
Forwarded from Data Science by ODS.ai 🦜
This media is not supported in your browser
VIEW IN TELEGRAM
Nvidia AI Noise Reduction
#Nvidia launches #KrispAI competitor Noise Reduction by AI on RTX Videocards.
Seems it works significantly better then other that kind of tools. But it needs to have Nvidia RTX officially.
But it possible to run it on older cards. The instruction is below. Or you can just download already hacked executable (also, below)
Setup Guide: https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
The instruction: https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
Executable (use it on your own risk): https://mega.nz/file/CJ0xDYTB#LPorY_aPVqVKfHqWVV7zxK8fNfRmxt6iw6KdkHodz1M
#noisereduction #soundlearning #dl #noise #sound #speech #nvidia
#Nvidia launches #KrispAI competitor Noise Reduction by AI on RTX Videocards.
Seems it works significantly better then other that kind of tools. But it needs to have Nvidia RTX officially.
But it possible to run it on older cards. The instruction is below. Or you can just download already hacked executable (also, below)
Setup Guide: https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/
The instruction: https://forums.guru3d.com/threads/nvidia-rtx-voice-works-without-rtx-gpu-heres-how.431781/
Executable (use it on your own risk): https://mega.nz/file/CJ0xDYTB#LPorY_aPVqVKfHqWVV7zxK8fNfRmxt6iw6KdkHodz1M
#noisereduction #soundlearning #dl #noise #sound #speech #nvidia
Forwarded from Data Science by ODS.ai 🦜
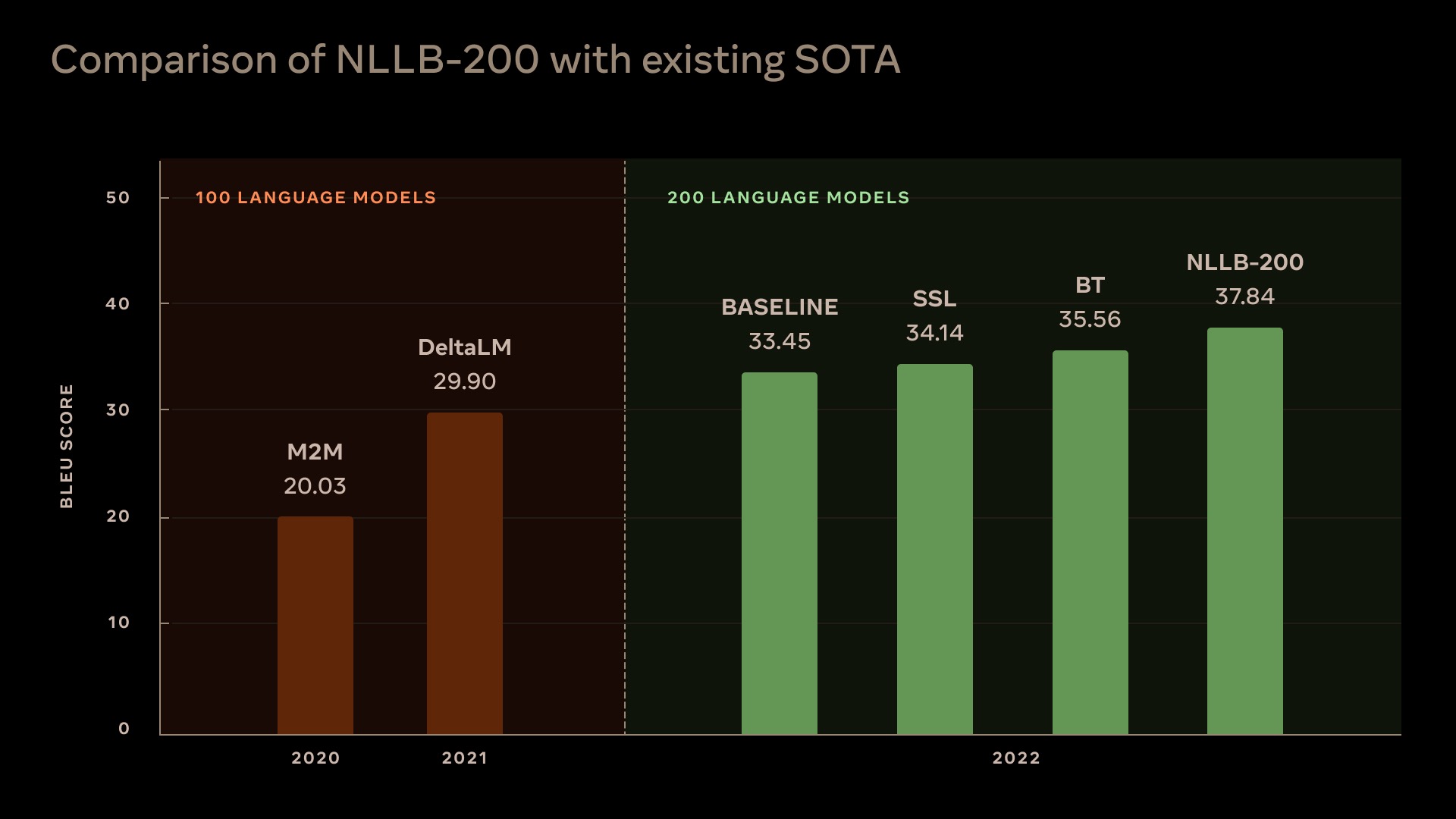
No Language Left Behind
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
{kind=link}