
Interesting dataset with room layouts (a lot of them)
- http://lsun.cs.princeton.edu/2015.html
- http://lsun.cs.princeton.edu/2016/
#datasets
- http://lsun.cs.princeton.edu/2015.html
- http://lsun.cs.princeton.edu/2016/
#datasets
Interesting datasets from Kaggle
Predict breast cancer from slide images
https://goo.gl/rDxrpZ
High quality academic dataset of 26k images of 41 fruits
https://goo.gl/JLWvLD
Gorgeous illustration of different network algorithms
https://goo.gl/z7oori
Crowd-sourced translation of parallel sentence pairs
https://goo.gl/7ky8Vw
5 years of hourly weather data for 36 cities
https://goo.gl/jjkRSq
#data_science
#datasets
Predict breast cancer from slide images
https://goo.gl/rDxrpZ
High quality academic dataset of 26k images of 41 fruits
https://goo.gl/JLWvLD
Gorgeous illustration of different network algorithms
https://goo.gl/z7oori
Crowd-sourced translation of parallel sentence pairs
https://goo.gl/7ky8Vw
5 years of hourly weather data for 36 cities
https://goo.gl/jjkRSq
#data_science
#datasets
Kaggle
Breast Histopathology Images
198,738 IDC(-) image patches; 78,786 IDC(+) image patches
New datasets
(1) HDR Dataset from Google
3,640 bursts of full-resolution raw images, made up of 28,461 individual images, along with HDR+ intermediate and final results for comparison
https://research.googleblog.com/2018/02/introducing-hdr-burst-photography.html
(2) Huge Anime dataset - 2.9m+ images annotated with 77.5m+ tags - https://www.gwern.net/Danbooru2017
#datasets
(1) HDR Dataset from Google
3,640 bursts of full-resolution raw images, made up of 28,461 individual images, along with HDR+ intermediate and final results for comparison
https://research.googleblog.com/2018/02/introducing-hdr-burst-photography.html
(2) Huge Anime dataset - 2.9m+ images annotated with 77.5m+ tags - https://www.gwern.net/Danbooru2017
#datasets
Google AI Blog
Introducing the HDR+ Burst Photography Dataset
Posted by Sam Hasinoff, Software Engineer, Machine Perception Burst photography is the key idea underlying the HDR+ software on Google's...
Forwarded from Data Science by ODS.ai 🦜
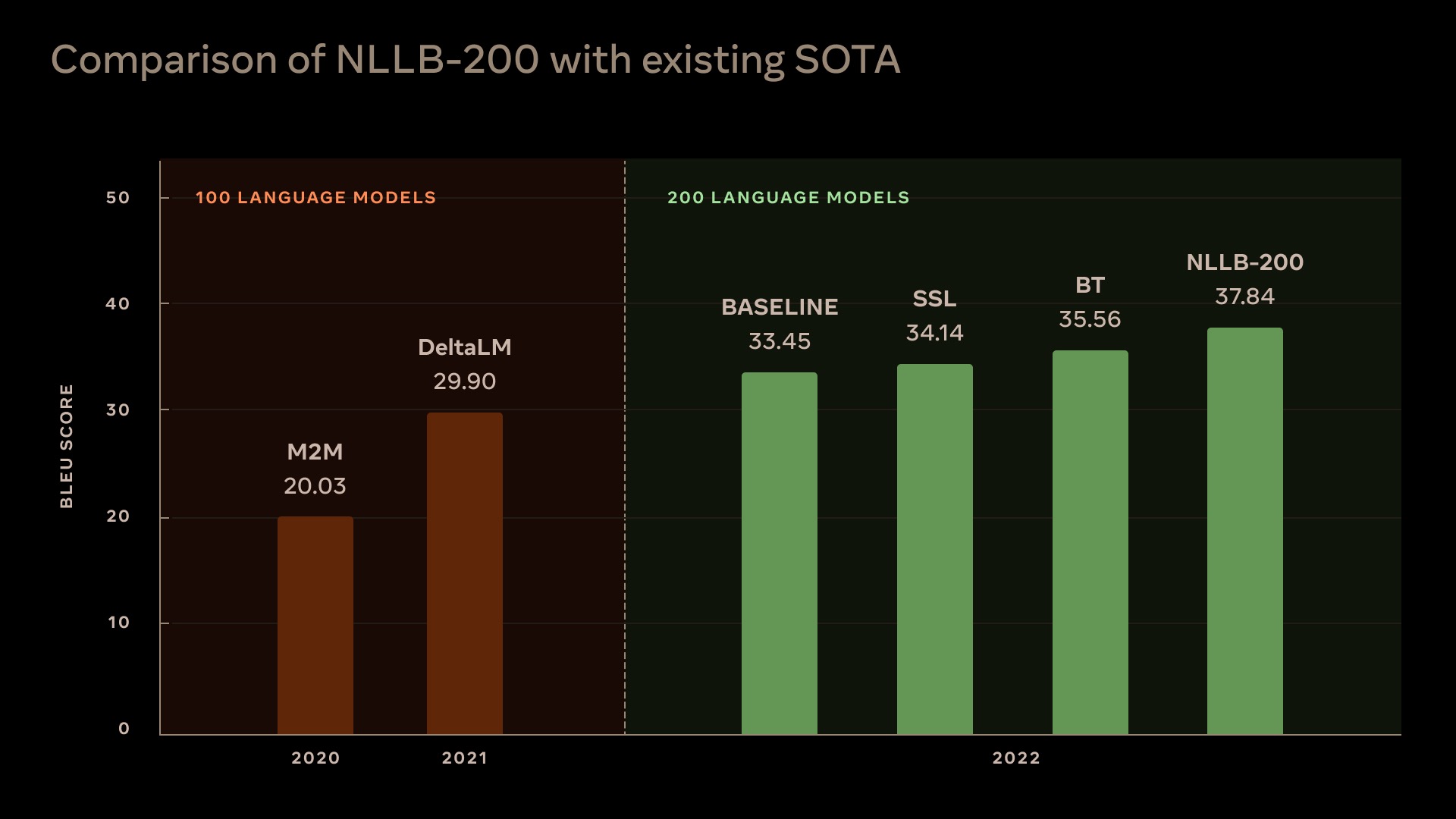
No Language Left Behind
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
{kind=link}