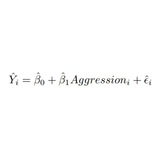
Доказная медыцына ці як навучыцца правяраць выпісаныя лекі, ч. 1
#science #health #everyday
У руках медыкаў я адчуваю сябе даволі бездапаможна: асіметрыя паміж жаданнем быць здаровым і здольнасцю кантраляваць сітуацыю стварае добрую глебу для трывожнасці. Мне проста гэта не падабаецца. Як не падабаецца лятаць (я ведаю, што яно працуе, але не ведаю як) ці чытаць “палітычных экспертаў” (я ведаю, што гэта істотна і ведаю, што яно не працуе).
Таксама я ведаю, што такія асіметрыі непазбежныя. Істотнасць сферы патрабуе глыбокай спецыялізацыі, ствараючы разрыў у ведах паміж спецыялістам і мной, вымушае мяне рабіць некамфортны выбар - чапляцца за рэшткі кантролю ці даверыць сябе інстытуту медыцыны.
Але медыцына бывае розная. Як і любы інстытут, яна можа мець лакальную спецыфіку і абсалютна дакладна мае чалавечую: у сацыя-эканамічна-навуковых цэнтрах лечаць лепш, чым на перэферыях, а людзьмі пануе сквапнасць.
У 2005 годзе John P. A. Ioannidis апублікаваў артыкул пад назвай Why Most Published Research Findings Are False. Аргумент аўтара заключны ў тым, што фінансавыя, кар’ерныя і іншыя інтарэсы не павінны перасякацца з акадэмічнымі. Але яны перасякаюцца і ў вялікай ступені. Часта фінансаванне і кар’ерны рост навукоўцаў залежыць ад колькасці публікацый. Таксама часта навуковыя часопісы аддаюць перавагу даследванням, у якіх сцвярджаецца даказанасць модных, нечаканых, захапляючых ці хайповых гіпотэз. Гэта вымушае навукоўцаў імкнуцца да eye-catching findings, што з’яўляецца эквівалентам навуковага выкавырвання разынак з булкі. Жаданне фармакалагічных кампаній, каб іх лекі выглядалі лепш, увогуле не патрабуе асаблівага абмеркавання.
Наколькі моцна гэтыя развагі стасуюцца з рэальнасцю можна зразумець на наступным прыкладзе. 41% з найлепшых (прэстыжныя часопісы, шырока цытаваныя) медыцынскіх даследванняў за апошнія 13 год былі “з дастатковасцю” абвергнутыя, калі каманда аўтара паспрабавала іх рэплікаваць. Сярод даследванняў: “вітамін Е зніжае рызыку сардэчных захворванняў”, “штодзённы прыём аспірыну зніжае рызыку сардэчнага прыступу і інстульту” і г.д.
Дадзены феномен цяпер вядомы пад назвай p-hacking ці, больш агульна, replication crisis і пра гэта не размаўляе толькі лянівы. Вячэрняе шоў Last Week Tonight нават прысвяціла гэтаму спецыяльны эпізод. Калі нешта з’яўляецца настолькі папулярным топікам у навуковых колах, што трапляе ў вячэрнія шоў - самы час звярнуць на гэта ўвагу.
Іронія сітуацыі заключана ў тым, што людзі, блізкія да навукі, не проста даўно пра гэта ведаюць, а здольныя даволі лёгка адгадваць, рэплікуецца тое ці іншае даследванне прачытаўшы толькі агульнае апісанне. У мяне, напрыклад, атрымалася набіць 24 з 30 у гэтым квізе. Ён тычыцца псіхалогіі, але няма падставаў лічыць, што ў іншых дысцыплінах сітуацыя не будзе аналагічнай.
Цяпер пра беларускую спецыфіку. Мне падаецца рацыянальным праводзіць мост паміж replication crisis і выпісанымі лекамі наступным чынам. Па-першае, калі ёсць у свеце, тады ёсць і ў Беларусі. Па-другое, няма падставы лічыць, што лічбы для Беларусі будуць лепш. Па-трэцяе, паміж тэрапеўтамі ў паліклініцы і рынкам навуковых публікацый таксама існуе пэўны разрыў ведаў (маё падазрэнне ў тым, што заўважны). Па-чацвёртае, я паняцця не маю, як у Беларусі працуе фармакалагічны рынак.
Усё гэта вымусіла мяне выпрацаваць шэраг правіл, з дапамогай якіх я арыентуюся ў незнаёмай і істотнай сферы беларускай медыцыны: якасць існуючай доказнай базы, моцнасць патэнцыйнага дызайну, праўдападобнасць эфекту, час і рэсурсы.
#science #health #everyday
У руках медыкаў я адчуваю сябе даволі бездапаможна: асіметрыя паміж жаданнем быць здаровым і здольнасцю кантраляваць сітуацыю стварае добрую глебу для трывожнасці. Мне проста гэта не падабаецца. Як не падабаецца лятаць (я ведаю, што яно працуе, але не ведаю як) ці чытаць “палітычных экспертаў” (я ведаю, што гэта істотна і ведаю, што яно не працуе).
Таксама я ведаю, што такія асіметрыі непазбежныя. Істотнасць сферы патрабуе глыбокай спецыялізацыі, ствараючы разрыў у ведах паміж спецыялістам і мной, вымушае мяне рабіць некамфортны выбар - чапляцца за рэшткі кантролю ці даверыць сябе інстытуту медыцыны.
Але медыцына бывае розная. Як і любы інстытут, яна можа мець лакальную спецыфіку і абсалютна дакладна мае чалавечую: у сацыя-эканамічна-навуковых цэнтрах лечаць лепш, чым на перэферыях, а людзьмі пануе сквапнасць.
У 2005 годзе John P. A. Ioannidis апублікаваў артыкул пад назвай Why Most Published Research Findings Are False. Аргумент аўтара заключны ў тым, што фінансавыя, кар’ерныя і іншыя інтарэсы не павінны перасякацца з акадэмічнымі. Але яны перасякаюцца і ў вялікай ступені. Часта фінансаванне і кар’ерны рост навукоўцаў залежыць ад колькасці публікацый. Таксама часта навуковыя часопісы аддаюць перавагу даследванням, у якіх сцвярджаецца даказанасць модных, нечаканых, захапляючых ці хайповых гіпотэз. Гэта вымушае навукоўцаў імкнуцца да eye-catching findings, што з’яўляецца эквівалентам навуковага выкавырвання разынак з булкі. Жаданне фармакалагічных кампаній, каб іх лекі выглядалі лепш, увогуле не патрабуе асаблівага абмеркавання.
Наколькі моцна гэтыя развагі стасуюцца з рэальнасцю можна зразумець на наступным прыкладзе. 41% з найлепшых (прэстыжныя часопісы, шырока цытаваныя) медыцынскіх даследванняў за апошнія 13 год былі “з дастатковасцю” абвергнутыя, калі каманда аўтара паспрабавала іх рэплікаваць. Сярод даследванняў: “вітамін Е зніжае рызыку сардэчных захворванняў”, “штодзённы прыём аспірыну зніжае рызыку сардэчнага прыступу і інстульту” і г.д.
Дадзены феномен цяпер вядомы пад назвай p-hacking ці, больш агульна, replication crisis і пра гэта не размаўляе толькі лянівы. Вячэрняе шоў Last Week Tonight нават прысвяціла гэтаму спецыяльны эпізод. Калі нешта з’яўляецца настолькі папулярным топікам у навуковых колах, што трапляе ў вячэрнія шоў - самы час звярнуць на гэта ўвагу.
Іронія сітуацыі заключана ў тым, што людзі, блізкія да навукі, не проста даўно пра гэта ведаюць, а здольныя даволі лёгка адгадваць, рэплікуецца тое ці іншае даследванне прачытаўшы толькі агульнае апісанне. У мяне, напрыклад, атрымалася набіць 24 з 30 у гэтым квізе. Ён тычыцца псіхалогіі, але няма падставаў лічыць, што ў іншых дысцыплінах сітуацыя не будзе аналагічнай.
Цяпер пра беларускую спецыфіку. Мне падаецца рацыянальным праводзіць мост паміж replication crisis і выпісанымі лекамі наступным чынам. Па-першае, калі ёсць у свеце, тады ёсць і ў Беларусі. Па-другое, няма падставы лічыць, што лічбы для Беларусі будуць лепш. Па-трэцяе, паміж тэрапеўтамі ў паліклініцы і рынкам навуковых публікацый таксама існуе пэўны разрыў ведаў (маё падазрэнне ў тым, што заўважны). Па-чацвёртае, я паняцця не маю, як у Беларусі працуе фармакалагічны рынак.
Усё гэта вымусіла мяне выпрацаваць шэраг правіл, з дапамогай якіх я арыентуюся ў незнаёмай і істотнай сферы беларускай медыцыны: якасць існуючай доказнай базы, моцнасць патэнцыйнага дызайну, праўдападобнасць эфекту, час і рэсурсы.
journals.plos.org
Why Most Published Research Findings Are False
Published research findings are sometimes refuted by subsequent evidence, says Ioannidis, with ensuing confusion and disappointment.
Доказная медыцына ці як навучыцца правяраць выпісаныя лекі, ч. 2
Першая частка - https://t.me/linearaggression/3
#science #health #everyday
Якасць існуючай доказнай базы: я карыстаюся Сochrane library і PubMed, якія служаць карыснай справе сістэматызацыі доказнай медыцыны. Пры праверцы прэпарата ці актыўнага рэчыва трэба звяртаць увагу на колькасць публікацый, іх незалежнасць (розныя людзі/лабараторыі/арганізацыі/краіны), моцнасць дызайну (пра гэта ніжэй) і ацэнку эфектыўнасці (калі ёсць на Cochrane). Шмат публікацый, розныя крыніцы, тысячы чалавек і RCT (randomized control trial) - добры аб’ём доказнай базы. Cochrane не ведае, што гэта, PubMed ведае 1.5 стромныя публікацыі на машыннай ангельскай, гугл з неабходнасцю прыводзіць на рускамоўныя сайты - дрэнны аб’ём доказнай базы.
Моцнасць дызайну даследвання: Пытанне, якое трэба сабе задаваць, гэта можна ці не правесці эксперымент. Калі можна, тады арыентуемся на RCT з вялікай колькасцю пацыентаў. Моцнасць эксперымента ў тым, што ўздеянне напрамую кантралюецца: мы самі дзелім людзей на кантрольную і эксперыментальную групы. Усё максімальна экспліцытна і транспарэнтна. Калі правесці эксперымент нельга, тады надзейней усяго ігнараваць вынікі такіх даследванняў, бо спроба размежаваць прычынна-следчы эфект і карэляцыю без кантролю за ўздзеяннем амаль не мае шанцаў на поспех. Для прыкладу, практычна немагчыма арганізаваць RCT для вывучэння доўгатэрміновых эфектаў дыеты, бо каштоўнасці гуманізм, а таксама крымінальнае заканадаўства забараняе дзяліць людзей на дзве вялікія групы, гвалтоўна карміць адных “фіялетавай садавінай”, у другой прынцыпова яе забараняць. Менавіта таму даследванні ў сферах кшталту дыеталогіі - поўнае, бязбожнае пекла, ступені бессаромнасці ў якой пазайздросцяць некаторыя фармакалагічныя кампаніі. І менавіта таму некаторыя даследчыкі выступаюць за поўнае ігнараванне неэксперыментальных даследванняў.
Праўдападобнасць эфекту: гэта пра тое, наколькі абсурдным з’яўляецца заяўлены ў даследванні эфект, спроба фільтрацыі “выкавырвання разынак з булкі” і неабмежаванага хайпу, пра якія я пісаў вышэй. Якая верагоднасць , што 10 хвілін у суткі праведзеныя з хатняй жывёлай змяншаюць верагоднасць інсульту на 30%? Вельмі нізкая, бо пры такой магнітудзе эфекту (30% - гэта вельмі шмат) ў такой простай і відавочнай працэдуры, пра гэты эфект вы б чыталі не ў навуковым часопісе, а даведаліся б ад вашай бабулі, калі б вам стукнула 27. Інакш кажучы - занадта добра, каб быць праўдай. З іншага богу, арганізаваць даследванне, каб такі эфект “знайсці” даволі проста. Калі загугліць “Bem 2011 Feeling the future”, можна пабачыць, як людзі даказваюць з дапамогай статыстыкі і эксперыментаў тэлепатычныя здольнасці. З коцікамі, відавочна, яшчэ прасцей.
Час і рэсурсы: адна справа, гэта кансультацыя бацькоў апасля чарговага наведвання профільнага спецыялісту на прадмет 10 выпісаных прэпаратаў, але зусім іншая - сур’ёзная, рэзкая хвароба, калі час на штудаванне метадалагічнай літаратуры можа проста адсутнічаць. Тут, як і агулам, кожны вырашае сам для сябе.
—————————————————————————-
Case-study на прыкладзе прэпарату thiotriazolinum:
1) Cochrane пра такую рэч не ведае, на PubMed 2 рускамоўных артыкулы з адным аўтарам і даследванне літоўцаў на машых.
2) Пра моцнасць дызайна ў публікацыях казаць складана, бо публікацый, па-сутнасці, няма.
3) Праўдападобнасць эфекту - з апісання прэпарата выцякае, што ён дапамагае у комплексным лячэнні ішэмічнай хваробы сэрца: інфаркту міякарда, стэнакардыі; сардэчных арытмій; хранічнага гепатыту фіброзу печані, цырозу печані. Тобок, у даволі шырокім, не заўсёды звязаным і вельмі распаўсюджаным спісе праблем.
4) З улікам таго, што прэпарат звычайна выпісваюць як “падтрымліваючы”, разабрацца з ім час ёсць
У выніку, мы маем прэпарат, які ў моц шырыні сферы выкарыстання павінен мець папулярнасць і камерцыйны поспех. Праблема ў тым, што аналагічныя поспехі з пункту гледжання доказнай медыцыны для дадзенага прэпарата адсутнічаюць.
Першая частка - https://t.me/linearaggression/3
#science #health #everyday
Якасць існуючай доказнай базы: я карыстаюся Сochrane library і PubMed, якія служаць карыснай справе сістэматызацыі доказнай медыцыны. Пры праверцы прэпарата ці актыўнага рэчыва трэба звяртаць увагу на колькасць публікацый, іх незалежнасць (розныя людзі/лабараторыі/арганізацыі/краіны), моцнасць дызайну (пра гэта ніжэй) і ацэнку эфектыўнасці (калі ёсць на Cochrane). Шмат публікацый, розныя крыніцы, тысячы чалавек і RCT (randomized control trial) - добры аб’ём доказнай базы. Cochrane не ведае, што гэта, PubMed ведае 1.5 стромныя публікацыі на машыннай ангельскай, гугл з неабходнасцю прыводзіць на рускамоўныя сайты - дрэнны аб’ём доказнай базы.
Моцнасць дызайну даследвання: Пытанне, якое трэба сабе задаваць, гэта можна ці не правесці эксперымент. Калі можна, тады арыентуемся на RCT з вялікай колькасцю пацыентаў. Моцнасць эксперымента ў тым, што ўздеянне напрамую кантралюецца: мы самі дзелім людзей на кантрольную і эксперыментальную групы. Усё максімальна экспліцытна і транспарэнтна. Калі правесці эксперымент нельга, тады надзейней усяго ігнараваць вынікі такіх даследванняў, бо спроба размежаваць прычынна-следчы эфект і карэляцыю без кантролю за ўздзеяннем амаль не мае шанцаў на поспех. Для прыкладу, практычна немагчыма арганізаваць RCT для вывучэння доўгатэрміновых эфектаў дыеты, бо каштоўнасці гуманізм, а таксама крымінальнае заканадаўства забараняе дзяліць людзей на дзве вялікія групы, гвалтоўна карміць адных “фіялетавай садавінай”, у другой прынцыпова яе забараняць. Менавіта таму даследванні ў сферах кшталту дыеталогіі - поўнае, бязбожнае пекла, ступені бессаромнасці ў якой пазайздросцяць некаторыя фармакалагічныя кампаніі. І менавіта таму некаторыя даследчыкі выступаюць за поўнае ігнараванне неэксперыментальных даследванняў.
Праўдападобнасць эфекту: гэта пра тое, наколькі абсурдным з’яўляецца заяўлены ў даследванні эфект, спроба фільтрацыі “выкавырвання разынак з булкі” і неабмежаванага хайпу, пра якія я пісаў вышэй. Якая верагоднасць , што 10 хвілін у суткі праведзеныя з хатняй жывёлай змяншаюць верагоднасць інсульту на 30%? Вельмі нізкая, бо пры такой магнітудзе эфекту (30% - гэта вельмі шмат) ў такой простай і відавочнай працэдуры, пра гэты эфект вы б чыталі не ў навуковым часопісе, а даведаліся б ад вашай бабулі, калі б вам стукнула 27. Інакш кажучы - занадта добра, каб быць праўдай. З іншага богу, арганізаваць даследванне, каб такі эфект “знайсці” даволі проста. Калі загугліць “Bem 2011 Feeling the future”, можна пабачыць, як людзі даказваюць з дапамогай статыстыкі і эксперыментаў тэлепатычныя здольнасці. З коцікамі, відавочна, яшчэ прасцей.
Час і рэсурсы: адна справа, гэта кансультацыя бацькоў апасля чарговага наведвання профільнага спецыялісту на прадмет 10 выпісаных прэпаратаў, але зусім іншая - сур’ёзная, рэзкая хвароба, калі час на штудаванне метадалагічнай літаратуры можа проста адсутнічаць. Тут, як і агулам, кожны вырашае сам для сябе.
—————————————————————————-
Case-study на прыкладзе прэпарату thiotriazolinum:
1) Cochrane пра такую рэч не ведае, на PubMed 2 рускамоўных артыкулы з адным аўтарам і даследванне літоўцаў на машых.
2) Пра моцнасць дызайна ў публікацыях казаць складана, бо публікацый, па-сутнасці, няма.
3) Праўдападобнасць эфекту - з апісання прэпарата выцякае, што ён дапамагае у комплексным лячэнні ішэмічнай хваробы сэрца: інфаркту міякарда, стэнакардыі; сардэчных арытмій; хранічнага гепатыту фіброзу печані, цырозу печані. Тобок, у даволі шырокім, не заўсёды звязаным і вельмі распаўсюджаным спісе праблем.
4) З улікам таго, што прэпарат звычайна выпісваюць як “падтрымліваючы”, разабрацца з ім час ёсць
У выніку, мы маем прэпарат, які ў моц шырыні сферы выкарыстання павінен мець папулярнасць і камерцыйны поспех. Праблема ў тым, што аналагічныя поспехі з пункту гледжання доказнай медыцыны для дадзенага прэпарата адсутнічаюць.
Telegram
Лінейная (аг | рэг) рэсія
Доказная медыцына ці як навучыцца правяраць выпісаныя лекі, ч. 1
#science #health #everyday
У руках медыкаў я адчуваю сябе даволі бездапаможна: асіметрыя паміж жаданнем быць здаровым і здольнасцю кантраляваць сітуацыю стварае добрую глебу для трывожнасці.…
#science #health #everyday
У руках медыкаў я адчуваю сябе даволі бездапаможна: асіметрыя паміж жаданнем быць здаровым і здольнасцю кантраляваць сітуацыю стварае добрую глебу для трывожнасці.…
Пра правалы, статыстыку, машнные навучанне, індустрыю і акадэмію. Частка 2
Першая частка - https://t.me/linearaggression/9
#statistics #science
Абяцаў працягнуць першую частку, але не пра індустрыю, а акадэмію. Пачнем з даследвання пра power poses. Сутнасць ідэі ў тым, што прыняццё т.з. power poses - рукі ў бокі, шырока пастаўленыя ногі, картаны на дзевяноста градусаў - змяняе гарманальны фон і робіць людзей больш упэўненымі.
Даследванне настолькі папулярнае, што пад адпаведным TED talk на ютубе 16 міліёнаў праглядаў, а брытанскія Торы адаптавалі гэтую стратэгію для сваіх публічных выступаў. Апошняе, дарэчы, выглядае абсалютна прэкрасна. Таксама, у галоўнай аўтаркі, Amy Cuddy, атрымалася напісаць на падставе даследвання папулярную кнігу, амазонаўскі рэйтынг якой на дадзены момант складае 4.4 з 5, а кніга мае 527 водгукаў.
Праблема ў тым, што эксперымент праводзіўся на 42 чалавеках. Не на 4200 і нават не на 420 - на 42 чалавеках. Калі гэта выглядае абсурдным, я спяшаюся вас папярэдзіць - значная частка даследванняў па псіхалогіі мае нават меншыя выбаркі.
Не дзіва, што калі іншая каманда паспрабавала паўтарыць даследванне, але на большай выбарцы, у іх нічога не атрымалася. Падрабязны статыстычна агляд арыгінальнага даследвання і рэплікацыі можна прачытаць тут.
Нашмат далей пайшоў дактарант паліталогіі з UCLA, Michael LaCour. Ён апублікаваў даследванне, як кароткая размова з геямі перманента змяншае гамафобію. Паспяхова атрымаў сваё PhD, здолеў апублікаваць даследванне ў Science і нават атрымаў пазіцыю ў Прынстане.
Іншым дактарантам было зайздрасна і яны вырашылі паўтарыць поспех. Шэраг далейшых разбораў паказаў, што даследванне не проста памылковае - яго не было. Тобок, LaCour прыдумаў грант, прыдумаў даследванне, прыдумаў людзей, якія яго праводзілі, стварыў фэйкавыя дадзеныя, гадамі пра гэта хлусіў і здолеў апублікавацца ў Science - топавым навуковым часопісе.
Як потым апынулася, большую частку свайго CV ён таксама выдумаў - гранты, даследванні, выдуманыя ўзнагароды і перамогі ў конкурсах. Наколькі я памятаю, народ дакапаўся да фальсіфікацый нават у ягонай бакалаўрскай. Ці дайшоў крыжовы паход да фактаў фальсіфікацыі аплікацыі ў дзіцячы садок мне не вядома.
Апасля гэтага LaСour знік, але ўсплыў праз год як “data scientist / visualization specialist" са сваім сайтам і брэндам. Увы, мае букмаркі на ягоныя працы даўно бітыя, але я памятаю, што візуалізацыі там былі проста топавыя. З іншага боку, правярнуць такую аферу неверагодна складана, а значыць чалавек далёка не бесталентны. Не здзіўлюся, калі ён скончыць якім-небудзь лабістам у Вашынгтоне - моцны талент і нямоцныя маральныя абмежаванні з’яўляюцца каштоўным рэсурам.
Але прыкладам сапраўднага правалу я лічу вядомы сярод эканамістаў log(NAICS) артыкул. Аўтар будаваў фінансавую мадэль і ўключыў лагарыфм ад NAICS у якасці адной са сваім пераменных. Справа ў тым, што NAICS, альбо North American Industry Classification System, з’ўляецца намінальным індэксам, у якога няма ніякай кардынальнасці і адносінаў парадку. Тобок, індэкс 111211 (вырошчванне бульбы) не з’яўляецца на 100095 пунктаў большым за індэкс 11116 (вырошчванне рысу). У гэтых “пунктаў” увогуле няма фізічнага сэнсу.
Больш за ўсё дастаўляе, што аўтар ўзяў ад яго лагарыфм, што з’яўляецца стандартнай працэдурай падгону размеркаванняў у лінейных мадэлях. Тобок, чалавек над ім разважаў.
Магчыма, мала хто б звярнуў на гэтую паперу ўвагу, калі б не той факт, што за яе аўтар атрымаў Edwin Elton Prize for Bes Job-Market Paper in Finance, а таксама падтрымку свайго навуковага кіраўніка, па сумяшчальніцтве - Нобелеўскага лаўрэата. Зараз аўтар - Assistant Professor у Гарвардзе. Such academia much meritocracy wow.
Першая частка - https://t.me/linearaggression/9
#statistics #science
Абяцаў працягнуць першую частку, але не пра індустрыю, а акадэмію. Пачнем з даследвання пра power poses. Сутнасць ідэі ў тым, што прыняццё т.з. power poses - рукі ў бокі, шырока пастаўленыя ногі, картаны на дзевяноста градусаў - змяняе гарманальны фон і робіць людзей больш упэўненымі.
Даследванне настолькі папулярнае, што пад адпаведным TED talk на ютубе 16 міліёнаў праглядаў, а брытанскія Торы адаптавалі гэтую стратэгію для сваіх публічных выступаў. Апошняе, дарэчы, выглядае абсалютна прэкрасна. Таксама, у галоўнай аўтаркі, Amy Cuddy, атрымалася напісаць на падставе даследвання папулярную кнігу, амазонаўскі рэйтынг якой на дадзены момант складае 4.4 з 5, а кніга мае 527 водгукаў.
Праблема ў тым, што эксперымент праводзіўся на 42 чалавеках. Не на 4200 і нават не на 420 - на 42 чалавеках. Калі гэта выглядае абсурдным, я спяшаюся вас папярэдзіць - значная частка даследванняў па псіхалогіі мае нават меншыя выбаркі.
Не дзіва, што калі іншая каманда паспрабавала паўтарыць даследванне, але на большай выбарцы, у іх нічога не атрымалася. Падрабязны статыстычна агляд арыгінальнага даследвання і рэплікацыі можна прачытаць тут.
Нашмат далей пайшоў дактарант паліталогіі з UCLA, Michael LaCour. Ён апублікаваў даследванне, як кароткая размова з геямі перманента змяншае гамафобію. Паспяхова атрымаў сваё PhD, здолеў апублікаваць даследванне ў Science і нават атрымаў пазіцыю ў Прынстане.
Іншым дактарантам было зайздрасна і яны вырашылі паўтарыць поспех. Шэраг далейшых разбораў паказаў, што даследванне не проста памылковае - яго не было. Тобок, LaCour прыдумаў грант, прыдумаў даследванне, прыдумаў людзей, якія яго праводзілі, стварыў фэйкавыя дадзеныя, гадамі пра гэта хлусіў і здолеў апублікавацца ў Science - топавым навуковым часопісе.
Як потым апынулася, большую частку свайго CV ён таксама выдумаў - гранты, даследванні, выдуманыя ўзнагароды і перамогі ў конкурсах. Наколькі я памятаю, народ дакапаўся да фальсіфікацый нават у ягонай бакалаўрскай. Ці дайшоў крыжовы паход да фактаў фальсіфікацыі аплікацыі ў дзіцячы садок мне не вядома.
Апасля гэтага LaСour знік, але ўсплыў праз год як “data scientist / visualization specialist" са сваім сайтам і брэндам. Увы, мае букмаркі на ягоныя працы даўно бітыя, але я памятаю, што візуалізацыі там былі проста топавыя. З іншага боку, правярнуць такую аферу неверагодна складана, а значыць чалавек далёка не бесталентны. Не здзіўлюся, калі ён скончыць якім-небудзь лабістам у Вашынгтоне - моцны талент і нямоцныя маральныя абмежаванні з’яўляюцца каштоўным рэсурам.
Але прыкладам сапраўднага правалу я лічу вядомы сярод эканамістаў log(NAICS) артыкул. Аўтар будаваў фінансавую мадэль і ўключыў лагарыфм ад NAICS у якасці адной са сваім пераменных. Справа ў тым, што NAICS, альбо North American Industry Classification System, з’ўляецца намінальным індэксам, у якога няма ніякай кардынальнасці і адносінаў парадку. Тобок, індэкс 111211 (вырошчванне бульбы) не з’яўляецца на 100095 пунктаў большым за індэкс 11116 (вырошчванне рысу). У гэтых “пунктаў” увогуле няма фізічнага сэнсу.
Больш за ўсё дастаўляе, што аўтар ўзяў ад яго лагарыфм, што з’яўляецца стандартнай працэдурай падгону размеркаванняў у лінейных мадэлях. Тобок, чалавек над ім разважаў.
Магчыма, мала хто б звярнуў на гэтую паперу ўвагу, калі б не той факт, што за яе аўтар атрымаў Edwin Elton Prize for Bes Job-Market Paper in Finance, а таксама падтрымку свайго навуковага кіраўніка, па сумяшчальніцтве - Нобелеўскага лаўрэата. Зараз аўтар - Assistant Professor у Гарвардзе. Such academia much meritocracy wow.
Telegram
Лінейная (аг | рэг) рэсія
Пра правалы, статыстыку, машнные навучанне, індустрыю і акадэмію. Частка 1
Выпадковы выдаліў, перазаліваю
#statistics #machinelearning
Правалы - гэта неад'емная, мабыць ключавая частка развіцця навукі, ды і ўвогуле развіцця. Вакол гэтай ідэі існуе шмат…
Выпадковы выдаліў, перазаліваю
#statistics #machinelearning
Правалы - гэта неад'емная, мабыць ключавая частка развіцця навукі, ды і ўвогуле развіцця. Вакол гэтай ідэі існуе шмат…
Dan Aierly, ягоны сабака і фальсіфікацыя дадзеных
#science
На гэтым тыдні распавяду вам пра тое, як навукоўцы фальсіфікуюць дадзеныя.
Ёсць такі эканаміст і псіхолаг Dan Aierly. Дэн - навуковец папулярны, ягоныя TED размовы глядзяць мільёны людзей, размовы ў гугле - сотні тысяч. Там ён распавядае пра кагнітыўныя скажэнні, ірацыянальнасць, чаму людзі хлусяць, дурнаватых мэйнстрымавых эканамістаў, пра іншыя модныя рэчы. Ягоныя працы працытаваныя 58 тысяч разоў.
Выглядае, што Дэн таксама выдумляе свае дадзеныя.
Зразумелі гэта на прыкладзе ягонага даследавання пра хлусню з прабегам аўтамабіляў. Пры розных справах са страхоўкамі ў вас могуць спытаць пра прабег. Людзі схільныя прабег заніжаць - каб павысіць шанцы на атрыманне выплат, напрыклад. Таму часам у канцы дамовы вас просяць падпісаць нешта кшталту “дадзеныя, якія я прадставіў, праўдзівыя”. Дэн прыдумаў гіпотэзу, што калі прасіць людзей падпісаць гэта перад тым, як запытваць пра прабег, а не ў самым канцы, людзі перастаюць хлусіць. І даказаў! - прабег у сярэднім пачаў вырастаць на 10.3% альбо на 3.862 кіламетры.
Цяпер, пра вясёлае.
1. Па-першае, у эксэль файле роўна 50% дадзеных у шрыфце Calibri, а іншыя 50% - у Cambria. Пры гэтым, на любога кліента страхавой у Calibri, можна знайсці амаль такога ж кліента ў шрыфце Cambria. Тобок увесь эксэль файл складаецца з кіроўцаў-двайнікоў - проста ў розных шрыфтах
2. Любы кіроўца ў шрыфце Cambria адрозніваецца ад свайго двайніка з Calibri на выпадковую велічыню ад 0 да 1000. Ну, як калі б нехта зрабіў Ctrl+C -> Ctrl+V, а потым, каб яго не злавілі, дадаў выпадковы лік ад нуля да тысячы да копіі
3. Калі б не розныя шрыфты, гэтага маглі б і не заўважыць. Але чаму розныя шрыфты? Хутчэй за ўсё, арыгінальныя дадзеныя ад страхавой кампаніі былі ў Calibri, а ўсе маніпуляцыі Дэн праводзіў на сваім камп'ютары з Cambria у эксэль ці іншай праграме, якой карыстаўся
4. Лікі ў гэтым эксэль файле агулам выглядаюць, як вынік рандомнага генератара. Калі ў людзей спытаць, колькі яны праехалі, нашмат больш людзей адкажа “нуу, 200.000 кіламетраў”, чым “нууу, 201.034 кіламетры”. А ў гэтых дадзеных месцамі няма пікаў на круглых лічбах
Але гэта яшчэ ладна - трэба было лезці і капацца. Калі вы лічыце, што навукоўцы часта пераправяраюць адзін за адным працу - гэта вы дарма. Пісаць арыгінальныя працы нашмат больш карысна для кар’еры, чым за кімьсці нешта правяраць, а калі правяраць усялякіх навуковых зорак, яны могуць у адказ паламаць табе кар’еру
Але ёсць у гэтым эксэль файле яшчэ больш смешнае. Ці Дэн адчаяны, ці яму проста пляваць, мне сказаць складана. Там ёсць размеркаванне кіламетражу за ~2 гады. Як людзі ездзяць на машынах? - нехта забіў і зусім не ездзіць, нехта ездзіць вельмі шмат, большасць ж ездзіць з сярэдняй інтэнсіўнасцю. Але ў Дэна ў дадзеных раўнамернае размеркаванне. Ну, кажучы проста, тых, хто праехаў адзін кіламетр за два гады прыкладна столькі ж, колькі тых, хто праехаў 100, 1.000, 10.000, ці 80.467 кіламетры (50.000 міль). Тых, хто праехаў больш, няма. Ну, тобок, як быццам б дадзеныя атрыманыя рандомным генератарам ад 0 да 50.000. Для таго, каб гэта пабачыць, трэба пабудаваць роўна адзін просты графік.
Гісторыя скончылася даволі стандартна для сучаснай акадэміі: артыкул адклікалі, Дэн сказаў “гэт не я”, ну і з большага ўсё. Узніклі пытанні і да іншых ягоных прац, але цяпер ён проста адказвае, што дадзеныяз’еў сабака згубіліся. Такія справы.
Прыемных TED і Google Talks відэа!
#science
На гэтым тыдні распавяду вам пра тое, як навукоўцы фальсіфікуюць дадзеныя.
Ёсць такі эканаміст і псіхолаг Dan Aierly. Дэн - навуковец папулярны, ягоныя TED размовы глядзяць мільёны людзей, размовы ў гугле - сотні тысяч. Там ён распавядае пра кагнітыўныя скажэнні, ірацыянальнасць, чаму людзі хлусяць, дурнаватых мэйнстрымавых эканамістаў, пра іншыя модныя рэчы. Ягоныя працы працытаваныя 58 тысяч разоў.
Выглядае, што Дэн таксама выдумляе свае дадзеныя.
Зразумелі гэта на прыкладзе ягонага даследавання пра хлусню з прабегам аўтамабіляў. Пры розных справах са страхоўкамі ў вас могуць спытаць пра прабег. Людзі схільныя прабег заніжаць - каб павысіць шанцы на атрыманне выплат, напрыклад. Таму часам у канцы дамовы вас просяць падпісаць нешта кшталту “дадзеныя, якія я прадставіў, праўдзівыя”. Дэн прыдумаў гіпотэзу, што калі прасіць людзей падпісаць гэта перад тым, як запытваць пра прабег, а не ў самым канцы, людзі перастаюць хлусіць. І даказаў! - прабег у сярэднім пачаў вырастаць на 10.3% альбо на 3.862 кіламетры.
Цяпер, пра вясёлае.
1. Па-першае, у эксэль файле роўна 50% дадзеных у шрыфце Calibri, а іншыя 50% - у Cambria. Пры гэтым, на любога кліента страхавой у Calibri, можна знайсці амаль такога ж кліента ў шрыфце Cambria. Тобок увесь эксэль файл складаецца з кіроўцаў-двайнікоў - проста ў розных шрыфтах
2. Любы кіроўца ў шрыфце Cambria адрозніваецца ад свайго двайніка з Calibri на выпадковую велічыню ад 0 да 1000. Ну, як калі б нехта зрабіў Ctrl+C -> Ctrl+V, а потым, каб яго не злавілі, дадаў выпадковы лік ад нуля да тысячы да копіі
3. Калі б не розныя шрыфты, гэтага маглі б і не заўважыць. Але чаму розныя шрыфты? Хутчэй за ўсё, арыгінальныя дадзеныя ад страхавой кампаніі былі ў Calibri, а ўсе маніпуляцыі Дэн праводзіў на сваім камп'ютары з Cambria у эксэль ці іншай праграме, якой карыстаўся
4. Лікі ў гэтым эксэль файле агулам выглядаюць, як вынік рандомнага генератара. Калі ў людзей спытаць, колькі яны праехалі, нашмат больш людзей адкажа “нуу, 200.000 кіламетраў”, чым “нууу, 201.034 кіламетры”. А ў гэтых дадзеных месцамі няма пікаў на круглых лічбах
Але гэта яшчэ ладна - трэба было лезці і капацца. Калі вы лічыце, што навукоўцы часта пераправяраюць адзін за адным працу - гэта вы дарма. Пісаць арыгінальныя працы нашмат больш карысна для кар’еры, чым за кімьсці нешта правяраць, а калі правяраць усялякіх навуковых зорак, яны могуць у адказ паламаць табе кар’еру
Але ёсць у гэтым эксэль файле яшчэ больш смешнае. Ці Дэн адчаяны, ці яму проста пляваць, мне сказаць складана. Там ёсць размеркаванне кіламетражу за ~2 гады. Як людзі ездзяць на машынах? - нехта забіў і зусім не ездзіць, нехта ездзіць вельмі шмат, большасць ж ездзіць з сярэдняй інтэнсіўнасцю. Але ў Дэна ў дадзеных раўнамернае размеркаванне. Ну, кажучы проста, тых, хто праехаў адзін кіламетр за два гады прыкладна столькі ж, колькі тых, хто праехаў 100, 1.000, 10.000, ці 80.467 кіламетры (50.000 міль). Тых, хто праехаў больш, няма. Ну, тобок, як быццам б дадзеныя атрыманыя рандомным генератарам ад 0 да 50.000. Для таго, каб гэта пабачыць, трэба пабудаваць роўна адзін просты графік.
Гісторыя скончылася даволі стандартна для сучаснай акадэміі: артыкул адклікалі, Дэн сказаў “гэт не я”, ну і з большага ўсё. Узніклі пытанні і да іншых ягоных прац, але цяпер ён проста адказвае, што дадзеныя
Прыемных TED і Google Talks відэа!
Wikipedia
Dan Ariely
Israeli-American professor of psychology and behavioral economics
Працягваем пра падман у навуковых артыкулах
#science
Ёсць (быў) такі навуковец Brain Wansnik. Ён дыетолаг (?), карацей food researcher - спецыяліст па харчаванні. Па стане на ўчора ў яго было 17 адкліканых навуковых артыкулаў, яшчэ 23 - пад разглядам, а сам ён вылецеў з працы.
Чаму гэта важная гісторыя? Таму што пра такія навуковыя артыкулы часта пішуць артыкулы ў СМІ: “навукоўцы даказалі, што кава выклікае рак пяткі” і кшталту таго. Больш за тое, яны кладуцца ў розныя дзяржаўныя праграмы, на падставе іх прымаюцца законы і г.д. Таксама, у яго ёсць даволі папулярная кніжка пра пераяданне, у якой на амазоне рэйтынг 4.5 з 5.
Вось некалькі сфабрыкаваных ім артыкулаў і высноў:
Калі есці з вялікіх талерак, людзі пераядаюць, калі вымушаць дзяцей “даядаць усё да чыстай талеркі”, яны таксама потым пераядаюць, калі шмат глядзець баевікоў ці токшоў, таксама, ага ага, пераядаеш, калі называць моркву “СУПЕРМОРКВА для СУПЕРГЕРОЯЎ”, дзеці больш з'ядаюць і г.д.
Усё гэта лухта. Не ў тым сэнсе, што гэтыя эфекты не могуць быць сапраўднымі (канешне дзеці будуць больш ахвотна есці буракі, чым, прабач госпадзі, “свёклу”), а ў тым сэнсе, што доказаў у гэтых артыкулах няма.
Цяпер. Адкуль мы ведаем, што доказаў там няма і там напісаная няпраўда? У адрозненні ад астатніх падманшчыкаў, якія фальсіфікуюць дадзеныя так, каб іх не злавілі, спадар Браян не запарваўся з хітрымі стратэгіямі, а проста маляваў лічбы ад балды. Уявіце, што вы пішаце: “у маіх дадзеных 20% людзей дашкольнага ўзросту”. Зразумела, што людзей не дашкольнага ўзросту ў вас павінна быць 80%. А Браян гэтымі матэматычнымі фармальнасцямі не абмежаваны: у яго можа быць і 80%, і 90%, і 50%.
Звычайна, калі заўважаюць такія памылкі, выпускаюць карэкцыі. У выпадку з Браянам, спачатку даўжыня гэтых карэкцый была больш, чым даўжыня арыгінальных артыкулаў, а потым людзі кінулі і пачалі іх проста выдаляць, маўляў занадта шмат пісаць. Аднойчы, на 4 артыкулы знайшлі 150 памылак. Натуральна, памылкі былі заўсёды ў той бок, які даказвае гіпотэзы нашага дыетолага. Ну, тобок.
#science
Ёсць (быў) такі навуковец Brain Wansnik. Ён дыетолаг (?), карацей food researcher - спецыяліст па харчаванні. Па стане на ўчора ў яго было 17 адкліканых навуковых артыкулаў, яшчэ 23 - пад разглядам, а сам ён вылецеў з працы.
Чаму гэта важная гісторыя? Таму што пра такія навуковыя артыкулы часта пішуць артыкулы ў СМІ: “навукоўцы даказалі, што кава выклікае рак пяткі” і кшталту таго. Больш за тое, яны кладуцца ў розныя дзяржаўныя праграмы, на падставе іх прымаюцца законы і г.д. Таксама, у яго ёсць даволі папулярная кніжка пра пераяданне, у якой на амазоне рэйтынг 4.5 з 5.
Вось некалькі сфабрыкаваных ім артыкулаў і высноў:
Калі есці з вялікіх талерак, людзі пераядаюць, калі вымушаць дзяцей “даядаць усё да чыстай талеркі”, яны таксама потым пераядаюць, калі шмат глядзець баевікоў ці токшоў, таксама, ага ага, пераядаеш, калі называць моркву “СУПЕРМОРКВА для СУПЕРГЕРОЯЎ”, дзеці больш з'ядаюць і г.д.
Усё гэта лухта. Не ў тым сэнсе, што гэтыя эфекты не могуць быць сапраўднымі (канешне дзеці будуць больш ахвотна есці буракі, чым, прабач госпадзі, “свёклу”), а ў тым сэнсе, што доказаў у гэтых артыкулах няма.
Цяпер. Адкуль мы ведаем, што доказаў там няма і там напісаная няпраўда? У адрозненні ад астатніх падманшчыкаў, якія фальсіфікуюць дадзеныя так, каб іх не злавілі, спадар Браян не запарваўся з хітрымі стратэгіямі, а проста маляваў лічбы ад балды. Уявіце, што вы пішаце: “у маіх дадзеных 20% людзей дашкольнага ўзросту”. Зразумела, што людзей не дашкольнага ўзросту ў вас павінна быць 80%. А Браян гэтымі матэматычнымі фармальнасцямі не абмежаваны: у яго можа быць і 80%, і 90%, і 50%.
Звычайна, калі заўважаюць такія памылкі, выпускаюць карэкцыі. У выпадку з Браянам, спачатку даўжыня гэтых карэкцый была больш, чым даўжыня арыгінальных артыкулаў, а потым людзі кінулі і пачалі іх проста выдаляць, маўляў занадта шмат пісаць. Аднойчы, на 4 артыкулы знайшлі 150 памылак. Натуральна, памылкі былі заўсёды ў той бок, які даказвае гіпотэзы нашага дыетолага. Ну, тобок.
Wikipedia
Brian Wansink
American consumer behavior researcher
Зоркі, геі і аплікацыя ў дзіцячы садок
#science
Героя самай фенаменальнай гісторыі пра навуковую фальсіфікацыю, якую я ведаю, завуць Michael LaCour. Не ведаю, як правільна чытаць ягоная імя (Міхаэль?), таму сёння ён будзе Мікалай.
Мікола быў дактарантам у Каліфарнійскім універсітэце ў Лос-Анджэлесе. Мікола, на маю думку, быў самай вялікай зоркай у 2015 годзе, прынамсі сярод студэнтаў і маладых навукоўцаў. Што ён такога зрабіў? Ён правёў даследаванне, дзе прадэманстраваў, што калі хадзіць з палітычнай агітацыяй ад дзвярэй да дзвярэй і размаўляць пра геяў з кансерватарамі, гэта зніжае іхнюю гамафобію, тут і зараз. Але праз 9 месяцаў эфект знікае - кансерватары вяртаюцца да сваіх гамафобій. Але! Калі з імі будуць размаўляць не проста агітатары, а агітатары-геі, гэта зніжае гамафобію у доўгую - яны і праз 9 месяцаў не вярталіся на свае гамафобныя пазіцыі. Больш за тое, гамафобія пачынала зніжацца спачатку ў гэтай хаце сярод сваякоў, а потым і сярод суседзяў.
Артыкул быў настолькі паспяховым, што яго апублікавалі ў Science - самым прэстыжным, аўтарытэтным і папулярным навуковым часопісе. Ён за кароткі час увайшоў у топ 5% самых папулярных навуковых артыкулаў у гісторыі. Шок-кантэнт. Мікалаю адразу прапанавалі пазіцыю ў Прынстане (і шмат яшчэ дзе, ён выбіраў), абвешалі грантамі і ўзнагародамі.
Але не ўсе маглі спакойна спаць побач з такім поспехам. Група маладых навукоўцам вырашыла паглядзець уважліва ў ягоныя дадзеныя. Тое, што яны там знайшлі - гісторыя легендарная. Знайшлі яны тое, што ніякага эксперыменту ніколі не было: дадзеныя былі сцягнутыя з іншага даследавання і крыху мадыфікаваныя, фірма, якая нібыта праводзіла апытанні, не ведала ні пра даследаванне, ні пра Мікалая і шмат, шмат чаго яшчэ.
Апынулася, што ўсё ягонае CV (рэзюмэ) таксама складаецца з фальсіфікацый: выдуманыя гранты на мільёны грошаў, якія ён не атрымліваў, конкурсы, у якіх ён не перамагаў, узнагароды, якіх ён не атрымліваў і г.д. На хвалі бязмежнага ўгару людзі праверылі яго магістарскую і там таксама знайшлі фальсіфікацыі. Калі я перастаў сачыць за гісторыяй, народ правяраў ягоныя бакалаўрскія працы і агульнае меркаванне было ў тым, што сваю аплікацыю ў дзіцячы садок ён таксама сфальсіфікаваў.
Чым скончылася ягоная навуковая кар'ера? Поўным разгромам: ён не атрымаў PhD (ці яго адразу ж забралі), пазбавіўся пазіцыі ў Прынстане, ад усіх схаваўся і здаецца пагражаў суіцыдам. Але паранёк ён спрытны, не такі просты. Пару год ён ляжаў на дне, потым змяніў імя наЛідзію Ярмошыну Michael Jules і наколькі я разумею працуе дата сайнцістам у Snapchat. І я не здзіўлены. Студэнтам ён быў відавочна таленавітым: ведаў шмат статыстыкі, меў крутыя навыкі візуалізацыі дадзеных, умеў прадаваць (нават занадта) свае даследаванні. Мяне здзіўляе ягонае рашэнне фальсіфікаваць дадзеныя - даволі відавочна, што статус навуковай зоркі ён б мог атрымаць і без гэтага. Сэ ля ві.
#science
Героя самай фенаменальнай гісторыі пра навуковую фальсіфікацыю, якую я ведаю, завуць Michael LaCour. Не ведаю, як правільна чытаць ягоная імя (Міхаэль?), таму сёння ён будзе Мікалай.
Мікола быў дактарантам у Каліфарнійскім універсітэце ў Лос-Анджэлесе. Мікола, на маю думку, быў самай вялікай зоркай у 2015 годзе, прынамсі сярод студэнтаў і маладых навукоўцаў. Што ён такога зрабіў? Ён правёў даследаванне, дзе прадэманстраваў, што калі хадзіць з палітычнай агітацыяй ад дзвярэй да дзвярэй і размаўляць пра геяў з кансерватарамі, гэта зніжае іхнюю гамафобію, тут і зараз. Але праз 9 месяцаў эфект знікае - кансерватары вяртаюцца да сваіх гамафобій. Але! Калі з імі будуць размаўляць не проста агітатары, а агітатары-геі, гэта зніжае гамафобію у доўгую - яны і праз 9 месяцаў не вярталіся на свае гамафобныя пазіцыі. Больш за тое, гамафобія пачынала зніжацца спачатку ў гэтай хаце сярод сваякоў, а потым і сярод суседзяў.
Артыкул быў настолькі паспяховым, што яго апублікавалі ў Science - самым прэстыжным, аўтарытэтным і папулярным навуковым часопісе. Ён за кароткі час увайшоў у топ 5% самых папулярных навуковых артыкулаў у гісторыі. Шок-кантэнт. Мікалаю адразу прапанавалі пазіцыю ў Прынстане (і шмат яшчэ дзе, ён выбіраў), абвешалі грантамі і ўзнагародамі.
Але не ўсе маглі спакойна спаць побач з такім поспехам. Група маладых навукоўцам вырашыла паглядзець уважліва ў ягоныя дадзеныя. Тое, што яны там знайшлі - гісторыя легендарная. Знайшлі яны тое, што ніякага эксперыменту ніколі не было: дадзеныя былі сцягнутыя з іншага даследавання і крыху мадыфікаваныя, фірма, якая нібыта праводзіла апытанні, не ведала ні пра даследаванне, ні пра Мікалая і шмат, шмат чаго яшчэ.
Апынулася, што ўсё ягонае CV (рэзюмэ) таксама складаецца з фальсіфікацый: выдуманыя гранты на мільёны грошаў, якія ён не атрымліваў, конкурсы, у якіх ён не перамагаў, узнагароды, якіх ён не атрымліваў і г.д. На хвалі бязмежнага ўгару людзі праверылі яго магістарскую і там таксама знайшлі фальсіфікацыі. Калі я перастаў сачыць за гісторыяй, народ правяраў ягоныя бакалаўрскія працы і агульнае меркаванне было ў тым, што сваю аплікацыю ў дзіцячы садок ён таксама сфальсіфікаваў.
Чым скончылася ягоная навуковая кар'ера? Поўным разгромам: ён не атрымаў PhD (ці яго адразу ж забралі), пазбавіўся пазіцыі ў Прынстане, ад усіх схаваўся і здаецца пагражаў суіцыдам. Але паранёк ён спрытны, не такі просты. Пару год ён ляжаў на дне, потым змяніў імя на
#science
Тут у твітэры чарговы рускі ліберал не можа разабрацца, як можна квантавую фізіку выкладаць па-ўкраінску. Пра беларускую мову таксама часта чуў такі аргумент.
Разбіраць імперскія комплексы рускіх лібералаў у мяне жадання няма, як і "русскость" слоў "квантавая" і "фізіка", а вось паглядзець на лінгвістычны ландшафт сучасных навук - заўсёды калі ласка.
Ёсць базы дадзеных, Web of Science і Scopus, якія індэксуюць навуковыя артыкулы. За 2018 год 93-95% усіх навуковых артыкулаў былі напісаныя па-англійску. На рускай было напісана прыкладна 0.5% усіх навуковых артыкулаў - у два разы менш, чым на іспанскай і прыкладна столькі ж, колькі на партугальскай.
Выснова з гэтага вельмі простая - ніякай мовай навукі руская не з'яўляецца. Вучыць рускую як "мову навукі" мае столькі ж сэнсу, як вучыць партугальскую. Калі вы хочаце займацца навукамі, трэба вучыць англійскую. Натуральна, ёсць выключэнні, напрыклад гісторыя - там людзі вучаць мовы тых рэгіёнаў, якімі займаюцца.
Тут у твітэры чарговы рускі ліберал не можа разабрацца, як можна квантавую фізіку выкладаць па-ўкраінску. Пра беларускую мову таксама часта чуў такі аргумент.
Разбіраць імперскія комплексы рускіх лібералаў у мяне жадання няма, як і "русскость" слоў "квантавая" і "фізіка", а вось паглядзець на лінгвістычны ландшафт сучасных навук - заўсёды калі ласка.
Ёсць базы дадзеных, Web of Science і Scopus, якія індэксуюць навуковыя артыкулы. За 2018 год 93-95% усіх навуковых артыкулаў былі напісаныя па-англійску. На рускай было напісана прыкладна 0.5% усіх навуковых артыкулаў - у два разы менш, чым на іспанскай і прыкладна столькі ж, колькі на партугальскай.
Выснова з гэтага вельмі простая - ніякай мовай навукі руская не з'яўляецца. Вучыць рускую як "мову навукі" мае столькі ж сэнсу, як вучыць партугальскую. Калі вы хочаце займацца навукамі, трэба вучыць англійскую. Натуральна, ёсць выключэнні, напрыклад гісторыя - там людзі вучаць мовы тых рэгіёнаў, якімі займаюцца.
Twitter
Fjallaleiðsögumaður
Сева Новгородцев, журналист, радиоведущий, диссидент, умница. И всё равно ёбаный имперец. Сука, ну как так? Что с ними не так вообще?!
#science
Псіхалогія - дысцыпліна правальная, у якой большасць (60-80%, у залежнасці ад таго, як лічыць) даследаванняў не праходзяць незалежную праверку. Я прыводзіў некалькі прыкладаў.
Тут зрабілі спіс вядомых і папулярных тэорый, эксперыментаў, даследаванняў, якія не прайшлі незалежную праверку. Ліст вельмі доўгі, я сканцэнтруюся на тым, што яны пазначаюць як “no good evidence” - адсутнасць добрых доказаў:
• “Стэнфардскі (турэмны) эксперымент” і ўсе ягоныя высновы. Калі сказаць адным, што яны цяпер назіральнікі, яны не пачнуць хутка здзекавацца над тымі, каму сказалі быць вязнямі
• “Эксперымент Мілгрэма”. Калі навуковец у белым халаце будзе казаць людзям біць іншых людзей токам, людзі звычайна гэтага не робяць
• Не, ураганы, якія называюцца жаночымі імёнамі, не забіваюць больш людзей, бо людзі менш баяцца жанчын
• Не выглядае, што сіла волі абмежаваная ў тым сэнсе, што і фізіялагічныя магчымасці чалавека - людзі не стамляюцца ад таго, што практыкуюць сілу волі, гэта не рэсурс
• Эфекту Даннінга — Кругера таксама верагодна не існуе. Хвіліна маўчання па тых, хто вакол гэтага мема пабудаваў сабе ідэнтычнасць
• “Множны інтэлект”, як набор статыстычна незалежных "інтэлектаў", напрыклад “эмацыйны інтэлект” vs той інтэлект, які мераецца тэстамі IQ
• Гены якія “адказваюць” за дэпрэсію. Пераправерка 18 даследаванняў з генамі-кандыдатамі паказала 0 станоўчых рэзультатаў
Псіхалогія - дысцыпліна правальная, у якой большасць (60-80%, у залежнасці ад таго, як лічыць) даследаванняў не праходзяць незалежную праверку. Я прыводзіў некалькі прыкладаў.
Тут зрабілі спіс вядомых і папулярных тэорый, эксперыментаў, даследаванняў, якія не прайшлі незалежную праверку. Ліст вельмі доўгі, я сканцэнтруюся на тым, што яны пазначаюць як “no good evidence” - адсутнасць добрых доказаў:
• “Стэнфардскі (турэмны) эксперымент” і ўсе ягоныя высновы. Калі сказаць адным, што яны цяпер назіральнікі, яны не пачнуць хутка здзекавацца над тымі, каму сказалі быць вязнямі
• “Эксперымент Мілгрэма”. Калі навуковец у белым халаце будзе казаць людзям біць іншых людзей токам, людзі звычайна гэтага не робяць
• Не, ураганы, якія называюцца жаночымі імёнамі, не забіваюць больш людзей, бо людзі менш баяцца жанчын
• Не выглядае, што сіла волі абмежаваная ў тым сэнсе, што і фізіялагічныя магчымасці чалавека - людзі не стамляюцца ад таго, што практыкуюць сілу волі, гэта не рэсурс
• Эфекту Даннінга — Кругера таксама верагодна не існуе. Хвіліна маўчання па тых, хто вакол гэтага мема пабудаваў сабе ідэнтычнасць
• “Множны інтэлект”, як набор статыстычна незалежных "інтэлектаў", напрыклад “эмацыйны інтэлект” vs той інтэлект, які мераецца тэстамі IQ
• Гены якія “адказваюць” за дэпрэсію. Пераправерка 18 даследаванняў з генамі-кандыдатамі паказала 0 станоўчых рэзультатаў
Wikipedia
Replication crisis
The replication crisis is an ongoing methodological crisis in which the results of many scientific studies are difficult or impossible to reproduce. Because the reproducibility of empirical results is an essential part of the scientific method, such failures…
#science
Выглядае, што ўбер плаціў эканамістам у Францыі і Германіі, каб яны пісалі для іх акадэмічныя паперы, у якіх падкрэслівалі перавагі ўбера: маўляў, працоўныя месцы стварае, транспартную сістэму паляпшае і г.д. Бо іхнія ўрады актыўна ставілі ўберу палкі ў колы рэгуляцыямі.
Наколькі гэта праўда ці не мне зрабіць выснову складана. Але нічога дзіўнага ў гэтым няма - фармакалагічныя кампаніі займаюцца подкупам акадэмікаў 24/7. І шмат яшчэ хто.
Год 5-7 таму часта бачыў спрэчкі пра ўбер, дзе там сям прыводзілі спасылкі на падобныя артыкулы з аргументацыяй “навука даказала”. Ахах, тобок ой.
Выглядае, што ўбер плаціў эканамістам у Францыі і Германіі, каб яны пісалі для іх акадэмічныя паперы, у якіх падкрэслівалі перавагі ўбера: маўляў, працоўныя месцы стварае, транспартную сістэму паляпшае і г.д. Бо іхнія ўрады актыўна ставілі ўберу палкі ў колы рэгуляцыямі.
Наколькі гэта праўда ці не мне зрабіць выснову складана. Але нічога дзіўнага ў гэтым няма - фармакалагічныя кампаніі займаюцца подкупам акадэмікаў 24/7. І шмат яшчэ хто.
Год 5-7 таму часта бачыў спрэчкі пра ўбер, дзе там сям прыводзілі спасылкі на падобныя артыкулы з аргументацыяй “навука даказала”. Ахах, тобок ой.
#statistics #science
Мне па працы часта прыходзіцца чытаць артыкулы пра пра менструальныя цыклы, цяжарнасці ці авуляцыі. Часам натыкаюся на вясёлы трэш. Зараз пра адзін распавяду.
Аўтары паперы знайшлі, што ў 2012 у ЗША замужнія жанчыны ў авуляцыю часцей выбіралі Ромні, а незамужнія ў авуляцыю - Абаму. Тлумачылі яны гэта прыкладна так: для незамужніх у авуляцыю важна перадаць свае гены, таму яны выбіраюць больш сіметрычнага Абаму (больш сіметрыі - лепшыя гены). А замужнія абіраюць кансерватара Ромні, бо гэта ў іх ад шлюбу развіўся механізм, які ў авуляцыю робіць іх больш кансерватыўнымі і такім чынам спрыяе захаванню шлюба.
Душэўна. Давайце ўявім, што аўтары б атрымалі вынікі наадварот - незамужнія ў авуляцыю галасуюць за кансерватараў, замужнія ў авуляцыю - за лібералаў. Прыдумаць такой якасці “тлумачэнне” - 2 хвіліны: “незамужнія выбіраюць у авуляцыю кансерватараў, бо шукаюць больш маскулінных партнёраў, а замужнія галасуюць за лібералаў, бо цяжар сямейнага быту робіць усялякія ліберальныя каштоўнасці, у тым ліку - вольныя сексуальныя паводзіны, больш прывабнымі”. Ну ці прыдумайце свой варыянт. Прыдумляць іх можна хоць да ночы.
Я гэта да чаго. Ёсць шмат прычын лічыць, што гэтае даследаванне - шум. Калі паварочаць любы шум - па рознаму вызначаць фертыльнае акно, паглядзець не на шлюбы, а на заробак, ці лакацыю і г.д. - шум пачне складацца ў патэрны. Якія патэрны мы б там не пабачылі, мы б заўсёды здолелі прыдумаць ім тлумачэнне.
Мне па працы часта прыходзіцца чытаць артыкулы пра пра менструальныя цыклы, цяжарнасці ці авуляцыі. Часам натыкаюся на вясёлы трэш. Зараз пра адзін распавяду.
Аўтары паперы знайшлі, што ў 2012 у ЗША замужнія жанчыны ў авуляцыю часцей выбіралі Ромні, а незамужнія ў авуляцыю - Абаму. Тлумачылі яны гэта прыкладна так: для незамужніх у авуляцыю важна перадаць свае гены, таму яны выбіраюць больш сіметрычнага Абаму (больш сіметрыі - лепшыя гены). А замужнія абіраюць кансерватара Ромні, бо гэта ў іх ад шлюбу развіўся механізм, які ў авуляцыю робіць іх больш кансерватыўнымі і такім чынам спрыяе захаванню шлюба.
Душэўна. Давайце ўявім, што аўтары б атрымалі вынікі наадварот - незамужнія ў авуляцыю галасуюць за кансерватараў, замужнія ў авуляцыю - за лібералаў. Прыдумаць такой якасці “тлумачэнне” - 2 хвіліны: “незамужнія выбіраюць у авуляцыю кансерватараў, бо шукаюць больш маскулінных партнёраў, а замужнія галасуюць за лібералаў, бо цяжар сямейнага быту робіць усялякія ліберальныя каштоўнасці, у тым ліку - вольныя сексуальныя паводзіны, больш прывабнымі”. Ну ці прыдумайце свой варыянт. Прыдумляць іх можна хоць да ночы.
Я гэта да чаго. Ёсць шмат прычын лічыць, што гэтае даследаванне - шум. Калі паварочаць любы шум - па рознаму вызначаць фертыльнае акно, паглядзець не на шлюбы, а на заробак, ці лакацыю і г.д. - шум пачне складацца ў патэрны. Якія патэрны мы б там не пабачылі, мы б заўсёды здолелі прыдумаць ім тлумачэнне.