
ZeRO, DeepSpeed & Turing-NLG
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
1. Add Gradient Partitioning (
2. Add Parameter Partitioning (
They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models
Turing-NLG: A 17-billion-parameter language model by Microsoft
Microsoft is releasing an open-source library called DeepSpeed, which vastly advances large model training by improving scale, speed, cost, and usability, unlocking the ability to train 100-billion-parameter models; compatible with PyTorch.
ZeRO – is a new parallelized optimizer that greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained.
ZeRO has three main optimization stages, which correspond to the partitioning of optimizer states, gradients, and parameters. When enabled cumulatively:
0. Optimizer State Partitioning (
P_os_) – 4x memory reduction, same communication volume as data parallelism1. Add Gradient Partitioning (
P_os+g_) – 8x memory reduction, same communication volume as data parallelism2. Add Parameter Partitioning (
P_os+g+p_) – memory reduction is linear with data parallelism degree N_d_They have used these breakthroughs to create Turing Natural Language Generation (Turing-NLG), the largest publicly known language model at 17 billion parameters, which you can learn more about in this accompanying blog post. Also, the abstract for Turing-NLG had been written by their own model
ZeRO & DeepSpeed: https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/
paper: https://arxiv.org/abs/1910.02054
github: https://github.com/microsoft/DeepSpeed
Turing-NLG: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
#nlp #dl #ml #microsoft #deepspeed #optimization
{kind=link}
Extending relational query processing with ML inference
In some way, it may sound like something strange, but in a close view, it is a brilliant idea in our opinion.
Microsoft develops SQL DB with an inference ML model inside them. So you can do SQL query with a model like usual query alongside good optimization and runtimes as part of the builtin functionality of SQL engine. Data scientists develop an ML model with a pipeline and just put it inside the database. A stored model with the pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
So:
0. A statement adds the source code for the model pipeline (Python in the example) to the database.
1. At some later point, a SQL query is issued which a model and then uses the function to generate a prediction from the model given some input data (which is itself, of course, the result of a query).
2. The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
3. A cross-optimizer then looks for opportunities to optimize the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
4. A runtime code generator creates a SQL query incorporating all of these optimizations.
5. An extended version of SQL Server, with an integrated ONNX Runtime engine, executes the query.
Neural network translation optimizations replace classical ML operators and data features with NN that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow.
paper (.pdf): http://cidrdb.org/cidr2020/papers/p24-karanasos-cidr20.pdf
blogpost: https://blog.acolyer.org/2020/02/21/extending-relational-query-processing/
software: https://azure.microsoft.com/en-gb/services/sql-database-edge/
#ml #db #sql
In some way, it may sound like something strange, but in a close view, it is a brilliant idea in our opinion.
Microsoft develops SQL DB with an inference ML model inside them. So you can do SQL query with a model like usual query alongside good optimization and runtimes as part of the builtin functionality of SQL engine. Data scientists develop an ML model with a pipeline and just put it inside the database. A stored model with the pipeline can then be invoked a bit like a stored procedure by issuing SQL commands.
So:
0. A statement adds the source code for the model pipeline (Python in the example) to the database.
1. At some later point, a SQL query is issued which a model and then uses the function to generate a prediction from the model given some input data (which is itself, of course, the result of a query).
2. The combined model and query undergo static analysis to produce an intermediate representation (IR) of the prediction computation as a DAG.
3. A cross-optimizer then looks for opportunities to optimize the data operator parts of the query given the ML model, and vice-versa (e.g., pruning).
4. A runtime code generator creates a SQL query incorporating all of these optimizations.
5. An extended version of SQL Server, with an integrated ONNX Runtime engine, executes the query.
Neural network translation optimizations replace classical ML operators and data features with NN that can be executed directly in e.g. ONNX Runtime, PyTorch, or TensorFlow.
paper (.pdf): http://cidrdb.org/cidr2020/papers/p24-karanasos-cidr20.pdf
blogpost: https://blog.acolyer.org/2020/02/21/extending-relational-query-processing/
software: https://azure.microsoft.com/en-gb/services/sql-database-edge/
#ml #db #sql
{kind=link}
TensorFlow Quantum
A Software Framework for Quantum Machine Learning
Introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data.
TFQ provides the tools necessary for bringing the quantum computing and ML research communities together to control and model natural or artificial quantum systems; e.g. Noisy Intermediate Scale Quantum (NISQ) processors with ~50-100 qubits.
A quantum model has the ability to represent and generalize data with a quantum mechanical origin. However, to understand quantum models, two concepts must be introduced – quantum data and hybrid quantum-classical models.
Quantum data exhibits superposition and entanglement, leading to joint probability distributions that could require an exponential amount of classical computational resources to represent or store. Quantum data, which can be generated/simulated on quantum processors/sensors/networks include the simulation of chemicals and quantum matter, quantum control, quantum communication networks, quantum metrology, and much more.
Quantum models cannot use quantum processors alone – NISQ processors will need to work in concert with classical processors to become effective. As TensorFlow already supports heterogeneous computing across CPUs, GPUs, and TPUs, it is a natural platform for experimenting with hybrid quantum-classical algorithms.
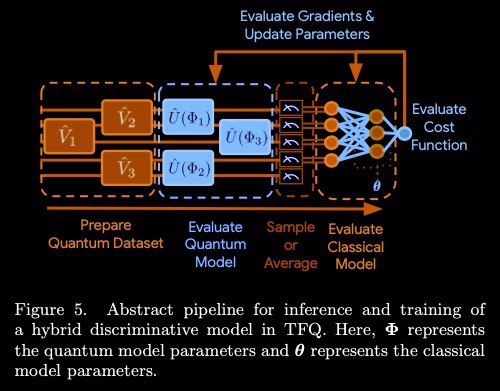
To build and train such a model, the researcher can do the following:
– prepare a quantum dataset
– evaluate a quantum NN model
- sample or Average
– evaluate a classical NN model
– evaluate сost function
– evaluate gradients & update parameters
blog post: https://ai.googleblog.com/2020/03/announcing-tensorflow-quantum-open.html
paper: https://arxiv.org/abs/2003.02989
#tfq #tensorflow #quantum #physics #ml
A Software Framework for Quantum Machine Learning
Introduce TensorFlow Quantum (TFQ), an open source library for the rapid prototyping of hybrid quantum-classical models for classical or quantum data.
TFQ provides the tools necessary for bringing the quantum computing and ML research communities together to control and model natural or artificial quantum systems; e.g. Noisy Intermediate Scale Quantum (NISQ) processors with ~50-100 qubits.
A quantum model has the ability to represent and generalize data with a quantum mechanical origin. However, to understand quantum models, two concepts must be introduced – quantum data and hybrid quantum-classical models.
Quantum data exhibits superposition and entanglement, leading to joint probability distributions that could require an exponential amount of classical computational resources to represent or store. Quantum data, which can be generated/simulated on quantum processors/sensors/networks include the simulation of chemicals and quantum matter, quantum control, quantum communication networks, quantum metrology, and much more.
Quantum models cannot use quantum processors alone – NISQ processors will need to work in concert with classical processors to become effective. As TensorFlow already supports heterogeneous computing across CPUs, GPUs, and TPUs, it is a natural platform for experimenting with hybrid quantum-classical algorithms.
To build and train such a model, the researcher can do the following:
– prepare a quantum dataset
– evaluate a quantum NN model
- sample or Average
– evaluate a classical NN model
– evaluate сost function
– evaluate gradients & update parameters
blog post: https://ai.googleblog.com/2020/03/announcing-tensorflow-quantum-open.html
paper: https://arxiv.org/abs/2003.02989
#tfq #tensorflow #quantum #physics #ml
{kind=link}
Survey of machine-learning experimental methods at NeurIPS2019 and ICLR2020
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Twitter
Delip Rao
Survey of #MachineLearning experimental methods (aka "how do ML folks do their experiments") at #NeurIPS2019 and #ICLR2020, a thread of results:
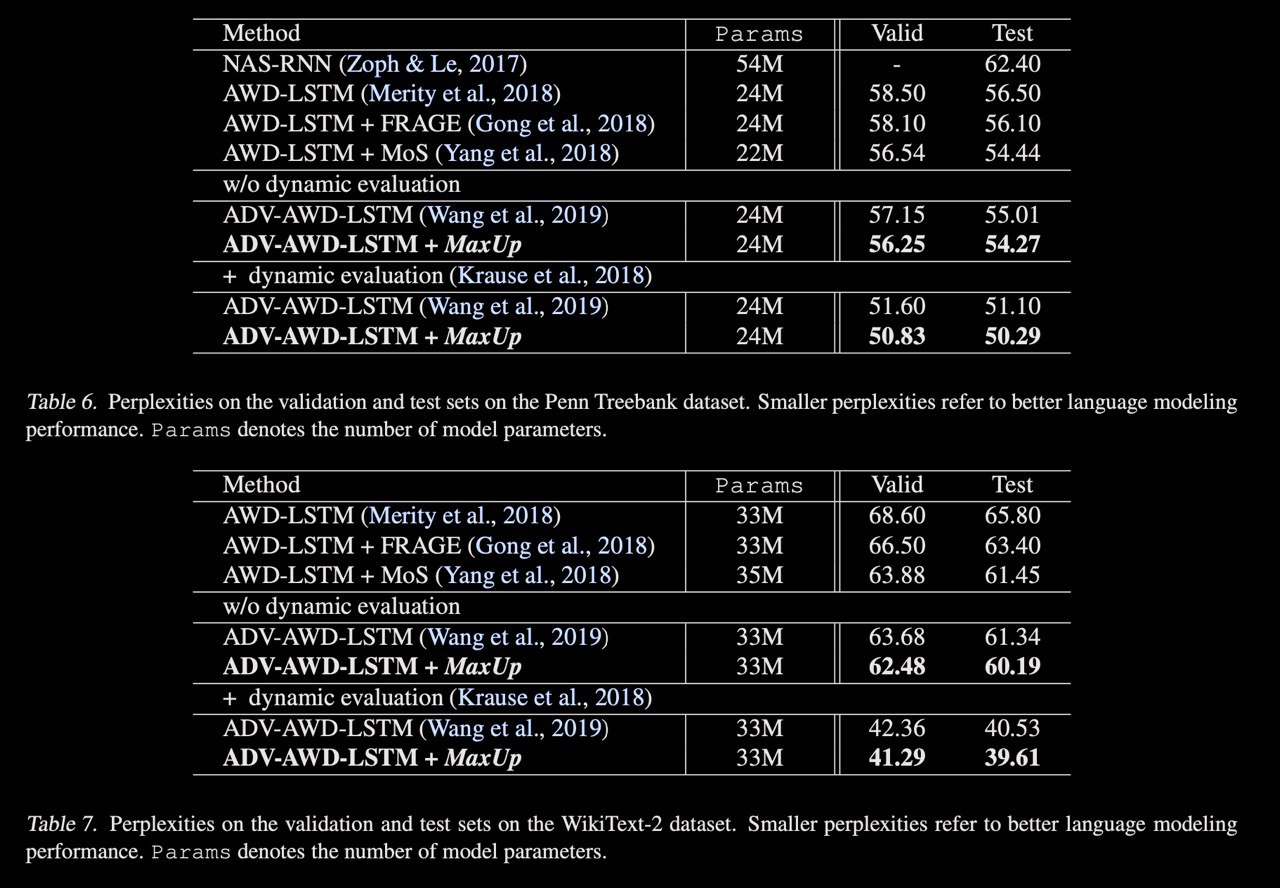
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
m times and then found aug with maximum loss and does backprop only through that. i.e. minimizing max loss.There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
augs without the overhead. Only m times to forward pass on the sample but one time to backprop. paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
{kind=link}
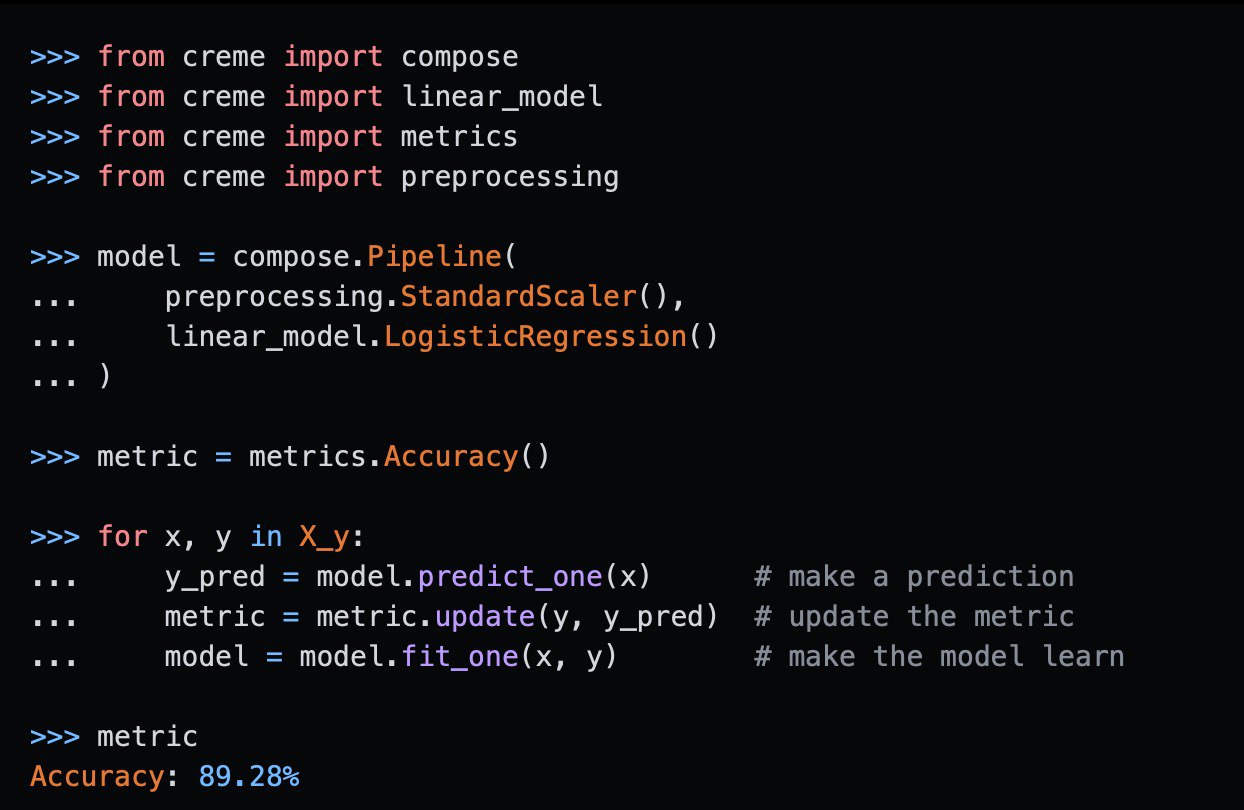
CREME – python library for online ML
All the tools in the library can be updated with a single observation at a time, and can therefore be used to learn from streaming data.
The model learns from one observation at a time, and can therefore be updated on the fly. This allows to learn from massive datasets that don't fit in main memory. Online machine learning also integrates nicely in cases where new data is constantly arriving. It shines in many use cases, such as time series forecasting, spam filtering, recommender systems, CTR prediction, and IoT applications. If you're bored with retraining models and want to instead build dynamic models, then online machine learning might be what you're looking for.
Here are some benefits of using creme (and online machine learning in general):
• incremental – models can update themselves in real-time
• adaptive – models can adapt to concept drift
• production-ready – working with data streams makes it simple to replicate production scenarios during model development
• efficient – models don't have to be retrained and require little compute power, which lowers their carbon footprint
api reference: https://creme-ml.github.io/content/api.html
github: https://github.com/creme-ml/creme
#ml #online #learning
All the tools in the library can be updated with a single observation at a time, and can therefore be used to learn from streaming data.
The model learns from one observation at a time, and can therefore be updated on the fly. This allows to learn from massive datasets that don't fit in main memory. Online machine learning also integrates nicely in cases where new data is constantly arriving. It shines in many use cases, such as time series forecasting, spam filtering, recommender systems, CTR prediction, and IoT applications. If you're bored with retraining models and want to instead build dynamic models, then online machine learning might be what you're looking for.
Here are some benefits of using creme (and online machine learning in general):
• incremental – models can update themselves in real-time
• adaptive – models can adapt to concept drift
• production-ready – working with data streams makes it simple to replicate production scenarios during model development
• efficient – models don't have to be retrained and require little compute power, which lowers their carbon footprint
api reference: https://creme-ml.github.io/content/api.html
github: https://github.com/creme-ml/creme
#ml #online #learning
{kind=link}
Data Version Control
open-source version control system for ML projects
DVC is a new type of experiment management software that has been built on top of the existing engineering toolset particularly on a source code version control system (currently Git). DVC reduces the gap between existing tools and data science needs, allowing users to take advantage of experiment management software while reusing existing skills and intuition.
Key features:
[0] simple command line Git-like experience. It does not require installing and maintaining any databases. It does not depend on any proprietary online services
[1] management and versioning of datasets and ML models. Data is saved in S3, Google Cloud, Azure, Alibaba cloud, SSH server, HDFS, or even local HDD RAID
[2] makes projects reproducible and shareable; helping to answer questions about how a model was built
[3] helps manage experiments with Git tags/branches and metrics tracking
The main commands :feelsgoodmeme:
webpage: https://dvc.org
docs: https://dvc.org/doc
github: https://github.com/iterative/dvc
:ods: channel: #tool_dvc
#dvc #version #control #ml #projects #system #git
open-source version control system for ML projects
DVC is a new type of experiment management software that has been built on top of the existing engineering toolset particularly on a source code version control system (currently Git). DVC reduces the gap between existing tools and data science needs, allowing users to take advantage of experiment management software while reusing existing skills and intuition.
Key features:
[0] simple command line Git-like experience. It does not require installing and maintaining any databases. It does not depend on any proprietary online services
[1] management and versioning of datasets and ML models. Data is saved in S3, Google Cloud, Azure, Alibaba cloud, SSH server, HDFS, or even local HDD RAID
[2] makes projects reproducible and shareable; helping to answer questions about how a model was built
[3] helps manage experiments with Git tags/branches and metrics tracking
The main commands :feelsgoodmeme:
$ dvc add <name_file>$ dvc run <name_file>$ dvc [push/pull]webpage: https://dvc.org
docs: https://dvc.org/doc
github: https://github.com/iterative/dvc
:ods: channel: #tool_dvc
#dvc #version #control #ml #projects #system #git
{kind=link}
Last day to apply for free Skoltech's Summer School of Machine Learning
Benefits of School:
+ top speakers from leading Data Science centers
+ new knowledge and advanced trends in statistical methods of machine learning.
+ free participation
How to apply:
Today is the LAST DAY to apply to school at the website
Link: https://smiles.skoltech.ru/school
#openedu #course #free #ml
Benefits of School:
+ top speakers from leading Data Science centers
+ new knowledge and advanced trends in statistical methods of machine learning.
+ free participation
How to apply:
Today is the LAST DAY to apply to school at the website
Link: https://smiles.skoltech.ru/school
#openedu #course #free #ml
{kind=link}
Simple book about #ML — Machine Learning Simplified
The main purpose of the book is to build an intuitive understanding of how algorithms work through basic examples. In order to understand the presented material, it is enough to know basic mathematics and linear algebra.
After reading this book, you will know the basics of supervised learning, understand complex mathematical models, understand the entire pipeline of a typical ML project, and also be able to share your knowledge with colleagues from related industries and with technical professionals.
And for those who find the theoretical part not enough - the book is supplemented with a repository on GitHub, which has Python implementation of all methods and algorithms described in chapters.
Book is absolutely free to read.
Link: themlsbook.com
#wheretostart #book
The main purpose of the book is to build an intuitive understanding of how algorithms work through basic examples. In order to understand the presented material, it is enough to know basic mathematics and linear algebra.
After reading this book, you will know the basics of supervised learning, understand complex mathematical models, understand the entire pipeline of a typical ML project, and also be able to share your knowledge with colleagues from related industries and with technical professionals.
And for those who find the theoretical part not enough - the book is supplemented with a repository on GitHub, which has Python implementation of all methods and algorithms described in chapters.
Book is absolutely free to read.
Link: themlsbook.com
#wheretostart #book
{kind=link}
Reliable ML track at Data Fest Online 2023
Call for Papers
Friends, we are glad to inform you that the largest Russian-language conference on Data Science - Data Fest - from the Open Data Science community will take place in 2023 (at the end of May).
And it will again have a section from Reliable ML community. We are waiting for your applications for reports: write directly to me or Dmitry.
Track Info
The concept of Reliable ML is about what to do so that the result of the work of data teams would be, firstly, applicable in the business processes of the customer company and, secondly, brought benefits to this company.
For this you need to be able to:
- correctly build a portfolio of projects (#business)
- think over the system design of each project (#ml_system_design)
- overcome various difficulties when developing a prototype (#tech #causal_inference #metrics)
- explain to the business that your MVP deserves a pilot (#interpretable_ml)
- conduct a pilot (#causal_inference #ab_testing)
- implement your solution in business processes (#tech #mlops #business)
- set up solution monitoring in the productive environment (#tech #mlops)
If you have something to say on the topics above, write to us! If in doubt, write anyway. Many of the coolest reports of previous Reliable ML tracks have come about as a result of discussion and collaboration on the topic.
If you are not ready to make a report but want to listen to something interesting, you can still help! Repost to a relevant community / forward to a friend = participate in the creation of good content.
Registration and full information about Data Fest 2023 is here.
@Reliable ML
Call for Papers
Friends, we are glad to inform you that the largest Russian-language conference on Data Science - Data Fest - from the Open Data Science community will take place in 2023 (at the end of May).
And it will again have a section from Reliable ML community. We are waiting for your applications for reports: write directly to me or Dmitry.
Track Info
The concept of Reliable ML is about what to do so that the result of the work of data teams would be, firstly, applicable in the business processes of the customer company and, secondly, brought benefits to this company.
For this you need to be able to:
- correctly build a portfolio of projects (#business)
- think over the system design of each project (#ml_system_design)
- overcome various difficulties when developing a prototype (#tech #causal_inference #metrics)
- explain to the business that your MVP deserves a pilot (#interpretable_ml)
- conduct a pilot (#causal_inference #ab_testing)
- implement your solution in business processes (#tech #mlops #business)
- set up solution monitoring in the productive environment (#tech #mlops)
If you have something to say on the topics above, write to us! If in doubt, write anyway. Many of the coolest reports of previous Reliable ML tracks have come about as a result of discussion and collaboration on the topic.
If you are not ready to make a report but want to listen to something interesting, you can still help! Repost to a relevant community / forward to a friend = participate in the creation of good content.
Registration and full information about Data Fest 2023 is here.
@Reliable ML
🔥 Say Goodbye to LoRA, Hello to DoRA 🤩🤩
DoRA consistently outperforms LoRA with various tasks (LLM, LVLM, etc.) and backbones (LLaMA, LLaVA, etc.)
[Paper] https://arxiv.org/abs/2402.09353
[Code] https://github.com/NVlabs/DoRA
#Nvidia
#icml #PEFT #lora #ML #ai
@opendatascience
DoRA consistently outperforms LoRA with various tasks (LLM, LVLM, etc.) and backbones (LLaMA, LLaVA, etc.)
[Paper] https://arxiv.org/abs/2402.09353
[Code] https://github.com/NVlabs/DoRA
#Nvidia
#icml #PEFT #lora #ML #ai
@opendatascience
Forwarded from Machinelearning
FoleyCrafter - методика, разработанная для автоматического создания звуковых эффектов, синхронизированных с целевым видеорядом
Архитектура метода построена на основе предварительно обученной модели преобразования текста в аудио (Text2Audio). Система состоит из двух ключевых компонентов:
Оба компонента являются обучаемыми модулями, которые принимают видео в качестве входных данных для синтеза аудио. При этом модель Text2Audio остается фиксированной для сохранения ее способности к синтезу аудио постоянного качества.
Разработчики FoleyCrafter провели количественные и качественные эксперименты на наборах данных VGGSound и AVSync15 по метрикам семантического соответствия MKL, CLIP Score, FID и временной синхронизации Onset ACC, Onset AP.
По сравнению с существующими методами Text2Audio (SpecVQGAN, Diff-Foley и V2A-Mapper) FoleyCrafter показал лучшие результаты.
# Clone the Repository
git clone https://github.com/open-mmlab/foleycrafter.git
# Navigate to the Repository
cd projects/foleycrafter
# Create Virtual Environment with Conda & Install Dependencies
conda create env create -f requirements/environment.yaml
conda activate foleycrafter
# Install GiT LFS
conda install git-lfs
git lfs install
# Download checkpoints
git clone https://huggingface.co/auffusion/auffusion-full-no-adapter checkpoints/auffusion
git clone https://huggingface.co/ymzhang319/FoleyCrafter checkpoints/
# Run Gradio
python app.py --share
🔗 Лицензирование: Apache-2.0
🔗Страница проекта
🔗Arxiv
🔗Модели на HF
🔗Demo
🔗Github [ Stars: 272 | Issues: 4 | Forks: 15]
@ai_machinelearning_big_data
#AI #Text2Audio #FoleyCrafter #ML
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
ControlNet++ - это набор моделей ControlNet, собранный на новой архитектуре и упакованный в один единый файл без необходимости скачивать дополнительные препроцессоры и наборы моделей.
Обновление ProMaх включает в себя весь существующий набор ControlNet Union, в который были добавлены возможности комбинации нескольких типов ControlNet к одному исходному изображению и новые функции Tile Deblur, Tile Superresolution, Tile Variation, Inpaint и Outpaint.
C учетом обновления, набор ControlNet ProMax выполняет 12 функций и 5 дополнительных методик редактирования изображений:
В архитектуре ControlNet++ были разработаны два новых модуля: Condition Transformer и Control Encoder, которые улучшают представление и обработку условий в модели.
Каждому условию назначается уникальный идентификатор типа управления, который преобразуется в эмбеддинги.
Condition Transformer позволяет обрабатывать несколько условий одновременно, используя один кодировщик и включает слой трансформера для обмена информацией между исходным изображением и условными изображениями.
Condition Encoder увеличивает количество каналов свертки для повышения представительной способности, сохраняя оригинальную архитектуру.
Также была использована единая стратегия обучения, которая одновременно оптимизировала сходимость для одиночных условий и управляла слиянием множественных условий, повышая устойчивость сети и ее способность к генерации качественных изображений.
ControlNet Pro Max поддерживает работу с любой генеративной моделью семейства Stable Diffusion XL. Поддержка семейства Stable Diffusion 3 находится в разработке.
@ai_machinelearning_big_data
#AI #ControlNet #ML #Diffusers #SDXL
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
Qwen2-Audio - аудио-языковых модель, которая способна принимать аудио и текст на вход и генерировать текст на выходе.
Предусмотрено два режима взаимодействия:
Обе опубликованные модели поддерживают 8 языков и диалектов: китайский, английский, кантонский, французский, итальянский, испанский, немецкий и японский:
Инференс на transformers в cli возможен в нескольких режимах:
# Ensure you have latest Hugging face transformers
pip install git+https://github.com/huggingface/transformers
# to build a web UI demoinstall the following packages
pip install -r requirements_web_demo.txt
# run Gradio web UI
python demo/web_demo_audio.py
@ai_machinelearning_big_data
#AI #LLM #ML #Qwen2
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
В Яндексе подробно рассказали про новую технологию, которую стали использовать в Яндекс Погоде. OmniCast работает на основе нейросетей, которые рассчитывают температуру воздуха, учитывая множество факторов, в том числе один совершенно новый — любительские метеостанции.
OmniCast помогает решать проблему точности прогноза в разных локальных районах мегаполисов. Подробнее про то, как работает метод, написано в статье.
▪️Хабр
@ai_machinelearning_big_data
#AI #ML #OmniCast
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
This open-source RAG tool for chatting with your documents is Trending at Number-1 in Github from the past few days
🔍 Open-source RAG UI for document QA
🛠️ Supports local LLMs and API providers
📊 Hybrid RAG pipeline with full-text & vector retrieval
🖼️ Multi-modal QA with figures & tables support
📄 Advanced citations with in-browser PDF preview
🧠 Complex reasoning with question decomposition
⚙️ Configurable settings UI
🔧 Extensible Gradio-based architecture
Key features:
🌐 Host your own RAG web UI with multi-user login
🤖 Organize LLM & embedding models (local & API)
🔎 Hybrid retrieval + re-ranking for quality
📚 Multi-modal parsing and QA across documents
💡 Detailed citations with relevance scores
🧩 Question decomposition for complex queries
🎛️ Adjustable retrieval & generation settings
🔌 Customizable UI and indexing strategies
#rag #ml
▪ Github
@opendatascience
🔍 Open-source RAG UI for document QA
🛠️ Supports local LLMs and API providers
📊 Hybrid RAG pipeline with full-text & vector retrieval
🖼️ Multi-modal QA with figures & tables support
📄 Advanced citations with in-browser PDF preview
🧠 Complex reasoning with question decomposition
⚙️ Configurable settings UI
🔧 Extensible Gradio-based architecture
Key features:
🌐 Host your own RAG web UI with multi-user login
🤖 Organize LLM & embedding models (local & API)
🔎 Hybrid retrieval + re-ranking for quality
📚 Multi-modal parsing and QA across documents
💡 Detailed citations with relevance scores
🧩 Question decomposition for complex queries
🎛️ Adjustable retrieval & generation settings
🔌 Customizable UI and indexing strategies
#rag #ml
▪ Github
@opendatascience
Forwarded from Machinelearning
PuLID (Pure and Lightning ID Customization) - метод генерации на основе внешности для диффузных моделей с управлением текстовым промптом. Ключевое преимущество PuLID состоит в его способности генерировать изображения с высокой степенью соответствия заданной личности, следуя заданным стилю и композиции.
PuLID для SD существует относительно давно и неплохо работал с моделями SDXL. Теперь этот метод стал доступен для FLUX-dev:
--aggressive_offload, но генерация будет выполняться очень, очень, очень медленно.В PuLID for FLUX есть два критически важных гиперпараметра:
timestep to start inserting ID. Этот параметр управляет там, в какой момент ID (лицо с входного изображения) будет вставлен в DIT (значение 0 - ID будет вставляться с первого шага). Градация: чем меньше значение - тем более похожим на исходный портрет будет результат. Рекомендованное значение для фотореализма - 4.true CFG scale. Параметр, модулирующий CFG-значение. Исходный процесс CFG метода PuLID, который требовал удвоенного количества этапов вывода, преобразован в шкалу управления чтобы имитировать истинный процесс CFG с половиной шагов инференса.Для возможности гибкой настройки результатов, разработчик оставил оба гиперпараметра : CFG FLUX и true CFG scale. Фотореализм получается лучше с применением true CFG scale, но если финальное сходство внешности с оригиналом не устраивает - вы можете перейти на обычный CFG.
Запуск возможен несколькими способами: GradioUI, Google Collab (free tier), Google Collab (pro tier) или с одним из имплементаций для среды ComfyUI:
⚠️ Важно!
# clone PuLID repo
git clone https://github.com/ToTheBeginning/PuLID.git
cd PuLID
# create conda env
conda create --name pulid python=3.10
# activate env
conda activate pulid
# Install dependent packages
# 1. For SDXL or Flux-bf16, install the following
pip install -r requirements.txt
# 2. For Flux-fp8, install this
pip install -r requirements_fp8.txt
# Run Gradio UI
python app.py
@ai_machinelearning_big_data
#AI #ML #FLUX #GenAI #PuLID
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
Forwarded from Machinelearning
В Google рассказали про схему итеративного взвешивания плотности (iterative density weighting scheme, IDW), которая помогает равномерно распределять интересы пользователя.
Она уменьшает влияние дисбалансированных данных и улучшает кластеризацию элементов, анализируя плотность предметов в пространстве представлений.
В подробном разборе статьи от ml-спецов Яндекса рассказали про устройство IDW и кратко привели результаты эксперимента.
@ai_machinelearning_big_data
#AI #ML #tech
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM