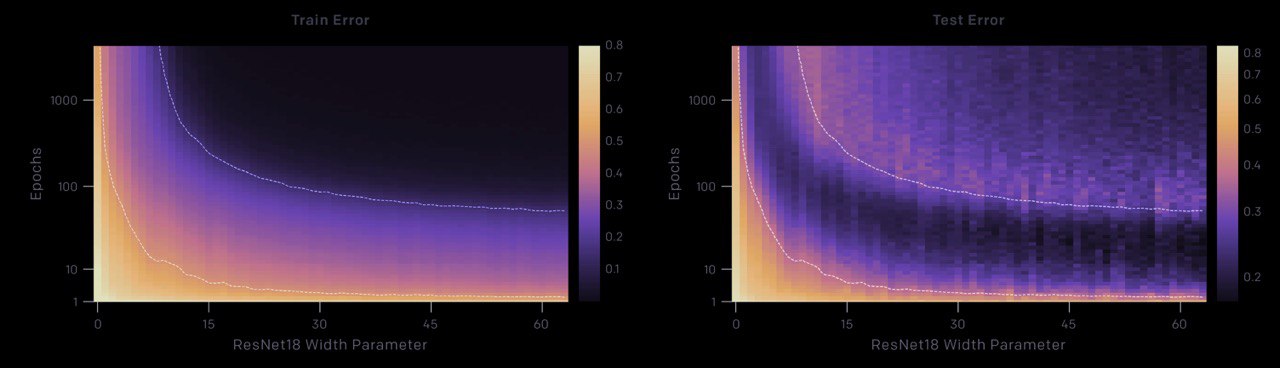
DEEP DOUBLE DESCENT
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
where bigger models and more data hurt
it's really cool & interesting research about where we watch that the performance first improves, then gets worse, and then improves again with increasing model size, data size, or training time. but this effect is often avoided through careful regularization.
some conclusions from research:
– there is a regime where bigger models are worse
– there is a regime where more samples hurt
– there is a regime where training longer reverses overfitting
blog post: https://openai.com/blog/deep-double-descent/
paper: https://arxiv.org/abs/1912.02292
#deep #train #size #openai
{kind=link}
Forwarded from Spark in me (Alexander)
Russian Text Normalization for Speech Recognition
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
- De-Normalization (
We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
Usually no one talks about this, but STT / TTS technologies contain many "small" tasks that have to be solved, to make your STT / TTS pipeline work in real life.
For example:
- Speech recognition / dataset itself;
- Post-processing - beam-search / decoding;
- Domain customizations;
- Normalization (5 =>
пять);- De-Normalization (
пять => 5);We want the Imagenet moment to arrive sooner in Speech in general.
So we released the Open STT dataset.
This time we have decided to share our text normalization to support STT research in Russian.
Please like / share / repost:
- Original publication
- Habr.com article
- GitHub repository
- Medium (coming soon!)
- Support dataset on Open Collective
#stt
#deep_learning
#nlp
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
Forwarded from Spark in me (Alexander)
Towards an ImageNet Moment for Speech-to-Text
First CV, and then (arguably) NLP, have had their ImageNet moment — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Following the release of our production models / metrics, this is our piece on this topic on thegradient.pub! So far this is the largest work ever we have done, and I hope that it will not go under the radar.
It is in our hands now to make sure that speech recognition brings value to people worldwide, and not only some fat cats.
So, without further ado:
- The piece itself https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/
- Some more links here https://spark-in.me/post/towards-an-imagenet-moment-for-speech-to-text
- If you are on Twitter, please repost this message - https://twitter.com/gradientpub/status/1243967773635571712
A lot of thanks to Thegradient team, especially Andrey and Jacob, for the sheer amount of work they put in to make this piece readable and understandable!
Please like, share, repost!
Also, there will be a second piece with criticism, so stay tuned!
#speech
#deep_learning
First CV, and then (arguably) NLP, have had their ImageNet moment — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Following the release of our production models / metrics, this is our piece on this topic on thegradient.pub! So far this is the largest work ever we have done, and I hope that it will not go under the radar.
It is in our hands now to make sure that speech recognition brings value to people worldwide, and not only some fat cats.
So, without further ado:
- The piece itself https://thegradient.pub/towards-an-imagenet-moment-for-speech-to-text/
- Some more links here https://spark-in.me/post/towards-an-imagenet-moment-for-speech-to-text
- If you are on Twitter, please repost this message - https://twitter.com/gradientpub/status/1243967773635571712
A lot of thanks to Thegradient team, especially Andrey and Jacob, for the sheer amount of work they put in to make this piece readable and understandable!
Please like, share, repost!
Also, there will be a second piece with criticism, so stay tuned!
#speech
#deep_learning
The Gradient
Towards an ImageNet Moment for Speech-to-Text
First CV, and then NLP, have had their 'ImageNet moment' — a technical shift that makes tackling many problems much easier. Could Speech-To-Text be next?
Forwarded from Spark in me (Alexander)
Trying Out New Ampere GPUs and MIG
Our hands on experience with new Ampere GPUs - 3090 and A100 (with multi instance GPU)
https://habr.com/ru/post/531436/
Please like / share / repost!
#hardware
#deep_learning
Our hands on experience with new Ampere GPUs - 3090 and A100 (with multi instance GPU)
https://habr.com/ru/post/531436/
Please like / share / repost!
#hardware
#deep_learning
Habr
Playing with Nvidia's New Ampere GPUs and Trying MIG
Every time when the essential question arises, whether to upgrade the cards in the server room or not, I look through similar articles and watch such videos.
Forwarded from Spark in me (Alexander)
Transformer Module Optimization
Article on how to apply different methods to make your transformer network up to 10x smaller and faster:
- Plain model optimization and PyTorch tricks;
- How and why to use FFT instead of self-attention;
- Model Factorization and quantization;
https://habr.com/ru/post/563778/
#deep_learning
Article on how to apply different methods to make your transformer network up to 10x smaller and faster:
- Plain model optimization and PyTorch tricks;
- How and why to use FFT instead of self-attention;
- Model Factorization and quantization;
https://habr.com/ru/post/563778/
#deep_learning
Хабр
Сжимаем трансформеры: простые, универсальные и прикладные способы cделать их компактными и быстрыми
Сейчас в сфере ML постоянно слышно про невероятные "успехи" трансформеров в разных областях. Но появляется все больше статей о том, что многие из этих успехов м...