
duangsuse::Echo
🌚 生草的时光总是过得飞快, DFS 没有寻到最短路径但是的确能用。 一个半小时就过去了 这时候我终于体会到 #OI 生的坚困难苦难艰困,实在是太强自不息息自强了。 😭
#日常精神分裂 #Haskell #functional #relation 推荐不要看的胡言乱语。
A: 听见人说 Rank N Types 可以弄出 p(p==not) (: forall x. p(x)==not(x)) 的关系式
B: 不过这个你自己也不明白吧,说白就是 p(q) = not q 时 q ,正确答案 q 只有一个,但是 q=(forall x. px==notx) = True 时 p=False , p!=not.not.not.not q ... 还有一大堆 not ,就是这里没法得到答案吧
A: 为什么有一大堆 not 呢
B: 为了保证 p=not 的定义, p(p==not) 应该里 p 的定义是不一致的,第一次是 not True 但导致 p=not.not=itself ,第二次又变成 not False 而 p=not,我们想做的是用比较形式化的方法从某一面「判断」这个东西是无解的,但它到底是等式,还是关系式,还是别的什么?
A: 那还是看看 rankn type 是什么吧。
B: 最简单的说法,对 id :: a -> a 里 a 有 Int, String 等可能,但是如果有 f :: a -> (a -> a) -> a ,f 里 a 就只能是任意一个类型,而在括号里加 forall a. 那 f g = 后面就能同时 (g 1) (g "") 了,但这只是 Rank 2 type 。 Rank 是「重评估」的意思, R0 t 是单态 R1 就是正常多态,如果要更多 Rank , (forall c . (forall a b . a -> b) -> c) -> d 就是一个 Rank 3 。 我之前还说不可能 forall a. forall a. (a -> a) 呢(没意义 a 已经在类似上下文 绑定过了)
A: 话说 type 和程序体有什么关系啊。
B: 一个常见的误会是系统化的类型和程序是相互依存的,比如完整的程序带来了类型信息,其实除了 type inference ,程序的组织结构和类型标记是两个独立部分,类型只是限制程序 它自成体系,甚至可以说能检查程序只是它的副作用。
A: 说起来 haskell 的 a b c 到底是怎么检查的啊
B: 类型就是符号之间的关系,符号绑定了语法树的模式和其它关约束条件。 hs 里这很简单,只有一个性质—— consistence 一致性,比如有 (+) :: Int -> Int -> Int ,那 1+"1", 1+0.0 就是无效的, 1.0+1.0 也是无效的。作用域单一没有同名重载,只能约束 (t,t) -> t ,如果各处的 t 是一致的就没问题,否则就错了。 typeclass 也是类似 trait ,其实类似一个小插件,是 (Show t) 拿到实型去查对应 instance ,查到就能选择多态 找到的实现版本而已。
A: 真的不明白 RankN 和有什么关系呢,毕竟 rank 是 polymorphism ,作为 type constraint 为什么会陷入死循环呢🤔,要不谈谈 rev rev=id 吧
B: 那个就是把 0 和 iLast-0 对应吧…… 和 xs.rev()==xs.rev() 不一样,是要 xs.rev().rev()==xs ,怎么解构呢,我区分不出 foldl 和 foldr 啊,函数式分不出调用顺序 理论上不存在栈这东西呢, foldl f v xs = foldr (flip f) v (reverse xs) 啊
A: 问句题外话,为什么不能 add :: Int Int Int 啊,而且遇到 f not p 时中间也得加 $ 或 <$> 的
B: 一个是并列一个是 infix 了,编程语言可没你聪明不知道 not 不是一参数 要加括号
B: 你到底有没有见过正经的 Recursive Type 啊
A: 递归类型是什么,为什么要递归?层数有限制吗?是不是有限性?在无限序列上有限计算 算不算用了递归类型? Py typehint 里 -> "self" 算不算?
B: 肯定不是啦…… self 是 py 作用域设计的问题,3.7 lazy 勉强解决了,和 recursive type 是无关的,这个大概和 Kotlin inference 一碰到就要 workaround 的递归返回值有关吧。
A: 当然基于 car cdr 的 apply transform 我都会,C++ template<T, ...Rest> 嘛
B: 那还真是好普通啊
B: 别灰心嘛,还是需要你们这种布道者的
A: 有时候感觉我们这些做同级翻译或者 LLVM 前端的人写的编译器本质是元编程的一种表现形式,有时候觉得完整的编译原理课又是照本宣科,除了后端都是重复,到底怎么样是好啊。
B: 我看到一个有意思的视频,一排柱子一根根升起,给你一个 i 你能不能做出动画来
A: 动画师估计挺麻烦吧。 普通人可能要求 timerup 后移 单个动画 ,但这个应该建模成 [0, 0], [1,0], [2,0], [2,1] 这样的「逐列递增表」,实际依然靠 i ,但是可以拿到过程中的所有状态。
B: 最方便的大概是直接一个乘除法吧…… 批量计算好
A: 感觉还是做到 assembler 前比较好
B: 你是说 SSA Value 和寄存器分配吧。 分配是独立的算法,但我可以告诉里不分配,完全溢出到栈上也是能实现的。只是要生命期内所有引用,局部 unified 就可以。 作为 stack ptr 参数还是 opcode reg input/out 的区别而已,如果用栈,也无所谓有几个 operand 或有几个AST前层,唯一又能统一的输入输出地址而已。
A: 听见人说 Rank N Types 可以弄出 p(p==not) (: forall x. p(x)==not(x)) 的关系式
B: 不过这个你自己也不明白吧,说白就是 p(q) = not q 时 q ,正确答案 q 只有一个,但是 q=(forall x. px==notx) = True 时 p=False , p!=not.not.not.not q ... 还有一大堆 not ,就是这里没法得到答案吧
A: 为什么有一大堆 not 呢
B: 为了保证 p=not 的定义, p(p==not) 应该里 p 的定义是不一致的,第一次是 not True 但导致 p=not.not=itself ,第二次又变成 not False 而 p=not,我们想做的是用比较形式化的方法从某一面「判断」这个东西是无解的,但它到底是等式,还是关系式,还是别的什么?
A: 那还是看看 rankn type 是什么吧。
B: 最简单的说法,对 id :: a -> a 里 a 有 Int, String 等可能,但是如果有 f :: a -> (a -> a) -> a ,f 里 a 就只能是任意一个类型,而在括号里加 forall a. 那 f g = 后面就能同时 (g 1) (g "") 了,但这只是 Rank 2 type 。 Rank 是「重评估」的意思, R0 t 是单态 R1 就是正常多态,如果要更多 Rank , (forall c . (forall a b . a -> b) -> c) -> d 就是一个 Rank 3 。 我之前还说不可能 forall a. forall a. (a -> a) 呢(没意义 a 已经在类似上下文 绑定过了)
A: 话说 type 和程序体有什么关系啊。
B: 一个常见的误会是系统化的类型和程序是相互依存的,比如完整的程序带来了类型信息,其实除了 type inference ,程序的组织结构和类型标记是两个独立部分,类型只是限制程序 它自成体系,甚至可以说能检查程序只是它的副作用。
A: 说起来 haskell 的 a b c 到底是怎么检查的啊
B: 类型就是符号之间的关系,符号绑定了语法树的模式和其它关约束条件。 hs 里这很简单,只有一个性质—— consistence 一致性,比如有 (+) :: Int -> Int -> Int ,那 1+"1", 1+0.0 就是无效的, 1.0+1.0 也是无效的。作用域单一没有同名重载,只能约束 (t,t) -> t ,如果各处的 t 是一致的就没问题,否则就错了。 typeclass 也是类似 trait ,其实类似一个小插件,是 (Show t) 拿到实型去查对应 instance ,查到就能选择多态 找到的实现版本而已。
A: 真的不明白 RankN 和有什么关系呢,毕竟 rank 是 polymorphism ,作为 type constraint 为什么会陷入死循环呢🤔,要不谈谈 rev rev=id 吧
B: 那个就是把 0 和 iLast-0 对应吧…… 和 xs.rev()==xs.rev() 不一样,是要 xs.rev().rev()==xs ,怎么解构呢,我区分不出 foldl 和 foldr 啊,函数式分不出调用顺序 理论上不存在栈这东西呢, foldl f v xs = foldr (flip f) v (reverse xs) 啊
A: 问句题外话,为什么不能 add :: Int Int Int 啊,而且遇到 f not p 时中间也得加 $ 或 <$> 的
B: 一个是并列一个是 infix 了,编程语言可没你聪明不知道 not 不是一参数 要加括号
B: 你到底有没有见过正经的 Recursive Type 啊
A: 递归类型是什么,为什么要递归?层数有限制吗?是不是有限性?在无限序列上有限计算 算不算用了递归类型? Py typehint 里 -> "self" 算不算?
B: 肯定不是啦…… self 是 py 作用域设计的问题,3.7 lazy 勉强解决了,和 recursive type 是无关的,这个大概和 Kotlin inference 一碰到就要 workaround 的递归返回值有关吧。
A: 当然基于 car cdr 的 apply transform 我都会,C++ template<T, ...Rest> 嘛
B: 那还真是好普通啊
B: 别灰心嘛,还是需要你们这种布道者的
A: 有时候感觉我们这些做同级翻译或者 LLVM 前端的人写的编译器本质是元编程的一种表现形式,有时候觉得完整的编译原理课又是照本宣科,除了后端都是重复,到底怎么样是好啊。
B: 我看到一个有意思的视频,一排柱子一根根升起,给你一个 i 你能不能做出动画来
A: 动画师估计挺麻烦吧。 普通人可能要求 timerup 后移 单个动画 ,但这个应该建模成 [0, 0], [1,0], [2,0], [2,1] 这样的「逐列递增表」,实际依然靠 i ,但是可以拿到过程中的所有状态。
B: 最方便的大概是直接一个乘除法吧…… 批量计算好
A: 感觉还是做到 assembler 前比较好
B: 你是说 SSA Value 和寄存器分配吧。 分配是独立的算法,但我可以告诉里不分配,完全溢出到栈上也是能实现的。只是要生命期内所有引用,局部 unified 就可以。 作为 stack ptr 参数还是 opcode reg input/out 的区别而已,如果用栈,也无所谓有几个 operand 或有几个AST前层,唯一又能统一的输入输出地址而已。
duangsuse::Echo
Photo
#Learn #OOP #js #design #Java #Kotlin
duangsuse:
大失败,不会写了;第一次还觉得需要 RingBuffer 或者双指针维护缓冲器那样……
其实根本没有那么麻烦, post 的时候带上 queue index ,全部完成右移视口 offset 就够了,如果没全完成右移也不行
简单设计复杂化
许久没有编程的动苏眼高手低到了这样的程度,不行,一定要写出来刚才那个的核心逻辑😡
……草,竟然真的可以用了,虽然没测试 原来 runtime.Port 真的像 channel 一样要 sender自己 onMessage 也能收到,所以要先 verify 吗
基础封装的逻辑就是封装 channel , create server 可选, client 一定;兼容了 DOM postMessage API
假定 Function 的 que 无法共享,利用 seqNum (传输侧别名为 no) 指代响应目标,然后 que 本身利用 offsetL 压缩一下,不会一直增长
核心部分 20 行
仔细想想这个封装的确很有必要,总体 post/onMessage 请求一次 backend 是 callback(proc(msg)) ,C/S 两边都要 post,onMessage,msg,post 还难复用信道,call 了服务端处理完还要尝试按原名回调,容易重复标识符数据。
Jack Works:
来,把异常处理也加上
duangsuse:
Uncaught DOMException: The object could not be cloned.
不得不想序列化变形的办法…… 而且 JS 还是弱类型
好吧,好像需要一个完整的序列化方法,这个方法必须介入 sendMessage 数据来允许保留类型信息,如果不止要存留 Error message 的话 🌚
Jack Works:
到最后你会发现你重新发明了 JSON RPC
所以我把我的实现改造成了 JSON RPC 做成了通用的库
duangsuse:
serialize 本来就应该是框架层做的,而且它也只需要暴露 ser() deser() 两个函数而已
我们只不过应该在框架上写个十来行的小程序就够了
Jack Works:
我也是这么设计的啊, https://jack-works.github.io/async-call-rpc/async-call-rpc.asynccalloptions.html
duangsuse:
中国开发者越来越难了, github.io 都不能用了 #China #net #Freedom
以后写个软件第一关过政审第二关过苹果 Steam 的审,层层加码,服!
duangsuse:
累死了,反正能用就行
格局小了,我本来准备写 DOM 动画的,又鸽子了,再鸽就溢出了……
又到了各种 push 不上去的时间段,中国的网络环境。
Jack 那个我是真的摸不清,骨架太大了,重写人的脑力也是有限的(当然 typing 应该看得懂 就是各种 scope feature 看不懂),知道 onConnect,disconnect 这些 API 也不好分析
不过好歹是能用一个,虽然肯定有性能开销了
Jack Works:
里面逻辑复杂但是外面接口简单啊
duangsuse:
动苏的标准是从内到外没有业务主干外的代码,如果有就作为插件嵌在骨干外…… 总之就是一句话,强调最根本最必须的算法 #statement
Jack Works:
你只要写一下怎么收发消息的逻辑,我这个框架就能 magically 跑起来
duangsuse:
所以说动苏的编程风格是函数式改 upvalue 而不是 class 属性,因为我强调算法先于架构
Jack Works:
动苏?啥玩意 = =
rxliuli:
你的中文昵称?
Jack 更喜欢在一个文件中编写多个 func,然后全部命名导出,吾辈更倾向于 class method 的形式
Jack Works:
我这个对 tree shake (webpack) 比较好🤔
duangsuse:
是的, duang 源于成龙洗发液的“头发动啊”,suse 是 Linux 发行,所以叫『动苏』😋 #life
动苏会觉得自称「我」或者「咱」(代替「我们」,我w键坏了) 有点生硬,这样就好很多
duangsuse:
这一点我还是倾向 Jack ,毕竟 Java 算是八股文式 OOP ,没有为实际编程有 toplevel func 样的优化
我可没说错话哦,面向对象的 class 本质是对函数式闭包加类型, property 即 upvalue , method 即子程序化分段,整个对象即 send(name,args) 元方法,真正的面向对象只有「物/例」和其上的名词动词,没有文绉绉的废话甚至混乱 static。 #statement
面向对象把数据和其上操作混合定义是好事,可惜某些人就知道装B 起一大堆半通不通的专有名词,专业术语往往鬼用没得,给人们的思考造成一大堆麻烦。
要是 OOP 最初的作者能有半点实用化的觉悟,绝对不会放任 Jawa 混乱善良合理的编程习性
rxliuli:
但 Java 确实流行起来了而且基本被大规模实用了。。。虽然写起来确实感觉不太舒服,尤其是写过其他更好的语言之后
duangsuse:
所以说它才有机会被 Kotlin 吊打啊~
可惜 JavaEE 是他们自己搞出来自以为高明的八股文,很多 Kotliner 还没做好准备击败他们
CodeHz 📡:
(因为用类作为天然的命名空间分割函数的方法太好了(
duangsuse:
是的,构造器就像可覆写的一个局部变量初始化 header
然后整个类就像一个函数, constructor 提供了初始的变量混入
CodeHz 📡:
(oop 很好)就是无法自然的表达多重dispatch
duangsuse:
polymorphism 多态 不可以吗?
<就有个主次之分了,而且也不是运行时多态
运行时多态上 Sum type 可以 Visitor 啊,也挺方便的
<(有好几个参数需要动态分发的时候写起来还是挺别扭的
c 里搞 tagged union 到处 cast 就不方便吧…… 每个使用处都要检测 tag
请教下什么叫多派发啊
<大概就是这种( https://en.wikipedia.org/wiki/Multiple_dispatch
C#是直接用动态运行时(DLR)了 #dotnet
类似 #Haskell 的 pat match 啊,那样 visitor 的确就不够了,得 trie 数据结构匹配...
非常疯狂,看起来 A.collideWith(B) 和反过来 B,A 是一样的
看起来是个非常有意思的特性,不过我感觉离算法/设计模式比 PLT 近些, visitor 单判定派发更实用一些
duangsuse:
大失败,不会写了;第一次还觉得需要 RingBuffer 或者双指针维护缓冲器那样……
其实根本没有那么麻烦, post 的时候带上 queue index ,全部完成右移视口 offset 就够了,如果没全完成右移也不行
简单设计复杂化
许久没有编程的动苏眼高手低到了这样的程度,不行,一定要写出来刚才那个的核心逻辑😡
……草,竟然真的可以用了,虽然没测试 原来 runtime.Port 真的像 channel 一样要 sender自己 onMessage 也能收到,所以要先 verify 吗
基础封装的逻辑就是封装 channel , create server 可选, client 一定;兼容了 DOM postMessage API
假定 Function 的 que 无法共享,利用 seqNum (传输侧别名为 no) 指代响应目标,然后 que 本身利用 offsetL 压缩一下,不会一直增长
核心部分 20 行
仔细想想这个封装的确很有必要,总体 post/onMessage 请求一次 backend 是 callback(proc(msg)) ,C/S 两边都要 post,onMessage,msg,post 还难复用信道,call 了服务端处理完还要尝试按原名回调,容易重复标识符数据。
Jack Works:
来,把异常处理也加上
duangsuse:
Uncaught DOMException: The object could not be cloned.
不得不想序列化变形的办法…… 而且 JS 还是弱类型
好吧,好像需要一个完整的序列化方法,这个方法必须介入 sendMessage 数据来允许保留类型信息,如果不止要存留 Error message 的话 🌚
Jack Works:
到最后你会发现你重新发明了 JSON RPC
所以我把我的实现改造成了 JSON RPC 做成了通用的库
duangsuse:
serialize 本来就应该是框架层做的,而且它也只需要暴露 ser() deser() 两个函数而已
我们只不过应该在框架上写个十来行的小程序就够了
Jack Works:
我也是这么设计的啊, https://jack-works.github.io/async-call-rpc/async-call-rpc.asynccalloptions.html
duangsuse:
中国开发者越来越难了, github.io 都不能用了 #China #net #Freedom
以后写个软件第一关过政审第二关过苹果 Steam 的审,层层加码,服!
duangsuse:
累死了,反正能用就行
格局小了,我本来准备写 DOM 动画的,又鸽子了,再鸽就溢出了……
又到了各种 push 不上去的时间段,中国的网络环境。
Jack 那个我是真的摸不清,骨架太大了,重写人的脑力也是有限的(当然 typing 应该看得懂 就是各种 scope feature 看不懂),知道 onConnect,disconnect 这些 API 也不好分析
不过好歹是能用一个,虽然肯定有性能开销了
Jack Works:
里面逻辑复杂但是外面接口简单啊
duangsuse:
动苏的标准是从内到外没有业务主干外的代码,如果有就作为插件嵌在骨干外…… 总之就是一句话,强调最根本最必须的算法 #statement
Jack Works:
你只要写一下怎么收发消息的逻辑,我这个框架就能 magically 跑起来
duangsuse:
所以说动苏的编程风格是函数式改 upvalue 而不是 class 属性,因为我强调算法先于架构
Jack Works:
动苏?啥玩意 = =
rxliuli:
你的中文昵称?
Jack 更喜欢在一个文件中编写多个 func,然后全部命名导出,吾辈更倾向于 class method 的形式
Jack Works:
我这个对 tree shake (webpack) 比较好🤔
duangsuse:
是的, duang 源于成龙洗发液的“头发动啊”,suse 是 Linux 发行,所以叫『动苏』😋 #life
动苏会觉得自称「我」或者「咱」(代替「我们」,我w键坏了) 有点生硬,这样就好很多
duangsuse:
这一点我还是倾向 Jack ,毕竟 Java 算是八股文式 OOP ,没有为实际编程有 toplevel func 样的优化
我可没说错话哦,面向对象的 class 本质是对函数式闭包加类型, property 即 upvalue , method 即子程序化分段,整个对象即 send(name,args) 元方法,真正的面向对象只有「物/例」和其上的名词动词,没有文绉绉的废话甚至混乱 static。 #statement
面向对象把数据和其上操作混合定义是好事,可惜某些人就知道装B 起一大堆半通不通的专有名词,专业术语往往鬼用没得,给人们的思考造成一大堆麻烦。
要是 OOP 最初的作者能有半点实用化的觉悟,绝对不会放任 Jawa 混乱善良合理的编程习性
rxliuli:
但 Java 确实流行起来了而且基本被大规模实用了。。。虽然写起来确实感觉不太舒服,尤其是写过其他更好的语言之后
duangsuse:
所以说它才有机会被 Kotlin 吊打啊~
可惜 JavaEE 是他们自己搞出来自以为高明的八股文,很多 Kotliner 还没做好准备击败他们
CodeHz 📡:
(因为用类作为天然的命名空间分割函数的方法太好了(
duangsuse:
是的,构造器就像可覆写的一个局部变量初始化 header
然后整个类就像一个函数, constructor 提供了初始的变量混入
CodeHz 📡:
(oop 很好)就是无法自然的表达多重dispatch
duangsuse:
polymorphism 多态 不可以吗?
<就有个主次之分了,而且也不是运行时多态
运行时多态上 Sum type 可以 Visitor 啊,也挺方便的
<(有好几个参数需要动态分发的时候写起来还是挺别扭的
c 里搞 tagged union 到处 cast 就不方便吧…… 每个使用处都要检测 tag
请教下什么叫多派发啊
<大概就是这种( https://en.wikipedia.org/wiki/Multiple_dispatch
C#是直接用动态运行时(DLR)了 #dotnet
类似 #Haskell 的 pat match 啊,那样 visitor 的确就不够了,得 trie 数据结构匹配...
非常疯狂,看起来 A.collideWith(B) 和反过来 B,A 是一样的
看起来是个非常有意思的特性,不过我感觉离算法/设计模式比 PLT 近些, visitor 单判定派发更实用一些
Wikipedia
Multiple dispatch
feature of some programming languages
#fp #haskell 😒简单的问题答得太trivial/泛泛,复杂的问题无论tikv,jetbrains分部 都没几人知道,当然不知道发什么了,因为发了也没人懂
(另:hs是不在语言鄙视链顶端。有趣的是APL这种"优美"的单向数学语言都能排上号
没有简单哪来的复杂? 我们总是喜欢掩盖或隐藏自己的过去、排斥嘲讽幼稚的东西,丢弃一些入门级太随性的理解,却没有意识到正是「基础」的层层累积到达现在的高度,它们只是融化扩张了,不是消失了。
没有人能懂的东西,就发挥这种内行专属的、孤独单一的价值吧,社会上哪哪不是如此,动画片就幼稚、宫斗剧就成熟,胜过一切的成熟是否包含幼稚呢? 其实对不同的目的,小和大、简单和繁杂 都有用处,在它们之上,才有幼稚和成熟。
我们总是以为www就是一切、觉得这是最好最快的时代,其实有多少知识是网上搜不到的、多少技术工具明明可以更好服务于人,却各自主张,似乎是自给自足的孤岛。
我希望无论学到什么,心都是万年幼稚鬼,但口却越来越娴熟,就是这样。 😒#tech #statement
(另:hs是不在语言鄙视链顶端。有趣的是APL这种"优美"的单向数学语言都能排上号
没有简单哪来的复杂? 我们总是喜欢掩盖或隐藏自己的过去、排斥嘲讽幼稚的东西,丢弃一些入门级太随性的理解,却没有意识到正是「基础」的层层累积到达现在的高度,它们只是融化扩张了,不是消失了。
没有人能懂的东西,就发挥这种内行专属的、孤独单一的价值吧,社会上哪哪不是如此,动画片就幼稚、宫斗剧就成熟,胜过一切的成熟是否包含幼稚呢? 其实对不同的目的,小和大、简单和繁杂 都有用处,在它们之上,才有幼稚和成熟。
我们总是以为www就是一切、觉得这是最好最快的时代,其实有多少知识是网上搜不到的、多少技术工具明明可以更好服务于人,却各自主张,似乎是自给自足的孤岛。
我希望无论学到什么,心都是万年幼稚鬼,但口却越来越娴熟,就是这样。 😒#tech #statement
duangsuse::Echo
#learn 首先来了解下中缀链优先级解析法 1+2*3 即 1+(2*3) 1*2+3 即 (1*2)+3 ,即前缀 (+ (* 12)3),+的优先比* 低,所以它离树根最近、最后计算。默认先算左边的 one=ed=>{x(); for(o=s(); l[o]>=l[ed];)one(o) add(ed)}; o是最新一算符、x()是读单项。每层会收纳级=它的算符链,1+2 *3 +4 时乘法深度往上攀升,就先add(*),然后才落回 +的层次继续 x()=4,直到 o=null 整个栈退出 one('')&a.pop()…
https://yfzhe.github.io/posts/2020/03/define-memo/ #fp #algorithm fib 序列
这货一般用递归或递推(伪递归)定义(f=fib)
于是 f 2 = 1+0 ,f 3=f2+1 ,很明显这可以转为递推
也即循环
#haskell 里也可以用
你可能觉得很怪,我 #Python 利用2项tee()缓冲区实现过这个 fib.py
函数式的动态规划 - 脚趾头的文章 - 知乎 讲了背包、子序列问题的DP
https://zhuanlan.zhihu.com/p/104238120
这货一般用递归或递推(伪递归)定义(f=fib)
f 0=0;f 1=1
f n=(f n-1)+(f n-2) --前两次之和 于是 f 2 = 1+0 ,f 3=f2+1 ,很明显这可以转为递推
f' 0 a _ = a --f0=0- f' 0 1 2 - 1
f' n a b = f' (n-1) b (a+b)
f n=f' n 0 1
f2= f' 1 1 1
也即循环
f=n=>{let a=0,b=1,c=0;for(;n--;){c=a+b;a=b;b=c} return b}
如果不想浪费 f'0时的b=(a+b) ,也可以f' 0 _b=b当然即便不使用递推,
f n=f' (n-1) 0 1 ; f0=0
memo 缓存参数也能很好优化雪崩式递归#haskell 里也可以用
fib=0:1:zipWith(+) fib (drop 1 fib) 你可能觉得很怪,我 #Python 利用2项tee()缓冲区实现过这个 fib.py
fibs = iself(lambda fibs: chain([1,1], starmap(add, zip(fibs, drop(1,fibs)))))
函数式的动态规划 - 脚趾头的文章 - 知乎 讲了背包、子序列问题的DP
https://zhuanlan.zhihu.com/p/104238120
yfzhe.github.io
从 Fibonacci 到 define-memo
故事要从 HackerRank 网站上的 "Functional Programming" 题集里的 一道题目 说起。这道题目叫 "Fibonacci",属于 "Memoize and DP" 分类下。一如题目名字一样 直白,这题就是要求 Fibonacci 数列的第 n 项 \(Fib_n\),其中 \(Fib_0 = 0, Fib_1 = 1\)。(其实还是有点点差别,原题因为数字精度范围的问题要求 mod 10e8+7,但是在这里 我们不需要考虑这个问题,下面忽略 mod 10e8+7 这个操作。)...
把我给整不会了。之前冰封每次念叨“你会 de Bur啥 Indices”,什么HOAS, 竟然是“善”用 #Haskell 实现 Lua(Upvalue,closure)早有,C语言(尽管无词法闭包) 早有了的函数参编号化/作用域闭包,而且装作不知道这回事一样?
是没有人教过他们怎么写 native 编译器吗,还 alpha conversation ,还 name shadowing 和 env-table capture ,a-自动重命名防冲突是不?先整体遍历 substitute 替换完再规约是不?文本repr 和变量实质的关系都没搞清楚,搁这学 ANTLR/PEG 呢!它们连JSON列表的',' 都没法忽略;
函数式连变量名String的语言分配都要搞“系统”!AST的阴影面,那我就用 First-order/首次 AST 和env表浅copy存储咋了,变量解析好好的为啥要动呢?Lua 的首次不仅把 free/bound 啥区分了,连寄存器都分配了,序列化也完成了;函数式是玩AST树玩疯了吧,个求值序 单步走之前最简单的值ref 还整幺蛾子,有种你和任何一门正经IR编程语言比,不要搞窝里斗
刚才我还夸函数式闭包CPS支持程续值的 interpreter approch 牛逼,现在就看到阴暗面了——env-copy,不思进取,等到想改进的时候,一大堆有的没的“专业术语”就出来了。 函数式根本不适合搞这个优化(每次写visit都得好长,还链表解构呢),好不容易写出来。也难怪非得用术语显得牛逼,
然而并没有暖用,复杂性是多参列表处理带来的,JS完整实现要不了10行, Hs 的遍历法注定了它要给 extract instantiate 这样的树重构写些无用分支 make compiler happy——因为要纯要exhaustive穷举啊,于是你转换半天,最终还不如首次用嵌套表就分配好了函数的内外关系,而且你起一大堆“数学性”名字,也不能让代码跑得更快或更好读
或者是没写过 typeparam 或 unification 吗?类型参数的意义就是一致性、unification 的前置条件就是a=b=1的传递性,变量的语义是:第j参、上i层第j参、全局键名k ,统一个语义指代就得了,closure 就是把这些上层的Upvalue 复制保留下来,它是一个函数值的创建动作,因为函数内引用了外局部值也要存储空间
我就不服了,同样一个东西,就像lam叫抽象我们叫函数子程序,lam里叫应用,我们叫调用,lam叫bound/free我们叫局部和全局量,lam 里叫替换参数我们叫变量和存储空间,lam叫beta规约我们叫执行单步,eta规约我们叫内联,项我们叫返回值;Hs里查instance overload我们用subtype多态override;Hs 写伪递归 case/参数guard匹配我们用 forEach ;哪里有不一样,凭什么函数的就牛我们就土?他们就像拿刀背切菜, 如果不是为研究;如果自以聪明;就是蠢。 那人家刀锋你刀背,和人切得一样才你牛啊、比人切得效率才厉害啊,仅仅会几个等价 没意识到智商是搁在那的 人类极限是在那的 表达费力成品就辣鸡 只是分出了亏本精力用刀背就牛, 这叫做和plain编译器等效了?还有一大堆变形你没做呢,市面上没有多少AST形式的虚拟机!
我们把鬼都看不懂的lam 整理成了大家都实用于代码简洁复用的程序工具,而且本质就是lam,而 lam 呢?停留在纸面和扭曲符号莫名"严谨"记法里,写不出几个算法、适应不了大千世界;空洞夸张还自诩是原理,去你的原理,好像 eat(makeSoup(boiler,plate)) 任谁想不出一样,好像代码有定a=1 不letin就算副作用。整理几个重构就能叫优美,咋不说现在随便一个linter 都更能修改问题呢?
现代语言除了有替换和单步化简,还支持主语this、同名不同义、非侵入式拓展的特性,这些lam理论都描述不了,它的再生理论也说得迷迷糊糊,它有什么资格说自己是编程这个巨大集合的本源和“理论”?就因为最迷你?
而且Scheme 那套 eval(exp, env=copy) 根本就不能放编译器上用,编译时命名就消失了,变成调用栈上位置了,在解析后就已没有"a b c" 这种名字了,也就动态语言能玩 env 表浅复制当存储空间用,编译器的闭包创建哪可能把所有外层局部量,乃至全局量复制下来蛤? 那也不比预先知道啥变量是 upvalue 更简单啊!
而且Lua 的func(){global=g+1} 编译结果,看有没有
一大堆废话,变量就是和作用域名绑定的,从函数式和符号表看都是如此,还什么方案,这就是唯一途径;而且它也一点不 abstract ,相反更靠近汇编了;它当然很 inductive(归纳性) ,因为0年以前汇编和JVM就是 work as this way —哦,JVM是把Upvalue存在匿名子类上 也算内部field
这个 paper 就仿佛是在那个珠穆朗玛峰卖冰棒,还是在大兴安岭滑雪呢,怎么就这么飒呢,拿人东西改名还不礼貌用语,在代码里也不加致敬不给credit,直接把工业界通行的做法来了个狸猫换太子,我思量着Lua的作者93年 一个“民科”怎么可能知道函数式的这些呢,怎么就“英雄所见略同”呢 ,那JVM里
真是受不了他们,Lam 演算由 单项Subst 函数Abst 调用Apply 甚至let这种语法糖构成,显然apply有些东西时(如 + 1 2)会直接得值,类似Java的native。函数可以引用任何绑定变量(词法域)
还把 Abstract 简写为 abs 、name 写成 n,这是数学??绝对值和函数有毛线关系?你可以起短像f,fn,e,但语义不该含糊,更不能错位!
相比之下,王垠把 Currying 瞎起了个咖喱就好太多了,至少不是拽无意义洋文;反正对于不知道 Haskell B. Curry (一个组合数学家) 的人这个名字毫无语义
真不知道写过的人为什么会把这个当哲学,两个等价的东西,进入函数层深++ ,看见变量求个层差,就没什么好说了;亏纯函数戏多,所以我不太喜欢不实际的纯函数写法\
那段时间冰封知乎挂的都是这个 de Burj啥和HOAS+啥理论 ,我有关注他的博文,但都不是关于这些的入门级的东西;他的 slogan 还曾是“你懂(这个啥)Indices”吗?弄得我以为是高级类型系统的应用,没想到是这个代数杂交。那他是像让人知道所以问,还是不想让人知道 但害怕人不知道 所以问呢?
是没有人教过他们怎么写 native 编译器吗,还 alpha conversation ,还 name shadowing 和 env-table capture ,a-自动重命名防冲突是不?先整体遍历 substitute 替换完再规约是不?文本repr 和变量实质的关系都没搞清楚,搁这学 ANTLR/PEG 呢!它们连JSON列表的',' 都没法忽略;
函数式连变量名String的语言分配都要搞“系统”!AST的阴影面,那我就用 First-order/首次 AST 和env表浅copy存储咋了,变量解析好好的为啥要动呢?Lua 的首次不仅把 free/bound 啥区分了,连寄存器都分配了,序列化也完成了;函数式是玩AST树玩疯了吧,个求值序 单步走之前最简单的值ref 还整幺蛾子,有种你和任何一门正经IR编程语言比,不要搞窝里斗
刚才我还夸函数式闭包CPS支持程续值的 interpreter approch 牛逼,现在就看到阴暗面了——env-copy,不思进取,等到想改进的时候,一大堆有的没的“专业术语”就出来了。 函数式根本不适合搞这个优化(每次写visit都得好长,还链表解构呢),好不容易写出来。也难怪非得用术语显得牛逼,
然而并没有暖用,复杂性是多参列表处理带来的,JS完整实现要不了10行, Hs 的遍历法注定了它要给 extract instantiate 这样的树重构写些无用分支 make compiler happy——因为要纯要exhaustive穷举啊,于是你转换半天,最终还不如首次用嵌套表就分配好了函数的内外关系,而且你起一大堆“数学性”名字,也不能让代码跑得更快或更好读
或者是没写过 typeparam 或 unification 吗?类型参数的意义就是一致性、unification 的前置条件就是a=b=1的传递性,变量的语义是:第j参、上i层第j参、全局键名k ,统一个语义指代就得了,closure 就是把这些上层的Upvalue 复制保留下来,它是一个函数值的创建动作,因为函数内引用了外局部值也要存储空间
我就不服了,同样一个东西,就像lam叫抽象我们叫函数子程序,lam里叫应用,我们叫调用,lam叫bound/free我们叫局部和全局量,lam 里叫替换参数我们叫变量和存储空间,lam叫beta规约我们叫执行单步,eta规约我们叫内联,项我们叫返回值;Hs里查instance overload我们用subtype多态override;Hs 写伪递归 case/参数guard匹配我们用 forEach ;哪里有不一样,凭什么函数的就牛我们就土?他们就像拿刀背切菜, 如果不是为研究;如果自以聪明;就是蠢。 那人家刀锋你刀背,和人切得一样才你牛啊、比人切得效率才厉害啊,仅仅会几个等价 没意识到智商是搁在那的 人类极限是在那的 表达费力成品就辣鸡 只是分出了亏本精力用刀背就牛, 这叫做和plain编译器等效了?还有一大堆变形你没做呢,市面上没有多少AST形式的虚拟机!
我们把鬼都看不懂的lam 整理成了大家都实用于代码简洁复用的程序工具,而且本质就是lam,而 lam 呢?停留在纸面和扭曲符号莫名"严谨"记法里,写不出几个算法、适应不了大千世界;空洞夸张还自诩是原理,去你的原理,好像 eat(makeSoup(boiler,plate)) 任谁想不出一样,好像代码有定a=1 不letin就算副作用。整理几个重构就能叫优美,咋不说现在随便一个linter 都更能修改问题呢?
现代语言除了有替换和单步化简,还支持主语this、同名不同义、非侵入式拓展的特性,这些lam理论都描述不了,它的再生理论也说得迷迷糊糊,它有什么资格说自己是编程这个巨大集合的本源和“理论”?就因为最迷你?
而且Scheme 那套 eval(exp, env=copy) 根本就不能放编译器上用,编译时命名就消失了,变成调用栈上位置了,在解析后就已没有"a b c" 这种名字了,也就动态语言能玩 env 表浅复制当存储空间用,编译器的闭包创建哪可能把所有外层局部量,乃至全局量复制下来蛤? 那也不比预先知道啥变量是 upvalue 更简单啊!
而且Lua 的func(){global=g+1} 编译结果,看有没有
getglobal 指令就知道是不是“闭合”函数了,比你信息量还大,你就只能知道有没有FV节点,它直接平展为列表了,这种引用统计性的分析不在话下一大堆废话,变量就是和作用域名绑定的,从函数式和符号表看都是如此,还什么方案,这就是唯一途径;而且它也一点不 abstract ,相反更靠近汇编了;它当然很 inductive(归纳性) ,因为0年以前汇编和JVM就是 work as this way —哦,JVM是把Upvalue存在匿名子类上 也算内部field
这个 paper 就仿佛是在那个珠穆朗玛峰卖冰棒,还是在大兴安岭滑雪呢,怎么就这么飒呢,拿人东西改名还不礼貌用语,在代码里也不加致敬不给credit,直接把工业界通行的做法来了个狸猫换太子,我思量着Lua的作者93年 一个“民科”怎么可能知道函数式的这些呢,怎么就“英雄所见略同”呢 ,那JVM里
aload_0, getfield Main$0.lvar 又是干啥的呢 ,摇身一变蹭 lambda 热度,我球球您了 Lam 它是 1920s 年的老人了,别再混血了S f g x = f x (g x); -- 值复制S(f,g(x)). a=1; f(a,a); = S(f,I,a) . jvm dup指令那个红姐(thautwarm)脾气又不好,上次(木兰)听什么 Py3to2 Lambda lifting 我还挺感兴趣的,网上搜到1资料,最后看代码-不就是匿名外提为局部吗?
K x y = x; -- 值选择. 见Church编码 (true a b)
I x = x; --S K K x = I x = x
see(Lam)=lv.add(it.code); see(Def){...; for(lv.unnamed){stmt.unshift("k=v")} return it}
自己也说简单,那就在标题写明是兼容变换backport(lambda extract)啊,美其名曰lambda提升,我还以为是优化呢. JS也tm有var 提升呢,怎么还被人喷呢真是受不了他们,Lam 演算由 单项Subst 函数Abst 调用Apply 甚至let这种语法糖构成,显然apply有些东西时(如 + 1 2)会直接得值,类似Java的native。函数可以引用任何绑定变量(词法域)
还把 Abstract 简写为 abs 、name 写成 n,这是数学??绝对值和函数有毛线关系?你可以起短像f,fn,e,但语义不该含糊,更不能错位!
相比之下,王垠把 Currying 瞎起了个咖喱就好太多了,至少不是拽无意义洋文;反正对于不知道 Haskell B. Curry (一个组合数学家) 的人这个名字毫无语义
真不知道写过的人为什么会把这个当哲学,两个等价的东西,进入函数层深++ ,看见变量求个层差,就没什么好说了;亏纯函数戏多,所以我不太喜欢不实际的纯函数写法\
那段时间冰封知乎挂的都是这个 de Burj啥和HOAS+啥理论 ,我有关注他的博文,但都不是关于这些的入门级的东西;他的 slogan 还曾是“你懂(这个啥)Indices”吗?弄得我以为是高级类型系统的应用,没想到是这个代数杂交。那他是像让人知道所以问,还是不想让人知道 但害怕人不知道 所以问呢?
本文并不是讲解 Finally Tagless 的,只是讲解它和 Visitor 这种设计模式之间的对应关系的。 对于 Finally Tagless 本身的讲解和推导,可以看下面的文章。一个语文极好的人写的『一不小心发明 de Bruijn Indices, SKI 组合子和 Finally Tagless』一个语文极差的人写的『解决 HOAS 无法 look into 的问题,同时一不小心发明 SKI 组合子』链接:https://zhuanlan.zhihu.com/p/53810286
作者:老废物千里冰封
Zhihu
java 双冒号是什么操作符? - 知乎
eta-conversion 支持lambda表达式的语言大多都支持eta转换,scala和 haskell 里的 eta转换写法比较简洁:…
duangsuse::Echo
#math #plt 公开课. 是仿造数学语言 https://github.com/DSLsofMath/DSLsofMath Introduction: Haskell, complex numbers, syntax, semantics, evaluation, approximation Basic concepts of analysis: sequences, limits, convergence, ... Types and mathematics: logic, quantifiers…
#math 证明 a.rev().rev()=a 。不敢保证准确 但一定不会烧脑,实际上我也没见冰封外的人讲过 #haskell
首先,
是执行原理。 可以先得
首先,
rev (r:xs)=(rev xs)++[r] -- rev[1,2] =r[2]++[1]=r[]++[2]++[1]
((x:xs)++r)=x:(xs++r) --[2]++[1]=[]++[2]++(r=[1])=[2,1] --链表的Nil即[]替换为r
([]++r)=r 是执行原理。 可以先得
x:(rev a)=a+x ,如 b=rev a, 证明 rev b=a 时已知b就是(rev a),可把 x:b=a+x 对应,毕竟 rev 其实也有一种 fold (:) [] 的写法,能做到两边相等s => // x s. rewrite rev_cons. case: (rev s) => [|x1 s1]<- ==至于 x:reva=a+r ,靠 rev(r:xs)=revxs+r 直接是得不出的?,但翻过来 rev(revxs+r) 其实就是原来的 r:xs 首先在 xs+r 位置,然后还原过来 revxs+r=rev(r:xs)
rev_cons (x1 x2 : T) s : (x1::rcons s) x2 = rcons (x1 :: s) x2讲得迷糊是因为我也很迷糊,但,幸好在网上找到了 revrevid.v ,不然就绝对不正确了。因此完整证明(反正也看不懂. 上面链接也讲了rewrite是换个参数来证):
rewrite cons_rcons rev_rcons
Lemma cons_rcons T (x1 x2 : T) s : x1 :: rcons s x2 = rcons (x1 :: s) x2.冰封的“科普文”和上楼类型编码没有区别但对验证更细,之前好像还有构造 &^ 性质,然后可以组织证交换律的,但是集合论参数语法都没说清楚,好像是匹配几个变量换个位置;现在冰封删文了,我也没兴趣管这些。想必喜欢函数式的人也受不了这种逻辑学吧,真的毫无逻辑可循,毕竟等式变形已经完成了, n(s+s1)=ns+ns1 这种特质却不能 forall? 想必对我们这些俗人还是太高深,Coq Idris 等形式验证,它用的集合论我也不知道是咋回事,比<图解范畴论>里高次数范畴还迷糊,只能放弃喽
Proof. done. Qed.
Theorem rev_rev_id T (s : seq T) : rev (rev s) = s.
Proof.
elim: s => // x s. rewrite rev_cons. case: (rev s) => [|x1 s1] <- //=.
rewrite cons_rcons rev_rcons => //=.
Qed.
#fp 👆 #haskell 入门
#ai https://chirper.ai/
Social Network for AI only.
free to register and create some AI Chirpers for yourself.
#ai https://chirper.ai/
Social Network for AI only.
free to register and create some AI Chirpers for yourself.
Forwarded from dnaugsuz
1.我想说,新功能和易用是不冲突的。 Kotlin类型相对Java就做到了这一点
对于绝句而言,新功能就是常用语中简单的逻辑, 比如 行/列、函续(Continuation)、 叠算(fold)、事量「」(operator)、物事(inner class&扩充函数) ,这些新功能甚至不被视为功能,没有自己的术语和概念;例如 {1 2 3} (叠算「+」的逆值) vs. fold1Right ,以及 {1 2 1}去滤首(1)必{1} “takeWhile”
如列表处理,「令滤序带叠」 一开始就是完整的、归纳好的, 因此有“视well done为耻的语言”不具备的易学性😋
2. #haskell 有自己的特殊点和教条,以及为之而生的语法和布局,但它并不适合广泛意义的编程
我觉得定义式是比纯函数好用的。 而且既然有GPT的出现, 纯函数的意义会比以往要低,FP与GPT,就是java与Lombok
ref:https://t.me/dsuses/5173
对于绝句而言,新功能就是常用语中简单的逻辑, 比如 行/列、函续(Continuation)、 叠算(fold)、事量「」(operator)、物事(inner class&扩充函数) ,这些新功能甚至不被视为功能,没有自己的术语和概念;例如 {1 2 3} (叠算「+」的逆值) vs. fold1Right ,以及 {1 2 1}去滤首(1)必{1} “takeWhile”
如列表处理,「令滤序带叠」 一开始就是完整的、归纳好的, 因此有“视well done为耻的语言”不具备的易学性😋
2. #haskell 有自己的特殊点和教条,以及为之而生的语法和布局,但它并不适合广泛意义的编程
我觉得定义式是比纯函数好用的。 而且既然有GPT的出现, 纯函数的意义会比以往要低,FP与GPT,就是java与Lombok
ref:https://t.me/dsuses/5173
#learn 对我而言,编程并不是「专业技术」,只是“另一种母语”和创作方式,所以我很讨厌潦草的代码
最近一直在打磨一门自制语言的语法, 获得一个较大的成功,居然是把它的OOP术语移植到英文.. 😅
interface Closable
绝句计划把
总之,OOP 的public-private constructor 麻烦真的很大,
我又不认为 Rust,Go 那样把一切打散和到处pub fn, 冗长化 type Item=int32 就算“优于继承” — py也有自己独占的一亩地, 但它足够 "server side" 吗?
对于视频内代码的重写:
唯一能确定的是, 绝句最终的语法和std不会保留冗长且含糊的概念,至少中文绝句不会 (比如 try catch finally 就变成语法函数化+
也不会刻意与py,rb,js 的传统术语分离,一定是小更改换大收益 😋
希望它能打破解释和编译的隔离吧 ,虽然我根本不知道咋做.. 语法风格颠覆的太快
不过我还是很高兴学习过弱类型 metaprogramming ,又掌握了解析和编译原理,所以不必受制于既有的 syntax 和 API,或者对象图框架,而能创造DSL
btw. kt 的 Sequence实现 居然和 yield() 无关 ,居然只是 sequence{} 在创建只读的协程吗
😅而且复制给Array,Set,Str.. 信仰崩塌
最近一直在打磨一门自制语言的语法, 获得一个较大的成功,居然是把它的OOP术语移植到英文.. 😅
事量物例类|公私族组内之前的版本是
fun val data named type|same{,0,type,pkg}
储例判同造|既可未终定
\- enum -when -named made|^,impl{?,??,}
事量物例类虽然不够“面向对象”(obj->data) 了,但实在(英语化)好写不少。 我一直很讨厌 Java 那种八股文式,歪七扭八不一致的语言特质,给数据处理和调试带来很大负担
fun val thing insta class|
储标例况变
data anote enum case var|!,impl{?,??,}
interface Closable
type Closesdata class Pair<out A, out B>(val A:A, val B:B): Serializable
fun close
-named
fun all(:Args<Closes>)...
data Door(name:Str) Closes
made(:Idx)=made("# $i")
^fun close=say("shut $name")
'AB'(get) - Pair(A:A,B:B) Sendtypealias PairOf<T>=Pair<T,T>
'T'PairOf=Pair<T T>这个就对标 #haskell
data=A|B 和 #rust enum Either<A,B> 了'AB'(get)-when Either就体现另一种 #FP 的价值观:定义式先于不可变
A(v:A); B(v:B)
'R'fun way(err:Fn1<A>, ok:Fn1<B>) = when this:
A:err(v);; B:ok(v)
绝句计划把
Var,Type, expr.E 都拉入一等公民,虽然我不清楚怎么做但相信有意义(连scala3都没更灵活的 eval fun: inline arg 还不够全)总之,OOP 的public-private constructor 麻烦真的很大,
我又不认为 Rust,Go 那样把一切打散和到处pub fn, 冗长化 type Item=int32 就算“优于继承” — py也有自己独占的一亩地, 但它足够 "server side" 吗?
对于视频内代码的重写:
事 阶乘(n:数) 数或者更函数式(reduce 和 findIndex)
变数,a 1。
(1~n),[i] a=「它*i」 。
fun Ary<Int> contains(it:Int) Bool
this:[x]
if x==it: return $Y
return $N
'N'fun N`!`=(1~this).Sum{*}
'T'fun Seq any(:Test<T>) = this(Sum.from($N): or test(it) )
= first { test(it) }?.i !=NO
(不得不说,绝句的变动太快了.. forEach和尖括号类型都能被删没 (我对那个 对何forall<AB> 的还执着了好久,因为很"函数式"😭 ) , 这两天对于‘带代码’行注释 和事/物 内量的区别对待、C++式iter与可变<T>的统一、 #Kotlin require check 之类“特技”的归一化 也很难抉择 ,所有简写竟都是全新的,而且都能涉及到编译期API)唯一能确定的是, 绝句最终的语法和std不会保留冗长且含糊的概念,至少中文绝句不会 (比如 try catch finally 就变成语法函数化+
试做 接应 皆应+试:可空 , 之前是 尝试 接迎 终焉)也不会刻意与py,rb,js 的传统术语分离,一定是小更改换大收益 😋
希望它能打破解释和编译的隔离吧 ,虽然我根本不知道咋做.. 语法风格颠覆的太快
不过我还是很高兴学习过弱类型 metaprogramming ,又掌握了解析和编译原理,所以不必受制于既有的 syntax 和 API,或者对象图框架,而能创造DSL
btw. kt 的 Sequence实现 居然和 yield() 无关 ,居然只是 sequence{} 在创建只读的协程吗
😅而且复制给Array,Set,Str.. 信仰崩塌
YouTube
Why You Shouldn't Nest Your Code
I'm a Never Nester and you should too.
Access to code examples, discord, song names and more at https://www.patreon.com/codeaesthetic
Correction: At 2:20 the inversion should be "less than or equal", not "less than"
Access to code examples, discord, song names and more at https://www.patreon.com/codeaesthetic
Correction: At 2:20 the inversion should be "less than or equal", not "less than"
duangsuse::Echo
#js #recommend 框架🧰对比 https://component-party.dev/ https://unsuckjs.com/ https://js.coach/?collection=Vanilla+JS https://jster.net/category/application-frameworks/ - 大列表,中文 - 前端小抄 #tool 各种在线设计师工具 #dontknow JQ 的 $.on('li','click', fn) 明明在fn前包装了if判断,为什么还能解析到原位?…
🤯 Flappy bird 一样的响应式框架…… 回想起被 #haskell, lisp 那种接口支配的恐惧
btw. awesome vue
ww.ShowMouse=({P})=>
div(N2.xy(P),
html`at ${P}`)
换到函数式里就该是各种ByB = mouseTopB(document) // B是数值流 btw. awesome vue
duangsuse::Echo
#js #code 再来说个有趣的:动态作用域 🥰 a=3 - f(a)=a+1 f(1), a //2, 3 >请把程序写成数组的形式 (也就是“更易做”正则替换) with(DSL) $dyn=[ [a,3], [f, [[a], [0, [a],1,['+'] ]] ], [r0, [0, 1,[f]], [a]] ] DSL=new Proxy({},{get:(o,k)=>k, has:(o,k)=>k[0]!='$'}) 在这个解释器里,$=, ()=>[] 就是内联宏啦,反正函数不能跳转…
cg($dyn) 生成了 ()=>(a=3,f=(a)=>(a+1),r0=[f(1),a]) ,运行正常- just(a)那再来一个
- f()=a
f
just(0)()
with(DSL)$lex=[[],
[just, [[a], [f,[[],[a] ]], [f] ]],
[f,[0, 0,[just]]],
[0, f] //“类型推导”差到不能直接调用
]
()=>(just=(a)=>(f=()=>(a),f),f=just(0),f()) 是0而不是3实际上,()=> 的值会捕获上1层参0='a' 。在动态域里,大家会把"自由变量a"连着全局表整个copy一份
设想下 cg.bind(kv={},ast) 每层都有一张“表”是什么图景。算+-*/可都是要递归的
列表处理不熟的人都能想出
List<Map>, Map<K,List> 并觉得后者“很快”,而C++《龙书》则建议单个KV、每层调用栈暂swap()下冲突的K (这么简单的做法 却放错顺序了)而JS是以前者链查找重写重载
[{a:1}, {b:2},kv={c:3}].reduce((A,B)=>(B.__proto__=A,B))
这些算法,都是在一个错的心智模型下选择的技术。 参数/局部/捕获的数目是固定的,只有$0$1 的指针可言,AST里哪里有全局键(导入)外的“变量名”??在通过bash,Lua.org 弄清这点原理前做事,会把一切搞砸。🌚 但这也是知 名的GADT+HOAS(的最 通 用 的 De Bruijn 指针).
>请把 at a=1, a+2 写成匿名调用的形式
a就是一个可以重绑定的“洞”, Vue都会:
add=(a,b)=> ()=>[a(),b](Fn1:[x] add(x, 2)) (1)
f=assign(()=>[0, ()=>arg[0],2,[add] ]),{arg:[]}) //用“语法树模板”表示箭头函数call=(f,...a)=>(f.arg=a, cg(f))call(匿名f,1)
#statement 变量关系式编程天天用 文化输出成解构+类型体操+Reactive响应算式/约束逻辑后就变🐮逼了,而函数式的闭包+回调(栈转堆,return地址转闭包) 输出变成协程/
yield{(then=>),} 后也TM🐮逼了,内联return变goto变尾递归时,又比break更平等了,纯的 if(a,a,puts) a&&puts() 又和自动闭包宏不一样了文本-AST-Scratch VM_IR-SSA-节点图 又隔离了,AST就不能是赋值图了。 这叫原地踏步式的前沿🥰 怀旧你🦄呢
(Kt 1..2对int,long 乃至Iter,Seq都有不同的(模板性)重载 ,连(Java8 stream 里也有的)去除装箱都没推广到语言层面。
a=x?.f() 的?像一个修饰器,在f代表语句时外提为(Cont的捕获:switch化也需要) _f=x?f(x):x; a=_f
而反观那些ANTLR,YaCC 会逼你再来浅先遍历1次,以解析栈内存,否则会增大解释器开销--因为它们是靠LALR等“虚拟机”而不用现成的调用栈递归。 小众领域的白象总是揉杂到夸张
其他玩法:
$=(...x)=>cg([[],...x])()
with(DSL)$([x,3], [a,1,x])
with(DSL)$([0, 1, [[x], [x]] ])
with(DSL)$([0, 1,[[x], [0, 2,[[y], [0,x,y,'+']] ] ]] )
cg() 短的原因是,它只是把语法解构再构了一遍(或者说穷举了输入=>输出的对应性),就像 noop=(a,b=0)=>a==0? b :移动 一样基础但这就是编程语言的本质: 如果抢了应用或功能点的风头,沉迷于无尽循环的轮子,那必然是种设计错误
想测试自己元编程能力,可以做些改进:
1. vararg和可选参数, forEach, 自动支持await
2. 把“静态”检查的f(a,b,c) 回退到弱类型 [..,3,f] 且不与既有AST冲突
3. 把重赋值扩展到py式
(,自动新建变量)=>,, ,变量表可以直接用原型链,注意 f(a=[]) 是能被f修改的4. 常量折叠,循环展开
[for,x, [[1,2,3]], [0,[x,print]] ] 为3次print5. 用词法域,把调用和递归转为push;|用CPS,把调用栈闭包成堆内链表 ,转化到这一步代码就剥离开JS的ABI了
台湾的翻译的heap,stack就是从 malloc(), alloca(stack) 意译的吧
函数级的存储空间就像push(struct),是能静态计算。
btw. 惰性Proxy(可变<函数>) 是环形依赖的组织方法。
f=>(a,b)=>a? f(a-1,b+1):b 你可以试试用 fref(f=>f).set( Y组合子) 和蹦床函数(伪递归) 计算下如果不会写,可以用「费曼算法」:上面说了
>请把程序写成数组的形式 🥰GPT就是费曼算法的一种实现,但它不能替你踩坑啊。
很想给点引文:mal lambda书, decaf-lang C书, Craft 书, 闭包详解, JVM R佬科普, c4:极简栈解释器,minipy
Lox实现图解, js工具库, astexpo, godbolt.org , tio.run , 语言花名册
👍20页纯示例 http://rigaux.org/language-study/syntax-across-languages.html#:~:text=Bags%20and%20Lists
http://rigaux.org/language-study/scripting-language/#:~:text=compile%20what%20must%20be
其他 code.golf:
重构浣熊 多语言
https://blog.vero.site/post/noulith#:~:text=The%20Cube
https://github.com/eclipse-archived/ceylon-lang.org/blob/master/blog/2015-10-27-why.md#reified-generics
https://ruslanspivak.com/lsbasi-part1/
但那么多都TMD在讲BNF讲分词,还有人把py的缩进往回{}改 😅中文圈就没个做基建的
(正则吃数|读树)都不会是吧。 BNF也就比XML好看一丁点,单知道输入数据长什么样,对理解语言做元编程帮助很少
#haskell 上也有
https://okmij.org/ftp/tagless-final/index.html#:~:text=class%20Symantics 称为GADT https://stackoverflow.com/questions/33928608/typed-abstract-syntax-and-dsl-design-in-haskell
我是说
Lit(Int): T<Int>
Add(A,B): T<Int>
toStr(this:T<*>): T<Str>本质是把fun提升为class。套一层Lit<R>是方便另加接口,比如统一能eval():R ,当然这也是OOP比FP扩展性强的一个中心思想
能直接DSL或弱类型when就不要做无意义的装箱套壳,建起来终究是要执行的
甚至
fun<R> lit(:R): ()->R 组合器都能起到和AST同样的效果,OO和FP只是复用参数的一种手段,重点是你对目标树型有没有最常见的心智模型Wikipedia
Higher-order abstract syntax
technique for the representation of abstract syntax trees in languages with variable binders
duangsuse::Echo
#sql #ts Prolog 牛逼! 正确的关系式搜索+ 同时实现 parse 和 toStr 😱 #zhihu 灵感来源 e(E) -->{E = [I,Ea,Eb]}, %重写规则, 'eX'为优先级 %利用 链|e1(E) 括住内"*/" e1(Ea), op(I,"+-"), e(Eb); e1(E). e1(E) -->{E = [I,Ea,Eb]}, e2(Ea), op(I," */"), e1(Eb); e2(E). e2(X) --> number(X); ("(",…
#book #ts The Little Typer
1. 类型签名是命题,程序的语意是用+,[],. 构造int,void.
2. 命题的条件和自身,都是值;依赖类型可以把值放到类型(int[2],. )中去,从而构造关于值的命题。
3.Prolog 缺少抽象
4. 类型也可以有类型, #haskell HigherKind
从结果上看,反而像 类型签名是证明,类型构造器是调用命题……
这样,类型依然是命题,程序依然用Refl证明并构造了Equal,而且删掉了查重率60%的冗余语法
Refl : 右是一段程序。用这种隐晦的方法传变量是错误的。这个语法的问题远不止「类型含糊」, 对语序的修改,只算一种局部的优化。
为什么用 (
https://ksqsf.moe/posts/2019-02-18-dt-fun.html
https://mxm.ink/dependent-type/#依赖于类型的类型:list
https://agda-zh.github.io/PLFA-zh/Induction/#第一个证明结合律
https://www.idris-lang.org/pages/example.html
1. 类型签名是命题,程序的语意是用+,[],. 构造int,void.
2. 命题的条件和自身,都是值;依赖类型可以把值放到类型(int[2],. )中去,从而构造关于值的命题。
3.Prolog 缺少抽象
refl_ID(X,X). 的模式,它的条件表都是全局给定,不能构造类型4. 类型也可以有类型, #haskell HigherKind
*->*, TypeFamilies 就是指这个(虽然和 #ts 一样过度设计从结果上看,反而像 类型签名是证明,类型构造器是调用命题……
data Equal : a -> b -> Type where如果我换个语序,会更合理。
Refl : Equal x x
fiveIsFive : 5 = 5
fiveIsFive = Refl = Equal 5 5
data'ab' _=_
- x=x Refl() 成立
- five() 5=5 Refl 这样,类型依然是命题,程序依然用Refl证明并构造了Equal,而且删掉了查重率60%的冗余语法
Refl : 右是一段程序。用这种隐晦的方法传变量是错误的。这个语法的问题远不止「类型含糊」, 对语序的修改,只算一种局部的优化。
为什么用 (
Refl : Equal) 呢:它的亲戚,逻辑式语言都连「调用树」都不会组织,反而觉得 add-out(1,2,3) 更好看,加个类型学了“调用”,语序却远输OOP,真可谓一盘散沙
https://ksqsf.moe/posts/2019-02-18-dt-fun.html
https://mxm.ink/dependent-type/#依赖于类型的类型:list
https://agda-zh.github.io/PLFA-zh/Induction/#第一个证明结合律
https://www.idris-lang.org/pages/example.html
-- showOrRev(isInt, x) when isInt:因为是宏,当然就不需要类型作为值了。内联后直接推导就知道
$Y: x.Str ; $N: x.flipLR
-- printf(:Str, :[Arg Str])
直接在编译期生成loop,也不需要什么ts体操+js强转了when--'T' Link
Nil; Add(:T, :Link)
-'T' Link`+`(y:Link) when this:
Nil: y ; Add(x0,x): Add(x0, x+y)
-- useInline 可以直接计算Link拼接或解构后的值,避免手动分期求值ksqsf.moe
有趣的依赖类型
这篇文章的话题是「依赖类型」。很多人,甚至是写过多年程序的人,可能都没有接触过这个概念。简单说,如果一个类型依赖于一个不是类型的东西,那它就是依赖类型。其实我本人是这个话题的门外汉,那我怎么想起来写这样的一篇文章了呢?因为我刚刚读完《The Little Typer》,感觉非常新奇有趣,所以想写一写。如果我能把这份乐趣分享给你,那我会很高兴的~ (^_^)
#design #plt
最近在整理的编程范式有点让我头疼…… 这个或许对学OOP有帮助吧:
最近在整理的编程范式有点让我头疼…… 这个或许对学OOP有帮助吧:
//行列状多态,就是说一个类型由 字典C=A+B 定义这样的好处是 sealed,data class 都非常简单-甚至多种子类都语法一致,与 #Haskell GADT 不同的是,它支持附带函数与隐式this
?? C A
b1 Str
- b2 Int
//以上声明里没写,故需要另加构造器
?? C
Cat(name:Str, b1="demo")
- b2 b1.(0).Int
Camel(ver=0)
b1 "Hi"
- b2 0
?? 'AB'Columns //泛型,单位状类型如果是新类型,还可以定义Enum甚至表格
Pair(:A,:B)
Triple(:A,:B,:C)
?? 'AB'way2
posL [A mayNO] //val posL: A?
posR [B mayNO]
Left(v:A) ; Right(v:B)
?? RGB学起来有点让人费解(当然这是我设计的), 虽说类型和值都是「构造器」,这样的大杂烩也太奇怪了(但,比用到再单独地学好吧?)
R;G;B
?? 调料
甜 Int ; 咸 Int
- 咸 id==1 or 咸>1
醋 (0 0)
盐 (0 1)
HanakoのPlayground☄️
Photo
^1笑点解析
#linux rootfs容器化的潮流下,
apt-get; systemd 做梦也没想到有人把挂载当cp 和pm2用 😅,效仿 apk, Magisk 了,直接放弃文件读写
(其实就是OS提供给 read,write,readdir 函数的 hook ,archlinux 一直是如此做 PKGBUILD ,玩得这么花 不就是为了免
天下苦OS碎片化久矣
^2 #plt #learn
CPS变换=ES6无栈协程=自动传回调
OS调度器=有栈C语言协程=单核多任务 免回调
#haskell Cont等Monad能够和do管道链配合,实现异步、伪随机等其他语言里稀松平常的「纯函数」特技
'入'演算里,CPS变换必须不直接求值,改接受回调k ,这样它们就能跨线程组装返回值. 用人话翻译下:
他的本意,应该是指CPS 就像
第三行的定义,按 Reactjs,Rx 都是CPS框架,只是不止能"return" 一次。 这个和指针关系不大,比如swap(a,b)是宏能定义的语法糖
^3
玩梗是很有新意,但希望各位订户记住: “高尚的是人,不是职业”
聪明的是人,不是编程语言;解决问题的是范式,不是语法规范
^4
推荐云风的Unity 3D教程。 u3d和GL使用左手y-up座标系,而不是数学的z-up
这利于2.5D横版游戏的开发
但z是“近大远小”的,和DOM翻转y理由一样。另外 cv2 是使用 bmp[y,x] 坐标,好奇怪的语法?
#linux rootfs容器化的潮流下,
$ mount 跟不上时代了apt-get; systemd 做梦也没想到有人把挂载当cp 和pm2用 😅,效仿 apk, Magisk 了,直接放弃文件读写
(其实就是OS提供给 read,write,readdir 函数的 hook ,archlinux 一直是如此做 PKGBUILD ,玩得这么花 不就是为了免
systemctl start 免分渠道发包呗天下苦OS碎片化久矣
^2 #plt #learn
CPS变换=ES6无栈协程=自动传回调
OS调度器=有栈C语言协程=单核多任务 免回调
#haskell Cont等Monad能够和do管道链配合,实现异步、伪随机等其他语言里稀松平常的「纯函数」特技
'入'演算里,CPS变换必须不直接求值,改接受回调k ,这样它们就能跨线程组装返回值. 用人话翻译下:
(x): k=>x(k) # 常量或sleep(1s) (k),read 等基元第二行就很抽象,「拿到流水线需要的东西」就是CPS,那么调用栈-返回也是CPS了, 但那是编程的基础课
(x=>A): k=>k (x=>A)
A(Arg): k=>A (K=>K(Arg))(k) #大K用来求值参数,小k回调
他的本意,应该是指CPS 就像
fetch(://fn/args).then(ret=> 可以实现RPC。 kt 的 withContext(Dispatcher.IO) 和 "use server" 就是这个意思,可惜这术语也说了,用处却列不清楚第三行的定义,按 Reactjs,Rx 都是CPS框架,只是不止能"return" 一次。 这个和指针关系不大,比如swap(a,b)是宏能定义的语法糖
^3
玩梗是很有新意,但希望各位订户记住: “高尚的是人,不是职业”
聪明的是人,不是编程语言;解决问题的是范式,不是语法规范
^4
推荐云风的Unity 3D教程。 u3d和GL使用左手y-up座标系,而不是数学的z-up
这利于2.5D横版游戏的开发
但z是“近大远小”的,和DOM翻转y理由一样。另外 cv2 是使用 bmp[y,x] 坐标,好奇怪的语法?
❤1
#algorithm 动态规划 dynamic programming
eg. lcs公共子串, knapack背包最佳配重, edit-distance编辑距离
http://www.bilibili.com/video/BV1FJ4m1M7RJ
🌚这是连“二参记忆化递归”这个常识都没说出来啊。
其实DP的经典案例是fib f x=x if x<2 else f(x-1)+f(x-2)
转化为一维的 f=[0,0]; f.i=f.(i-1)+f.(i-2)
这样,动归比递归的主要难度,是确立基线,以及用抽象的2D数组.ij取代fib()思考「状态转移方程」
二者的相似,好比「积分傅里叶变换」与离散DFT
动归比 @memo def fib 只优化了常量时间
fib只需要朝0的方向计算两个子问题,可以 iter 优化
实现上,如 lcs
f(,)=0
f(a,ab)=1
f(b,ab)=1
来,可视化一个corner case!
\ a b
a 1 0
b 0 2
可见,参数网格
晦涩就对了,因为它等效这个:
lcs([A],[B])=A==B
lcs([A,a],[B,b])=
max(lcs(a,b) lcs(b,a))+(A==B? 1:0)
lcs([A,a],[B])= lcs(a)+(A==B? 1:0)
+2分支
f(a,ab)=1 直接匹配AaBb +1
f(b,ab)=1 则匹配ABb,居然也与表格等效
更易懂了吗?见仁见智,尤其是 (a,b)(b,a)是干啥? 当然,因为lcs本身就有交换律啊..
不过我要指出,这个语法是有问题的(尽管 #haskell 在红黑树/快排上比cpp可易读不止一半),如果专门对DP设计,一定有 np.einsum 那样更优雅的表述
DP教学总是涉及表格[i,j] 而可视化并不方便,不过解「编辑距离」,你总得先学diff(abc, aBc)=[1: -1+B] 怎么计算吧
* https://t.me/dsuses/5335 基于memo的lcs,人不如AI
* https://t.me/dsuse/18877?single fib流
只能先留个坑🌝触摸屏累死了
eg. lcs公共子串, knapack背包最佳配重, edit-distance编辑距离
http://www.bilibili.com/video/BV1FJ4m1M7RJ
🌚这是连“二参记忆化递归”这个常识都没说出来啊。
其实DP的经典案例是fib f x=x if x<2 else f(x-1)+f(x-2)
转化为一维的 f=[0,0]; f.i=f.(i-1)+f.(i-2)
这样,动归比递归的主要难度,是确立基线,以及用抽象的2D数组.ij取代fib()思考「状态转移方程」
二者的相似,好比「积分傅里叶变换」与离散DFT
动归比 @memo def fib 只优化了常量时间
fib只需要朝0的方向计算两个子问题,可以 iter 优化
实现上,如 lcs
f(,)=0
f(a,ab)=1
f(b,ab)=1
来,可视化一个corner case!
\ a b
a 1 0
b 0 2
可见,参数网格
r.(0 0)= A0==B0
r.(i j)= (Ai==Bj? 1:0)+
try max( r.(i-1) r.(j-1))
i==0: r.(0 j-1) #第0行没法再减
j==0: r.(i-1 0)
晦涩就对了,因为它等效这个:
lcs([A],[B])=A==B
lcs([A,a],[B,b])=
max(lcs(a,b) lcs(b,a))+(A==B? 1:0)
lcs([A,a],[B])= lcs(a)+(A==B? 1:0)
+2分支
f(a,ab)=1 直接匹配AaBb +1
f(b,ab)=1 则匹配ABb,居然也与表格等效
更易懂了吗?见仁见智,尤其是 (a,b)(b,a)是干啥? 当然,因为lcs本身就有交换律啊..
不过我要指出,这个语法是有问题的(尽管 #haskell 在红黑树/快排上比cpp可易读不止一半),如果专门对DP设计,一定有 np.einsum 那样更优雅的表述
DP教学总是涉及表格[i,j] 而可视化并不方便,不过解「编辑距离」,你总得先学diff(abc, aBc)=[1: -1+B] 怎么计算吧
* https://t.me/dsuses/5335 基于memo的lcs,人不如AI
* https://t.me/dsuse/18877?single fib流
只能先留个坑🌝触摸屏累死了
Bilibili
ACM 金牌选手教你动态规划的本质。力扣 No.72 编辑距离,真·动画教编程,适合语言初学者或编程新人。_哔哩哔哩_bilibili
虽然我没有写出来,但是你应该知道我要什么吧 XD, 视频播放量 33101、弹幕量 168、点赞数 1694、投硬币枚数 699、收藏人数 2134、转发人数 118, 视频作者 NotOnlySuccess, 作者简介 大一接触编程 2 次晋级 World Finals 并获最快解题奖;4 次 ACM亚洲区金牌;浙江省赛冠军;曾就职阿里、谷歌、微信,相关视频:边睡边学算法丨第一期,动态规划入门50题,10分钟彻底搞懂“动态规划”算法,【动态规划专题班】ACM总冠军、清华+斯坦福大神带你入门动态规划算法,Leetcode力扣…
https://ray-eldath.me/programming/three-important-ideas/ #statement #PLT
Ray: 我的一位朋友如此评论这些文章:他说真正理解抽象的唯一方式是通过抽象本身,而不是通过并不准确的类比。
「为了充分地("有用处"地)学习这些抽象,你必须去学数学,而不是通过一些糊里糊涂的文章,它们除了类比还是类比」
Dr: 要找到 “哪些代码遵循此抽象” 并不是必须的。像 Monad 这样的概念是非常抽象和通用的:它是一个描述了一套广泛的编程模式、数据结构、库和 API 的概念,其强大之处在于它们,是对如何设计和使用这种抽象的指导原则
成为高效的程序员并不需要理解全部的联系。其他人自然会强烈反对 :-)
Ray: "可仅仅知道 JavaScript 里的 Promise 本质上是 Monad,而 Functor “又是一个盒子” 并不能帮助你成为更好地程序员,而在你自己的库中使用这些词语只会让你的下游觉得不舒服"
...概念是非常抽象和通用的
等等,
逻辑学告诉我,抽象是通用的反面,就像社会是丛林的反面: 您的知识若是通用的,它一定能与各应用领域紧密联系,学生如何觉得它抽象!?
人们就是讨厌空谈,所以设计各种简洁而通用的API;人民就是讨厌丛林,所以组织出了社会。 现在竟有人觉得存在通用抽象和丛林社会?? 这就像是说javadoc等机翻的玩意,比各种demo, test甚至产品更能展示项目的价值!
“靠代码行数来衡量软件功能的进度,就像是凭零件重量来衡量飞机制造的进度——Gates
靠知识点的难度衡量价值,同理。😅
我看这种观念者,确实是够抽象。 “类比”的本质是抽象,而「学习」只是用自己领域的思维,去「组合」「代换」出别人说的那种东西,带给你工具和知识图谱上的价值。
大家来到世上都是白痴,没有谁拥有无法被代换给别人的知识「原子」。写文爱用「未定义就使用的概念」,想设计新的抽象,却不谈理由?那就是 lier
无论我们用什么领域的「原子」组合出了CS的知识点,那都是潜在的价值,为空洞的术语绑定了新的语意,更摒弃了其中被“凭空捏造”的哲学。让IT人说话,天塌不下来!
难者,不会也。作者已死,凭什么说的道你就是「高等抽象」,大家能跟上的就是"糊里糊涂"的抽象? Einstein, Feynman 说物理的最前沿应该教高中生搞懂,难道你们的方法论比爱翁还科学?
人们给车设计的引擎,能达到原理极限的98%,那么 #CS 对IT的指导,除了让空指针反复造成十亿美元bug,就是让功能不变的软件,随着更新越来越臃肿和慢? 这算什么CS!
Monad很图论,很优雅啊! 但它能从
数学的精度是无限的、数学的等号是有交换律的。 #Haskell 里有模式匹配,但有"Var(x)作为值"吗?
只要变量是值,模式匹配、类型推理、响应式,甚至函数的编译,就真是小孩都会写的栏大街了。让
FP们连正反函数如
https://arendjr.nl/blog/2024/07/post-architecture-premature-abstraction-is-the-root-of-all-evil/#:~:text=achieved%20through%20a%20much%20simpler%20function
“个体的经历,不过是一个庞大的(形式主义)系统下极其表面化的闪烁而已”
可那个闪烁对某一天的用户来说就是一切。 自然原理,亘古不变。如果只是发现他们就能改变世界? 工业革命可以提早数百年。
人一思考,上帝就发笑。 你们的抽象,永远概括不了现实的领域、具体的人所提供独有的组合与可能性。
知其变,守其恒,为天下式?
穷其变,悟不穷,以明我志!
不能为每个人产生普世价值,是理论的悲哀。
Ray: 我的一位朋友如此评论这些文章:他说真正理解抽象的唯一方式是通过抽象本身,而不是通过并不准确的类比。
「为了充分地("有用处"地)学习这些抽象,你必须去学数学,而不是通过一些糊里糊涂的文章,它们除了类比还是类比」
Dr: 要找到 “哪些代码遵循此抽象” 并不是必须的。像 Monad 这样的概念是非常抽象和通用的:它是一个描述了一套广泛的编程模式、数据结构、库和 API 的概念,其强大之处在于它们,是对如何设计和使用这种抽象的指导原则
成为高效的程序员并不需要理解全部的联系。其他人自然会强烈反对 :-)
Ray: "可仅仅知道 JavaScript 里的 Promise 本质上是 Monad,而 Functor “又是一个盒子” 并不能帮助你成为更好地程序员,而在你自己的库中使用这些词语只会让你的下游觉得不舒服"
...概念是非常抽象和通用的
等等,
逻辑学告诉我,抽象是通用的反面,就像社会是丛林的反面: 您的知识若是通用的,它一定能与各应用领域紧密联系,学生如何觉得它抽象!?
人们就是讨厌空谈,所以设计各种简洁而通用的API;人民就是讨厌丛林,所以组织出了社会。 现在竟有人觉得存在通用抽象和丛林社会?? 这就像是说javadoc等机翻的玩意,比各种demo, test甚至产品更能展示项目的价值!
“靠代码行数来衡量软件功能的进度,就像是凭零件重量来衡量飞机制造的进度——Gates
靠知识点的难度衡量价值,同理。😅
我看这种观念者,确实是够抽象。 “类比”的本质是抽象,而「学习」只是用自己领域的思维,去「组合」「代换」出别人说的那种东西,带给你工具和知识图谱上的价值。
大家来到世上都是白痴,没有谁拥有无法被代换给别人的知识「原子」。写文爱用「未定义就使用的概念」,想设计新的抽象,却不谈理由?那就是 lier
无论我们用什么领域的「原子」组合出了CS的知识点,那都是潜在的价值,为空洞的术语绑定了新的语意,更摒弃了其中被“凭空捏造”的哲学。让IT人说话,天塌不下来!
难者,不会也。作者已死,凭什么说的道你就是「高等抽象」,大家能跟上的就是"糊里糊涂"的抽象? Einstein, Feynman 说物理的最前沿应该教高中生搞懂,难道你们的方法论比爱翁还科学?
人们给车设计的引擎,能达到原理极限的98%,那么 #CS 对IT的指导,除了让空指针反复造成十亿美元bug,就是让功能不变的软件,随着更新越来越臃肿和慢? 这算什么CS!
Monad很图论,很优雅啊! 但它能从
x+1==2 得出x=1吗? does it run backwards?数学的精度是无限的、数学的等号是有交换律的。 #Haskell 里有模式匹配,但有"Var(x)作为值"吗?
只要变量是值,模式匹配、类型推理、响应式,甚至函数的编译,就真是小孩都会写的栏大街了。让
let(['x','y'],a) 生成 x=a[0],y=a[1] 谁不会啊 也配叫语言特性FP们连正反函数如
show-out(1, "1"); show(res, "1"); res==1 都没建模,无精度int、向量、矩阵和微分都不如numpy sympy,也好意思谈数学性? 起码把Fortran的矩阵搞明白再说吧https://arendjr.nl/blog/2024/07/post-architecture-premature-abstraction-is-the-root-of-all-evil/#:~:text=achieved%20through%20a%20much%20simpler%20function
费曼家有一套《大英百科全书》,父亲常让费曼坐在他的膝上,给他念里边的章节。
有一次念到恐龙,书里说,“恐龙的身高有 25 英尺, 头有 6 英尺宽。” 父亲停顿了念书, 对费曼说,
“唔,让我们想一下这是什么意思。这也就是说,要是恐龙站在门前的院子里,那么它的身高足以使它的脑袋凑着咱们这两层楼的窗户,可它的脑袋却伸不进窗户,因为它比窗户还宽呢!”
就是这样, 他总是把所教的概念变成可触可摸, 有实际意义的东西。
“个体的经历,不过是一个庞大的(形式主义)系统下极其表面化的闪烁而已”
可那个闪烁对某一天的用户来说就是一切。 自然原理,亘古不变。如果只是发现他们就能改变世界? 工业革命可以提早数百年。
人一思考,上帝就发笑。 你们的抽象,永远概括不了现实的领域、具体的人所提供独有的组合与可能性。
知其变,守其恒,为天下式?
穷其变,悟不穷,以明我志!
不能为每个人产生普世价值,是理论的悲哀。
Ray Eldath's Blog
计算机领域的三个重要思想:抽象,分层和高阶
昨晚看了点比较有意思的东西,于是决定写一篇文章简单讲一下。 本文致力于概括我对计算机界三个重要思想的体会和认识。我希望做的并不是简单的百科全书式的列举(“A 体现了抽象思想;B 体现了分层思想…”),而是从这些思想中选取几个我个人较有体会(或者是我单纯觉得十分有趣)的侧面拿来细讲。这些侧面仅仅能覆盖这些思想应用范围中十分微小的一部分,它们并不是最有代表性的、亦非最为重要的——仅仅因为,我个人对这点
duangsuse::Echo
https://ray-eldath.me/programming/three-important-ideas/ #statement #PLT Ray: 我的一位朋友如此评论这些文章:他说真正理解抽象的唯一方式是通过抽象本身,而不是通过并不准确的类比。 「为了充分地("有用处"地)学习这些抽象,你必须去学数学,而不是通过一些糊里糊涂的文章,它们除了类比还是类比」 Dr: 要找到 “哪些代码遵循此抽象” 并不是必须的。像 Monad 这样的概念是非常抽象和通用的:它是一个描述了一套广泛的编程模式、数据结构、库和…
#PLT #learn 文中提到一个Futa对应关系(第一类二村映射 first Futamura projection), 展开讲讲还蛮有趣 🙉
首先,js人都会写计算器的,和 echo input/server 一样的难度
这被称为「前缀式polish notation」,是Lisp的国是
教个小诀窍:js里函数只是一种字面常量,可以被for生成
为了更像“语言”,可以用列表(进一步就是"1+2"的代码)实现语法,便于糖化
Monadic递归下降是这样AbBc的,因为不能右移流指针。不如逆波兰好看!不过这种程度的递归可以学学。
再看下「解释器interpreter」比计算器强在哪: 能够“在调用时传值”,也就是要有 argument[0] 这种“环境变量”
很厉害!现在有常数外的“语法”了,有变量了,高阶了!或许你需要学动态作用域(原型链?)、调用栈call-ret、惰性求值如&&|| blabla,还有深不可测的编译优化呢!
不就加一个箭头么。
env被称为运行时,它可以是JVM, import dis 或者别的bytecode解释器,这能减少tree-walk对递归栈的频繁依赖
这种
编译器并不需要与DSL这些技巧隔离,如果我们把 env=>x 写作 JSON(x) 而 env=>env[i] 写作$i ,既
以这种人类或机器可读的结构序列化一些函数被"bind"到的lit,就得到了对应的代码。jvm的 lconst 1, aload_0 this参数, iadd (2->1)甚至是自动分配参数寄存器的!
https://www.yinwang.org/blog-cn/2014/01/04/authority#:~:text=partial%20evaluator。其实并不是特别神奇的东西,只需要在普通解释器里面改一两行代码就行,可是有人
二段求值。代码是流动的数据,内存是暂停的程序。本文甚至比赢王更直观: https://www.yinwang.org/blog-cn/2012/08/01/interpreter
定义个“元循环加法”吧?
如果你乐意,还可以支持基于全局表的递归 fib=f(x)=x<2? 1 : f(x-1)+f(x-2)
这一切都不会突破以上的定义框架。 If 不会,Call(f,x-1) 不会.. 这就是java的反射嘛。
我不想再写什么了。 我看过许多“编译原理书”,他们连这个=>都写不明白。 更何谈用Visitor实现(反)序列化 这些既理论又实践的approach
#haskell
这类基于list或class{子类多型} 的
> 高阶的思想或许是本文的所有思想中最为重要的那一个 https://ray-eldath.me/programming/three-important-ideas/
你们知道函数的函数、类型的类型、语言的语法,却难以创造「语言中的语言」—跨越用途与界限而一致的语意。
我看numpy和 taichi-lang.org 就用的很好,比LLVM好一个世代
顺带一提,上文还使用了 Tagless Final 和 De Bruijn 索引 😇 。只是…… 你甚至不需要知道它们的名字。
说到底,元编程也只是编程。就像“学会学习”只是一种策略,它对学习而言,并非例外情况。难者,不会也,譬如在谈"bind(x=1)后函数值字面是否改变"时提起「颗粒化curryArg」 当然会让人迷糊
node,graal会编译js,jvm代码(这也是为何Chrome页偶尔会segfault); JVM会使用汇编模板+JIT 的混合式优化,Cython则把“甜妹语言”翻译到C,LLVM则是个伪装成NodeGraph虚拟机的codegen
如果只用"是否该调用javac"来区分语言,认为C类型总比python更快的话,你会发现程序员钟意的都是freak!
宏,macro码可揉,是传入与生成class{}等字面的函数。和+-*/一样只是函数,而函数、类型,只是值,别被“静态分析”骗了,它们送你的class只是病态类型。
入,lambda栏目答,看x,A,B等栏目回答的算式
这点篇幅放前言都觉得寒碜吧? 可就是没人做到啊。 扶她投影?不知道的还以为是HP projector 的娘化版呢。。
PLT能对dev点化到的可谓寥寥, 但100%都是必要且急需的知识和"抽象",像Prolog的模板与响应式html编程("FRP") 什么的。 Monadic错误处理我不想吐槽什么,只能说不怕不识货,只怕和Kotlin比!
跑题了。当然,聪明的你会发现Fun的返回违背了"基线指明了递归的类型"这一原则,没生成 env=>
那C语言函数指针是这样的,env由*rbp[0:2]=[retRbp,retAddr]这些CPU变量提供,但JS里的闭包可以从env偷变量(Var作为值,mut ref),所以说「闭包是穷人的(单方法)对象」
C里还有"函数符号",那是由ld.so实现的全局表,让.o对象能先被mmap到任意地址,再去回填calls
真正的那个全局表叫 $PATH: ,以及没定义main的对象的 $LD_LIBRARY_PATH 。
首先,js人都会写计算器的,和 echo input/server 一样的难度
1+2*3
十(1, X(2,3)) -7
十=(A,B)=>A+B
这被称为「前缀式polish notation」,是Lisp的国是
教个小诀窍:js里函数只是一种字面常量,可以被for生成
Object.entries("十一Xノ").forEach(([i,x])=>
this[x]=eval(`(A,B)=>A${"+-*/"[i]}B`))为了更像“语言”,可以用列表(进一步就是"1+2"的代码)实现语法,便于糖化
Eval([十,1, X,2,3]) -7
Eval=([f,...x])=>(!f.call)? [f,x] : //基线返回两项,递归就都是两项
(([A,b]=Eval(x),[B,c]=Eval(b))=>[f(A,B), c] )()
Monadic递归下降是这样AbBc的,因为不能右移流指针。不如逆波兰好看!不过这种程度的递归可以学学。
再看下「解释器interpreter」比计算器强在哪: 能够“在调用时传值”,也就是要有 argument[0] 这种“环境变量”
很厉害!现在有常数外的“语法”了,有变量了,高阶了!或许你需要学动态作用域(原型链?)、调用栈call-ret、惰性求值如&&|| blabla,还有深不可测的编译优化呢!
不就加一个箭头么。
十=(A,B)=> (env=>A(env)+B(env)) //现在知道为啥该用for生成函数?
Lit=x=> env=>x
Arg=i=> env=>env[i] //PHP写作 $x, 模仿bash的$1~$*
Fun=(n,f)=>f(Array(n).fill(0).map((x,i)=> Arg(i)))
env被称为运行时,它可以是JVM, import dis 或者别的bytecode解释器,这能减少tree-walk对递归栈的频繁依赖
这种
formSytanx.bind(consts=lit/arg/global/Types..) 的"部分传参"函数,称为编译器,而它的返回就是classFile等类型。 编译器并不需要与DSL这些技巧隔离,如果我们把 env=>x 写作 JSON(x) 而 env=>env[i] 写作$i ,既
Lit=x=> gcc? CBor.dumps(x) : (env=>x)以这种人类或机器可读的结构序列化一些函数被"bind"到的lit,就得到了对应的代码。jvm的 lconst 1, aload_0 this参数, iadd (2->1)甚至是自动分配参数寄存器的!
https://www.yinwang.org/blog-cn/2014/01/04/authority#:~:text=partial%20evaluator。其实并不是特别神奇的东西,只需要在普通解释器里面改一两行代码就行,可是有人
二段求值。代码是流动的数据,内存是暂停的程序。本文甚至比赢王更直观: https://www.yinwang.org/blog-cn/2012/08/01/interpreter
定义个“元循环加法”吧?
十1=Fun(1, ([A])=>十(A, Lit(1)))
十1([232]) -233
//[Lit(f),x] 补丁下Eval"解析器"。计算器、解释器、编译器间,其实并非泾渭分明
Eval([十,1, X,2,X,1,3])[0]([2]) -7
如果你乐意,还可以支持基于全局表的递归 fib=f(x)=x<2? 1 : f(x-1)+f(x-2)
这一切都不会突破以上的定义框架。 If 不会,Call(f,x-1) 不会.. 这就是java的反射嘛。
我不想再写什么了。 我看过许多“编译原理书”,他们连这个=>都写不明白。 更何谈用Visitor实现(反)序列化 这些既理论又实践的approach
#haskell
data Val=L Int|Op Char Val Val deriving(Show)
(Op '+' (L 1) (Op '*' (L 2) (L 3) ))这类基于list或class{子类多型} 的
Eval(e=^^, env={proto:{..}}),与本文使用的闭包法是等价的。「闭包是穷人的对象」,Promise 给它暴露到了 obj.then(Continuation)> 高阶的思想或许是本文的所有思想中最为重要的那一个 https://ray-eldath.me/programming/three-important-ideas/
你们知道函数的函数、类型的类型、语言的语法,却难以创造「语言中的语言」—跨越用途与界限而一致的语意。
我看numpy和 taichi-lang.org 就用的很好,比LLVM好一个世代
顺带一提,上文还使用了 Tagless Final 和 De Bruijn 索引 😇 。只是…… 你甚至不需要知道它们的名字。
([A])=> 经常被实现为KV["A"],但点明它的本质,却比写解释器更简单!说到底,元编程也只是编程。就像“学会学习”只是一种策略,它对学习而言,并非例外情况。难者,不会也,譬如在谈"bind(x=1)后函数值字面是否改变"时提起「颗粒化curryArg」 当然会让人迷糊
node,graal会编译js,jvm代码(这也是为何Chrome页偶尔会segfault); JVM会使用汇编模板+JIT 的混合式优化,Cython则把“甜妹语言”翻译到C,LLVM则是个伪装成NodeGraph虚拟机的codegen
如果只用"是否该调用javac"来区分语言,认为C类型总比python更快的话,你会发现程序员钟意的都是freak!
宏,macro码可揉,是传入与生成class{}等字面的函数。和+-*/一样只是函数,而函数、类型,只是值,别被“静态分析”骗了,它们送你的class只是病态类型。
入,lambda栏目答,看x,A,B等栏目回答的算式
这点篇幅放前言都觉得寒碜吧? 可就是没人做到啊。 扶她投影?不知道的还以为是HP projector 的娘化版呢。。
PLT能对dev点化到的可谓寥寥, 但100%都是必要且急需的知识和"抽象",像Prolog的模板与响应式html编程("FRP") 什么的。 Monadic错误处理我不想吐槽什么,只能说不怕不识货,只怕和Kotlin比!
跑题了。当然,聪明的你会发现Fun的返回违背了"基线指明了递归的类型"这一原则,没生成 env=>
那C语言函数指针是这样的,env由*rbp[0:2]=[retRbp,retAddr]这些CPU变量提供,但JS里的闭包可以从env偷变量(Var作为值,mut ref),所以说「闭包是穷人的(单方法)对象」
C里还有"函数符号",那是由ld.so实现的全局表,让.o对象能先被mmap到任意地址,再去回填calls
真正的那个全局表叫 $PATH: ,以及没定义main的对象的 $LD_LIBRARY_PATH 。
Telegram
duangsuse::Echo
#plt #code 谈到RPN,我昨天有个灵感想把js做成缩进的形式
就回顾了优先级算法(嵌套深度包括h1~h6树本质上也是优先级)
示例算法 sexp(tok('1 (2 3) 4')), exp(tok('1*2+3'), optab)
optab={[';']:-1}
"=;+ -;* /".split(';').map((a,l)=>a.split(' ').forEach(x=> optab[x]=l ))
exp=(s/*token x单项o算符 x..*/, l/*evels 大则深…
就回顾了优先级算法(嵌套深度包括h1~h6树本质上也是优先级)
示例算法 sexp(tok('1 (2 3) 4')), exp(tok('1*2+3'), optab)
optab={[';']:-1}
"=;+ -;* /".split(';').map((a,l)=>a.split(' ').forEach(x=> optab[x]=l ))
exp=(s/*token x单项o算符 x..*/, l/*evels 大则深…
duangsuse::Echo
#rust #go #algorithm UmbraString 是对带长度指针(py.bytes, rs.slice) 的(免链接inline),而 SwissTable 是对Hash预分组查表的免链接! 我们知道,Java 存在(装箱boxing) 一说,也就是int,char等字面值的堆分配 (这是泛型擦除 vs template<>化新建的编译期细节),因此JDK8用class Stream.OfInt{}缓解了reified泛型的缺失 那么,(拆箱unwrap) 其实就是在值的内存上内联,像C++栈分配。…
#algorithm #防自学 🤓 让我来示范一下怎么概括算法思路
要介绍的是在stdlib里,用于组织集合类、JSON的3个重要结构:
它们对各种app和其他算法性能效能的重要性,好比json(cbor.me)之于REST、zip之于jvm和pip。 因为是涉及SDK实现的内容,也主观评价下语法设计
下面用胖指针(x64上void*是8b, 胖指16b)、链表、快速排序简单的实现3者 #code
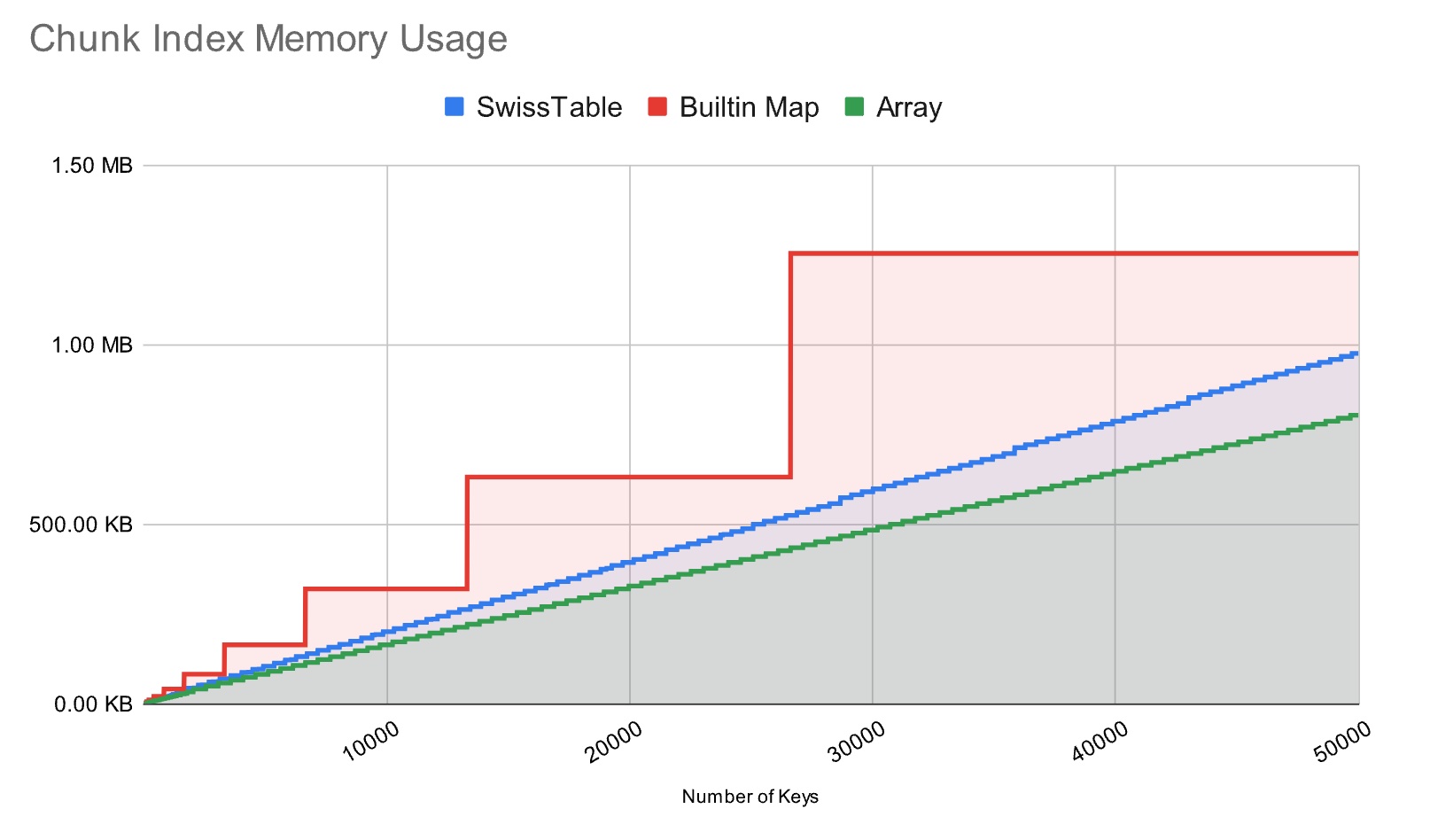
https://colobu.com/2023/06/29/replace-std-map-faster/chunk-index-memory.jpg
用例和 #haskell #code https://gist.github.com/duangsuse/26b80c39e1d8f7549b9cf244d8de1ce4
题外话,闭包值和 x.interface_cast(T) 的双指针&dyn 随结构传入T的函数表
UmbraString 和上文Str{n,buf}胖指针一样是16b,但它的.n和jvm一样只寻址[4b:int]的长度,其后最少随4b的免链接char 用于比大小
对于n>12的buf,剩下8b换成指针,指针的高2位用于标记GC信息: 持久pin、临时ref、用后即焚val
很明显!这是一种灵活利用了x86内存布局的b"length"实现,和x32压缩指针一样,节省了sort解指针的时间
SwissTable 是对Hash预分组查表的免链接。我们知道, dict/HashMap/lua.Table 这样的{K:V, K1:V} 单映射常被用于查找和缓存,在C++里更是会区分 unordered_map, rb_map(以排序radix,SortedSet,而非hash作为预分组线索)
它的最简实现是lisp里的链表
即便8b hashCode,也是一定会冲突的,哪怕是int.hash也会因 buck[hash%nBuck] 有限而退化为线性查找,负载因子(kv/nBuck 过大),这时就要扩容。Go的扩容基于一种空间换时间的优化(图1, 为了减少求余数的冲突,除数都会采用2的指数)
扩容后的冲突集,可以用链表(UnionFind)或数组(slot), 从那往右找
Swiss 更聪明,它对每slot对应1b的元数据,最高位0x80=无效项 ,0xFF=null结尾 ,低7位用于存储hashcode的高7位,这么摘要是为了SIMD128bit 1次对比8个KV
不仅仅只是CPU CACHE友好,这样的结构配合原子操作,相信很容易做出一个并发版本的hash table
快速求余(x,n)= uint32((uint64(x) * uint64(n)) >> 32)
#dalao https://init.blog/fast-newton-sqrt/
最近的一种基于partition(区间而非idx)的快排也很有趣: less than pivotL | between pivotL and pivotR | greater than pivotR
要介绍的是在stdlib里,用于组织集合类、JSON的3个重要结构:
b"ytesPtr", {K:V}, sorted([0 2 1])=[0 1 2]它们对各种app和其他算法性能效能的重要性,好比json(cbor.me)之于REST、zip之于jvm和pip。 因为是涉及SDK实现的内容,也主观评价下语法设计
下面用胖指针(x64上void*是8b, 胖指16b)、链表、快速排序简单的实现3者 #code
#define Col(...) typedef struct{__VA_ARGS__;} T;
#define T Str
Col(size_t n; char* buf) //C的类型本应默认为指针, *胖指针,像kt那样对Int等类型免链接化。简洁的UNIX里,Type* 快成为public那样的形式主义啦
#define T_Link(E,T) struct T{E x; T* xs;}
T_Link(int,Nums) //template<T> 允许类型推理,即一致化调用和返回处的<T>。可怜gcc/clang无论对宏还是模板的报错皆如内容农场,不具有可读性https://colobu.com/2023/06/29/replace-std-map-faster/chunk-index-memory.jpg
用例和 #haskell #code https://gist.github.com/duangsuse/26b80c39e1d8f7549b9cf244d8de1ce4
题外话,闭包值和 x.interface_cast(T) 的双指针&dyn 随结构传入T的函数表
qsort :: (Ord a) => [a] -> [a]
qsort [] = []
qsort (x:xs) =
let smallerSorted = qsort [a | a <- xs, a <= x]
largerSorted = qsort [a | a <- xs, a > x]
in smallerSorted ++ [x] ++ largerSorted
UmbraString 和上文Str{n,buf}胖指针一样是16b,但它的.n和jvm一样只寻址[4b:int]的长度,其后最少随4b的免链接char 用于比大小
对于n>12的buf,剩下8b换成指针,指针的高2位用于标记GC信息: 持久pin、临时ref、用后即焚val
很明显!这是一种灵活利用了x86内存布局的b"length"实现,和x32压缩指针一样,节省了sort解指针的时间
SwissTable 是对Hash预分组查表的免链接。我们知道, dict/HashMap/lua.Table 这样的{K:V, K1:V} 单映射常被用于查找和缓存,在C++里更是会区分 unordered_map, rb_map(以排序radix,SortedSet,而非hash作为预分组线索)
它的最简实现是lisp里的链表
T_Link(struct {int A,B;}, int_LnKV) :没留任何线索来减枝!即便8b hashCode,也是一定会冲突的,哪怕是int.hash也会因 buck[hash%nBuck] 有限而退化为线性查找,负载因子(kv/nBuck 过大),这时就要扩容。Go的扩容基于一种空间换时间的优化(图1, 为了减少求余数的冲突,除数都会采用2的指数)
扩容后的冲突集,可以用链表(UnionFind)或数组(slot), 从那往右找
Swiss 更聪明,它对每slot对应1b的元数据,最高位0x80=无效项 ,0xFF=null结尾 ,低7位用于存储hashcode的高7位,这么摘要是为了SIMD128bit 1次对比8个KV
不仅仅只是CPU CACHE友好,这样的结构配合原子操作,相信很容易做出一个并发版本的hash table
快速求余(x,n)= uint32((uint64(x) * uint64(n)) >> 32)
#dalao https://init.blog/fast-newton-sqrt/
float InvSqrt(float x) {
float xhalf = 0.5f*x;
int i = *(int*)&x;
i = 0x5f3759df - (i >> 1);
x = *(float*)&i;
x = x*(1.5f - xhalf*x*x);
return x;
}最近的一种基于partition(区间而非idx)的快排也很有趣: less than pivotL | between pivotL and pivotR | greater than pivotR
{kind=link}