
🎓 Сегодня пятница, а пятница — это почти выходной, когда уже не хочется заниматься делами. Лучше это время потратить с пользой и заняться самообразованием. А в этом нам может помочь набор TUI программ для обучения в консоли.
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
Запускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
Ответ правильный и мне предлагают ещё вариант:
С sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
Я ошибся и срезал только 4 строки. Поправился:
Утилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
Тоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
#обучение #terminal #bash
⇨ https://github.com/learnbyexample/TUI-apps
Их тут несколько, и я начал с того, что мне показалось наиболее полезным - Linux CLI Text Processing Exercises. Это простенькая оболочка с вопросами на тему обработки текстовых файлов консольными утилитами в Linux. Поставил по инструкции:
# python3 -m venv textual_apps# cd textual_apps# source bin/activate# pip install cliexercises# cliexercisesЗапускаю, первый же вопрос:
❓Display the first 5 lines for the input file ip.txt.
Для меня это просто. Отвечаю:
head -n 5 ip.txtОтвет правильный и мне предлагают ещё вариант:
sed '5q' ip.txtС sed часто работаю, но не знал, что с его помощью можно так просто вывести первые 5 строк. Записал сразу себе в шпаргалку.
Следующий вопрос посложнее, но тоже в целом простой:
❓Display except the first 5 lines for the input blocks.txt.
Выводим всё, кроме первых 5-ти строк:
tail -n +5 blocks.txt Я ошибся и срезал только 4 строки. Поправился:
tail -n +6 blocks.txtУтилита подтвердила, что мой вариант правильный. Честно говоря, я думал, что вряд ли в ней будет вариант с tail, поэтому взял именно его. Но она в виде правильных вариантов предложила как раз с tail и ещё с sed:
sed '1,5d' blocks.txtТоже сразу записал в шпаргалку. Решил ещё проверить вариант с awk. Я думал, что именно он и будет предложен, так как первый пришёл в голову:
awk 'NR>5' blocks.txt Тоже помечен, как правильный. Возможно программа проверяет вывод, используя все доступные системные утилиты, так что правильным будет даже тот вариант, что отсутствует в её базе.
Таких заданий тут много. Конкретно в этой программе 68. Проходить увлекательно и полезно, так что рекомендую для самообразования и пополнения своей коллекции bash костылей. Можно в исходниках сразу всё посмотреть, но не рекомендую. Так ничего не запомнится. А если самому подумать, то лучше отложится в голове.
Вот примерчик из того, что будет ближе к концу:
❓From blocks.txt extract only the 3rd block. A line containing %=%= determines the start of a block.
То есть файл разделён на блоки, а разделитель блоков - символы
%=%=, надо вывести 3-й блок. Для меня это уже сложно, чтобы что-то сходу придумать. Вот решение:awk '$0 == \"%=%=\"{c++} c==3' blocks.txt#обучение #terminal #bash
{kind=link}
У меня в управлении много различных серверов. Я обычно не заморачивался с типом файловых систем. Выбирал то, что сервер ставит по умолчанию. Для серверов общего назначения особо нет разницы, будет это XFS или EXT4. А выбор обычно из них стоит. RPM дистрибутивы используют по умолчанию XFS, а DEB — EXT4.
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
Она вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
Лично для меня имеют значения следующие принципиальные отличия:
1️⃣ XFS можно расширить, но нельзя уменьшить. EXT4 уменьшать можно. На практике это очень редко надо, но разница налицо.
2️⃣ У EXT4 по умолчанию создаётся не очень много inodes. Я нередко упирался в стандартное ограничение. В XFS их по умолчанию очень много, так как используется динамическое выделение. С проблемой нехватки не сталкивался ни разу.
3️⃣ EXT4 по умолчанию резервирует 5% свободного места на диске. Это можно изменить при желании. XFS если что-то и резервирует, то в разы меньше и это не настраивается.
❗️У меня была заметка про отличия ext4 и xfs. Можете почитать, кому интересно. Рассказать я хотел не об этом. Нередко нужно узнать, какая файловая система используется, особенно, когда закончилось свободное место. Для этого использую команду mount без ключей:
# mountОна вываливает трудночитаемую лапшу в терминал, где трудно быстро найти корневой или какой-то другой раздел. Конкретный раздел ещё можно грепнуть, а вот корень никак. Я всё думал, как же сделать, чтобы было удобно. Просмотрел все ключи mount или возможности обработки вывода. Оказалось, нужно было подойти с другой стороны. У утилиты
df есть нужный ключ:# df -TFilesystem Type 1K-blocks Used Available Use% Mounted onudev devtmpfs 1988408 0 1988408 0% /devtmpfs tmpfs 401244 392 400852 1% /run/dev/sda2 ext4 19948144 2548048 16361456 14% /tmpfs tmpfs 2006220 0 2006220 0% /dev/shmtmpfs tmpfs 5120 0 5120 0% /run/lock/dev/sda1 vfat 523244 5928 517316 2% /boot/efitmpfs tmpfs 401244 0 401244 0% /run/user/0И не надо мучать mount. У df вывод отформатирован, сразу всё видно.
#bash #terminal
{kind=link}
В комментариях к заметке, где я рассказывал про неудобочитаемый вывод mount один человек посоветовал утилиту column, про которую я раньше вообще не слышал и не видел, чтобы ей пользовались. Не зря говорят: "Век живи, век учись". Ведение канала и сайта очень развивает. Иногда, когда пишу новый текст по трудной теме, чувствую, как шестерёнки в голове скрипят и приходится напрягаться. Это реально развивает мозг и поддерживает его в тонусе.
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
Получается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
Получается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
Возвращаясь к column. Эта простая утилита делает одну вещь: выстраивает данные в удобочитаемые таблицы, используя различные разделители. В общем случае разделителем считается пробел, но его через ключ можно переназначить.
Структурируем вывод mount:
# mount | column -tПолучается очень аккуратно и читаемо. Ничего придумывать не надо, чтобы преобразовать вывод.
А вот пример column, но с заменой разделителя на двоеточие:
# column -s ":" -t /etc/passwdПолучается удобочитаемое представление. Из него можно без особых проблем вывести любой столбец через awk. Как по мне, так это самый простой способ, который сразу приходит в голову и не надо думать, как тут лучше выделить какую-то фразу. Выводим только имена пользователей:
# column -s ":" -t /etc/passwd | awk '{print $1}'Каждый пользователь в отдельной строке. Удобно сформировать массив и передать куда-то на обработку.
Утилита полезная и удобная. Главное теперь про неё не забыть, чтобы применить в нужный момент.
#bash #terminal
{kind=link}
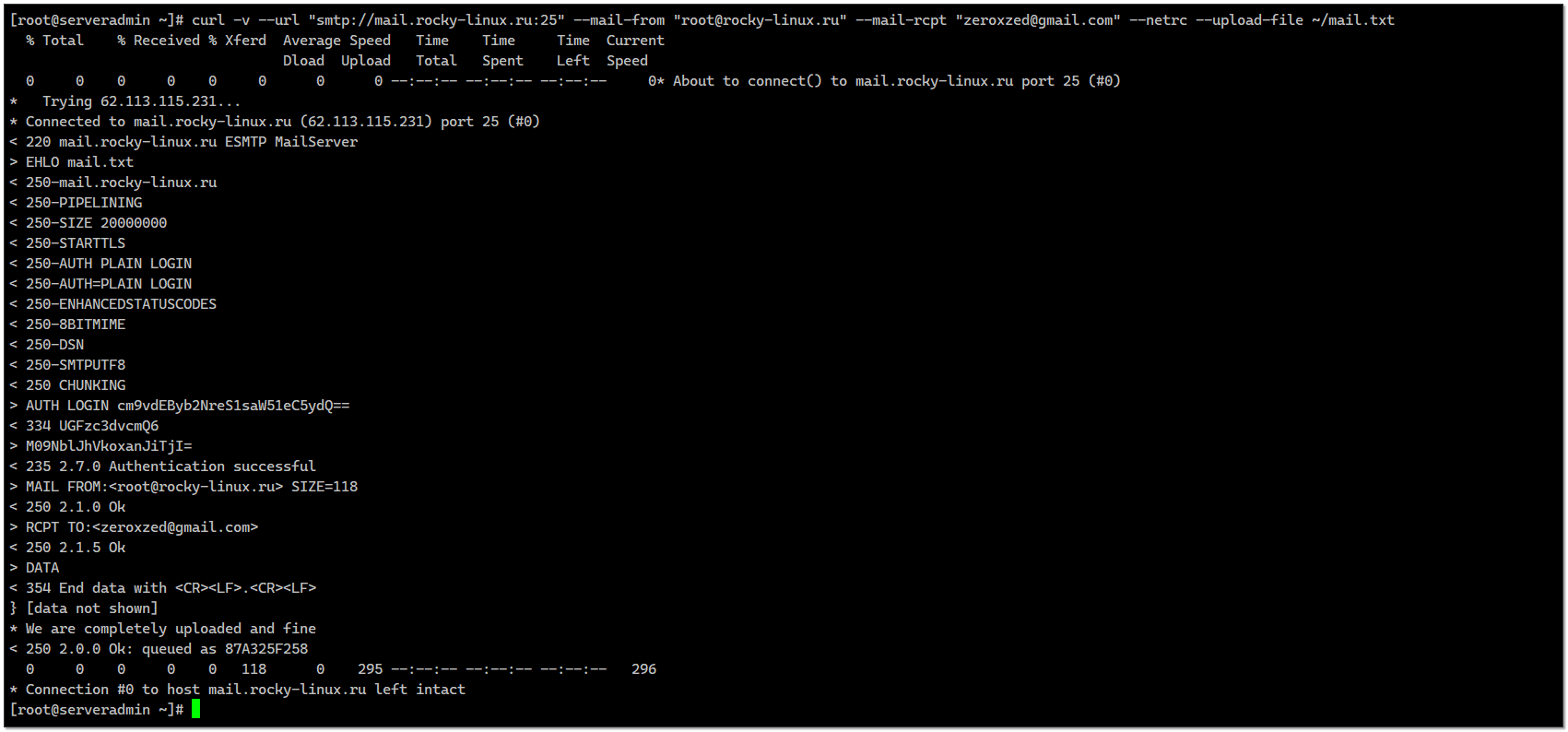
Вы знали, что curl умеет отправлять почту через внешние smtp серверы? Я в целом знаю, что curl умеет всё, что только можно придумать про передачу данных, но конкретно вопрос не прорабатывал, хотя вскользь уже упоминал об этом, но в рамках решения другой задачи, поэтому особо не погружался в тему. Поэтому для отправки почты из консоли всё время ставлю какую-то дополнительную утилиту, типа mailx. На самом деле это не обязательно. Сейчас покажу, как отправлять почту через curl, не светя пароль в консоли.
Сразу ссылка на документацию. Оправляем почту полностью через ключи curl:
Содержимое mail.txt примерно следующее:
Причём с помощью curl очень удобно управлять адресом отправителя. В mail.txt его любой указать можно, а не тот, от которого идёт отправка. Впрочем, как и другие заголовки.
Не очень хорошая идея светить почтовый пароль в консоли. Можно его спрятать в
Каждый сервер на новой строке. Удобно, если используется отправка через несколько разных серверов. В соответствии с указанным smtp сервером берутся настройки учётной записи из файла
Так как мы используем ключ
Если используется шифрованное соединение и порт 465, то достаточно просто указать адрес сервера в виде
Для того, чтобы явно указать HELO / EHLO при отправке, добавьте его через слеш после адреса сервера. Примерно так:
#terminal #curl
Сразу ссылка на документацию. Оправляем почту полностью через ключи curl:
# curl -v --url "smtp://mail.server.ru:25" --mail-from "root@server.ru" --mail-rcpt "user@gmail.com" --user 'root@server.ru:password123' --upload-file ~/mail.txtСодержимое mail.txt примерно следующее:
From: "Vladimir" <root@server.ru>To: "User" <user@gmail.com>Subject: Mail from curlHello! How are you?Причём с помощью curl очень удобно управлять адресом отправителя. В mail.txt его любой указать можно, а не тот, от которого идёт отправка. Впрочем, как и другие заголовки.
Не очень хорошая идея светить почтовый пароль в консоли. Можно его спрятать в
.netrc файл. Для этого его надо создать в домашней директории пользователя ~/.netrc. Содержание такое:machine mail.server.ru login root@server.ru password password123machine mail.server02.ru login user@server02.ru password password12345Каждый сервер на новой строке. Удобно, если используется отправка через несколько разных серверов. В соответствии с указанным smtp сервером берутся настройки учётной записи из файла
.netrc. Команда на отправку с использованием .netrc будет такая:# curl -v --url "smtp://mail.server.ru:25" --mail-from "root@server.ru" --mail-rcpt "user@gmail.com" --netrc --upload-file ~/mail.txtТак как мы используем ключ
-v, в консоли видим весь лог общения с почтовым сервером, что может быть удобно для отладки. Если не указывать никаких ключей для TLS, то будет использоваться нешифрованное соединение. Если нужно только шифрованное, то можно добавить ключ --ssl-reqd, а если хотите чтобы при поддержке сервером шифрование использовалось, а если поддержки нет, то нет, тогда добавьте ключ --ssl. Если используется шифрованное соединение и порт 465, то достаточно просто указать адрес сервера в виде
smtps://mail.server.ru. Отдельно указывать порт и ключи для ssl не обязательно. Для того, чтобы явно указать HELO / EHLO при отправке, добавьте его через слеш после адреса сервера. Примерно так:
smtp://mail.server.ru/client_helo.server.ru#terminal #curl
{kind=link}
Когда готовил материал по отправке email сообщений через curl, подумал, он же наверное и читать умеет. И не ошибся. Curl реально умеет читать, и не только, почту по imap. Это открывает очень широкие возможности по мониторингу почтовых серверов с помощью утилиты.
Меня не раз спрашивали, как удобнее всего настроить мониторинг почтовых сообщений в ящике, чтобы приходили уведомления при получении письма определённого содержания. Я обычно советовал либо на самом почтовом сервере прямо в ящике анализировать текст писем, если это возможно. Либо использовать какие-то программы типа fetchmail, imapsync или обычные почтовые клиенты. И уже в них как-то анализировать письма.
Но с curl всё получается намного проще. Она много чего умеет. Расскажу по порядку. Сразу важная сноска, которая сильно затормозила меня в этом вопросе. Когда будете пробовать, возьмите свежую версию curl. Более старые некоторые команды для imap не поддерживают. Я сначала наткнулся на это в старом сервере Centos 7. Потом уже перешёл на современный Debian и там всё получилось.
Сразу перенесём логин с паролем в отдельный файл
Проверяем количество сообщений в imap папке INBOX:
Получили число 405. Посмотрим, сколько из них непрочитанных:
147 непрочитанных сообщений. Думаю, идею вы поняли. С помощью curl можно напрямую передавать серверу команды imap.
Смотрим список директорий в ящике:
Или просто:
Ищем в ящике письма с темой test:
или так:
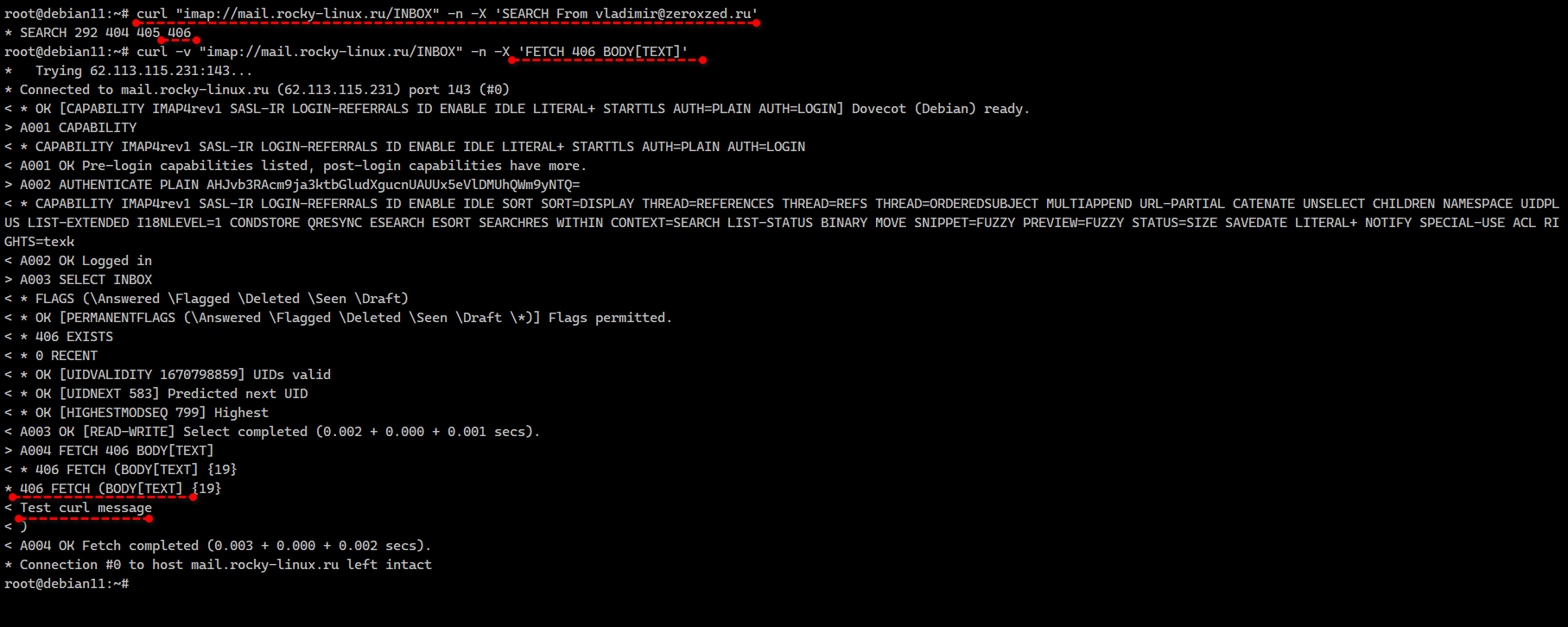
Сообщения от определённого адресата:
Получили UIDs писем. Смотрим содержание письма с конкретным UID. Для этого надо добавить ключ
или так:
И так далее. Письмо после проверки можно пометить прочтённым, переместить в другую директорию, удалить. Чтобы осмысленно дёргать imap сервер, достаточно посмотреть описание протокола. Информация по нему легко находится в поиске.
Команды imap рассмотрены в упоминаемом недавно курсе по сетям от Созыкина Андрея. Вот конкретный урок: ▶️ Протокол IMAP. Вообще, было интересно во всём этом разобраться. Если надо будет настроить мониторинг очередного почтового сервера, попробую что-то применить с помощью curl.
Первое, что приходит в голову в плане мониторинга - отправлять письмо с меткой времени в теле, а потом забирать его и анализировать эту метку. Если метка старая, значит письма не ходят. Это надёжнее, чем просто проверять статус служб и доступность портов. Тут и smtp, и imap сервер проверяются. И реализуется полностью с помощью curl и zabbix.
#curl #terminal
Меня не раз спрашивали, как удобнее всего настроить мониторинг почтовых сообщений в ящике, чтобы приходили уведомления при получении письма определённого содержания. Я обычно советовал либо на самом почтовом сервере прямо в ящике анализировать текст писем, если это возможно. Либо использовать какие-то программы типа fetchmail, imapsync или обычные почтовые клиенты. И уже в них как-то анализировать письма.
Но с curl всё получается намного проще. Она много чего умеет. Расскажу по порядку. Сразу важная сноска, которая сильно затормозила меня в этом вопросе. Когда будете пробовать, возьмите свежую версию curl. Более старые некоторые команды для imap не поддерживают. Я сначала наткнулся на это в старом сервере Centos 7. Потом уже перешёл на современный Debian и там всё получилось.
Сразу перенесём логин с паролем в отдельный файл
~/.netrc:machine mail.server.tld login username password supersecretpwПроверяем количество сообщений в imap папке INBOX:
# curl "imap:/mail.server.tld" -n -X 'STATUS INBOX (MESSAGES)'* STATUS INBOX (MESSAGES 405)Получили число 405. Посмотрим, сколько из них непрочитанных:
# curl "imap://mail.server.tld" -n -X 'STATUS INBOX (UNSEEN)'* STATUS INBOX (UNSEEN 147)147 непрочитанных сообщений. Думаю, идею вы поняли. С помощью curl можно напрямую передавать серверу команды imap.
Смотрим список директорий в ящике:
# curl "imap://mail.server.tld" -n -X 'LIST "" "*"'* LIST (\HasNoChildren \Marked \Trash) "/" Trash* LIST (\HasNoChildren \UnMarked \Junk) "/" Junk* LIST (\HasNoChildren \UnMarked \Drafts) "/" Drafts* LIST (\HasNoChildren \Sent) "/" Sent* LIST (\HasChildren) "/" INBOXИли просто:
# curl "imap://mail.server.tld" -nИщем в ящике письма с темой test:
# curl "imap://mail.server.tld/INBOX?SUBJECT%20test" -n* SEARCH 62 404 405 406или так:
# curl "imap://mail.server.tld/INBOX" -n -X 'SEARCH HEADER Subject test'Сообщения от определённого адресата:
# curl "imap://mail.server.tld/INBOX" -n -X 'SEARCH From vladimir@zeroxzed.ru'* SEARCH 292 404 405 406Получили UIDs писем. Смотрим содержание письма с конкретным UID. Для этого надо добавить ключ
-v, так как оно передаётся в отладочной информации, как и все остальные ответы сервера:# curl -v "imap://mail.server.tld/INBOX" -n -X 'FETCH 406 BODY[TEXT]'или так:
# curl -v "imap://mail.server.tld/INBOX;UID=406/;BODY=TEXT" -nИ так далее. Письмо после проверки можно пометить прочтённым, переместить в другую директорию, удалить. Чтобы осмысленно дёргать imap сервер, достаточно посмотреть описание протокола. Информация по нему легко находится в поиске.
Команды imap рассмотрены в упоминаемом недавно курсе по сетям от Созыкина Андрея. Вот конкретный урок: ▶️ Протокол IMAP. Вообще, было интересно во всём этом разобраться. Если надо будет настроить мониторинг очередного почтового сервера, попробую что-то применить с помощью curl.
Первое, что приходит в голову в плане мониторинга - отправлять письмо с меткой времени в теле, а потом забирать его и анализировать эту метку. Если метка старая, значит письма не ходят. Это надёжнее, чем просто проверять статус служб и доступность портов. Тут и smtp, и imap сервер проверяются. И реализуется полностью с помощью curl и zabbix.
#curl #terminal
{kind=link}
Когда на тестовом стенде разворачиваешь что-то кластерное и надо на нескольких хостах выполнить одни и те же действия, внезапно может помочь tmux. У него есть режим синхронизации панелей. С его помощью можно делать одновременно одно и то же на разных хостах.
Работает это так. Ставим tmux:
Запускаем на одном из хостов и открываем несколько панелей. По одной панели на каждый хост. Делается это с помощью комбинации клавиш
После этого в каждой панели нужно подключиться по SSH к нужному хосту. У вас получится несколько панелей, в каждой отдельная консоль от удалённого хоста. Теперь включаем режим синхронизации панелей. Нажимаем опять префикс
Включён режим синхронизации панелей. Теперь всё, что вводится в активную панель, будет автоматически выполняться во всех остальных. Отключить этот режим можно точно так же, как и включали. Просто ещё раз вводим эту же команду.
Если постоянно используете один и тот же стенд, то можно автоматизировать запуск tmux и подключение по SSH, чтобы не делать это каждый раз вручную.
#linux #terminal
Работает это так. Ставим tmux:
# apt install tmuxЗапускаем на одном из хостов и открываем несколько панелей. По одной панели на каждый хост. Делается это с помощью комбинации клавиш
CTRL-B и дальше либо %, либо ". Первое - это вертикальное разделение, второе - горизонтальное. Переключаться между панелями с помощью CTRL-B и стрелочек. В общем, всё стандартно для тех, кто работает с tmux.После этого в каждой панели нужно подключиться по SSH к нужному хосту. У вас получится несколько панелей, в каждой отдельная консоль от удалённого хоста. Теперь включаем режим синхронизации панелей. Нажимаем опять префикс
CTRL-B и дальше пишем снизу в командной строке tmux::setw synchronize-panesВключён режим синхронизации панелей. Теперь всё, что вводится в активную панель, будет автоматически выполняться во всех остальных. Отключить этот режим можно точно так же, как и включали. Просто ещё раз вводим эту же команду.
Если постоянно используете один и тот же стенд, то можно автоматизировать запуск tmux и подключение по SSH, чтобы не делать это каждый раз вручную.
#linux #terminal
{kind=link}
❓Как бы вы решили следующую задачу.
Как проверить, есть ли обращение клиента на порт TCP 22 сервера с определённого IP адреса и порта?
Это, кстати, вопрос из того же списка, что я публиковал ранее, но я решил его вынести в отдельную публикацию, потому что он объёмный, а там уже лимит сообщения был превышен.
В таком виде этот вопрос выглядит довольно просто, так как тут речь скорее всего про службу sshd, которая по умолчанию логируется практически везде. Можно просто зайти в её лог и посмотреть, какие там были подключения.
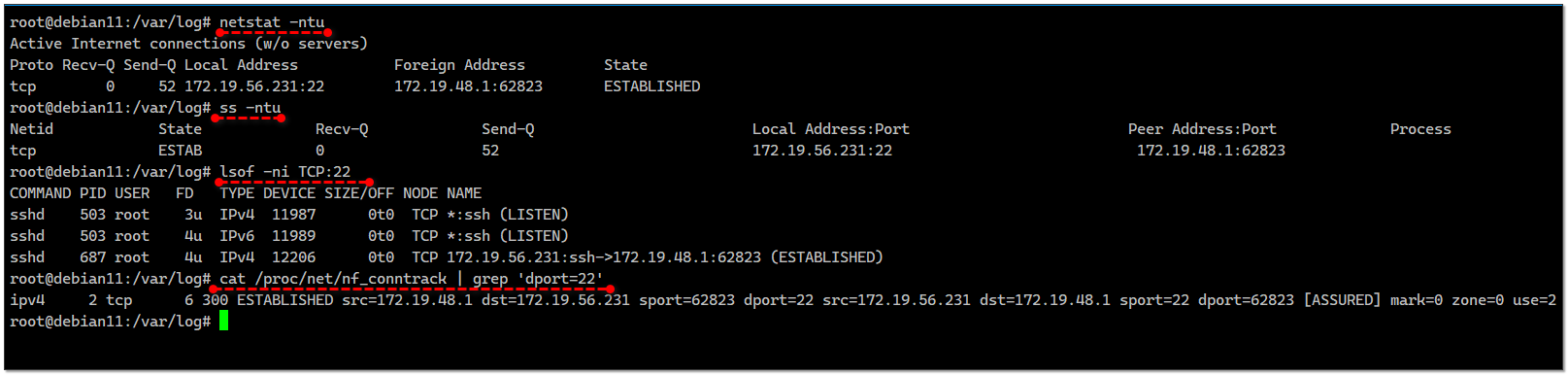
Если же речь идёт о любом другом соединении, то если оно активно, посмотреть его можно с помощью
Нужный адрес и порт можно грепнуть:
Менее очевидный вариант с помощью
Если же речь вести про прошлые, а не активные соединения, то первое, что мне приходит на ум из подручных системных средств - логирование с помощью firewall. В iptables я это делаю примерно так:
Сделал отдельную цепочку для логирования и отправил туда запись всех пакетов с портом назначения 22. Логи будут по умолчанию собираться в системном логе syslog. При желании можно в отдельный файл вынести через правило в rsyslog. Отдельную цепочку для каждой службы я обычно не делаю. Вместо этого создаю три цепочки - input, output, forward, куда добавляю правила для тех адресов и портов, которые я хочу логировать.
Это всё, что мне пришло в голову по данному вопросу. Если знаете ещё какие-то способы, то напишите. Будет интересно посмотреть.
Пока заканчивал материал, вспомнил про ещё один:
В принципе, это тот же самый ss или netstat. Они скорее всего отсюда и берут информацию.
#network #terminal
Как проверить, есть ли обращение клиента на порт TCP 22 сервера с определённого IP адреса и порта?
Это, кстати, вопрос из того же списка, что я публиковал ранее, но я решил его вынести в отдельную публикацию, потому что он объёмный, а там уже лимит сообщения был превышен.
В таком виде этот вопрос выглядит довольно просто, так как тут речь скорее всего про службу sshd, которая по умолчанию логируется практически везде. Можно просто зайти в её лог и посмотреть, какие там были подключения.
Если же речь идёт о любом другом соединении, то если оно активно, посмотреть его можно с помощью
netstat или более современного ss:# netstat -ntu# ss -ntuНужный адрес и порт можно грепнуть:
# netstat -ntu | grep ':22'Менее очевидный вариант с помощью
lsof:# lsof -ni TCP:22Если же речь вести про прошлые, а не активные соединения, то первое, что мне приходит на ум из подручных системных средств - логирование с помощью firewall. В iptables я это делаю примерно так:
# iptables -N ssh_in# iptables -A INPUT -j ssh_in# iptables -A ssh_in -j LOG --log-level info --log-prefix "--IN--SSH--"# iptables -A INPUT -p tcp --dport 22 -j ACCEPTСделал отдельную цепочку для логирования и отправил туда запись всех пакетов с портом назначения 22. Логи будут по умолчанию собираться в системном логе syslog. При желании можно в отдельный файл вынести через правило в rsyslog. Отдельную цепочку для каждой службы я обычно не делаю. Вместо этого создаю три цепочки - input, output, forward, куда добавляю правила для тех адресов и портов, которые я хочу логировать.
Это всё, что мне пришло в голову по данному вопросу. Если знаете ещё какие-то способы, то напишите. Будет интересно посмотреть.
Пока заканчивал материал, вспомнил про ещё один:
# cat /proc/net/nf_conntrack | grep 'dport=22'В принципе, это тот же самый ss или netstat. Они скорее всего отсюда и берут информацию.
#network #terminal
{kind=link}
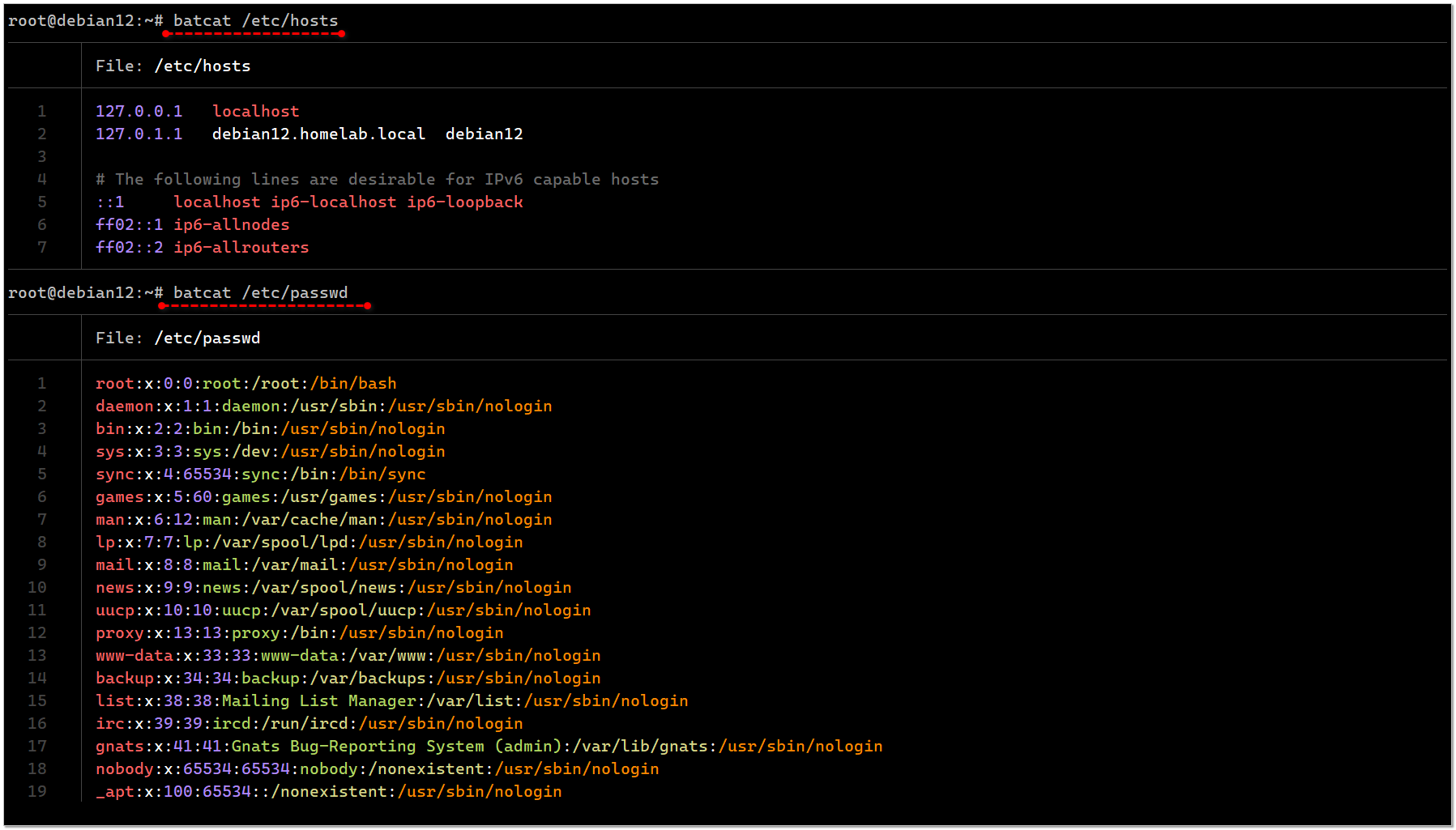
Перебираю иногда старые публикации в поисках интересной и актуальной информации. Каналу уже много лет и что-то из старого не потеряло актуальность, а аудитория с тех пор выросла в разы. Нашёл утилиту bat, как аналог cat и less одновременно.
Со времён первого упоминания утилиты bat не было в базовых репозиториях Debian (была в sid) и ставить приходилось вручную бинарник. Очевидно, что это неудобно и не располагает к регулярному использованию. С тех пор ситуация изменилась и теперь эту удобную программу можно поставить из стандартного репозитория:
В системе она почему-то появится с именем не bat, хотя оно не занято, а batcat. Её удобно использовать как для просмотра небольших файлов, так и огромных.
Короткий файл она целиком выводит в терминал с подсветкой и нумерацией строк, а длинный, который не умещается на экран, подгружает по мере прокрутки вниз, как less. То есть по сути она заменяет две эти стандартные утилиты.
Благодаря тому, что bat по умолчанию (это поведение можно изменить) не подгружает сразу весь файл, с её помощью удобно смотреть большие логи. Нумерация строк слева помогает более наглядно воспринимать длинные записи с переносом на несколько строк.
При просмотре больших файлов, горячие клавиши такие же, как у less, так что привыкать не придётся:
▪️ Стрелка вверх – перемещение на одну строку вверх
▪️ Стрелка вниз – перемещение на одну строку вниз
▪️ Пробел или PgDn – перемещение на одну страницу вниз
▪️ b или PgUp – переместить на одну страницу вверх
▪️ g – переместить в начало файла
▪️ G – переместить в конец файла
▪️ ng – перейти на n-ю строку
Ещё bat умеет:
◽хранить свои настройки в файле конфигураций
◽интегрироваться с git
◽показывать непечатаемые символы (ключ -A или настройка в конфиге)
◽интегрироваться с разными утилитами (find, tail, man и другими)
◽использовать разные темы и подсветки синтаксиса
В общем, утилита удобная. Быстро набрала популярность, кучу звёзд на github, поэтому приехала в стандартные репозитории почти всех популярных дистрибутивов Linux. И даже во FreeBSD и Windows. Не нашёл только в RHEL и его форках. Единственный заметный минус - если нужно будет скопировать какую-то строку, то будет захватываться псевдографика с нумерацией строк. Так что для просмотра удобно, для копирования длинных строк - нет.
⇨ Исходники / Описание на русском
#terminal
Со времён первого упоминания утилиты bat не было в базовых репозиториях Debian (была в sid) и ставить приходилось вручную бинарник. Очевидно, что это неудобно и не располагает к регулярному использованию. С тех пор ситуация изменилась и теперь эту удобную программу можно поставить из стандартного репозитория:
# apt install batВ системе она почему-то появится с именем не bat, хотя оно не занято, а batcat. Её удобно использовать как для просмотра небольших файлов, так и огромных.
# batcat /etc/passwd# batcat /var/log/syslogКороткий файл она целиком выводит в терминал с подсветкой и нумерацией строк, а длинный, который не умещается на экран, подгружает по мере прокрутки вниз, как less. То есть по сути она заменяет две эти стандартные утилиты.
Благодаря тому, что bat по умолчанию (это поведение можно изменить) не подгружает сразу весь файл, с её помощью удобно смотреть большие логи. Нумерация строк слева помогает более наглядно воспринимать длинные записи с переносом на несколько строк.
При просмотре больших файлов, горячие клавиши такие же, как у less, так что привыкать не придётся:
▪️ Стрелка вверх – перемещение на одну строку вверх
▪️ Стрелка вниз – перемещение на одну строку вниз
▪️ Пробел или PgDn – перемещение на одну страницу вниз
▪️ b или PgUp – переместить на одну страницу вверх
▪️ g – переместить в начало файла
▪️ G – переместить в конец файла
▪️ ng – перейти на n-ю строку
Ещё bat умеет:
◽хранить свои настройки в файле конфигураций
◽интегрироваться с git
◽показывать непечатаемые символы (ключ -A или настройка в конфиге)
◽интегрироваться с разными утилитами (find, tail, man и другими)
◽использовать разные темы и подсветки синтаксиса
В общем, утилита удобная. Быстро набрала популярность, кучу звёзд на github, поэтому приехала в стандартные репозитории почти всех популярных дистрибутивов Linux. И даже во FreeBSD и Windows. Не нашёл только в RHEL и его форках. Единственный заметный минус - если нужно будет скопировать какую-то строку, то будет захватываться псевдографика с нумерацией строк. Так что для просмотра удобно, для копирования длинных строк - нет.
⇨ Исходники / Описание на русском
#terminal
{kind=link}
Небольшая шпаргалка с командами, которая пригодится, когда у вас закончилось свободное место на дисках на сервере под управлением Linux.
🟢 Смотрим, что у нас вообще по занимаемому месту:
🟢 Если в какой-то точке монтирования занято на 100% свободное место, можно быстро посмотреть, в каких конкретно директориях оно занято. Тут может быть много разных вариантов:
Ограничиваем вывод:
Смотрим топ 20 самых больших директорий:
Смотрим топ 20 самых больших файлов:
🟢 На всякий случай проверяем inodes. Иногда свободное место заканчивается из-за них:
🟢 Если вывод du показывает, что места свободного нет, но сумма всех директорий явно меньше занимаемого места, то надо проверить удалённые файлы, которые всё ещё держит какой-то процесс. Они не видны напрямую, посмотреть их можно через lsof:
Если увидите там файлы большого размера, то посмотрите, какая служба их держит открытыми и перезапустите её. Обычно это помогает. Если служба зависла, то грохните её принудительно через
🟢 Ещё один важный момент. Может получиться так, что du оказывает, что всё место занято. В файловой системе напрямую вы не можете найти, чем оно занято, так как сумма всех файлов и директорий явно меньше, чем занято места. Среди удалённых файлов тоже ничего нет. Тогда проверяйте свои точки монтирования. Бывает так, что у вас, к примеру, скриптом монтируется сетевой диск в /mnt/backup и туда копируются бэкапы. А потом диск отключается. Если по какой-то причине в момент бэкапа диск не подмонтируется, а данные туда скопируются, то они все лягут на корневую систему, хоть и в папку /mnt/backup. Если после этого туда смонтировать сетевой диск, то ранее скопированные файлы будут не видны, но они будут занимать место. Ситуация хоть и кажется довольно редкой, но на самом деле она иногда случается и я сам был свидетелем такого. И читатели писали такие же истории. Вот одна из них. Поэтому если скриптом подключаете диски, то всегда проверяйте, успешно ли они подключились, прежде чем копировать туда файлы. Вот примеры, как это можно сделать.
#bash #terminal
🟢 Смотрим, что у нас вообще по занимаемому месту:
# df -h🟢 Если в какой-то точке монтирования занято на 100% свободное место, можно быстро посмотреть, в каких конкретно директориях оно занято. Тут может быть много разных вариантов:
# du -h -d 1 / | sort -hr# du -hs /* | sort -hrОграничиваем вывод:
# du -h -d 1 / | sort -hr | head -10Смотрим топ 20 самых больших директорий:
# du -hcx --max-depth=6 / | sort -rh | head -n 20Смотрим топ 20 самых больших файлов:
# find / -mount -ignore_readdir_race -type f -exec du -h "{}" + 2>&1 \> | sort -rh | head -n 20🟢 На всякий случай проверяем inodes. Иногда свободное место заканчивается из-за них:
# df -ih🟢 Если вывод du показывает, что места свободного нет, но сумма всех директорий явно меньше занимаемого места, то надо проверить удалённые файлы, которые всё ещё держит какой-то процесс. Они не видны напрямую, посмотреть их можно через lsof:
# lsof | grep '(deleted)'# lsof +L1Если увидите там файлы большого размера, то посмотрите, какая служба их держит открытыми и перезапустите её. Обычно это помогает. Если служба зависла, то грохните её принудительно через
kill -9 <pid>.🟢 Ещё один важный момент. Может получиться так, что du оказывает, что всё место занято. В файловой системе напрямую вы не можете найти, чем оно занято, так как сумма всех файлов и директорий явно меньше, чем занято места. Среди удалённых файлов тоже ничего нет. Тогда проверяйте свои точки монтирования. Бывает так, что у вас, к примеру, скриптом монтируется сетевой диск в /mnt/backup и туда копируются бэкапы. А потом диск отключается. Если по какой-то причине в момент бэкапа диск не подмонтируется, а данные туда скопируются, то они все лягут на корневую систему, хоть и в папку /mnt/backup. Если после этого туда смонтировать сетевой диск, то ранее скопированные файлы будут не видны, но они будут занимать место. Ситуация хоть и кажется довольно редкой, но на самом деле она иногда случается и я сам был свидетелем такого. И читатели писали такие же истории. Вот одна из них. Поэтому если скриптом подключаете диски, то всегда проверяйте, успешно ли они подключились, прежде чем копировать туда файлы. Вот примеры, как это можно сделать.
#bash #terminal
Нравятся тенденции последних лет по принятию разных полезных современных утилит в базовые репозитории популярных дистрибутивов. Недавно рассказывал про hyperfine и bat. К ним можно теперь добавить утилиту duf, как замену df. Она теперь тоже переехала в базовый репозиторий:
Когда первый раз про неё писал, её там не было. Качал бинарник вручную. Рассказывать про неё особо нечего. Так же, как и df, duf показывает использование диска разных устройств и точек монтирования. Вывод более наглядный, чем в df. Плюс, есть несколько дополнительных возможностей, которые могут быть полезны:
▪️ Умеет делать вывод в формате json:
▪️ Умеет сразу сортировать по разным признакам:
▪️ Умеет группировать и сортировать устройства:
и т.д.
То есть эта штука удобна не только для визуального просмотра через консоль, но и для использования в различных костылях, велосипедах и мониторингах. Не нужно парсить регулярками вывод df, а можно отфильтровать, выгрузить в json и обработать jq. Написана duf на GO, работает шустро. Хороший софт, можно брать на вооружение.
#linux #terminal
# apt install dufКогда первый раз про неё писал, её там не было. Качал бинарник вручную. Рассказывать про неё особо нечего. Так же, как и df, duf показывает использование диска разных устройств и точек монтирования. Вывод более наглядный, чем в df. Плюс, есть несколько дополнительных возможностей, которые могут быть полезны:
▪️ Умеет делать вывод в формате json:
# duf -json▪️ Умеет сразу сортировать по разным признакам:
# duf -sort size# duf -sort used# duf -sort avail▪️ Умеет группировать и сортировать устройства:
# duf --only local# duf --only network# duf --hide local# duf --only-mp /,/mnt/backupи т.д.
То есть эта штука удобна не только для визуального просмотра через консоль, но и для использования в различных костылях, велосипедах и мониторингах. Не нужно парсить регулярками вывод df, а можно отфильтровать, выгрузить в json и обработать jq. Написана duf на GO, работает шустро. Хороший софт, можно брать на вооружение.
#linux #terminal
{kind=link}
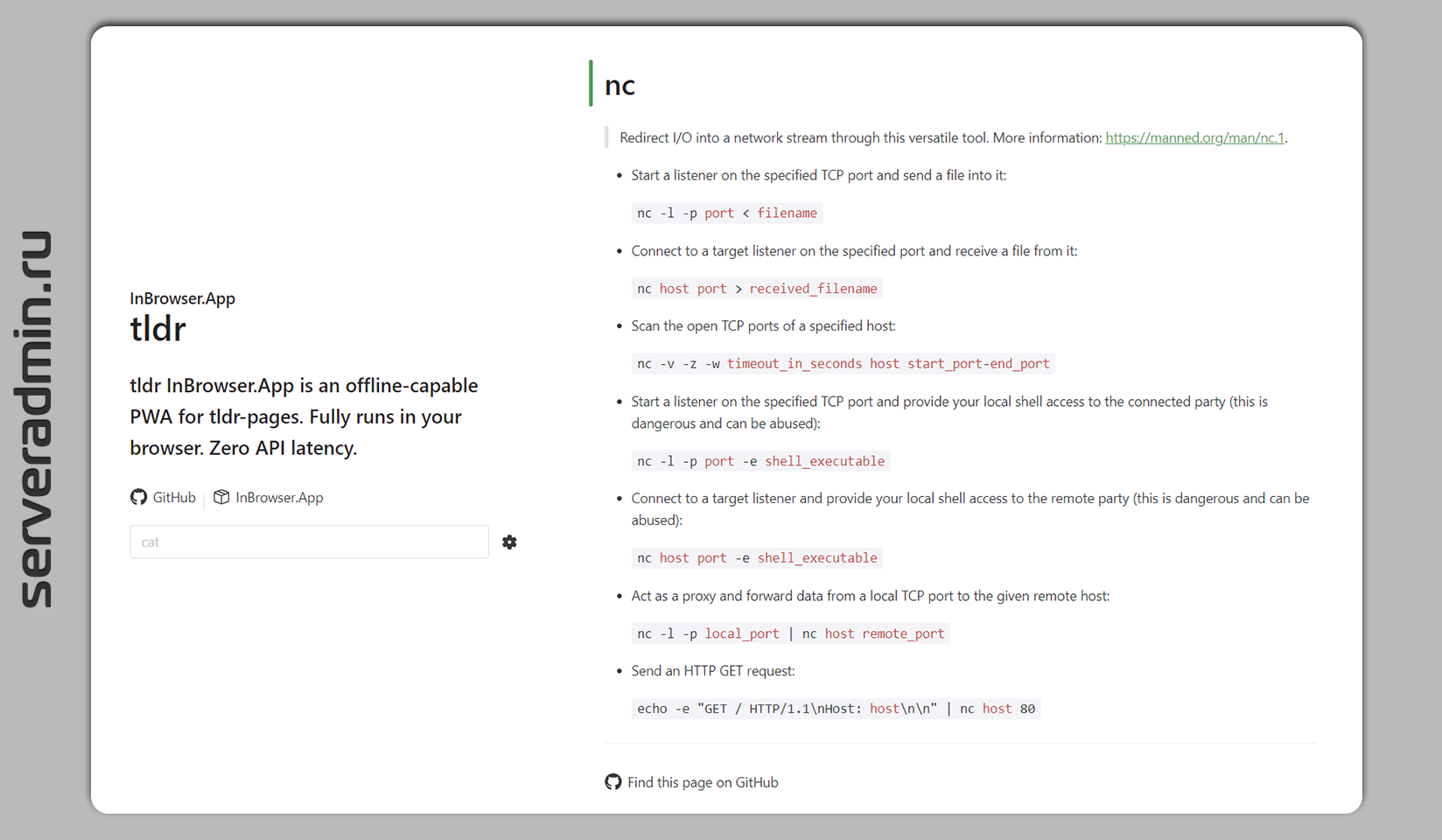
Для тех, кто не любит читать многостраничные man, существует его упрощённая версия, поддерживаемая сообществом — tldr. Аббревиатура как бы говорит сама за себя — Too long; didn't read. Это урезанный вариант man, где кратко представлены примеры использования консольных программ в Linux с минимальным описанием.
Для просмотра информации из tldr можно использовать консольный клиент, либо просто пользоваться веб версией. Описание каждой программы умещается в одну страницу. Авторы, судя по всему, последователи чеховского принципа: "Краткость — сестра таланта".
Вот пример выдачи для lsof:
lsof — Lists open files and the corresponding processes. Note: Root privileges (or sudo) is required to list files opened by others. More information: https://manned.org/lsof.
● Find the processes that have a given file open:
● Find the process that opened a local internet port:
● Only output the process ID (PID):
● List files opened by the given user:
● List files opened by the given command or process:
● List files opened by a specific process, given its PID:
● List open files in a directory:
● Find the process that is listening on a local IPv6 TCP port and don't convert network or port numbers:
В принципе, всё основное охватили. Кому интересно, может посмотреть мою подборку с примерами использования lsof. Я тоже люблю такие краткие выжимки с примерами. Надо будет собрать их все в одну публикацию. На канале уже много набралось по многим популярным утилитам.
Проект интересный и полезный. В закладки можно забрать и иногда пользоваться по нужде. Он похож на некоторые другие, про которые я уже писал ранее:
▪️ cheat.sh — он удобнее организован, можно информацию получать через curl сразу в консоль, без установки клиента
▪️ explainshell.com — тут немного другой принцип, на основе man выдаёт описание длинных команд с разными ключами
Отдельно упомяну сервис, который немного про другое, но тоже очень полезный. Регулярно им пользуюсь:
🔥 shellcheck.net — проверка синтаксиса shell скриптов
#linux #terminal
Для просмотра информации из tldr можно использовать консольный клиент, либо просто пользоваться веб версией. Описание каждой программы умещается в одну страницу. Авторы, судя по всему, последователи чеховского принципа: "Краткость — сестра таланта".
Вот пример выдачи для lsof:
lsof — Lists open files and the corresponding processes. Note: Root privileges (or sudo) is required to list files opened by others. More information: https://manned.org/lsof.
● Find the processes that have a given file open:
lsof path/to/file● Find the process that opened a local internet port:
lsof -i :port● Only output the process ID (PID):
lsof -t path/to/file● List files opened by the given user:
lsof -u username● List files opened by the given command or process:
lsof -c process_or_command_name● List files opened by a specific process, given its PID:
lsof -p PID● List open files in a directory:
lsof +D path/to/directory● Find the process that is listening on a local IPv6 TCP port and don't convert network or port numbers:
lsof -i6TCP:port -sTCP:LISTEN -n -PВ принципе, всё основное охватили. Кому интересно, может посмотреть мою подборку с примерами использования lsof. Я тоже люблю такие краткие выжимки с примерами. Надо будет собрать их все в одну публикацию. На канале уже много набралось по многим популярным утилитам.
Проект интересный и полезный. В закладки можно забрать и иногда пользоваться по нужде. Он похож на некоторые другие, про которые я уже писал ранее:
▪️ cheat.sh — он удобнее организован, можно информацию получать через curl сразу в консоль, без установки клиента
▪️ explainshell.com — тут немного другой принцип, на основе man выдаёт описание длинных команд с разными ключами
Отдельно упомяну сервис, который немного про другое, но тоже очень полезный. Регулярно им пользуюсь:
🔥 shellcheck.net — проверка синтаксиса shell скриптов
#linux #terminal
{kind=link}
Решил собрать в одну публикацию все мои заметки по базовым консольным программам Linux с описанием и примерами использования. Давно хотел сделать, но откладывал, так как хлопотно весь канал перетряхивать. В заметках не только стандартное описание, но и мой авторский текст о них и практические примеры.
▪️ curl: работа с веб серверами, отправка почты, чтение почты по imap,
▪️ systemctl: управление службами, работа с таймерами, просмотр информации о системе,
▪️ find: общие примеры, очистка старых файлов, поиск дубликатов файлов,
▪️ lsof: работа с файлами и сетевыми соединениями
▪️ grep - поиск строк и шаблонов в текстах
▪️ cat - использование cat как текстового редактора
▪️ type - возвращает тип введённой в оболочку команды
▪️ touch - обновление информации о atime и mtime файла
▪️ hash - просмотр кэша путей к исполняемым файлам
▪️ auditctl - аудит доступа к файлам
▪️ history - просмотр истории введённых в консоль команд
▪️ at - планировщик разовых заданий
▪️ ps - вывод списка процессов с подробностями
▪️ dig - запросы к dns серверам
▪️ nc - установка сетевых соединений и передача по ним информации
▪️ screen - защита терминальных сессий от разрыва соединения
▪️ cut - работа с текстовыми строками
▪️ w - информация об uptime, подключенных пользователях, la
▪️ less - постраничный вывод информации в консоль
▪️ truncate - усечение текстовых файлов (логов)
▪️ split - разделение файлов на части
▪️ units - конвертация единиц измерения
▪️ chsh - замена оболочки пользователя
▪️ fc - утилита из состава оболочки bash для работы с историей команд
▪️ socat - создание потоков для передачи данных, прямой доступ к shell
▪️ lsmem и chmem - информация об оперативной памяти, управление объёмом использования
▪️ column - выводит данные других команд в табличном виде
▪️ vmstat - информация по использованию оперативной памяти, cpu и дисках
▪️ findmnt - информация о точках монтирования
▪️ sed - автоматическая замена текста в файлах
▪️ date - вывод информации о дате и времени в различных форматах
▪️ basename - показывает только имя файла из полного пути
▪️ lsblk - информации об устройствах хранения
#terminal #подборка
▪️ curl: работа с веб серверами, отправка почты, чтение почты по imap,
▪️ systemctl: управление службами, работа с таймерами, просмотр информации о системе,
▪️ find: общие примеры, очистка старых файлов, поиск дубликатов файлов,
▪️ lsof: работа с файлами и сетевыми соединениями
▪️ grep - поиск строк и шаблонов в текстах
▪️ cat - использование cat как текстового редактора
▪️ type - возвращает тип введённой в оболочку команды
▪️ touch - обновление информации о atime и mtime файла
▪️ hash - просмотр кэша путей к исполняемым файлам
▪️ auditctl - аудит доступа к файлам
▪️ history - просмотр истории введённых в консоль команд
▪️ at - планировщик разовых заданий
▪️ ps - вывод списка процессов с подробностями
▪️ dig - запросы к dns серверам
▪️ nc - установка сетевых соединений и передача по ним информации
▪️ screen - защита терминальных сессий от разрыва соединения
▪️ cut - работа с текстовыми строками
▪️ w - информация об uptime, подключенных пользователях, la
▪️ less - постраничный вывод информации в консоль
▪️ truncate - усечение текстовых файлов (логов)
▪️ split - разделение файлов на части
▪️ units - конвертация единиц измерения
▪️ chsh - замена оболочки пользователя
▪️ fc - утилита из состава оболочки bash для работы с историей команд
▪️ socat - создание потоков для передачи данных, прямой доступ к shell
▪️ lsmem и chmem - информация об оперативной памяти, управление объёмом использования
▪️ column - выводит данные других команд в табличном виде
▪️ vmstat - информация по использованию оперативной памяти, cpu и дисках
▪️ findmnt - информация о точках монтирования
▪️ sed - автоматическая замена текста в файлах
▪️ date - вывод информации о дате и времени в различных форматах
▪️ basename - показывает только имя файла из полного пути
▪️ lsblk - информации об устройствах хранения
#terminal #подборка
Как быстро прибить приложение, которое слушает определённый порт?
Вариантов решения этой задачи может быть много. Первое, что приходит в голову - посмотреть список открытых портов в ss, узнать pid процесса и завершить его:
Но быстрее и проще воспользоваться lsof:
Или вообще в одно действие:
Lsof могучая утилита. Я как-то особо не пользовался ей, кроме как для файлов, пока не подготовил заметку год назад с примерами использования. С тех порт и для сетевых соединений стал активно применять. Особенно вот в таком виде:
Возвращаюсь к открытым портам. Есть утилита killport, которая делает то же самое, что я делал выше, только в одну команду:
В стандартных репах её нет, придётся качать бинарник из репозитория. Если для Linux это не сильно надо, так как там много инструментов для подобных действий, что я продемонстрировал выше, то для Windows это будет более актуально. Killport есть и под винду (❗️) Использовать можно примерно так:
То есть сначала смотрим, что будет прибито, а потом только делаем.
Такая штука обычно нужна для каких-то костылей и велосипедов, когда что-то зависает, не перезапускается, а надо освободить порт, чтобы запустить новый экземпляр.
#terminal #bash
Вариантов решения этой задачи может быть много. Первое, что приходит в голову - посмотреть список открытых портов в ss, узнать pid процесса и завершить его:
# ss -tulnp | grep 8080tcp LISTEN 0 5 0.0.0.0:8080 0.0.0.0:* users:(("python3",pid=5152,fd=3))# kill 5152Но быстрее и проще воспользоваться lsof:
# lsof -i:8080COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEpython3 5156 root 3u IPv4 41738 0t0 TCP *:http-alt (LISTEN)# kill 5152Или вообще в одно действие:
# lsof -i:8080 -t | xargs killLsof могучая утилита. Я как-то особо не пользовался ей, кроме как для файлов, пока не подготовил заметку год назад с примерами использования. С тех порт и для сетевых соединений стал активно применять. Особенно вот в таком виде:
# lsof -i# lsof -i TCP:25# lsof -i TCP@1.2.3.4Возвращаюсь к открытым портам. Есть утилита killport, которая делает то же самое, что я делал выше, только в одну команду:
# killport 8080В стандартных репах её нет, придётся качать бинарник из репозитория. Если для Linux это не сильно надо, так как там много инструментов для подобных действий, что я продемонстрировал выше, то для Windows это будет более актуально. Killport есть и под винду (❗️) Использовать можно примерно так:
> killport 445 --dry-runWould kill process 'System' listening on port 445То есть сначала смотрим, что будет прибито, а потом только делаем.
Такая штука обычно нужна для каких-то костылей и велосипедов, когда что-то зависает, не перезапускается, а надо освободить порт, чтобы запустить новый экземпляр.
#terminal #bash
Медленно, но верно, я перестаю использовать
Самые популярные ключи к ss это tulnp:
Список открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
Вывести только сокеты можно и другой командой:
Но там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
И сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
То же самое, только выводим тех, у кого более 30 соединений с нами:
Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
Всё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
Больше лично я
#linux #terminal
netstat и привыкаю к ss. У неё хоть и не такой удобный для восприятия вывод, но цепляться за netstat уже не имеет смысла. Она давно устарела и не рекомендуется к использованию. Плюс, её нет в стандартных минимальных поставках дистрибутивов. Надо ставить отдельно. Это как с ifconfig. Поначалу упирался, но уже много лет использую только ip. Ifconfig вообще не запускаю. Даже ключи все забыл. Самые популярные ключи к ss это tulnp:
# ss -tulnpСписок открытых tcp и udp портов. Может показаться смешным и нелепым, но чтобы запомнить эту комбинацию и не лазить в шпаргалки, я представил её написание как тулуп (tulnp). Он хоть и не совсем тулуп, но это помогло мне запомнить эти ключи и активно использовать. Такие ассоциативные якоря помогают запоминать многие вещи. Я постоянно их использую в жизни.
Из того, что ещё часто используется - просмотр открытых сокетов. Актуально, чтобы быстро глянуть, поднялся ли сокет php-fpm или mariadb:
# ss -l | grep .sockВывести только сокеты можно и другой командой:
# ss -axНо там будет много лишнего. Трудно для восприятия. Поэтому грепнуть общий список мне проще, лучше запоминается и короче вывод.
У ss есть одна неприятная особенность, из-за которой она не кажется такой удобной, как netstat. Возможно, это только для меня актуально. Если терминал не очень широкий, то вывод расползается и труден для визуального восприятия. Я не люблю широкие окна для ssh подключений, обычно это небольшое окон посередине экрана, перед глазами. В таком окне вывод netstat выглядит аккуратнее, чем ss. Чтобы посмотреть ss, приходится разворачивать терминал на весь экран.
По памяти я больше ничего из ss не помню. Ещё несколько команд сохранены в заметках, остальные вообще не использую.
Просмотр активных сетевых соединений:
# ss -ntuИ сразу же практический пример для наглядного анализа каких-то проблем через консоль сервера. Подсчет активных сетевых соединений с каждого IP:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//'То же самое, только выводим тех, у кого более 30 соединений с нами:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | cut -d: -f1 | sort | uniq -c | sort -n| sed 's/^[ \t]*//' | awk '{if ($1 > 30) print$2}'Получаем чистый список IP адресов, который можно куда-то направить. Например, в fail2ban, ipset или nftables. Если вас донимают простым досом какие-то мамкины хакеры, можете таким простым способом от них избавиться. Все эти примеры заработают только на ipv4. Для ipv6 нужно будет изменения вносить. Я пока отключаю везде ipv6, не использую.
Количество активных сетевых соединений с сервером:
# ss -ntuH | awk '{print $6}' | grep -vE 127.0.0.1 | wc -lВсё то же самое, что делали выше, можно сделать не только для активных соединений, но и всех остальных, добавив ключ
a:# ss -ntuaБольше лично я
ss ни для чего не использую. Если смотрите ещё что-то полезное с помощью этой утилиты, поделитесь в комментариях.#linux #terminal
Стал регулярно сталкиваться с одной проблемой. Есть сервер с бюджетными SSD дисками. Они для многих задач вполне подходят, несмотря на низкую стоимость и скорость записи. Последнее как раз их узкое место. Но если у вас в основном с дисков чтение, то можно существенно экономить, используя десктопные диски.
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
Ограничил скорость записи в 20 MiB/s через ключ
Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
У меня как раз такой случай. Несколько виртуалок под веб сервера, где в основном чтение из кэшей на дисках. По производительности никаких нареканий, кроме одного момента. Когда дампишь для бэкапов базы данных, весь гипервизор начинает прилично тормозить, а в мониторинг сыпятся уведомления о медленном ответе веб сервера и увеличении отклика дисков. Обычно это происходит ночью и особых проблем не доставляет. Но тем не менее, решил это исправить.
Самый простой способ в лоб - ограничить скорость пайпа, через который данные с mysqldump записываются в файл. По умолчанию всё читается и пишется параллельными потоками с одних и тех же SSD. Десктопные диски такой режим очень не любят и заметно тормозят при выполнении.
Я использовал утилиту pv:
# apt install pv# mysqldump --opt -v --single-transaction --databases db01 | pv -L 20m > /mnt/backup/db01.sqlОграничил скорость записи в 20 MiB/s через ключ
-L. Для того, чтобы посмотреть текущую скорость записи, используйте pv без ограничения:# mysqldump --opt -v --single-transaction --databases db01 | pv > /mnt/backup/db01.sql............................ 1319MiB 0:00:06 [ 205MiB/s]Вообще pv интересная утилита. Стоит написать о ней отдельно. Если знаете ещё какие-то способы решения этой задачи, поделитесь в комментариях. Если дампишь сразу по сети, то можно скорость сетевой передачи ограничивать. А вот так, чтобы локально, больше ничего в голову не приходит. Разве что жать сразу на лету с сильной компрессией, чтобы медленно было. Но это как-то муторно подбирать подходящую скорость.
#linux #terminal
Вчера вскользь упомянул утилиту
PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
Чаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
Можно его притормозить, при желании, чтобы не утилизировать всю запись диска:
Можно измерить скорость выполнения дампа СУБД:
🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
Можно и просто скорость по ssh между двух серверов проверить:
В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
pv, хотя она вполне заслуживает отдельного рассказа. Знаю её очень давно, но использую не часто. Конкретно в задаче по ограничению скорости записи дампа на диск она очень выручила. Других простых способов я не нашёл, да и никто не предложил ничего лучше.PV это аббревиатура от pipeviewer. То есть это инструмент для работы с пайпами. Обычно есть в репозиториях всех популярных дистрибутивов:
# apt install pv# dnf install pvЧаще всего pv упоминают в контексте прогресс бара при работе с файлами и каталогами. Например, при копировании, перемещении, сжатии. Так как размер файлов заранее известен, а так же видна скорость обработки файлов, pv может предсказать, сколько процесс продлится и когда закончится. Примерно так:
# pv testfile > copy/testfile_copy 976MiB 0:00:02 [ 344MiB/s] [=======================>] 100 Размер файла, который копировали, известен, скорость тоже, так что прогресс бар нормально отработал.
То же самое для сжатия:
# pv testfile | gzip > testfile.gz 976MiB 0:00:05 [ 183MiB/s] [=======================>] 100 При этом pv может притормозить этот процесс, если у вас есть в этом потребность. Это очень полезная и практически уникальная возможность. Копируем файл с заданной скоростью:
# pv -L 50m testfile > copy/testfile_copy 976MiB 0:00:19 [49.9MiB/s] [=======================>] 100 Ограничили скорость записи в 50 Мб в секунду (на самом деле мебибайт, но не суть важно, и зачем только придумали эту путаницу). Подобным образом можно ограничивать скорость любого пайпа.
Во время работы с каталогами, pv ничего не знает об их размерах, поэтому прогресс бар корректно работать не будет. Но это можно исправить, передав утилите размер каталога. Примерно так:
# tar -czf - usr | pv -s $(du -sb /usr | grep -o '[0-9]*') > /tmp/usr.tgz 126MiB 0:00:16 [9.46MiB/s] [==> ] 5% ETA 0:04:18Наглядно виден процесс сжатия, сколько времени осталось. Мы по сути просто определили размер каталога usr через du и передали этот размер в pv через ключ
-s. Можно и напрямую передать туда размер, если он известен. На самом деле со сжатием этот пример практически бесполезен, так как скорость сжатия всегда разная, в зависимости от того, какие файлы сжимаются.Область применения pv обширная. Её можно воткнуть куда угодно, где используется пайп, как минимум, чтобы посмотреть скорость прохождения данных там, где это не видно. Например, можно проследить за снятием образа диска:
# pv -EE /dev/sda > disk-image.imgМожно его притормозить, при желании, чтобы не утилизировать всю запись диска:
# pv -L 50m -EE /dev/sda > disk-image.imgМожно измерить скорость выполнения дампа СУБД:
# mysqldump --opt -v --databases db01 | pv > db01.sql🔥 С помощью pv можно посмотреть за работой всех файловых дескрипторов, открытых процессов. Причём не просто список увидеть, но и скорость обработки данных в них:
# pv -d 1404 3:/prometheus/queries.active: 0.00 B 0:01:40 [0.00 B/s] 8:/prometheus/lock: 0.00 B 0:01:40 [0.00 B/s] 9:/prometheus/wal/00000000: 10.9MiB 0:01:40 [4.28KiB/s] 14:/prometheus/chunks_head/000001: 8.00 B 0:01:40 [0.00 B/s] 16:/prometheus/chunks_head/000001: 0.00 B 0:01:40 [0.00 B/s]С помощью pv легко ограничивать скорость передачи данных по сети, если направить их через pipe:
# pv -L 10m /tmp/testfile | ssh user@server02 'cat > /tmp/testfile'Пример синтетический, так как копировать удобнее через rsync, так как там можно штатно указать ограничение на использование канала. Другое дело, что лично я эти ключи rsync наизусть не помню, надо смотреть. А ключ
-L (limit) для pv помню. Можно и просто скорость по ssh между двух серверов проверить:
# pv /dev/zero | ssh user@server02 'cat > /dev/null'В общем, применять pv можно везде, где используются пайпы в Unix. Очень удобная штука.
#linux #terminal
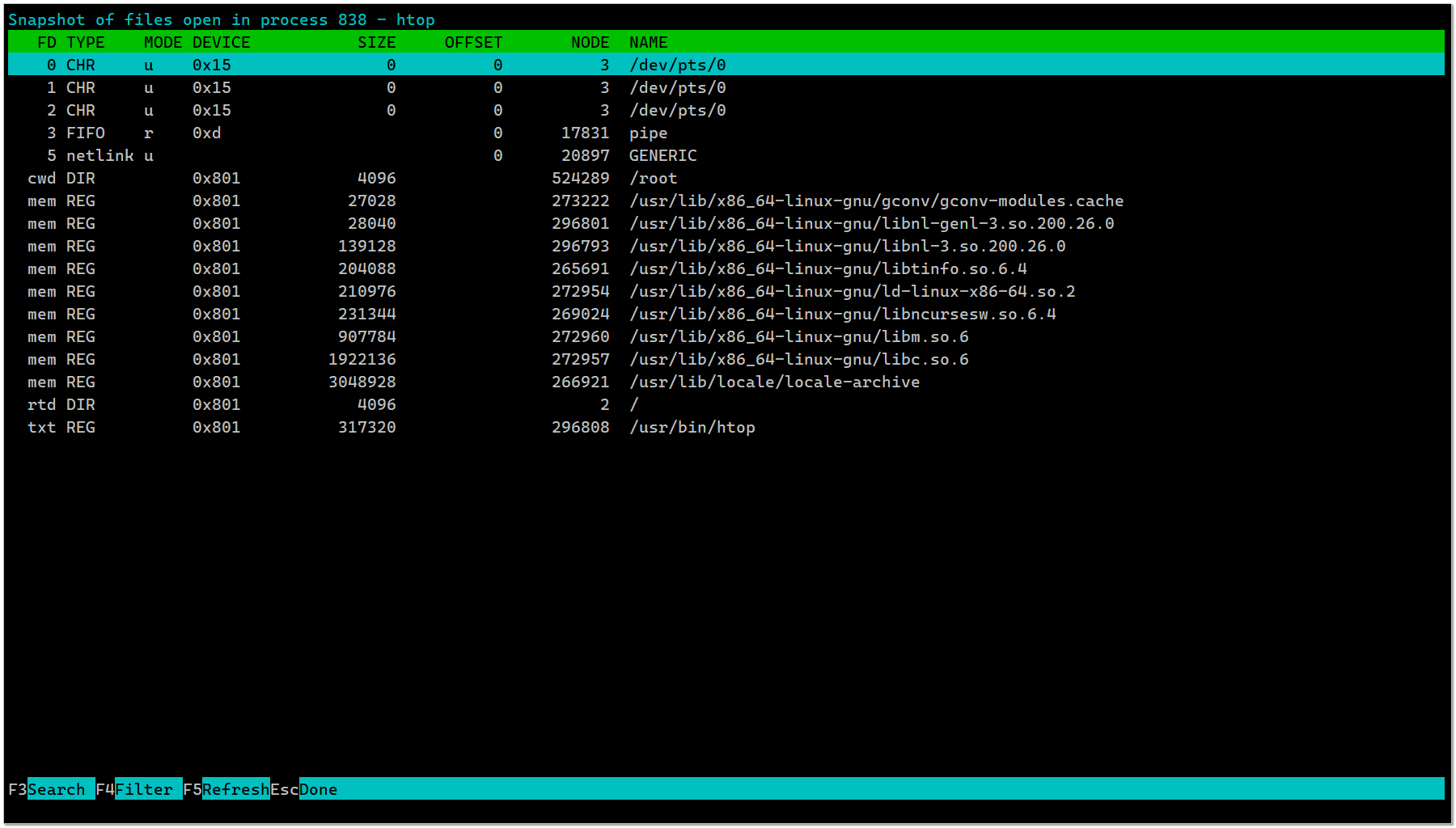
Всегда смотрел список открытых файлов каким-то процессом с помощью lsof. Неоднократно писал об этом.
Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
Теперь можно выбрать процесс, нажать
Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
# lsof -p <pid>Вчера случайно заметил, просматривая опции htop, что он умеет делать то же самое. Достаточно выбрать какой-то процесс из списка и нажать клавишу
l (латинская л). Удивился и не понял, как я раньше это не замечал. Подумал, что это очередное нововведение последних версий. Htop с некоторого времени начал развиваться и обрастать новыми возможностями. Открыл старый сервер на Centos 7, там htop версии 2.2.0 от 2019 года и тоже есть эта функция. Скорее всего была она там со стародавних времён, а я просто не замечал. Пользоваться ею удобно.
Вообще, htop крутая программа. Я настолько привык к ней, что чувствую себя неуютно на сервере, если она не установлена. После того, как появилась вкладка с I/O вообще хорошо стало. Не нужно дополнительно iotop или что-то подобное ставить. Достаточно запустить htop и можно сделать всю базовую диагностику в нём.
Если установить strace, то и трейсы можно смотреть прямо в htop:
# apt install straceТеперь можно выбрать процесс, нажать
s и посмотреть все системные вызовы.Когда пользуешься одним и тем же, привыкаешь к этому и забываешь остальные возможности. В htop по памяти помню только несколько команд, которыми пользуюсь примерно в 90% случаев:
◽t - включить древовидное отображение
◽P - отсортировать по потреблению CPU
◽M - отсортировать по потреблению памяти
◽F9 - прибить процесс
◽TAB - переключиться на кладку с I/O и обратно
В htop не хватает только одного - сетевой активности. Надо туда добавить отдельную вкладку, по аналогии с I/O, где будет выводиться примерно то же самое, что показывает утилита iftop.
#linux #terminal
{kind=link}
Полезной возможностью Tmux является расширение функциональности за счёт плагинов. Для тех, кто не знает, поясню, что с помощью Tmux можно не переживать за разрыв SSH сессии. Исполнение всех команд продолжится даже после вашего отключения. Потом можно подключиться заново и попасть в свою сессию. Я в обязательном порядке все более-менее долгосрочные операции делаю в подобных программах. Раньше использовал Screen для этого, но последнее время перехожу на Tmux, так как он удобнее и функциональнее.
Особенно важно выполнять обновление систем в Tmux или Screen, так как обрыв соединения в этот момент может привести к реальным проблемам. Я и сам сталкивался, и читатели присылали свои проблемы по этой же части. У меня были заметки на этот счёт.
Для Tmux есть плагин Tmux Resurrect, который позволяет сохранить состояние Tmux со всеми панелями и окнами и порядком их размещения. Вы сможете подключиться в свою настроенную сессию не только в случае отключения, но и перезагрузки Tmux или всего сервера. То есть вы можете настроить в первом окне несколько панелей, к примеру, с htop, tail каких-то логов, переход в какую-то директорию. Во втором окне что-то ещё. Потом сохранить эту сессию. Даже если сервер будет перезагружен, вы сможете восстановить всё окружение.
Демонстрация, как это работает:
▶️ https://vimeo.com/104763018
Установить Tmux Resurrect можно либо через Tmux Plugin Manager, либо напрямую:
Добавляем в ~/.tmux.conf в самое начало:
Заходим в сессию Tmux и сохраняем её состояние через prefix + Ctrl-s, по умолчанию префикс это Ctrl-b, то есть жмём Ctrl-b потом сразу Ctrl-s. Внизу будет информационное сообщение, что сессия сохранена. Восстановить её можно будет через комбинацию Ctrl-b потом сразу Ctrl-r.
Интересная возможность, которая позволяет завершать сессию, сохраняя её состояние. У меня привычка не оставлять запущенные сессии в фоне. Если их оставлять, то они накапливаются, забываются и могут месяцами висеть. Я обычно поработаю и все сессии после себя завершаю.
#linux #terminal
Особенно важно выполнять обновление систем в Tmux или Screen, так как обрыв соединения в этот момент может привести к реальным проблемам. Я и сам сталкивался, и читатели присылали свои проблемы по этой же части. У меня были заметки на этот счёт.
Для Tmux есть плагин Tmux Resurrect, который позволяет сохранить состояние Tmux со всеми панелями и окнами и порядком их размещения. Вы сможете подключиться в свою настроенную сессию не только в случае отключения, но и перезагрузки Tmux или всего сервера. То есть вы можете настроить в первом окне несколько панелей, к примеру, с htop, tail каких-то логов, переход в какую-то директорию. Во втором окне что-то ещё. Потом сохранить эту сессию. Даже если сервер будет перезагружен, вы сможете восстановить всё окружение.
Демонстрация, как это работает:
▶️ https://vimeo.com/104763018
Установить Tmux Resurrect можно либо через Tmux Plugin Manager, либо напрямую:
# git clone https://github.com/tmux-plugins/tmux-resurrectДобавляем в ~/.tmux.conf в самое начало:
run-shell ~/tmux-resurrect/resurrect.tmuxЗаходим в сессию Tmux и сохраняем её состояние через prefix + Ctrl-s, по умолчанию префикс это Ctrl-b, то есть жмём Ctrl-b потом сразу Ctrl-s. Внизу будет информационное сообщение, что сессия сохранена. Восстановить её можно будет через комбинацию Ctrl-b потом сразу Ctrl-r.
Интересная возможность, которая позволяет завершать сессию, сохраняя её состояние. У меня привычка не оставлять запущенные сессии в фоне. Если их оставлять, то они накапливаются, забываются и могут месяцами висеть. Я обычно поработаю и все сессии после себя завершаю.
#linux #terminal
{kind=link}
В репозиториях популярных дистрибутивов есть маленькая, но в некоторых случаях полезная программа progress. Из названия примерно понятно, что она делает - показывает шкалу в % выполнения различных дисковых операций. Она поддерживает так называемые coreutils - cp, mv, dd, tar, gzip/gunzip, cat и т.д.
Progress по смыслу немного похожа на pv, но принцип работы там совсем другой. Pv берёт информацию из пайпов, соответственно, надо заранее направить поток в неё, чтобы что-то увидеть. А progress сканирует каталог
Для того, чтобы посмотреть прогресс той или иной команды, не обязательно запускать утилиту progress вместе с выполнением. Это можно сделать в любой момент времени. Например, запустили упаковку или распаковку большого архива gz и хотите посмотреть, как она выполняется. Достаточно открыть вторую консоль и там посмотреть. Мне это часто актуально, когда большие дампы sql распаковываю. Иногда это прям очень долго, особенно, когда однопоточный gzip используется.
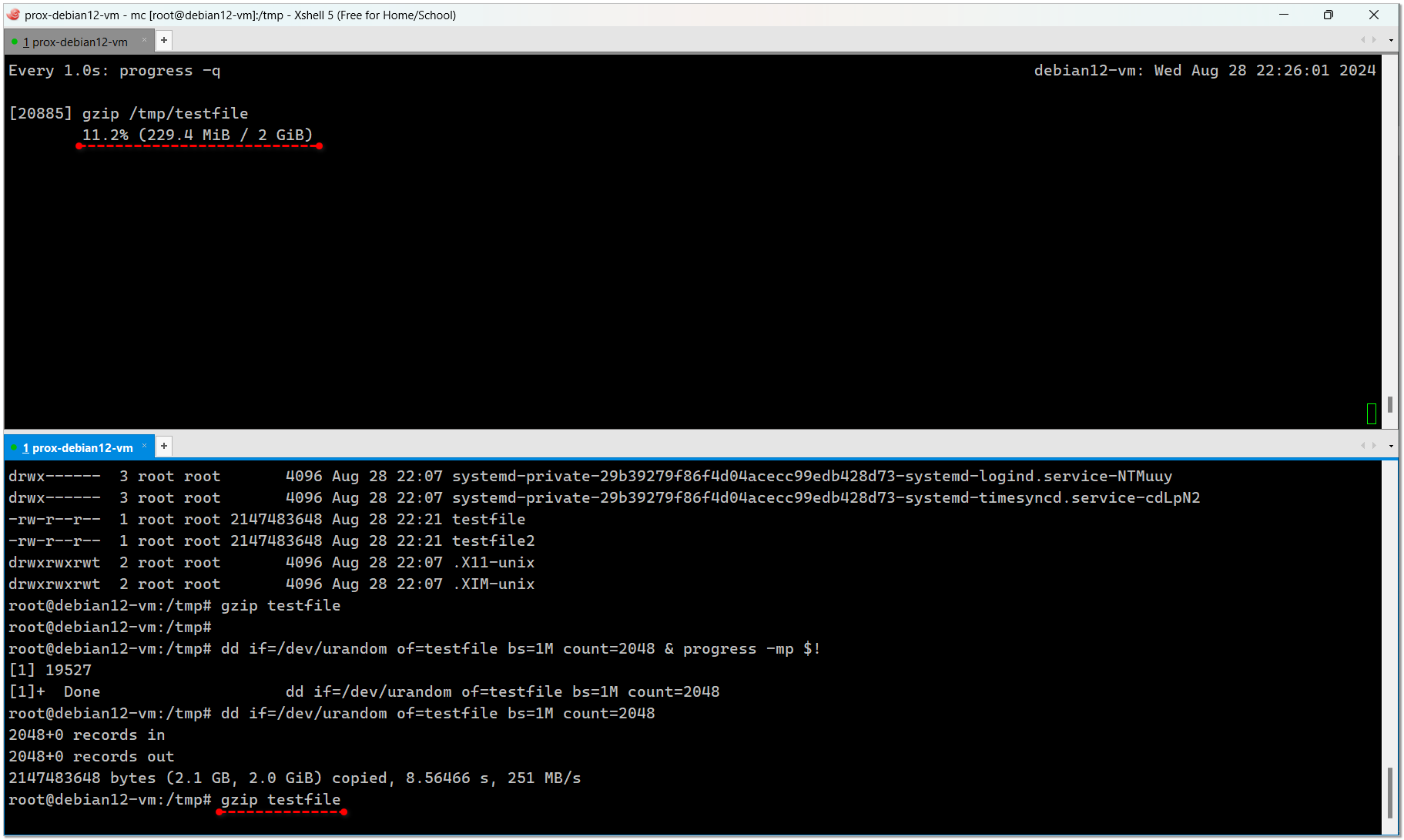
Покажу сразу на примере. Создадим файл:
За процессом, кстати, тоже можно следить с помощью progress, только не будет отображаться % выполнения, потому что утилита ничего не знает о конечном размере. Будет отображаться только скорость записи в режиме реального времени.
Жмём файл:
Открываем вторую консоль и там смотрим за процессом:
Если запустить без watch, то progress выведет только текущую информацию и сразу же закроется. То есть не получится наблюдать в режиме реального времени.
То же самое будет и с распаковкой:
В соседней консоли смотрим:
Progress очень маленькая утилитка, написанная на чистом C (вспоминается песня "Папа может в C"). Размер - 31K. Из зависимостей только небольшая библиотека ncurses для вывода информации от сишных программ в терминал. Есть почти под все линуксы:
⇨ Исходники
#terminal #linux
Progress по смыслу немного похожа на pv, но принцип работы там совсем другой. Pv берёт информацию из пайпов, соответственно, надо заранее направить поток в неё, чтобы что-то увидеть. А progress сканирует каталог
/proc, находит там поддерживаемые утилиты, далее идёт в fd и fdinfo, находит там открытые файлы и следит за их изменениями.Для того, чтобы посмотреть прогресс той или иной команды, не обязательно запускать утилиту progress вместе с выполнением. Это можно сделать в любой момент времени. Например, запустили упаковку или распаковку большого архива gz и хотите посмотреть, как она выполняется. Достаточно открыть вторую консоль и там посмотреть. Мне это часто актуально, когда большие дампы sql распаковываю. Иногда это прям очень долго, особенно, когда однопоточный gzip используется.
Покажу сразу на примере. Создадим файл:
# dd if=/dev/urandom of=testfile bs=1M count=2048За процессом, кстати, тоже можно следить с помощью progress, только не будет отображаться % выполнения, потому что утилита ничего не знает о конечном размере. Будет отображаться только скорость записи в режиме реального времени.
Жмём файл:
# gzip testfileОткрываем вторую консоль и там смотрим за процессом:
# watch -n 1 progress -q[34209] gzip /tmp/testfile 6.5% (132.2 MiB / 2 GiB)Если запустить без watch, то progress выведет только текущую информацию и сразу же закроется. То есть не получится наблюдать в режиме реального времени.
То же самое будет и с распаковкой:
# gunzip testfile.gzВ соседней консоли смотрим:
# watch -n 1 progress -q[35685] gzip /tmp/testfile.gz 76.1% (1.5 GiB / 2.0 GiB)Progress очень маленькая утилитка, написанная на чистом C (вспоминается песня "Папа может в C"). Размер - 31K. Из зависимостей только небольшая библиотека ncurses для вывода информации от сишных программ в терминал. Есть почти под все линуксы:
# apt install progress# dnf install progress ⇨ Исходники
#terminal #linux
{kind=link}
Я уже как-то упоминал, что последнее время в репозитории популярных дистрибутивов попадают современные утилиты, аналоги более старых с расширенной функциональностью. Я писал о некоторых из них:
▪️ duf как замена df
▪️ bat как замена cat
▪️ hyperfine как замена time
В этот список можно добавить exa как замена ls. Я про exa уже писал несколько лет назад, но тогда её не было в стабильном репозитории. А сейчас приехала и туда:
Это небольшая утилита с параллельной обработкой файлов, благодаря чему работает быстро. Но при этом обладает рядом дополнительных возможностей по сравнению с ls:
◽более информативная расцветка
◽умеет показывать расширенные атрибуты файлов (xattrs)
🔥иерархичное древовидное отображение
◽отображает статус файлов в git репозитории (изменён или нет со времени последнего коммита)
◽может выводить в несколько колонок информацию
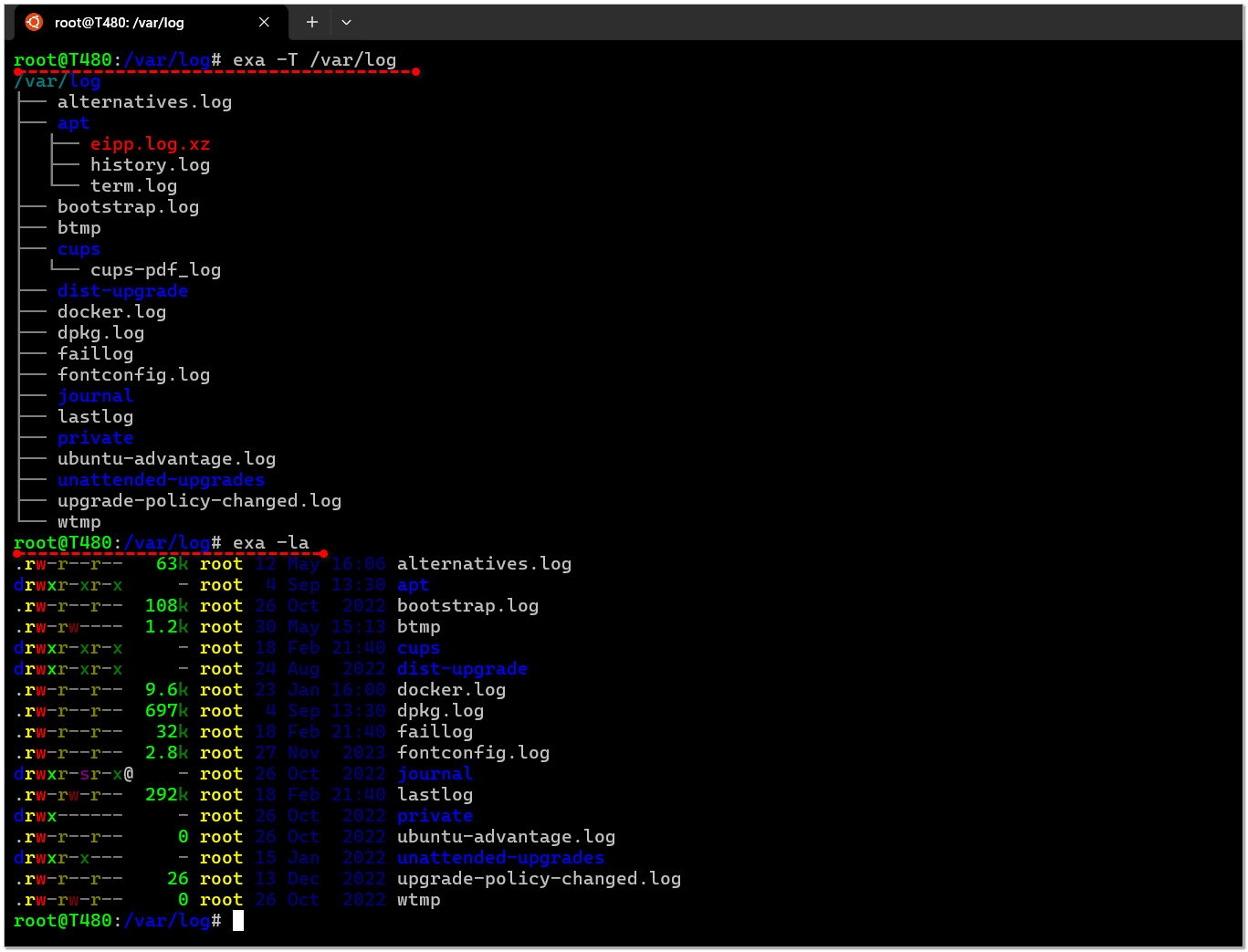
Все привычные ключи ls тоже поддерживает. Мне лично только расцветка понравилась и древовидное отображение:
Можно ограничить максимальный уровень вложенности:
Привычные ключи ls, как я уже сказал, поддерживаются, поэтому можно алиасом заменить ls на exa:
❗️К сожалению, exa больше не развивается, потому что автор куда-то пропал. В репозитории есть об этом информация. Предлагают переходить на форк eza, но его пока нет в репозиториях для Debian 12, но планируется в Debian 13. В Ubuntu 24 уже есть eza. Так что всё написанное актуально и для неё. Если в вашем дистрибутиве она уже есть, то имеет смысл поставить именно её. Там есть ряд небольших правок багов и некоторые улучшения функциональности. Я себе поставил в WSL как замену ls.
⇨ Исходники / Сайт
#linux #terminal
▪️ duf как замена df
▪️ bat как замена cat
▪️ hyperfine как замена time
В этот список можно добавить exa как замена ls. Я про exa уже писал несколько лет назад, но тогда её не было в стабильном репозитории. А сейчас приехала и туда:
# apt install exaЭто небольшая утилита с параллельной обработкой файлов, благодаря чему работает быстро. Но при этом обладает рядом дополнительных возможностей по сравнению с ls:
◽более информативная расцветка
◽умеет показывать расширенные атрибуты файлов (xattrs)
🔥иерархичное древовидное отображение
◽отображает статус файлов в git репозитории (изменён или нет со времени последнего коммита)
◽может выводить в несколько колонок информацию
Все привычные ключи ls тоже поддерживает. Мне лично только расцветка понравилась и древовидное отображение:
# exa -T /var/log├── alternatives.log├── alternatives.log.1├── alternatives.log.2.gz├── alternatives.log.3.gz├── alternatives.log.4.gz├── apt│ ├── eipp.log.xz│ ├── history.log│ ├── history.log.1.gz│ ├── history.log.2.gz......................................Можно ограничить максимальный уровень вложенности:
# exa -T -L 2 /var/logПривычные ключи ls, как я уже сказал, поддерживаются, поэтому можно алиасом заменить ls на exa:
# echo 'alias ls=exa' >> ~/.bashrc# source ~/.bashrc# ls -la❗️К сожалению, exa больше не развивается, потому что автор куда-то пропал. В репозитории есть об этом информация. Предлагают переходить на форк eza, но его пока нет в репозиториях для Debian 12, но планируется в Debian 13. В Ubuntu 24 уже есть eza. Так что всё написанное актуально и для неё. Если в вашем дистрибутиве она уже есть, то имеет смысл поставить именно её. Там есть ряд небольших правок багов и некоторые улучшения функциональности. Я себе поставил в WSL как замену ls.
⇨ Исходники / Сайт
#linux #terminal
{kind=link}