
#java #news #algorithm https://www.ithome.com.tw/news/163820
当我听说这个月Gosling退休时,其实我挺开心的,因为java API在我看来普及了不少无语意的知识,为八股文爱好者提供了极大方便,可以说是糟粕
这样给程序员带来麻烦的老灯,退休当然是好事,让他们的OOP繁衍下去是浪费人类的逻辑
但另一方面,这并不是JDK本身或 Doug Lea 等工程师的问题。与C++相比,java并不难。除了简化发布流程,还自带电池,提供了许多xml这类最终被滥用的工具
尽管在数据结构/IO上灵活性低,以及导致了十亿美元bug(nullish),java API并没有做错什么.
错就错在跨领域研究编程范式的人太少,以至于过去20年里没有新模型,Rust go 这些还是在拿interface 模仿OOP,没有一种把 json struct enum union override,FP 混合起来的通用编程方法
当我听说这个月Gosling退休时,其实我挺开心的,因为java API在我看来普及了不少无语意的知识,为八股文爱好者提供了极大方便,可以说是糟粕
这样给程序员带来麻烦的老灯,退休当然是好事,让他们的OOP繁衍下去是浪费人类的逻辑
但另一方面,这并不是JDK本身或 Doug Lea 等工程师的问题。与C++相比,java并不难。除了简化发布流程,还自带电池,提供了许多xml这类最终被滥用的工具
尽管在数据结构/IO上灵活性低,以及导致了十亿美元bug(nullish),java API并没有做错什么.
错就错在跨领域研究编程范式的人太少,以至于过去20年里没有新模型,Rust go 这些还是在拿interface 模仿OOP,没有一种把 json struct enum union override,FP 混合起来的通用编程方法
iThome
Java之父James Gosling宣布退休
被稱為Java之父的James Gosling宣布辭去AWS傑出工程師職務,現年69歲的Gosling選擇退而不休,日後仍將參與他有興趣的專案
#algorithm 动态规划 dynamic programming
eg. lcs公共子串, knapack背包最佳配重, edit-distance编辑距离
http://www.bilibili.com/video/BV1FJ4m1M7RJ
🌚这是连“二参记忆化递归”这个常识都没说出来啊。
其实DP的经典案例是fib f x=x if x<2 else f(x-1)+f(x-2)
转化为一维的 f=[0,0]; f.i=f.(i-1)+f.(i-2)
这样,动归比递归的主要难度,是确立基线,以及用抽象的2D数组.ij取代fib()思考「状态转移方程」
二者的相似,好比「积分傅里叶变换」与离散DFT
动归比 @memo def fib 只优化了常量时间
fib只需要朝0的方向计算两个子问题,可以 iter 优化
实现上,如 lcs
f(,)=0
f(a,ab)=1
f(b,ab)=1
来,可视化一个corner case!
\ a b
a 1 0
b 0 2
可见,参数网格
晦涩就对了,因为它等效这个:
lcs([A],[B])=A==B
lcs([A,a],[B,b])=
max(lcs(a,b) lcs(b,a))+(A==B? 1:0)
lcs([A,a],[B])= lcs(a)+(A==B? 1:0)
+2分支
f(a,ab)=1 直接匹配AaBb +1
f(b,ab)=1 则匹配ABb,居然也与表格等效
更易懂了吗?见仁见智,尤其是 (a,b)(b,a)是干啥? 当然,因为lcs本身就有交换律啊..
不过我要指出,这个语法是有问题的(尽管 #haskell 在红黑树/快排上比cpp可易读不止一半),如果专门对DP设计,一定有 np.einsum 那样更优雅的表述
DP教学总是涉及表格[i,j] 而可视化并不方便,不过解「编辑距离」,你总得先学diff(abc, aBc)=[1: -1+B] 怎么计算吧
* https://t.me/dsuses/5335 基于memo的lcs,人不如AI
* https://t.me/dsuse/18877?single fib流
只能先留个坑🌝触摸屏累死了
eg. lcs公共子串, knapack背包最佳配重, edit-distance编辑距离
http://www.bilibili.com/video/BV1FJ4m1M7RJ
🌚这是连“二参记忆化递归”这个常识都没说出来啊。
其实DP的经典案例是fib f x=x if x<2 else f(x-1)+f(x-2)
转化为一维的 f=[0,0]; f.i=f.(i-1)+f.(i-2)
这样,动归比递归的主要难度,是确立基线,以及用抽象的2D数组.ij取代fib()思考「状态转移方程」
二者的相似,好比「积分傅里叶变换」与离散DFT
动归比 @memo def fib 只优化了常量时间
fib只需要朝0的方向计算两个子问题,可以 iter 优化
实现上,如 lcs
f(,)=0
f(a,ab)=1
f(b,ab)=1
来,可视化一个corner case!
\ a b
a 1 0
b 0 2
可见,参数网格
r.(0 0)= A0==B0
r.(i j)= (Ai==Bj? 1:0)+
try max( r.(i-1) r.(j-1))
i==0: r.(0 j-1) #第0行没法再减
j==0: r.(i-1 0)
晦涩就对了,因为它等效这个:
lcs([A],[B])=A==B
lcs([A,a],[B,b])=
max(lcs(a,b) lcs(b,a))+(A==B? 1:0)
lcs([A,a],[B])= lcs(a)+(A==B? 1:0)
+2分支
f(a,ab)=1 直接匹配AaBb +1
f(b,ab)=1 则匹配ABb,居然也与表格等效
更易懂了吗?见仁见智,尤其是 (a,b)(b,a)是干啥? 当然,因为lcs本身就有交换律啊..
不过我要指出,这个语法是有问题的(尽管 #haskell 在红黑树/快排上比cpp可易读不止一半),如果专门对DP设计,一定有 np.einsum 那样更优雅的表述
DP教学总是涉及表格[i,j] 而可视化并不方便,不过解「编辑距离」,你总得先学diff(abc, aBc)=[1: -1+B] 怎么计算吧
* https://t.me/dsuses/5335 基于memo的lcs,人不如AI
* https://t.me/dsuse/18877?single fib流
只能先留个坑🌝触摸屏累死了
Bilibili
ACM 金牌选手教你动态规划的本质。力扣 No.72 编辑距离,真·动画教编程,适合语言初学者或编程新人。_哔哩哔哩_bilibili
虽然我没有写出来,但是你应该知道我要什么吧 XD, 视频播放量 33101、弹幕量 168、点赞数 1694、投硬币枚数 699、收藏人数 2134、转发人数 118, 视频作者 NotOnlySuccess, 作者简介 大一接触编程 2 次晋级 World Finals 并获最快解题奖;4 次 ACM亚洲区金牌;浙江省赛冠军;曾就职阿里、谷歌、微信,相关视频:边睡边学算法丨第一期,动态规划入门50题,10分钟彻底搞懂“动态规划”算法,【动态规划专题班】ACM总冠军、清华+斯坦福大神带你入门动态规划算法,Leetcode力扣…
duangsuse::Echo
#os #rust struct/union不能实现的短字符串(16byte)优化? https://duanmeng.github.io/2023/12/14/umbra/#:~:text=包含12个或更少字符的短字符串直接存储在字符串头部的剩余12个字节中,从而避免了昂贵的指针间接寻址 https://nan01ab.github.io/2020/12/Umbra.html 可以类比 x32 ABI (指针范围压缩为4GB, 因为大部分单线程不会超过这个数, 就像 int 在x64和x86默认宽度相同)…
#rust #go #algorithm UmbraString 是对带长度指针(py.bytes, rs.slice) 的(免链接inline),而 SwissTable 是对Hash预分组查表的免链接!
我们知道,Java 存在(装箱boxing) 一说,也就是int,char等字面值的堆分配 (这是泛型擦除 vs template<>化新建的编译期细节),因此JDK8用class Stream.OfInt{}缓解了reified泛型的缺失
那么,(拆箱unwrap) 其实就是在值的内存上内联,像C++栈分配。 除了禁止null,拆箱在运行时有省内存GC、免链接、CPU快取等好处
这么好的算法升级,实现难吗?
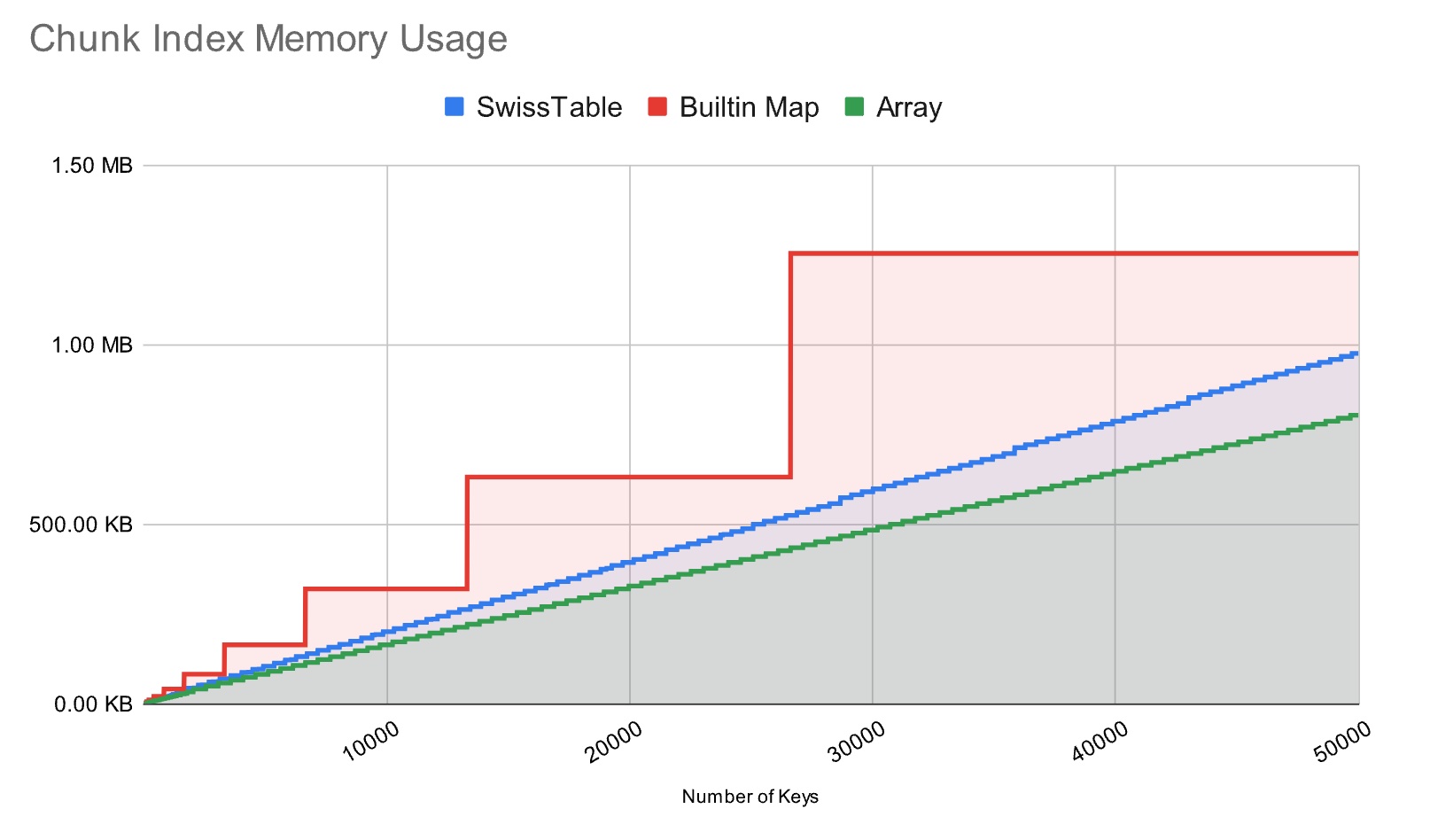
map采用预分组查表,哈希值冲突(哈希值一样)的键值对会被放在一个桶中,查找桶=hash(key) mod size,然后再遍历桶中Eq的元素,这里有通过额外的bit做更快的检查。 #dalao https://gufeijun.com/post/map/1/
一旦map的负载因子(键值对个数与桶个数比值)过大,查找需要线性遍历多个桶,性能会退化为O(n),所以这种实现需要更频繁地对桶进行扩容,保持负载因子在低水平。
拉链法是大多数编程语言的选择,每个桶后面跟上一个链表,所有的同义词通过链表中节点形式串联
SwissTable 使用一种称为Closed Hashing的方案。每一个哈希值都会有一个自己的槽位(slot),槽的选择是由哈希值决定,从hash(key) mod size的槽开始查找,一直往后查找到空的槽(null)
SwissTable也是和内建的map一样采用短哈希(8b hash),以便支持快速检查,但是它的元数据却是独立存储的,和哈希值存储分开。
把hash值分为高7位和低57位:
高7位用在control byte中解决hash冲突 (这7位只是以很低的代价,减少了90%键与键的比较。)
低57位是slot的指针,每个slot对应一个1一个byte的控制字节。
Control byte的高1位用于表示状态 0xFF=undef, 0x80=null值 ,低7位用于存储hashcode的高7位
128bit对齐的连续8字节的control byte称为一个group
使用这种方式,可以通过SIMD 指令并行比较 16 个短哈希,比 std::unord_set 快两倍 (map只是K:V元组按K搜的set)
Flat hashtable不仅仅只是CPU CACHE友好,这样的结构配合原子操作,相信很容易做出一个并发版本的hash table
我们知道,Java 存在(装箱boxing) 一说,也就是int,char等字面值的堆分配 (这是泛型擦除 vs template<>化新建的编译期细节),因此JDK8用class Stream.OfInt{}缓解了reified泛型的缺失
那么,(拆箱unwrap) 其实就是在值的内存上内联,像C++栈分配。 除了禁止null,拆箱在运行时有省内存GC、免链接、CPU快取等好处
这么好的算法升级,实现难吗?
map采用预分组查表,哈希值冲突(哈希值一样)的键值对会被放在一个桶中,查找桶=hash(key) mod size,然后再遍历桶中Eq的元素,这里有通过额外的bit做更快的检查。 #dalao https://gufeijun.com/post/map/1/
一旦map的负载因子(键值对个数与桶个数比值)过大,查找需要线性遍历多个桶,性能会退化为O(n),所以这种实现需要更频繁地对桶进行扩容,保持负载因子在低水平。
拉链法是大多数编程语言的选择,每个桶后面跟上一个链表,所有的同义词通过链表中节点形式串联
SwissTable 使用一种称为Closed Hashing的方案。每一个哈希值都会有一个自己的槽位(slot),槽的选择是由哈希值决定,从hash(key) mod size的槽开始查找,一直往后查找到空的槽(null)
SwissTable也是和内建的map一样采用短哈希(8b hash),以便支持快速检查,但是它的元数据却是独立存储的,和哈希值存储分开。
把hash值分为高7位和低57位:
高7位用在control byte中解决hash冲突 (这7位只是以很低的代价,减少了90%键与键的比较。)
低57位是slot的指针,每个slot对应一个1一个byte的控制字节。
Control byte的高1位用于表示状态 0xFF=undef, 0x80=null值 ,低7位用于存储hashcode的高7位
128bit对齐的连续8字节的control byte称为一个group
使用这种方式,可以通过SIMD 指令并行比较 16 个短哈希,比 std::unord_set 快两倍 (map只是K:V元组按K搜的set)
Flat hashtable不仅仅只是CPU CACHE友好,这样的结构配合原子操作,相信很容易做出一个并发版本的hash table
Gufeijun
一个系列彻底搞懂map(一):hash表 - 辜飞俊的博客
duangsuse::Echo
#rust #go #algorithm UmbraString 是对带长度指针(py.bytes, rs.slice) 的(免链接inline),而 SwissTable 是对Hash预分组查表的免链接! 我们知道,Java 存在(装箱boxing) 一说,也就是int,char等字面值的堆分配 (这是泛型擦除 vs template<>化新建的编译期细节),因此JDK8用class Stream.OfInt{}缓解了reified泛型的缺失 那么,(拆箱unwrap) 其实就是在值的内存上内联,像C++栈分配。…
#algorithm #防自学 🤓 让我来示范一下怎么概括算法思路
要介绍的是在stdlib里,用于组织集合类、JSON的3个重要结构:
它们对各种app和其他算法性能效能的重要性,好比json(cbor.me)之于REST、zip之于jvm和pip。 因为是涉及SDK实现的内容,也主观评价下语法设计
下面用胖指针(x64上void*是8b, 胖指16b)、链表、快速排序简单的实现3者 #code
https://colobu.com/2023/06/29/replace-std-map-faster/chunk-index-memory.jpg
用例和 #haskell #code https://gist.github.com/duangsuse/26b80c39e1d8f7549b9cf244d8de1ce4
题外话,闭包值和 x.interface_cast(T) 的双指针&dyn 随结构传入T的函数表
UmbraString 和上文Str{n,buf}胖指针一样是16b,但它的.n和jvm一样只寻址[4b:int]的长度,其后最少随4b的免链接char 用于比大小
对于n>12的buf,剩下8b换成指针,指针的高2位用于标记GC信息: 持久pin、临时ref、用后即焚val
很明显!这是一种灵活利用了x86内存布局的b"length"实现,和x32压缩指针一样,节省了sort解指针的时间
SwissTable 是对Hash预分组查表的免链接。我们知道, dict/HashMap/lua.Table 这样的{K:V, K1:V} 单映射常被用于查找和缓存,在C++里更是会区分 unordered_map, rb_map(以排序radix,SortedSet,而非hash作为预分组线索)
它的最简实现是lisp里的链表
即便8b hashCode,也是一定会冲突的,哪怕是int.hash也会因 buck[hash%nBuck] 有限而退化为线性查找,负载因子(kv/nBuck 过大),这时就要扩容。Go的扩容基于一种空间换时间的优化(图1, 为了减少求余数的冲突,除数都会采用2的指数)
扩容后的冲突集,可以用链表(UnionFind)或数组(slot), 从那往右找
Swiss 更聪明,它对每slot对应1b的元数据,最高位0x80=无效项 ,0xFF=null结尾 ,低7位用于存储hashcode的高7位,这么摘要是为了SIMD128bit 1次对比8个KV
不仅仅只是CPU CACHE友好,这样的结构配合原子操作,相信很容易做出一个并发版本的hash table
快速求余(x,n)= uint32((uint64(x) * uint64(n)) >> 32)
#dalao https://init.blog/fast-newton-sqrt/
最近的一种基于partition(区间而非idx)的快排也很有趣: less than pivotL | between pivotL and pivotR | greater than pivotR
要介绍的是在stdlib里,用于组织集合类、JSON的3个重要结构:
b"ytesPtr", {K:V}, sorted([0 2 1])=[0 1 2]它们对各种app和其他算法性能效能的重要性,好比json(cbor.me)之于REST、zip之于jvm和pip。 因为是涉及SDK实现的内容,也主观评价下语法设计
下面用胖指针(x64上void*是8b, 胖指16b)、链表、快速排序简单的实现3者 #code
#define Col(...) typedef struct{__VA_ARGS__;} T;
#define T Str
Col(size_t n; char* buf) //C的类型本应默认为指针, *胖指针,像kt那样对Int等类型免链接化。简洁的UNIX里,Type* 快成为public那样的形式主义啦
#define T_Link(E,T) struct T{E x; T* xs;}
T_Link(int,Nums) //template<T> 允许类型推理,即一致化调用和返回处的<T>。可怜gcc/clang无论对宏还是模板的报错皆如内容农场,不具有可读性https://colobu.com/2023/06/29/replace-std-map-faster/chunk-index-memory.jpg
用例和 #haskell #code https://gist.github.com/duangsuse/26b80c39e1d8f7549b9cf244d8de1ce4
题外话,闭包值和 x.interface_cast(T) 的双指针&dyn 随结构传入T的函数表
qsort :: (Ord a) => [a] -> [a]
qsort [] = []
qsort (x:xs) =
let smallerSorted = qsort [a | a <- xs, a <= x]
largerSorted = qsort [a | a <- xs, a > x]
in smallerSorted ++ [x] ++ largerSorted
UmbraString 和上文Str{n,buf}胖指针一样是16b,但它的.n和jvm一样只寻址[4b:int]的长度,其后最少随4b的免链接char 用于比大小
对于n>12的buf,剩下8b换成指针,指针的高2位用于标记GC信息: 持久pin、临时ref、用后即焚val
很明显!这是一种灵活利用了x86内存布局的b"length"实现,和x32压缩指针一样,节省了sort解指针的时间
SwissTable 是对Hash预分组查表的免链接。我们知道, dict/HashMap/lua.Table 这样的{K:V, K1:V} 单映射常被用于查找和缓存,在C++里更是会区分 unordered_map, rb_map(以排序radix,SortedSet,而非hash作为预分组线索)
它的最简实现是lisp里的链表
T_Link(struct {int A,B;}, int_LnKV) :没留任何线索来减枝!即便8b hashCode,也是一定会冲突的,哪怕是int.hash也会因 buck[hash%nBuck] 有限而退化为线性查找,负载因子(kv/nBuck 过大),这时就要扩容。Go的扩容基于一种空间换时间的优化(图1, 为了减少求余数的冲突,除数都会采用2的指数)
扩容后的冲突集,可以用链表(UnionFind)或数组(slot), 从那往右找
Swiss 更聪明,它对每slot对应1b的元数据,最高位0x80=无效项 ,0xFF=null结尾 ,低7位用于存储hashcode的高7位,这么摘要是为了SIMD128bit 1次对比8个KV
不仅仅只是CPU CACHE友好,这样的结构配合原子操作,相信很容易做出一个并发版本的hash table
快速求余(x,n)= uint32((uint64(x) * uint64(n)) >> 32)
#dalao https://init.blog/fast-newton-sqrt/
float InvSqrt(float x) {
float xhalf = 0.5f*x;
int i = *(int*)&x;
i = 0x5f3759df - (i >> 1);
x = *(float*)&i;
x = x*(1.5f - xhalf*x*x);
return x;
}最近的一种基于partition(区间而非idx)的快排也很有趣: less than pivotL | between pivotL and pivotR | greater than pivotR
{kind=link}
https://liyucang-git.github.io/2021/02/12/前端包管理器对比-npm-yarn-和-pnpm/#:~:text=2、大量重复的包被安装,文件体积超级大。比如跟%20foo%20同级目录下有一个baz,两者都依赖于同一个版本的lodash,那么%20lodash%20会分别在两者的%20node_modules%20中被安装,也就是重复安装;
#js #meme #algorithm PNPM.io 的前世, 幽默脚本小子: 依赖图(dependency graph #tool) 都没学过,只知道递归下载(wget -r)树 😅
一个 ln -s 文件树+硬链接=图DAG; =NodeGraph滤镜=let赋值复用=.. 的道理都没学过, 居然敢做软件架构 ……
Python 当初是没有 malloc 或 GC 的,全靠Rc,和当今一堆编译期运行时的过度工程相比。简直是一股清流。
#js #meme #algorithm PNPM.io 的前世, 幽默脚本小子: 依赖图(dependency graph #tool) 都没学过,只知道递归下载(wget -r)树 😅
一个 ln -s 文件树+硬链接=图DAG; =NodeGraph滤镜=let赋值复用=.. 的道理都没学过, 居然敢做软件架构 ……
Python 当初是没有 malloc 或 GC 的,全靠Rc,和当今一堆编译期运行时的过度工程相比。简直是一股清流。
liyucang-git.github.io
前端包管理器对比 npm、yarn 和 pnpm - 李宇仓 | Li Yucang
李宇仓的博客
#linux #algorithm 嵌入式 链表
在内核中,我们不能用定长数组(pid这些东西是经常增删、完全遍历的),首尾相接 双向链表 + inline优化 是Linus的选择
IntList* 只能保存int, 但嵌入式链表能包含多个子类,都可以遍历查表,再以 container_of 解指针。 Lua 以这种做法实现 int tag; union{}
这和C的
https://www.zhihu.com/question/30262900/answer/34688512238
#冷知识 py.list tuple js.array cpp.vector gl.vec3(ndarray) .. 「茴的四种写法」是哪来的?
英语上只有 list 和 matrix ,LISP 把(只读)链表称为 list,C因长度固定用了 array
C++ 因长度动态且非链表,用了 std::vec .. list 则意味着 linked
tuple 则是 namedtuple 结构体的前身
在内核中,我们不能用定长数组(pid这些东西是经常增删、完全遍历的),首尾相接 双向链表 + inline优化 是Linus的选择
IntList* 只能保存int, 但嵌入式链表能包含多个子类,都可以遍历查表,再以 container_of 解指针。 Lua 以这种做法实现 int tag; union{}
这和C的
struct T{ char tail []} 很像,被用于保存 len+ptr\0 字符串https://www.zhihu.com/question/30262900/answer/34688512238
#冷知识 py.list tuple js.array cpp.vector gl.vec3(ndarray) .. 「茴的四种写法」是哪来的?
英语上只有 list 和 matrix ,LISP 把(只读)链表称为 list,C因长度固定用了 array
C++ 因长度动态且非链表,用了 std::vec .. list 则意味着 linked
tuple 则是 namedtuple 结构体的前身
xinqiu.gitbooks.io
双向链表 · Linux Insides中文
#algorithm Tex 使用的 text-wrap: pretty 算法,和默认的wrap差在会主动缩减行长,来为尾行凑字数,偶尔看起来更整齐
https://blog.ppresume.com/posts/zh-cn/on-typesetting-engines#:~:text=并未实现%20Knuth%20Plass
https://output.jsbin.com/hopejeb
https://github.com/mnater/Hyphenopoly?tab=readme-ov-file#automatic-hyphenation
https://opentype.js.org/ <<SVG 字形的滤镜
哈哈,Web怎么可能没实现呢? MathJax.org 都比Tex好用的多了。Tex不仅慢还难调 https://github.com/robertknight/tex-linebreak
和这个 #tool https://latex.js.org/playground.html 一比差好远,简直不比 PostScript 美观
https://blog.ppresume.com/posts/zh-cn/on-typesetting-engines#:~:text=并未实现%20Knuth%20Plass
https://output.jsbin.com/hopejeb
[...new Intl.Segmenter('zh', {granularity: 'word'}).segment( "hello world 你好世界")]
//Intl.Hyphenation 是 granularity: 'wordroot'https://github.com/mnater/Hyphenopoly?tab=readme-ov-file#automatic-hyphenation
https://opentype.js.org/ <<SVG 字形的滤镜
哈哈,Web怎么可能没实现呢? MathJax.org 都比Tex好用的多了。Tex不仅慢还难调 https://github.com/robertknight/tex-linebreak
和这个 #tool https://latex.js.org/playground.html 一比差好远,简直不比 PostScript 美观
Ppresume
排版引擎纵谈:程序员的视角
Pros and cons for different typesetting engines from engineering perspective and why PPReseume chose LaTeX.
#c #algorithm #bin 位运算 优化跳空格
glibc strlen.c 默认实现 «Bit Twiddling Hacks>
btw. “减法时间比位运算长”的问题,时间的最小粒度是CPU周期。只需要看这个指令需要几个周期就行了,ALU都是1cycle,比从内存读取快了几个数量级
向量实现手写AVX,然而再怎么玩都不如string类型直接存好长度快。
glibc strlen.c 默认实现 «Bit Twiddling Hacks>
btw. “减法时间比位运算长”的问题,时间的最小粒度是CPU周期。只需要看这个指令需要几个周期就行了,ALU都是1cycle,比从内存读取快了几个数量级
bool has_zero_byte(uint32_t v)
{
const uint32_t himagic = 0x80808080;
const uint32_t lomagic = 0x01010101;
return ((v - lomagic) & ~v & himagic) != 0;
}
向量实现手写AVX,然而再怎么玩都不如string类型直接存好长度快。
duangsuse::Echo
#cg #code 国产剧《点燃我,温暖你》/110w 里面的一个桥段,天才程序员男主李峋期中考试中完成的爱心代码 效仿评论区就自己写了个…… 另外GL里字体/for循环是较难的 float heart(vec2 P) { float t= mix(.3,.8, mod(iTime,1.2)),//心跳 r=pow(P.y-pow(abs(P.x),t), 2.)+pow(P.x,2.) -1.;//灰度函数 return r<.3? mix(1.,4.,-r) : r; //黑心换白心…
This media is not supported in your browser
VIEW IN TELEGRAM
纯sdf, 顺手移植了一个给 numpy+tty
花了1小时吧:
cv2.open(mode=HSL亮L).降采样为(stty size) mix(256色到" .*#"色) .追加\n列 .光标到(0,0)print
我用了比yes命令内存效能低的join'',但也不打紧
#performance fwrite() 就像CtrlV,要打'y'*500你是粘贴五百次还是多复制、缓冲?
把rows('<U1').buf分隔复制到 int8(w*h+1h),按帧yield给/dev/pts/0管道更省
若一开始就 open(w+1'\n',h) 就是SIMD汇编一样快了,当然,0copy 不如 diff update ,之前逐px试过确实。
有时看 #bilibili 编程圈,感觉是「时无英雄竖子成名」,比如那个开「知识」星球赚百w的鱼皮
像🐴一龙那样因追求,最终有钱的少,更多技术人有比钱更高的需求。
在老中这很搞笑很虚伪吧? #statement
不过我是很清楚,B站上真大佬有 #algorithm #OI 的一大堆, @从0开始数 就是,
其实是学生们只喜欢看抽象的「编程娱乐直播」 JavaWeb PHP 什么的曾经很赚钱的 🥰 甚至不一定要有代码,可敬抄嘛,
那个微信首屏卡成 🐴,音视频通话按钮都混乱,拿AI做避讳和偷窥这样的脏事, 还一堆人 pixel perfect 地致敬张小龙,其实就是这种大厂功利心态,
何同学呢? 作为主=5G的第二个受益者 ,其实不配说热爱 奋斗 赛博丁真
花了1小时吧:
cv2.open(mode=HSL亮L).降采样为(stty size) mix(256色到" .*#"色) .追加\n列 .光标到(0,0)print
我用了比yes命令内存效能低的join'',但也不打紧
#performance fwrite() 就像CtrlV,要打'y'*500你是粘贴五百次还是多复制、缓冲?
把rows('<U1').buf分隔复制到 int8(w*h+1h),按帧yield给/dev/pts/0管道更省
若一开始就 open(w+1'\n',h) 就是SIMD汇编一样快了,当然,0copy 不如 diff update ,之前逐px试过确实。
有时看 #bilibili 编程圈,感觉是「时无英雄竖子成名」,比如那个开「知识」星球赚百w的鱼皮
像🐴一龙那样因追求,最终有钱的少,更多技术人有比钱更高的需求。
在老中这很搞笑很虚伪吧? #statement
不过我是很清楚,B站上真大佬有 #algorithm #OI 的一大堆, @从0开始数 就是,
其实是学生们只喜欢看抽象的「编程娱乐直播」 JavaWeb PHP 什么的曾经很赚钱的 🥰 甚至不一定要有代码,可敬抄嘛,
那个微信首屏卡成 🐴,音视频通话按钮都混乱,拿AI做避讳和偷窥这样的脏事, 还一堆人 pixel perfect 地致敬张小龙,其实就是这种大厂功利心态,
何同学呢? 作为主=5G的第二个受益者 ,其实不配说热爱 奋斗 赛博丁真
duangsuse::Echo
噢对了,之前做一个这个 https://duangsuse.github.io/mkey/making_reco/#sorts3 #algorithm #visualize
https://t.me/hyi0618/5036?comment=6393
#algorithm #visualize
>poetry pip 用 #Rust rewrite #statement
这种类似 docker/chroot 的东西其实C API调用都很少,最复杂的部分反而可能是 CLI getopt 和配置文件模板,根本不需要rust..
rust 的意义就是让我们觉得很Niubility,很neo,但写出来的东西,其实不比拿zsh或py胶水几个包快。 printf "\e[33m黄字" 这样的功能强吗? ruby也能做啊,写那么麻烦没意义,其实就是上情绪价值。
像 Vue 最近那个 oxc ESTree 用Rust才有点意义,因为它背后有一个更简洁通用的数据模型,类似与 tree-sitter vs ANTLR/PEGgyjs.org ,这才是革命性的
#algorithm #visualize
>poetry pip 用 #Rust rewrite #statement
这种类似 docker/chroot 的东西其实C API调用都很少,最复杂的部分反而可能是 CLI getopt 和配置文件模板,根本不需要rust..
rust 的意义就是让我们觉得很Niubility,很neo,但写出来的东西,其实不比拿zsh或py胶水几个包快。 printf "\e[33m黄字" 这样的功能强吗? ruby也能做啊,写那么麻烦没意义,其实就是上情绪价值。
像 Vue 最近那个 oxc ESTree 用Rust才有点意义,因为它背后有一个更简洁通用的数据模型,类似与 tree-sitter vs ANTLR/PEGgyjs.org ,这才是革命性的
Telegram
duangsuse in Channel comments
找了俩更好玩的
https://gallery.selfboot.cn/en/algorithms/dijkstra
https://clementmihailescu.github.io/Pathfinding-Visualizer/#
其实Web上算法+UIUX双修的大佬很多, 一定要找visualized
https://gallery.selfboot.cn/en/algorithms/dijkstra
https://clementmihailescu.github.io/Pathfinding-Visualizer/#
其实Web上算法+UIUX双修的大佬很多, 一定要找visualized
#py #code #learn 协程
https://gist.github.com/BeautyyuYanli/0a6891d8959bcf06b5cd2e5bd30ef3d1
……利用了py本身就支持 yield&return 而已。 其实和 https://www.ruanyifeng.com/blog/2015/05/co.html 一模一样,加了个 await(1)不回调优化
如果编译器愿意,它也可以在有 await() 时自动把def变async,甚至用类型隐藏await,只是这样就不一致了
*仅仅对pyjs有效,因为它们的参数数量是可修改的, jvm的固定为class{}里的方法签名
besides, await 'val' 在js里本身就是可行且优化的
把 yield* fRED() 当await也是co.js的发明
https://gist.github.com/duangsuse/3674d747ec5ea8ca510add26295e5a7d
>没错,async就是允许你setTimeout(retAddr,0s)并return的空函数,你们叫它yield或await。
这样一切回调地狱都能用 await new Promise(ret=> timers.push(1s,ret)) 解决,不是吗?
能捕获当前语句/算式号为变量的(ret)叫函续。等返回值卡线程,if分1段执行不完,就必须用 div(10,5,ok), div.bind(10,0)(ok,err) 的回调链表代替调用-返回栈
#algorithm 以前的
https://gist.github.com/BeautyyuYanli/0a6891d8959bcf06b5cd2e5bd30ef3d1
……利用了py本身就支持 yield&return 而已。 其实和 https://www.ruanyifeng.com/blog/2015/05/co.html 一模一样,加了个 await(1)不回调优化
如果编译器愿意,它也可以在有 await() 时自动把def变async,甚至用类型隐藏await,只是这样就不一致了
*仅仅对pyjs有效,因为它们的参数数量是可修改的, jvm的固定为class{}里的方法签名
besides, await 'val' 在js里本身就是可行且优化的
把 yield* fRED() 当await也是co.js的发明
https://gist.github.com/duangsuse/3674d747ec5ea8ca510add26295e5a7d
>没错,async就是允许你setTimeout(retAddr,0s)并return的空函数,你们叫它yield或await。
这样一切回调地狱都能用 await new Promise(ret=> timers.push(1s,ret)) 解决,不是吗?
能捕获当前语句/算式号为变量的(ret)叫函续。等返回值卡线程,if分1段执行不完,就必须用 div(10,5,ok), div.bind(10,0)(ok,err) 的回调链表代替调用-返回栈
#algorithm 以前的
from itertools import accumulate,product as X
def generate(op, init, stop):
acc = init
while acc != stop: yield acc; acc = op(acc)
list(accumulate("是这样呢", lambda s,x: s+x))
_ == ['是', '是这', '是这样', '是这样呢']
list(generate(lambda s: s[1:], "不可能啊", ""))
_ == ['不可能啊', '可能啊', '能啊', '啊']
xz= X(*(s.split() for s in ["可乐 雪碧", "好喝 难喝"] ))
[*xz] #二层for, O(nn)
[('可乐', '好喝'), ('可乐', '难喝'), ('雪碧', '好喝'), ('雪碧', '难喝')]
permutations "abc" -> ["abc", "acb", "bac", "bca", "cab", "cba"]
//a是空数组,把每元素x放在a[i], i<n(a) 上,剩下的i同理
permut=a=> n(a)? a.flatMap((x,i)=> permut(a.toSpliced(i,1)).map(X=>[x, ...X]) ) : [[]]
n=a=>a.length
Gist
cwaitable.py
GitHub Gist: instantly share code, notes, and snippets.
duangsuse::Echo
#py #code #learn 协程 https://gist.github.com/BeautyyuYanli/0a6891d8959bcf06b5cd2e5bd30ef3d1 ……利用了py本身就支持 yield&return 而已。 其实和 https://www.ruanyifeng.com/blog/2015/05/co.html 一模一样,加了个 await(1)不回调优化 如果编译器愿意,它也可以在有 await() 时自动把def变async,甚至用类型隐藏await,只是这样就不一致了…
#algorithm #visualize 前缀树 https://youtu.be/af1oqpnH1vA?t=361 🔎"懂KMP"
KMP 是为了减少如 substr.index(s,S)==2 ; s="adad_ads" S="ad_ad" 里判定 for i in S: s[pos+i]==S[i] 移动对齐的次数,避免低效的pos++
如果"ada"\="ad_" 而pos+=3,一定会漏判a"d_ads",需要有办法不跳过'a',这就是next.'_'=2 = (n"ad" - failgo['_'])
S="ABCDAB" 时,failgo[后俩AB]=[1 2] ,我们就能记住AB已读,goto回"CDAB"继续。 O(nm) 变成了 O(n)! failgo是只依赖S的共同前后缀长度生成的,您可以了解分治三兄贵: DP动态规划 、递归、伪递归aka递推
这是一种阉割版Trie+failgoto,也叫AC自动机,是DFA确定性状态机,使用树状数组的压缩思路(图即KV, V=Int=K)。Regex实现的一步就是NFA图压缩到DFA
今天用于中英分词的就是双数组字典树版DA-Trie。 编译原理里LL(1)也很在乎是否右侧最多有peek s[i+1], s[i++]
但没必要实现这些比goto更难看的算法。不妨试一下后缀树如何生成
>我发现"adad_ads" 这个例子举的不如"ABCDAB" …… 当时心里知道KMP是为回文pattern优化的,但回文不朗朗上口,竟然想了老半天。
99% 算法题解从不考虑 demo input 是否既揭示边界条件+算法特性,又朗朗上口。 我非常注重,总是白费许多时间……
KMP 是为了减少如 substr.index(s,S)==2 ; s="adad_ads" S="ad_ad" 里判定 for i in S: s[pos+i]==S[i] 移动对齐的次数,避免低效的pos++
如果"ada"\="ad_" 而pos+=3,一定会漏判a"d_ads",需要有办法不跳过'a',这就是next.'_'=2 = (n"ad" - failgo['_'])
S="ABCDAB" 时,failgo[后俩AB]=[1 2] ,我们就能记住AB已读,goto回"CDAB"继续。 O(nm) 变成了 O(n)! failgo是只依赖S的共同前后缀长度生成的,您可以了解分治三兄贵: DP动态规划 、递归、伪递归aka递推
这是一种阉割版Trie+failgoto,也叫AC自动机,是DFA确定性状态机,使用树状数组的压缩思路(图即KV, V=Int=K)。Regex实现的一步就是NFA图压缩到DFA
今天用于中英分词的就是双数组字典树版DA-Trie。 编译原理里LL(1)也很在乎是否右侧最多有peek s[i+1], s[i++]
但没必要实现这些比goto更难看的算法。不妨试一下后缀树如何生成
echo p/{ub,r/{ot,iv}}n=a=>a.length; trieS=d=>(k,v)=>{
let pre=(a,b)=>{let i=0,N=Math.min(n(a),n(b));for(;i<N;i++)if(a[i]!==b[i])return i; return N},
p=d,K,p1 ,S//AME part
fndK:for(;;){for([K,p1]of p)if(S=pre(K,k))
if(p1.set&&S==n(K) ){p=p1,k=k.slice(S);continue fndK} else {
p.set(K.slice(0,S), p.delete(K)&&new Map([[k.slice(S),v],[K.slice(S),p1]]) /*长k短'' 新先*/);return}
p.set(k,v) ;break}
}
k=trieS(ks=new Map)
`pub priv prot`.split(/ /).forEach(k) >我发现"adad_ads" 这个例子举的不如"ABCDAB" …… 当时心里知道KMP是为回文pattern优化的,但回文不朗朗上口,竟然想了老半天。
99% 算法题解从不考虑 demo input 是否既揭示边界条件+算法特性,又朗朗上口。 我非常注重,总是白费许多时间……
YouTube
最浅显易懂的 KMP 算法讲解
duangsuse::Echo
https://github.com/mirtlecn/chaizi-re?tab=readme-ov-file#汉字拆字字典修订 #school https://zh.wikipedia.org/wiki/中日韓統一表意文字#漢字等同 🙄 作为一个「语言人」,我非常遗憾, 关于中文的一切开发 (Unicode CJK, IDS统一表意..),竟然与大陆本土无缘,且完全没有如 jpdb.io 般惠及中文学习。 只有拼音和五笔,这些为机器服务的层是中国人为营利想出来, 为学习者的,是完全没有。 乃至二简字,都是好大喜功不成气候…
#blog https://dieken.github.io/posts/chinese-input-methods/
>输入法界,俗称码圈,在 2024 年的今天,毫无疑问是个小众圈子
(1) 做码人,或称算码人、字圈,喜欢研究汉字拆分和字根的键盘布局,(2) 跟打人,或称赛文人、赛圈,喜欢竞速跟打,以手快为荣,可谓武玩,(3) 其它人,菜鸟龙套捧哏普通用户,可谓文玩。三个小圈子之间以及内部少不了日常逗乐拌嘴,反正有人的地方就有江湖,很感慨的是,八九十年代的万「码」奔腾到如今的万「码」齐喑、十「码」互踢
>形码可以打整句吗?习惯了拼音整句后,突然发现形码要人肉分词,可真是「一夜回到解放前」,搞不好就碰到打词打空了,非常恶心,因此码圈大佬们的建议是要么记住小词库谨慎打词,要么索性只打单字,极端点就是不要简码只打全码单字。
>岁寒输入法:就我而言,我做的第一版输入法,全世界都没人会用,只有我一个人会用;我做的第二版输入法,别人也会用了,但是没有人用;我做的第三版输入法,终于有人愿意用了。
在设计完岁寒输入法的布局和输入规则后,我惊奇地发现岁寒输入法呈现出一种非常重要的特性——输入声韵的无二义性。简单地说,就是任何一条滑行路径都明确地指向某一个声母或者韵母,不会存在歧义,不依赖于已经输入的信息,经常用于处理无声母的拼音。「xian」不可能是「xi'an」,「gang」不可能是「gan'g」,这个特性是全拼和双拼输入法都不具备的。
ps. 智能选词使用的 #algorithm HMM 比DNN难懂不少,用途也窄,不知道现在的智能拼音都在用什么算法,还是马尔可夫链?
https://shurufa.app/ chaifen.app
https://dieken.github.io/posts/some-words-about-chinese-input-method-circle/
>输入法界,俗称码圈,在 2024 年的今天,毫无疑问是个小众圈子
(1) 做码人,或称算码人、字圈,喜欢研究汉字拆分和字根的键盘布局,(2) 跟打人,或称赛文人、赛圈,喜欢竞速跟打,以手快为荣,可谓武玩,(3) 其它人,菜鸟龙套捧哏普通用户,可谓文玩。三个小圈子之间以及内部少不了日常逗乐拌嘴,反正有人的地方就有江湖,很感慨的是,八九十年代的万「码」奔腾到如今的万「码」齐喑、十「码」互踢
>形码可以打整句吗?习惯了拼音整句后,突然发现形码要人肉分词,可真是「一夜回到解放前」,搞不好就碰到打词打空了,非常恶心,因此码圈大佬们的建议是要么记住小词库谨慎打词,要么索性只打单字,极端点就是不要简码只打全码单字。
>岁寒输入法:就我而言,我做的第一版输入法,全世界都没人会用,只有我一个人会用;我做的第二版输入法,别人也会用了,但是没有人用;我做的第三版输入法,终于有人愿意用了。
在设计完岁寒输入法的布局和输入规则后,我惊奇地发现岁寒输入法呈现出一种非常重要的特性——输入声韵的无二义性。简单地说,就是任何一条滑行路径都明确地指向某一个声母或者韵母,不会存在歧义,不依赖于已经输入的信息,经常用于处理无声母的拼音。「xian」不可能是「xi'an」,「gang」不可能是「gan'g」,这个特性是全拼和双拼输入法都不具备的。
ps. 智能选词使用的 #algorithm HMM 比DNN难懂不少,用途也窄,不知道现在的智能拼音都在用什么算法,还是马尔可夫链?
https://shurufa.app/ chaifen.app
https://dieken.github.io/posts/some-words-about-chinese-input-method-circle/
dieken.github.io
中文输入法
duangsuse::Echo
#english #learn 区块链到底是什么? 我在基于base,ton,bsc和sol扫链网站的CORS API为新框架设计「零门槛捐款码和收据」 stdpay服务时,向小白解释了USDC为何能被作为资产持有。 在公私钥证明后,crypto做了什么来保证严苛的1增1减? 区块有多大,挖矿又是什么? 有人买账的废纸,就不是智商税吗? 在简短的介绍后,你会发现EVM与SOL是比SWIFT更透明、稳健、高效的结算公证工具,只是因为反洗钱的要求被排挤,它们在一个没有CRINK的世界能极大降低金融成本,并且提升支付与娱乐体验。…
https://www.bilibili.com/video/BV11x411i72w?p=1 13:29 #algorithm #math #经济 🌚
如果早几年让我来解释就好了。 其实以上说法也没有说明在51%的节点都在做假账后,BTC如何保证自身的公信力,以及PK/SK的密码学基础如何证明「你是你」「记账者是诚实的」、「叔块」和硬分叉是什么、智能合约脚本对于著作权、税收等社会制度的安全模拟, 更别说关于「元宇宙」似乎有无尽的话题可聊-- 当然这不会改变我认为Metaverse还不如大型页游和3A乃至AI值钱的认识。
但是关于比特币,最重要的事情不是密码学、共识、去中心化这些宏大叙事,而是价值的来源,或者说锚定物,也同时是钱的去向:市场。
比方说, bitcoin.org 将PoW解释为分散风险,雨露均沾的记账权共识,但这无法解释高算力为何就是诚信—— 「卖云盘」「公证费」很好地解释了为何BTC不会受到51%攻击和DDoS这样的威胁,因为人性。
在会为了钱出售尊严,无底线跪舔羊毛月、出售代孕等服务的经济体里,钱总会比其他地方来的有用;不过,这只是对市场的短期影响。有恒产者有恒心,通过血汗红利让生活变好的这种搔操作,究竟会带来繁荣,还是破坏了人的价值,透支了经济持续性-直到失去二十年, 没有人能简单的通过钱的数字得到答案。
数字是正确的,逻辑是永恒的。
钱是一种世界通用的语言。「不懂外语的人也不会懂自己的母语——歌德」, 一种货物的绰号可不是它自己发明的。 汇率、长期持有、换手率和利率, 这些不能被随便捏造的数据才是做我们选择的风向标。
如果早几年让我来解释就好了。 其实以上说法也没有说明在51%的节点都在做假账后,BTC如何保证自身的公信力,以及PK/SK的密码学基础如何证明「你是你」「记账者是诚实的」、「叔块」和硬分叉是什么、智能合约脚本对于著作权、税收等社会制度的安全模拟, 更别说关于「元宇宙」似乎有无尽的话题可聊-- 当然这不会改变我认为Metaverse还不如大型页游和3A乃至AI值钱的认识。
但是关于比特币,最重要的事情不是密码学、共识、去中心化这些宏大叙事,而是价值的来源,或者说锚定物,也同时是钱的去向:市场。
比方说, bitcoin.org 将PoW解释为分散风险,雨露均沾的记账权共识,但这无法解释高算力为何就是诚信—— 「卖云盘」「公证费」很好地解释了为何BTC不会受到51%攻击和DDoS这样的威胁,因为人性。
在会为了钱出售尊严,无底线跪舔羊毛月、出售代孕等服务的经济体里,钱总会比其他地方来的有用;不过,这只是对市场的短期影响。有恒产者有恒心,通过血汗红利让生活变好的这种搔操作,究竟会带来繁荣,还是破坏了人的价值,透支了经济持续性-直到失去二十年, 没有人能简单的通过钱的数字得到答案。
数字是正确的,逻辑是永恒的。
钱是一种世界通用的语言。「不懂外语的人也不会懂自己的母语——歌德」, 一种货物的绰号可不是它自己发明的。 汇率、长期持有、换手率和利率, 这些不能被随便捏造的数据才是做我们选择的风向标。
Bilibili
【官方双语】想知道比特币(和其他加密货币)的原理吗?_哔哩哔哩_bilibili
体验发明自己的加密货币的过程,从中理解比特币协议和区块链等等的含义。更多信息请看下方评论翻译:ZSC 校对:FPS罗兹 时间轴&后期:Solara570Ever wonder how Bitcoin (and other cryptocurrencies) actually work?https://youtu.be/bBC-nXj3Ng4, 视频播放量 348032、弹幕量 2061、点赞数 8349、投硬币枚数 10265、收藏人数 19304、转发人数 10082, 视频作者 3Blue1Brown…
#rust #algorithm #ml
https://go.dev/blog/swisstable
https://tangdh.life/posts/interesting/double-free/
分布式文件系统Fire-Flyer File System (3FS) ,专为解决AI训练和推理工作负载挑战而设计。它利用现代SSD和RDMA网络
https://github.com/deepseek-ai/smallpond
https://go.dev/blog/swisstable
https://tangdh.life/posts/interesting/double-free/
分布式文件系统Fire-Flyer File System (3FS) ,专为解决AI训练和推理工作负载挑战而设计。它利用现代SSD和RDMA网络
https://github.com/deepseek-ai/smallpond
go.dev
Faster Go maps with Swiss Tables - The Go Programming Language
Go 1.24 improves map performance with a brand new map implementation
duangsuse::Echo
duangsuse: #经济 #life 银行 中国特有非竞争性资源也要小道消息 关于墙内资产,你们有没有什么好理由减持国内银行的存款(债权) 按道理,医疗买车这些大件是不可能限制你转账的。 银联互转也不可能限制 但是继续把钱给银行,仍然会觉得不安全 只是怎么解释呢 duangsuse: 安全是取决于人民币能购买商品和服务的范围 如果范围内商品的性价比越来越低,包括利率这些不够硬的话,又不让你自由买换,其实也不算安全。 如果从「世界工厂」式微,楼市上下游爆雷,各种科技狠活的角度,只持有本币也是不安全的…
#learn #recommend 币圈导论🌚
Web3 是改良自比特币的「产权分享网络」
常用提供商是 TOBASC (TON Opt/APT BASE BSC)
常用资产是 $USDT $EURC $USDC $PAXG $AAVE $STETH
Web3和DeFi,相较于传统银行/金融业,有四大优势:
好换好用 竞价打折 公报私账 12Key压缩黄金
- P2P银行,换汇 贷款(BTC TVL锁仓质押) 无需通过任何银行RM和柜台,无差别对待。零手续费,无存贷中介。NFT©️版权免佣金拍卖,商家户公司户随便开。
- Web3网费,是全球节点竞价排名后的最低价,经常是1分钱。 暴打SWIFT和银行垄断的利率汇率差、ATM手续费
- Web3测试网,有国家级TPS「网速」,支持高频交易、量化投资,适合监管财报、审计,也支持个人一键开小号。
- 对EVM银行卡而言,记住12个词=持有账户和黄金。遍及四海,穿越年代,您的财富,不用请求任何机构、过问任何网点。 稳定币对您失信,就是对整个网络失信,而数学不可能失信。就这么简单。 #看多
区块链是种只读数据库,即便网点能由任何人接入,也不怕攻击:厚账本优先 + 1层账1层难,使得不可信的机构们也无法修改既成数字、做假钞、收铸币税。
DeFi 还天然支持现货期货、合约杠杆,除了追涨杀跌,追跌杀涨也低费。
合约是期权的降风险版:
假设小明看空小丽的房子,他借来房子卖掉(有保证金的) ,等三年房价跌后,抄底还给小丽, 价格差-利息即收益
杠杆额度被称为「保证金」。 质押还可以为涨幅和转账费都很高的BTC提供U本位流动性,变现花
永续合约即便你赌错了方向,反手还能回血,盈亏很灵活。
这就是赌场的用户体验,以及向赌狗放债的红利。
即便有新技术的好处,
为了解决消费重放、51%和刷单攻击、撤单攻击,各大交易所、背后的Web3使用区块链集群,基于烂大街的「去中心化、貔貅共识、零知识组网、可编程合约」。
也就是实现「分布式只增数据库」「分时垄断动账公证」。 而为了防范刷流水,1层账本就是1层难度,像链条那样。
- 区块链的聊天记录里包含由A君私钥签名、群发的转账小票,就像 Tx(A, B=0xCAFE, nCoin=1,dt=Now)。 不对等加解密是加密货币的防伪证明,就像https握手,apk签名
- 厚账本优先。记账即印钞,所以,既没人能故意拉黑A君来冻结存款,也没人能超发货币、撤回到旧账本:做假账和印假钞一样难! 这就是挖矿共识,BTC ETH 分别采用 PoW PoS (work/stake) 奖励公证者
- 转账公证者,保底也要收取Web3网费(BNB,ETH..)。 越老的链收支相抵越亏,因此TRC,ERC的公链费已不适合日常交易。
如何防止「厚账本」是刷单伪造的呢?厚度必须有难度。
#algorithm
5min左右结算一个账单区块,通过集群内hashRate难度自平衡,要求其 head=hardwork(校验码(body+旧head))
难度链条。这就卡死了诈骗节点: 撤回转账需要单机打败全网51%的显卡或选民投票。旧head校验旧body,越远越难改!
具体来说BTC链上, verify(hardwork(txLogs+nOnce, rate)) 这一对函数是hash后缀碰撞,以rate降低难度。
密码学里,hash反函数的最优解,是不断查找nOnce以符合不必含rate个前导零的SHA值,这是GPU计算的强项。
--
那么,区块链比SWIFT大数据库优势何在?
就像微软更新站 vs [IPFS星际文件系统]!新网点可以由任何人-包括微软加入,EVM账目也能在月度年度解决分叉,达到最终一致,原理和git一样。
网点故障(CEX下线、冷钱包闪退)不影响Web3的效率、费率和可用性, 这种公信力,不依靠任何公司盈利政策、形式主义黑箱、个人隐私的过度登记, 只靠开源的分布式算法即可保持财富。
FAQ: bitcoin.org/zh_CN/how-it-works
ref:https://t.me/dsuse/20481
https://www.youtube.com/watch?v=g_fSistU3MQ 李永乐 关于SHA256(SHA256(bill)) 的解释
Web3 是改良自比特币的「产权分享网络」
常用提供商是 TOBASC (TON Opt/APT BASE BSC)
常用资产是 $USDT $EURC $USDC $PAXG $AAVE $STETH
Web3和DeFi,相较于传统银行/金融业,有四大优势:
好换好用 竞价打折 公报私账 12Key压缩黄金
- P2P银行,换汇 贷款(BTC TVL锁仓质押) 无需通过任何银行RM和柜台,无差别对待。零手续费,无存贷中介。NFT©️版权免佣金拍卖,商家户公司户随便开。
- Web3网费,是全球节点竞价排名后的最低价,经常是1分钱。 暴打SWIFT和银行垄断的利率汇率差、ATM手续费
- Web3测试网,有国家级TPS「网速」,支持高频交易、量化投资,适合监管财报、审计,也支持个人一键开小号。
- 对EVM银行卡而言,记住12个词=持有账户和黄金。遍及四海,穿越年代,您的财富,不用请求任何机构、过问任何网点。 稳定币对您失信,就是对整个网络失信,而数学不可能失信。就这么简单。 #看多
区块链是种只读数据库,即便网点能由任何人接入,也不怕攻击:厚账本优先 + 1层账1层难,使得不可信的机构们也无法修改既成数字、做假钞、收铸币税。
DeFi 还天然支持现货期货、合约杠杆,除了追涨杀跌,追跌杀涨也低费。
合约是期权的降风险版:
假设小明看空小丽的房子,他借来房子卖掉(有保证金的) ,等三年房价跌后,抄底还给小丽, 价格差-利息即收益
杠杆额度被称为「保证金」。 质押还可以为涨幅和转账费都很高的BTC提供U本位流动性,变现花
永续合约即便你赌错了方向,反手还能回血,盈亏很灵活。
这就是赌场的用户体验,以及向赌狗放债的红利。
即便有新技术的好处,
为了解决消费重放、51%和刷单攻击、撤单攻击,各大交易所、背后的Web3使用区块链集群,基于烂大街的「去中心化、貔貅共识、零知识组网、可编程合约」。
也就是实现「分布式只增数据库」「分时垄断动账公证」。 而为了防范刷流水,1层账本就是1层难度,像链条那样。
- 区块链的聊天记录里包含由A君私钥签名、群发的转账小票,就像 Tx(A, B=0xCAFE, nCoin=1,dt=Now)。 不对等加解密是加密货币的防伪证明,就像https握手,apk签名
- 厚账本优先。记账即印钞,所以,既没人能故意拉黑A君来冻结存款,也没人能超发货币、撤回到旧账本:做假账和印假钞一样难! 这就是挖矿共识,BTC ETH 分别采用 PoW PoS (work/stake) 奖励公证者
- 转账公证者,保底也要收取Web3网费(BNB,ETH..)。 越老的链收支相抵越亏,因此TRC,ERC的公链费已不适合日常交易。
如何防止「厚账本」是刷单伪造的呢?厚度必须有难度。
#algorithm
5min左右结算一个账单区块,通过集群内hashRate难度自平衡,要求其 head=hardwork(校验码(body+旧head))
难度链条。这就卡死了诈骗节点: 撤回转账需要单机打败全网51%的显卡或选民投票。旧head校验旧body,越远越难改!
具体来说BTC链上, verify(hardwork(txLogs+nOnce, rate)) 这一对函数是hash后缀碰撞,以rate降低难度。
密码学里,hash反函数的最优解,是不断查找nOnce以符合不必含rate个前导零的SHA值,这是GPU计算的强项。
--
那么,区块链比SWIFT大数据库优势何在?
就像微软更新站 vs [IPFS星际文件系统]!新网点可以由任何人-包括微软加入,EVM账目也能在月度年度解决分叉,达到最终一致,原理和git一样。
网点故障(CEX下线、冷钱包闪退)不影响Web3的效率、费率和可用性, 这种公信力,不依靠任何公司盈利政策、形式主义黑箱、个人隐私的过度登记, 只靠开源的分布式算法即可保持财富。
FAQ: bitcoin.org/zh_CN/how-it-works
ref:https://t.me/dsuse/20481
https://www.youtube.com/watch?v=g_fSistU3MQ 李永乐 关于SHA256(SHA256(bill)) 的解释
duangsuse::Echo
在拜占庭环境下
ps. 回看起来,这个术语老奇怪了。 其实就是说「资本主义价值」需要中介来公证嘛
难道你在生活中,就从来没担心过淘宝外,某种虚拟商品会在付款后,撤单拉黑吗? 公信力需要被强者(机构、资本家)或制度塑造,这需要假设外部环境吗?
《版主担保制》 《合作ytb担保制》《第三方好评成交率》 就是网上交易的几种形式
我不知道为什么需要这么一个术语,实际上BT和Tor网络也存在蜜罐, 他们没有这个术语仅仅是它们的设计缺陷。默认Web是可信防伪的,本身就很天真。
能分辨善恶并不该很麻烦, 在抓奸细对暗号上任何黑帮的头目都不会输于程序员,这一步在「碳基文明」里就是个小哈基米
YouTu.be/e9KVmyI1eCg
😅😅 又是一个故作深沉的 #algorithm
怎么说呢?science is elegant。
区块链PoW/PoS 、AI 的DNN高维梯度下降拟合、diffusion,其实都是本领域好懂好用的算法,至少有直观的讲法。
输入法候选词常用的HMM,已经完全输给了DNN,但是想学会Markov chain 可是图论,DNN却只要你懂导数和函数回归,再让numpy做线性代数就够了……
殊途同归, 李老师讲了半天的原始解法, 将军放一个「不对等加密」公钥出来签名验证就行了,总不能连将军是谁都不知道吧?
Paxos使用的BPFT,根据AI所说,是一种阶级分明的,通过奔走相告打乒乓,实现1/3容错的小范围共识算法,因为拉群乒乓会造成流量雪崩。
这是介于信任中央和不信任广播之间的验证方法,直观感觉就是两边不是人,既没效率也不民主,要靠善意主节点列表进网,就像DHT。
能产生商业价值的,从来都是简单的原理。 人的智慧可不是专门用来玩文字游戏的
难道你在生活中,就从来没担心过淘宝外,某种虚拟商品会在付款后,撤单拉黑吗? 公信力需要被强者(机构、资本家)或制度塑造,这需要假设外部环境吗?
《版主担保制》 《合作ytb担保制》《第三方好评成交率》 就是网上交易的几种形式
我不知道为什么需要这么一个术语,实际上BT和Tor网络也存在蜜罐, 他们没有这个术语仅仅是它们的设计缺陷。默认Web是可信防伪的,本身就很天真。
能分辨善恶并不该很麻烦, 在抓奸细对暗号上任何黑帮的头目都不会输于程序员,这一步在「碳基文明」里就是个小哈基米
YouTu.be/e9KVmyI1eCg
😅😅 又是一个故作深沉的 #algorithm
怎么说呢?science is elegant。
区块链PoW/PoS 、AI 的DNN高维梯度下降拟合、diffusion,其实都是本领域好懂好用的算法,至少有直观的讲法。
输入法候选词常用的HMM,已经完全输给了DNN,但是想学会Markov chain 可是图论,DNN却只要你懂导数和函数回归,再让numpy做线性代数就够了……
殊途同归, 李老师讲了半天的原始解法, 将军放一个「不对等加密」公钥出来签名验证就行了,总不能连将军是谁都不知道吧?
Paxos使用的BPFT,根据AI所说,是一种阶级分明的,通过奔走相告打乒乓,实现1/3容错的小范围共识算法,因为拉群乒乓会造成流量雪崩。
这是介于信任中央和不信任广播之间的验证方法,直观感觉就是两边不是人,既没效率也不民主,要靠善意主节点列表进网,就像DHT。
能产生商业价值的,从来都是简单的原理。 人的智慧可不是专门用来玩文字游戏的
#algorithm #rust #math
https://blog.mwish.me/2025/04/19/Notes-on-Integer-Float-Operations/
https://gregoryszorc.com/blog/2024/03/17/my-shifting-open-source-priorities/
https://blog.mwish.me/2025/04/19/Notes-on-Integer-Float-Operations/
https://gregoryszorc.com/blog/2024/03/17/my-shifting-open-source-priorities/
风空之岛
Notes on Integer/Float Operations
一些整数和浮点数的基础,最近碰到一些坑,顺手整理一下。有的章节写的不太细是因为手头上没碰到直接的坑,所以只收集材料,不过多展开。碰到再补上。 整数的表示https://blog.mwish.me/2020/09/19/Integer-Endian/ 本节图片来自:https://cs61c.org/sp25/lectures/lec02/ 对于无符号整数 (unsigned integer),所有