
New deep learning framework from Facebook
Pythia is a deep learning framework that supports multitasking in the vision and language domain. Built on our open-source #PyTorch framework, the modular, plug-and-play design enables researchers to quickly build, reproduce, and benchmark AI models. #Pythia is designed for vision and language tasks, such as answering questions related to visual data and automatically generating image captions.
Link: https://code.fb.com/ai-research/pythia/
GitHub: https://github.com/facebookresearch/pythia
#Facebook #FacebookAI #DL #CV #multimodal
Pythia is a deep learning framework that supports multitasking in the vision and language domain. Built on our open-source #PyTorch framework, the modular, plug-and-play design enables researchers to quickly build, reproduce, and benchmark AI models. #Pythia is designed for vision and language tasks, such as answering questions related to visual data and automatically generating image captions.
Link: https://code.fb.com/ai-research/pythia/
GitHub: https://github.com/facebookresearch/pythia
#Facebook #FacebookAI #DL #CV #multimodal
Engineering at Meta
Releasing Pythia for vision and language multimodal AI models
Pythia is a new open source deep learning framework that enables researchers to quickly build, reproduce, and benchmark AI models.
ImageBind: One Embedding Space To Bind Them All
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
{kind=link}
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
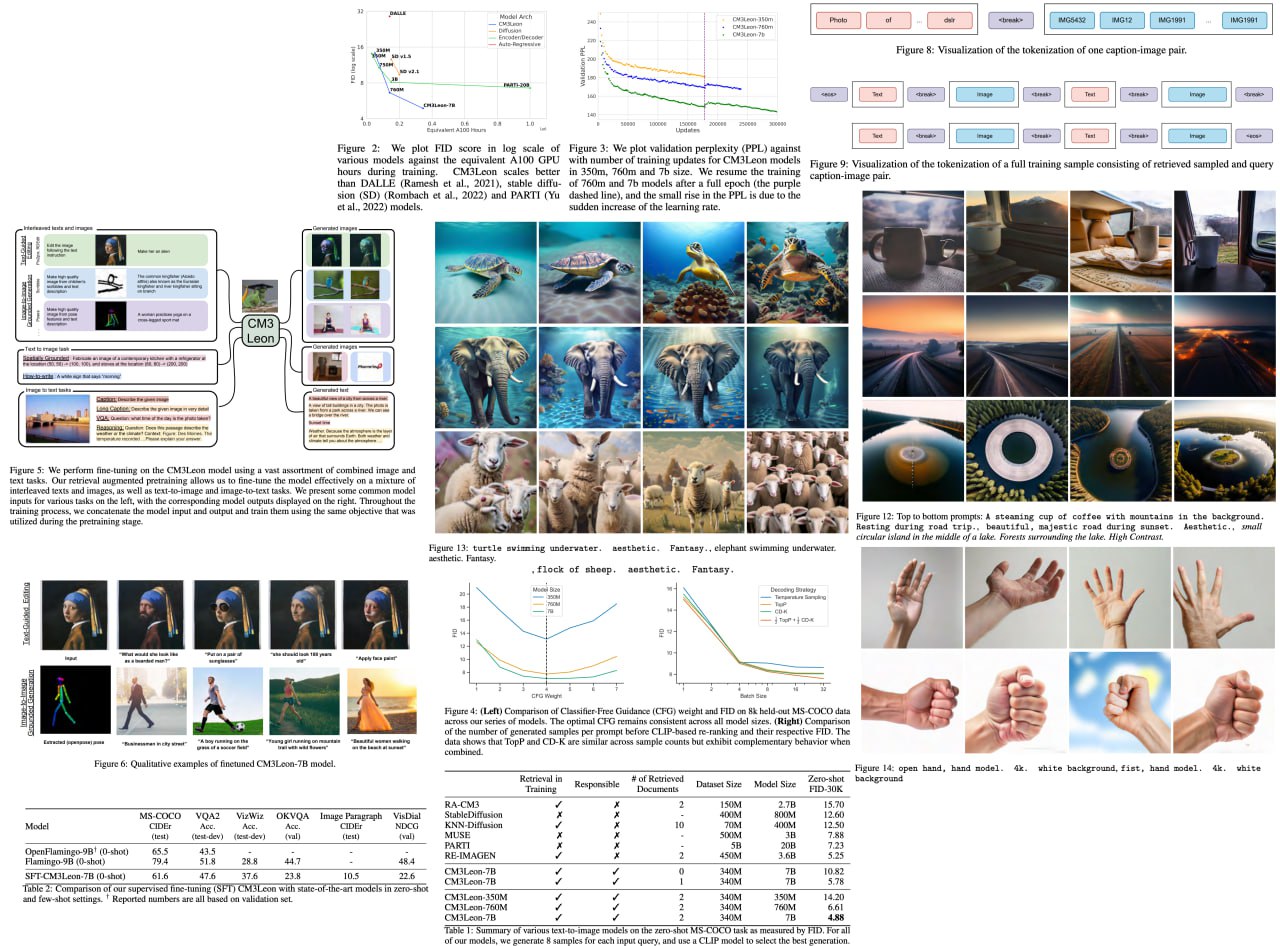
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
{kind=link}