
There is a new $1MM competition on Kaggle to use ML / AI to diagnose lung cancer from CT scans.
Not only it is the great breakthrough for Kaggle (it is the first competition with this huge prize fund), it is also a breakthrough for science, since top world researchers and enginners will compete to basically crowdsource and ease the lung cancer diagnostics.
Competition is available at: https://www.kaggle.com/c/data-science-bowl-2017
#kaggle #segmentation #deeplearning #cv
Not only it is the great breakthrough for Kaggle (it is the first competition with this huge prize fund), it is also a breakthrough for science, since top world researchers and enginners will compete to basically crowdsource and ease the lung cancer diagnostics.
Competition is available at: https://www.kaggle.com/c/data-science-bowl-2017
#kaggle #segmentation #deeplearning #cv
Kaggle
Data Science Bowl 2017
Can you improve lung cancer detection?
Google purchased scene segmentation technology.
https://techcrunch.com/2017/08/16/google-acquires-aimatter-maker-of-the-fabby-computer-vision-app/
#dl #segmentation #cv #google
https://techcrunch.com/2017/08/16/google-acquires-aimatter-maker-of-the-fabby-computer-vision-app/
#dl #segmentation #cv #google
TechCrunch
Google acquires AIMatter, maker of the Fabby computer vision app
Computer vision -- the branch of artificial intelligence that lets computers "see" and process images like humans do (and, actually, often better than
Semantic Segmentation Models for Autonomous Vehicles
https://www.kdnuggets.com/2018/03/semantic-segmentation-models-autonomous-vehicles.html
#deeplearning #segmentation
https://www.kdnuggets.com/2018/03/semantic-segmentation-models-autonomous-vehicles.html
#deeplearning #segmentation
ModaNet: A Large-Scale Street Fashion Dataset with Polygon Annotations
Latest segmentation and detection approaches (DeepLabV3+, FasterRCNN) applied to street fashion images. Arxiv paper contains information about both: net and dataset.
Arxiv link: https://arxiv.org/abs/1807.01394
Paperdoll dataset: http://vision.is.tohoku.ac.jp/~kyamagu/research/paperdoll/
#segmentation #dataset #fashion #sv
Latest segmentation and detection approaches (DeepLabV3+, FasterRCNN) applied to street fashion images. Arxiv paper contains information about both: net and dataset.
Arxiv link: https://arxiv.org/abs/1807.01394
Paperdoll dataset: http://vision.is.tohoku.ac.jp/~kyamagu/research/paperdoll/
#segmentation #dataset #fashion #sv
vision.is.tohoku.ac.jp
Kota Yamaguchi - PaperDoll Parsing
Kota Yamaguchi's website
Cancer metastasis detection with neural conditional random field (NCRF)
Github: https://github.com/baidu-research/NCRF?utm_source=telegram&utm_medium=opendatascience
#Baidu #Cancer #Segmentation #cv #DL
Github: https://github.com/baidu-research/NCRF?utm_source=telegram&utm_medium=opendatascience
#Baidu #Cancer #Segmentation #cv #DL
GitHub
GitHub - baidu-research/NCRF: Cancer metastasis detection with neural conditional random field (NCRF)
Cancer metastasis detection with neural conditional random field (NCRF) - baidu-research/NCRF
Paper «A Probabilistic U-Net for Segmentation of Ambiguous Images» from #NIPS2018 spotlight presentation.
Github: https://github.com/SimonKohl/probabilistic_unet
Github: Arxiv: https://arxiv.org/abs/1806.05034
#DeepMind #segmentation #cv
Github: https://github.com/SimonKohl/probabilistic_unet
Github: Arxiv: https://arxiv.org/abs/1806.05034
#DeepMind #segmentation #cv
GitHub
GitHub - SimonKohl/probabilistic_unet: A U-Net combined with a variational auto-encoder that is able to learn conditional distributions…
A U-Net combined with a variational auto-encoder that is able to learn conditional distributions over semantic segmentations. - GitHub - SimonKohl/probabilistic_unet: A U-Net combined with a variat...
Faster R-CNN and Mask R-CNN in #PyTorch 1.0
Another release from #Facebook.
Mask R-CNN Benchmark: a fast and modular implementation for Faster R-CNN and Mask R-CNN written entirely in @PyTorch 1.0. It brings up to 30% speedup compared to mmdetection during training.
Webcam demo and ipynb file are available.
Github: https://github.com/facebookresearch/maskrcnn-benchmark
#CNN #CV #segmentation #detection
Another release from #Facebook.
Mask R-CNN Benchmark: a fast and modular implementation for Faster R-CNN and Mask R-CNN written entirely in @PyTorch 1.0. It brings up to 30% speedup compared to mmdetection during training.
Webcam demo and ipynb file are available.
Github: https://github.com/facebookresearch/maskrcnn-benchmark
#CNN #CV #segmentation #detection
GitHub
GitHub - facebookresearch/maskrcnn-benchmark: Fast, modular reference implementation of Instance Segmentation and Object Detection…
Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch. - facebookresearch/maskrcnn-benchmark
Papers from #DeepMind panel at #NIPS2018
Work on radiotherapy planning: https://arxiv.org/abs/1809.04430
Triaging eye diseases: https://www.nature.com/articles/s41591-018-0107-6
Probabilistic U-net: https://arxiv.org/abs/1806.05034
#segmentation #CV #Unet
Work on radiotherapy planning: https://arxiv.org/abs/1809.04430
Triaging eye diseases: https://www.nature.com/articles/s41591-018-0107-6
Probabilistic U-net: https://arxiv.org/abs/1806.05034
#segmentation #CV #Unet
Fast video object segmentation with Spatio-Temporal GANs
Spatio-Temporal GANs to the Video Object Segmentation task, allowing to run at 32 FPS without fine-tuning.
#FaSTGAN #GAN #Segmentation #videomining #CV #DL
Spatio-Temporal GANs to the Video Object Segmentation task, allowing to run at 32 FPS without fine-tuning.
#FaSTGAN #GAN #Segmentation #videomining #CV #DL
{kind=link}
Deep Learning Image Segmentation for Ecommerce Catalogue Visual Search
Microsoft’s article on image segmentation
Link: https://www.microsoft.com/developerblog/2018/04/18/deep-learning-image-segmentation-for-ecommerce-catalogue-visual-search/
#CV #DL #Segmentation #Microsoft
Microsoft’s article on image segmentation
Link: https://www.microsoft.com/developerblog/2018/04/18/deep-learning-image-segmentation-for-ecommerce-catalogue-visual-search/
#CV #DL #Segmentation #Microsoft
{kind=link}
GSCNN: video segmetation architecture
Semantic segmentation GSCNN significantly outperforms DeepLabV3+ on Cityscapes benchmark.
Paper: https://arxiv.org/abs/1907.05740
Github (Project): https://github.com/nv-tlabs/GSCNN
#DL #CV #NVidiaAI #Nvidia #autonomous #selfdriving #car #RL #segmentation
Semantic segmentation GSCNN significantly outperforms DeepLabV3+ on Cityscapes benchmark.
Paper: https://arxiv.org/abs/1907.05740
Github (Project): https://github.com/nv-tlabs/GSCNN
#DL #CV #NVidiaAI #Nvidia #autonomous #selfdriving #car #RL #segmentation
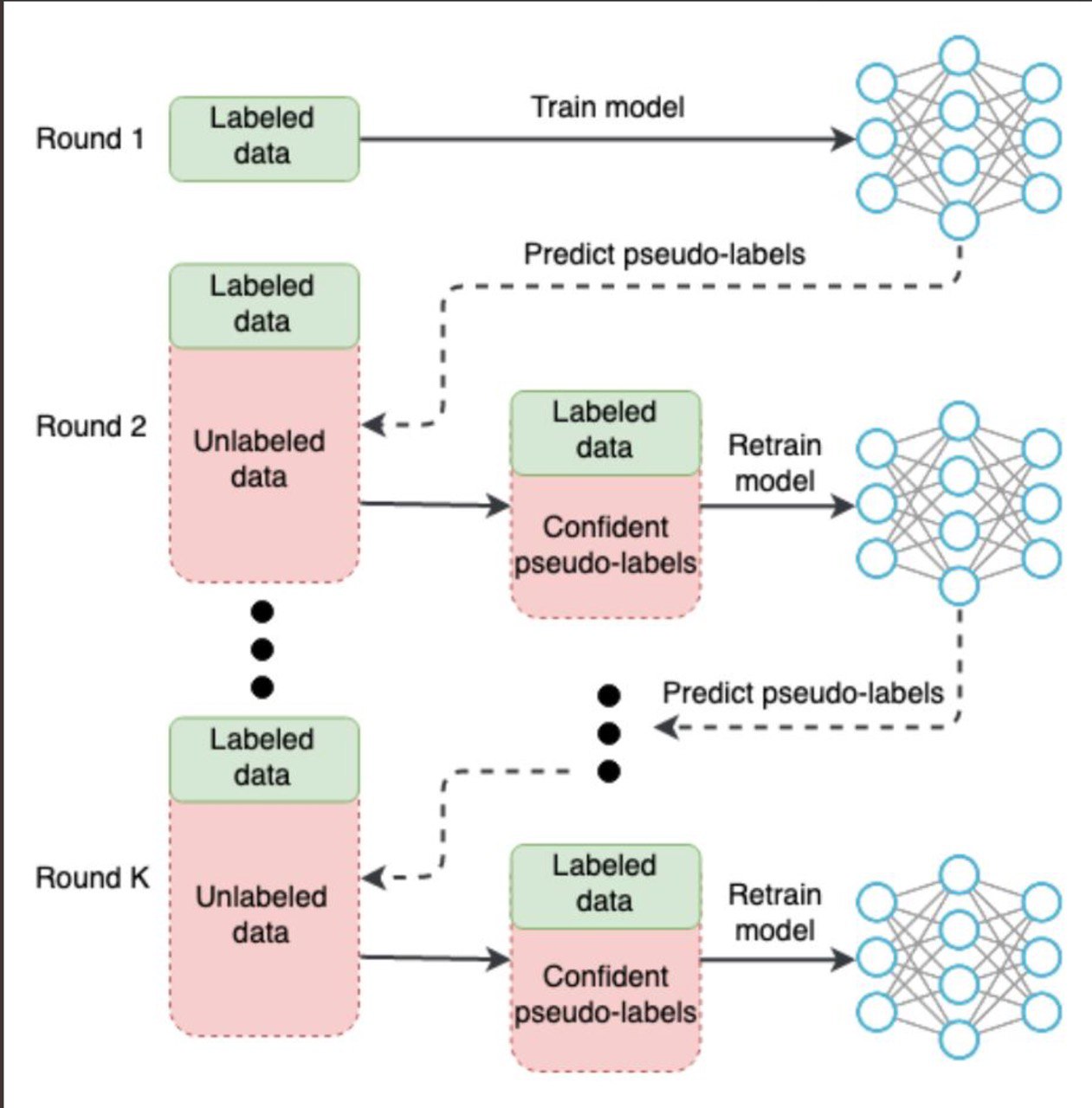
New paper on training with pseudo-labels for semantic segmentation
Semi-Supervised Segmentation of Salt Bodies in Seismic Images:
SOTA (1st place) at TGS Salt Identification Challenge.
Github: https://github.com/ybabakhin/kaggle_salt_bes_phalanx
ArXiV: https://arxiv.org/abs/1904.04445
#GCPR2019 #Segmentation #CV
Semi-Supervised Segmentation of Salt Bodies in Seismic Images:
SOTA (1st place) at TGS Salt Identification Challenge.
Github: https://github.com/ybabakhin/kaggle_salt_bes_phalanx
ArXiV: https://arxiv.org/abs/1904.04445
#GCPR2019 #Segmentation #CV
{kind=link}
Video on how Facebook continues to develop its #Portal device
How #Facebook used Mask R-CNN, #PyTorch, and custom hardware integrations like foveated processing to improve Portal’s Smart Camera system.
Link: https://ai.facebook.com/blog/smart-camera-portal-advances/
#CV #DL #Segmentation
How #Facebook used Mask R-CNN, #PyTorch, and custom hardware integrations like foveated processing to improve Portal’s Smart Camera system.
Link: https://ai.facebook.com/blog/smart-camera-portal-advances/
#CV #DL #Segmentation
Meta
How we’ve advanced Smart Camera for new Portal video-calling devices
We’ve used Detectron2, Mask R-CNN, and custom hardware integrations like foveated processing in order to make additional speed and precision improvements in the computer vision models that power Smart Camera.
YOLACT_ Real-Time Instance Segmentation [ICCV Trailer].mp4
19.2 MB
YOLACT: Real-time Instance Segmentation
Fully-convolutional model for real-time instance segmentation that achieves 29.8 mAP on MS COCO at 33.5 fps evaluated on a single Titan Xp, which is significantly faster than any previous competitive approach. They obtain this result after training on only one GPU.
video: https://www.youtube.com/watch?v=0pMfmo8qfpQ
paper: https://arxiv.org/abs/1904.02689
code: https://github.com/dbolya/yolact
#yolo #instance_segmentation #segmentation #real_time
Fully-convolutional model for real-time instance segmentation that achieves 29.8 mAP on MS COCO at 33.5 fps evaluated on a single Titan Xp, which is significantly faster than any previous competitive approach. They obtain this result after training on only one GPU.
video: https://www.youtube.com/watch?v=0pMfmo8qfpQ
paper: https://arxiv.org/abs/1904.02689
code: https://github.com/dbolya/yolact
#yolo #instance_segmentation #segmentation #real_time
BodyPix: Real-time Person Segmentation in the Browser with TensorFlow.js
Released BodyPix 2.0 with #multiperson support and improved accuracy (based on ResNet50), a new API, weight quantization, and support for different image sizes with TensorFlow.js
It estimates and renders person and body-part segmentation at 25 fps on a 2018 15-inch MacBook Pro, and 21 fps on an iPhone X.
code: https://github.com/tensorflow/tfjs-models/tree/master/body-pix
demo: https://storage.googleapis.com/tfjs-models/demos/body-pix/index.html
blog: https://blog.tensorflow.org/2019/11/updated-bodypix-2.html
#dl #segmentation
Released BodyPix 2.0 with #multiperson support and improved accuracy (based on ResNet50), a new API, weight quantization, and support for different image sizes with TensorFlow.js
It estimates and renders person and body-part segmentation at 25 fps on a 2018 15-inch MacBook Pro, and 21 fps on an iPhone X.
code: https://github.com/tensorflow/tfjs-models/tree/master/body-pix
demo: https://storage.googleapis.com/tfjs-models/demos/body-pix/index.html
blog: https://blog.tensorflow.org/2019/11/updated-bodypix-2.html
#dl #segmentation
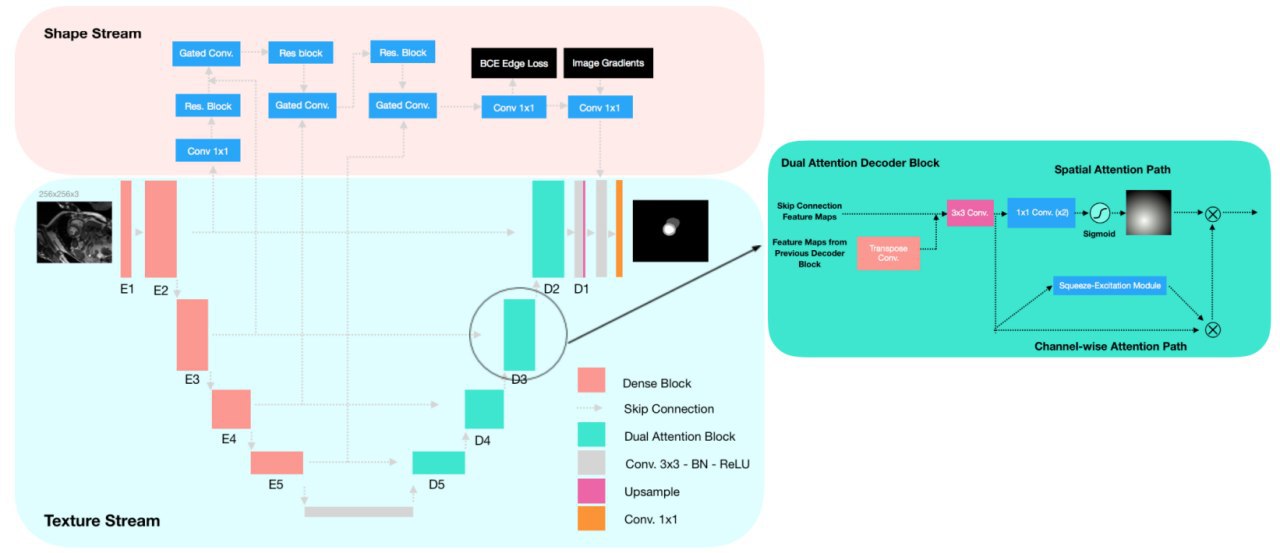
SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
{kind=link}
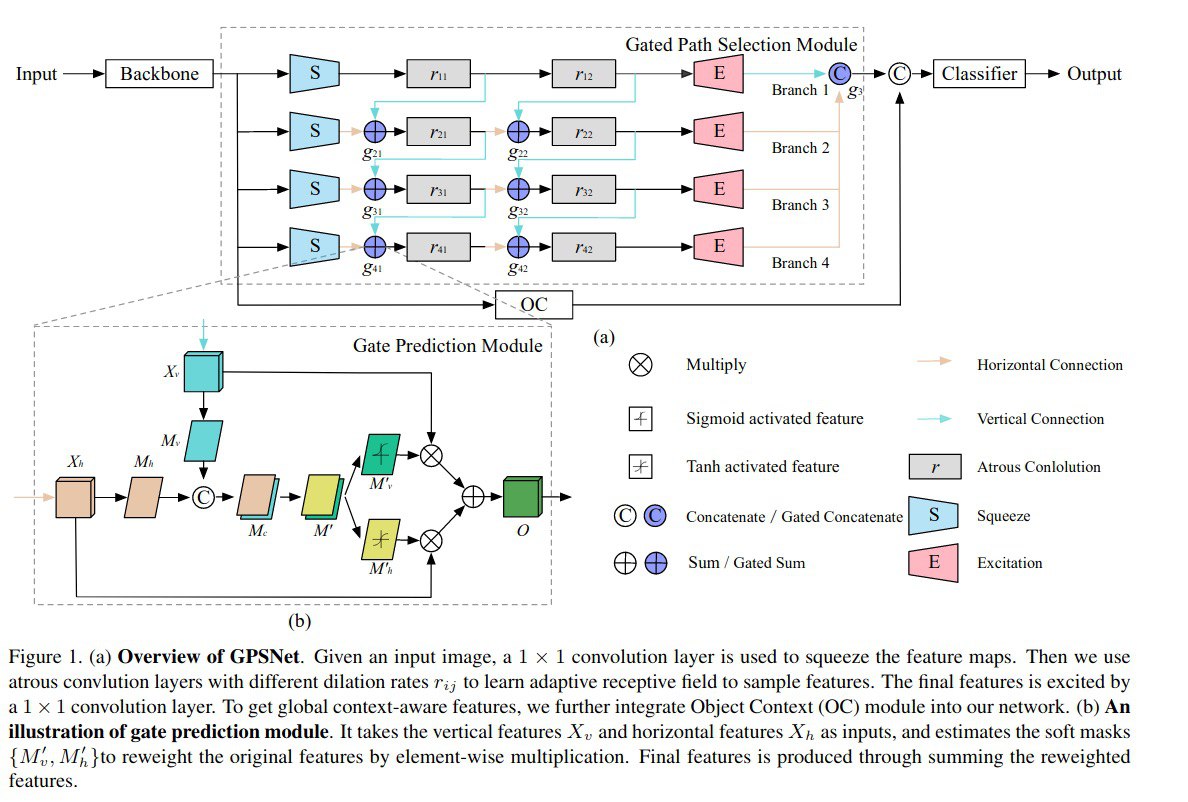
Gated Path Selection Network for Semantic Segmentation
A new approach for improving APSS-like networks for image segmentation.
Atrous Spatial Pyramid Pooling (ASPP) is an architecture that concatenates multiple atrous-convolved features using different dilution rates.
In this paper, authors develop a novel architecture named GPSNet, which aims to densely capture semantic context and to learn adaptive receptive fields, which are flexible to model various geometric deformations.
They designed architecture with multiple branches called SuperNet. The main characteristics are the following:
- it stacks a series of bottlenecked branches which consist of differently tuned dilation convolutions;
- multiple dense connections;
- a new module - Gate Prediction, which produces soft masks;
- improved sampling.
This approach was tested on Cityscapes и ADE20K datasets and showed better quality than other ASPP architectures, but still not as good as the current SOTA.
An ablation study shows that all changes introduced in this paper improve the score.
GPS module is lightweight and can be easily used in other models with ASPP architecture.
paper: https://deepai.org/publication/gated-path-selection-network-for-semantic-segmentation
#cv #semantic #segmentation #ASPP
A new approach for improving APSS-like networks for image segmentation.
Atrous Spatial Pyramid Pooling (ASPP) is an architecture that concatenates multiple atrous-convolved features using different dilution rates.
In this paper, authors develop a novel architecture named GPSNet, which aims to densely capture semantic context and to learn adaptive receptive fields, which are flexible to model various geometric deformations.
They designed architecture with multiple branches called SuperNet. The main characteristics are the following:
- it stacks a series of bottlenecked branches which consist of differently tuned dilation convolutions;
- multiple dense connections;
- a new module - Gate Prediction, which produces soft masks;
- improved sampling.
This approach was tested on Cityscapes и ADE20K datasets and showed better quality than other ASPP architectures, but still not as good as the current SOTA.
An ablation study shows that all changes introduced in this paper improve the score.
GPS module is lightweight and can be easily used in other models with ASPP architecture.
paper: https://deepai.org/publication/gated-path-selection-network-for-semantic-segmentation
#cv #semantic #segmentation #ASPP
{kind=link}
Albumentation – fast & flexible image augmentations
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
To date
The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
Albumentations were born out of necessity. The authors were actively participating in various Deep Learning competitions. To get to the top they needed something better than what was already available. All of them, independently, started working on more powerful augmentation pipelines. Later they merged their efforts and released the code in the form of the library.To date
Albumentations has more than 70 transforms and supports image classification, #segmentation, object and keypoint detection tasks.The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
GitHub
GitHub - albumentations-team/albumentations: Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078…
Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 - albumentations-team/albumentations
Image Segmentation: tips and tricks from 39 Kaggle competitions
this article gave you some background into #image #segmentation tips and tricks
also, collect some tools and frameworks that you can use to start competing
the author overview:
* architectures
* training tricks
* losses
* pre-processing
* post processing
* ensembling
* tools and frameworks
link here
this article gave you some background into #image #segmentation tips and tricks
also, collect some tools and frameworks that you can use to start competing
the author overview:
* architectures
* training tricks
* losses
* pre-processing
* post processing
* ensembling
* tools and frameworks
link here
neptune.ai
Image Segmentation: Tips and Tricks from 39 Kaggle Competitions
Learn about image segmentation insights from 39 Kaggle comps: evaluation methods, ensembling techniques, and post-processing strategies.
Automatic product tagging on photoes on Facebook Pages
#FacebookAI released an improvement aiming at enhancing shopping platform.
Post: https://ai.facebook.com/blog/powered-by-ai-advancing-product-understanding-and-building-new-shopping-experiences
Paper: https://scontent-arn2-1.xx.fbcdn.net/v/t39.8562-6/99353320_565175057533429_3886205100842024960_n.pdf
#GrokNet #DL #segmentation #PyTorch
#FacebookAI released an improvement aiming at enhancing shopping platform.
Post: https://ai.facebook.com/blog/powered-by-ai-advancing-product-understanding-and-building-new-shopping-experiences
Paper: https://scontent-arn2-1.xx.fbcdn.net/v/t39.8562-6/99353320_565175057533429_3886205100842024960_n.pdf
#GrokNet #DL #segmentation #PyTorch