
Baidu’s Optimized ERNIE Achieves State-of-the-Art Results in Natural Language Processing Tasks
#Baide developed ERNIE 2.0, a continual pre-training framework for language understanding. The model built on this framework has outperformed #BERT and #XLNet on 16 tasks in Chinese and English.
Link: http://research.baidu.com/Blog/index-view?id=121
#NLP #NLU
#Baide developed ERNIE 2.0, a continual pre-training framework for language understanding. The model built on this framework has outperformed #BERT and #XLNet on 16 tasks in Chinese and English.
Link: http://research.baidu.com/Blog/index-view?id=121
#NLP #NLU
spaCy meets PyTorch-Transformers: Fine-tune BERT, XLNet and GPT-2
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
pip install spacy-pytorch-transformers#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
explosion.ai
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2 · Explosion
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
Self-supervised QA from Facebook AI
The researchers from Facebook AI published a paper with the results of exploring the idea of unsupervised extractive question answering and the following training of the supervised question answering model. This approach achieves 56.41F1 on SQuAD2 dataset.
Original paper: https://research.fb.com/wp-content/uploads/2019/07/Unsupervised-Question-Answering-by-Cloze-Translation.pdf?
Code for experiments: https://github.com/facebookresearch/UnsupervisedQA
#NLP #BERT #FacebookAI #SelfSupervised
The researchers from Facebook AI published a paper with the results of exploring the idea of unsupervised extractive question answering and the following training of the supervised question answering model. This approach achieves 56.41F1 on SQuAD2 dataset.
Original paper: https://research.fb.com/wp-content/uploads/2019/07/Unsupervised-Question-Answering-by-Cloze-Translation.pdf?
Code for experiments: https://github.com/facebookresearch/UnsupervisedQA
#NLP #BERT #FacebookAI #SelfSupervised
Simple, Scalable Adaptation for Neural Machine Translation
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. Researchers from Google propose a simple yet efficient approach for adaptation in #NMT. Their proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously.
Guess it can be applied not only in #NMT but in many other #NLP, #NLU and #NLG tasks.
Paper: https://arxiv.org/pdf/1909.08478.pdf
#BERT #NMT #FineTuning
Fine-tuning pre-trained Neural Machine Translation (NMT) models is the dominant approach for adapting to new languages and domains. However, fine-tuning requires adapting and maintaining a separate model for each target task. Researchers from Google propose a simple yet efficient approach for adaptation in #NMT. Their proposed approach consists of injecting tiny task specific adapter layers into a pre-trained model. These lightweight adapters, with just a small fraction of the original model size, adapt the model to multiple individual tasks simultaneously.
Guess it can be applied not only in #NMT but in many other #NLP, #NLU and #NLG tasks.
Paper: https://arxiv.org/pdf/1909.08478.pdf
#BERT #NMT #FineTuning
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
It's the method for pre-training seq2seq models by de-noising text.
BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
They evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token.
BART matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, Q&A, and summarization tasks, with gains of up to 6 ROUGE.
Paper: https://arxiv.org/abs/1910.13461
#nlp #bert
It's the method for pre-training seq2seq models by de-noising text.
BART is trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
They evaluate a number of noising approaches, finding the best performance by both randomly shuffling the order of the original sentences and using a novel in-filling scheme, where spans of text are replaced with a single mask token.
BART matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new state-of-the-art results on a range of abstractive dialogue, Q&A, and summarization tasks, with gains of up to 6 ROUGE.
Paper: https://arxiv.org/abs/1910.13461
#nlp #bert
{kind=link}
Revealing the Dark Secrets of BERT
This work interpretation of self-attention.
Using a subset of GLUE tasks and a set of handcrafted features-of-interest, they proposed the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
The findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization.
Also, show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
paper: https://arxiv.org/abs/1908.08593
#nlp #bert
This work interpretation of self-attention.
Using a subset of GLUE tasks and a set of handcrafted features-of-interest, they proposed the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
The findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization.
Also, show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
paper: https://arxiv.org/abs/1908.08593
#nlp #bert
{kind=link}
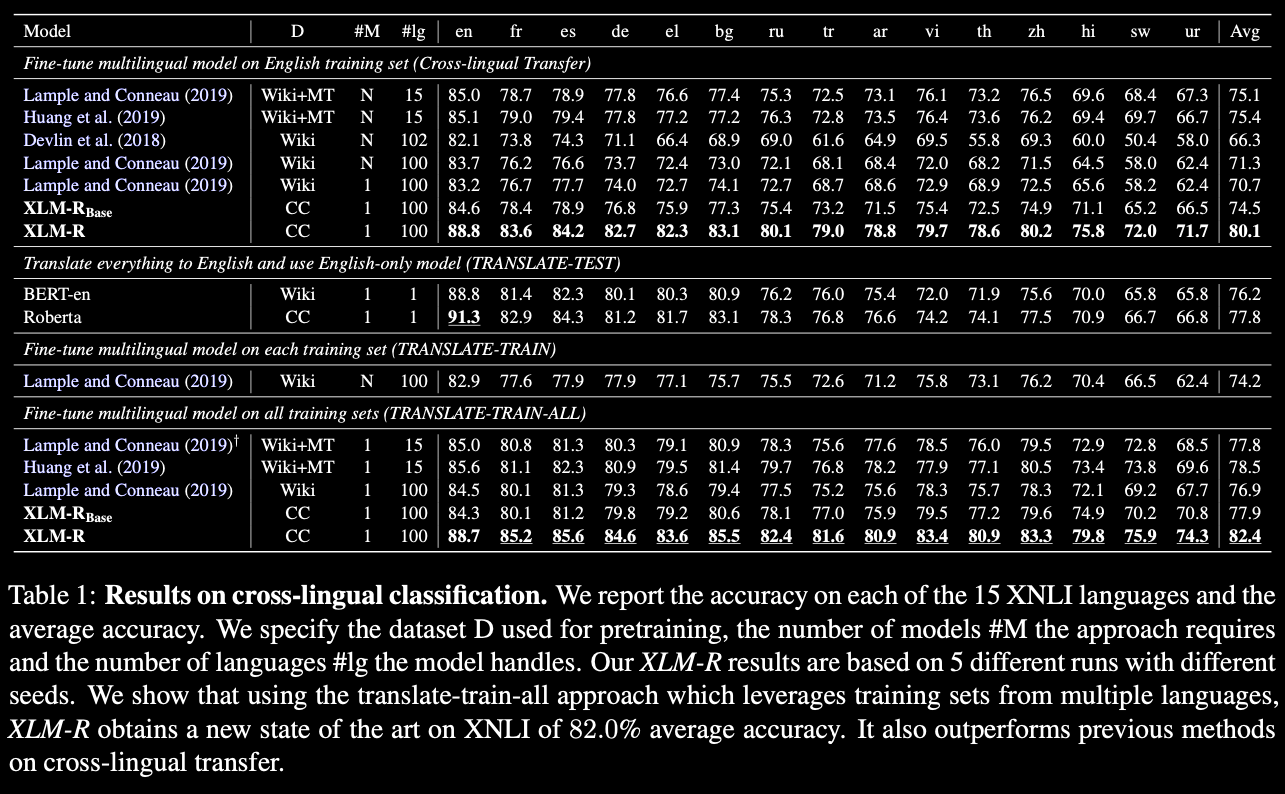
Unsupervised Cross-lingual Representation Learning at Scale
They release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data! Which obtains state-of-the-art performance on cross-lingual classification, sequence labeling and question answering.
Introduced a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI.
Soon on transformers by huggingface repo & at tf.hub
paper: https://arxiv.org/abs/1911.02116
code: https://github.com/pytorch/fairseq/tree/master/examples/xlmr
#nlp #bert #xlu #transformer
They release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data! Which obtains state-of-the-art performance on cross-lingual classification, sequence labeling and question answering.
Introduced a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI.
Soon on transformers by huggingface repo & at tf.hub
paper: https://arxiv.org/abs/1911.02116
code: https://github.com/pytorch/fairseq/tree/master/examples/xlmr
#nlp #bert #xlu #transformer
{kind=link}
CamemBERT
New state-of-the-art in French NLU 🇫🇷
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
Project page & examples: https://camembert-model.fr/
#nlp #bert #lm
New state-of-the-art in French NLU 🇫🇷
CamemBERT is a state-of-the-art language model for French based on the RoBERTa architecture pretrained on the French subcorpus of the newly available multilingual corpus OSCAR.
Project page & examples: https://camembert-model.fr/
#nlp #bert #lm
CamemBERT
A Tasty French Language Model
A Visual Guide to Using BERT for the First Time
A new blog post and notebook by Jay Alammar to get you started with using a pre-trained BERT model for the first time. It uses huggingface libs for sentence embedding and scikitLearn for classification
blog: https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time
#nlp #bert
A new blog post and notebook by Jay Alammar to get you started with using a pre-trained BERT model for the first time. It uses huggingface libs for sentence embedding and scikitLearn for classification
blog: https://jalammar.github.io/a-visual-guide-to-using-bert-for-the-first-time
#nlp #bert
{kind=link}
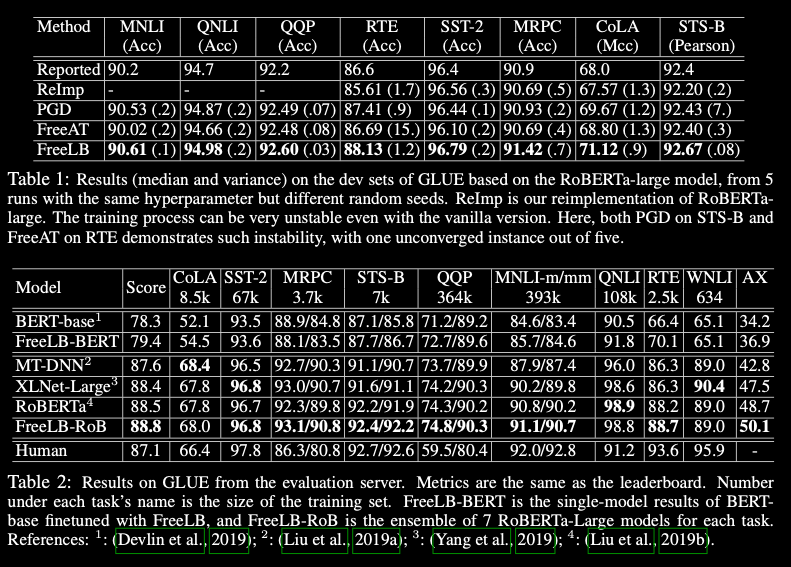
FreeLB: Enhanced Adversarial Training for Language Understanding
The authors propose a novel adversarial training algorithm – FreeLB, that promotes higher robustness and invariance in the embedding space, by adding adversarial perturbations to word embeddings and minimizing the resultant adversarial risk inside different regions around input samples, applied to Transformer-based models for NLU & commonsense reasoning tasks.
Experiments on the GLUE benchmark show that when applied only to the finetuning stage, it is able to improve the overall test scores:
* of BERT-based model from 78.3 -> 79.4
* RoBERTa-large model from 88.5 -> 88.8
The proposed approach achieves SOTA single-model test accuracies of 85.44% and 67.75% on ARC-Easy and ARC-Challenge.
paper: https://arxiv.org/abs/1909.11764
#nlp #nlu #bert #adversarial #ICLR
The authors propose a novel adversarial training algorithm – FreeLB, that promotes higher robustness and invariance in the embedding space, by adding adversarial perturbations to word embeddings and minimizing the resultant adversarial risk inside different regions around input samples, applied to Transformer-based models for NLU & commonsense reasoning tasks.
Experiments on the GLUE benchmark show that when applied only to the finetuning stage, it is able to improve the overall test scores:
* of BERT-based model from 78.3 -> 79.4
* RoBERTa-large model from 88.5 -> 88.8
The proposed approach achieves SOTA single-model test accuracies of 85.44% and 67.75% on ARC-Easy and ARC-Challenge.
paper: https://arxiv.org/abs/1909.11764
#nlp #nlu #bert #adversarial #ICLR
{kind=link}