
Forwarded from Data Science by ODS.ai 🦜
LLaMA: Open and Efficient Foundation Language Models
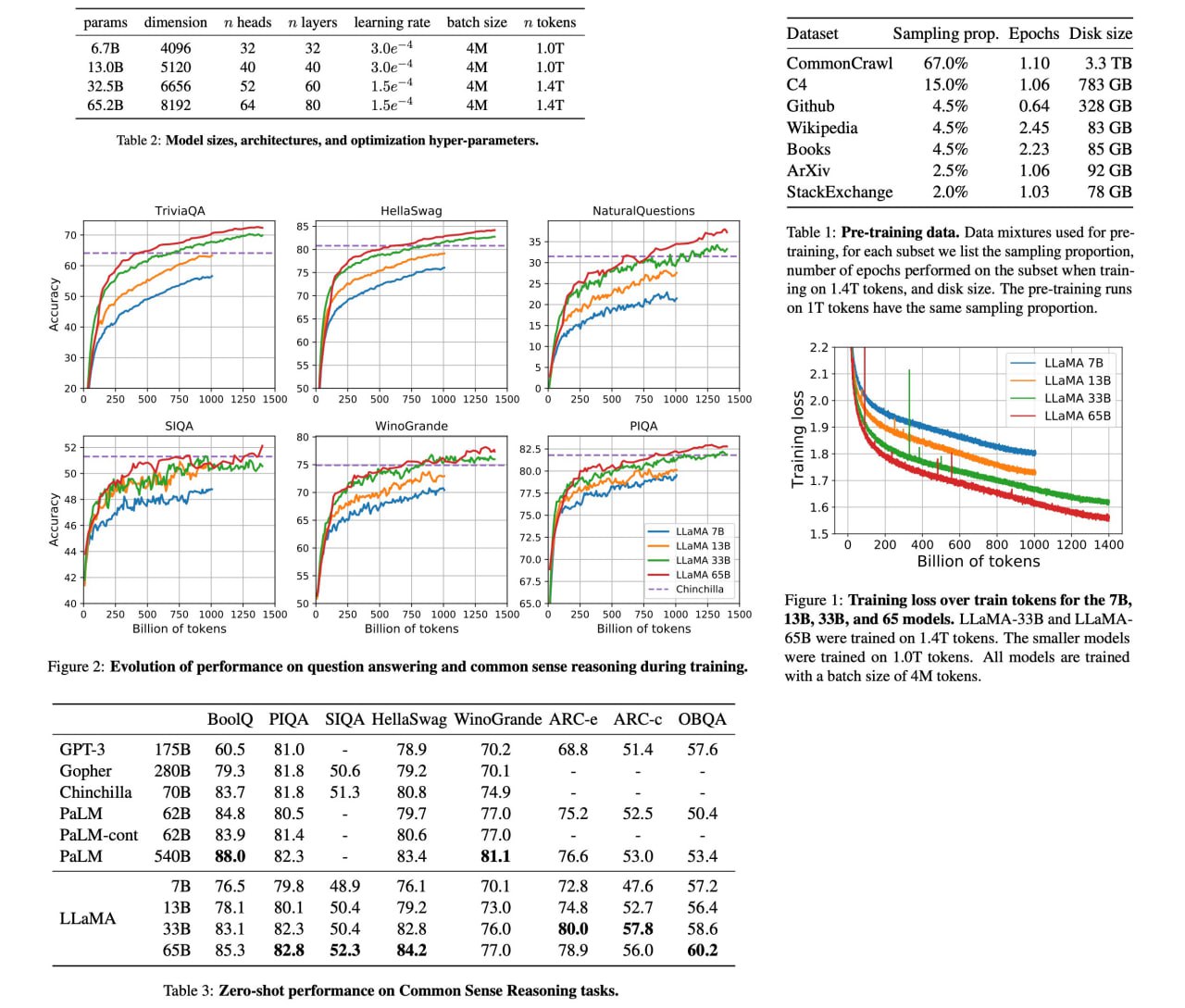
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
DINOv2: Learning Robust Visual Features without Supervision
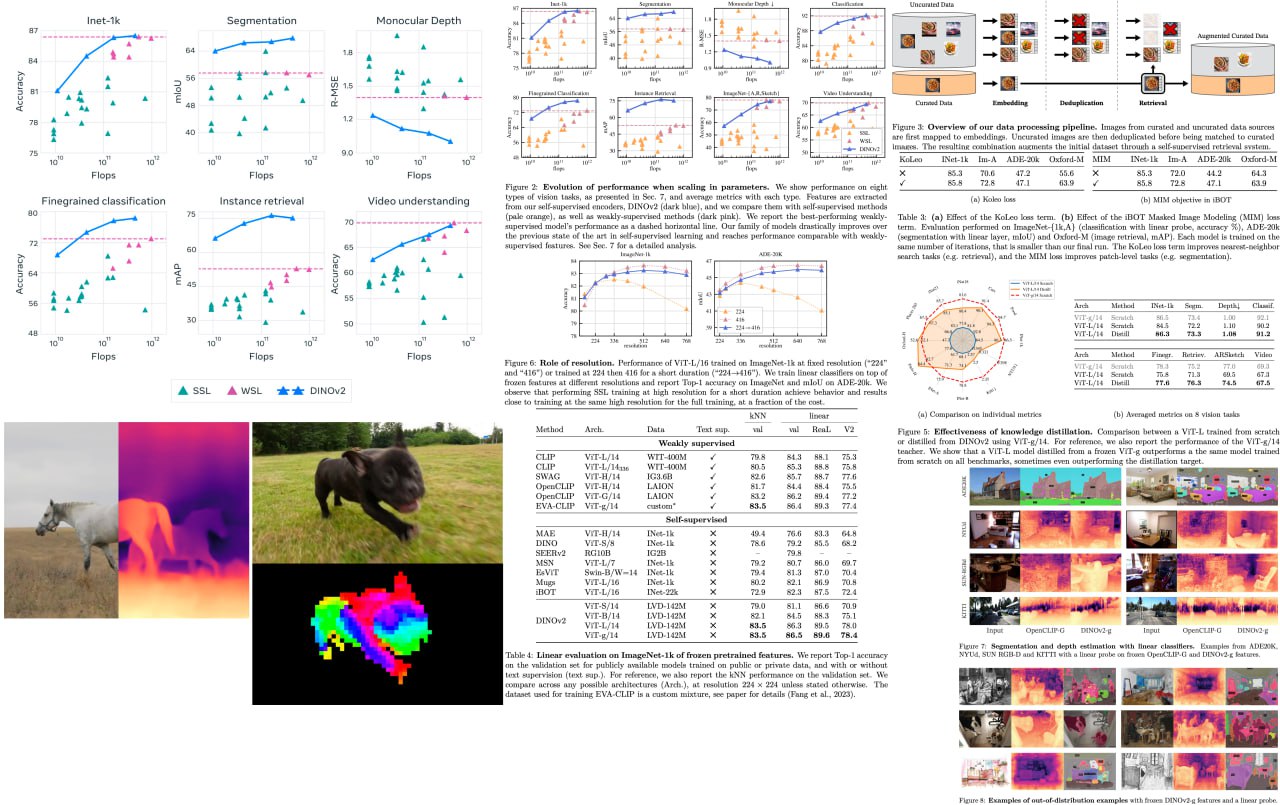
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Fast Segment Anything
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
The Segment Anything Model (SAM), a revolutionary tool in computer vision tasks, has significantly impacted various high-level tasks like image segmentation, image captioning, and image editing. However, its application has been restricted in industry scenarios due to its enormous computational demand, largely attributed to the Transformer architecture handling high-resolution inputs.
The authors of this paper have proposed a speedier alternative method that accomplishes this foundational task with performance on par with SAM, but at a staggering 50 times faster! By ingeniously reformulating the task as segments-generation and prompting and employing a regular CNN detector with an instance segmentation branch, they've converted this task into the well-established instance segmentation task. The magic touch? They've trained the existing instance segmentation method using just 1/50 of the SA-1B dataset, a stroke of brilliance that led to a solution marrying performance and efficiency.
Paper link: https://huggingface.co/papers/2306.12156
Code link: https://github.com/CASIA-IVA-Lab/FastSAM
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-fastsam
#deeplearning #cv #segmentanythingmodel #efficiency
{kind=link}
Forwarded from Data Science by ODS.ai 🦜
Retentive Network: A Successor to Transformer for Large Language Models
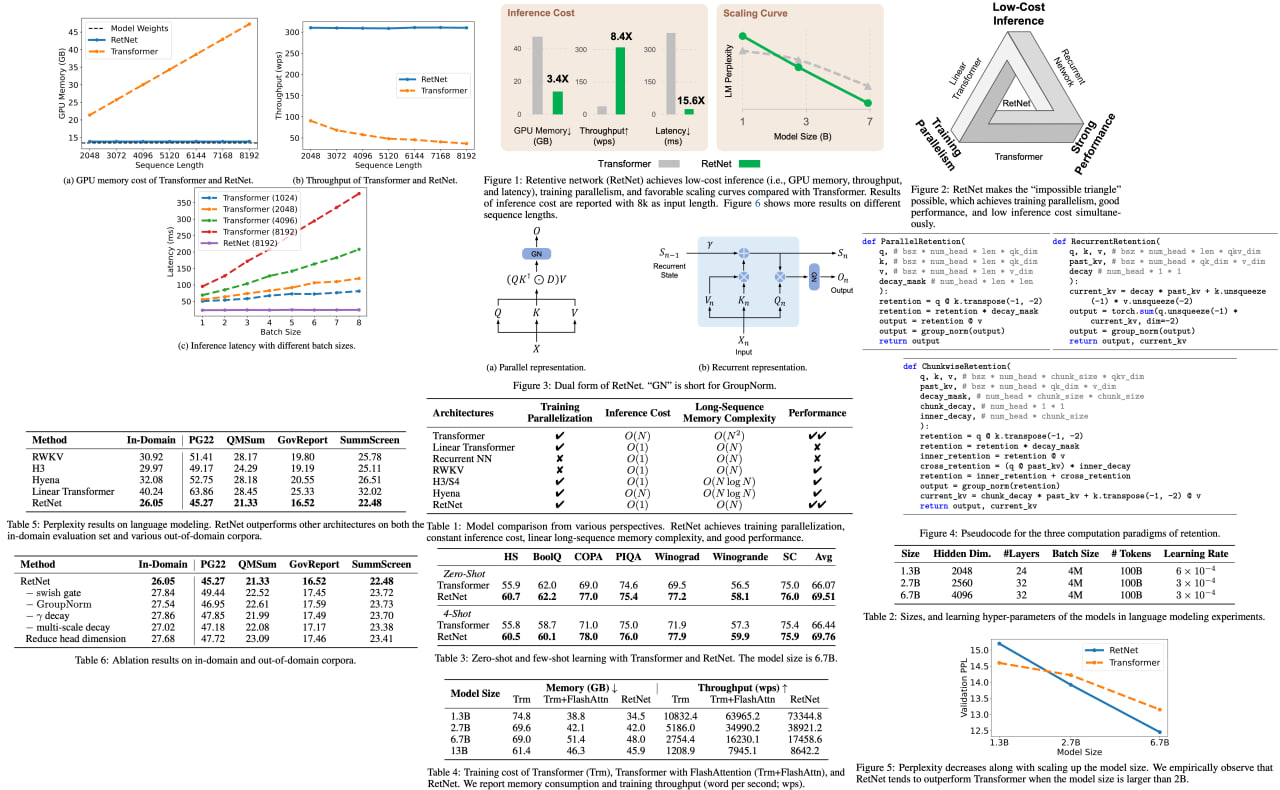
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
{kind=link}