
Казалось бы, что может быть проще копирования файлов из одной директории в другую. Тем не менее в консоли Linux это не всегда простая и очевидная процедура. Для этого существует небольшая утилита
Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
Но так скопируются только файлы, без вложенных директорий. Добавляем ключ
По моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
На длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
Ещё засаду с
Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
Тут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
cp, которая обычно присутствует во всех дистрибутивах. Лично у меня сложности возникают с тем, что я начинаю вспоминать, нужно ли использовать *, ставить или нет слеш на конце директории и т.д. Всё это влияет на конечный результат. Например, надо скопировать содержимое одной директории в другую. Вроде бы ничего сложного:
# cp /dir_a/* /dir_bНо так скопируются только файлы, без вложенных директорий. Добавляем ключ
-r или сразу -a, чтобы и все атрибуты скопировать:# cp -a /dir_a/* /dir_bПо моему субъективному мнению, логично было бы по умолчанию копировать рекурсивно и с сохранением всех атрибутов.
Но и в таком копировании есть различные неочевидные моменты. Использование звёздочки обрабатывает сама оболочка bash. Она передаёт команде cp аргументы, заменяя звёздочку. Если в директории не будет файлов, то cp вернёт ошибку, потому что оболочка ей ничего не передаст. А если файлов наоборот будет очень много, то может и зависнуть, потому что оболочка передаст cp примерно следующее:
# cp -a /dir_a/file1 /dir_a/file2 /dir_a/file3 ...... /dir_bНа длину такой команды есть ограничение оболочки. Не помню, как её посмотреть, но не суть. Важно понимать, что оно есть, и что
* в командах, запускаемых в bash, работает именно так.Ещё засаду с
cp можно получить, если в директории будут файлы, начинающиеся с точки. Те же .htaccess. Если скопируем предложенной выше командой со *, то все файлы с точкой в начале имени потеряем. Будет неприятно. Это опять же особенность bash, которая по умолчанию трактует такие файлы как скрытые. Такое поведение можно изменить.Скопировать файлы в консоли Linux можно большим количеством способов и инструментов. Но всегда, когда используете * (wildcard) в командах, имейте ввиду, что на самом деле это означает и к каким последствиям может привести. Если можно без них, то лучше обойтись.
Пример с тем же cp, только без
* :# cp -aT /dir_a /dir_bТут и файлы с точками не потеряли, и разворачивание звёздочки в длиннющую команду не происходит.
#bash
Вчера в заметке про копирование с помощью
Мы всё содержимое директории
В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
Можно сделать:
и остаться в текущем каталоге, либо:
и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
Явно указываем на скрипт, который запускаем. Иначе оболочка проверит
Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
Создали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
cp в комментариях справедливо привели ещё один вариант копирования. Причём самый простой и удобный. Я про него знал, но не стал упоминать, потому что нужны будут пояснения для тех, кто не знает про некоторые особенности псевдопапок в виде точки или двух точек. Речь идёт о примерно такой конструкции:# cp -a /dir_a/. /dir_bМы всё содержимое директории
dir_a со всеми скрытыми файлами скопировали в dir_b. В Linux, как и в DOS кстати, существуют некие псевдопапки-ссылки на текущую и вышестоящую директории. Точка - это, соответственно, текущая директория, а две точки - вышестоящая по отношению к текущей. Обращаться к ним можно так же, как и к обычным папкам. Они, собственно, на вид ничем от остальных и не отличаются. Если сделать
ls -la, то мы их увидим вместе с остальными директориями:# ls -latotal 56drwx------ 8 root root 4096 Nov 22 21:37 .drwxr-xr-x 18 root root 4096 Oct 13 12:30 ..-rw------- 1 root root 6115 Nov 22 16:02 .bash_history-rw-r--r-- 1 root root 571 Apr 10 2021 .bashrcdrwx------ 3 root root 4096 Dec 9 2022 .cachedrwx------ 4 root root 4096 Nov 16 21:22 .config-rw-r--r-- 1 root root 56 Nov 15 00:19 .gitconfigdrwx------ 3 root root 4096 Dec 9 2022 .local-rw-r--r-- 1 root root 161 Jul 9 2019 .profile-rw-r--r-- 1 root root 72 Dec 9 2022 .selected_editordrwx------ 2 root root 4096 Nov 15 00:21 .sshМожно сделать:
# cd .и остаться в текущем каталоге, либо:
# cd .. и перейти в вышестоящий, родительский каталог для текущего.
Отсюда становится понятно, почему для запуска скрипта в текущем каталоге, мы используем точку:
# ./script.shЯвно указываем на скрипт, который запускаем. Иначе оболочка проверит
$PATH, там не окажется текущего каталога и скрипт не будет выполнен. Так что надо написать либо полный путь, либо использовать точку, если скрипт в текущем каталоге. Точно помню, что вот эту тему с точкой я очень долго не понимал и просто использовал. Даже мысли не было, что это я текущий каталог указываю. Думал, это какой-то признак исполняемого файла.Две точки часто используют в скриптах, чтобы обращаться в родительский каталог, когда надо оперировать файлами не только текущего. А так как мы не можем точно знать без дополнительных проверок, как называется родительский каталог, то две точки это удобный вариант.
# touch ../file.nameСоздали файл в вышестоящем каталоге, ничего не зная про него. Без двух точек нам сначала пришлось бы выяснить, где мы находимся, чтобы определить родительский каталог. А так всё делаем сразу.
Если я не ошибаюсь, то точка и две точки это просто ссылки на inode конкретных директорий. Так что их наличие будет зависеть от файловой системы. В наиболее популярных они присутствуют.
#bash
Хочу напомнить про 2 очень полезные утилиты Linux, с помощью которых удобно в скриптах делать проверки наличия подключенных и примонтированных блочных устройств и файловых систем. Речь пойдёт про findmnt и findfs.
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
А если в чём-то ошибётесь, то получите ошибку:
Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
Если файловая система не будет найдена, код будет 1:
Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
Вместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
Проверяем:
Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Про первую я уже когда-то рассказывал. Findmnt удобна и полезна сама по себе, без привязки к скриптам. Просто запустите её и посмотрите вывод. Она выводит в консоль подробную информацию о всех точках монтирования. А ключ
-x ещё и позволяет проверить отредактированный файл fstab на наличие в нём ошибок. Рекомендую запомнить эту возможность и использовать:# findmnt -xSuccess, no errors or warnings detectedА если в чём-то ошибётесь, то получите ошибку:
# findmnt -x/mnt/backup [E] unreachable on boot required source: UUID=151ea24d-977a-412c-818f-0d374baa5012Findfs сама по себе ничего не выводит. Она умеет искать файловые системы по заданными параметрами В качестве аргумента принимает значение LABEL, UUID, PARTLABEL и PARTUUID. Например так:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5013"/dev/sda2Нашли файловую систему на /dev/sda2 с заданным UUID. При этом код выхода будет 0:
# echo $?0Если файловая система не будет найдена, код будет 1:
# findfs "UUID=151ea24d-977a-412c-818f-0d374baa5012"findfs: unable to resolve 'UUID=151ea24d-977a-412c-818f-0d374baa5012'# echo $?1Соответственно, подобную проверку мы может использовать в скриптах перед тем, как выполнять какие-то действия. Это актуально для каких-нибудь бэкапов или синхронизаций на сетевых или внешних дисках. Делаем простую проверку, типа такой:
if findfs "UUID=$1" >/dev/null; then echo "$1 connected."elseecho "$1 not connected."fiВместо echo можно сразу выполнять какое-то действие. Оно будет выполнено, если указанный скрипту UUID подключен. То есть сам скрипт работает так:
# ./check-fs.sh 151ea24d-977a-412c-818f-0d374baa5013151ea24d-977a-412c-818f-0d374baa5013 connected.И точно так же по аналогии можно сделать проверку точек монтирования с помощью findmnt:
if findmnt -rno TARGET "$1" >/dev/null; then echo "$1 mounted."elseecho "$1 not mounted."fiПроверяем:
# ./check-mnt.sh /mnt/extbackup/mnt/extbackup not mounted.Внешнее хранилище для бэкапов не смонтировано, ничего не делаем. Очень важно делать такие проверки, когда копируете что-то на примонтированные устройства. Если запустить процесс копирования при отмонтированном устройстве, то вы просто забьёте весь диск локальной системы, так как все файлы польются на неё.
Я и сам с таким сталкивался, и много раз видел вопросы людей на тему того, что не могут понять, что происходит. Обычно это выглядит так. В момент бэкапа сетевой диск не был примонтирован и мы забили весь корень файлами. А потом в какой-то момент этот диск примонтировался и мы больше не видим те файлы, что были скопированы в точку монтирования в тот момент, когда там не было диска. Его надо отмонтировать и удалить локальные файлы. Если это сразу не просечёшь, то можно много времени потратить на поиск того, что занимает всё свободное место на разделе.
Так что назначайте метки внешним дискам, проверяйте их, делайте проверки монтирования сетевых дисков и т.д. Не выполняйте копирования и синхронизации без этих проверок. А то можно сильно удивиться из-за какой-нибудь неожиданной ошибки. Я реально сталкивался сам с этим не раз, пока не начал постоянно добавлять проверки. Вроде думаешь в локалке всё стабильно, сервера и сеть никто не дёргает, всё в одной стойке стоит. А потом оказалось, что после выключения электричества сервера поднялись не равномерно и сервер с бэкапами поднялся позже остальных. В итоге куда-то не примонтировался сетевой диск для бэкапов и они начали литься локально, пока там место не кончится.
#bash #script
Кажется, я ни разу не упоминал про простой и быстрый способ отладки bash скрипта. Для этого достаточно в самое начало написать:
В этом случай bash начнёт выводить в консоль каждую команду, которую он выполняет. Успешно выполненная команда помечается плюсом в начале строки. Не сказать, что это прям очень сильно помогает отладить, если есть ошибка, но в целом проще и удобнее. Особенно если скрипт большой, с условиями, вычислением переменных и т.д. Вы всё будете видеть на каждом этапе.
Покажу как это работает на простом скрипте по добавлению swap в систему:
Запускаем скрипт:
Благодаря
Когда не знал про
#bash #script
set -xВ этом случай bash начнёт выводить в консоль каждую команду, которую он выполняет. Успешно выполненная команда помечается плюсом в начале строки. Не сказать, что это прям очень сильно помогает отладить, если есть ошибка, но в целом проще и удобнее. Особенно если скрипт большой, с условиями, вычислением переменных и т.д. Вы всё будете видеть на каждом этапе.
Покажу как это работает на простом скрипте по добавлению swap в систему:
#!/bin/bashset -xread -p 'Enter swap size in megabytes: ' size_mbsize_kb=$((1024*${size_mb}))dd if=/dev/zero of=/swap bs=1024 count=${size_kb}chmod 0600 /swapmkswap /swapswapon /swapif [ "$(grep '/swap' /etc/fstab)" ]; then echo "Error: file /etc/fstab already has 'Swap' record"else echo "Add Swap record to /etc/fstab" echo -e '\n/swap swap swap defaults 0 0' >> /etc/fstabfiswapon --showЗапускаем скрипт:
# ./script.sh + read -p 'Enter swap size in megabytes: ' size_mbEnter swap size in megabytes: 512+ size_kb=524288+ dd if=/dev/zero of=/swap bs=1024 count=524288524288+0 records in524288+0 records out536870912 bytes (537 MB, 512 MiB) copied, 1.26859 s, 423 MB/s+ chmod 0600 /swap+ mkswap /swapSetting up swapspace version 1, size = 512 MiB (536866816 bytes)no label, UUID=e873faad-881e-4df0-b25f-23580b952738+ swapon /swap++ grep /swap /etc/fstab+ '[' '' ']'+ echo 'Add Swap record to /etc/fstab'Add Swap record to /etc/fstab+ echo -e '\n/swap swap swap defaults 0 0'+ swapon --showNAME TYPE SIZE USED PRIO/swap file 512M 0B -2Благодаря
set -x мы видим каждое действие, которое выполняет скрипт. Оно начинается с +, а дальше виден стандартный вывод после этого действия. Так разбирать работу скрипта проще, потому что в командах видны все переменные. В этом примере это не очень актуально, а когда они будут неявно указаны, а вычисляемые, то это может сильно помочь. Когда не знал про
set -x, выводил нужные мне переменные в разных местах скрипта с помощью echo во время отладки, чтобы понимать, что там происходит после каждой команды. Но этот путь намного проще.#bash #script
{kind=link}
Почти во всех популярных дистрибутивах Linux в составе присутствует утилита vmstat. С её помощью можно узнать подробную информацию по использованию оперативной памяти, cpu и дисках. Лично я её не люблю, потому что вывод неинформативен. Утилита больше для какой-то глубокой диагностики или мониторинга, нежели простого использования в консоли.
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
Как можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
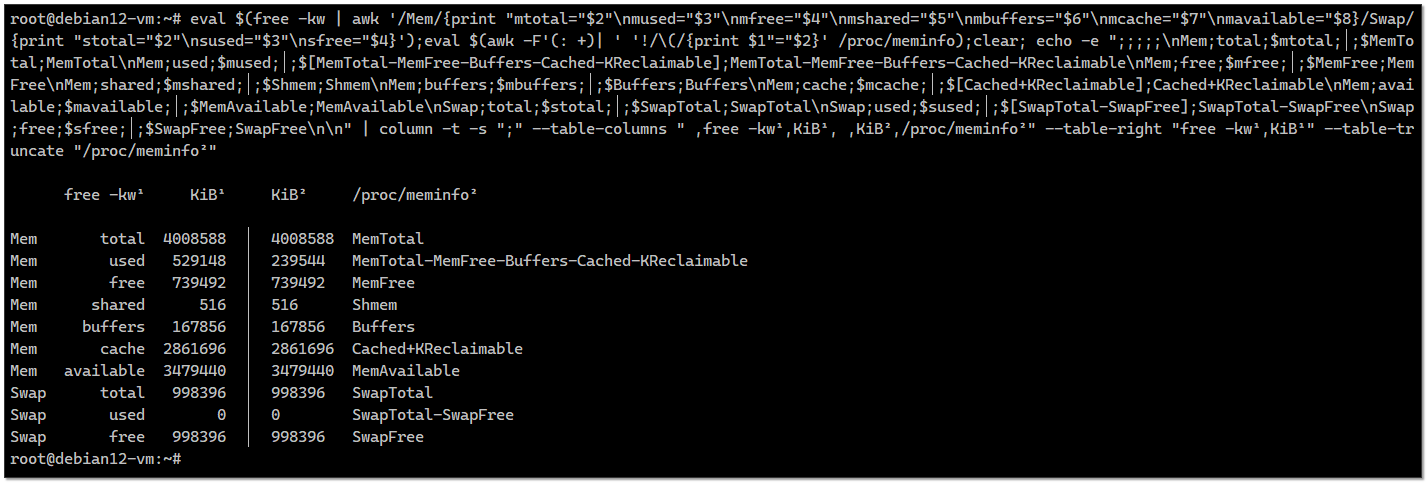
А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
Если есть возможность установить дополнительный пакет, то я предпочту dstat. Там и вывод более наглядный, и ключей больше. А информацию по базовому отображению памяти хорошо перекрывает утилита free.
Тем не менее, если хочется быстро посмотреть некоторую системную информацию, то можно воспользоваться vmstat. У неё есть возможность выводить с определённым интервалом информацию в консоль. Иногда для быстрой отладки это может быть полезно. Запускать лучше сразу с парой дополнительных ключей для вывода информации в мегабайтах и с более широкой таблицей:
# vmstat 1 -w -S MКак можно убедиться, вывод такой себе. Сокращения, как по мне, выбраны неудачно и неинтуитивно. В том же dstat такой проблемы нет. Но в целом привыкнуть можно. В
man vmstat они подробно описаны, так что с интерпретацией проблем не должно возникать.А вообще, эта заметка была написана, чтобы в неё тиснуть необычный однострочник для bash, который меня поразил своей сложностью и непонятностью, но при этом он рабочий. Увидел его в комментариях на хабре и сохранил. Он сравнивает вывод информации об использовании памяти утилиты
free и cat /proc/meminfo: # eval $(free -kw | awk '/Mem/{print "mtotal="$2"\nmused="$3"\nmfree="$4"\nmshared="$5"\nmbuffers="$6"\nmcache="$7"\nmavailable="$8}/Swap/{print "stotal="$2"\nsused="$3"\nsfree="$4}');eval $(awk -F'(: +)| ' '!/\(/{print $1"="$2}' /proc/meminfo);clear; echo -e ";;;;;\nMem;total;$mtotal;│;$MemTotal;MemTotal\nMem;used;$mused;│;$[MemTotal-MemFree-Buffers-Cached-KReclaimable];MemTotal-MemFree-Buffers-Cached-KReclaimable\nMem;free;$mfree;│;$MemFree;MemFree\nMem;shared;$mshared;│;$Shmem;Shmem\nMem;buffers;$mbuffers;│;$Buffers;Buffers\nMem;cache;$mcache;│;$[Cached+KReclaimable];Cached+KReclaimable\nMem;available;$mavailable;│;$MemAvailable;MemAvailable\nSwap;total;$stotal;│;$SwapTotal;SwapTotal\nSwap;used;$sused;│;$[SwapTotal-SwapFree];SwapTotal-SwapFree\nSwap;free;$sfree;│;$SwapFree;SwapFree\n\n" | column -t -s ";" --table-columns " ,free -kw¹,KiB¹, ,KiB²,/proc/meminfo²" --table-right "free -kw¹,KiB¹" --table-truncate "/proc/meminfo²"Это прям какой-то царь-однострочник. Я когда его первый раз запускал, не верил, что он заработает. Но он заработал. В принципе, можно сохранить и использовать.
В завершении дам ссылку на свою заметку с небольшой инструкцией, как и чем быстро в консоли провести диагностику сервера, если он тормозит. Обратите внимание там в комментариях на вот этот. Его имеет смысл сохранить к себе.
#bash #script #perfomance
{kind=link}
Недавно, когда вырезал из дампа mysql содержимое одной таблицы с помощью sed, подумал, что неплохо было бы сделать подборочку с наиболее актуальными и прикладными примерами с sed.
Уже когда начал её составлять вдруг подумал, а нужно ли сейчас вообще всё это? Как считаете? Мы находимся на сломе эпох. Сейчас же ChatGPT сходу приводит все эти команды и практически не ошибается в типовых задачах. Я до сих пор так и не начал им пользоваться. Пробовал несколько раз, но постоянно не использую. По привычке ищу решение в своих записях, чаще всего тут на канале.
Брюзжать, как старый дед, на тему того, что надо своими мозгами думать, а то совсем захиреют, не буду. ИИ помощники это уже наше настоящее и 100% наше будущее, как сейчас калькуляторы. Надо начинать осваивать инструментарий и активно использовать. Ну а пока вернёмся к sed 😁
🟢 Вырезаем всё, что между указанными строками в файле:
🟢 Вырезать первую и последнюю строки. Часто нужно, когда отправляешь в мониторинг вывод каких-нибудь консольных команд. Там обычно в начале какие-то заголовки столбцов идут, а в конце тоже служебная информация:
🟢 Заменить в файле слово old_function на new_function:
🟢 Если нужен более гибкий вариант поиска нужного слова, то можно использовать регулярные выражения:
🟢 Удаляем комментарии и пустые строки:
🟢 Вывести записи в логе веб сервера в интервале 10.01.2024 15:20 - 16:20. Удобная штука, рекомендую сохранить.
🟢 Добавить после каждой строки ещё одну пустую. Иногда нужно, чтобы нагляднее текст оценить. Второй пример - добавление пустой строки после найденного слова в строке:
Про sed можно писать бесконечно, но лично я что-то более сложное редко использую, а вот эти простые конструкции постоянно. Чаще всего именно они используются в связке с другими консольными утилитами.
#bash #sed
Уже когда начал её составлять вдруг подумал, а нужно ли сейчас вообще всё это? Как считаете? Мы находимся на сломе эпох. Сейчас же ChatGPT сходу приводит все эти команды и практически не ошибается в типовых задачах. Я до сих пор так и не начал им пользоваться. Пробовал несколько раз, но постоянно не использую. По привычке ищу решение в своих записях, чаще всего тут на канале.
Брюзжать, как старый дед, на тему того, что надо своими мозгами думать, а то совсем захиреют, не буду. ИИ помощники это уже наше настоящее и 100% наше будущее, как сейчас калькуляторы. Надо начинать осваивать инструментарий и активно использовать. Ну а пока вернёмся к sed 😁
🟢 Вырезаем всё, что между указанными строками в файле:
# sed -i.back '22826,26719 d' dump.sql🟢 Вырезать первую и последнюю строки. Часто нужно, когда отправляешь в мониторинг вывод каких-нибудь консольных команд. Там обычно в начале какие-то заголовки столбцов идут, а в конце тоже служебная информация:
# sed -i.back '1d;$d' filename🟢 Заменить в файле слово old_function на new_function:
# sed -i.back 's/old_function/new_function/g' filename🟢 Если нужен более гибкий вариант поиска нужного слова, то можно использовать регулярные выражения:
# sed -i.back -r 's/old_function.*?/new_function/g' filename# sed -i.back -r 's/^post_max_size =.*/post_max_size = 32M/g' php.ini🟢 Удаляем комментарии и пустые строки:
# sed -i.back '/^;\|^$\|^#/d' php.ini🟢 Вывести записи в логе веб сервера в интервале 10.01.2024 15:20 - 16:20. Удобная штука, рекомендую сохранить.
# sed -n '/10\/Jan\/2024:15:20/,/10\/Jan\/2024:16:20/p' access.log🟢 Добавить после каждой строки ещё одну пустую. Иногда нужно, чтобы нагляднее текст оценить. Второй пример - добавление пустой строки после найденного слова в строке:
# sed -i.back G filename# sed -i.back '/pattern/G' filenameПро sed можно писать бесконечно, но лично я что-то более сложное редко использую, а вот эти простые конструкции постоянно. Чаще всего именно они используются в связке с другими консольными утилитами.
#bash #sed
{kind=link}
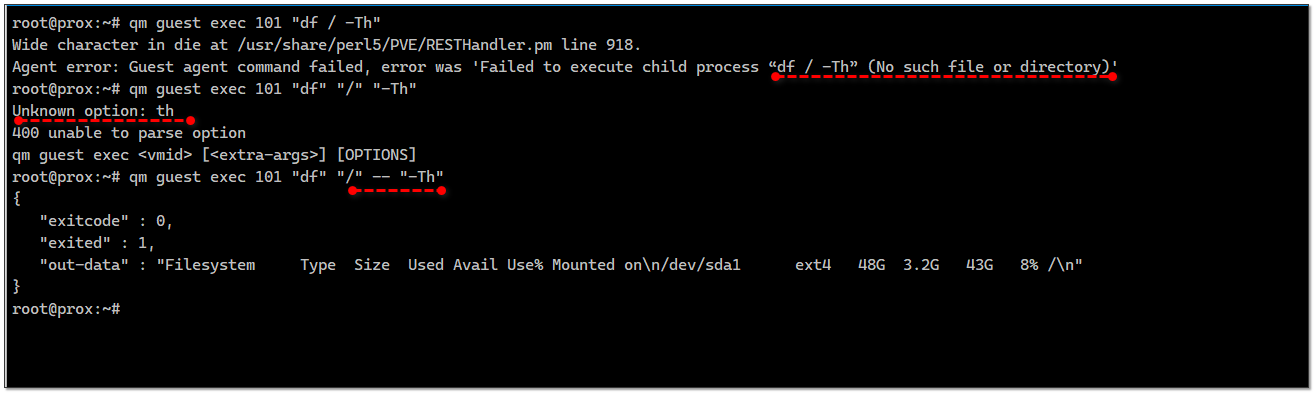
Расскажу об одной возможности bash, с которой хоть и не часто, но приходится сталкиваться. Я столкнулся, когда писал утреннюю заметку про qemu-guest-agent. С его помощью можно выполнить любую команду на гостевой системе. Например так:
Далее мне захотелось добавить некоторые ключи к этой команде:
Получил ошибку. Эта команда так не работает. Агент пытается найти бинарник
В таком виде работает. Добавляю ключи к df и опять ошибка:
Тут типичная проблема для bash. Команда
В таком виде команда отработает так, как ожидается. Двойным тире мы дали понять
С подобной проблемой легко столкнуться, когда, к примеру, вам через grep нужно найти строку -v. Как её указать? Это очень наглядный пример по данной теме. Grep будет считать, что
#bash
# qm guest exec 101 "df"Далее мне захотелось добавить некоторые ключи к этой команде:
# qm guest exec 101 "df -Th"Agent error: Guest agent command failed, error was 'Failed to execute child process “df -Th” (No such file or directory)'Получил ошибку. Эта команда так не работает. Агент пытается найти бинарник
df -Th. Читаю описание команды. Дополнительные аргументы надо передавать отдельно, примерно так:# qm guest exec 101 "df" "/"В таком виде работает. Добавляю ключи к df и опять ошибка:
# qm guest exec 101 "df" "/" "-Th"Unknown option: th400 unable to parse optionТут типичная проблема для bash. Команда
qm считает, что в конструкции -Th я передаю параметры для неё, а она их не понимает. Как же быть? Для этого существуют два тире --. Они говорят команде, что после них нужно игнорировать любые аргументы. То есть правильно будет вот так:# qm guest exec 101 "df" "/" -- "-Th"В таком виде команда отработает так, как ожидается. Двойным тире мы дали понять
qm, что -Th не её аргументы. С подобной проблемой легко столкнуться, когда, к примеру, вам через grep нужно найти строку -v. Как её указать? Это очень наглядный пример по данной теме. Grep будет считать, что
-v это её аргумент и вместо поиска будет выводить свою версию. Тут надо действовать аналогично:# grep -- -v file.txt-- нужны, когда какая-то строка начинается с тире -, реже с +, но при этом не является аргументом команды, и нам нужно дать ей понять это.#bash
{kind=link}
Если вам необходимо кому-то передать свой bash скрипт, но при этом вы не хотите, чтобы этот кто-то видел его содержимое, то есть простое решение. С помощью утилиты shc его можно транслировать в язык C и скомпилировать. На выходе будет обычный бинарник, который будет успешно работать практически на любой ОС Linux.
Это может быть актуально, если вы делаете кому-то что-то на заказ и надо продемонстрировать работоспособность решения. Если сразу отдать скрипт, то недобросовестные заказчики могут не заплатить, так как всё решение это и есть текст скрипта. Возможно, вы просто захотите от кого-то скрыть чувствительные данные или идею реализации той или иной функциональности.
Shc живёт в базовых репозиториях Debian или Ubuntu, возможно и в других дистрибутивах. Для сборки также понадобится пакет gcc.
Пользоваться ей очень просто. Покажу на примере небольшого скрипта с вводом переменной в консоли.
Запускаем:
Теперь компилируем его в бинарник:
На выходе получаем два файла:
- script.sh.x - бинарник
- script.sh.x.c - исходный код
Запускаем бинарь:
Отработал точно так же, как и bash скрипт. С помощью shc можно указать дату, после которой скрипт запускаться не будет. Выглядит это примерно так:
Я подозреваю, что прятать какие-то важные пароли таким образом опасно. Наверняка есть способ, чтобы его вытащить оттуда. Мне даже кажется, что это и не слишком сложно. В памяти то всё равно содержимое будет в каком-то виде отображаться. Можно сдампить память в момент запуска и посмотреть.
Быстро поискал и нашёл готовое решение по расшифровке таких файлов:
⇨ https://github.com/yanncam/UnSHc
Так что имейте ввиду, что это в основном защита от дурака.
#bash #script
Это может быть актуально, если вы делаете кому-то что-то на заказ и надо продемонстрировать работоспособность решения. Если сразу отдать скрипт, то недобросовестные заказчики могут не заплатить, так как всё решение это и есть текст скрипта. Возможно, вы просто захотите от кого-то скрыть чувствительные данные или идею реализации той или иной функциональности.
Shc живёт в базовых репозиториях Debian или Ubuntu, возможно и в других дистрибутивах. Для сборки также понадобится пакет gcc.
# apt install shc gccПользоваться ей очень просто. Покажу на примере небольшого скрипта с вводом переменной в консоли.
#!/bin/bashv=$1echo "Simple BASH script. Entered VARIABLE: $v"Запускаем:
# ./script.sh 111Simple BASH script. Entered VARIABLE: 111Теперь компилируем его в бинарник:
# shc -f -r script.shНа выходе получаем два файла:
- script.sh.x - бинарник
- script.sh.x.c - исходный код
Запускаем бинарь:
# ./script.sh.x 123Simple BASH script. Entered VARIABLE: 123Отработал точно так же, как и bash скрипт. С помощью shc можно указать дату, после которой скрипт запускаться не будет. Выглядит это примерно так:
# shc -e 31/12/2023 -m "Извини, но ты опоздал!" -f -r script.sh# ./script.sh.x./script.sh.x: has expired!Извини, но ты опоздал!Я подозреваю, что прятать какие-то важные пароли таким образом опасно. Наверняка есть способ, чтобы его вытащить оттуда. Мне даже кажется, что это и не слишком сложно. В памяти то всё равно содержимое будет в каком-то виде отображаться. Можно сдампить память в момент запуска и посмотреть.
Быстро поискал и нашёл готовое решение по расшифровке таких файлов:
⇨ https://github.com/yanncam/UnSHc
Так что имейте ввиду, что это в основном защита от дурака.
#bash #script
{kind=link}
Вчера заметка про простенький http сервер на python породила интересное обсуждение на тему передачи файлов. Конечно, способов существует уйма, и каждый использует то, что ему привычнее, удобнее, быстрее.
Лично у меня прижились следующие способы передачи.
🟢 Если надо перекинуть один файл между серверами, я использую scp:
Сразу привёл пример с нестандартным портом, там как тут используется заглавная
🟢 Если файлов много, использую rsync:
Тоже такой универсальный пример, где сразу и порт, и ключ указан, если аутентификация не по паролю.
🟢 А вот если надо скопировать что-то разово на мой рабочий ноут или какой-то виндовый комп, то я запускаю веб сервер на python и просто скачиваю. Для текстовых логов актуально, чтобы сразу забрать все, что нужны:
🔴 А вот простой трюк, когда надо перекинуть файл с одного сервера на другой, но при этом подключение между серверами не настроено, но я со своего ноута или jump сервера могу подключиться к обоим. Тогда можно сделать вот так:
#bash
Лично у меня прижились следующие способы передачи.
🟢 Если надо перекинуть один файл между серверами, я использую scp:
# scp -P 22777 user@10.1.4.4:/mnt/data/BackUp/onlyoffice.tar.gz /backupСразу привёл пример с нестандартным портом, там как тут используется заглавная
-P. Я долго не мог запомнить это, используя маленькую -p, как в ssh.🟢 Если файлов много, использую rsync:
# rsync -avz -e "ssh -p 1234 -i /root/.ssh/id_rsa" user@10.1.4.22:/data/mail /dataТоже такой универсальный пример, где сразу и порт, и ключ указан, если аутентификация не по паролю.
🟢 А вот если надо скопировать что-то разово на мой рабочий ноут или какой-то виндовый комп, то я запускаю веб сервер на python и просто скачиваю. Для текстовых логов актуально, чтобы сразу забрать все, что нужны:
# cd /var/log# python3 -m http.server 8000🔴 А вот простой трюк, когда надо перекинуть файл с одного сервера на другой, но при этом подключение между серверами не настроено, но я со своего ноута или jump сервера могу подключиться к обоим. Тогда можно сделать вот так:
# ssh user01@10.1.4.4 'cat /home/user01/file.tar.gz' | ssh user02@10.1.5.10 'cat > /home/user02/file.tar.gz'#bash
{kind=link}
Небольшая шпаргалка с командами, которая пригодится, когда у вас закончилось свободное место на дисках на сервере под управлением Linux.
🟢 Смотрим, что у нас вообще по занимаемому месту:
🟢 Если в какой-то точке монтирования занято на 100% свободное место, можно быстро посмотреть, в каких конкретно директориях оно занято. Тут может быть много разных вариантов:
Ограничиваем вывод:
Смотрим топ 20 самых больших директорий:
Смотрим топ 20 самых больших файлов:
🟢 На всякий случай проверяем inodes. Иногда свободное место заканчивается из-за них:
🟢 Если вывод du показывает, что места свободного нет, но сумма всех директорий явно меньше занимаемого места, то надо проверить удалённые файлы, которые всё ещё держит какой-то процесс. Они не видны напрямую, посмотреть их можно через lsof:
Если увидите там файлы большого размера, то посмотрите, какая служба их держит открытыми и перезапустите её. Обычно это помогает. Если служба зависла, то грохните её принудительно через
🟢 Ещё один важный момент. Может получиться так, что du оказывает, что всё место занято. В файловой системе напрямую вы не можете найти, чем оно занято, так как сумма всех файлов и директорий явно меньше, чем занято места. Среди удалённых файлов тоже ничего нет. Тогда проверяйте свои точки монтирования. Бывает так, что у вас, к примеру, скриптом монтируется сетевой диск в /mnt/backup и туда копируются бэкапы. А потом диск отключается. Если по какой-то причине в момент бэкапа диск не подмонтируется, а данные туда скопируются, то они все лягут на корневую систему, хоть и в папку /mnt/backup. Если после этого туда смонтировать сетевой диск, то ранее скопированные файлы будут не видны, но они будут занимать место. Ситуация хоть и кажется довольно редкой, но на самом деле она иногда случается и я сам был свидетелем такого. И читатели писали такие же истории. Вот одна из них. Поэтому если скриптом подключаете диски, то всегда проверяйте, успешно ли они подключились, прежде чем копировать туда файлы. Вот примеры, как это можно сделать.
#bash #terminal
🟢 Смотрим, что у нас вообще по занимаемому месту:
# df -h🟢 Если в какой-то точке монтирования занято на 100% свободное место, можно быстро посмотреть, в каких конкретно директориях оно занято. Тут может быть много разных вариантов:
# du -h -d 1 / | sort -hr# du -hs /* | sort -hrОграничиваем вывод:
# du -h -d 1 / | sort -hr | head -10Смотрим топ 20 самых больших директорий:
# du -hcx --max-depth=6 / | sort -rh | head -n 20Смотрим топ 20 самых больших файлов:
# find / -mount -ignore_readdir_race -type f -exec du -h "{}" + 2>&1 \> | sort -rh | head -n 20🟢 На всякий случай проверяем inodes. Иногда свободное место заканчивается из-за них:
# df -ih🟢 Если вывод du показывает, что места свободного нет, но сумма всех директорий явно меньше занимаемого места, то надо проверить удалённые файлы, которые всё ещё держит какой-то процесс. Они не видны напрямую, посмотреть их можно через lsof:
# lsof | grep '(deleted)'# lsof +L1Если увидите там файлы большого размера, то посмотрите, какая служба их держит открытыми и перезапустите её. Обычно это помогает. Если служба зависла, то грохните её принудительно через
kill -9 <pid>.🟢 Ещё один важный момент. Может получиться так, что du оказывает, что всё место занято. В файловой системе напрямую вы не можете найти, чем оно занято, так как сумма всех файлов и директорий явно меньше, чем занято места. Среди удалённых файлов тоже ничего нет. Тогда проверяйте свои точки монтирования. Бывает так, что у вас, к примеру, скриптом монтируется сетевой диск в /mnt/backup и туда копируются бэкапы. А потом диск отключается. Если по какой-то причине в момент бэкапа диск не подмонтируется, а данные туда скопируются, то они все лягут на корневую систему, хоть и в папку /mnt/backup. Если после этого туда смонтировать сетевой диск, то ранее скопированные файлы будут не видны, но они будут занимать место. Ситуация хоть и кажется довольно редкой, но на самом деле она иногда случается и я сам был свидетелем такого. И читатели писали такие же истории. Вот одна из них. Поэтому если скриптом подключаете диски, то всегда проверяйте, успешно ли они подключились, прежде чем копировать туда файлы. Вот примеры, как это можно сделать.
#bash #terminal
Расскажу про необычную комбинацию клавиш в консоли bash, о которой наверняка многие не знают, а она иногда бывает полезной. Это из серии советов, когда те, кто про него знают, думаю, что тут такого, зачем об этом писать. А кто-то вообще об этом никогда не слышал.
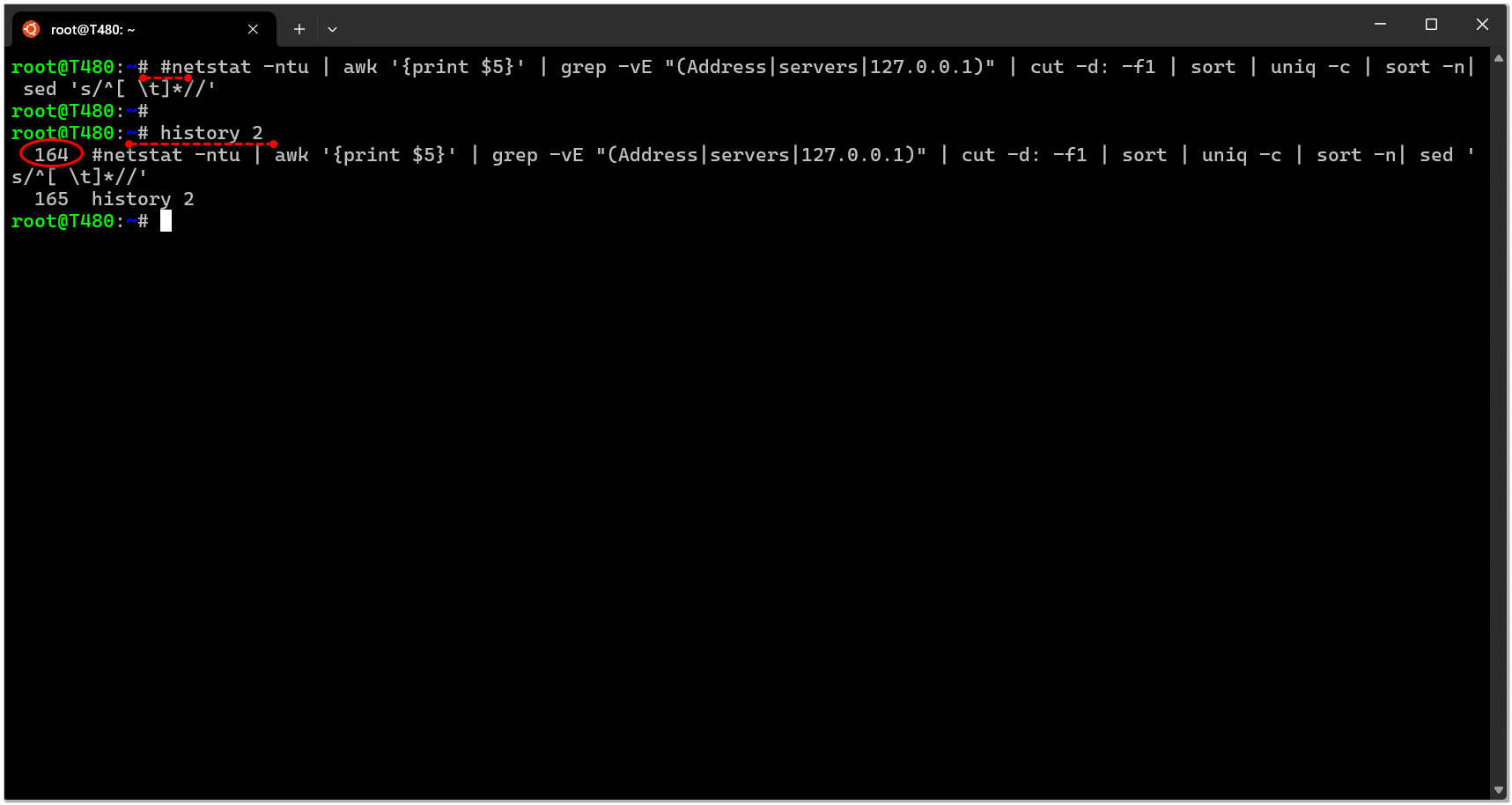
Допустим, вы набираете в консоли длинную команду, а потом вдруг решили, что запускать её по какой-то причине не будете. Но вам хочется её сохранить, чтобы запустить потом. Самое первое, что приходит в голову, это скопировать её и куда-то записать. Но можно поступить проще и быстрее.
Нажимаем комбинацию Alt+Shif+3. После этого к команде автоматически добавляется в самое начало
Такой вот маленький трюк. Если не знали, то запомните. Облегчает работу в консоли.
#bash
Допустим, вы набираете в консоли длинную команду, а потом вдруг решили, что запускать её по какой-то причине не будете. Но вам хочется её сохранить, чтобы запустить потом. Самое первое, что приходит в голову, это скопировать её и куда-то записать. Но можно поступить проще и быстрее.
Нажимаем комбинацию Alt+Shif+3. После этого к команде автоматически добавляется в самое начало
# и команда как-бы выполняется, но на самом деле не выполняется, потому что стоит #. При этом команда улетает вместе с # в history. После этого её можно там посмотреть, либо быстро вызвать через поиск по Ctrl+R. Если искать по #, то она первая и выскочит.Такой вот маленький трюк. Если не знали, то запомните. Облегчает работу в консоли.
#bash
{kind=link}
Прошлая заметка про комбинацию в терминале Alt+Shift+3 получила какой-то невероятный отклик в виде лайков, хотя не делает чего-то особенного. Не ожидал такой реакции. Раз это так востребовано, расскажу ещё про одну комбинацию клавиш в bash, про которую наверняка многие не знают, но она куда более полезная на практике по сравнению с упомянутой выше.
Для тех, кто часто работает в bash, наверняка будет знакома история, когда вы что-то запустили в терминале и постоянно появляются новые строки. Вы хотите прочитать что-то, что уже ушло вверх с экрана, но из-за того, что постоянно появляются новые строки, терминал неизменно проматывается в самый низ. Бесячая ситуация, когда несколько раз пытаешься промотать вверх и не получается.
Такое возникает, например, когда ты смотришь логи в режиме реального времени:
C tail ситуация вымышленная, просто для демонстрации того, о чём идёт речь. Нет никакой проблемы прервать tail, прекратить появление новых строк, чтобы можно было спокойно промотать терминал.
Более реальная ситуация, когда ты запустил Docker контейнер не в режиме демона, он сыпет своими логами в терминал, где-то проскочила ошибка, ты хочешь к ней вернуться, скролишь, но ничего не получается, потому что появляются новые строки. А прервать выполнение ты не можешь, контейнер прекратит свою работу, если его остановить.
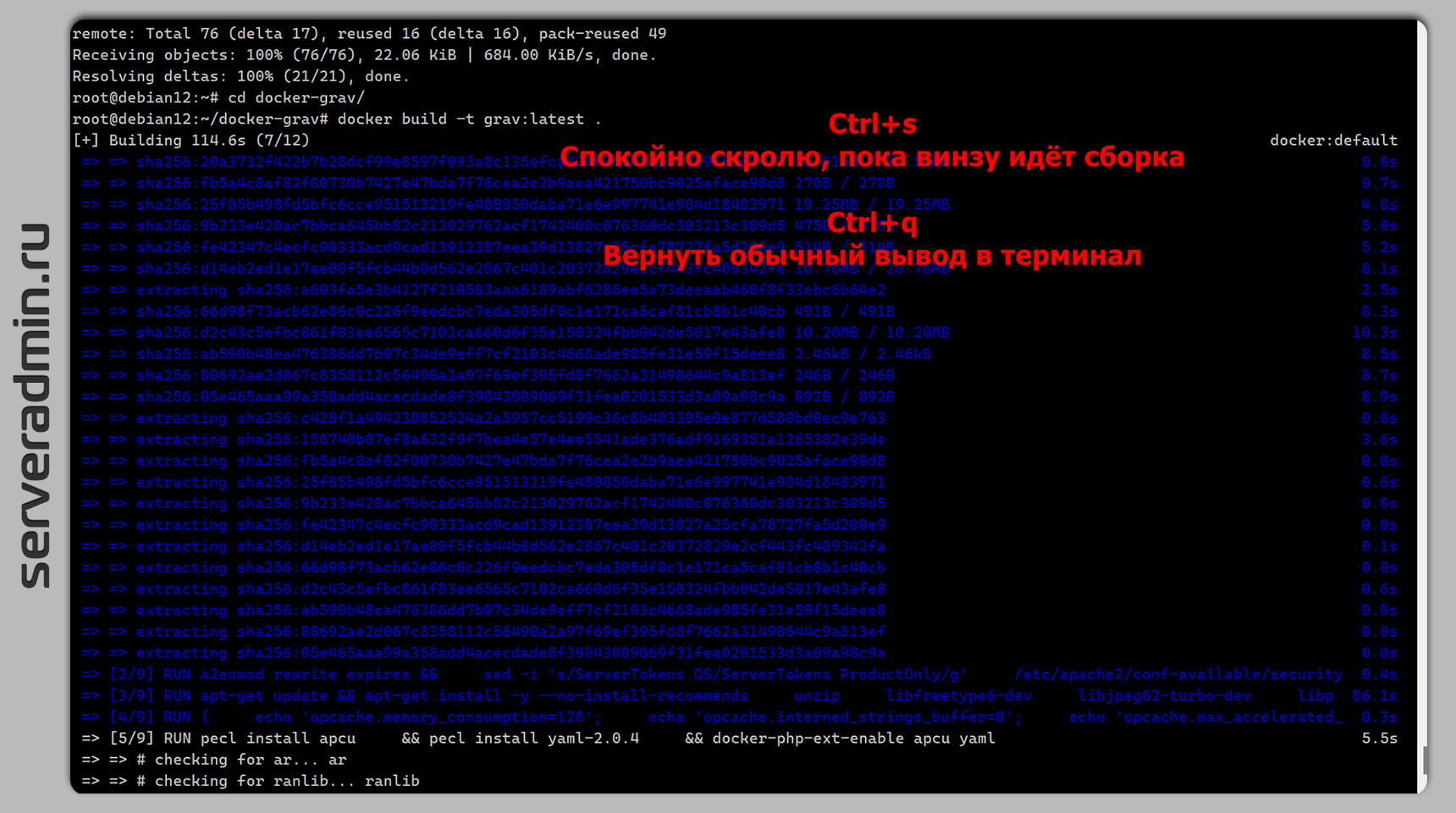
И тут тебе поможет комбинация Ctrl + s. Она поставит вывод в терминал на паузу. Новые строки не будут появляться, а ты спокойно сможешь проскролить экран до ошибки и прочитать её. Когда закончишь, нажмёшь Ctrl + q, и терминал продолжит работу в обычном режиме.
То же самое происходит, когда в терминале собирает Dockerfile, запускается большой docker-compose и т.д. Невозможно проскролить терминал наверх, пока процесс не завершится. Но если сделать Ctrl + s, то всё получится.
Это прям реальная тема. Я, когда узнал, очень обрадовался знанию. Сразу как-то проникся, потому что закрыл реальную проблему, которая раздражала время от времени.
#bash
Для тех, кто часто работает в bash, наверняка будет знакома история, когда вы что-то запустили в терминале и постоянно появляются новые строки. Вы хотите прочитать что-то, что уже ушло вверх с экрана, но из-за того, что постоянно появляются новые строки, терминал неизменно проматывается в самый низ. Бесячая ситуация, когда несколько раз пытаешься промотать вверх и не получается.
Такое возникает, например, когда ты смотришь логи в режиме реального времени:
# tail -f /var/log/nginx/access.logC tail ситуация вымышленная, просто для демонстрации того, о чём идёт речь. Нет никакой проблемы прервать tail, прекратить появление новых строк, чтобы можно было спокойно промотать терминал.
Более реальная ситуация, когда ты запустил Docker контейнер не в режиме демона, он сыпет своими логами в терминал, где-то проскочила ошибка, ты хочешь к ней вернуться, скролишь, но ничего не получается, потому что появляются новые строки. А прервать выполнение ты не можешь, контейнер прекратит свою работу, если его остановить.
И тут тебе поможет комбинация Ctrl + s. Она поставит вывод в терминал на паузу. Новые строки не будут появляться, а ты спокойно сможешь проскролить экран до ошибки и прочитать её. Когда закончишь, нажмёшь Ctrl + q, и терминал продолжит работу в обычном режиме.
То же самое происходит, когда в терминале собирает Dockerfile, запускается большой docker-compose и т.д. Невозможно проскролить терминал наверх, пока процесс не завершится. Но если сделать Ctrl + s, то всё получится.
Это прям реальная тема. Я, когда узнал, очень обрадовался знанию. Сразу как-то проникся, потому что закрыл реальную проблему, которая раздражала время от времени.
#bash
{kind=link}
Возникла небольшая прикладная задача. Нужно было периодически с одного mysql сервера перекидывать дамп одной таблицы из базы на другой сервер в такую же базу. Решений этой задачи может быть много. Я взял и решил в лоб набором простых команд на bash. Делюсь с вами итоговым скриптом. Даже если он вам не нужен в рамках этой задачи, то можете взять какие-то моменты для использования в другой.
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
#!/bin/bash
# Дамп базы с заменой общего комплексного параметра --opt, где используется ключ --lock-tables на набор отдельных ключей, где вместо lock-tables используется --single-transaction
/usr/bin/mysqldump --add-drop-database --add-locks --create-options --disable-keys --extended-insert --single-transaction --quick --set-charset --routines --events --triggers --comments --quote-names --order-by-primary --hex-blob --databases database01 -u'userdb' -p'password' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
# Из общего дампа вырезаю дамп только данных таблицы table01. Общий дамп тоже оставляю, потому что он нужен для других задач
/usr/bin/cat /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql | /usr/bin/awk '/LOCK TABLES `table01`/,/UNLOCK TABLES/' > /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Сжимаю оба дампа
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-database01.sql
/usr/bin/gzip /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql
# Копирую дамп таблицы на второй сервер, аутентификация по ключам
/usr/bin/scp /mnt/backup/sql/"$(date +%Y-%m-%d)"-table01.sql.gz sshuser@10.20.30.45:/tmp
# Выполняю на втором сервере ряд заданий в рамках ssh сессии: распаковываю дамп таблицы, очищаю таблицу на этом сервере, заливаю туда данные из дампа
/usr/bin/ssh sshuser@10.20.30.45 '/usr/bin/gunzip /tmp/"$(date +%Y-%m-%d)"-table01.sql.gz && /usr/bin/mysql -e "delete from database01.table01; use database01; source /tmp/"$(date +%Y-%m-%d)"-table01.sql;"'
# Удаляю дамп
/usr/bin/ssh sshuser@10.20.30.45 'rm /tmp/"$(date +%Y-%m-%d)"-table01.sql'
Скрипт простой, можно легко подогнать под свои задачи. Наверное эту задачу смог бы решить и ChatGPT, но я не проверял. Сделал по старинке сам.
Отдельно отмечу для тех, кто не в курсе, что можно вот так запросто тут же после подключения по ssh выполнять какие-то команды в автоматическом режиме. Это удобно и часто пригождается.
#mysql #bash #script
Как быстро прибить приложение, которое слушает определённый порт?
Вариантов решения этой задачи может быть много. Первое, что приходит в голову - посмотреть список открытых портов в ss, узнать pid процесса и завершить его:
Но быстрее и проще воспользоваться lsof:
Или вообще в одно действие:
Lsof могучая утилита. Я как-то особо не пользовался ей, кроме как для файлов, пока не подготовил заметку год назад с примерами использования. С тех порт и для сетевых соединений стал активно применять. Особенно вот в таком виде:
Возвращаюсь к открытым портам. Есть утилита killport, которая делает то же самое, что я делал выше, только в одну команду:
В стандартных репах её нет, придётся качать бинарник из репозитория. Если для Linux это не сильно надо, так как там много инструментов для подобных действий, что я продемонстрировал выше, то для Windows это будет более актуально. Killport есть и под винду (❗️) Использовать можно примерно так:
То есть сначала смотрим, что будет прибито, а потом только делаем.
Такая штука обычно нужна для каких-то костылей и велосипедов, когда что-то зависает, не перезапускается, а надо освободить порт, чтобы запустить новый экземпляр.
#terminal #bash
Вариантов решения этой задачи может быть много. Первое, что приходит в голову - посмотреть список открытых портов в ss, узнать pid процесса и завершить его:
# ss -tulnp | grep 8080tcp LISTEN 0 5 0.0.0.0:8080 0.0.0.0:* users:(("python3",pid=5152,fd=3))# kill 5152Но быстрее и проще воспользоваться lsof:
# lsof -i:8080COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAMEpython3 5156 root 3u IPv4 41738 0t0 TCP *:http-alt (LISTEN)# kill 5152Или вообще в одно действие:
# lsof -i:8080 -t | xargs killLsof могучая утилита. Я как-то особо не пользовался ей, кроме как для файлов, пока не подготовил заметку год назад с примерами использования. С тех порт и для сетевых соединений стал активно применять. Особенно вот в таком виде:
# lsof -i# lsof -i TCP:25# lsof -i TCP@1.2.3.4Возвращаюсь к открытым портам. Есть утилита killport, которая делает то же самое, что я делал выше, только в одну команду:
# killport 8080В стандартных репах её нет, придётся качать бинарник из репозитория. Если для Linux это не сильно надо, так как там много инструментов для подобных действий, что я продемонстрировал выше, то для Windows это будет более актуально. Killport есть и под винду (❗️) Использовать можно примерно так:
> killport 445 --dry-runWould kill process 'System' listening on port 445То есть сначала смотрим, что будет прибито, а потом только делаем.
Такая штука обычно нужна для каких-то костылей и велосипедов, когда что-то зависает, не перезапускается, а надо освободить порт, чтобы запустить новый экземпляр.
#terminal #bash
Вчера в комментариях к заметке со скриптом речь зашла про шебанг (shebang). Слово какое-то непонятное. Я первые года и Unix админил, и скрипты писал, и слова такого не знал, пока случайно не услышал.
Шебанг - это то, с чего начинается практически любой скрипт:
или так
Интуитивно и так было понятно, для чего это. Конструкцию с
Хотя указывать его можно не только так. Но абсолютно во всех дистрибутивах, с которыми я работал, по
Тем не менее, шебанг можно указать и более точно без привязки к конкретному пути в файловой системе:
Расположение bash будет взято из окружения, в котором будет запускаться скрипт. Так писать дольше, поэтому я такую конструкцию не использую.
Вообще, шебанг просто помогает понять, в какой оболочке запускать скрипт. Если его не писать, то эту оболочку придётся явно указывать при запуске скрипта:
А если не указать явно, то будет использована оболочка по умолчанию. Большая часть скриптов, с которыми я работаю, успешно отработает и в sh, и в bash. Именно эти оболочки наиболее распространены, остальное экзотика для серверов. Есть ещё dash, но, насколько я помню, она полностью совместима с sh.
В шебанге можно указать какие-то нюансы интерпретатора. В основном это актуально для python. Он как минимум может быть разных версий на одной и той же системе. Особенно это было актуально во времена перехода с python2 на python3. Когда был только python2 в шебангах могли указать python и скрипт выполнялся 2-й версией, так как именно она была в системе по умолчанию. Когда в системах стала появляться 3-я версия, для старых скриптов надо было отдельно ставить 2-ю и явно её указывать, либо редактируя шебанги в скриптах, либо запуская нужную версию явно:
Из экзотического применения шебангов можно привести примеры с awk или ansible:
И awk, и ansible-playbook являются интерпретаторами кода, так что для простого и быстрого запуска скриптов, написанных для них, можно использовать соответствующие шебанги, чтобы сразу запускать скрипт по аналогии с башем:
На практике я такое применение ни разу не встречал, хотя почему бы и нет. Но лично я всегда всё, что не bash, явно указываю в консоли. Это актуально и для php, код которого не так уж и редко приходится исполнять в консоли сервера.
Строки с шебангом могут содержать дополнительные аргументы, которые передаются интерпретатору (см. пример для awk -f выше). Однако, обработка аргументов может различаться, для переносимости лучше использовать только один аргумент без пробелов внутри. Теоретически это можно обойти в env, но на практике я не проверял. Увидел сам вчера в комментариях:
#bash
Шебанг - это то, с чего начинается практически любой скрипт:
#!/bin/bashили так
#!/bin/shИнтуитивно и так было понятно, для чего это. Конструкцию с
sh я использовал, когда работал с FreeBSD. Перейдя на Linux, стал использовать bash. Причём именно в таком виде:#!/bin/bashХотя указывать его можно не только так. Но абсолютно во всех дистрибутивах, с которыми я работал, по
/bin/bash был именно bash либо в явном виде, либо символьной ссылкой на него. Так что если не хотите лишний раз забивать себе голову новой информацией, то пишите так же. Вероятность, что что-то пойдёт не так, очень мала. У меня ни разу за всю мою карьеру с таким шебангом проблем на Linux с bash скриптами не было. Исключение - контейнеры. Там отсутствие bash - обычное дело. Но там тогда и скрипты не будут нужны.Тем не менее, шебанг можно указать и более точно без привязки к конкретному пути в файловой системе:
#!/usr/bin/env bashРасположение bash будет взято из окружения, в котором будет запускаться скрипт. Так писать дольше, поэтому я такую конструкцию не использую.
Вообще, шебанг просто помогает понять, в какой оболочке запускать скрипт. Если его не писать, то эту оболочку придётся явно указывать при запуске скрипта:
# bash script.shА если не указать явно, то будет использована оболочка по умолчанию. Большая часть скриптов, с которыми я работаю, успешно отработает и в sh, и в bash. Именно эти оболочки наиболее распространены, остальное экзотика для серверов. Есть ещё dash, но, насколько я помню, она полностью совместима с sh.
В шебанге можно указать какие-то нюансы интерпретатора. В основном это актуально для python. Он как минимум может быть разных версий на одной и той же системе. Особенно это было актуально во времена перехода с python2 на python3. Когда был только python2 в шебангах могли указать python и скрипт выполнялся 2-й версией, так как именно она была в системе по умолчанию. Когда в системах стала появляться 3-я версия, для старых скриптов надо было отдельно ставить 2-ю и явно её указывать, либо редактируя шебанги в скриптах, либо запуская нужную версию явно:
# python2 script.pyИз экзотического применения шебангов можно привести примеры с awk или ansible:
#!/usr/bin/awk -f#!/usr/bin/env ansible-playbookИ awk, и ansible-playbook являются интерпретаторами кода, так что для простого и быстрого запуска скриптов, написанных для них, можно использовать соответствующие шебанги, чтобы сразу запускать скрипт по аналогии с башем:
# ./my-playbook.yamlНа практике я такое применение ни разу не встречал, хотя почему бы и нет. Но лично я всегда всё, что не bash, явно указываю в консоли. Это актуально и для php, код которого не так уж и редко приходится исполнять в консоли сервера.
Строки с шебангом могут содержать дополнительные аргументы, которые передаются интерпретатору (см. пример для awk -f выше). Однако, обработка аргументов может различаться, для переносимости лучше использовать только один аргумент без пробелов внутри. Теоретически это можно обойти в env, но на практике я не проверял. Увидел сам вчера в комментариях:
#!/usr/bin/env -S python3 -B -E -s#bash
Пройдусь немного по важной теории по поводу работы в консоли bash. Я в разное время всё это затрагивал в заметках, но информация размазана через большие промежутки в публикациях. Имеет смысл повторить базу.
Покажу сразу очень наглядный пример:
В первом случае ключ не сработал, а во втором сработал, хотя запускал вроде бы одно и то же. А на самом деле нет. В первом примере я запустил echo из состава оболочки bash, а во втором случае - это бинарник в файловой системе. Это по факту разные программы. У них даже ключи разные.
Узнать, что конкретно мы запускаем, проще всего через type:
В первом случае прямо указано, что echo - встроена в оболочку.
И ещё один очень характерный пример:
Очень часто ls это не утилита ls, а алиас с дополнительными параметрами.
Когда вы вводите команду в терминал, происходит следующее:
1️⃣ Проверяются алиасы. Если команда будет там найдена, то поиск остановится и она исполнится.
2️⃣ Далее команда проверяется, встроена в ли она в оболочку, или нет. Если встроена, то выполнится именно она.
3️⃣ Только теперь идёт поиск бинарника в директориях, определённых в
У последнего варианта тоже есть свои нюансы. У вас может быть несколько исполняемых файлов в разных директориях с одинаковым именем. Ситуация нередкая. Можно столкнуться при наличии разных версий python или php в системе. Поиск бинарника ведётся по порядку следования этих директорий в переменной слева направо.
Что раньше будет найдено в директориях, определённых в этой строке, то и будет исполнено.
И ещё важный нюанс по этой теме. Есть привычные команды из оболочки, которых нет в бинарниках. Например, cd.
В выводе последней команды пусто, то есть бинарника
А вот если вы cd используете в юните systemd, то ничего не заработает:
Вот так работать не будет. Systemd не будет запускать автоматом оболочку. Надо это явно указать:
То есть либо явно указывайте bash, либо запускайте скрипт, где bash будет прописан в шебанге.
❗️В связи с этим могу дать совет, который вам сэкономит кучу времени на отладке. Всегда и везде в скриптах, в кронах, в юнитах systemd и т.д. пишите полные пути до бинарников. Команда, в зависимости от пользователя, прав доступа и многих других условий, может быть запущена в разных оболочках и окружениях. Чтобы не было неожиданностей, пишите явно, что вы хотите запустить.
#bash #terminal
Покажу сразу очень наглядный пример:
# echo --version--version# /usr/bin/echo --versionecho (GNU coreutils) 9.1В первом случае ключ не сработал, а во втором сработал, хотя запускал вроде бы одно и то же. А на самом деле нет. В первом примере я запустил echo из состава оболочки bash, а во втором случае - это бинарник в файловой системе. Это по факту разные программы. У них даже ключи разные.
Узнать, что конкретно мы запускаем, проще всего через type:
# type echoecho is a shell builtin# type /usr/bin/echo/usr/bin/echo is /usr/bin/echoВ первом случае прямо указано, что echo - встроена в оболочку.
И ещё один очень характерный пример:
# type lsls is aliased to `ls --color=auto'Очень часто ls это не утилита ls, а алиас с дополнительными параметрами.
Когда вы вводите команду в терминал, происходит следующее:
1️⃣ Проверяются алиасы. Если команда будет там найдена, то поиск остановится и она исполнится.
2️⃣ Далее команда проверяется, встроена в ли она в оболочку, или нет. Если встроена, то выполнится именно она.
3️⃣ Только теперь идёт поиск бинарника в директориях, определённых в
$PATH.У последнего варианта тоже есть свои нюансы. У вас может быть несколько исполняемых файлов в разных директориях с одинаковым именем. Ситуация нередкая. Можно столкнуться при наличии разных версий python или php в системе. Поиск бинарника ведётся по порядку следования этих директорий в переменной слева направо.
# echo $PATH/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/binЧто раньше будет найдено в директориях, определённых в этой строке, то и будет исполнено.
И ещё важный нюанс по этой теме. Есть привычные команды из оболочки, которых нет в бинарниках. Например, cd.
# type cdcd is a shell builtin# which cdВ выводе последней команды пусто, то есть бинарника
cd нет. Если вы будете использовать cd в скриптах, то проблем у вас не будет, так как там обычно в шебанге указан интерпретатор. Обычно это bash или sh, и там cd присутствует.А вот если вы cd используете в юните systemd, то ничего не заработает:
ExecStart=cd /var/www/ ....... && .........Вот так работать не будет. Systemd не будет запускать автоматом оболочку. Надо это явно указать:
ExecStart=/usr/bin/bash -с "cd /var/www/ ......."То есть либо явно указывайте bash, либо запускайте скрипт, где bash будет прописан в шебанге.
❗️В связи с этим могу дать совет, который вам сэкономит кучу времени на отладке. Всегда и везде в скриптах, в кронах, в юнитах systemd и т.д. пишите полные пути до бинарников. Команда, в зависимости от пользователя, прав доступа и многих других условий, может быть запущена в разных оболочках и окружениях. Чтобы не было неожиданностей, пишите явно, что вы хотите запустить.
#bash #terminal
На всех серверах на базе Linux, а раньше и не только Linux, которые настраиваю и обслуживаю сам, изменяю параметры хранения истории команд, то есть history. Настройки обычно добавляю в файл
✅ Для того, чтобы сразу же сохранять в историю введённую команду, использую переменную bash - PROMPT_COMMAND. Содержимое этой переменной выполняется как обычная команда Bash непосредственно перед тем, как Bash отобразит приглашение. Соответственно, команда
✅ Сохранение метки времени вместе с самой командой и вывод её в определённом формате (2024-09-25 16:39:30):
✅ Увеличение числа строк в файле с историей. По умолчанию хранится вроде бы только 500 последних команд, более старые удаляются. Я увеличиваю этот размер до 10000 строк. Ни разу не было, чтобы этого не хватило:
✅ Некоторые команды не сохраняю в истории, так как они не представляют какой-то ценности, только отвлекают и занимают место. Вы можете свой список таких команд вести:
✅ Если я не хочу, чтобы команда попала в историю, то ставлю в консоли перед ней пробел. За это поведение отвечает соответствующий параметр:
Для применения настроек можно выполнить:
Посмотреть свои применённые параметры для истории можно вот так:
Если вы хотите, чтобы эти параметры применялись для всех пользователей сервера, то создайте отдельный файл с настройками, к примеру,
❗️Для поиска по истории нажмите сочетание клавиш Ctrl+r и начните вводить команду. Для перебора множественных совпадений продолжайте нажимать Ctrl+r, пока не найдёте то, что ищите. Я лично привык просто грепать, а не искать в истории:
Тут сразу всё перед глазами, можно быстро либо найти, то, что надо, либо скопировать команду.
⚡️Расскажу про один нюанс, связанный HISTIGNORE, который не раз меня подставлял. У меня в исключениях, к примеру, есть команда htop. Она в историю не попадает. Бывало такое, что я перезагружал сервер командой reboot. Потом загружался и первым делом вводил команду htop, что-то смотрел, закрывал htop. Потом нужно было запустить htop снова. Я на автомате нажимаю стрелку вверх, чтобы запустить последнюю команду, там выскакивает reboot, потому что htop не сохранился, и я тут же жму enter. И сокрушаюсь, что на автомате выполнил не ту команду. Реально много раз на это попадался, правда без последствий. В основном это во время какой-то отладки бывает, там и так перезагрузки идут.
#linux #terminal #bash
🦖 Selectel — дешёвые и не очень дедики с аукционом!
~/.bashrc. Постоянно обращаюсь к истории команд, поэтому стараюсь, чтобы они туда попадали и сохранялись. Покажу свои привычные настройки:✅ Для того, чтобы сразу же сохранять в историю введённую команду, использую переменную bash - PROMPT_COMMAND. Содержимое этой переменной выполняется как обычная команда Bash непосредственно перед тем, как Bash отобразит приглашение. Соответственно, команда
history -a сохраняет историю команд этого сеанса в файл с историей.PROMPT_COMMAND='history -a'✅ Сохранение метки времени вместе с самой командой и вывод её в определённом формате (2024-09-25 16:39:30):
export HISTTIMEFORMAT='%F %T '✅ Увеличение числа строк в файле с историей. По умолчанию хранится вроде бы только 500 последних команд, более старые удаляются. Я увеличиваю этот размер до 10000 строк. Ни разу не было, чтобы этого не хватило:
export HISTSIZE=10000✅ Некоторые команды не сохраняю в истории, так как они не представляют какой-то ценности, только отвлекают и занимают место. Вы можете свой список таких команд вести:
export HISTIGNORE="ls:history:w:htop:pwd:top:iftop"✅ Если я не хочу, чтобы команда попала в историю, то ставлю в консоли перед ней пробел. За это поведение отвечает соответствующий параметр:
export HISTCONTROL=ignorespace Для применения настроек можно выполнить:
# source ~/.bashrcПосмотреть свои применённые параметры для истории можно вот так:
# export | grep -i histЕсли вы хотите, чтобы эти параметры применялись для всех пользователей сервера, то создайте отдельный файл с настройками, к примеру,
history.sh и положите его в директорию /etc/profile.d. Скрипты из этой директории выполняются при запуске шелла пользователя. ❗️Для поиска по истории нажмите сочетание клавиш Ctrl+r и начните вводить команду. Для перебора множественных совпадений продолжайте нажимать Ctrl+r, пока не найдёте то, что ищите. Я лично привык просто грепать, а не искать в истории:
# history | grep 'apt install'Тут сразу всё перед глазами, можно быстро либо найти, то, что надо, либо скопировать команду.
⚡️Расскажу про один нюанс, связанный HISTIGNORE, который не раз меня подставлял. У меня в исключениях, к примеру, есть команда htop. Она в историю не попадает. Бывало такое, что я перезагружал сервер командой reboot. Потом загружался и первым делом вводил команду htop, что-то смотрел, закрывал htop. Потом нужно было запустить htop снова. Я на автомате нажимаю стрелку вверх, чтобы запустить последнюю команду, там выскакивает reboot, потому что htop не сохранился, и я тут же жму enter. И сокрушаюсь, что на автомате выполнил не ту команду. Реально много раз на это попадался, правда без последствий. В основном это во время какой-то отладки бывает, там и так перезагрузки идут.
#linux #terminal #bash
Please open Telegram to view this post
VIEW IN TELEGRAM
Пробую в ежедневной рутине использовать в качестве помощника ИИ. В данном случае я имею ввиду Openchat-3.5-0106, которым пользуюсь. Как я уже отмечал ранее, там, где нужно выдать какую-то справочную информацию или скомбинировать известную информацию, он способен помочь. А где надо немного подумать и что-то написать новое, то уже не очень.
У меня возникла простая задача. В запросах к API на выборку данных нужно указывать год, номер месяца, дни месяца. Это нетрудно сделать с помощью bash. Решил сразу задать вопрос боту и посмотреть результат. Сформулировал запрос так:
Напиши bash скрипт, который будет показывать текущую дату, номер текущего месяца, текущий год, первый и последний день текущего месяца, прошлого месяца и будущего месяца.
Получил на выходе частично работающий скрипт. Текущий год, месяц и дату показывает, первые дни нет. Вот скрипт, который предложил ИИ.
Гугл первой же ссылкой дал правильный ответ на stackexchange. Идею я понял, немного переделал скрипт под свои потребности. То есть сделал сразу себе мини-шпаргалку, заготовку. Получилось вот так:
Можете себе забрать, если есть нужда работать с датами. Иногда это нужно для работы с бэкапами, которые по маске с датой создаются. Директории удобно по месяцам и годам делать. Потом оттуда удобно забирать данные или чистить старое. То же самое с API. К ним часто нужно указывать интервал запроса. Года, месяцы, даты чаще всего отдельными переменными идут.
Проверять подобные скрипты удобно с помощью faketime:
Я в своей деятельности пока не вижу какой-то значимой пользы от использования ИИ. Не было так, что вот задал ему вопрос и получил готовый ответ.
#bash #script
У меня возникла простая задача. В запросах к API на выборку данных нужно указывать год, номер месяца, дни месяца. Это нетрудно сделать с помощью bash. Решил сразу задать вопрос боту и посмотреть результат. Сформулировал запрос так:
Напиши bash скрипт, который будет показывать текущую дату, номер текущего месяца, текущий год, первый и последний день текущего месяца, прошлого месяца и будущего месяца.
Получил на выходе частично работающий скрипт. Текущий год, месяц и дату показывает, первые дни нет. Вот скрипт, который предложил ИИ.
Гугл первой же ссылкой дал правильный ответ на stackexchange. Идею я понял, немного переделал скрипт под свои потребности. То есть сделал сразу себе мини-шпаргалку, заготовку. Получилось вот так:
#!/bin/bash
CUR_DATE=$(date "+%F")
CUR_YEAR=$(date "+%Y")
CUR_MONTH=$(date "+%m")
DAY_CUR_START_FULL=$(date +%Y-%m-01)
DAY_CUR_START=$(date "+%d" -d $(date +'%Y-%m-01'))
DAY_CUR_END_FULL=$(date -d "`date +%Y%m01` +1 month -1 day" +%Y-%m-%d)
DAY_CUR_END=$(date "+%d" -d "$DAY_CUR_START_FULL +1 month -1 day")
LAST_MONTH_DATE=$(date "+%F" -d "$(date +'%Y-%m-01') -1 month")
LAST_MONTH_YEAR=$(date "+%Y" -d "$(date +'%Y-%m-01') -1 month")
LAST_MONTH=$(date "+%m" -d "$(date +'%Y-%m-01') -1 month")
DAY_LAST_START=$(date "+%d" -d "$(date +'%Y-%m-01') -1 month")
DAY_LAST_START_FULL=$(date "+%Y-%m-01" -d "$(date +'%Y-%m-01') -1 month")
DAY_LAST_END=$(date "+%d" -d "$LAST_MONTH_DATE +1 month -1 day")
DAY_LAST_END_FULL=$(date -d "$LAST_MONTH_DATE +1 month -1 day" +%Y-%m-%d)
echo -e "\n"
echo "Полная текущая дата: $CUR_DATE"
echo "Текущий год: $CUR_YEAR"
echo "Номер текущего месяца: $CUR_MONTH"
echo "Первый день этого месяца: $DAY_CUR_START_FULL, $DAY_CUR_START"
echo "Последний день этого месяца: $DAY_CUR_END_FULL, $DAY_CUR_END"
echo -e "\n"
echo "Начало прошлого месяца: $LAST_MONTH_DATE"
echo "Год прошлого месяца: $LAST_MONTH_YEAR"
echo "Номер прошлого месяца: $LAST_MONTH"
echo "Первый день прошлого месяца: $DAY_LAST_START_FULL, $DAY_LAST_START"
echo "Последний день прошлого месяца: $DAY_LAST_END_FULL, $DAY_LAST_END"
echo -e "\n"
Можете себе забрать, если есть нужда работать с датами. Иногда это нужно для работы с бэкапами, которые по маске с датой создаются. Директории удобно по месяцам и годам делать. Потом оттуда удобно забирать данные или чистить старое. То же самое с API. К ним часто нужно указывать интервал запроса. Года, месяцы, даты чаще всего отдельными переменными идут.
Проверять подобные скрипты удобно с помощью faketime:
# apt install faketime# faketime '2024-01-05' bash date.shЯ в своей деятельности пока не вижу какой-то значимой пользы от использования ИИ. Не было так, что вот задал ему вопрос и получил готовый ответ.
#bash #script
Небольшая практическая шпаргалка, которая с большой долей вероятности пригодится, если работаете с текстом в консоли Linux или каких-то других редакторах. Я взял для примера VSCode и Notepad++, с которыми сам работаю. Последний по старой памяти. Особой нужды в нём нет, но он, как и Total Commander, навечно прописался в моём компьютере.
Добавить в конец каждой строки переход на новую строку
🟡 С помощью sed:
Заменили анкор
🟡 С помощью VSCode:
Открываем окно поиска и замены через Ctrl + H. В строке поиска пишем
🟡 С помощью Notepad++:
Открываем окно поиска через Ctrl + F, переходим на вкладку замена. Ищем
По аналогии можно добавить в конец любой другой символ. Я взял переход на новую строку как наиболее сложный вариант замены.
Добавить символы в начало каждой строки
🟢 С помощью sed:
Добавили фразу +7 в начало каждой строки.
🟢 С помощью VSCode:
Открываем окно поиска и замены через Ctrl + H. В строке поиска пишем
🟢 С помощью Notepad++:
Открываем окно поиска через Ctrl + F, переходим на вкладку замена. Ищем
Оба упомянутых анкора
Отобразили конфиг без строк, начинающихся с # , ; и пустых строк.
Кстати, я первый вопрос с sed решил задать chatgpt. И на удивление, он мне дал неправильный ответ на такой простой вопрос. Добавил лишнее экранирование. Не понимаю, как он некоторым программировать помогает или шаблоны для Zabbix пишет. Я как не обращусь к нему, регулярно получаю ошибки. Если ты не в теме, то эти ошибки сложно исправлять.
По этой теме у меня уже была ранее заметка, только с акцентом на grep, а не изменение данных. Если не видели, рекомендую посмотреть и сохранить. Там много примеров из моей практики.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#bash
Добавить в конец каждой строки переход на новую строку
🟡 С помощью sed:
# sed 's/$/\n/' file.txt > new_file.txtЗаменили анкор
$, означающий конец строки на специальный символ \n - новая строка.🟡 С помощью VSCode:
Открываем окно поиска и замены через Ctrl + H. В строке поиска пишем
$ и жмём кнопку .*, что означает использование регулярных выражений. В качестве замены указываем /n и жмём заменить всё.🟡 С помощью Notepad++:
Открываем окно поиска через Ctrl + F, переходим на вкладку замена. Ищем
\r, заменяем на \n. Режим поиска ставим Расширенный. По аналогии можно добавить в конец любой другой символ. Я взял переход на новую строку как наиболее сложный вариант замены.
Добавить символы в начало каждой строки
🟢 С помощью sed:
# sed 's/^/+7/' file.txt > new_file.txtДобавили фразу +7 в начало каждой строки.
🟢 С помощью VSCode:
Открываем окно поиска и замены через Ctrl + H. В строке поиска пишем
^ и жмём кнопку .*, что означает использование регулярных выражений. В качестве замены указываем +7 и жмём заменить всё.🟢 С помощью Notepad++:
Открываем окно поиска через Ctrl + F, переходим на вкладку замена. Ищем
^, заменяем на +7. Режим поиска ставим Регулярные выражения.Оба упомянутых анкора
^$ вместе означают пустую строку. Можно так же заменять или удалять пустые строки. Актуально для больших конфигов, которые хочется почистить. Примерно так:# sed '/^#\|^;\|^$/d' php.ini# grep -E -v '^#|^;|^$' php.iniОтобразили конфиг без строк, начинающихся с # , ; и пустых строк.
Кстати, я первый вопрос с sed решил задать chatgpt. И на удивление, он мне дал неправильный ответ на такой простой вопрос. Добавил лишнее экранирование. Не понимаю, как он некоторым программировать помогает или шаблоны для Zabbix пишет. Я как не обращусь к нему, регулярно получаю ошибки. Если ты не в теме, то эти ошибки сложно исправлять.
По этой теме у меня уже была ранее заметка, только с акцентом на grep, а не изменение данных. Если не видели, рекомендую посмотреть и сохранить. Там много примеров из моей практики.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#bash