
Написал небольшое сравнение Zabbix и Prometheus, как вижу это я. Сразу говорю, что сравнение полностью субъективное, так как сам в основном использую Zabbix, а Пром изучал на курсах, плюс делал тестовые установки у себя. У меня под него просто нет задач.
Так что для объективности нужны комментарии и замечания от тех, кто как минимум, хорошо знает Prometheus, а в идеале обоих.
https://serveradmin.ru/sravnenie-zabbix-vs-prometheus/
Какой мониторинг используете у себя?
#статья #zabbix #prometheus
Так что для объективности нужны комментарии и замечания от тех, кто как минимум, хорошо знает Prometheus, а в идеале обоих.
https://serveradmin.ru/sravnenie-zabbix-vs-prometheus/
Какой мониторинг используете у себя?
#статья #zabbix #prometheus
Server Admin
Сравнение Zabbix vs Prometheus | serveradmin.ru
Наглядное сравнение двух популярных систем мониторинга - Zabbix и Prometheus. Отмечены наиболее существенные отличия.
Некоторое время назад я обновил статью по Zabbix на тему проверки времени делегирования доменов. В комментариях один читатель сказал, что как-то все сложно. В prometheus все проще и быстрее, так как есть готовый экспортер. Я посмотрел на него, действительно, все просто, так как есть готовый контейнер docker. Запустил его, погонял сервис и просто прикрутил передачу данных из этого экспортера в Zabbix. Теперь в нем тоже все стало просто и быстро 🙂
Нужно иметь ввиду, что данная простота скрывает в себе риски по безопасности. Да, удобно и быстро запустить готовый контейнер, но что там внутри и кто его собирал? Если все внимательно проверять, то потратишь столько же времени, сколько я потратил на самостоятельное написание скриптов проверки делегирования доменов на баше, питоне или руби. Примеры есть в статье. Так что надо понимать, что не все простое и быстрое полезно.
В моей статье пример с автообнаружением доменов из списка в текстовом файле. Если вам не нужно автообнаружение, то можно вообще обойтись без скриптов, так как данные можно забирать напрямую с zabbix-server через HTTP агента. Только для каждого домена придется вручную item создавать. Как в таком случае сделать автообнаружение доменов без скриптов я не очень представляю.
Чуть позже то же самое сделаю и для мониторинга ssl сертификатов. У прома тоже для этого экспортер есть.
https://serveradmin.ru/monitoring-vremeni-delegirovaniya-domena-v-zabbix/#Prometheus_domain_exporter
#статья #zabbix
Нужно иметь ввиду, что данная простота скрывает в себе риски по безопасности. Да, удобно и быстро запустить готовый контейнер, но что там внутри и кто его собирал? Если все внимательно проверять, то потратишь столько же времени, сколько я потратил на самостоятельное написание скриптов проверки делегирования доменов на баше, питоне или руби. Примеры есть в статье. Так что надо понимать, что не все простое и быстрое полезно.
В моей статье пример с автообнаружением доменов из списка в текстовом файле. Если вам не нужно автообнаружение, то можно вообще обойтись без скриптов, так как данные можно забирать напрямую с zabbix-server через HTTP агента. Только для каждого домена придется вручную item создавать. Как в таком случае сделать автообнаружение доменов без скриптов я не очень представляю.
Чуть позже то же самое сделаю и для мониторинга ssl сертификатов. У прома тоже для этого экспортер есть.
https://serveradmin.ru/monitoring-vremeni-delegirovaniya-domena-v-zabbix/#Prometheus_domain_exporter
#статья #zabbix
Server Admin
Мониторинг времени делегирования домена в zabbix
Пример настройки мониторинга за временем делегирования домена с помощью Zabbix и внешнего скрипта. Все скрипты и готовый шаблон представлены.
Для Prometheus существует множество готовых решений для учёта SLA или SLO. Я уже помнится писал про одну - SLO tracker. Сейчас посмотрел похожую панельку, но она мне понравилась больше - Pyrra (https://github.com/pyrra-dev/pyrra). Выглядит симпатичнее и настраивается проще.
Для тех, кто захочет попробовать, в репе лежит пример с готовым docker-compose.yaml и конфигом pyrra, где в качестве примера взята метрика prometheus_http_requests_total и 5XX ошибки для неё. Сам конфиг в директории pyrra. Можно наглядно оценить, насколько просто и быстро она настраивается.
Готовая демка есть тут - https://demo.pyrra.dev. Можно посмотреть, как всё это выглядит. В репозитории есть все инструкции и описание, так что запустить не трудно. Мне хотелось бы что-то подобное получить для Zabbix, но ничего похожего и раньше не видел, и сейчас не смог найти. Всё самое современное, удобное, быстро настраиваемое пишут под пром.
Даже и не знаю, переползать на него что ли потихоньку в каких-то случаях. Не хочется две системы использовать, но сейчас реально гораздо быстрее и проще поднять мониторинг на Prometheus. Под него все экспортеры есть и готовые шаблоны, инструменты на любой вкус.
#devops #prometheus
Для тех, кто захочет попробовать, в репе лежит пример с готовым docker-compose.yaml и конфигом pyrra, где в качестве примера взята метрика prometheus_http_requests_total и 5XX ошибки для неё. Сам конфиг в директории pyrra. Можно наглядно оценить, насколько просто и быстро она настраивается.
Готовая демка есть тут - https://demo.pyrra.dev. Можно посмотреть, как всё это выглядит. В репозитории есть все инструкции и описание, так что запустить не трудно. Мне хотелось бы что-то подобное получить для Zabbix, но ничего похожего и раньше не видел, и сейчас не смог найти. Всё самое современное, удобное, быстро настраиваемое пишут под пром.
Даже и не знаю, переползать на него что ли потихоньку в каких-то случаях. Не хочется две системы использовать, но сейчас реально гораздо быстрее и проще поднять мониторинг на Prometheus. Под него все экспортеры есть и готовые шаблоны, инструменты на любой вкус.
#devops #prometheus
{kind=link}
Технический пост, который уже давно нужно было сделать, но всё руки не доходили. На канале много содержательных заметок по различным темам. Иногда сам через поиск ищу то, о чём писал. Ниже набор наиболее популярных тэгов по которым можно найти что-то полезное (и не очень).
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
#remote - все, что касается удалённого управления компьютерами
#helpdesk - обзор helpdesk систем
#backup - софт для бэкапа и некоторые мои заметки по теме
#zabbix - всё, что касается системы мониторинга Zabbix
#мониторинг - в этот тэг иногда попадает Zabbix, но помимо него перечислено много различных систем мониторинга
#управление #ITSM - инструменты для управления инфраструктурой
#devops - в основном софт, который так или иначе связан с методологией devops
#kuber - небольшой цикл постов про работу с kubernetes
#chat - мои обзоры на популярные чат платформы, которые можно развернуть у себя
#бесплатно - в основном подборка всяких бесплатностей, немного бесплатных курсов
#сервис - сервисы, которые мне показались интересными и полезными
#security - заметки, так или иначе связанные с безопасностью
#webserver - всё, что касается веб серверов
#gateway - заметки на тему шлюзов
#mailserver - всё, что касается почтовых серверов
#elk - заметки по ELK Stack
#mikrotik - очень много заметок про Mikrotik
#proxmox - заметки о популярном гипервизоре Proxmox
#terminal - всё, что связано с работой в терминале
#bash - заметки с примерами полезных и не очень bash скриптов или каких-то команд. По просмотрам, комментариям, сохранениям самая популярная тематика канала.
#windows - всё, что касается системы Windows
#хостинг - немного информации и хостерах, в том числе о тех, кого использую сам
#vpn - заметки на тему VPN
#perfomance - анализ производительности сервера и профилирование нагрузки
#курсы - под этим тэгом заметки на тему курсов, которые я сам проходил, которые могу порекомендовать, а также некоторые бесплатные курсы
#игра - игры исключительно IT тематики, за редким исключением
#совет - мои советы на различные темы, в основном IT
#подборка - посты с компиляцией нескольких продуктов, объединённых одной тематикой
#отечественное - обзор софта из реестра отечественного ПО
#юмор - большое количество каких-то смешных вещей на тему IT, которые я скрупулезно выбирал, чтобы показать вам самое интересное. В самом начале есть шутки, которые придумывал сам, проводил конкурсы.
#мысли - мои рассуждения на различные темы, не только IT
#разное - этим тэгом маркирую то, что не подошло ни под какие другие, но при этом не хочется, чтобы материал терялся, так как я посчитал его полезным
#дети - информация на тему обучения и вовлечения в IT детей
#развитие_канала - серия постов на тему развития данного telegram канала
Остальные тэги публикую общим списком без комментариев, так как они про конкретный софт, понятный из названия тэга:
#docker #nginx #mysql #postgresql #gitlab #asterisk #openvpn #lxc #postfix #bitrix #икс #debian #hyperv #rsync #wordpress #zfs #grafana #iptables #prometheus #1с #waf #logs #netflow
▶️ Я подписываюсь и слежу практически за всеми авторскими каналами в youtube по системному администрированию. Ранее делал подборку подобных каналов, но она устарела и требует актуализации и дополнения. Возможно соберусь и сделаю это.
А сейчас хочу порекомендовать ещё один интересный канал от практикующего сисдамина и девопса, про который я сам узнал из комментариев на днях - #linux life ( https://www.youtube.com/c/linuxlifepage )
Я посмотрел некоторые видео и мне они показались полезными. Много практики, где автор просто берёт и что-то настраивает, а нам записывает свои действия в терминале и не только.
Вот примеры полезных видео:
Secure FTP - Быстрая установка FTP сервера с помощью Ansible
aaPanel - БЕСПЛАТНАЯ web-панель для ARM серверов!
Wireguard portal - веб интерфейс для управления
Grafana #Prometheus - МОНИТОРИМ сервера
Если знаете хорошие авторские каналы по IT тематике (но не программирование), делитесь в комментариях.
#видео
А сейчас хочу порекомендовать ещё один интересный канал от практикующего сисдамина и девопса, про который я сам узнал из комментариев на днях - #linux life ( https://www.youtube.com/c/linuxlifepage )
Я посмотрел некоторые видео и мне они показались полезными. Много практики, где автор просто берёт и что-то настраивает, а нам записывает свои действия в терминале и не только.
Вот примеры полезных видео:
Secure FTP - Быстрая установка FTP сервера с помощью Ansible
aaPanel - БЕСПЛАТНАЯ web-панель для ARM серверов!
Wireguard portal - веб интерфейс для управления
Grafana #Prometheus - МОНИТОРИМ сервера
Если знаете хорошие авторские каналы по IT тематике (но не программирование), делитесь в комментариях.
#видео
{kind=link}
Когда у вас много независимых друг от друга мониторингов, возникает проблема за контролем всего этого хозяйства. Лично я для Zabbix использую интеграцию с Grafana и делаю на последней дашборд с выводом триггеров с нескольких Zabbix серверов. Меня вполне устраивает такое решение для быстрого просмотра состояния нескольких (у меня 6) серверов мониторинга.
Подозреваю, что для Prometheus и его Alertmanager тоже должно быть что-то похоже на базе Grafana, но я сегодня хочу вам рассказать про другой дашборд, который может объединять в себе события от нескольких Alertmanager. Это программа под названием Karma - https://github.com/prymitive/karma, которая как раз представляет из себя Alert dashboard для Prometheus Alertmanager.
У Karma плиточный интерфейс с возможностью настройки под свой вкус. В примерах из репозитория он разукрашен, как новогодняя ёлка. Лично мне не кажется это удобным и наглядным, но это дело вкуса. Можно брать цвета одного оттенка. Внешний вид оптимизирован для отображения на смартфонах.
Конфиг у Karma, как не трудно догадаться, в формате yaml и в общем случае довольно простой. В репозитории есть пример с подключением локального alertmanager. Для удалённых просто uri будет отличаться и их будет несколько. Для самой простой настройки достаточно их подключить в режиме readonly:
Для аутентификации в Karma есть 2 способа: basic auth или передача учётных данных через header в запросе. А для авторизации - ACL списки. То есть этот продукт подходит для работы различных команд с разграничением доступа к поступающим оповещениям. Ограничение доступа работает не на просмотр, а на возможность подавления оповещения.
Demo - https://karma-demo.herokuapp.com
Исходники - https://github.com/prymitive/karma
Обзор и пример настройки - https://www.youtube.com/watch?v=pLI8-gHgedA
#prometheus #мониторинг #devops
Подозреваю, что для Prometheus и его Alertmanager тоже должно быть что-то похоже на базе Grafana, но я сегодня хочу вам рассказать про другой дашборд, который может объединять в себе события от нескольких Alertmanager. Это программа под названием Karma - https://github.com/prymitive/karma, которая как раз представляет из себя Alert dashboard для Prometheus Alertmanager.
У Karma плиточный интерфейс с возможностью настройки под свой вкус. В примерах из репозитория он разукрашен, как новогодняя ёлка. Лично мне не кажется это удобным и наглядным, но это дело вкуса. Можно брать цвета одного оттенка. Внешний вид оптимизирован для отображения на смартфонах.
Конфиг у Karma, как не трудно догадаться, в формате yaml и в общем случае довольно простой. В репозитории есть пример с подключением локального alertmanager. Для удалённых просто uri будет отличаться и их будет несколько. Для самой простой настройки достаточно их подключить в режиме readonly:
servers: - name: prod uri: https://user:password@prod.alert.example.com timeout: 20s proxy: false readonly: true - name: dev uri: https://user:password@dev.alert.example.com timeout: 20s proxy: false readonly: trueДля аутентификации в Karma есть 2 способа: basic auth или передача учётных данных через header в запросе. А для авторизации - ACL списки. То есть этот продукт подходит для работы различных команд с разграничением доступа к поступающим оповещениям. Ограничение доступа работает не на просмотр, а на возможность подавления оповещения.
Demo - https://karma-demo.herokuapp.com
Исходники - https://github.com/prymitive/karma
Обзор и пример настройки - https://www.youtube.com/watch?v=pLI8-gHgedA
#prometheus #мониторинг #devops
{kind=link}
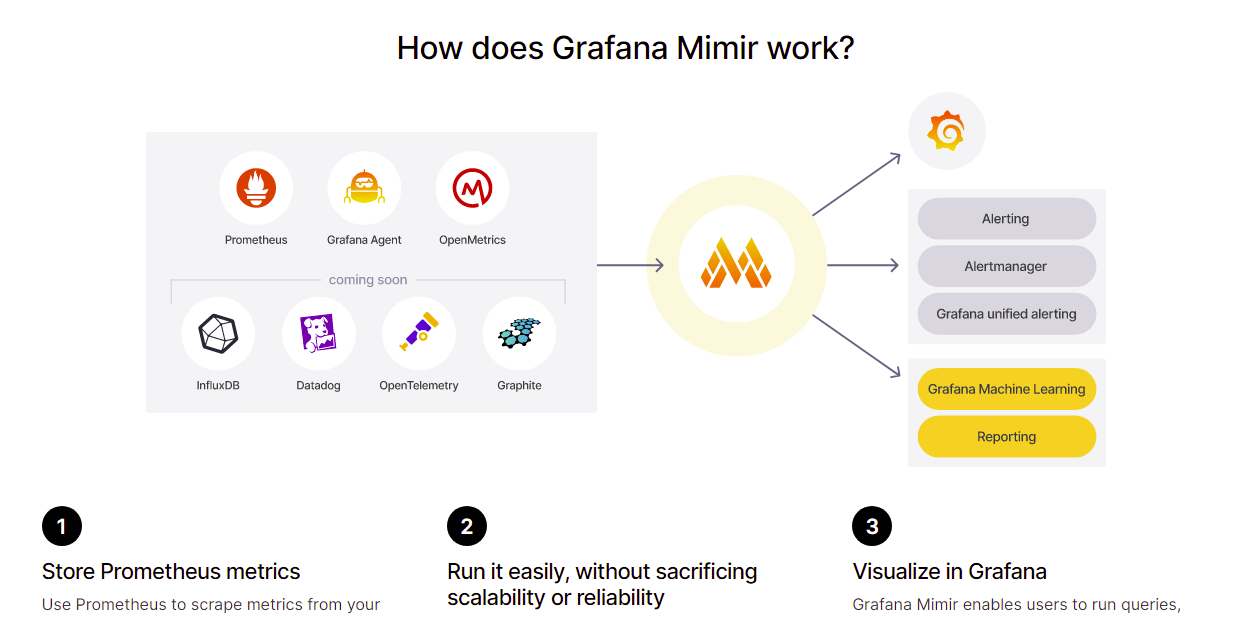
Долгосрочное хранение метрик всегда было одной из слабых сторон Prometheus. Изначально он был спроектирован для оперативного мониторинга, не подразумевающего хранение истории метрик на срок более двух недель. Сохранить в нём тренды месячных или годовых интервалов было отдельной задачей с привлечением внешних хранилищ и инструментов.
Весной Grafana анонсировала своё решение под названием Grafana Mimir, которое способно максимально просто, быстро и дёшево решить вопрос с долгосрочным хранением метрик в том числе с помощью S3 совместимого хранилища. В самом простом варианте может на файловую систему складывать данные. Одним из основных преимуществ указывается возможность быстро и просто настроить горизонтально масштабируемый high availability кластер хранения.
Настроить всё это дело реально очень просто.
1️⃣ Поднимаете в Docker сервер Mimir, указав в его конфиге бэкенд для хранения данных. В самом простом случае это может быть локальная директория.
2️⃣ Указываете в Prometheus в качестве remote_write сервер с Mimir.
3️⃣ В веб панели Grafana добавляете сервер Mimir в качестве Prometheus data source.
Авторы Mimir называют её самой производительной TSDB для долговременного хранения метрик Prometheus. Насколько это правда, трудно судить. Вот пример их нагрузочных тестов. Авторы конкурирующего хранилища из VictoriaMetrics собрали свои стенды с обоими продуктами и протестировали их производительность. В результате оказалось, что Mimir более требовательна к памяти, больше нагружает процессор и больше расходует места хранилища, но имеет ниже задержку в 50-м перцентиле и выше в 99-м. По результатам теста почти по всем параметрам Mimir хуже, причем с кратной разницей, что немного странно.
Ниже ссылка на get started, где в самом начале представлено наглядное видео по настройке связки Prometheus + Grafana + Mimir + MinIO.
Сайт - https://grafana.com/oss/mimir/
Исходники - https://github.com/grafana/mimir
Get started - https://grafana.com/docs/mimir/v2.3.x/operators-guide/get-started/
#prometheus #grafana #devops #мониторинг
Весной Grafana анонсировала своё решение под названием Grafana Mimir, которое способно максимально просто, быстро и дёшево решить вопрос с долгосрочным хранением метрик в том числе с помощью S3 совместимого хранилища. В самом простом варианте может на файловую систему складывать данные. Одним из основных преимуществ указывается возможность быстро и просто настроить горизонтально масштабируемый high availability кластер хранения.
Настроить всё это дело реально очень просто.
1️⃣ Поднимаете в Docker сервер Mimir, указав в его конфиге бэкенд для хранения данных. В самом простом случае это может быть локальная директория.
2️⃣ Указываете в Prometheus в качестве remote_write сервер с Mimir.
3️⃣ В веб панели Grafana добавляете сервер Mimir в качестве Prometheus data source.
Авторы Mimir называют её самой производительной TSDB для долговременного хранения метрик Prometheus. Насколько это правда, трудно судить. Вот пример их нагрузочных тестов. Авторы конкурирующего хранилища из VictoriaMetrics собрали свои стенды с обоими продуктами и протестировали их производительность. В результате оказалось, что Mimir более требовательна к памяти, больше нагружает процессор и больше расходует места хранилища, но имеет ниже задержку в 50-м перцентиле и выше в 99-м. По результатам теста почти по всем параметрам Mimir хуже, причем с кратной разницей, что немного странно.
Ниже ссылка на get started, где в самом начале представлено наглядное видео по настройке связки Prometheus + Grafana + Mimir + MinIO.
Сайт - https://grafana.com/oss/mimir/
Исходники - https://github.com/grafana/mimir
Get started - https://grafana.com/docs/mimir/v2.3.x/operators-guide/get-started/
#prometheus #grafana #devops #мониторинг
{kind=link}
Я вчера рассказал, как собрать Nginx с модулем статистики vts. Расскажу теперь, как его настроить и собрать метрики в систему мониторинга Prometheus.
Для настройки статистики вам достаточно добавить в основной файл конфигурации
И в любой виртуальных хост ещё один location. Я обычно в default добавляю:
Теперь можно сходить по ip адресу сервера и посмотреть статистику прямо в браузере - http://10.20.1.56/status/. Сразу покажу ещё два важных и полезных урла: /status/format/json и /status/format/prometheus. По ним вы заберёте метрики в формате json или prometheus. Последняя ссылка нам будет нужна далее. Я покажу настройку мониторинга Nginx на примере Prometheus, так как это самый быстрый вариант. Имея все метрики в json формате, нетрудно и в Zabbix всё это закинуть через предобработку с помощью jsonpath, но времени побольше уйдёт.
Устанавливаем Prometheus. Нам нужен будет любой хост с Docker. Готовим конфиг, куда сразу добавим сервер с Nginx:
Это по сути стандартный конфиг, куда я добавил ещё один target nginx_vts. Запускаем Prometheus:
Идём на ip адрес хоста и порт 9090, где запущен Prometheus. Убеждаемся, что он работает, а в разделе Status -> Targets наш Endpoint nginx_vts доступен. Можете взять метрики со страницы /status/format/prometheus и подёргать их в Prometheus. Разбирать работу с ним не буду, так как это отдельная история.
Теперь ставим Grafana, можно на этот же хост с Prometheus:
Идём на ip адрес и порт 3000, видим интерфейс Графаны. Учётка по умолчанию admin / admin. Идём в раздел Administration -> Data sources и добавляем новый типа Prometheus. Из необходимых настроек достаточно указать только URL прома. В моём случае http://172.27.60.187:9090.
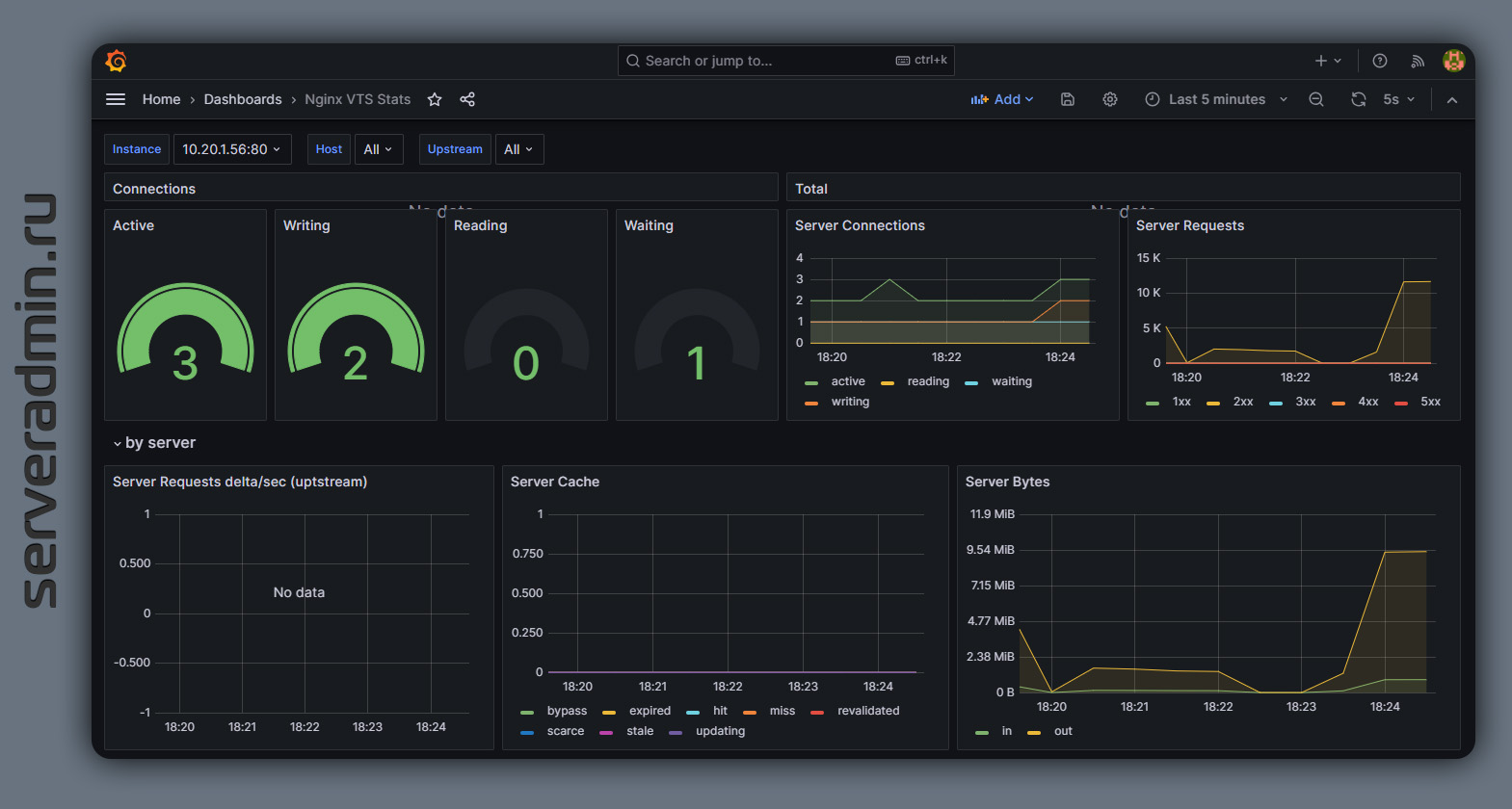
Теперь нам надо добавить готовый Dashboard для Nginx VTS. Их представлено штук 10 на сайте Grafana, но реально актуальный и работающий без доработки только один - https://grafana.com/grafana/dashboards/14824-nginx-vts-stats/. Соответственно, в разделе Dashboards Графаны нажимаем Import и указываем URL приведённого выше дашборда. Все основные метрики вы увидите на нём. Если надо добавить что-то ещё, то идёте на /status/format/prometheus, смотрите метрику и добавляете запрос с ней в Grafana.
Если с Prometheus не работали ранее, то подобное описание возможно не очень подробное, но в рамках заметки тему не раскрыть. Зато когда разберётесь и научитесь, настройка такого мониторинга будет занимать минут 10. Даже если в готовом дашборде что-то не будет работать, нетрудно подредактировать. Как Grafana, так и VTS модуль активно развиваются, поэтому старые дашборды в основном нерабочие. Но тут метрик не так много, так что не критично. Можно либо поправить, либо самому всё сделать.
На картинке всё не уместилось. Ниже ещё статистика по бэкендам будет. Примеры можно посмотреть в описании дашборда на сайте Grafana.
#nginx #мониторинг #prometheus #grafana
Для настройки статистики вам достаточно добавить в основной файл конфигурации
nginx.conf в секцию http:vhost_traffic_status_zone;И в любой виртуальных хост ещё один location. Я обычно в default добавляю:
server { listen 80; server_name localhost;.........................location /status { vhost_traffic_status_display; vhost_traffic_status_display_format html;}..................Теперь можно сходить по ip адресу сервера и посмотреть статистику прямо в браузере - http://10.20.1.56/status/. Сразу покажу ещё два важных и полезных урла: /status/format/json и /status/format/prometheus. По ним вы заберёте метрики в формате json или prometheus. Последняя ссылка нам будет нужна далее. Я покажу настройку мониторинга Nginx на примере Prometheus, так как это самый быстрый вариант. Имея все метрики в json формате, нетрудно и в Zabbix всё это закинуть через предобработку с помощью jsonpath, но времени побольше уйдёт.
Устанавливаем Prometheus. Нам нужен будет любой хост с Docker. Готовим конфиг, куда сразу добавим сервер с Nginx:
# mkdir prom_data && cd prom_data && touch prometheus.yamlglobal: scrape_interval: 5s evaluation_interval: 5srule_files:scrape_configs: - job_name: prometheus static_configs: - targets: ['localhost:9090'] - job_name: nginx_vts metrics_path: '/status/format/prometheus' static_configs: - targets: ['10.20.1.56:80']Это по сути стандартный конфиг, куда я добавил ещё один target nginx_vts. Запускаем Prometheus:
# docker run -p 9090:9090 -d --name=prom \-v ~/prom_data/prometheus.yaml:/etc/prometheus/prometheus.yml \ prom/prometheusИдём на ip адрес хоста и порт 9090, где запущен Prometheus. Убеждаемся, что он работает, а в разделе Status -> Targets наш Endpoint nginx_vts доступен. Можете взять метрики со страницы /status/format/prometheus и подёргать их в Prometheus. Разбирать работу с ним не буду, так как это отдельная история.
Теперь ставим Grafana, можно на этот же хост с Prometheus:
# docker run -p 3000:3000 -d --name=grafana grafana/grafanaИдём на ip адрес и порт 3000, видим интерфейс Графаны. Учётка по умолчанию admin / admin. Идём в раздел Administration -> Data sources и добавляем новый типа Prometheus. Из необходимых настроек достаточно указать только URL прома. В моём случае http://172.27.60.187:9090.
Теперь нам надо добавить готовый Dashboard для Nginx VTS. Их представлено штук 10 на сайте Grafana, но реально актуальный и работающий без доработки только один - https://grafana.com/grafana/dashboards/14824-nginx-vts-stats/. Соответственно, в разделе Dashboards Графаны нажимаем Import и указываем URL приведённого выше дашборда. Все основные метрики вы увидите на нём. Если надо добавить что-то ещё, то идёте на /status/format/prometheus, смотрите метрику и добавляете запрос с ней в Grafana.
Если с Prometheus не работали ранее, то подобное описание возможно не очень подробное, но в рамках заметки тему не раскрыть. Зато когда разберётесь и научитесь, настройка такого мониторинга будет занимать минут 10. Даже если в готовом дашборде что-то не будет работать, нетрудно подредактировать. Как Grafana, так и VTS модуль активно развиваются, поэтому старые дашборды в основном нерабочие. Но тут метрик не так много, так что не критично. Можно либо поправить, либо самому всё сделать.
На картинке всё не уместилось. Ниже ещё статистика по бэкендам будет. Примеры можно посмотреть в описании дашборда на сайте Grafana.
#nginx #мониторинг #prometheus #grafana
{kind=link}
Предлагаю вашему вниманию любопытный проект по мониторингу одиночного хоста с Docker - domolo. Сразу скажу, что это продукт уровня курсовой работы с каких-нибудь курсов по DevOps на тему мониторинга. Он представляет из себя преднастроенный набор контейнеров на современном стеке.
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
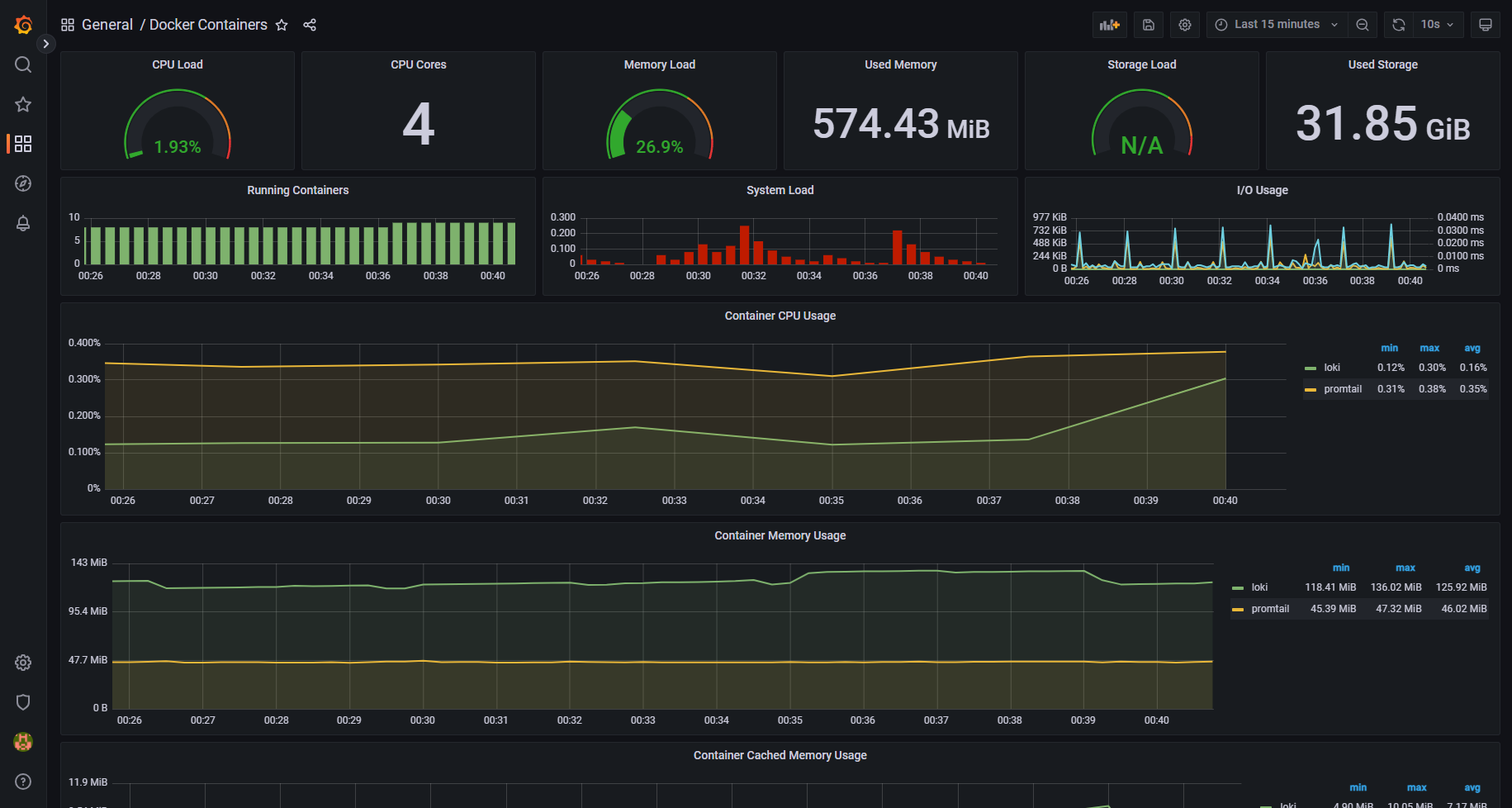
Идём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
Domolo состоит из:
◽Prometheus вместе с Pushgateway, AlertManager и Promtail
◽Grafana с набором дашбордов
◽Loki для сбора логов с хоста и контейнеров
◽NodeExporter - для сбора метрик хоста
◽cAdvisor - для сбора метрик контейнеров
◽Caddy - реверс прокси для prometheus и alertmanager
Сначала подумал, что это какая-та ерунда. Не думал, что заработает без напильника. Но, на моё удивление, это не так. Всё заработало вообще сразу:
# git clone https://github.com/ductnn/domolo.git# cd domolo# docker-compose up -dИдём в Grafana по адресу http://ip-хоста:3000, учётка admin / changeme. Здесь мы можем наблюдать уже настроенные дашборды на все случаи жизни. Там есть буквально всё, что надо и не надо. Loki и сбор логов тоже работает сразу же без напильника. Идём в Explore, выбираем Datasource Loki и смотрим логи.
Если вам нужно мониторить одиночный хост с контейнерами, то это прям полностью готовое решение. Запускаете и наслаждаетесь. Репозиторий domolo удобен и для того, чтобы научиться всё это дело настраивать. Все конфиги и docker-compose файлы присутствуют. На мой взгляд для обучения это удобнее, чем какая-нибудь статья или обучающее видео. Здесь всё в одном месте и гарантированно работает.
Можно разобраться, настроить под себя и, к примеру, добавить туда поддержку внешних хостов. Надо будет добавить новые внешние Datasources и какие-то метки внедрить, чтобы различать хосты и делать общие дашборды. Получится ещё одна курсовая работа.
Сам проект не развивается и не обновляется. Так что ждать от него чего-то сверх того, что там есть, не имеет смысла.
#мониторинг #grafana #docker #prometheus
{kind=link}
Наиболее популярным и простым в настройке мониторингом сейчас является Prometheus. Простым не в плане возможностей, а в плане начальной настройки. Так как для него очень много всего автоматизировано, начать сбор метрик можно в несколько простых действий. Мониторинг сразу заработает и дальше с ним можно разбираться и настраивать.
Напишу краткую шпаргалку по запуску связки Prometheus + Grafana, чтобы её можно было сохранить и использовать по мере надобности. Я установлю их в Docker, сразу буду мониторить сам Prometheus и локальных хост Linux. Подключу для примера ещё один внешний Linux сервер.
Ставим Docker:
Готовим файл
Содержимое файла:
И рядом кладём конфиг
Запускаем весь стек:
Если будут ошибки, прогоните весь yaml через какой-нибудь валидатор. При копировании он часто ломается.
Ждём, когда всё поднимется, и идём по IP адресу сервера на порт 3000. Логинимся в Grafana под учёткой admin / admin. Заходим в Connections ⇨ Data sources и добавляем источник prometheus. В качестве параметра Prometheus server URL указываем http://prometheus:9090. Сохраняем.
Идём в Dashboards, нажимаем New ⇨ Import. Вводим ID дашборда для Node Exporter - 1860. Сохраняем и идём смотреть дашборд. Увидите все доступные графики и метрики хоста Linux, на котором всё запущено.
Идём на удалённый Linux хост и запускаем там любым подходящим способом node-exporter. Например, через Docker напрямую:
Проверяем, что сервис запущен на порту 9100:
Возвращаемся на сервер с prometheus и добавляем в его конфиг еще одну job с этим сервером:
Перезапускаем стек:
Идём в Dashboard в Grafana и выбираем сверху в выпадающем списке job от этого нового сервера - node-remote.
На всю настройку уйдёт минут 10. Потом ещё 10 на настройку базовых уведомлений. У меня уже места не хватило их добавить сюда. Наглядно видна простота и скорость настройки, о которых я сказал в начале.
❗️В проде не забывайте ограничивать доступ ко всем открытым портам хостов с помощью файрвола.
#мониторинг #prometheus #devops
Напишу краткую шпаргалку по запуску связки Prometheus + Grafana, чтобы её можно было сохранить и использовать по мере надобности. Я установлю их в Docker, сразу буду мониторить сам Prometheus и локальных хост Linux. Подключу для примера ещё один внешний Linux сервер.
Ставим Docker:
# curl https://get.docker.com | bash -Готовим файл
docker-compose.yml:# mkdir ~/prometheus && cd ~/prometheus# touch docker-compose.ymlСодержимое файла:
version: '3.9'networks: monitoring: driver: bridgevolumes: prometheus_data: {}services: prometheus: image: prom/prometheus:latest volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml - prometheus_data:/prometheus container_name: prometheus hostname: prometheus command: - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' expose: - 9090 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoring node-exporter: image: prom/node-exporter volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro container_name: exporter hostname: exporter command: - '--path.procfs=/host/proc' - '--path.rootfs=/rootfs' - '--path.sysfs=/host/sys' - '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)' expose: - 9100 restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoring grafana: image: grafana/grafana user: root depends_on: - prometheus ports: - 3000:3000 volumes: - ./grafana:/var/lib/grafana - ./grafana/provisioning/:/etc/grafana/provisioning/ container_name: grafana hostname: grafana restart: unless-stopped environment: TZ: "Europe/Moscow" networks: - monitoringИ рядом кладём конфиг
prometheus.yml:scrape_configs: - job_name: 'prometheus' scrape_interval: 5s scrape_timeout: 5s static_configs: - targets: ['localhost:9090'] - job_name: 'node-local' scrape_interval: 5s static_configs: - targets: ['node-exporter:9100']Запускаем весь стек:
# docker-compose up -dЕсли будут ошибки, прогоните весь yaml через какой-нибудь валидатор. При копировании он часто ломается.
Ждём, когда всё поднимется, и идём по IP адресу сервера на порт 3000. Логинимся в Grafana под учёткой admin / admin. Заходим в Connections ⇨ Data sources и добавляем источник prometheus. В качестве параметра Prometheus server URL указываем http://prometheus:9090. Сохраняем.
Идём в Dashboards, нажимаем New ⇨ Import. Вводим ID дашборда для Node Exporter - 1860. Сохраняем и идём смотреть дашборд. Увидите все доступные графики и метрики хоста Linux, на котором всё запущено.
Идём на удалённый Linux хост и запускаем там любым подходящим способом node-exporter. Например, через Docker напрямую:
# docker run -d --net="host" --pid="host" -v "/:/host:ro,rslave" prom/node-exporter:latest --path.rootfs=/hostПроверяем, что сервис запущен на порту 9100:
# ss -tulnp | grep 9100Возвращаемся на сервер с prometheus и добавляем в его конфиг еще одну job с этим сервером:
- job_name: 'node-remote' scrape_interval: 5s static_configs: - targets: ['10.20.1.56:9100']Перезапускаем стек:
# docker compose restartИдём в Dashboard в Grafana и выбираем сверху в выпадающем списке job от этого нового сервера - node-remote.
На всю настройку уйдёт минут 10. Потом ещё 10 на настройку базовых уведомлений. У меня уже места не хватило их добавить сюда. Наглядно видна простота и скорость настройки, о которых я сказал в начале.
❗️В проде не забывайте ограничивать доступ ко всем открытым портам хостов с помощью файрвола.
#мониторинг #prometheus #devops
{kind=link}
Вчера была заметка про быструю установку связки Prometheus + Grafana. Из-за лимита Telegram на длину сообщений разом всё описать не представляется возможным. А для полноты картины не хватает настройки уведомлений, так как мониторинг без них это не мониторинг, а красивые картинки.
Для примера я настрою два типа уведомлений:
◽SMTP для только для метки critical
◽Telegram для меток critical и warning
Уведомления будут отправляться на основе двух событий:
▪️ С хоста нету метрик, то есть он недоступен мониторингу, метка critical
▪️ На хосте процессор занят в течении минуты более чем на 70%, метка warning
Я взял именно эти ситуации, так как на их основе будет понятен сам принцип настройки и формирования конфигов, чтобы каждый потом смог доработать под свои потребности.
Постить сюда все конфигурации в формате yaml неудобно, поэтому решил их собрать в архив и прикрепить в следующем сообщении. Там будут 4 файла:
-
-
-
-
Для запуска всего стека с уведомлениями достаточно положить эти 4 файла в отдельную директорию и там запустить compose:
На момент отладки рекомендую запускать прямо в консоли, чтобы отлавливать ошибки. Если где-то ошибётесь в конфигурациях правил или alertmanager, сразу увидите ошибки и конкретные строки конфигурации, с которыми что-то не так. В таком случае останавливайте стэк:
Исправляйте конфиги и заново запускайте. Зайдя по IP адресу сервера на порт 9090, вы попадёте в веб интерфейс Prometheus. Там будет отдельный раздел Alerts, где можно следить за работой уведомлений.
В данном примере со всем стэком наглядно показан принцип построения современного мониторинга с подходом инфраструктура как код (IaC). Имея несколько файлов конфигурации, мы поднимаем необходимую систему во всей полноте. Её легко переносить, изменять конфигурацию и отслеживать эти изменения через git.
#мониторинг #prometheus #devops
Для примера я настрою два типа уведомлений:
◽SMTP для только для метки critical
◽Telegram для меток critical и warning
Уведомления будут отправляться на основе двух событий:
▪️ С хоста нету метрик, то есть он недоступен мониторингу, метка critical
▪️ На хосте процессор занят в течении минуты более чем на 70%, метка warning
Я взял именно эти ситуации, так как на их основе будет понятен сам принцип настройки и формирования конфигов, чтобы каждый потом смог доработать под свои потребности.
Постить сюда все конфигурации в формате yaml неудобно, поэтому решил их собрать в архив и прикрепить в следующем сообщении. Там будут 4 файла:
-
docker-compose.yml - основной файл с конфигурацией всех сервисов. Его описание можно посмотреть в предыдущем посте. Там добавился новый контейнер с alertmanager и файл с правилами для prometheus - alert.rules-
prometheus.yml - настройки Прометеуса.-
alert.rules - файл с двумя правилами уведомлений о недоступности хоста и превышении нагрузки CPU.-
alertmanager.yml - настройки alertmanager с двумя источниками для уведомлений: email и telegram. Не забудьте там поменять токен бота, id своего аккаунта, куда бот будет отправлять уведомления и настройки smtp.Для запуска всего стека с уведомлениями достаточно положить эти 4 файла в отдельную директорию и там запустить compose:
# docker compose upНа момент отладки рекомендую запускать прямо в консоли, чтобы отлавливать ошибки. Если где-то ошибётесь в конфигурациях правил или alertmanager, сразу увидите ошибки и конкретные строки конфигурации, с которыми что-то не так. В таком случае останавливайте стэк:
# docker compose stopИсправляйте конфиги и заново запускайте. Зайдя по IP адресу сервера на порт 9090, вы попадёте в веб интерфейс Prometheus. Там будет отдельный раздел Alerts, где можно следить за работой уведомлений.
В данном примере со всем стэком наглядно показан принцип построения современного мониторинга с подходом инфраструктура как код (IaC). Имея несколько файлов конфигурации, мы поднимаем необходимую систему во всей полноте. Её легко переносить, изменять конфигурацию и отслеживать эти изменения через git.
#мониторинг #prometheus #devops
{kind=link}
Я недавно написал 2 публикации на тему настройки мониторинга на базе Prometheus (1, 2). Они получились чуток недоделанными, потому что некоторые вещи всё же приходилось делать руками - добавлять Datasource и шаблоны. Решил это исправить, чтобы в полной мере раскрыть принцип IaC (инфраструктура как код). Плюс, для полноты картины, добавил туда в связку ещё и blackbox-exporter для мониторинга за сайтами. В итоге в пару кликов можно развернуть полноценный мониторинг с примерами стандартных конфигураций, дашбордов, оповещений.
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
Что есть что:
▪️
▪️
▪️
▪️
▪️
▪️
▪️
Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
Идём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
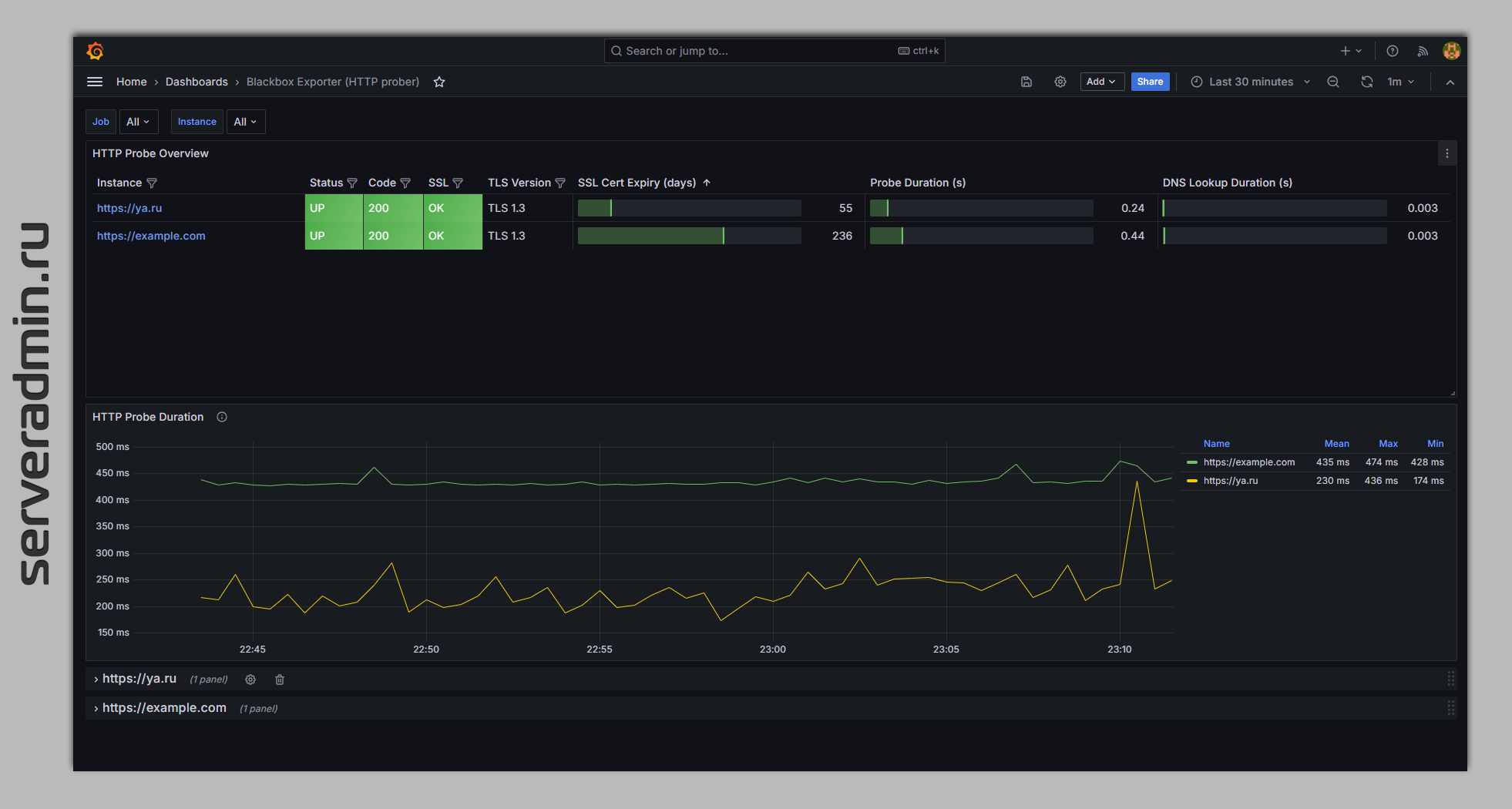
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
Для того, чтобы более ясно представлять о чём тут пойдёт речь, лучше прочитать две первых публикации, на которые я дал ссылки. Я подготовил docker-compose и набор других необходимых файлов, чтобы автоматически развернуть базовый мониторинг на базе Prometheus, Node-exporter, Blackbox-exporter, Alert Manager и Grafana.
По просьбам трудящихся залил всё в Git репозиторий. Клонируем к себе и разбираемся:
# git clone https://gitflic.ru/project/serveradmin/prometheus.git# cd prometheusЧто есть что:
▪️
docker-compose.yml - основной compose файл, где описаны все контейнеры.▪️
prometheus.yml - настройки prometheus, где для примера показаны задачи мониторинга локального хоста, удалённого хоста с node-exporter, сайтов через blackbox.▪️
blackbox.yml - настройки для blackbox, для примера взял только проверку кодов ответа веб сервера. ▪️
alertmanager.yml - настройки оповещений, для примера настроил smtp и telegram▪️
alert.rules - правила оповещений для alertmanager, для примера настроил 3 правила - недоступность хоста, перегрузка по CPU, недоступность сайта.▪️
grafana\provisioning\datasources\prometheus.yml - автоматическая настройка datasource в виде локального prometheus, чтобы не ходить, руками не добавлять.▪️
grafana\provisioning\dashboards - автоматическое добавление трёх дашбордов: один для node-exporter, два других для blackbox.Скопировали репозиторий, пробежались по настройкам, что-то изменили под свои потребности. Запускаем:
# docker compose up -dИдём на порт сервера 3000 и заходим в Grafana. Учётка стандартная - admin / admin. Видим там уже 3 настроенных дашборда. На порту 9090 живёт сам Prometheus, тоже можно зайти, посмотреть.
Вот ссылки на шаблоны, которые я добавил. Можете посмотреть картинки, как это будет выглядеть. У Blackbox информативные дашборды. Уже только для них можно использовать эту связку, так как всё уже сделано за вас. Вам нужно будет только список сайтов заполнить в prometheus.yml.
⇨ Blackbox Exporter (HTTP prober)
⇨ Prometheus Blackbox Exporter
⇨ Node Exporter Full
Для того, чтобы автоматически доставлять все изменения в настройках на сервер мониторинга, можно воспользоваться моей инструкцией на примере gatus и gitlab-ci. Точно таким же подходом вы можете накатывать и изменения в этот мониторинг.
Мне изначально казалось, что подобных примеров уже много. Но когда стало нужно, не нашёл чего-то готового, чтобы меня устроило. В итоге сам набросал вот такой проект. Сделал в том числе и для себя, чтобы всё в одном месте было для быстрого развёртывания. Каждая отдельная настройка, будь то prometheus, alertmanager, blackbox хорошо гуглятся. Либо можно сразу в документацию идти, там всё подробно описано. Не стал сюда ссылки добавлять, чтобы не перегружать.
❗️Будьте аккуратны при работе с Prometheus и ему подобными, где всё состояние инфраструктуры описывается только кодом. После него будет трудно возвращаться к настройке и управлению Zabbix. Давно это ощущаю на себе. Хоть у них и сильно разные возможности, но IaC подкупает.
#prometheus #devops #мониторинг
{kind=link}