
spaCy meets PyTorch-Transformers: Fine-tune BERT, XLNet and GPT-2
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
pip install spacy-pytorch-transformers#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
explosion.ai
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2 · Explosion
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
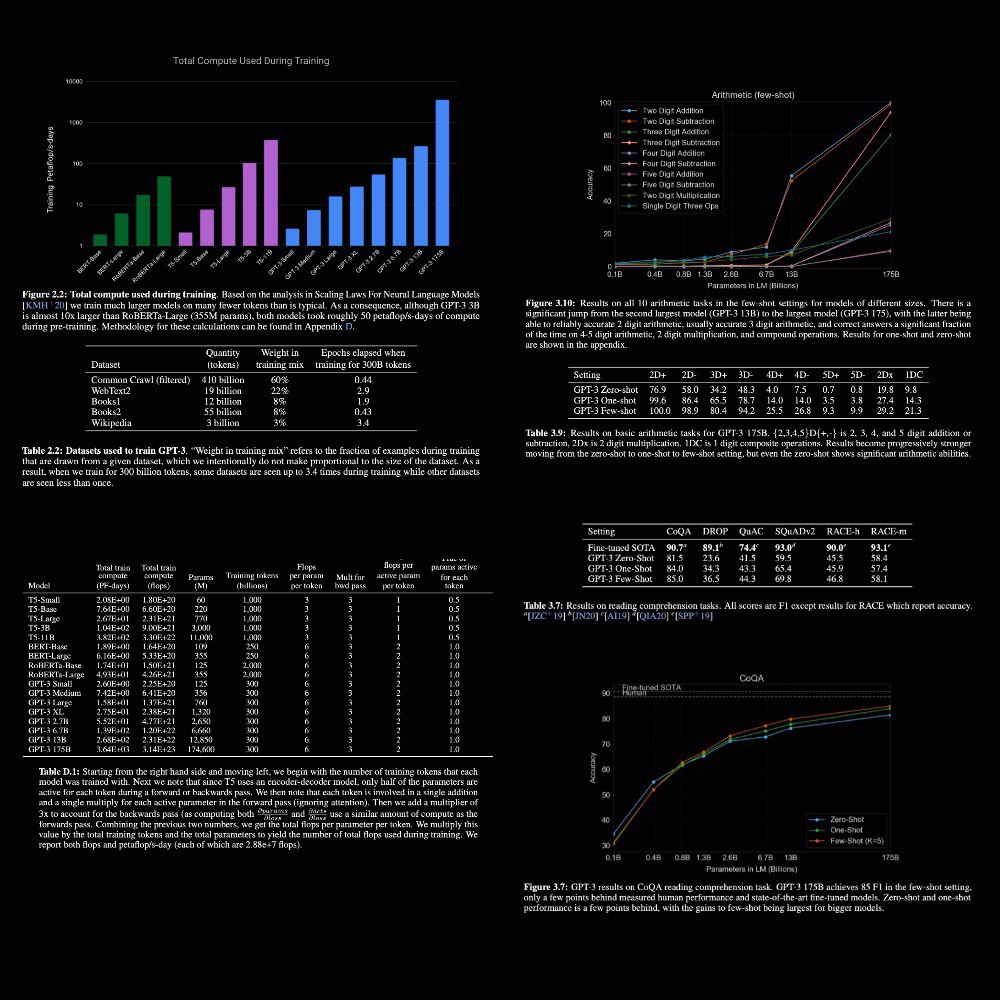
GPT-3: Language Models are Few-Shot Learners
#openAI train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting
Their model applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
Achieves strong performance on many NLP datasets, including translation, q&a, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Also, they find that GPT-3 can generate samples of news articles in which human evaluators have difficulty distinguishing from articles written by humans.
175 billion parameters! And on some tasks, it is not performed
It is all you need to know about
paper: https://arxiv.org/abs/2005.14165.pdf
#nlp #gpt #gpt3 #language #model
#openAI train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting
Their model applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
Achieves strong performance on many NLP datasets, including translation, q&a, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Also, they find that GPT-3 can generate samples of news articles in which human evaluators have difficulty distinguishing from articles written by humans.
175 billion parameters! And on some tasks, it is not performed
It is all you need to know about
paper: https://arxiv.org/abs/2005.14165.pdf
#nlp #gpt #gpt3 #language #model
{kind=link}
mingpt – a minimal pytorch re-implementation of the openai generative pretrained transformer training
by karpathy
small, clean, interpretable and educational, as most of the currently available ones are a bit sprawling. this implementation is appropriately about 300 lines of code, including boilerplate and a totally unnecessary custom causal self-attention module. all that's going on is that a sequence of indices goes into a sequence of transformer blocks, and a probability distribution of the next index comes out.
with a bpe encoder, distributed training and maybe fp16 this implementation may be able to reproduce gpt-1/gpt-2 results, though they haven't tried $$$. gpt-3 is likely out of reach as his understanding is that it does not fit into gpu memory and requires a more careful model-parallel treatment.
https://twitter.com/karpathy/status/1295410274095095810?s=20
#nlp #karpathy #gpt #torch
by karpathy
small, clean, interpretable and educational, as most of the currently available ones are a bit sprawling. this implementation is appropriately about 300 lines of code, including boilerplate and a totally unnecessary custom causal self-attention module. all that's going on is that a sequence of indices goes into a sequence of transformer blocks, and a probability distribution of the next index comes out.
with a bpe encoder, distributed training and maybe fp16 this implementation may be able to reproduce gpt-1/gpt-2 results, though they haven't tried $$$. gpt-3 is likely out of reach as his understanding is that it does not fit into gpu memory and requires a more careful model-parallel treatment.
https://twitter.com/karpathy/status/1295410274095095810?s=20
#nlp #karpathy #gpt #torch
Twitter
Andrej Karpathy
I wrote a minimal/educational GPT training library in PyTorch, am calling it minGPT as it is only around ~300 lines of code: https://t.co/79S9lShJRN +demos for addition and character-level language model. (quick weekend project, may contain sharp edges)
Forwarded from Kirill from TOP
GPT-3 for self-therapy
Just came across an interesting article about using #GPT-3 to analyze past journal entries and summarize therapy sessions for gaining new perspectives on personal struggles. Dan Shipper loaded person journal into the neural network so he could ask different questions, including asking about his own Myers-Briggs personality type (INTJ for those who wondered).
It's a powerful example of how AI tools can help individuals become more productive, effective, and happy. As we continue to see the integration of #AI in various industries, it's important for modern blue collar workers to learn how to properly work with these tools in order to stay at the peak of efficiency.
Let's embrace the future and learn to use AI to our advantage rather than to spread FUD about AI replacing workforce. It won’t but it will enable some people to achieve more and be way more productive.
Link: https://every.to/chain-of-thought/can-gpt-3-explain-my-past-and-tell-me-my-future
#aiusecase #toolsnotactors
Just came across an interesting article about using #GPT-3 to analyze past journal entries and summarize therapy sessions for gaining new perspectives on personal struggles. Dan Shipper loaded person journal into the neural network so he could ask different questions, including asking about his own Myers-Briggs personality type (INTJ for those who wondered).
It's a powerful example of how AI tools can help individuals become more productive, effective, and happy. As we continue to see the integration of #AI in various industries, it's important for modern blue collar workers to learn how to properly work with these tools in order to stay at the peak of efficiency.
Let's embrace the future and learn to use AI to our advantage rather than to spread FUD about AI replacing workforce. It won’t but it will enable some people to achieve more and be way more productive.
Link: https://every.to/chain-of-thought/can-gpt-3-explain-my-past-and-tell-me-my-future
#aiusecase #toolsnotactors
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
{kind=link}