
Почему не нужно указывать размер освобождаемого блока для free()
Второй пост в формате телеграф статьи. Поговорим о том, как так вышло, что не нужно указывать размер освобождаемой памяти для функции free. Поговорим про API, отправимся в прошлое на 40 лет назад и представим, как принималось это решение.
Понимаю, что формат лонгридов подходит не всем в нашем hectic lifestyle мире. Но тема реально интересная, особенно, если вы никогда об этом не задумывались.
Накидайте реакций на этот пост, если вам нравится такой формат, чтобы я понимал, что это востребовано в нашем маленьком(пока что) коммьюнити.
Ссылочка на статью: https://telegra.ph/Pochemu-ne-nuzhno-ukazyvat-razmer-osvobozhdaemogo-bloka-dlya-free-12-07
Stay cool.
#hardcore #OS #memory #howitworks
Второй пост в формате телеграф статьи. Поговорим о том, как так вышло, что не нужно указывать размер освобождаемой памяти для функции free. Поговорим про API, отправимся в прошлое на 40 лет назад и представим, как принималось это решение.
Понимаю, что формат лонгридов подходит не всем в нашем hectic lifestyle мире. Но тема реально интересная, особенно, если вы никогда об этом не задумывались.
Накидайте реакций на этот пост, если вам нравится такой формат, чтобы я понимал, что это востребовано в нашем маленьком(пока что) коммьюнити.
Ссылочка на статью: https://telegra.ph/Pochemu-ne-nuzhno-ukazyvat-razmer-osvobozhdaemogo-bloka-dlya-free-12-07
Stay cool.
#hardcore #OS #memory #howitworks
Telegraph
Почему не нужно указывать размер освобождаемого блока для free()
Мы уже знаем, почему стандартный сишный аллокатор при удалении не просит указывать количество освобождаемых байт. Это более подробно раскрывается тут и тут. Вопрос скорее в другом. Почему вообще malloc+free было создано таким образом. Поскольку C - это язык…
Вызываем метод класса через указатель
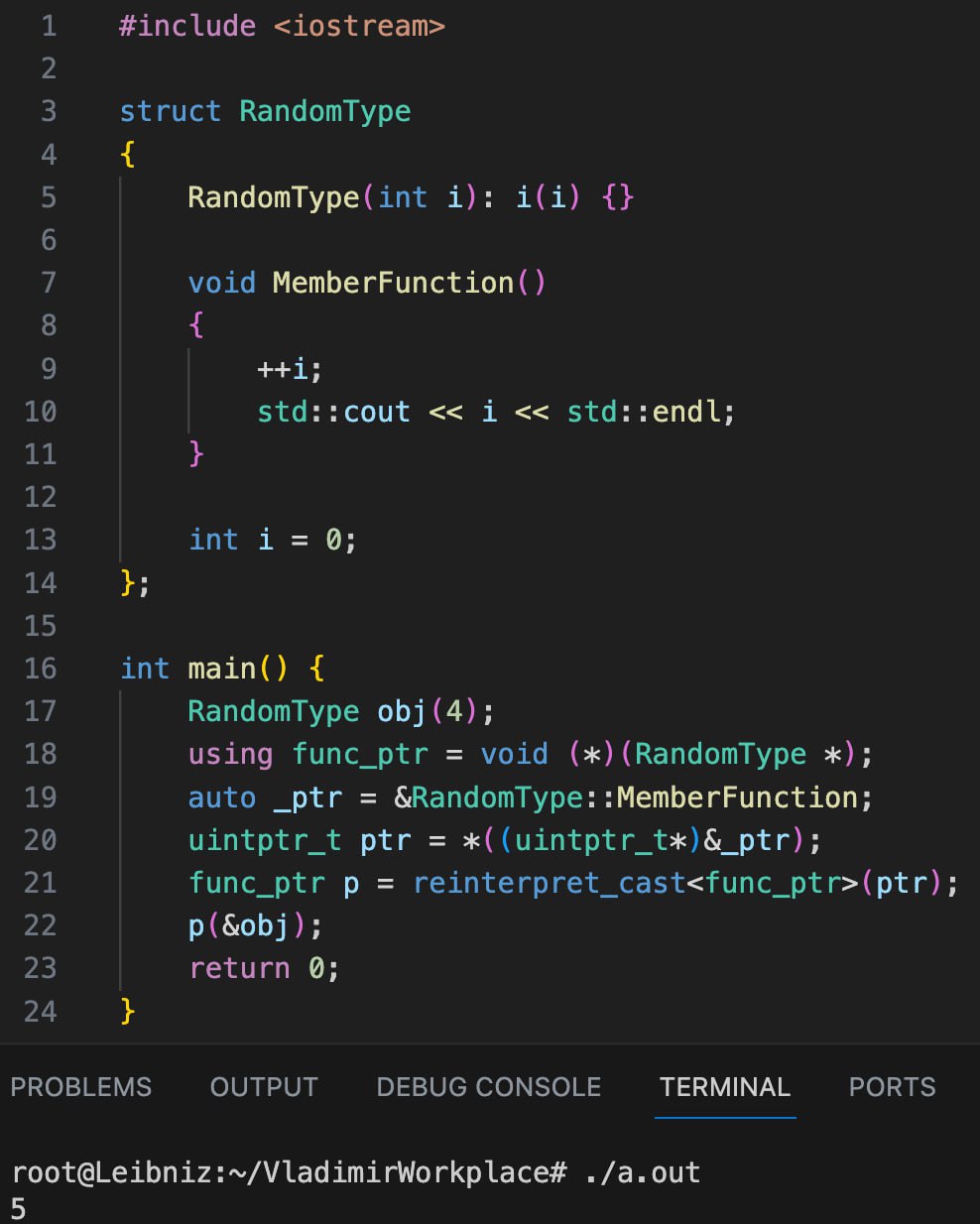
Настоящего плюсовика не должны пугать указатели на функции. И хоть в С++ есть нормальная обертка над всеми сущностями, которые можно исполнить - std::function - она довольно тяжеловесная и медленная. Да и с сишным апи с ней не поработаешь. К чему это я. Да. Указатели на функции. С ними, в целом, все просто.
int func() {
return 1;
}
using func_ptr = int (*) ();
func_ptr ptr = func;
std::cout << ptr();
Этот код со всеми обертками должен написать единичку на экран. С более сложными функциями сделать что-то похожее не составит труда. Но вот как насчет методов класса? Можно ли вызвать метод класса через указатель на него, а не через объект?
Ответ - можно. Но прежде чем посмотреть на рабочий код, попробуйте сами это сделать. Уверяю, что это не так тривиально)
Если читаете с телефона или нет времени, лучше вернитесь к этому посту после того, как попробуете сами. Эмоции будут совершенно другие)
Ну а для тех, кто уже попробовал или для ленивых дяденек, продолжаю.
Первое, что приходит на ум - такой же подход, как и с функциями.
auto ptr = RandomType::MemberFunction;
И тут же гцц плюнет вам в лицо с фразой error: invalid use of non-static member function ‘void RandomType::MemberFunction()’
auto ptr = RandomType::MemberFunction;
На этом я и закончил пробовать и пошел ресерчить. А снизу код, который у меня получился по итогам моих поисков. Все в духе С, ничего не понятно, одни указатели. Выглядит как фокус и по факту им и является. В следующий раз объясню, почему все так.
Stay hardcore. Stay cool.
#fun #hardcore #memory #cppcore
Настоящего плюсовика не должны пугать указатели на функции. И хоть в С++ есть нормальная обертка над всеми сущностями, которые можно исполнить - std::function - она довольно тяжеловесная и медленная. Да и с сишным апи с ней не поработаешь. К чему это я. Да. Указатели на функции. С ними, в целом, все просто.
int func() {
return 1;
}
using func_ptr = int (*) ();
func_ptr ptr = func;
std::cout << ptr();
Этот код со всеми обертками должен написать единичку на экран. С более сложными функциями сделать что-то похожее не составит труда. Но вот как насчет методов класса? Можно ли вызвать метод класса через указатель на него, а не через объект?
Ответ - можно. Но прежде чем посмотреть на рабочий код, попробуйте сами это сделать. Уверяю, что это не так тривиально)
Если читаете с телефона или нет времени, лучше вернитесь к этому посту после того, как попробуете сами. Эмоции будут совершенно другие)
Ну а для тех, кто уже попробовал или для ленивых дяденек, продолжаю.
Первое, что приходит на ум - такой же подход, как и с функциями.
auto ptr = RandomType::MemberFunction;
И тут же гцц плюнет вам в лицо с фразой error: invalid use of non-static member function ‘void RandomType::MemberFunction()’
auto ptr = RandomType::MemberFunction;
На этом я и закончил пробовать и пошел ресерчить. А снизу код, который у меня получился по итогам моих поисков. Все в духе С, ничего не понятно, одни указатели. Выглядит как фокус и по факту им и является. В следующий раз объясню, почему все так.
Stay hardcore. Stay cool.
#fun #hardcore #memory #cppcore
{kind=link}
Продолжение про вызов метода через указатель
В прошлом мы выяснили, как можно вызвать нестатический метод класса через указатель. Пост с кодом находится здесь. Для удобства, прикреплю его и к сюда. Сегодня мы попробуем разобраться, почему код такой и он еще и рабочий? Пойдем по порядку. Совсем тривиальные вещи затрагиваться не будут, будут только важные в контексте объяснения.
18 строка - Объявляется синоним к типу указателя на функцию, которая ничего не возвращает и принимает указатель на тип RandomType. Позже будет понятно, зачем это нужно.
19 строка - Есть 2 возможных синтаксиса для получения указателя на функцию: с амперсантом(сюрприз, кто не знал) и без. Без амперсанта не работает, потому такой синтаксис уже используется для вызова статических методов и будет путаница. Итак, мы получили какого-то неизвестного нам типа указатель на функцию. Идем дальше.
20 строка - Это трюк, который позволяет превратить указатель на функцию в указатель на число. Это необходимо для того, чтобы скастовать указатель _ptr из 19 строки к указателю на функцию типа func_ptr. Такого рода касты очень опасные и ведут к неопределенному поведению. Поэтому компиляторы просто их запрещают. Поэтому и нужно какое-то прокси состояние. Только компиляторы также запрещают кастовать указатель на функцию к указателю на число. Поэтому в ход идет наращивание индирекции указателя.
Мы можем посмотреть не на сам указатель, а на ячейку памяти, которая хранит наш указатель. И сказать, что по этому адресу лежит не указатель на функцию, а указатель на число. Вот так сделать можно. А потом кастуем указатель на число к указателю на функцию. Так тоже можно сделать.
И, наконец, важнейший пункт. Помните в книжках всегда говорили, что в методы скрытно передается указатель на вызывающий его объект this? Так вот сейчас вам скорее всего впервые понадобится это знание на практике!
Методы неполиморфных классов - те же самые обычные функции(кто не знал). От остальных их отличает лишь этот параметр this, который скрытно передается первым аргументом. Именно поэтому, чтобы вызвать нестатический метод, нам нужен объект. Чтобы передать его первым параметром в функцию. Иначе вызов будет не соответствовать сигнатуре.
Поэтому мы берем созданный на стеке объект, находим адрес первого байта и передаем его в метод в качестве аргумента.
И вуаля. Все работает. Выводится пятёрочка.
Кто понял, тот понял. Кто не понял - сорян, я сделал, что мог. Но есть хорошая новость - эту задачу можно решить и более щедящим способом, хоть и не таким элегантным с точки зрения важности первого аргумента. В будущем разберем его.
Из этого поста надо вынести главное: ООП - лишь абстракция над более примитивными и низкоуровневыми конструкциями. Уметь оперировать абстракциями - полезнейший навык в нашем мире. Чем более сложные абстракции ты обрабатываешь, тем больше понимаешь мир и эффективнее решаешь задачи. Однако знать те самые кирпичики, на которых строятся сложные конструкции - не менее важная вещь. Только полная картина мира дает полное понимание происходящего.
Конструируй абстракции и погружайся в детали. Stay cool.
#fun #memory #howitworks #cppcore #hardcore
В прошлом мы выяснили, как можно вызвать нестатический метод класса через указатель. Пост с кодом находится здесь. Для удобства, прикреплю его и к сюда. Сегодня мы попробуем разобраться, почему код такой и он еще и рабочий? Пойдем по порядку. Совсем тривиальные вещи затрагиваться не будут, будут только важные в контексте объяснения.
18 строка - Объявляется синоним к типу указателя на функцию, которая ничего не возвращает и принимает указатель на тип RandomType. Позже будет понятно, зачем это нужно.
19 строка - Есть 2 возможных синтаксиса для получения указателя на функцию: с амперсантом(сюрприз, кто не знал) и без. Без амперсанта не работает, потому такой синтаксис уже используется для вызова статических методов и будет путаница. Итак, мы получили какого-то неизвестного нам типа указатель на функцию. Идем дальше.
20 строка - Это трюк, который позволяет превратить указатель на функцию в указатель на число. Это необходимо для того, чтобы скастовать указатель _ptr из 19 строки к указателю на функцию типа func_ptr. Такого рода касты очень опасные и ведут к неопределенному поведению. Поэтому компиляторы просто их запрещают. Поэтому и нужно какое-то прокси состояние. Только компиляторы также запрещают кастовать указатель на функцию к указателю на число. Поэтому в ход идет наращивание индирекции указателя.
Мы можем посмотреть не на сам указатель, а на ячейку памяти, которая хранит наш указатель. И сказать, что по этому адресу лежит не указатель на функцию, а указатель на число. Вот так сделать можно. А потом кастуем указатель на число к указателю на функцию. Так тоже можно сделать.
И, наконец, важнейший пункт. Помните в книжках всегда говорили, что в методы скрытно передается указатель на вызывающий его объект this? Так вот сейчас вам скорее всего впервые понадобится это знание на практике!
Методы неполиморфных классов - те же самые обычные функции(кто не знал). От остальных их отличает лишь этот параметр this, который скрытно передается первым аргументом. Именно поэтому, чтобы вызвать нестатический метод, нам нужен объект. Чтобы передать его первым параметром в функцию. Иначе вызов будет не соответствовать сигнатуре.
Поэтому мы берем созданный на стеке объект, находим адрес первого байта и передаем его в метод в качестве аргумента.
И вуаля. Все работает. Выводится пятёрочка.
Кто понял, тот понял. Кто не понял - сорян, я сделал, что мог. Но есть хорошая новость - эту задачу можно решить и более щедящим способом, хоть и не таким элегантным с точки зрения важности первого аргумента. В будущем разберем его.
Из этого поста надо вынести главное: ООП - лишь абстракция над более примитивными и низкоуровневыми конструкциями. Уметь оперировать абстракциями - полезнейший навык в нашем мире. Чем более сложные абстракции ты обрабатываешь, тем больше понимаешь мир и эффективнее решаешь задачи. Однако знать те самые кирпичики, на которых строятся сложные конструкции - не менее важная вещь. Только полная картина мира дает полное понимание происходящего.
Конструируй абстракции и погружайся в детали. Stay cool.
#fun #memory #howitworks #cppcore #hardcore
{kind=link}
Квантовая суперпозиция bool переменных
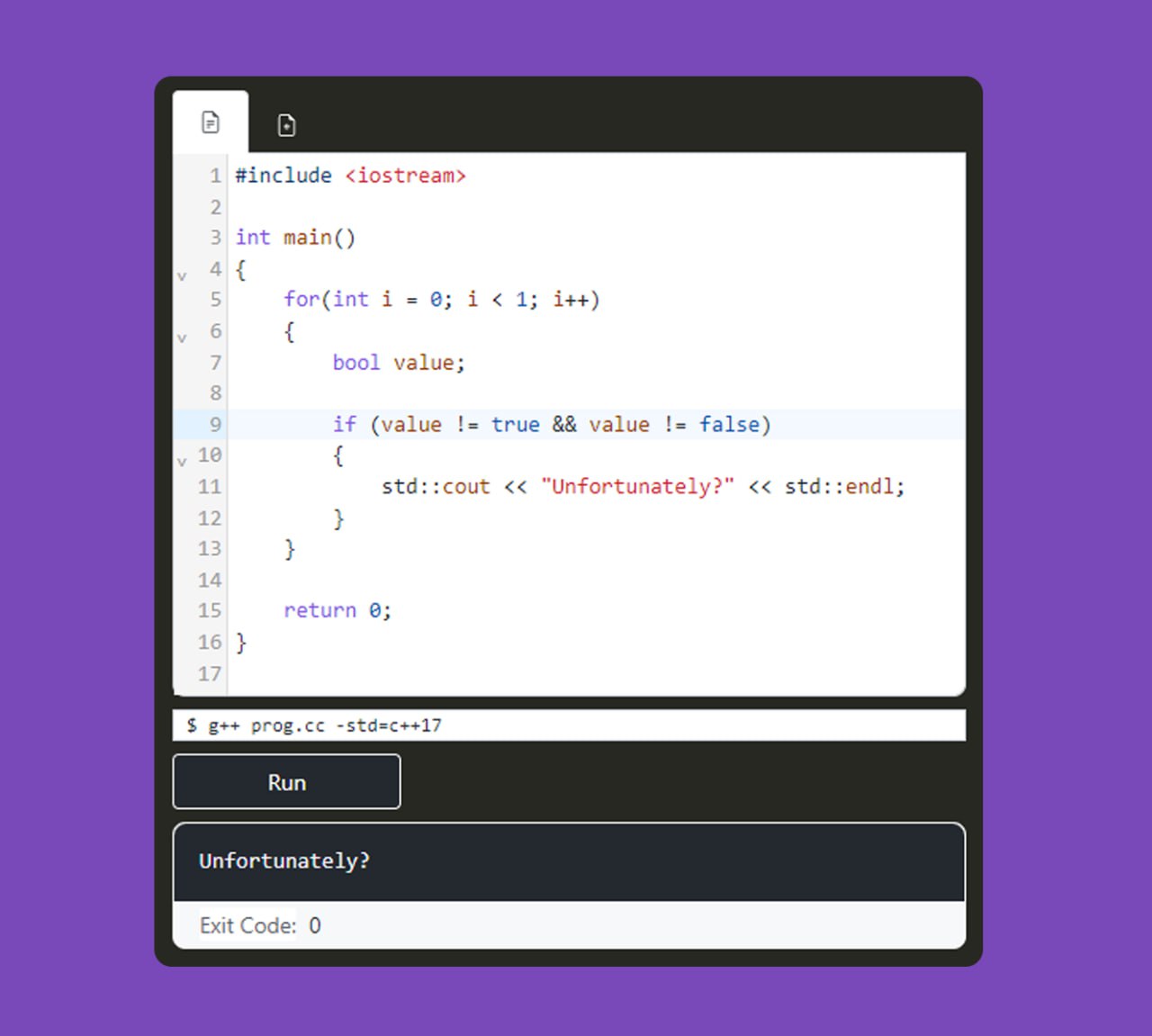
Наверно у многих в головах давно лежит прямая и четкая ассоциация, что тип данных bool всегда принимает значение true или false. Спешу развеять ваши убеждения!
На первый взгляд кажется, что такая ветка условия никогда не может быть выполнена:
Но, неожиданно и к сожалению, у менять есть вот такой пример: https://compiler-explorer.com/z/jf7zE64eq
С точки зрения ожидаемой модели языка C++ это невозможно, т.к. модель не предполагает какого-либо еще состояния логической переменной. Однако, если знать, что находится под капотом булей, то все становится вполне очевидным.
Небольшой экскурс в историю. Раньше в языке C такого типа как bool не существовало в принципе. Вместо него использовались целочисленные переменные, такие как int. Неявное приведение происходит по правилу:
Но как мы знаем, С++ во многом совместимым с С. Следовательно, он перенимает некоторые особенности своего прародителя, поэтому логическая переменная может скрывать под собой абсолютно любое целочисленное значение! И напротив, логические константы true и false однозначно определены, как 1 и 0 соответственно.
Получается, что на самом деле мы работаем с этим:
Конечно, в С++ этого получается почти всегда избежать, т.к. есть заранее определенные константы и неявные преобразования к типу bool. Но все же иногда бывают случаи, когда этого недостаточно. Например, когда переменная осталась неинициализированной.
Чисто теоретически можно создать другие, очень специфичные условия. Приведу другой пример, но напоминаю -- это UB: https://compiler-explorer.com/z/fn6YPvnzP
Да, просто под капотом сравнивается
У вас могут появиться вопросы, зачем нам может понадобиться такое знание? Это ведь, фактически, UB, которое надо постараться воспроизвести!
Приведу практический пример из моей опыта. Я написал этот код несколько лет назад. Мне хотелось избежать лишних условных ветвлений в коде и написать что-то типа такого:
А-ля, если логическая переменная
Пока что этот код не выстрелил :) Но я вижу его проблему... Так что перепроверяйте некоторые очевидные убеждения и пишите безопасный код!
#hardcore #cppcore #goodoldc
Наверно у многих в головах давно лежит прямая и четкая ассоциация, что тип данных bool всегда принимает значение true или false. Спешу развеять ваши убеждения!
На первый взгляд кажется, что такая ветка условия никогда не может быть выполнена:
bool condition;
if (condition != true && condition != false)
{
// Недостижимый код?
}
Но, неожиданно и к сожалению, у менять есть вот такой пример: https://compiler-explorer.com/z/jf7zE64eq
С точки зрения ожидаемой модели языка C++ это невозможно, т.к. модель не предполагает какого-либо еще состояния логической переменной. Однако, если знать, что находится под капотом булей, то все становится вполне очевидным.
Небольшой экскурс в историю. Раньше в языке C такого типа как bool не существовало в принципе. Вместо него использовались целочисленные переменные, такие как int. Неявное приведение происходит по правилу:
0 -> false, иначе true. Приведу пример:if ( 0) // false
if ( 1) // true
if ( 2) // true
if (-1) // true
Но как мы знаем, С++ во многом совместимым с С. Следовательно, он перенимает некоторые особенности своего прародителя, поэтому логическая переменная может скрывать под собой абсолютно любое целочисленное значение! И напротив, логические константы true и false однозначно определены, как 1 и 0 соответственно.
Получается, что на самом деле мы работаем с этим:
int condition; // Неинициализированное значение
if (condition != 1 && condition != 0)
{
// Вполне себе достимый код
}
Конечно, в С++ этого получается почти всегда избежать, т.к. есть заранее определенные константы и неявные преобразования к типу bool. Но все же иногда бывают случаи, когда этого недостаточно. Например, когда переменная осталась неинициализированной.
Чисто теоретически можно создать другие, очень специфичные условия. Приведу другой пример, но напоминаю -- это UB: https://compiler-explorer.com/z/fn6YPvnzP
Да, просто под капотом сравнивается
10 != 1 - и никакой магии. Но увидеть это порой столь же неожиданно.У вас могут появиться вопросы, зачем нам может понадобиться такое знание? Это ведь, фактически, UB, которое надо постараться воспроизвести!
Приведу практический пример из моей опыта. Я написал этот код несколько лет назад. Мне хотелось избежать лишних условных ветвлений в коде и написать что-то типа такого:
bool condition = ???;
int position = index + static_cast<int>(condition);
А-ля, если логическая переменная
condition == true (типа оно равно 1), значит index + 1, иначе index + 0. Так вот на самом деле нельзя с уверенностью сказать, какое целочисленное значение лежит под булем.Пока что этот код не выстрелил :) Но я вижу его проблему... Так что перепроверяйте некоторые очевидные убеждения и пишите безопасный код!
#hardcore #cppcore #goodoldc
{kind=link}
Сколько памяти вы можете аллоцировать?
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
{kind=link}
Как система может выделить 131 Терабайт оперативы?
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
{kind=link}
std::byte
Если вы приличное время работаете с байтами на низком уровне, вы понимаете, что стандартные сишные возможности репрезентации сырых байтов данных не очень удобные. В основном сложности, конечно, в семантике. Вот возьмём какой-нибудь указатель на чар char *. Что это? Символ, число или просто сырой байт? Да, со временем это уже откладывается на подкорке, все всё понимают, ничего лучше же нет. Или есть?
Что такое std::byte?
std::byte — это фундаментальный тип данных, предназначенный для представления необработанных байтов памяти. Это неотъемлемая часть стандарта C++17, призванная обеспечить стандартизированный способ работы с необработанными двоичными данными. В отличие от базовых числовых типов, таких как char, int или float, std::byte — это отдельный тип, оптимизированный для операций на уровне байтов, что делает его более подходящим для задач, связанных с манипулированием памятью и низкоуровневым программированием.
Откуда оно взялось?
На самом деле все просто. В cтандарте этот тип определяется как enum class byte : unsigned char {} ;
Выглядит просто, но такая сущность давно напрашивалась. В плюсах есть большая необходимость в стандартизированном, независимом от платформы способа манипулирования необработанными двоичными данными, особенно в таких сценариях, как сериализация данных, работа с сетевыми протоколами и взаимодействие с оборудованием. Появление отдельного типа для байтов в C++17 частично решило эти проблемы, так как std::byte:
1️⃣ Обеспечивает строгое разделение манипуляций с сырой памятью от числовых типов. Вы сразу видите, что оперируете с байтами, что снижает риск путаницы с типами данных.
2️⃣ Обеспечивает безопасность при проверке типов. Операции над std::byte выполняются без непреднамеренного преобразования типов, так как нет переопределенных операторов преобразования в базовые типы. Это помогает выявить потенциальные проблемы, связанные с типами, и повышает безопасность кода при работе с данными низкого уровня.
3️⃣ Явно поддерживает только байтовую и битовую арифметику за счёт переопределенных операторов сравнения и битовых манипуляций. Это с одной стороны, ограничивает функционал класса, а, с другой стороны, че вы ещё хотите делать с байтами?
4️⃣ В качестве стандартной фичи C++ использование std::byte обеспечивает безопасность вашего кода на уровне языка.
Есть один единственный минус у этой фичи. Очень мало народу ей пользуется. Большинству существующих проектов на плюсах больше 5 лет и там есть уже свои привычные методы работы с сырой памятью и сишным интерфейсом, которые естественно все завязано на типе char. И только потому, что в стандарте появилась новая фича, никто эти методы изменять не будет. Да и новые проекты могут по инерции использовать старый подход. Он всем знаком и проверен временем.
Так что и, хоть вам не часто доведётся работать с этим типом, знать о его существовании и функционале есть смысл. Вы всегда можете написать новый микросервис или модуль в вашем проекте с использование этой фичи и сделаете код лучше и безопаснее.
Stay hardcore. Stay cool.
#cpp17 #memory #hardcore
Если вы приличное время работаете с байтами на низком уровне, вы понимаете, что стандартные сишные возможности репрезентации сырых байтов данных не очень удобные. В основном сложности, конечно, в семантике. Вот возьмём какой-нибудь указатель на чар char *. Что это? Символ, число или просто сырой байт? Да, со временем это уже откладывается на подкорке, все всё понимают, ничего лучше же нет. Или есть?
Что такое std::byte?
std::byte — это фундаментальный тип данных, предназначенный для представления необработанных байтов памяти. Это неотъемлемая часть стандарта C++17, призванная обеспечить стандартизированный способ работы с необработанными двоичными данными. В отличие от базовых числовых типов, таких как char, int или float, std::byte — это отдельный тип, оптимизированный для операций на уровне байтов, что делает его более подходящим для задач, связанных с манипулированием памятью и низкоуровневым программированием.
Откуда оно взялось?
На самом деле все просто. В cтандарте этот тип определяется как enum class byte : unsigned char {} ;
Выглядит просто, но такая сущность давно напрашивалась. В плюсах есть большая необходимость в стандартизированном, независимом от платформы способа манипулирования необработанными двоичными данными, особенно в таких сценариях, как сериализация данных, работа с сетевыми протоколами и взаимодействие с оборудованием. Появление отдельного типа для байтов в C++17 частично решило эти проблемы, так как std::byte:
1️⃣ Обеспечивает строгое разделение манипуляций с сырой памятью от числовых типов. Вы сразу видите, что оперируете с байтами, что снижает риск путаницы с типами данных.
2️⃣ Обеспечивает безопасность при проверке типов. Операции над std::byte выполняются без непреднамеренного преобразования типов, так как нет переопределенных операторов преобразования в базовые типы. Это помогает выявить потенциальные проблемы, связанные с типами, и повышает безопасность кода при работе с данными низкого уровня.
3️⃣ Явно поддерживает только байтовую и битовую арифметику за счёт переопределенных операторов сравнения и битовых манипуляций. Это с одной стороны, ограничивает функционал класса, а, с другой стороны, че вы ещё хотите делать с байтами?
4️⃣ В качестве стандартной фичи C++ использование std::byte обеспечивает безопасность вашего кода на уровне языка.
Есть один единственный минус у этой фичи. Очень мало народу ей пользуется. Большинству существующих проектов на плюсах больше 5 лет и там есть уже свои привычные методы работы с сырой памятью и сишным интерфейсом, которые естественно все завязано на типе char. И только потому, что в стандарте появилась новая фича, никто эти методы изменять не будет. Да и новые проекты могут по инерции использовать старый подход. Он всем знаком и проверен временем.
Так что и, хоть вам не часто доведётся работать с этим типом, знать о его существовании и функционале есть смысл. Вы всегда можете написать новый микросервис или модуль в вашем проекте с использование этой фичи и сделаете код лучше и безопаснее.
Stay hardcore. Stay cool.
#cpp17 #memory #hardcore
{kind=link}
Рефлексия
Вам когда-нибудь хотелось получить значение enum'а, который имеет имя, соответствующее определенной строке? Или например во время выполнения на основе данных конфига выбрать подходящий класс для обработки? Или вызвать метод класса с помощью строки, содержащей его имя? Да все это в плюсах можно сделать, но какой ценой. Нужны эти нагромождения условных конструкций, которые смотрятся просто ужасно и от которых глаза вытекают из орбит. Почему нельзя сделать так, чтобы существовала какая-то структура, типа словаря, к которому можно обращаться в рантайме и выбирать произвольный тип, из которого я хочу создать объект?
Ответ прост. Можно. Но не в плюсах)
Эта фича называется рефлексией. То есть это способность программы получать информацию о своей структуре и изменять ее. Простым языком: она позволяет вам вызывать методы объектов, создавать новые объекты, модифицировать их, даже не зная имён интерфейсов, полей, методов во время компиляции. Из-за такой природы рефлексии её труднее реализовать в статически типизированных языках, поскольку ошибки типизации должны быть отловлены во время компиляции, а не исполнения программы, чтобы все работало корректно. И хоть это возможно для байт-код языков, типа жабы и Си за решеткой, но для плюсов это сделать очень трудно. Вы конечно сами где-нибудь можете набросать какой-то код, который будет имитировать рефлексию, но полноценного стандартного решения рантайм рефлексии мы не получить не можем и на это есть несколько причин.
1️⃣ Язык C++ имеет совместимость с языком C и является его логическим приемником. Поэтому он стремится быть эффективным и близким к машинному коду. Полноценная рефлексия встроенная в язык требует дополнительные значительные вычислительные и ресурсные затраты, что может не соответствовать целям C++ для высокой производительности и низкого уровня абстракции. Как говорится, не плати за то, чем не пользуешься(слоган эмбеддед разработчиков по жизни).
2️⃣ Сюрприз: эффективность кода. Компиляторы с++ знамениты тем, что издеваются над нашим кодом во всех непристойных позициях и выдают самый эффективный машинный код. Они могут разворачивать циклы, встраивать функции и даже целые классы. Это все нужно для максимальной скорости и работает только за счет того, что все известно на момент компиляции. Что позволяет избегать накладных расходов и предоставлять предсказуемое поведение(не всегда). А рефлексия может нарушить эту предсказуемость, а значит и производительность.
Тем не менее плюсы медленно, но верно продвигаются в расширении рефлексивной функциональности. Мало того, что шаблонная магия позволяет из коробки делать очень многие вещи, так и в современных стандартах появляются такие штуки, как std::any, std::experimental::source_location и тд. Вряд ли когда-нибудь завезут что-то стандартное, подходящее всем и для любых целей, если за 40 лет этого так и не случилось ни с одной библиотекой или модулем. Но тенденция явно позитивная. А в пропоузале к С++26 есть даже целый раздел, посвященный статической рефлексии. Так что per aspera ad astra.
Stay optimistic. Stay cool.
#howitworks #hardcore
Вам когда-нибудь хотелось получить значение enum'а, который имеет имя, соответствующее определенной строке? Или например во время выполнения на основе данных конфига выбрать подходящий класс для обработки? Или вызвать метод класса с помощью строки, содержащей его имя? Да все это в плюсах можно сделать, но какой ценой. Нужны эти нагромождения условных конструкций, которые смотрятся просто ужасно и от которых глаза вытекают из орбит. Почему нельзя сделать так, чтобы существовала какая-то структура, типа словаря, к которому можно обращаться в рантайме и выбирать произвольный тип, из которого я хочу создать объект?
Ответ прост. Можно. Но не в плюсах)
Эта фича называется рефлексией. То есть это способность программы получать информацию о своей структуре и изменять ее. Простым языком: она позволяет вам вызывать методы объектов, создавать новые объекты, модифицировать их, даже не зная имён интерфейсов, полей, методов во время компиляции. Из-за такой природы рефлексии её труднее реализовать в статически типизированных языках, поскольку ошибки типизации должны быть отловлены во время компиляции, а не исполнения программы, чтобы все работало корректно. И хоть это возможно для байт-код языков, типа жабы и Си за решеткой, но для плюсов это сделать очень трудно. Вы конечно сами где-нибудь можете набросать какой-то код, который будет имитировать рефлексию, но полноценного стандартного решения рантайм рефлексии мы не получить не можем и на это есть несколько причин.
1️⃣ Язык C++ имеет совместимость с языком C и является его логическим приемником. Поэтому он стремится быть эффективным и близким к машинному коду. Полноценная рефлексия встроенная в язык требует дополнительные значительные вычислительные и ресурсные затраты, что может не соответствовать целям C++ для высокой производительности и низкого уровня абстракции. Как говорится, не плати за то, чем не пользуешься(слоган эмбеддед разработчиков по жизни).
2️⃣ Сюрприз: эффективность кода. Компиляторы с++ знамениты тем, что издеваются над нашим кодом во всех непристойных позициях и выдают самый эффективный машинный код. Они могут разворачивать циклы, встраивать функции и даже целые классы. Это все нужно для максимальной скорости и работает только за счет того, что все известно на момент компиляции. Что позволяет избегать накладных расходов и предоставлять предсказуемое поведение(не всегда). А рефлексия может нарушить эту предсказуемость, а значит и производительность.
Тем не менее плюсы медленно, но верно продвигаются в расширении рефлексивной функциональности. Мало того, что шаблонная магия позволяет из коробки делать очень многие вещи, так и в современных стандартах появляются такие штуки, как std::any, std::experimental::source_location и тд. Вряд ли когда-нибудь завезут что-то стандартное, подходящее всем и для любых целей, если за 40 лет этого так и не случилось ни с одной библиотекой или модулем. Но тенденция явно позитивная. А в пропоузале к С++26 есть даже целый раздел, посвященный статической рефлексии. Так что per aspera ad astra.
Stay optimistic. Stay cool.
#howitworks #hardcore
{kind=link}
Application Binary Interface
Вчера разобрали, что обратная совместимость ABI играет значительную роль при разработке shared библиотек. Но это только применение этого понятие, сам термин мы еще не разбирали. Сегодня исправим этот момент.
ABI - набор правил, которые определяют соглашения о вызовах и расположение структур(стека, ваших кастомных и тд) в памяти. Соглашение о вызовах, наверное, здесь центровую роль играет. В общих словах, это какие операции нужно делать, чтобы выполнить функцию. Компьютер на самом деле не знает, что такое "выполнить функцию". Он знает лишь небольшой набор команд. Типа сложить, переместить, прыгнуть. То, как передаются аргументы для функции - через стек или через регистры, в каком порядке передаются аргументы, как очищать регистры, куда сохранять возвращаемое значение, и определяет calling convention. Но это что-то низкоуровневое, нам бы поближе к коду.
Сравним с API. Если API говорит, что вот есть такой-то набор функций и вы можете их использовать. То ABI говорит, как вы должны этими функциями пользоваться. Ну не вы, а скомпилированный код. Можно представить себе, что все детали того, что нужно сделать процессору, чтобы выполнить ваш код - это и есть ABI. То есть, как API, только на уровень ниже.
Что может изменить ABI? Очень много вещей. Именно поэтому имплементацию выносят в отдельный класс. Всего одна перестановка полей класса местами ломает низкоуровневое представление о том, как работать с вашим кодом. Потому что для доступа к определенному полю нужен определенный сдвиг от начала данных объекта. При перестановке эти сдвиги меняются и использование вашего кода без перекомпиляции будет вести к неправильной работе приложения.
Приведу некоторые изменения в коде, которые могут аффектить ABI.
👉🏿 Добавление, удаление и изменение порядка полей класса.
👉🏿 Изменение иерархии классов. Данные всех базовых классов лежат в определенном порядке, изменение иерархии влечет изменения в том, как данные объекта располагаются в памяти.
👉🏿 Изменение шаблонных аргументов в шаблонных классах. Это влияет на то, какое mangled имя будет у класса, и соответсвенно, то как к нему обращаться.
👉🏿 Объявление функции как inline. Компилятор может встроить такую функцию и ее имени просто больше не будет в списке доступных функций.
👉🏿 Изменение сигнатуры функций, включая cv-квалификаторы. Тоже по причине манглинга.
👉🏿 Добавление первого виртуального метода. Обычно внутри объекта появляется vptr, это ведет к изменению расположения объекта в памяти.
👉🏿 Изменение порядка объявления виртуальных методов. В таблице виртуальных функций они располагаются по порядку и вызываются по порядку. Изменив порядок можно вызвать не тот метод.
👉🏿 Изменение набора приватных методов. Ну а здесь-то што?! Клиент же их даже вызвать не может? Дело в том, что приватные методы участвуют в разрешении перегрузок, поэтому клиентский код в каком-то смысле имеет к ним доступ и знает об этом наборе методов. Его изменение в коде не перезаписывает знание клиента о нем, поэтому низя так делать.
👉🏿 И еще куча приколюх с наследованием.
Деталей очень много и списочек там реально очень большой. Я привел только самую верхушку, которую все понимают.
И вот при стандартном подходе с header/implementation любое изменение из этого списка влечет за собой перекомпиляцию всего кода, использующего ваш класс. А это как бы пипец. Почти любая реальная промышленная плюсовая задача требует таких изменений.
При использовании pimpl мы избегаем такого исхода. Указатель - он и в Африке указатель. На заданной платформе имеет один и тот же размер. И пока вы не делаете этих "опасных" изменений в публичном классе, его структура никак не изменяется. А обычно таких изменений не делают, потому что там оставляют только базовый API, который очень стабилен.
Вот такие пироги. Надеюсь, этот пост прояснил некоторые вопросы, которые могли вчера у вас возникнуть.
Stay compatible. Stay cool.
#design #hardcore #cppcore
Вчера разобрали, что обратная совместимость ABI играет значительную роль при разработке shared библиотек. Но это только применение этого понятие, сам термин мы еще не разбирали. Сегодня исправим этот момент.
ABI - набор правил, которые определяют соглашения о вызовах и расположение структур(стека, ваших кастомных и тд) в памяти. Соглашение о вызовах, наверное, здесь центровую роль играет. В общих словах, это какие операции нужно делать, чтобы выполнить функцию. Компьютер на самом деле не знает, что такое "выполнить функцию". Он знает лишь небольшой набор команд. Типа сложить, переместить, прыгнуть. То, как передаются аргументы для функции - через стек или через регистры, в каком порядке передаются аргументы, как очищать регистры, куда сохранять возвращаемое значение, и определяет calling convention. Но это что-то низкоуровневое, нам бы поближе к коду.
Сравним с API. Если API говорит, что вот есть такой-то набор функций и вы можете их использовать. То ABI говорит, как вы должны этими функциями пользоваться. Ну не вы, а скомпилированный код. Можно представить себе, что все детали того, что нужно сделать процессору, чтобы выполнить ваш код - это и есть ABI. То есть, как API, только на уровень ниже.
Что может изменить ABI? Очень много вещей. Именно поэтому имплементацию выносят в отдельный класс. Всего одна перестановка полей класса местами ломает низкоуровневое представление о том, как работать с вашим кодом. Потому что для доступа к определенному полю нужен определенный сдвиг от начала данных объекта. При перестановке эти сдвиги меняются и использование вашего кода без перекомпиляции будет вести к неправильной работе приложения.
Приведу некоторые изменения в коде, которые могут аффектить ABI.
👉🏿 Добавление, удаление и изменение порядка полей класса.
👉🏿 Изменение иерархии классов. Данные всех базовых классов лежат в определенном порядке, изменение иерархии влечет изменения в том, как данные объекта располагаются в памяти.
👉🏿 Изменение шаблонных аргументов в шаблонных классах. Это влияет на то, какое mangled имя будет у класса, и соответсвенно, то как к нему обращаться.
👉🏿 Объявление функции как inline. Компилятор может встроить такую функцию и ее имени просто больше не будет в списке доступных функций.
👉🏿 Изменение сигнатуры функций, включая cv-квалификаторы. Тоже по причине манглинга.
👉🏿 Добавление первого виртуального метода. Обычно внутри объекта появляется vptr, это ведет к изменению расположения объекта в памяти.
👉🏿 Изменение порядка объявления виртуальных методов. В таблице виртуальных функций они располагаются по порядку и вызываются по порядку. Изменив порядок можно вызвать не тот метод.
👉🏿 Изменение набора приватных методов. Ну а здесь-то што?! Клиент же их даже вызвать не может? Дело в том, что приватные методы участвуют в разрешении перегрузок, поэтому клиентский код в каком-то смысле имеет к ним доступ и знает об этом наборе методов. Его изменение в коде не перезаписывает знание клиента о нем, поэтому низя так делать.
👉🏿 И еще куча приколюх с наследованием.
Деталей очень много и списочек там реально очень большой. Я привел только самую верхушку, которую все понимают.
И вот при стандартном подходе с header/implementation любое изменение из этого списка влечет за собой перекомпиляцию всего кода, использующего ваш класс. А это как бы пипец. Почти любая реальная промышленная плюсовая задача требует таких изменений.
При использовании pimpl мы избегаем такого исхода. Указатель - он и в Африке указатель. На заданной платформе имеет один и тот же размер. И пока вы не делаете этих "опасных" изменений в публичном классе, его структура никак не изменяется. А обычно таких изменений не делают, потому что там оставляют только базовый API, который очень стабилен.
Вот такие пироги. Надеюсь, этот пост прояснил некоторые вопросы, которые могли вчера у вас возникнуть.
Stay compatible. Stay cool.
#design #hardcore #cppcore
{kind=link}
Что не нарушает ABI класса?
В комментах к предыдущему посту @MayerArtur удачно ванганул тему поста, который я писал в момент публикации его коммента. Поэтому этот пост обязан был выйти сегодня 😁. Вчера мы поговорили о том, что делать нельзя, если мы хотим сохранить стабильный ABI. Сегодня коротко пройдемся по тому, что делать можно. Завершим, так сказать, тему с ABI, чтобы картинка полная у вас была. Тут будет все в перемешку: и для хедеров, и для файлов реализации. Поехали:
✅ Изменять реализацию метода. Довольно очевидно. Если не трогать сигнатуру, то внутри можно хоть хороводы водить с гусями, ничего для внешнего наблюдателя не изменится.
✅ Добавлять новые публичные невиртуальные методы. Это новая функциональность, которая никак не мешает находить и пользоваться старой.
✅ Добавлять новые конструкторы. Same thing. Ничто не помешает создать объект старым способом.
✅ Добавлять новые енамы в класс.
✅ Добавлять новые поля в существующие енамы. Сишные енамы - это всего лишь красивенькие цифры, памяти они не занимают и компилятор их встраивает в код в виде обычных чисел.
✅ Добавление новых статических полей и изменение их порядка. Дело в том, что статические поля аллоцируются в области глобальных данных и никак не влияют на репрезентацию объекта в памяти.
✅ Добавлять новые классы и функции в файл. Obviously.
✅ Изменять параметр по умолчанию. Это тоже ничего не меняет, можно пользоваться как и прежде, но перекомпиляция нужна, чтобы новый параметр встал на место старого.
🥴 Чет есть какая-то инфа по поводу того, что удаление приватных невиртуальных методов может не сломать ABI, если они не вызываются и никогда не вызывались никакими инлайн мембер-функциями. Но учитывая, что в стандарте написано, что любые изменения в приватных полях и методах ведут к перекомпиляции, а также, что компилятор может встраивать методы без вашего на то разрешения, я бы это не брал в расчет.
Как-то так. Не густо. Но и не пусто.
На этом, думаю, тему завершаем на какое-то время разговор про бинарный интерфейс. Верхнеуровнево затронули самые важные моменты. Возможно в будущем будем возвращаться к отдельным деталям и прорабатывать их.
Stay compatible. Stay cool.
#design #hardcore #cppcore
В комментах к предыдущему посту @MayerArtur удачно ванганул тему поста, который я писал в момент публикации его коммента. Поэтому этот пост обязан был выйти сегодня 😁. Вчера мы поговорили о том, что делать нельзя, если мы хотим сохранить стабильный ABI. Сегодня коротко пройдемся по тому, что делать можно. Завершим, так сказать, тему с ABI, чтобы картинка полная у вас была. Тут будет все в перемешку: и для хедеров, и для файлов реализации. Поехали:
✅ Изменять реализацию метода. Довольно очевидно. Если не трогать сигнатуру, то внутри можно хоть хороводы водить с гусями, ничего для внешнего наблюдателя не изменится.
✅ Добавлять новые публичные невиртуальные методы. Это новая функциональность, которая никак не мешает находить и пользоваться старой.
✅ Добавлять новые конструкторы. Same thing. Ничто не помешает создать объект старым способом.
✅ Добавлять новые енамы в класс.
✅ Добавлять новые поля в существующие енамы. Сишные енамы - это всего лишь красивенькие цифры, памяти они не занимают и компилятор их встраивает в код в виде обычных чисел.
✅ Добавление новых статических полей и изменение их порядка. Дело в том, что статические поля аллоцируются в области глобальных данных и никак не влияют на репрезентацию объекта в памяти.
✅ Добавлять новые классы и функции в файл. Obviously.
✅ Изменять параметр по умолчанию. Это тоже ничего не меняет, можно пользоваться как и прежде, но перекомпиляция нужна, чтобы новый параметр встал на место старого.
🥴 Чет есть какая-то инфа по поводу того, что удаление приватных невиртуальных методов может не сломать ABI, если они не вызываются и никогда не вызывались никакими инлайн мембер-функциями. Но учитывая, что в стандарте написано, что любые изменения в приватных полях и методах ведут к перекомпиляции, а также, что компилятор может встраивать методы без вашего на то разрешения, я бы это не брал в расчет.
Как-то так. Не густо. Но и не пусто.
На этом, думаю, тему завершаем на какое-то время разговор про бинарный интерфейс. Верхнеуровнево затронули самые важные моменты. Возможно в будущем будем возвращаться к отдельным деталям и прорабатывать их.
Stay compatible. Stay cool.
#design #hardcore #cppcore
{kind=link}
Inline функции
Самый оптимальный с точки зрения производительности код - это сплошной набор вычислительных инструкций от начала и до конца. Это может быть и быстро, но никто так не пишет код. Любую целостную функциональность пришлось бы заново писать самостоятельно или копировать. Это все увеличивает время разработки(которое иногда важнее времени выполнения кода) и количество ошибок на единицу объема кода. Это естественно всех не устраивало.
Но в любой программе отчетливо просматривается группировка команд по смыслу. То есть определенная группа команд отвечает за выполнение какого-то комплексного действия. Это можно представить в виде графа, где вершины - эти группы, а ребра - переходы между ними. И оказалось очень удобным ввести сущность, отражающую во эту общность набора строк. Такая сущность называется функцией. И чтобы организовывать код с учетом наличия функций, нужны правила, согласно которым их будут вызывать. Так появился стек вызовов, calling conventions и так далее.
Что здесь важно знать. Чтобы выполнить функцию нужно сделать довольно много дополнительных действий. Положить значение base pointer'а на стек, через него же или через регистры передать аргументы, прыгнуть по адресу функции, сохранить возвращаемое значение функции, восстановить base pointer и прыгнуть обратно в вызывающий код. Может что-то забыл, но не суть. Суть в том, что дополнительные действия - дополнительные временные затраты на выполнение. Опять такой trade-off между перфомансом и удобством.
Для человека может быть очень удобно определить функцию сложения двух чисел. Семантически это действительно отдельная операция, которую удобно вынести в отдельную функцию и всегда ей пользоваться. Но с точки зрения машинного кода, затраты на вызов функции вносят значительный вклад в вычисление нужного значения. А вообще-то нам бы хотелось и рыбку съесть и на..., то есть перфоманс не потерять. И такой способ существует!
Называется инлайнинг. Для не очень сложных функций компилятор может просто взять и вставить код из функции в вызывающий код. Таким образом мы получаем преимущества организации кода по функциям и не просаживаем производительность. И еще дополнительно компилятор может сделать и другие оптимизации, которые невозможны были бы при вызове функции.
Для этих целей когда-то давно было придумано ключевое слово inline. Оно служило индикатором оптимизатору, что функцию, помеченную этим словом, нужно встроить. Эх, были времена, когда слово программиста имело вес...
Сейчас компилятор настолько преисполнился в своем познании, что может любую функцию сам встроить по своему хотению. А еще может просто проигнорировать вашу пометку inline и не встраивать функцию. Да и вообще, сейчас все методы, которые определены в объявлении класса неявно помечены как inline. С учетом наплевательского отношения компилятора к нашим пожеланиям, кажется, что вообще бессмысленно использовать ключевое слово inline для оптимизации кода. Хотя у inline есть и другое полезное свойство, но об этом в другой раз.
Но помимо бенефитов встраивания кода, у него есть и недостатки.
Из очевидного - увеличение размера бинаря. Код функции можно переиспользовать, а код заинлайненной функции будет располагаться в каждом ее вызове. Больше инструкций - больший размер бинаря.
Из неочевидного - встраивание функций может оказывать повышенное давление на кэш процессора. Например, если функция слишком большая, чтобы поместиться в L1, она может выполниться медленнее, чем при обычном выполнении function call. Для вызова функции CPU может заранее подгрузить ее инструкции и адрес возврата и выполнить ее быстрее. Или например, большое количество одного и того же встроенного кода может увеличить вероятность кэш-промаха и замедлить пайплайн процессора.
Опций, контролирующих встраивание, в компиляторе довольно много. Если будет желание, накидайте лайков и расскажу о них подробнее. Но самый простой способ разрешить инлайнинг - включить оптимизации O1 или даже О2.
Stay optimized. Stay cool.
#compiler #optimization #cppcore #performance #hardcore #memory
Самый оптимальный с точки зрения производительности код - это сплошной набор вычислительных инструкций от начала и до конца. Это может быть и быстро, но никто так не пишет код. Любую целостную функциональность пришлось бы заново писать самостоятельно или копировать. Это все увеличивает время разработки(которое иногда важнее времени выполнения кода) и количество ошибок на единицу объема кода. Это естественно всех не устраивало.
Но в любой программе отчетливо просматривается группировка команд по смыслу. То есть определенная группа команд отвечает за выполнение какого-то комплексного действия. Это можно представить в виде графа, где вершины - эти группы, а ребра - переходы между ними. И оказалось очень удобным ввести сущность, отражающую во эту общность набора строк. Такая сущность называется функцией. И чтобы организовывать код с учетом наличия функций, нужны правила, согласно которым их будут вызывать. Так появился стек вызовов, calling conventions и так далее.
Что здесь важно знать. Чтобы выполнить функцию нужно сделать довольно много дополнительных действий. Положить значение base pointer'а на стек, через него же или через регистры передать аргументы, прыгнуть по адресу функции, сохранить возвращаемое значение функции, восстановить base pointer и прыгнуть обратно в вызывающий код. Может что-то забыл, но не суть. Суть в том, что дополнительные действия - дополнительные временные затраты на выполнение. Опять такой trade-off между перфомансом и удобством.
Для человека может быть очень удобно определить функцию сложения двух чисел. Семантически это действительно отдельная операция, которую удобно вынести в отдельную функцию и всегда ей пользоваться. Но с точки зрения машинного кода, затраты на вызов функции вносят значительный вклад в вычисление нужного значения. А вообще-то нам бы хотелось и рыбку съесть и на..., то есть перфоманс не потерять. И такой способ существует!
Называется инлайнинг. Для не очень сложных функций компилятор может просто взять и вставить код из функции в вызывающий код. Таким образом мы получаем преимущества организации кода по функциям и не просаживаем производительность. И еще дополнительно компилятор может сделать и другие оптимизации, которые невозможны были бы при вызове функции.
Для этих целей когда-то давно было придумано ключевое слово inline. Оно служило индикатором оптимизатору, что функцию, помеченную этим словом, нужно встроить. Эх, были времена, когда слово программиста имело вес...
Сейчас компилятор настолько преисполнился в своем познании, что может любую функцию сам встроить по своему хотению. А еще может просто проигнорировать вашу пометку inline и не встраивать функцию. Да и вообще, сейчас все методы, которые определены в объявлении класса неявно помечены как inline. С учетом наплевательского отношения компилятора к нашим пожеланиям, кажется, что вообще бессмысленно использовать ключевое слово inline для оптимизации кода. Хотя у inline есть и другое полезное свойство, но об этом в другой раз.
Но помимо бенефитов встраивания кода, у него есть и недостатки.
Из очевидного - увеличение размера бинаря. Код функции можно переиспользовать, а код заинлайненной функции будет располагаться в каждом ее вызове. Больше инструкций - больший размер бинаря.
Из неочевидного - встраивание функций может оказывать повышенное давление на кэш процессора. Например, если функция слишком большая, чтобы поместиться в L1, она может выполниться медленнее, чем при обычном выполнении function call. Для вызова функции CPU может заранее подгрузить ее инструкции и адрес возврата и выполнить ее быстрее. Или например, большое количество одного и того же встроенного кода может увеличить вероятность кэш-промаха и замедлить пайплайн процессора.
Опций, контролирующих встраивание, в компиляторе довольно много. Если будет желание, накидайте лайков и расскажу о них подробнее. Но самый простой способ разрешить инлайнинг - включить оптимизации O1 или даже О2.
Stay optimized. Stay cool.
#compiler #optimization #cppcore #performance #hardcore #memory
{kind=link}
Универсальные ссылки
Вообще говоря, вся эта серия постов началась с просьбы нашего подписчика Сергея Нефедова объяснить зачем нужны универсальные ссылки. Дождались! 🤩
В предыдущей статье я сделал акцент:
Тип rvalue reference задаётся с помощью && перед именем класса.
ОДНО БОЛЬШОЕ НО! Вместо имени класса может быть установлен параметр-тип шаблона:
Ожидается, что из него будет выведен тип
В своё время Scott Meyers, придумал такой термин как универсальные ссылки, чтобы объяснить некоторые тонкости языка. Рассмотрим на примере вышеупомянутой
Оба вызова функции
Универсальная ссылка (т.н. universal reference) — это переменная или параметр, которая имеет тип T&& для выведенного типа T. Из неё будет выведен тип rvalue reference, либо lvalue reference. Это так же касается auto переменных, т.к. их тип тоже выводится.
Расставляем точки над i вместе со Scott Meyers:
В соответствии с этим маленьким нюансом поведение может меняться внутри функции
Я немного изменил предыдущий пример: https://compiler-explorer.com/z/EzddYhjdv. В зависимости от выведенного типа, строка будет либо скопирована, либо перемещена. Соответственно, в области видимости функции
Причем, это не работает, если
Пример: https://compiler-explorer.com/z/We4qzG5xG
Получается, что в универсальные ссылки заложен дуализм поведения. Зачем же так было сделано? А за тем, что существуют
Как мы видим, разные аргументы вызова
Кстати, если не знать и не пытаться в эти тонкости, то можно вполне спокойно использовать стандартные структуры. Если говорить с натяжкой, то можно, конечно, сказать, что такая универсальность может снижать порог вхождения в C++. Не знаешь — пишешь просто рабочий код, а знаешь — пишешь ещё и эффективный.
Другое дело, непонятно, почему нельзя было для универсальных ссылок сделать отдельный синтаксис? Например, добавить
Я думаю, что нам еще нужны посты на разбор этой темы, чтобы это в голове уложилось. А пока будем развивать тему в сторону move семантики. Не забываем об исключениях в перемещающем конструкторе, а так же про оптимизации RVO/NRVO.
#cppcore #memory #algorithm #hardcore
Вообще говоря, вся эта серия постов началась с просьбы нашего подписчика Сергея Нефедова объяснить зачем нужны универсальные ссылки. Дождались! 🤩
В предыдущей статье я сделал акцент:
Тип rvalue reference задаётся с помощью && перед именем класса.
ОДНО БОЛЬШОЕ НО! Вместо имени класса может быть установлен параметр-тип шаблона:
template<typename T>
void foo(T &&message)
{
...
}
Ожидается, что из него будет выведен тип
rvalue reference, но это не всегда так. Такие ссылки позволяют с одной стороны определить поведения для работы с xvalue, а с другой, неожиданно, для lvalue.В своё время Scott Meyers, придумал такой термин как универсальные ссылки, чтобы объяснить некоторые тонкости языка. Рассмотрим на примере вышеупомянутой
foo:std::string str = "blah blah blah";
// Передает lvalue
foo(str);
// Передает xvalue (rvalue reference)
foo(std::move(str));
Оба вызова функции
foo будут корректны, если не брать во внимание реализацию foo. Живой примерУниверсальная ссылка (т.н. universal reference) — это переменная или параметр, которая имеет тип T&& для выведенного типа T. Из неё будет выведен тип rvalue reference, либо lvalue reference. Это так же касается auto переменных, т.к. их тип тоже выводится.
Расставляем точки над i вместе со Scott Meyers:
Widget &&var1 = someWidget;
// ~~^~~
// rvalue reference
auto &&var2 = var1;
// ~~^~~
// universal reference
template<typename T>
void f(std::vector<T> &¶m);
// ~~^~~
// rvalue reference
template<typename T>
void f(T &¶m);
// ~~^~~
// universal reference
В соответствии с этим маленьким нюансом поведение может меняться внутри функции
foo. Банально, можно накодить тормозящее копирование вместо производительной передачи ресурса.Я немного изменил предыдущий пример: https://compiler-explorer.com/z/EzddYhjdv. В зависимости от выведенного типа, строка будет либо скопирована, либо перемещена. Соответственно, в области видимости функции
main объект либо выводит текст, либо нет (т.к. ресурс был передан другому объекту внутри foo).Причем, это не работает, если
T — параметр-тип шаблонного класса:template<class T>
class mycontainer
{
public:
void push_back(T &&other) { ... }
~~~^~~~
rvalue reference
...
};
Пример: https://compiler-explorer.com/z/We4qzG5xG
Получается, что в универсальные ссылки заложен дуализм поведения. Зачем же так было сделано? А за тем, что существуют
template parameter pack:template<class... Ts>
void foo(Ts... args)
{
bar(args...);
}
foo(std::move(string), value);
~~~~^~~~ ~~^~~~
xvalue lvalue
Как мы видим, разные аргументы вызова
foo могут относиться к разным категориям выражений.Кстати, если не знать и не пытаться в эти тонкости, то можно вполне спокойно использовать стандартные структуры. Если говорить с натяжкой, то можно, конечно, сказать, что такая универсальность может снижать порог вхождения в C++. Не знаешь — пишешь просто рабочий код, а знаешь — пишешь ещё и эффективный.
Другое дело, непонятно, почему нельзя было для универсальных ссылок сделать отдельный синтаксис? Например, добавить
T &&&. Т.к. сейчас это рушит всю концептуальную целостность системы типов. Если это планировалось как гибкий механизм, то он граничит с полной дезориентацией разработчиков 😊Я думаю, что нам еще нужны посты на разбор этой темы, чтобы это в голове уложилось. А пока будем развивать тему в сторону move семантики. Не забываем об исключениях в перемещающем конструкторе, а так же про оптимизации RVO/NRVO.
#cppcore #memory #algorithm #hardcore
{kind=link}