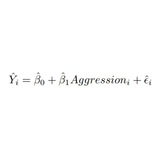
Пра правалы, статыстыку, машнные навучанне, індустрыю і акадэмію. Частка 1
Выпадковы выдаліў, перазаліваю
#statistics #machinelearning
Правалы - гэта неад'емная, мабыць ключавая частка развіцця навукі, ды і ўвогуле развіцця. Вакол гэтай ідэі існуе шмат добрых канцэптаў, напрыклад - failure CV. Але я хачу распавесці не проста пра няўдачы, а пра канкрэтны трэш ва ўжыванні статыстыкі і пабудове статыстычных мадэляў: у акадэміі, а таксама ў індустрыі.
З акадэміяй у гэтым плане вельмі проста, бо ўсё задакументавана. З індустрыяй нашмат больш складана, бо бізнэс-спецыфіка, NDA, а таксама жаданне абмежаваць рэпутацыйныя выдаткі. Таму пачнем з індустрыі. Частка гэтых гісторый - хутчэй за ўсё байкі. Частка - абсалютна рэальныя і я нават ведаю ўдзельнікаў. Істотна, аднак, што кожная з іх магла здарыцца з аднолькавай верагоднасцю і магчыма здаралася неаднойчы.
З улікам таго, што пра “AI failures” пішуць шмат, а ад гісторый кшталту “напужаны Цукенберг закрыў АІ праэкт, таму што нейронкі стварылі сваю сакрэтную мову” у мяне пачынае балець галава, распавядаць я буду пра банальныя, чалавечыя, прыземленыя індустрыйныя правалы.
Большасць фэйлаў ў машынным навучанні добра апісваецца анекдотам пра “хачу сабе танк на ўсю спіну – гатова – а чаму так хутка? – а хулі там чатыры літары”. Таму першая байка – пра савецкія/расійскія і амерыканскія танкі. Алгарытм павінен быў навучыцца іх адрозніваць. Працаваў добра, але ўпарта класіфікаваў новыя расійскія мадэлі як амерыканскія. Разбор паказаў, што фота савецкіх танкаў былі горшай якасці, што алгарытм паспяхова і вывучыў. Альтэрнатыўная версія гэтай байкі: алгарытм вучылі адрозніваць танкі, замаскіраваныя ў лесе, ад проста фота лясных масіваў, але два тыпы фота былі зробленыя ў розныя дні, таму алгарытм вырашыў, што прасцей замест танкаў адрозніваць воблачнасць.
Наступная байка - пра алгарытм, які павінен адрозніваць хаскі ад ваўкоў. Спрабуючы ўявіць сабе практычны сэнс такога алгарытму, я прыйшоў да высновы, што мець магчымасць адрозніць хаскі ад воўка смартфонам, у лесе, ноччу, калі нешта рыкае ў метры ад цябе ў цемры – гэта сапраўды карысна і шматабяцальна. Гісторыя ў тым, што алгарытм паказаў сябе вельмі добра, апроч рэдкіх кейсаў, дзе расава чыстыя хаскі ўпарта класіфікаваліся як ваўкі. На ўсіх гэтых анамальных фота хаскі былі на снезе. І ўсе ваўкі ў датасэце былі на снезе. Дэталёвы разбор паказаў, што алгартым наўпрост навучыўся адрозніваць белы фон на фота.
Зараз шырокую папулярнасць набываюць разнастайныя мабільныя дадаткі на мяжы “медыцыны і AI”. Адна апка абяцала адрозніваць здаровую і хворую скуру па фота з камеры. Але пры першых real life выпрабаваннях алгарытм праваліўся. Як высветлілася, якасць класіфікатара ў істотнай прапорцыі базавалася на здольнасці вызначыць на фота лінейку. Каб зразумець чаму, можна паглядзець на фота па запыце "identifying red spots".
Яшчэ адна гісторыя – пра амбіцыёзны стартап аўтаматычнай дапамогі ў прыняцці медыцынскіх рашэнняў. У людзей ёсць магчымасць насмяяцца з абсурдных карэляцый. У няшчасных робатаў – не. Таму, апасля серыі плоскіх калькуляцый, алгарытм параіў медыкам перастаць адпраўляць людзей на хіміятэрапію, бо пацыенты апасля яе часцяком паміралі. Усё па першым законе робататэхнікі Азімава.
Мая ўлюбленая гісторыя - пра каманду пачынаючых дата сайнцістаў, якія распрацавалі алгарытм прадказання адтоку кліентаў у наступным месяцы. Алгарытм меў “99% дакладнасці”, а прэзентацыя ўтрымлівала невыносную колькасць словаў Artificial і Intelligence. Старыя каманды CRM і аналітыкаў моцна напружыліся і іх можна зразумець – робаты забіраюць працу, “скураныя мяшкі не патрэбныя”, вось гэта ўсё. Як апынулася, найбольш моцнай фічой для прадказання ў новым алгарытме была “колькасць дзён без аплаты”. Сам факт адтоку кліента па бізнэс-правілах, якія пачынаючых будавацеляў робатаў цікавілі мала, вызначаўся як “90 дзён без аплаты”. Тобок, 90 дзён без аплаты ідэальна прадказвала 90 дзён без аплаты. Як і менш 59 дзён без аплаты ідэальна прадказвала адсутнасць адтоку, бо алгарытм прадказваў на месяц наперад. Ваісціну, неабмежаваныя магчымасці.
Выпадковы выдаліў, перазаліваю
#statistics #machinelearning
Правалы - гэта неад'емная, мабыць ключавая частка развіцця навукі, ды і ўвогуле развіцця. Вакол гэтай ідэі існуе шмат добрых канцэптаў, напрыклад - failure CV. Але я хачу распавесці не проста пра няўдачы, а пра канкрэтны трэш ва ўжыванні статыстыкі і пабудове статыстычных мадэляў: у акадэміі, а таксама ў індустрыі.
З акадэміяй у гэтым плане вельмі проста, бо ўсё задакументавана. З індустрыяй нашмат больш складана, бо бізнэс-спецыфіка, NDA, а таксама жаданне абмежаваць рэпутацыйныя выдаткі. Таму пачнем з індустрыі. Частка гэтых гісторый - хутчэй за ўсё байкі. Частка - абсалютна рэальныя і я нават ведаю ўдзельнікаў. Істотна, аднак, што кожная з іх магла здарыцца з аднолькавай верагоднасцю і магчыма здаралася неаднойчы.
З улікам таго, што пра “AI failures” пішуць шмат, а ад гісторый кшталту “напужаны Цукенберг закрыў АІ праэкт, таму што нейронкі стварылі сваю сакрэтную мову” у мяне пачынае балець галава, распавядаць я буду пра банальныя, чалавечыя, прыземленыя індустрыйныя правалы.
Большасць фэйлаў ў машынным навучанні добра апісваецца анекдотам пра “хачу сабе танк на ўсю спіну – гатова – а чаму так хутка? – а хулі там чатыры літары”. Таму першая байка – пра савецкія/расійскія і амерыканскія танкі. Алгарытм павінен быў навучыцца іх адрозніваць. Працаваў добра, але ўпарта класіфікаваў новыя расійскія мадэлі як амерыканскія. Разбор паказаў, што фота савецкіх танкаў былі горшай якасці, што алгарытм паспяхова і вывучыў. Альтэрнатыўная версія гэтай байкі: алгарытм вучылі адрозніваць танкі, замаскіраваныя ў лесе, ад проста фота лясных масіваў, але два тыпы фота былі зробленыя ў розныя дні, таму алгарытм вырашыў, што прасцей замест танкаў адрозніваць воблачнасць.
Наступная байка - пра алгарытм, які павінен адрозніваць хаскі ад ваўкоў. Спрабуючы ўявіць сабе практычны сэнс такога алгарытму, я прыйшоў да высновы, што мець магчымасць адрозніць хаскі ад воўка смартфонам, у лесе, ноччу, калі нешта рыкае ў метры ад цябе ў цемры – гэта сапраўды карысна і шматабяцальна. Гісторыя ў тым, што алгарытм паказаў сябе вельмі добра, апроч рэдкіх кейсаў, дзе расава чыстыя хаскі ўпарта класіфікаваліся як ваўкі. На ўсіх гэтых анамальных фота хаскі былі на снезе. І ўсе ваўкі ў датасэце былі на снезе. Дэталёвы разбор паказаў, што алгартым наўпрост навучыўся адрозніваць белы фон на фота.
Зараз шырокую папулярнасць набываюць разнастайныя мабільныя дадаткі на мяжы “медыцыны і AI”. Адна апка абяцала адрозніваць здаровую і хворую скуру па фота з камеры. Але пры першых real life выпрабаваннях алгарытм праваліўся. Як высветлілася, якасць класіфікатара ў істотнай прапорцыі базавалася на здольнасці вызначыць на фота лінейку. Каб зразумець чаму, можна паглядзець на фота па запыце "identifying red spots".
Яшчэ адна гісторыя – пра амбіцыёзны стартап аўтаматычнай дапамогі ў прыняцці медыцынскіх рашэнняў. У людзей ёсць магчымасць насмяяцца з абсурдных карэляцый. У няшчасных робатаў – не. Таму, апасля серыі плоскіх калькуляцый, алгарытм параіў медыкам перастаць адпраўляць людзей на хіміятэрапію, бо пацыенты апасля яе часцяком паміралі. Усё па першым законе робататэхнікі Азімава.
Мая ўлюбленая гісторыя - пра каманду пачынаючых дата сайнцістаў, якія распрацавалі алгарытм прадказання адтоку кліентаў у наступным месяцы. Алгарытм меў “99% дакладнасці”, а прэзентацыя ўтрымлівала невыносную колькасць словаў Artificial і Intelligence. Старыя каманды CRM і аналітыкаў моцна напружыліся і іх можна зразумець – робаты забіраюць працу, “скураныя мяшкі не патрэбныя”, вось гэта ўсё. Як апынулася, найбольш моцнай фічой для прадказання ў новым алгарытме была “колькасць дзён без аплаты”. Сам факт адтоку кліента па бізнэс-правілах, якія пачынаючых будавацеляў робатаў цікавілі мала, вызначаўся як “90 дзён без аплаты”. Тобок, 90 дзён без аплаты ідэальна прадказвала 90 дзён без аплаты. Як і менш 59 дзён без аплаты ідэальна прадказвала адсутнасць адтоку, бо алгарытм прадказваў на месяц наперад. Ваісціну, неабмежаваныя магчымасці.
Пра правалы, статыстыку, машнные навучанне, індустрыю і акадэмію. Частка 2
Першая частка - https://t.me/linearaggression/9
#statistics #science
Абяцаў працягнуць першую частку, але не пра індустрыю, а акадэмію. Пачнем з даследвання пра power poses. Сутнасць ідэі ў тым, што прыняццё т.з. power poses - рукі ў бокі, шырока пастаўленыя ногі, картаны на дзевяноста градусаў - змяняе гарманальны фон і робіць людзей больш упэўненымі.
Даследванне настолькі папулярнае, што пад адпаведным TED talk на ютубе 16 міліёнаў праглядаў, а брытанскія Торы адаптавалі гэтую стратэгію для сваіх публічных выступаў. Апошняе, дарэчы, выглядае абсалютна прэкрасна. Таксама, у галоўнай аўтаркі, Amy Cuddy, атрымалася напісаць на падставе даследвання папулярную кнігу, амазонаўскі рэйтынг якой на дадзены момант складае 4.4 з 5, а кніга мае 527 водгукаў.
Праблема ў тым, што эксперымент праводзіўся на 42 чалавеках. Не на 4200 і нават не на 420 - на 42 чалавеках. Калі гэта выглядае абсурдным, я спяшаюся вас папярэдзіць - значная частка даследванняў па псіхалогіі мае нават меншыя выбаркі.
Не дзіва, што калі іншая каманда паспрабавала паўтарыць даследванне, але на большай выбарцы, у іх нічога не атрымалася. Падрабязны статыстычна агляд арыгінальнага даследвання і рэплікацыі можна прачытаць тут.
Нашмат далей пайшоў дактарант паліталогіі з UCLA, Michael LaCour. Ён апублікаваў даследванне, як кароткая размова з геямі перманента змяншае гамафобію. Паспяхова атрымаў сваё PhD, здолеў апублікаваць даследванне ў Science і нават атрымаў пазіцыю ў Прынстане.
Іншым дактарантам было зайздрасна і яны вырашылі паўтарыць поспех. Шэраг далейшых разбораў паказаў, што даследванне не проста памылковае - яго не было. Тобок, LaCour прыдумаў грант, прыдумаў даследванне, прыдумаў людзей, якія яго праводзілі, стварыў фэйкавыя дадзеныя, гадамі пра гэта хлусіў і здолеў апублікавацца ў Science - топавым навуковым часопісе.
Як потым апынулася, большую частку свайго CV ён таксама выдумаў - гранты, даследванні, выдуманыя ўзнагароды і перамогі ў конкурсах. Наколькі я памятаю, народ дакапаўся да фальсіфікацый нават у ягонай бакалаўрскай. Ці дайшоў крыжовы паход да фактаў фальсіфікацыі аплікацыі ў дзіцячы садок мне не вядома.
Апасля гэтага LaСour знік, але ўсплыў праз год як “data scientist / visualization specialist" са сваім сайтам і брэндам. Увы, мае букмаркі на ягоныя працы даўно бітыя, але я памятаю, што візуалізацыі там былі проста топавыя. З іншага боку, правярнуць такую аферу неверагодна складана, а значыць чалавек далёка не бесталентны. Не здзіўлюся, калі ён скончыць якім-небудзь лабістам у Вашынгтоне - моцны талент і нямоцныя маральныя абмежаванні з’яўляюцца каштоўным рэсурам.
Але прыкладам сапраўднага правалу я лічу вядомы сярод эканамістаў log(NAICS) артыкул. Аўтар будаваў фінансавую мадэль і ўключыў лагарыфм ад NAICS у якасці адной са сваім пераменных. Справа ў тым, што NAICS, альбо North American Industry Classification System, з’ўляецца намінальным індэксам, у якога няма ніякай кардынальнасці і адносінаў парадку. Тобок, індэкс 111211 (вырошчванне бульбы) не з’яўляецца на 100095 пунктаў большым за індэкс 11116 (вырошчванне рысу). У гэтых “пунктаў” увогуле няма фізічнага сэнсу.
Больш за ўсё дастаўляе, што аўтар ўзяў ад яго лагарыфм, што з’яўляецца стандартнай працэдурай падгону размеркаванняў у лінейных мадэлях. Тобок, чалавек над ім разважаў.
Магчыма, мала хто б звярнуў на гэтую паперу ўвагу, калі б не той факт, што за яе аўтар атрымаў Edwin Elton Prize for Bes Job-Market Paper in Finance, а таксама падтрымку свайго навуковага кіраўніка, па сумяшчальніцтве - Нобелеўскага лаўрэата. Зараз аўтар - Assistant Professor у Гарвардзе. Such academia much meritocracy wow.
Першая частка - https://t.me/linearaggression/9
#statistics #science
Абяцаў працягнуць першую частку, але не пра індустрыю, а акадэмію. Пачнем з даследвання пра power poses. Сутнасць ідэі ў тым, што прыняццё т.з. power poses - рукі ў бокі, шырока пастаўленыя ногі, картаны на дзевяноста градусаў - змяняе гарманальны фон і робіць людзей больш упэўненымі.
Даследванне настолькі папулярнае, што пад адпаведным TED talk на ютубе 16 міліёнаў праглядаў, а брытанскія Торы адаптавалі гэтую стратэгію для сваіх публічных выступаў. Апошняе, дарэчы, выглядае абсалютна прэкрасна. Таксама, у галоўнай аўтаркі, Amy Cuddy, атрымалася напісаць на падставе даследвання папулярную кнігу, амазонаўскі рэйтынг якой на дадзены момант складае 4.4 з 5, а кніга мае 527 водгукаў.
Праблема ў тым, што эксперымент праводзіўся на 42 чалавеках. Не на 4200 і нават не на 420 - на 42 чалавеках. Калі гэта выглядае абсурдным, я спяшаюся вас папярэдзіць - значная частка даследванняў па псіхалогіі мае нават меншыя выбаркі.
Не дзіва, што калі іншая каманда паспрабавала паўтарыць даследванне, але на большай выбарцы, у іх нічога не атрымалася. Падрабязны статыстычна агляд арыгінальнага даследвання і рэплікацыі можна прачытаць тут.
Нашмат далей пайшоў дактарант паліталогіі з UCLA, Michael LaCour. Ён апублікаваў даследванне, як кароткая размова з геямі перманента змяншае гамафобію. Паспяхова атрымаў сваё PhD, здолеў апублікаваць даследванне ў Science і нават атрымаў пазіцыю ў Прынстане.
Іншым дактарантам было зайздрасна і яны вырашылі паўтарыць поспех. Шэраг далейшых разбораў паказаў, што даследванне не проста памылковае - яго не было. Тобок, LaCour прыдумаў грант, прыдумаў даследванне, прыдумаў людзей, якія яго праводзілі, стварыў фэйкавыя дадзеныя, гадамі пра гэта хлусіў і здолеў апублікавацца ў Science - топавым навуковым часопісе.
Як потым апынулася, большую частку свайго CV ён таксама выдумаў - гранты, даследванні, выдуманыя ўзнагароды і перамогі ў конкурсах. Наколькі я памятаю, народ дакапаўся да фальсіфікацый нават у ягонай бакалаўрскай. Ці дайшоў крыжовы паход да фактаў фальсіфікацыі аплікацыі ў дзіцячы садок мне не вядома.
Апасля гэтага LaСour знік, але ўсплыў праз год як “data scientist / visualization specialist" са сваім сайтам і брэндам. Увы, мае букмаркі на ягоныя працы даўно бітыя, але я памятаю, што візуалізацыі там былі проста топавыя. З іншага боку, правярнуць такую аферу неверагодна складана, а значыць чалавек далёка не бесталентны. Не здзіўлюся, калі ён скончыць якім-небудзь лабістам у Вашынгтоне - моцны талент і нямоцныя маральныя абмежаванні з’яўляюцца каштоўным рэсурам.
Але прыкладам сапраўднага правалу я лічу вядомы сярод эканамістаў log(NAICS) артыкул. Аўтар будаваў фінансавую мадэль і ўключыў лагарыфм ад NAICS у якасці адной са сваім пераменных. Справа ў тым, што NAICS, альбо North American Industry Classification System, з’ўляецца намінальным індэксам, у якога няма ніякай кардынальнасці і адносінаў парадку. Тобок, індэкс 111211 (вырошчванне бульбы) не з’яўляецца на 100095 пунктаў большым за індэкс 11116 (вырошчванне рысу). У гэтых “пунктаў” увогуле няма фізічнага сэнсу.
Больш за ўсё дастаўляе, што аўтар ўзяў ад яго лагарыфм, што з’яўляецца стандартнай працэдурай падгону размеркаванняў у лінейных мадэлях. Тобок, чалавек над ім разважаў.
Магчыма, мала хто б звярнуў на гэтую паперу ўвагу, калі б не той факт, што за яе аўтар атрымаў Edwin Elton Prize for Bes Job-Market Paper in Finance, а таксама падтрымку свайго навуковага кіраўніка, па сумяшчальніцтве - Нобелеўскага лаўрэата. Зараз аўтар - Assistant Professor у Гарвардзе. Such academia much meritocracy wow.
Telegram
Лінейная (аг | рэг) рэсія
Пра правалы, статыстыку, машнные навучанне, індустрыю і акадэмію. Частка 1
Выпадковы выдаліў, перазаліваю
#statistics #machinelearning
Правалы - гэта неад'емная, мабыць ключавая частка развіцця навукі, ды і ўвогуле развіцця. Вакол гэтай ідэі існуе шмат…
Выпадковы выдаліў, перазаліваю
#statistics #machinelearning
Правалы - гэта неад'емная, мабыць ключавая частка развіцця навукі, ды і ўвогуле развіцця. Вакол гэтай ідэі існуе шмат…
#machinelearning #visualization
Падзялюся з вамі візуалізацыяй таго, як працуе машыннае навучанне ака Machine Learning. Перыядычна ёй з усімі дзялюся, бо надта добра зроблена і зроблена для людзей, а не тэхнічных спецыялістаў. Па-беларуску, увы, няма, але ёсць на іншых мовах.
http://www.r2d3.us/visual-intro-to-machine-learning-part-1/
Падзялюся з вамі візуалізацыяй таго, як працуе машыннае навучанне ака Machine Learning. Перыядычна ёй з усімі дзялюся, бо надта добра зроблена і зроблена для людзей, а не тэхнічных спецыялістаў. Па-беларуску, увы, няма, але ёсць на іншых мовах.
http://www.r2d3.us/visual-intro-to-machine-learning-part-1/
www.r2d3.us
A visual introduction to machine learning
What is machine learning? See how it works with our animated data visualization.